
A Review on Human–AI Interaction in Machine Learning and Insights for Medical Applications




Abstract
:1. Introduction
1.1. Human-in-the-Loop Machine Learning: Definition and Terminology
1.2. The Difference between This Survey and Former Ones
1.3. Contributions of This Survey
2. Materials and Methods
Survey Methodology
3. Results
3.1. Why Should Humans Be in the Loop?
3.1.1. Tasks Are Too Complicated
3.1.2. ML Methods Are Not Transparent and Explicable
3.1.3. ML Results Are Not Satisfactory for Humans
3.2. Where Does Human–AI Interaction Occur in the ML Processes?
3.2.1. Human-in-the-Loop for Data Producing and Pre-Processing
Data Producing
- Providing data set samples
- Data labelling
Data Pre-Processing
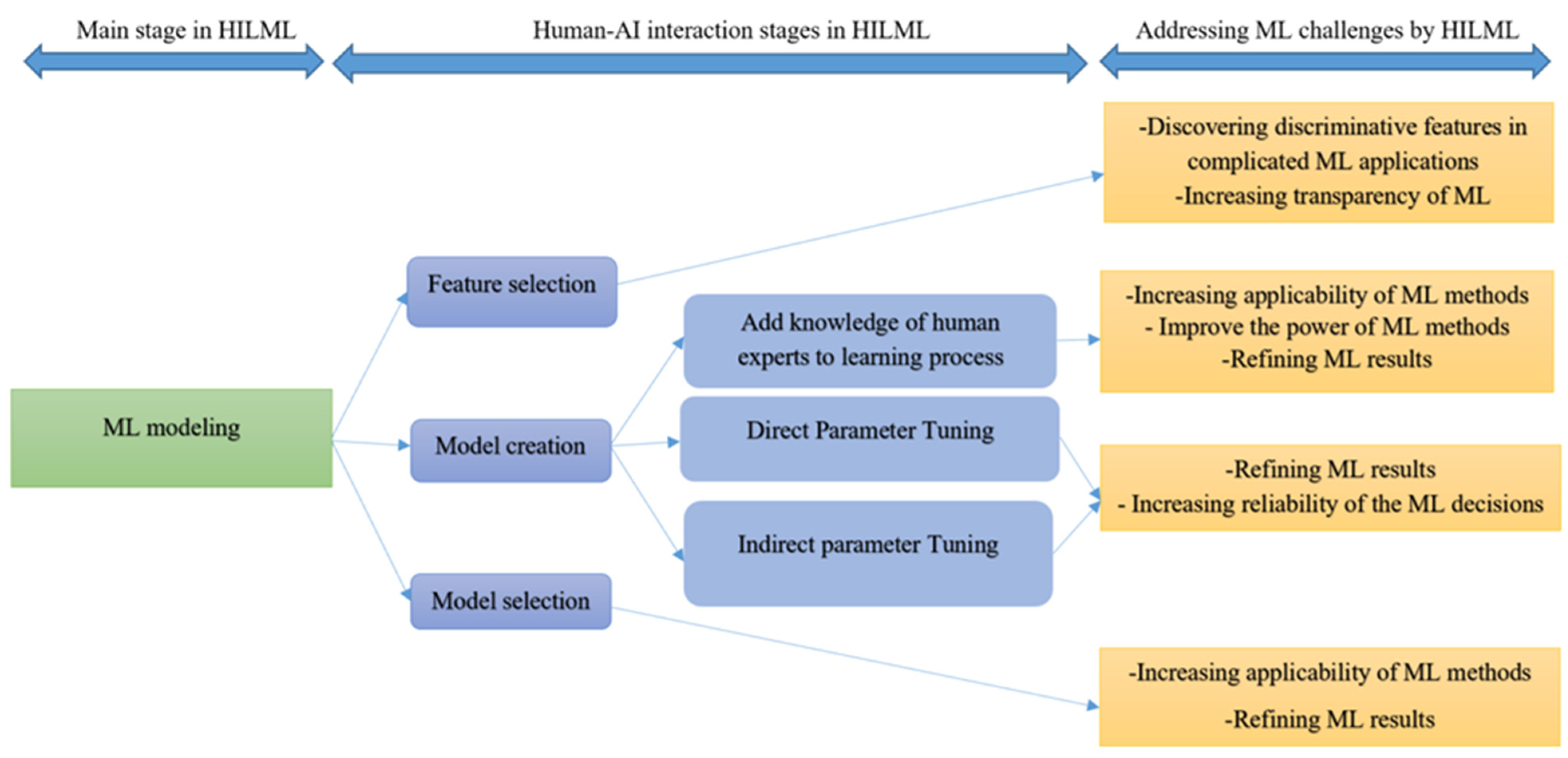
3.2.2. Human-in-the-Loop for ML Modelling
- Feature selection
- Model creation
- Model selection
3.2.3. Human-in-the-Loop for ML Evaluation and Refinement
Human-in-the-Loop for ML Evaluation
- Subjective measures for ML evaluation
- Objective measures for ML evaluation
Human-in-the-Loop for ML Refinement
- Human–AI interaction for ML refinement to get desired outputs
- Human–AI interaction for ML refinement at specific times
- Human–AI interaction for ML refinement once
3.3. Who Are the Humans in the Loop?
3.4. How Do Humans Interact with ML in HILML?
- Humans iteratively interact with ML methods
- Humans interact with ML methods at specific times
- Humans interact with ML methods once
3.5. Human-in-the-Loop in Medical ML Applications
3.5.1. HILML for Data Producing and Pre-Processing in Medical Applications
3.5.2. HILML for ML Modelling in Medical Applications
3.5.3. HILML for ML Evaluation and Refinement in Medical Applications
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Zerilli, J.; Knott, A.; Maclaurin, J.; Gavaghan, C. Algorithmic Decision-Making and the Control Problem. Minds Mach. 2019, 29, 555–578. [Google Scholar] [CrossRef] [Green Version]
- Lundberg, J.; Bang, M.; Johansson, J.; Cheaitou, A.; Josefsson, B.; Tahboub, Z. Human-in-the-loop AI: Requirements on future (unified) air traffic management systems. In Proceedings of the AIAA/IEEE Digital Avionics Systems Conference, San Diego, CA, USA, 8–12 September 2019; pp. 1–9. [Google Scholar]
- Nascimento, N.; Alencar, P.; Lucena, C.; Cowan, D. Toward Human-in-the-Loop Collaboration between Software Engineers and Machine Learning Algorithms. In Proceedings of the 2018 IEEE International Conference on Big Data, Seattle, WA, USA, 10–13 December 2018; pp. 3534–3540. [Google Scholar]
- Roccetti, M.; Delnevo, G.; Casini, L.; Salomoni, P. A Cautionary Tale for Machine Learning Design: Why we Still Need Human-Assisted Big Data Analysis. Mob. Netw. Appl. 2020, 25, 1075–1083. [Google Scholar] [CrossRef]
- Kläs, M.; Vollmer, A.M. Uncertainty in machine learning applications: A practice-driven classification of uncertainty. In Proceedings of the Computer Safety, Reliability and Security, Turku, Finland, 11–13 September 2019; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Weber, T.; Hußmann, H.; Han, Z.; Matthes, S.; Liu, Y. Draw with me: Human-in-the-loop for image restoration. In Proceedings of the 25th International Conference on Intelligent User Interfaces; Association for Computing Machinery: New York, NY, USA, 2020; pp. 243–253. [Google Scholar]
- Portelli, R.A. Don’t throw the baby out with the bathwater: Reappreciating the dynamic relationship between humans, machines and landscape images. Landsc. Ecol. 2020, 35, 815–822. [Google Scholar] [CrossRef]
- Yang, L.; Li, M.; Ren, J.; Zuo, C.; Ma, J.; Kong, W. A human-in-the-loop method for developing machine learning applications. In Proceedings of the 2019 6th International Conference on Systems and Informatics, ICSAI 2019, Shanghai, China, 2–4 November 2019; pp. 492–498. [Google Scholar]
- Dellermann, D.; Calma, A.; Lipusch, N.; Weber, T.; Weigel, S.; Ebel, P. The Future of Human–AI Collaboration: A Taxonomy of Design Knowledge for Hybrid Intelligence Systems. In Proceedings of the Hawaii International Conference on System Sciences (HICSS), Maui, HI, USA, 8–11 January 2019; 2019; pp. 1–10. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Bae, J.; Helldin, T.; Falkman, G.; Riveiro, M.; Nowaczyk, S.; Bouguelia, M.R. Interactive Clustering: A Comprehensive Review. ACM Comput. Surv. 2020, 53, 1–39. [Google Scholar] [CrossRef] [Green Version]
- Ware, M.; Frank, E.; Holmes, G.; Hall, M.; Witten, I.H. Interactive machine learning: Letting users build classifiers. Int. J. Hum. Comput. Stud. 2001, 55, 281–292. [Google Scholar] [CrossRef] [Green Version]
- Fails, J.A.; Olsen, D.R. Interactive machine learning. In Proceedings of the International Conference on Intelligent User Interfaces, Miami, FL, USA, 12–15 January 2003; Association for Computing Machinery (ACM): New York, NY, USA, 2003; pp. 39–45. [Google Scholar]
- Aodha, O.M.; Stathopoulos, V.; Brostow, G.J.; Terry, M.; Girolami, M.; Jones, K.E. Putting the Scientist in the Loop-Accelerating Scientific Progress with Interactive Machine Learning. In Proceedings of the International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 9–17. [Google Scholar]
- Dudley, J.J.; Kristensson, P.O. A review of user interface design for interactive machine learning. ACM Trans. Interact. Intell. Syst. 2018, 8. [Google Scholar] [CrossRef] [Green Version]
- Amershi, S.; Cakmak, M.; Knox, W.B.; Kulesza, T. Power to the people: The role of humans in interactive machine learning. AI Mag. 2014, 35, 105–120. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Wang, Y.; Lv, Q. Crowd-Assisted Machine Learning: Current Issues and Future Directions. Computer (Long. Beach. Calif). 2019, 52, 46–53. [Google Scholar] [CrossRef]
- Girardi, D.; Kueng, J.; Holzinger, A. A domain-expert centered process model for knowledge discovery in medical research: Putting the expert-in-the-loop. In Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2015; Volume 9250, pp. 389–398. [Google Scholar]
- Holzinger, A. Interactive machine learning for health informatics: When do we need the human-in-the-loop? Brain Inform. 2016, 3, 119–131. [Google Scholar] [CrossRef] [Green Version]
- Kunneman, F.; Lambooij, M.; Wong, A.; Bosch, A.; Van Den Mollema, L. Monitoring stance towards vaccination in twitter messages. BMC Med. Inform. Decis. Mak. 2020, 20, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cadavid, U.J.P.; Lamouri, S.; Grabot, B.; Pellerin, R.; Fortin, A. Machine learning applied in production planning and control: A state-of-the-art in the era of industry 4.0. J. Intell. Manuf. 2020, 31, 1531–1558. [Google Scholar] [CrossRef]
- Liu, A.; Guerra, S.; Fung, I.; Matute, G.; Kamar, E.; Lasecki, W. Towards Hybrid Human–AI Workflows for Unknown Unknown Detection. In Proceedings of the Web Conference 2020, New York, NY, USA, 20–24 April 2020; pp. 2432–2442. [Google Scholar]
- Sakata, Y.; Baba, Y.; Kashima, H. Crownn: Human-in-the-loop Network with Crowd-generated Inputs. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019; pp. 7555–7559. [Google Scholar]
- Bahrami, M.; Chen, W.P. WATAPI: Composing Web API Specification from API Documentations through an Intelligent and Interactive Annotation Tool. In Proceedings of the 2019 IEEE International Conference on Big Data, Los Angeles, CA, USA, 9–12 December 2019; pp. 4573–4578. [Google Scholar]
- Feder, A.; Vainstein, D.; Rosenfeld, R.; Hartman, T.; Hassidim, A.; Matias, Y. Active deep learning to detect demographic traits in free-form clinical notes. J. Biomed. Inform. 2020, 107, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Wen, X.; Niu, Y.; Wang, C.; Wu, L.; Zhu, Y.; Yin, D. Human-in-the-loop Multi-task Tracking Improved by Interactive Learning. In Proceedings of the 2018 Chinese Automation Congress, Xi’an, China, 30 November–2 December 2019; pp. 2289–2294. [Google Scholar]
- Stroganov, O.V.; Novikov, F.N.; Medvedev, M.G.; Dmitrienko, A.O.; Gerasimov, I.; Svitanko, I.V.; Chilov, G.G. The role of human in the loop: Lessons from D3R challenge 4. J. Comput. Aided. Mol. Des. 2020, 34, 121–130. [Google Scholar] [CrossRef]
- Yang, Y.; Kandogan, E.; Li, Y.; Sen, P.; Lasecki, W.S. A Study on Interaction in Human-in-the-Loop Machine Learning for Text Analytics. In Proceedings of the 2019 Joint ACM IUI Workshops, Los Angeles, CA, USA, 20 March 2019; pp. 1–7. [Google Scholar]
- Drobnič, F.; Kos, A.; Pustišek, M. On the Interpretability of Machine Learning Models and Experimental Feature Selection in Case of Multicollinear Data. Electronics 2020, 9, 761. [Google Scholar] [CrossRef]
- Calderon, N.A.; Fisher, B.; Hemsley, J.; Ceskavich, B.; Jansen, G.; Marciano, R.; Lemieux, V.L. Mixed-initiative social media analytics at the World Bank: Observations of citizen sentiment in Twitter data to explore «trust» of political actors and state institutions and its relationship to social protest. In Proceedings of the 2015 IEEE International Conference on Big Data, IEEE Big Data 2015, Santa Clara, CA, USA, 29 October–1 November 2015; pp. 1678–1687. [Google Scholar]
- Cheng, J.; Bernstein, M.S. Flock: Hybrid crowd-machine learning classifiers. In Proceedings of the CSCW 2015 ACM International Conference on Computer-Supported Cooperative Work and Social Computing, New York, NY, USA, 14–18 February 2015; pp. 600–611. [Google Scholar]
- Correia, A.H.C.; Lecue, F. Human-in-the-Loop Feature Selection. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 2438–2445. [Google Scholar]
- Kulesza, T.; Stumpf, S.; Wong, W.K.; Burnett, M.M.; Perona, S.; Ko, A.; Oberst, I. Why-oriented end-user debugging of naive Bayes text classification. ACM Trans. Interact. Intell. Syst. 2011, 1, 1–31. [Google Scholar] [CrossRef] [Green Version]
- Yuksel, B.F.; Kim, S.J.; Jin, S.J.; Lee, J.J.; Fazli, P.; Mathur, U.; Bisht, V.; Yoon, I.; Siu, Y.T.; Miele, J.A. Increasing video accessibility for visually impaired users with human-in-the-loop machine learning. In Proceedings of the Conference on Human Factors in Computing Systems, New York, NY, USA, 8–13 April 2020; pp. 1–9. [Google Scholar]
- Boddy, A.; Hurst, W.; Mackay, M.; El Rhalibi, A. A Hybrid Density-Based Outlier Detection Model for Privacy in Electronic Patient Record system. In Proceedings of the 5th International Conference on Information Management, ICIM 2019, Cambridge, UK, 24–27 March 2019; pp. 92–96. [Google Scholar]
- Zhang, T.; Moody, M.; Nelon, J.P.; Boyer, D.M.; Smith, D.H.; Visser, R.D. Using Natural Language Processing to Accelerate Deep Analysis of Open-Ended Survey Data. In Proceedings of the Conference IEEE SOUTHEASTCON, Huntsville, AL, USA, 11–14 April 2019; pp. 1–3. [Google Scholar]
- Abhigna, B.S.; Soni, N.; Dixit, S. Crowdsourcing-A Step Towards Advanced Machine Learning. In Procedia Computer Science; Elsevier: Amsterdam, The Netherlands, 2018; Volume 132, pp. 632–642. [Google Scholar]
- Ho, C.J.; Slivkins, A.; Vaughan, J.W. Adaptive contract design for crowdsourcing markets: Bandit algorithms for repeated principal-agent problems. J. Artif. Intell. Res. 2016, 55, 317–359. [Google Scholar] [CrossRef] [Green Version]
- Abraham, I.; Alonso, O.; Kandylas, V.; Patel, R.; Shelford, S.; Slivkins, A. How many workers to ask? Adaptive exploration for collecting high quality labels. In Proceedings of the SIGIR 2016 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 17–21 July 2016; pp. 473–482. [Google Scholar]
- Fan, J.; Li, G.; Ooi, B.C.; Tan, K.L.; Feng, J. ICrowd: An adaptive crowdsourcing framework. In Proceedings of the ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 4–6 May 2015; pp. 1015–1030. [Google Scholar]
- Huang, Q.; Chen, Y.; Liu, L.; Tao, D.; Li, X. On Combining Biclustering Mining and AdaBoost for Breast Tumor Classification. IEEE Trans. Knowl. Data Eng. 2020, 32, 728–738. [Google Scholar] [CrossRef]
- Michalopoulos, D.P.; Jacob, J.; Coviello, A. Ai-enabled litigation evaluation: Data-driven empowerment for legal decision makers. In Proceedings of the 17th International Conference on Artificial Intelligence and Law, ICAIL 2019, New York, NY, USA, 17–21 June 2019; pp. 264–265. [Google Scholar]
- Kulesza, T.; Amershi, S.; Caruana, R.; Fisher, D.; Charles, D. Structured labeling to facilitate concept evolution in machine learning. In Proceedings of the Conference on Human Factors in Computing Systems, New York, NY, USA, 26 April 2014; pp. 3075–3084. [Google Scholar]
- Chang, J.C.; Amershi, S.; Kamar, E. Revolt: Collaborative crowdsourcing for labeling machine learning datasets. In Proceedings of the Conference on Human Factors in Computing Systems, New York, NY, USA, 8–13 May 2017; pp. 2334–2346. [Google Scholar]
- Zhou, N.; Siegel, Z.D.; Zarecor, S.; Lee, N.; Campbell, D.A.; Andorf, C.M.; Nettleton, D.; Lawrence-Dill, C.J.; Ganapathysubramanian, B.; Kelly, J.W.; et al. Crowdsourcing image analysis for plant phenomics to generate ground truth data for machine learning. PLoS Comput. Biol. 2018, 14, 6337. [Google Scholar] [CrossRef] [Green Version]
- Snow, R.; O’connor, B.; Jurafsky, D.; Ng, A.Y. Cheap and Fast-But is it Good? Evaluating Non-Expert Annotations for Natural Language Tasks. In Proceedings of the EMNLP ’08 Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, USA, 10 October 2008; pp. 254–263. [Google Scholar]
- Netzer, E.; Geva, A.B. Human-in-the-loop active learning via brain computer interface. Ann. Math. Artif. Intell. 2020, 1–15. [Google Scholar] [CrossRef]
- Wrede, F.; Hellander, A.; Wren, J. Smart computational exploration of stochastic gene regulatory network models using human-in-the-loop semi-supervised learning. Bioinformatics 2019, 35, 5199–5206. [Google Scholar] [CrossRef]
- Yang, K.; Ren, J.; Zhu, Y.; Zhang, W. Active Learning for Wireless IoT Intrusion Detection. IEEE Wirel. Commun. 2018, 25, 19–25. [Google Scholar] [CrossRef] [Green Version]
- Laroze, M.; Dambreville, R.; Friguet, C.; Kijak, E.; Lefevre, S. Active learning to assist annotation of aerial images in environmental surveys. In Proceedings of the International Workshop on Content-Based Multimedia Indexing, La Rochelle, France, 4–6 September 2018. [Google Scholar]
- Krishnan, S.; Haas, D.; Franklin, M.J.; Wu, E. Towards reliable interactive data cleaning: A user survey and recommendations. In Proceedings of the HILDA 2016 Workshop on Human-In-the-Loop Data Analytics, New York, NY, USA, 10 June 2016; pp. 1–5. [Google Scholar]
- Rezig, E.K.; Ouzzani, M.; Elmagarmid, A.K.; Aref, W.G.; Stonebraker, M. Towards an end-to-end human-centric data cleaning framework. In Proceedings of the ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 6 July 2019; pp. 1–7. [Google Scholar]
- Equille, B.L. Reinforcement Learning for Data Preparation with Active Reward Learning. In Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Perpignan, France, 25 November 2019; Volume 11938 LNCS, pp. 121–132. [Google Scholar]
- Ye, C.; Wang, H.; Lu, W.; Li, J. Effective Bayesian-network-based missing value imputation enhanced by crowdsourcing. Knowl. Based Syst. 2020, 190, 105–199. [Google Scholar] [CrossRef]
- Doan, A.H.; Ardalan, A.; Ballard, J.; Das, S.; Govind, Y.; Konda, P.; Li, H.; Mudgal, S.; Paulson, E.; Paul Suganthan, G.C.; et al. Human-in-the-loop challenges for entity matching: A midterm report. In Proceedings of the 2nd Workshop on Human-In-the-Loop Data Analytics, HILDA 2017, New York, NY, USA, 14 May 2017; pp. 1–6. [Google Scholar]
- Siddiqui, M.A.; Wright, R.; Fern, A.; Theriault, A.; Dietterich, T.G.; Archer, D.W. Feedback-guided anomaly discovery via online optimization. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24 July 2018; Volume 18, pp. 2200–2209. [Google Scholar]
- Chu, X.; Morcos, J.; Ilyas, I.F.; Ouzzani, M.; Papotti, P.; Tang, N.; Ye, Y. KATARA: A Data Cleaning System Powered by Knowledge Bases and Crowdsourcing. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, Australia, 31 May 2015; pp. 1247–1261. [Google Scholar]
- Assadi, A.; Milo, T.; Novgorodov, S. DANCE: Data cleaning with constraints and experts. In Proceedings of the International Conference on Data Engineering, San Diego, CA, USA, 19–22 April 2017; pp. 1409–1410. [Google Scholar]
- Brooks, M.; Amershi, S.; Lee, B.; Drucker, S.M.; Kapoor, A.; Simard, P. FeatureInsight: Visual support for error-driven feature ideation in text classification. In Proceedings of the 2015 IEEE Conference on Visual Analytics Science and Technology, VAST 2015, Chicago, IL, USA, 25–30 October 2015; pp. 105–112. [Google Scholar]
- Deng, J.; Krause, J.; Stark, M.; Fei, F.L. Leveraging the wisdom of the crowd for fine-grained recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 666–676. [Google Scholar] [CrossRef]
- Takahama, R.; Baba, Y.; Shimizu, N.; Fujita, S.; Kashima, H. AdaFlock: Adaptive Feature Discovery for Human-in-the-Loop Predictive Modeling. In Proceedings of the the 32nd AAAI Conference on Artificial Intelligence (AAAI-18), Kyoto, Japan, 2 February 2018; pp. 1619–1626. [Google Scholar]
- Kim, B.; Glassman, E.; Johnson, B.; Shah, J. iBCM: Interactive Bayesian Case Model Empowering Humans via Intuitive Interaction iBCM: Interactive Bayesian Case Model Empowering Humans via Intuitive Interaction; MIT Libraries: Cambridge, MA, USA, 2015. [Google Scholar]
- Corrêa, G.N.; Marcacini, R.M.; Hruschka, E.R.; Rezende, S.O. Interactive textual feature selection for consensus clustering. Pattern Recognit. Lett. 2015, 52, 25–31. [Google Scholar] [CrossRef]
- Wang, P.; Peng, D.; Li, L.; Chen, L.; Wu, C.; Wang, X.; Childs, P.; Guo, Y. Human-in-the-loop design with machine learning. In Proceedings of the International Conference on Engineering Design, Amsterdam, The Netherlands, 5–8 August 2019; Volume 1, pp. 2577–2586. [Google Scholar]
- Zou, J.Y.; Chaudhuri, K.; Kalai, A.T. Crowdsourcing Feature Discovery via Adaptively Chosen Comparisons. In Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, San Diego, CA, USA, 23 September 2015; Volume 3. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Elsevier: Amsterdam, The Netherlands, 2016; ISBN 9780128042915. [Google Scholar]
- Hu, Y.; Milios, E.E.; Blustein, J. Interactive feature selection for document clustering. In Proceedings of the ACM Symposium on Applied Computing, New York, NY, USA, 20 March 2011; pp. 1143–1150. [Google Scholar]
- Constantinou, A.C.; Fenton, N.; Neil, M. Integrating expert knowledge with data in Bayesian networks: Preserving data-driven expectations when the expert variables remain unobserved. Expert Syst. Appl. 2016, 56, 197–208. [Google Scholar] [CrossRef]
- Fogarty, J.; Tan, D.; Kapoor, A.; Winder, S. CueFlik: Interactive concept learning in image search. In Proceedings of the Conference on Human Factors in Computing Systems, New York, NY, USA, 13 April 2008; pp. 29–38. [Google Scholar]
- Cruz, C.A.; Igarashi, T. A Survey on Interactive Reinforcement Learning: Design Principles and Open Challenges. In Proceedings of the 2020 ACM Designing Interactive Systems Conference, Eindhoven, The Netherlands, 6 July 2020; pp. 1195–1209. [Google Scholar]
- Warnell, G.; Waytowich, N.; Lawhern, V.; Stone, P. Deep TAMER: Interactive Agent Shaping in High-Dimensional State Spaces. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Griffith, S.; Subramanian, K.; Scholz, J.; Isbell, C.L.; Thomaz, A. Policy Shaping: Integrating Human Feedback with Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems, Atlanta, GA, USA, 5–8 December 2013; Volume 26, pp. 2625–2633. [Google Scholar]
- Fachantidis, A.; Taylor, M.; Vlahavas, I. Learning to Teach Reinforcement Learning Agents. Mach. Learn. Knowl. Extr. 2017, 1, 2. [Google Scholar] [CrossRef] [Green Version]
- Brys, T.; Harutyunyan, A.; Suay, H.B.; Chernova, S.; Taylor, M.E.; Nowé, A. Reinforcement Learning from Demonstration through Shaping. In Proceedings of the 24th International Conference on Artificial Intelligence (IJCAI’15), San Diego, CA, USA, 8 July 2015; pp. 3352–3358. [Google Scholar]
- Lee Isbell, C.; Shelton, C.J.R.; Stone, K.S.S.P.M. Cobot: A Social Reinforcement Learning Agent. In Proceedings of the Advances in Neural Information Processing Systems, London, UK, 4 May 2002; pp. 1393–1400. [Google Scholar]
- Knox, W.B.; Stone, P. Framing reinforcement learning from human reward: Reward positivity, temporal discounting, episodicity and performance. Artif. Intell. 2015, 225, 24–50. [Google Scholar] [CrossRef]
- Thomaz, A.L.; Breazeal, C. Reinforcement Learning with Human Teachers: Evidence of Feedback and Guidance with Implications for Learning Performance. In Proceedings of the AAAI, Cambridge, MA, USA, 16–20 July 2006; pp. 1000–1005. [Google Scholar]
- Shah, P.; Tur, H.D.; Heck, L. Interactive reinforcement learning for task-oriented dialogue management. In Proceedings of the Workshop on Deep Learning for Action and Interaction, NIPS 2016, Barcelona, Spain, 10 December 2016; pp. 1–11. [Google Scholar]
- De Winter, J.; De Beir, A.; El Makrini, I.; Van de Perre, G.; Nowé, A.; Vanderborght, B. Accelerating interactive reinforcement learning by human advice for an assembly task by a cobot. Robotics 2019, 8, 104. [Google Scholar] [CrossRef] [Green Version]
- Self, J.Z.; Dowling, M.; Wenskovitch, J.; Crandell, I.; Wang, M.; House, L.; Leman, S.; North, C. Observation-level and parametric interaction for high-dimensional data analysis. ACM Trans. Interact. Intell. Syst. 2018, 8, 1–36. [Google Scholar] [CrossRef]
- Kapoor, A.; Lee, B.; Tan, D.; Horvitz, E. Interactive optimization for steering machine classification. In Proceedings of the Conference on Human Factors in Computing Systems, New York, NY, USA, 27 April 2010; Volume 2, pp. 1343–1352. [Google Scholar]
- Hu, Y.; Milios, E.E.; Blustein, J. Interactive document clustering with feature supervision through reweighting. Intell. Data Anal. 2014, 18, 561–581. [Google Scholar] [CrossRef]
- Arın, İ.; Erpam, M.K.; Saygın, Y. I-TWEC: Interactive clustering tool for Twitter. Expert Syst. Appl. 2018, 96, 1–13. [Google Scholar] [CrossRef]
- Schneider, B.; Jackle, D.; Stoffel, F.; Diehl, A.; Fuchs, J.; Keim, D. Integrating Data and Model Space in Ensemble Learning by Visual Analytics. IEEE Trans. Big Data 2018, 15. [Google Scholar] [CrossRef]
- Perry, B.J.; Guo, Y.; Atadero, R.; van de Lindt, J.W. Streamlined bridge inspection system utilizing unmanned aerial vehicles (UAVs) and machine learning. Meas. J. Int. Meas. Confed. 2020, 164, 1–14. [Google Scholar] [CrossRef]
- Fiebrink, R.; Cook, P.R.; Trueman, D. Human model evaluation in interactive supervised learning. In Proceedings of the Conference on Human Factors in Computing Systems, New York, NY, USA, 8–13 May 2011; pp. 147–156. [Google Scholar]
- Talbot, J.; Lee, B.; Kapoor, A.; Tan, D.S. EnsembleMatrix: Interactive visualization to support machine learning with multiple classifiers. In Proceedings of the Conference on Human Factors in Computing Systems, New York, NY, USA, 2–4 April 2009; pp. 1283–1292. [Google Scholar]
- Liang, J.; Aronson, J.D.; Hauptmann, A. Shooter localization using social media videos. In Proceedings of the MM 2019 27th ACM International Conference on Multimedia; Association for Computing Machinery, Inc.: New York, NY, USA, 2019; pp. 2280–2283. [Google Scholar]
- Alahmari, S.; Goldgof, D.; Hall, L.; Dave, P.; Phoulady, A.H.; Mouton, P. Iterative Deep Learning Based Unbiased Stereology with Human-in-the-Loop. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications, ICMLA 2018, Orlando, FL, USA, 17–20 December 2019; pp. 665–670. [Google Scholar]
- Kwon, D.; Kim, S.; Wei, C.H.; Leaman, R.; Lu, Z. EzTag: Tagging biomedical concepts via interactive learning. Nucleic Acids Res. 2018, 46, W523–W529. [Google Scholar] [CrossRef]
- Kulesza, T.; Burnett, M.; Wong, W.K.; Stumpf, S. Principles of Explanatory Debugging to personalize interactive machine learning. In Proceedings of the International Conference on Intelligent User Interfaces, New York, NY, USA, 13 May 2015; pp. 126–137. [Google Scholar]
- Groce, A.; Kulesza, T.; Zhang, C.; Shamasunder, S.; Burnett, M.; Wong, W.K.; Stumpf, S.; Das, S.; Shinsel, A.; Bice, F.; et al. You are the only possible oracle: Effective test selection for end users of interactive machine learning systems. IEEE Trans. Softw. Eng. 2014, 40, 307–323. [Google Scholar] [CrossRef]
- Bellazzi, R.; Ferrazzi, F.; Sacchi, L. Predictive data mining in clinical medicine: A focus on selected methods and applications. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 416–430. [Google Scholar] [CrossRef]
- Itani, S.; Lecron, F.; Fortemps, P. Specifics of medical data mining for diagnosis aid: A survey. Expert Syst. Appl. 2019, 118, 300–314. [Google Scholar] [CrossRef]
- Caruana, R.; Lou, Y.; Gehrke, J.; Koch, P.; Sturm, M.; Elhadad, N. Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 31 August 2015; pp. 1721–1730. [Google Scholar]
- Yimam, S.M.; Biemann, C.; Majnaric, L.; Šabanović, Š.; Holzinger, A. Interactive and iterative annotation for biomedical entity recognition. In Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), London, UK, 30 August–2 September 2015; Volume 9250, pp. 347–357. [Google Scholar]
- Liu, J.; Cao, L.; Tian, Y. Deep Active Learning for Effective Pulmonary Nodule Detection. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention-MICCAI 2020, Lima, Peru, 4–8 October 2020; Volume 12266 LNCS, pp. 609–618. [Google Scholar]
- Sheng, M.; Dong, J.; Zhang, Y.; Bu, Y.; Li, A.; Lin, W.; Li, X.; Xing, C. AHIAP: An Agile Medical Named Entity Recognition and Relation Extraction Framework Based on Active Learning. In Proceedings of the International Conference on Health Information Science—HIS 2020, Amsterdam, The Netherlands, 20–23 October 2020; Volume 12435 LNCS, pp. 68–75. [Google Scholar]
- Cai, C.J.; Reif, E.; Hegde, N.; Hipp, J.; Kim, B.; Smilkov, D.; Wattenberg, M.; Viegas, F.; Corrado, G.S.; Stumpe, M.C.; et al. Human-centered tools for coping with imperfect algorithms during medical decision-making. Conf. Hum. Factors Comput. Syst. Proc. 2019, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Remeseiro, B.; Canedo, B.V. A review of feature selection methods in medical applications. Comput. Biol. Med. 2019, 112, 1–9. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Type of Interaction in HILML | Main Stopping Conditions | Samples of Studies |
|---|---|---|
| Human iteratively interacts with ML | The satisfaction of the user, no improvement in the ML results, the achievement of a determined objective measure | Alahmari et al. [89], Yang et al. [28] |
| Human interacts with ML at specific times | limited number of interactions is usually determined by humans as the users of the case study | Perry et al. [85], Feder et al. [25], Wen et al. [26] |
| Human interacts with ML once | Interaction happens once in data producing and pre-processing, ML modelling and ML refinement | Roccetti et al. [4], Netzer and Geva [47], Yuksel et al. [34] |
| HILML Stage | Human Expert’ Task According to the Literature | Sample of Papers | Suggestions for Future Research |
|---|---|---|---|
| Data producing and pre-processing | Generating the whole data set | Huang et al. [41] | Active learning (Liu et al. [97], Sheng et al. [98] Human–AI interaction for data pre-processing |
| Data labelling | Yimam et al. [96], Wrede et al. [48] | ||
| Selecting samples | Alahmari et al. [89] | ||
| ML modelling | Feature selection | J. Cai et al. [99] | Indirect parameter tuning Developing rule-based ML approaches Human-in-the-loop reinforcement learning |
| Direct Parameter tuning | J. Cai et al. [99] | ||
| ML evaluation and refinement | Evaluation of the ML outputs | J. Cai et al. [99] | Using human experts’ criteria to evaluate and refine HILML outputs to increase the explicability of ML methods |
| ML outputs refinement | Alahmari et al. [89] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maadi, M.; Akbarzadeh Khorshidi, H.; Aickelin, U. A Review on Human–AI Interaction in Machine Learning and Insights for Medical Applications. Int. J. Environ. Res. Public Health 2021, 18, 2121. https://doi.org/10.3390/ijerph18042121
Maadi M, Akbarzadeh Khorshidi H, Aickelin U. A Review on Human–AI Interaction in Machine Learning and Insights for Medical Applications. International Journal of Environmental Research and Public Health. 2021; 18(4):2121. https://doi.org/10.3390/ijerph18042121
Chicago/Turabian StyleMaadi, Mansoureh, Hadi Akbarzadeh Khorshidi, and Uwe Aickelin. 2021. "A Review on Human–AI Interaction in Machine Learning and Insights for Medical Applications" International Journal of Environmental Research and Public Health 18, no. 4: 2121. https://doi.org/10.3390/ijerph18042121
APA StyleMaadi, M., Akbarzadeh Khorshidi, H., & Aickelin, U. (2021). A Review on Human–AI Interaction in Machine Learning and Insights for Medical Applications. International Journal of Environmental Research and Public Health, 18(4), 2121. https://doi.org/10.3390/ijerph18042121