1. Introduction
Leveraging social influence is an increasingly common strategy to change population behavior or acceptance of public health policies and interventions. For example, an ongoing study—with a completed pilot—seeks to assess the feasibility of increasing pre-exposure prophylaxis (PrEP) interest for Black men who have sex with men (BMSM) through the use of a social network intervention: engaging and training network leaders to communicate the benefits of PrEP within their social networks [
1]. Since the intervention is inherently a social network intervention based on the premise that the network leaders will be more influential than other network members or
agents, an assessment of the intervention should incorporate both network structure and varying influence.
In order to analyze data from this study, we developed a novel genetic algorithm to fit DeGroot opinion diffusion models, incorporating the network structure and allowing for varying influence between agents in the network [
2]. Fitting this model makes possible both predicting future opinions and interpreting parameters that describe the opinion diffusion process, allowing us—for example—to identify particularly influential or stubborn agents. We previously demonstrated algorithm performance across a variety of network and dataset features; however, the performance was assessed under relatively ideal conditions, ignoring common issues present in this and other public health applications. Informed by known limitations of the dataset and those expected in similar research, we perform a simulation study to assess the performance of the algorithm in the presence of ordinal (rather than continuous) opinion measurements, network sampling (not observing the full network), and model misspecification, providing researchers necessary information about the performance of this method under the assumption violations expected for health behavior interventions.
Given the ubiquity of Likert or other ordinal scales in social and behavioral science research, we expect most studies using opinion data will use an ordinal scale as is done in the PrEP study [
3]. Since our selected model assumes opinions are continuous, we make the common assumption that ordinal data posses interval properties and convert them to a continuous
scale. This induces measurement error since the latent (continuous) opinions can only be measured as pre-defined values on the interval, determined by the number of items in the ordinal scale. Since both the objective function we optimize to fit a model and assessments of model fit incorporate the difference between modeled and observed opinions on the ordinal scale, the precision of the ordinal scale affects not only the quality of data provided to the algorithm but also the informativeness of each of these measures, making the use of ordinal data a concern for both model fitting and assessments of the usefulness of the model, in terms of parameter recovery, modeling observed opinions, and predicting future opinions.
The DeGroot model also assumes that the full network is sampled and the presence or absence of each possible link between agents is known. In practice, it is impractical to obtain the full social network due to agents declining to participate or failing to meet eligibility criteria and limitations of network sampling methods, such as the snowball sampling method used in the PrEP study where agents recruit other agents. While it may initially seem reasonable to determine the presence or absence of each possible link between sampled agents—particularly for the small networks for which this method was developed—by simply asking each agent if they know the others, our focus on public health applications introduces ethical concerns. When these networks are comprised of agents sharing stigmatized characteristics relating to sexuality, high-risk behaviors, or health status, identifying someone as a member of one of these networks is tantamount to revealing sexuality, high-risk behaviors, or health status. For these reasons, we expect missing agents and unknown links to be concerns for most applications of this method.
Finally, we consider the possibility that the opinion diffusion process does not follow the DeGroot model but bounded confidence and decay extensions to this model. Bounded confidence models are based on the premise that agents with substantially different opinions on a topic will either not discuss the topic or will be unable to influence each other if they do. This is of particular concern for the PrEP study since the network leader intervention is used to overcome disinformation and negative PrEP stereotypes within the social networks. Decay models allow for agents to be initially open to influence but become progressively more confident in their own opinions and less susceptible to influence over time. In the context of the PrEP study, this would allow for the intervention to initially be more effective, with the network leaders presenting new information using the techniques learned in training, but become less effective in the absence of any additional information after agents develop opinions based on the initial new information.
Since ordinal data and network sampling are concerns for the PrEP study and are expected for any other studies involving opinion diffusion on social networks, it is necessary to understand how the algorithm performs under these conditions. We also consider the possibility that the opinion diffusion process follows extensions of the simple DeGroot model for which the algorithm was developed: bounded confidence and decay. We detail these assumption violations along with the simulation study, the methodological development, and relevant details of the PrEP study in
Section 2. In
Section 3, we assess the ability of the algorithm to estimate parameters, model observed opinions, and predict future opinions. To provide concrete examples of the phenomena demonstrated in the simulation study, we revisit selected results from the PrEP study in
Section 4. Finally, to facilitate researchers using this method, we include recommendations for using model fit to assess performance and dealing with with ordinal data, network sampling, and alternate models in
Section 5.
4. Discussion
We revisit the results of the pilot PrEP study, placing them in the context of the simulation study. Only selected results are presented here, with full results available in Johnson et al. [
2]. Since these models are fit using only two time steps and use a fairly precise scale, the estimates presented here are less accurate and conclusions relating to the PrEP study should instead be drawn based on an analysis of the data from the full study, once available. We reassess these results to provide a concrete example of how this method can be used and demonstrate some of the phenomena seen in the simulation study. This section is intended to serve only as an example and not as a comprehensive analysis of the PrEP data
All results presented are from ten separate runs of the algorithm for each adjacency matrix, network, and measure combination. Though we strongly discourage the use of the build matrix based on the results of the simulation study, both the build and remove matrices are used here for comparison. We also note the two observations per agent, taken three months apart, are treated as time steps and , with time steps and missing, to allow for indirect influence, and that missing values on the observed time steps were imputed.
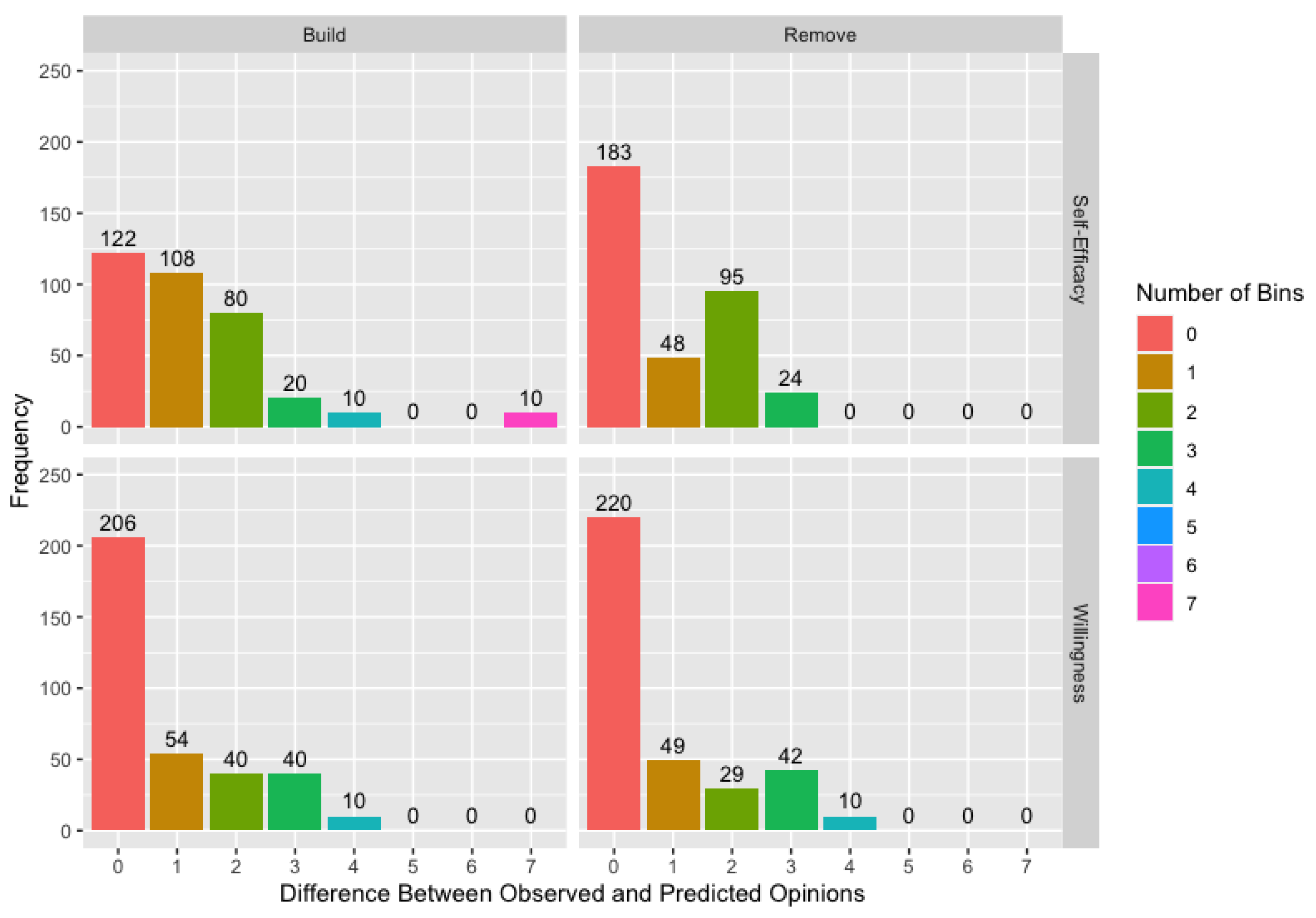
Figure 5 shows the deviation between observed and modeled opinions at follow-up across ten runs of the algorithm for willingness and self-efficacy using the
build and
remove matrices. While these deviations are measured in bins, note that self-efficacy uses a more precise 25-point composite scale while willingness uses a 13-point composite scale, so a bin covers a wider range of continuous opinions for willingness than for self-efficacy. Though we did find differences in performance across scales in the simulation study, these two measures differ in more than just the scales used, so we mention this only to highlight that a bin is not comparable between the two measures.
Figure 5 demonstrates the overall improvement in model fit for the
remove matrix compared to the
build matrix, but it also provides a specific example of why the
remove matrix results in better model fit. The ten modeled opinions for the self-efficacy
build matrix combination that are seven bins away from the observed opinions represent a single agent across the ten runs. We will refer to this agent as Ali and the other two agents involved in this example as Tom and Moe, with these names used for illustrative purposes only. Over the course of this study, Ali’s self-efficacy score increases, but his only connection in the
build matrix is to Tom, whose initial self-efficacy score is lower than Ali’s. Consequently, the
build matrix does not contain any connections that can explain the increase in Ali’s score, resulting in consistently poor estimates of Ali’s opinion at follow-up. When we use the
remove matrix, Ali has potential connection to a variety of other agents including Moe, whose initial self-efficacy score is higher than Ali’s. Since the connection to Moe, and potentially to other agents, can now be used to explain the change in Ali’s score, we are better able to model Ali’s change in score. This is not to say that Ali is necessarily connected to Moe in the true network as we discuss in the following example.
Table 2 and
Table 3 show the estimated weight matrices for network 5 with means across the ten runs using both the
build and
remove matrices for willingness and self-efficacy, respectively. We select this small network and exclude variability estimates for readability. Bold values in the
remove matrix are structural zeros in the
build matrix. Again, names are included purely for illustrative purposes. For these estimated weight matrices, we assess the relationships between Jay and Uba and Uba and Max, beginning with the estimated weight matrices for willingness. In the
build matrix, we assume Jay and Uba are not connected but allow for the possibility of a link in the
remove matrix. The average estimates of
in both directions of influence for the
remove matrix suggest the absence of a link between Jay and Uba or at least the lack of influence. This also explains the minimal change in estimates for Jay between the two matrices.
There are, however, substantial changes in the estimates for Uba between the two matrices. When not fixed at zero, Uba’s influence on Max is still estimated to be
, but Max’s influence on Uba is estimated as
. There are two potential explanations for these seemingly contradictory estimates. It is possible that, though Uba and Max are connected in the true network, the nature of their relationship or beliefs about PrEP means Uba is influenced by Max, while Max does not value Uba’s opinion. Another reasonable explanation is that Uba and Max are not connected, but Uba is, instead, influenced by an agent missing from the sampled network whose willingness score is similar to Max’s.
Table 3 suggests the latter explanation since neither Uba nor Max are influenced by the other for self-efficacy. This explanation shows how the
remove matrix can improve modeling and prediction by allowing agents to place weight on, if not the correct agent, an agent with roughly the correct score.
It also demonstrates the potential for the less intuitive effect of improving overall recovery when agents are missing from the sampled network. Assuming the true weight Uba places on Max is a structural zero, an estimated value of clearly contributes to incorrect recovery, but it also changes the other estimates in the row, hopefully bringing them closer to the true weight. If we assume Uba’s true self-weight is and that Uba is uninfluenced by Eli, as estimated in the remove matrix, recovery RMSE for Uba goes from for the build matrix to for the remove matrix, ignoring that the weight placed on Jay was not structurally zero. (The weights for Uba that we are presenting as the ground truth for this example (0.00, 0.00, 0.68, and 0.00) do not sum to one without the weight of 0.32 placed on a missing agent. This is consistent with how we calculate recovery RMSE with missing agents in the simulation study. If we instead acknowledge that the true weight placed on Jay is a structural zero that is correctly estimated, the calculation is . Since the purpose of the example is to show that placing non-zero weight on a link not present in the true network can improve overall recovery, the inclusion of a correctly estimated structural zero obscures this point.) While the above example relies on the unreasonable assumption that the estimated weights perfectly match the true weights other than weight placed on Max, the direct impact on recovery within Uba’s row is not the only way the estimate of 0.32 improves recovery. The incorrect weight of 0.32 also produces more accurate modeled opinions for Uba, potentially improving weight recovery for any agents influenced by Uba. This process can also continue: improving the modeled scores of agents influenced by Uba which, in turn, improve recovery for their contacts.
Finally, we present the results comparing leaders to non-leaders that are most appropriate given the recommendation to use the
remove matrix for parameter recovery.
Table 4 shows the average weight placed on leaders and non-leaders and the difference between the two (leader−non-leader) across networks for willingness and self-efficacy, excluding self-weights and agents not connected to a leader. The higher mean weight for each leader and non-leader comparison is noted in bold. For willingness, leaders are consistently more influential, with the exception of network 4. The trend for self-efficacy is the opposite: non-leaders being more influential than leaders, with network 4 again being an exception. It is worth noting that both the mean weights and differences are typically lower in absolute value for self-efficacy than for willingness.
Since the behavior of network 4 is inconsistent with other networks in terms of the effect of the leader training intervention for both willingness and self-efficacy, this network merits additional assessment.
Figure 6 shows the network representations of the
build and
remove adjacency matrices for network 4. Note that the
build matrix represents the network as sampled—the links known to exist based on the recruitment chain—and the
remove matrix represents the network provided to the algorithm. Again, names are only for narrative purposes. The agent in yellow is the seed, and the agent in green is the only agent in the network who attended leadership training. While other networks had agents other than the seed who attended training, network 4 is unique in having a seed who did not attend training. We include
Table 5 with the estimated weight matrices for willingness and self-efficacy using the
remove matrix for network 4 to support this example. Variability estimates are again excluded for readability.
The different behavior of network 4 suggests that a leader’s position in the network is important for a successful intervention; however, we must also consider the consequences for estimation of the only leader being recruited in the first wave of recruitment instead of as the seed. Specifically, the only leader in the network has unknown links and is directly linked to peripheral agents—those recruited in the second wave. These peripheral agents are expected to have links to the most missing agents: those who would theoretically have been recruited in a third wave. Since any weight placed on missing agents must be redistributed within the estimated weight matrix, an agent with links to more missing agents will have less accurate estimates for their row of the weight matrix. In this specific case, the only agent recruited in the second wave (Ray), places drastically differing estimated weights on the leader: 0.03 and 0.91 for willingness and self-efficacy, respectively. Given these extreme estimates, especially when the weight placed on others is typically lower for self-efficacy than for willingness, these estimates are likely being influenced by agents missing from the sampled network.
Regarding unknown links, the leader has potential links to both Cam and Obe, with the leader’s influence on Obe estimated to be 0.00 for both willingness and self-efficacy. Assuming these zeros indicate the absence of a link, these estimates, while correct, artificially decrease the average weight placed on the leader. Excluding zero or nearly zero estimated weights from the calculations in
Table 4 is a potential solution, but this artificially inflates influence in cases where zero or nearly zero estimates are indicative of a failure to influence instead of the absence of a link. If this approach is used, recall that both
and
will be zero in the absence of a link between agents
i and
j. Using the median instead of the mean for summary statistics on estimated weights also has the potential to minimize the effect of correctly estimated structural zeros without requiring a decision on whether estimates indicate the absence of a link or failure to influence. While we have shown the
remove matrix is the best solution to unknown links, this example highlights limitations when condensing estimates into summary statistics. We do not provide a specific recommendation but, instead, suggest assessing the options presented here with an awareness of the limitations and assumptions inherent in the approach selected.
5. Conclusions
We assessed the performance of the genetic algorithm for fitting DeGroot opinion diffusion models in terms of parameter recovery, modeling latent opinions, and predicting future opinions, considering known or expected problems of real-world datasets: ordinal data, network sampling, and alternate models. We also investigated whether the only performance metric available to the user, how well the model fits the data, is informative in terms of recovery, modeling and prediction. We highlight the results most relevant to researchers using this method when these assumption violations are known or expected.
Since even perfect fit is a poor indicator of parameter recovery, we recommend running the algorithm multiple times to identify a variety of solutions that produce perfect or very good fit. Note that averaging estimated weights across multiple runs will preserve the sum-to-one constraint. If multiple runs of the algorithm result in models with poor fit, the assumption violations are likely too extensive for use of this method. Good ordinal fit does suggest better modeling and prediction of latent opinions, particularly for more precise scales with more time steps. As with recovery, perfect fit should be viewed skeptically, especially with less precise scales and fewer time steps. This is especially true for prediction with only two time steps, regardless of the scale.
For alternate models, we considered bounded confidence models, where agents are not influenced by those with sufficiently differing opinions, and decay models, where agents become less open to the opinions of others over time. We found that even extreme values of the bounded confidence parameter are not concerning for recovery, modeling, or prediction. Decay models are also of little concern, especially when moderated by extreme bounded confidence parameters. We caution against the use of the model for opinion prediction when moderate to extreme decay is expected. Note that the potential for both bounded confidence or decay can be identified by looking at opinion data. Opinions that initially change quickly and become progressively more consistent suggest decay, and opinions that change minimally or not at all suggest bounded confidence. While little to no change could also be the result of a network comprised of very stubborn agents, this is not a particularly meaningful distinction as the algorithm handles data involving bounded confidence very well and the result is the same either way: agents place weight on only themselves or those with similar opinions.
A more precise ordinal scale—one with more points—generally improves recovery, modeling, and prediction with the exception of parameter recovery with only two time steps, where more precise scales result in slightly worse recovery. Consequently, we suggest prioritizing at least three observations per agent over a more precise scale when estimated parameters are of primary interest. When prediction is the primary goal, we recommend revisiting
Figure 1 and the related discussion since more time steps can improve prediction more than a precise scale. In all other cases, using more precise scales should be considered as an alternative to collecting more observations per agent to improve overall performance with minimal impact to cost or participation.
While network sampling results in both agents missing from the sampled network and unknown links between sampled agents, the
remove matrix—where links are included unless known not to exist—is a solution to both problems. We suggest using this matrix in most situations. It outperformed the
correct matrix—containing correct information about all links between sampled agents—not just for modeling and prediction, but also for parameter recovery. When producing summary measures for parameter estimates using the
remove matrix, we suggest revisiting the discussion relating to
Table 5. Given the lack of benefit and impracticality, we do not recommend attempting to determine all links between sampled agents. Since the
complete matrix—with links between all agents—had roughly equivalent performance to the
remove matrix in terms of recovery, modeling, and prediction, we advise its use only when missing agents are expected and all links between sampled agents are known, making the
correct matrix the only alternative. Finally, we strongly discourage the use of the
build matrix—including only links known to exist—in all cases as it has consistently poor performance.
Overall, this method can handle the assumption violations assessed. We encourage the use of more precise scales which reduce measurement error, making the observed opinions closer to the latent continuous opinions. The alternate models we considered are of little concern except for specific cases where prediction is of primary interest. Most importantly, the inability to collect data on a full network, including all links between agents, is not a barrier to the use of this method. Instead, the inclusion of links that may or may not exist in the true network typically improves performance. While our ongoing work will continue to improve usability of this method through simulation studies to establish default hyperparameter values and investigate variability estimates, this simulation study provides researchers with the information necessary to use the method under the assumption violations expected when modeling opinion diffusion on the social networks for health behavior interventions or similar applications.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}