
Comparison of Random Forest and Gradient Boosting Machine Models for Predicting Demolition Waste Based on Small Datasets and Categorical Variables


Abstract
:1. Introduction
2. Description of Artificial Intelligence in Predicting DW Generation in This Study
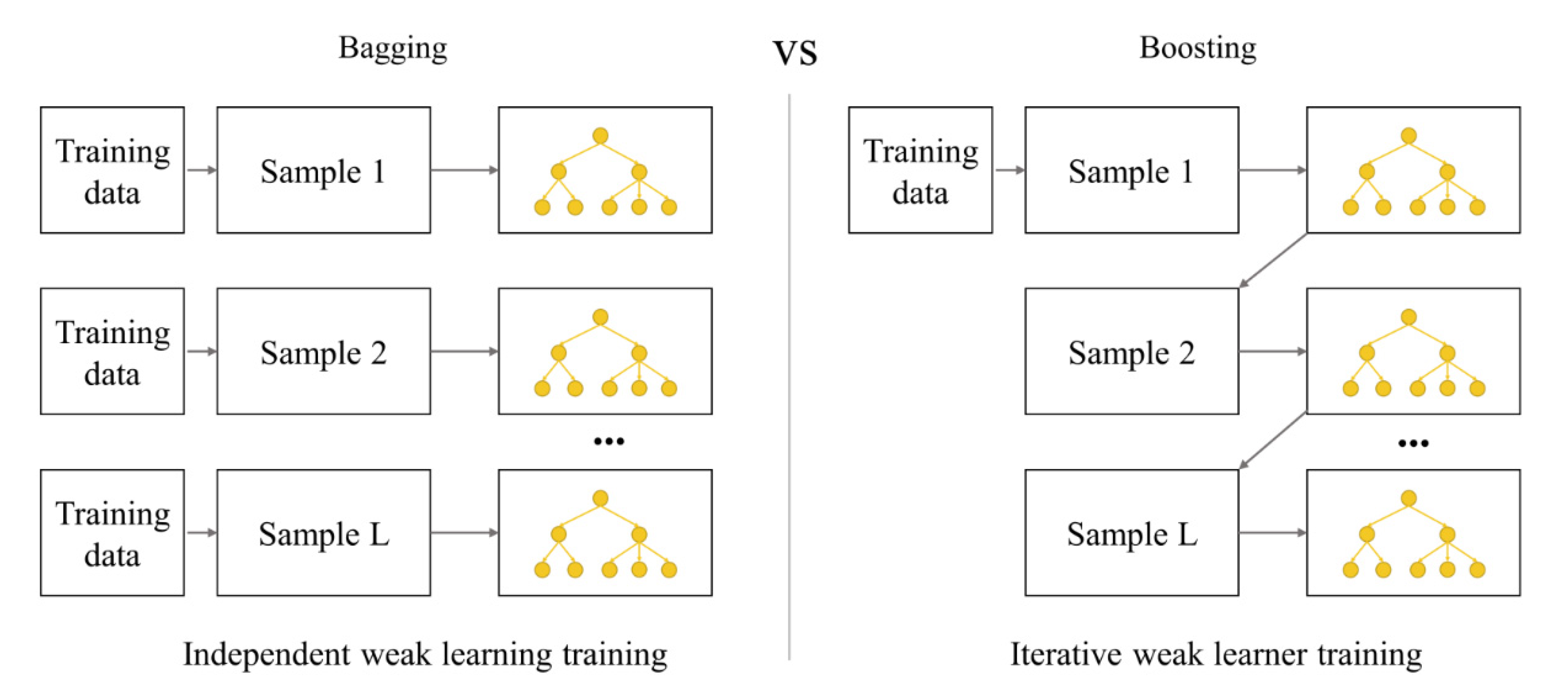
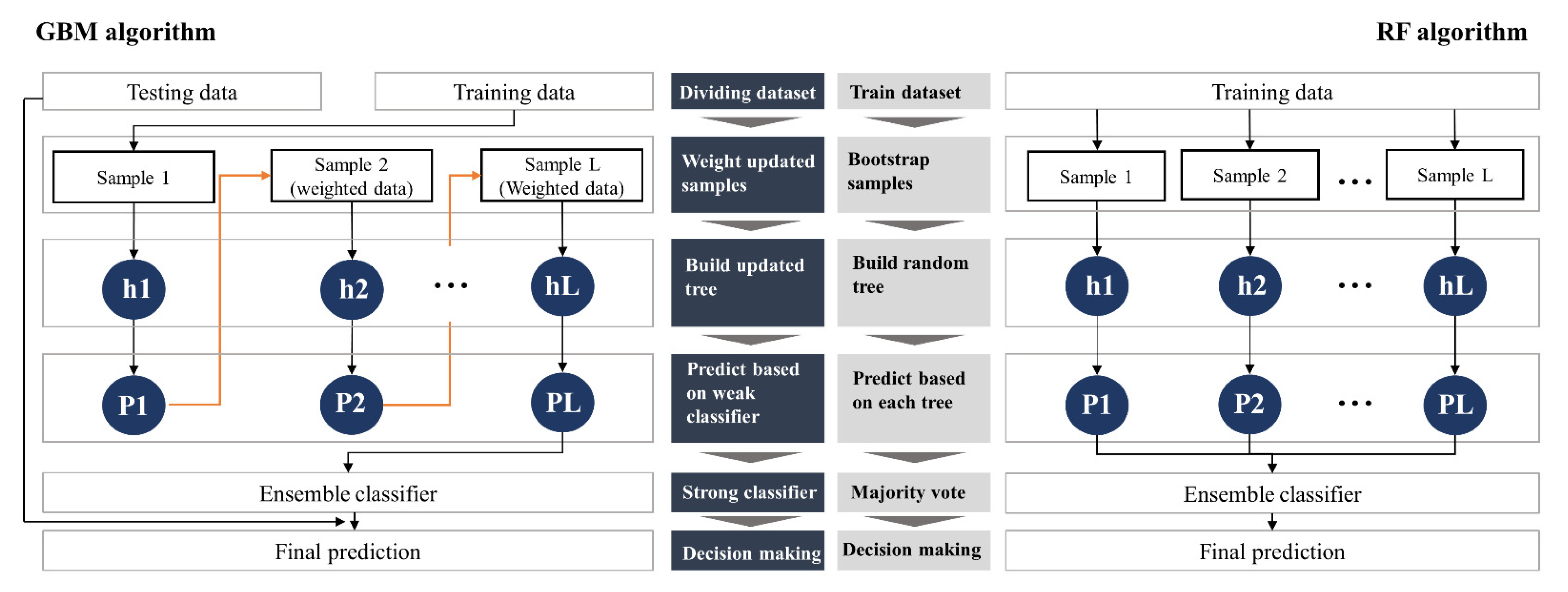
2.1. Ensemble Model
2.2. Gradient Boosting Machine and Random Forest
2.3. Leave-One-Out Cross-Validation (LOOCV)
3. Materials and Methods
3.1. Data Source of Demolition Waste Generation (DWG) Data
3.2. Data Preprocessing and Preparing Datasets for Prediction Models
3.3. Characteristics and Composition of Variables
3.4. Application of Machine Learning Techniques
3.5. Model Validation
4. Results and Discussions
4.1. Model Performance
4.2. Comparison of Predictive Models
4.3. Discussion, Limitations, and Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization Centre for Health Development; World Health Organization. Hidden Cities: Unmasking and Overcoming Health Inequities in Urban Settings. 2010. Available online: https://www.who.int/publications/i/item/9789241548038 (accessed on 12 May 2021).
- Leão, S.; Bishop, I.; Evans, D. Spatial–Temporal Model for Demand and Allocation of Waste Landfills in Growing Urban Regions. Comput. Environ. Urban Syst. 2004, 28, 353–385. [Google Scholar] [CrossRef]
- World Bank. What a Waste 2.0: A Global Snapshot of Solid Waste Management to 2050; International Bank for Reconstruction and Development/World Bank: Washington, DC, USA, 2018. [Google Scholar]
- Llatas, C. A Model for Quantifying Construction Waste in Projects According to the European Waste List. Waste Manag. 2011, 31, 1261–1276. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Ding, Z.; Mi, X.; Wang, J. A Model for Estimating Construction Waste Generation Index for Building Project in China. Resour. Conserv. Recycl. 2013, 74, 20–26. [Google Scholar] [CrossRef]
- Wang, J.; Li, Z.; Tam, V.W.Y. Identifying Best Design Strategies for Construction Waste Minimization. J. Clean. Prod. 2015, 92, 237–247. [Google Scholar] [CrossRef]
- Lu, W.; Yuan, H.; Li, J.; Hao, J.J.; Mi, X.; Ding, Z. An Empirical Investigation of Construction and Demolition Waste Generation Rates in Shenzhen City, South China. Waste Manag. 2011, 31, 680–687. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Butera, S.; Christensen, T.H.; Astrup, T.F. Composition and Leaching of Construction and Demolition Waste: Inorganic Elements and Organic Compounds. J. Hazard. Mater. 2014, 276, 302–311. [Google Scholar] [CrossRef]
- Banias, G.; Achillas, C.; Vlachokostas, C.; Moussiopoulos, N.; Papaioannou, I. A Web-Based Decision Support System for the Optimal Management of Construction and Demolition Waste. Waste Manag. 2011, 31, 2497–2502. [Google Scholar] [CrossRef]
- Song, Y.; Wang, Y.; Liu, F.; Zhang, Y. Development of a Hybrid Model to Predict Construction and Demolition Waste: China as a Case Study. Waste Manag. 2017, 59, 350–361. [Google Scholar] [CrossRef]
- Lu, W.S.; Yuan, H.P. A Framework for Understanding Waste Management Studies in Construction. Waste Manag. 2011, 31, 1252–1260. [Google Scholar] [CrossRef] [Green Version]
- Hurley, J.W. Valuing the Pre-Demolition Audit Process. In Proceedings of the 11th Rinker International Conference (CIB report 287), Gainesville, FL, USA, 7–10 May 2003; pp. 151–164. Available online: https://www.cce.ufl.edu/wp-content/uploads/2012/08/Deconstruction_and_Materials_Reuse.pdf (accessed on 3 May 2021).
- Nagalli, A. Estimation of construction waste generation using machine learning. Proc. Inst. Civ. Eng. Waste Resour. Manag. 2021, 174, 22–31. [Google Scholar]
- Coskuner, G.; Jassim, M.S.; Zontul, M.; Karateke, S. Application of Artificial Intelligence Neural Network Modeling to Predict the Generation of Domestic, Commercial and Construction Wastes. Waste Manag. Res. 2021, 39, 499–507. [Google Scholar] [CrossRef]
- Abdallah, M.; Abu Talib, M.A.; Feroz, S.; Nasir, Q.; Abdalla, H.; Mahfood, B. Artificial Intelligence Applications in Solid Waste Management: A Systematic Research Review. Waste Manag. 2020, 109, 231–246. [Google Scholar] [CrossRef] [PubMed]
- Golbaz, S.; Nabizadeh, R.; Sajadi, H.S. Comparative Study of Predicting Hospital Solid Waste Generation Using Multiple Linear Regression and Artificial Intelligence. J. Environ. Health Sci. Eng. 2019, 17, 41–51. [Google Scholar] [CrossRef]
- Noori, R.; Karbassi, A.; Salman Sabahi, M.S. Evaluation of PCA and Gamma Test Techniques on ANN Operation for Weekly Solid Waste Prediction. J. Environ. Manag. 2010, 91, 767–771. [Google Scholar] [CrossRef] [PubMed]
- Abbasi, M.; Abduli, M.A.; Omidvar, B.; Baghvand, A. Forecasting Municipal Solid Waste Generation by Hybrid Support Vector Machine and Partial Least Square Model. Int. J. Environ. Resour. 2013, 7, 27–38. [Google Scholar]
- Kumar, A.; Samadder, S.R.; Kumar, N.; Singh, C. Estimation of the Generation Rate of Different Types of Plastic Wastes and Possible Revenue Recovery from Informal Recycling. Waste Manag. 2018, 79, 781–790. [Google Scholar] [CrossRef] [PubMed]
- Abdoli, M.A.; Nezhad, M.F.; Sede, R.S.; Behboudian, S. Longterm Forecasting of Solid Waste Generation by the Artificial Neural Networks. Environ. Prog. Sustain. Energy 2011, 31, 628–636. [Google Scholar] [CrossRef]
- Azadi, S.; Karimi-Jashni, A. Verifying the Performance of Artificial Neural Network and Multiple Linear Regression in Predicting the Mean Seasonal Municipal Solid Waste Generation Rate: A Case Study of Fars Province, Iran. Waste Manag. 2016, 48, 14–23. [Google Scholar] [CrossRef] [PubMed]
- Chhay, L.; Reyad, M.A.H.; Suy, R.; Islam, M.R.; Mian, M.M. Municipal Solid Waste Generation in China: Influencing Factor Analysis and Multi-Model Forecasting. J. Mater. Cycles Waste Manag. 2018, 20, 1761–1770. [Google Scholar] [CrossRef]
- Cha, G.W.; Moon, H.J.; Kim, Y.M.; Hong, W.H.; Hwang, J.H.; Park, W.J.; Kim, Y.C. Development of a Prediction Model for Demolition Waste Generation Using a Random Forest Algorithm Based on Small DataSets. Int. J. Environ. Res. Public Health 2020, 17, 6997. [Google Scholar] [CrossRef]
- Raschka, S. Model Evaluation, Model Selection, and Algorithm Selection in Machine Learning. Comput. Res. Repos. 2018, 1811, 12808. [Google Scholar]
- Jiang, Y.; Lin, J.; Cukic, B.; Menzies, T. Variance Analysis in Software Fault Prediction Models. In Proceedings of the ISSRE’09: 20th I.E.E.E. international Conference on Software Reliability Engineering, Bengaluru, India, 16–19 November 2009; pp. 99–108. [Google Scholar]
- Cha, G.W.; Kim, Y.C.; Moon, H.J. New Approach for Forecasting Demolition Waste Generation Using Chi-Squared Automatic Interaction Detection (CHAID) Method. J. Clean. Prod. 2017, 168, 375–385. [Google Scholar] [CrossRef]
- Opitz, D.; Maclin, R. Popular Ensemble Methods: An Empirical Study. J. Artif. Intell. Res. 1999, 11, 169–198. [Google Scholar] [CrossRef]
- Ghimire, B.; Rogan, J.; Galiano, V.R.; Panday, P.; Neeti, N. An Evaluation of Bagging, Boosting, and Random Forests for Land-Cover Classification in Cape Cod, Massachusetts, USA. GISci. Remote Sens. 2012, 49, 623–643. [Google Scholar] [CrossRef]
- Dietterich, T.G. An Experimental Comparison of Three Methods for Constructing Ensembles of Decision Trees: Bagging, Boosting, and Randomization. Mach. Learn. 2000, 40, 139–157. [Google Scholar] [CrossRef]
- Zhou, Z.H. Ensemble Methods; Foundations and Algorithms; CRC Press: Boca Raton, FL, USA; London, UK; New York, NY, USA, 2012. [Google Scholar]
- Van der Laan, M.J.; Polley, E.C.; Hubbard, A.E. Super Learner. Stat. Appl. Genet. Mol. Biol. 2007, 6, 25. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, X.C.; Nguyen, T.T.H.; La, D.D.; Kumar, G.; Rene, E.R.; Nguyen, D.D.; Chang, S.W.; Chung, W.J.; Nguyen, X.H.; Nguyen, V.K. Development of Machine Learning—Based Models to Forecast Solid Waste Generation in Residential Areas: A Case Study from Vietnam. Resour. Conserv. Recycl. 2021, 167, 105381. [Google Scholar] [CrossRef]
- Johnson, N.E.; Ianiuk, O.; Cazap, D.; Liu, L.; Starobin, D.; Dobler, G.; Ghandehari, M. Patterns of Waste Generation: A Gradient Boosting Model for Short-Term Waste Prediction in New York City. Waste Manag. 2017, 62, 3–11. [Google Scholar] [CrossRef]
- Kontokosta, C.E.; Hong, B.; Johnson, N.E.; Starobin, D. Using Machine Learning and Small Area Estimation to Predict Building-Level Municipal Solid Waste Generation in Cities. Comput. Environ. Urban Syst. 2018, 70, 151–162. [Google Scholar] [CrossRef]
- Qi, C.; Tang, X. Slope Stability Prediction Using Integrated Metaheuristic and Machine Learning Approaches: A Comparative Study. Comput. Ind. Eng. 2018, 118, 112–122. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Fernandez-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do We Need Hundreds of Classifiers to Solve Real World Classification Problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Morgan Kaufmann: Waltham, MA, USA, 2011. [Google Scholar]
- Wong, T.T. Performance Evaluation of Classification Algorithms by k-Fold and Leave-One-Out Cross Validation. Pattern Recognit. 2015, 48, 2839–2846. [Google Scholar] [CrossRef]
- Cha, G.W.; Moon, H.J.; Kim, Y.C.; Hong, W.H.; Jeon, G.Y.; Yoon, Y.R.; Hwang, C.; Hwang, J.H. Evaluating Recycling Potential of Demolition Waste Considering Building Structure Types: A Study in South Korea. J. Clean. Prod. 2020b, 256, 120385. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: New York, NY, USA, 2013; pp. 27–59. [Google Scholar]
- Nisbet, R.; Elder, J.; Miner, G. Handbook of Statistical Analysis and Data Mining Applications; Academic Press: Cambridge, MA, USA, 2009. [Google Scholar]
- RandomForestClassifier. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html (accessed on 15 May 2021).
- GradientBoostingClassifier. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html (accessed on 15 May 2021).
- Shao, Z.; Er, M.J. Efficient Leave-One-Out Cross-Validation-Based Regularized Extreme Learning Machine. Neurocomputing 2016, 194, 260–270. [Google Scholar] [CrossRef]
- Carter, D.S. Comparison of different shrinkage formulas in estimating the population multiple correlation coefficients. Educ. Psychol. Meas. 1979, 39, 261–266. [Google Scholar] [CrossRef]
- Fan, X. Statistical significance and effect size in education research: Two sides of a coin. J. Educ. Res. 2001, 94, 275–282. [Google Scholar] [CrossRef]
- Kannangara, M.; Dua, R.; Ahmadi, L.; Bensebaa, F. Modeling and Prediction of Regional Municipal Solid Waste Generation and Diversion in Canada Using Machine Learning Approaches. Waste Manag. 2018, 74, 3–15. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Structure Type | Number of Buildings | Total Floor Area (m2) |
|---|---|---|
| RC | 147 | 56,929 |
| Masonry | 352 | 33,291 |
| Wood | 285 | 22,750 |
| Total | 784 | 112,970 |
| Variables Type | Variables | Description | Unit or Scale of Variables |
|---|---|---|---|
| Independent variables | Region | Nominal variable; Areas where DW has occurred; Three region variables (Region A, B, C) | Region A is 1 Region B is 2 Region C is 3 |
| Building use | Nominal variable; Usage of building where DW has occurred; Three usage variables (residential-only, commercial and residential, commercial-only) | Residential-only is 1 Commercial and Residential is 2 Commercial-only is 3 | |
| Building structure | Nominal variable; Structure of building where DW has occurred; Three structure variables (reinforced concrete, masonry, wooden) | Reinforced concrete is 1 Masonry is 2 Wooden is 3 | |
| Wall material | Nominal variable; Main wall material of building where DW has occurred; Four wall material variables (reinforced concrete wall, brick wall, block wall, wall made of soil) | Reinforced concrete wall is 1 Brick wall is 2 Block wall is 3 Wall made of soil is 4 | |
| Roofing material | Nominal variable; Main roofing material of building where DW has occurred; Four roofing material variables (slab, slab and roofing tile, roof with asbestos, roofing tile) | Slab is 1 Slab and roofing tile is 2 Roof with asbestos is 3 Roofing tile is 4 | |
| Gross floor area (GFA) | Numeric variable | m2 | |
| Dependent variable | Waste generation | Numeric variable | kg/m2 |
| Algorithm | Parameter | Definition | Applied Value or Reference |
|---|---|---|---|
| RF | criterion | Quality measurement of a split | Mean squared error |
| n_estimators | The number of trees in the forest | 500 | |
| min_samples_split | The minimum number of samples required to split an internal node | 2 | |
| min_samples_leaf | The minimum number of samples required to be at a leaf node | 1 | |
| max_depth | The maximum depth of the tree | Maximum possible | |
| GBM | criterion | Quality measurement of a split | Mean squared error |
| n_estimators | The number of boosting stages | 500 | |
| min_samples_split | The minimum number of samples required to split an internal node | 2 | |
| loss | Least squares | Least squares | |
| learning rate | Amount of learning | 0.1 | |
| subsample | Rate of sampling data to control overfitting | 1.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cha, G.-W.; Moon, H.-J.; Kim, Y.-C. Comparison of Random Forest and Gradient Boosting Machine Models for Predicting Demolition Waste Based on Small Datasets and Categorical Variables. Int. J. Environ. Res. Public Health 2021, 18, 8530. https://doi.org/10.3390/ijerph18168530
Cha G-W, Moon H-J, Kim Y-C. Comparison of Random Forest and Gradient Boosting Machine Models for Predicting Demolition Waste Based on Small Datasets and Categorical Variables. International Journal of Environmental Research and Public Health. 2021; 18(16):8530. https://doi.org/10.3390/ijerph18168530
Chicago/Turabian StyleCha, Gi-Wook, Hyeun-Jun Moon, and Young-Chan Kim. 2021. "Comparison of Random Forest and Gradient Boosting Machine Models for Predicting Demolition Waste Based on Small Datasets and Categorical Variables" International Journal of Environmental Research and Public Health 18, no. 16: 8530. https://doi.org/10.3390/ijerph18168530