
Development and Validation of a New Measure of Work Annoyance Using a Psychometric Network Approach



Abstract
:1. Introduction
1.1. The Substantive Issue: The Need for a Measure of Work Annoyance
1.2. The Methodological Issue: The Usefulness of Psychometric Network Approach
1.2.1. The Latent Variable Approach
1.2.2. The Network Approach
Redundancy
Dimensionality
Internal Structure
External Validity
1.3. The Present Study
2. Materials and Methods
2.1. Samples and Procedure
2.2. Materials
2.2.1. Cohort 1
2.2.2. Cohort 2
2.3. Data Analysis
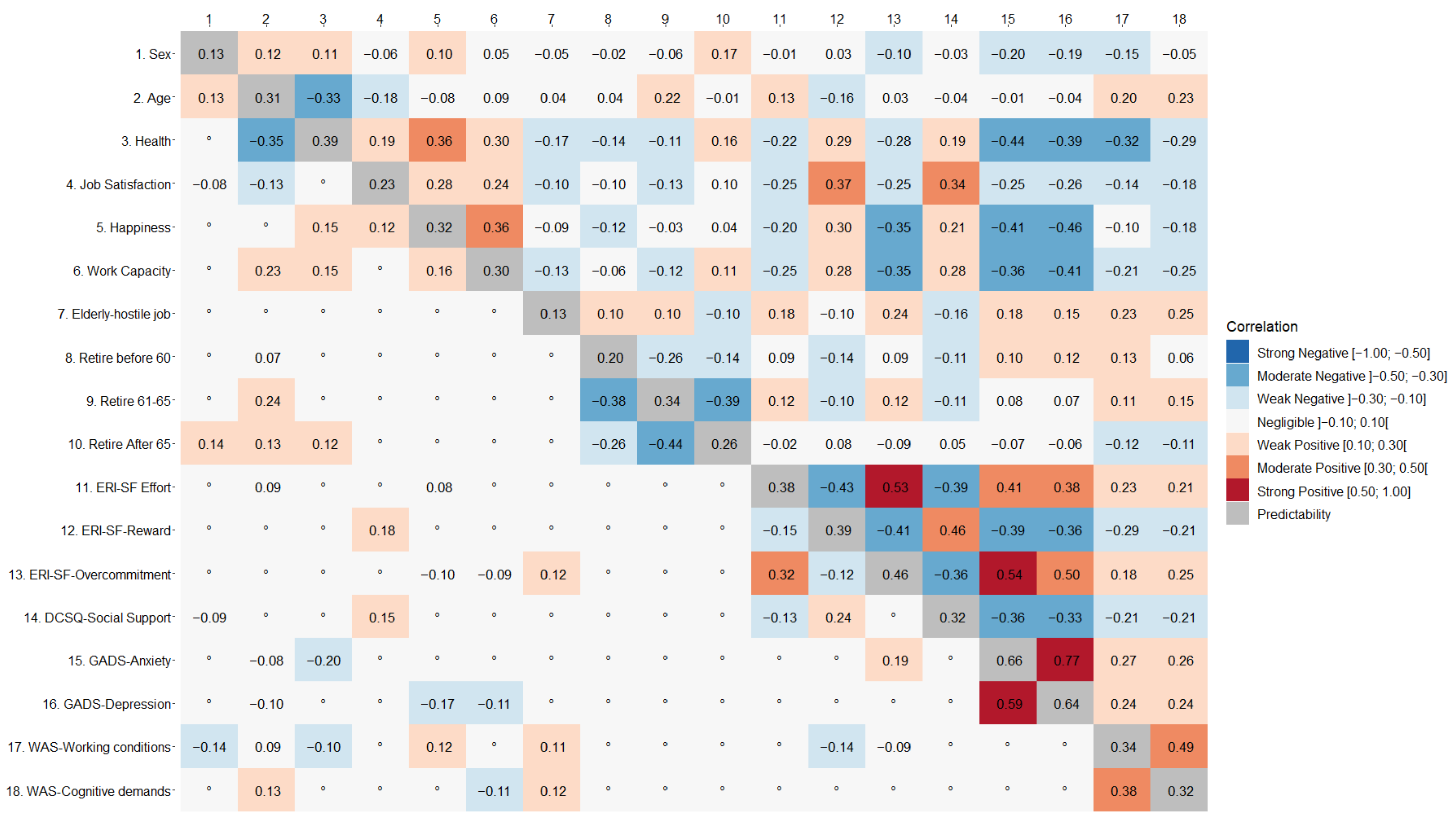
3. Results
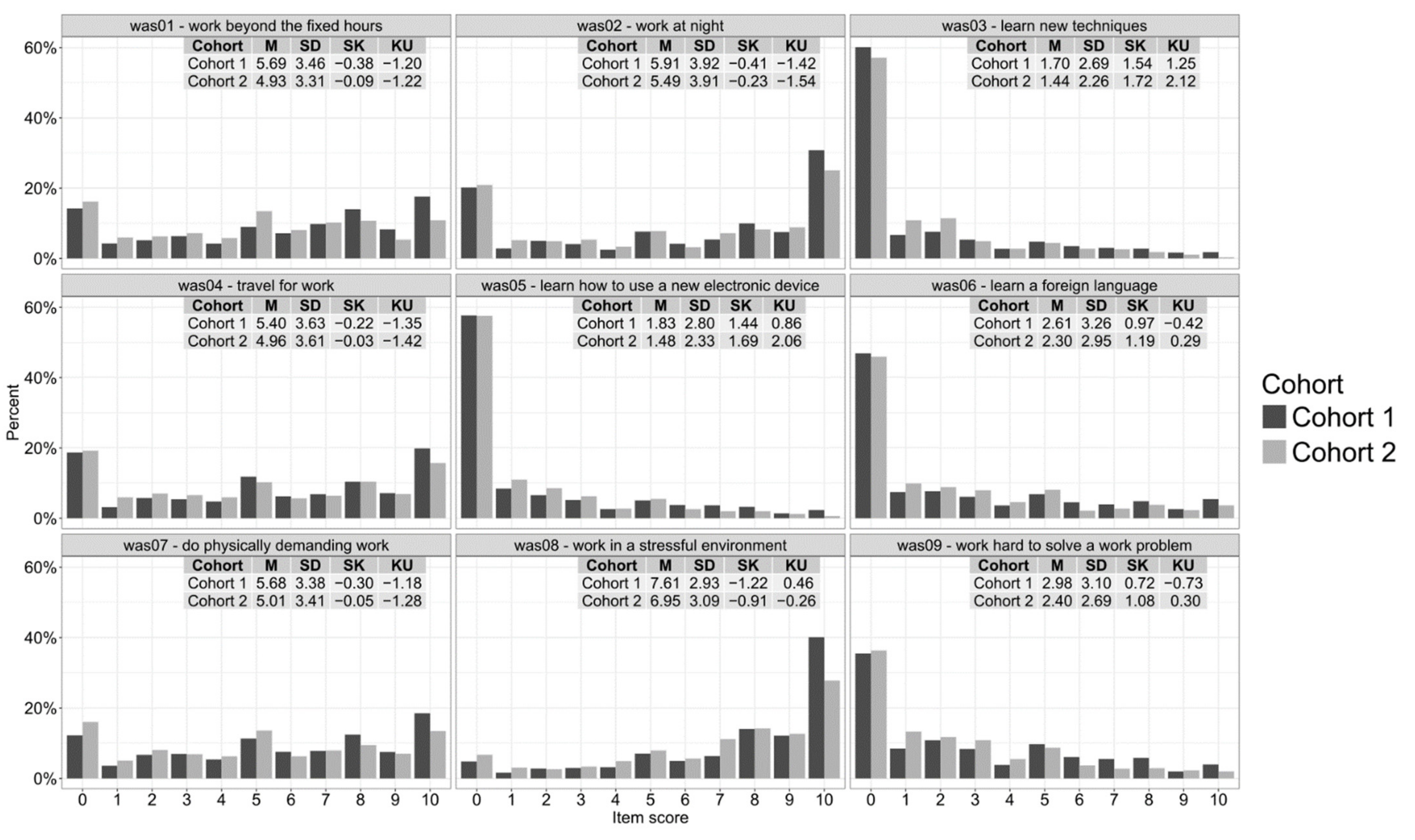
3.1. Traditional Approach
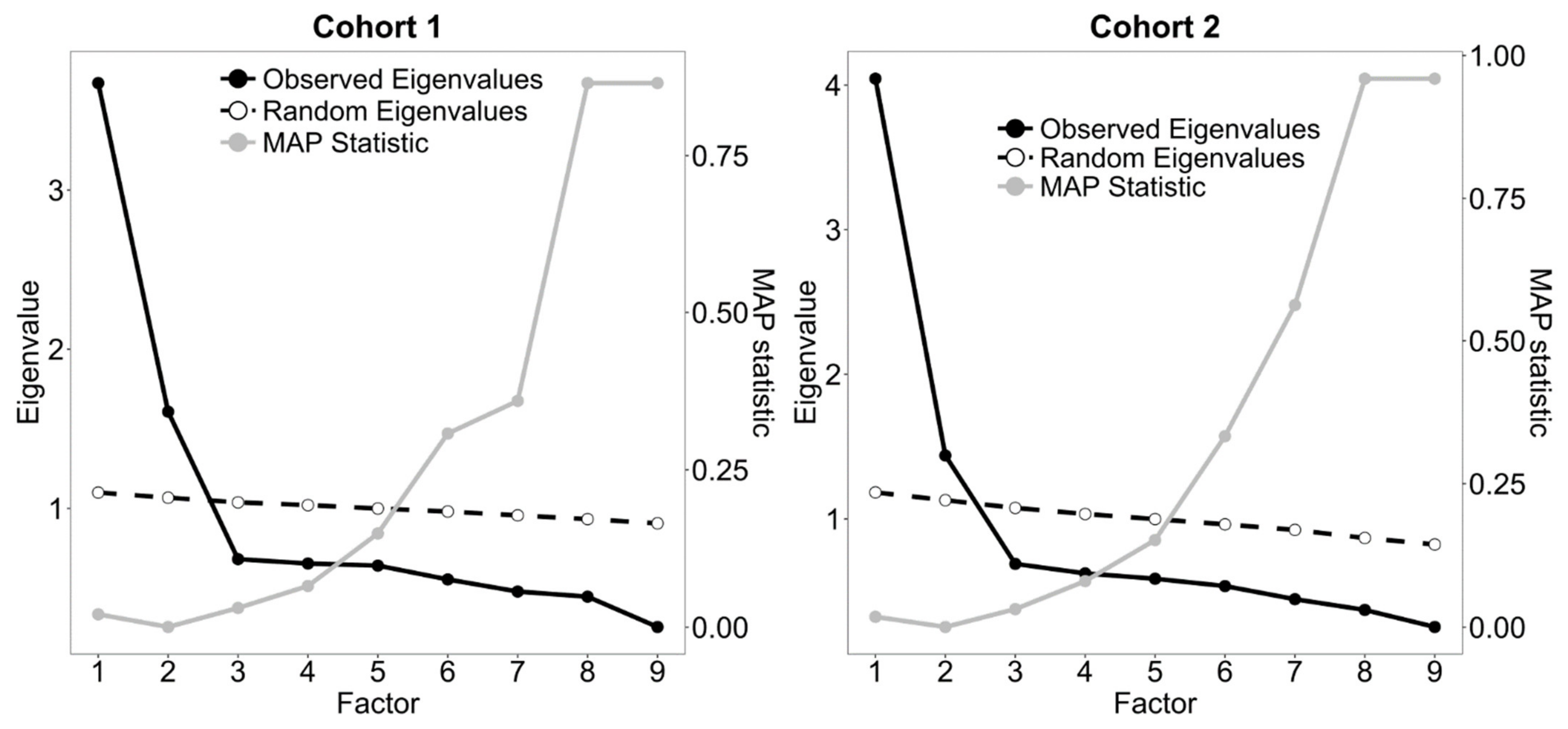
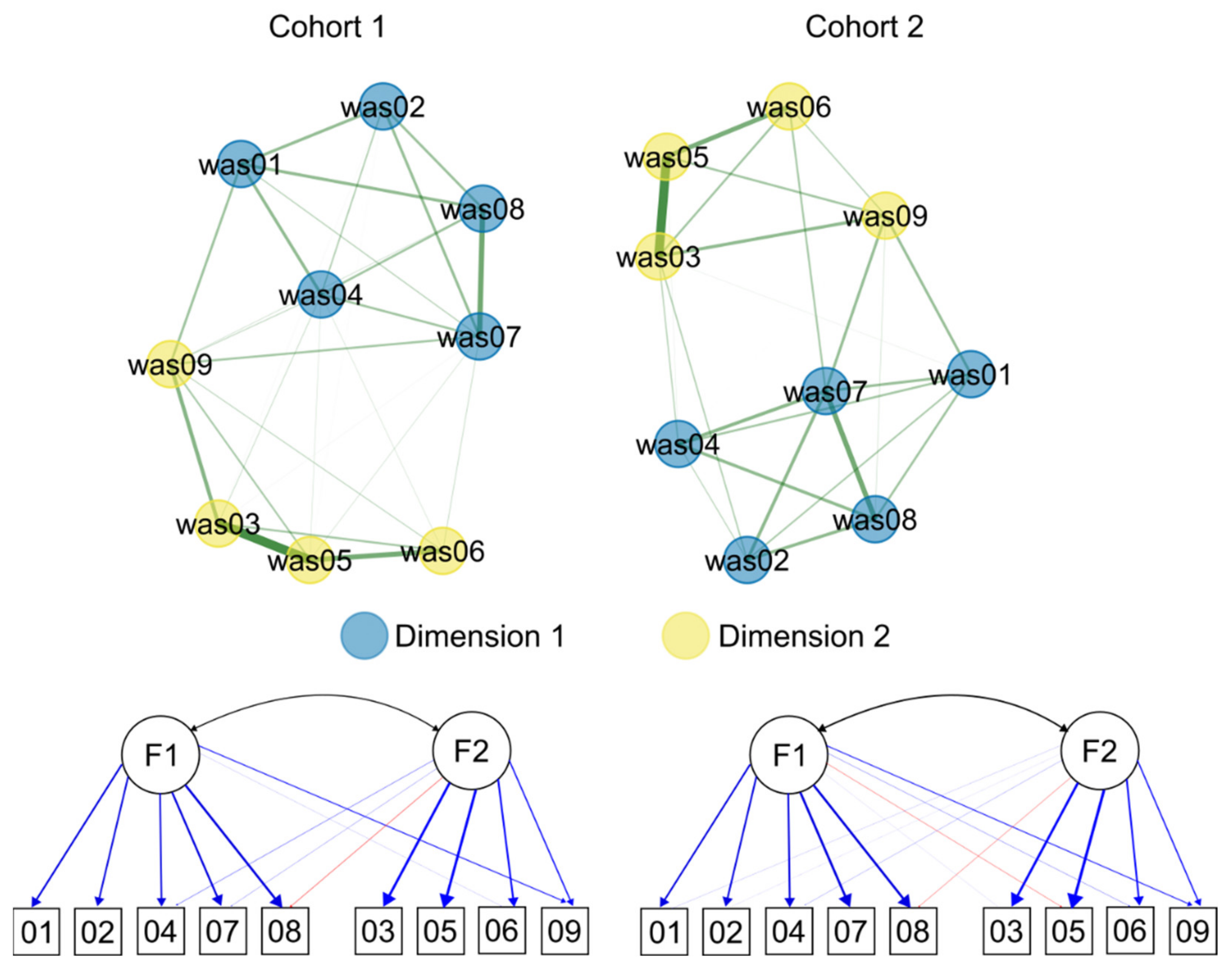
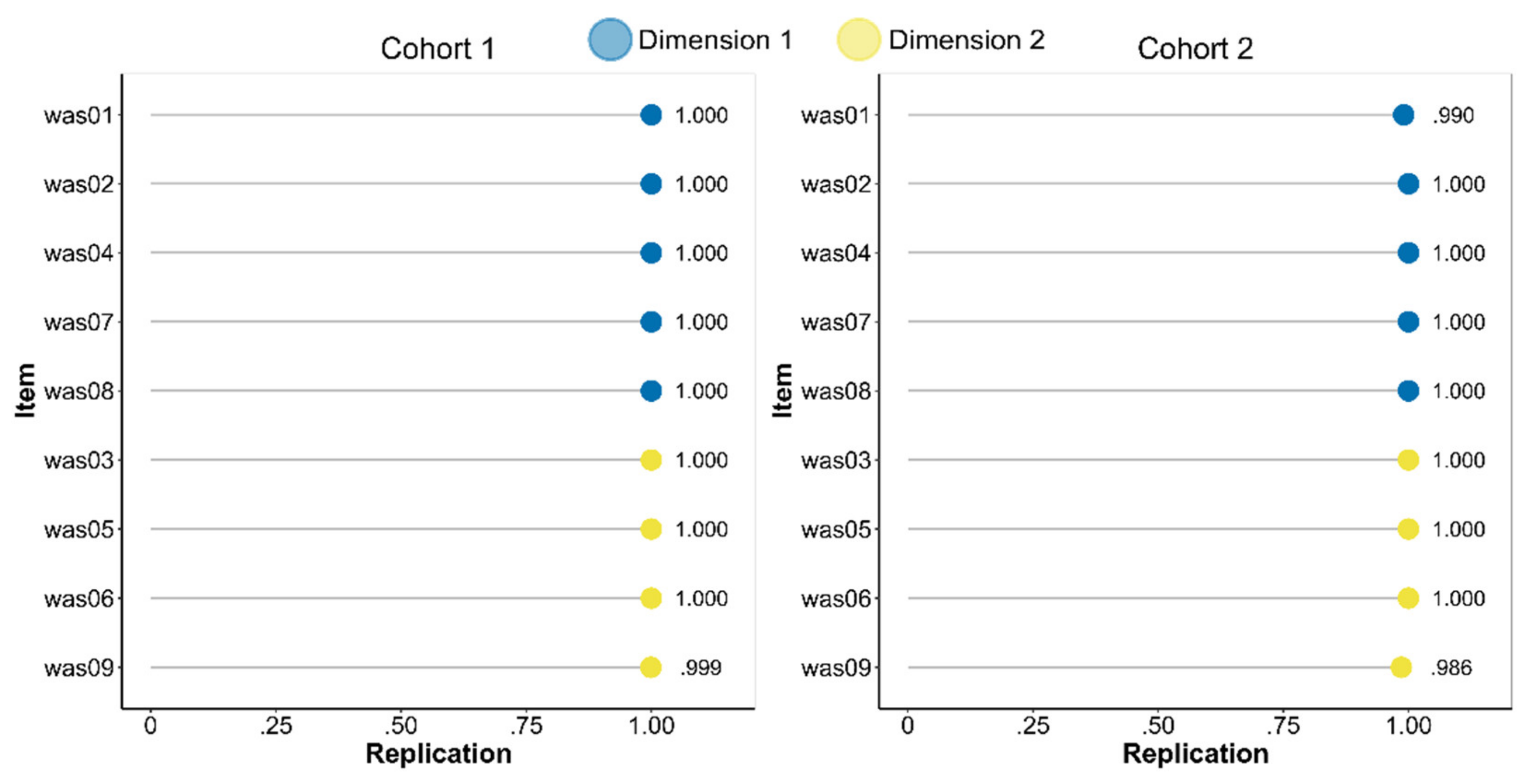
3.2. Network Approach
3.3. External Validation
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Borsboom, D. Psychometric Perspectives on Diagnostic Systems. J. Clin. Psychol. 2008, 64, 1089–1108. [Google Scholar] [CrossRef]
- Borsboom, D. A Network Theory of Mental Disorders. World Psychiatry 2017, 16, 5–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Christensen, A.P.; Golino, H.; Silvia, P.J. A Psychometric Network Perspective on the Validity and Validation of Personality Trait Questionnaires. Eur. J. Pers. 2020, 34, 1095–1108. [Google Scholar] [CrossRef]
- Judge, T.A.; Kammeyer-Mueller, J.D. Job Attitudes. Annu. Rev. Psychol. 2011, 63, 341–367. [Google Scholar] [CrossRef] [PubMed]
- Hackman, J.R.; Oldham, G.R. Motivation through the Design of Work: Test of a Theory. Organ. Behav. Hum. Perform. 1976, 16, 250–279. [Google Scholar] [CrossRef]
- Judge, T.A.; Bono, J.E.; Locke, E.A.; Tippie, H.B.; Judge, T.A. Personality and Job Satisfaction: The Mediating Role of Job Characteristics. J. Appl. Psychol. 2000, 85, 237–249. [Google Scholar] [CrossRef] [PubMed]
- Karasek, R.A. Job Demands, Job Decision Latitude, and Mental Strain: Implications for Job Redesign. Adm. Sci. Q. 1979, 24, 285–308. [Google Scholar] [CrossRef]
- Siegrist, J. Adverse Health Effects of High-Effort/Low-Reward Conditions. J. Occup. Health Psychol. 1996, 1, 27–41. [Google Scholar] [CrossRef]
- Johnson, J.V.; Hall, E.M. Job Strain, Work Place Social Support, and Cardiovascular Disease: A Cross-Sectional Study of a Random Sample of the Swedish Working Population. Am. J. Public Health 1988, 78, 1336–1342. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Johnson, J.V.; Hall, E.M.; Theorell, T. Combined Effects of Job Strain and Social Isolation on Cardiovascular Disease Morbidity and Mortality in a Random Sample of the Swedish Male Working Population. Scand. J. Work. Environ. Health 1989, 15, 271–279. [Google Scholar] [CrossRef] [Green Version]
- Siegrist, J. Effort-Reward Imbalance and Health in a Globalized Economy. Scand. J. Work. Environ. Health 2008, 35, 163–168. [Google Scholar]
- Calnan, M.; Wainwright, D.; Wadsworth, E.; Smith, A.; May, M. Job Strain, Effort-Reward Imbalance, and Stress at Work: Competing or Complementary Models? Scand. J. Public Health 2004, 32, 84–93. [Google Scholar] [CrossRef] [PubMed]
- Demerouti, E.; Nachreiner, F.; Bakker, A.B.; Schaufeli, W.B. The Job Demands-Resources Model of Burnout. J. Appl. Psychol. 2001, 86, 499–512. [Google Scholar] [CrossRef]
- Bakker, A.B.; Demerouti, E. The Job Demands-Resources Model: State of the Art. J. Manag. Psychol. 2007, 22, 309–328. [Google Scholar] [CrossRef] [Green Version]
- Bakker, A.B.; Van Emmerik, H.; Van Riet, P. How Job Demands, Resources, and Burnout Predict Objective Performance: A Constructive Replication. Anxiety Stress Coping 2008, 21, 309–324. [Google Scholar] [CrossRef] [PubMed]
- Bakker, A.B.; Demerouti, E. Job Demands-Resources Theory: Taking Stock and Looking Forward. J. Occup. Health Psychol. 2017, 22, 273–285. [Google Scholar] [CrossRef] [PubMed]
- Siegrist, J.; Starke, D.; Chandola, T.; Godin, I.; Marmot, M.; Niedhammer, I.; Peter, R. The Measurement of Effort-Reward Imbalance at Work: European Comparisons. Soc. Sci. Med. 2004, 58, 1483–1499. [Google Scholar] [CrossRef]
- Karasek, R.; Brisson, C.; Kawakami, N.; Houtman, I.; Bongers, P.; Amick, B. The Job Content Questionnaire (JCQ): An Instrument for Internationally Comparative Assessments of Psychosocial Job Characteristics. J. Occup. Health Psychol. 1998, 3, 322–355. [Google Scholar] [CrossRef] [PubMed]
- Rafferty, Y.; Friend, R.; Landsbergis, P.A. The Association between Job Skill Discretion, Decision Authority and Burnout. Work Stress 2001, 15, 73–85. [Google Scholar] [CrossRef]
- Lehtonen, E.E.; Nokelainen, P.; Rintala, H.; Puhakka, I. Thriving or Surviving at Work: How Workplace Learning Opportunities and Subjective Career Success Are Connected with Job Satisfaction and Turnover Intention? J. Work. Learn. 2022, 34, 88–109. [Google Scholar] [CrossRef]
- Ayres, J.; Malouff, J.M. Problem-Solving Training to Help Workers Increase Positive Affect, Job Satisfaction, and Life Satisfaction. Eur. J. Work Organ. Psychol. 2007, 16, 279–294. [Google Scholar] [CrossRef]
- Viotti, S.; Converso, D. Relationship between Job Demands and Psychological Outcomes among Nurses: Does Skill Discretion Matter? Int. J. Occup. Med. Environ. Health 2016, 29, 439–460. [Google Scholar] [CrossRef] [PubMed]
- Bakker, A.B.; van Veldhoven, M.; Xanthopoulou, D. Beyond the Demand-Control Model: Thriving on High Job Demands and Resources. J. Pers. Psychol. 2010, 9, 3–16. [Google Scholar] [CrossRef]
- Dollard, M.F.; Winefield, H.R.; Winefield, A.H.; De Jonge, J. Psychosocial Job Strain and Productivity in Human Service Workers: A Test of the Demand-Control-Support Model. J. Occup. Organ. Psychol. 2000, 73, 501–510. [Google Scholar] [CrossRef] [Green Version]
- Van Ruysseveldt, J.; Proost, K.; Verboon, P. The Role of Work-Home Interference and Workplace Learning in the Energy-Depletion Process. Manag. Rev. 2011, 22, 151–168. [Google Scholar] [CrossRef] [Green Version]
- Meyer, S.C.; Hünefeld, L. Challenging Cognitive Demands at Work, Related Working Conditions, and Employee Well-Being. Int. J. Environ. Res. Public Health 2018, 15, 2911. [Google Scholar] [CrossRef] [Green Version]
- Belloni, M.; Carrino, L.; Meschi, E. The Impact of Working Conditions on Mental Health: Novel Evidence from the UK. Labour Econ. 2022, 76, 102176. [Google Scholar] [CrossRef]
- Borsboom, D.; Mellenbergh, G.J.; Van Heerden, J. The Concept of Validity. Psychol. Rev. 2004, 111, 1061–1071. [Google Scholar] [CrossRef]
- Michell, J. Quantitative Science and the Definition of Measurement in Psychology. Br. J. Psychol. 1997, 88, 355–383. [Google Scholar] [CrossRef]
- Borsboom, D.; Mellenbergh, G.J.; Van Heerden, J. The Theoretical Status of Latent Variables. Psychol. Rev. 2003, 110, 203–219. [Google Scholar] [CrossRef] [Green Version]
- Fried, E.I. What Are Psychological Constructs? On the Nature and Statistical Modelling of Emotions, Intelligence, Personality Traits and Mental Disorders. Health Psychol. Rev. 2017, 11, 130–134. [Google Scholar] [CrossRef]
- Stevens, S.S. On the Theory of Scales of Measurement. Science 1946, 103, 677–680. [Google Scholar] [CrossRef] [PubMed]
- Bridgman, P.W. The Logic of Modern Physics; Macmillan: New York, NY, USA, 1927. [Google Scholar]
- American Psychological Association Extraversion (Extroversion). Available online: https://dictionary.apa.org/extraversion (accessed on 15 April 2022).
- Borsboom, D.; Mellenbergh, G.J. Test Validity in Cognitive Assessment. In Cognitive Diagnostic Assessment for Education: Theory and Applications; Leighton, J.P., Gierl, M.J., Eds.; Cambridge University Press: New York, NY, USA, 2007; pp. 85–116. [Google Scholar]
- Allport, G.W. Pattern and Growth in Personality; Holt, Reinhart, & Winston: Oxford, UK, 1961. [Google Scholar]
- Baumert, A.; Schmitt, M.; Perugini, M.; Johnson, W.; Blum, G.; Borkenau, P.; Costantini, G.; Denissen, J.J.A.; Fleeson, W.; Grafton, B.; et al. Integrating Personality Structure, Personality Process, and Personality Development. Eur. J. Pers. 2017, 31, 503–528. [Google Scholar] [CrossRef] [Green Version]
- Hogan, R.; Foster, J. Rethinking Personality. Int. J. Personal. Psychol. 2016, 2, 37–43. [Google Scholar]
- Olthof, M.; Hasselman, F.; Oude Maatman, F.; Bosman, A.M.T.; Lichtwarck-Aschoff, A. Complexity Theory of Psychopathology. PsyArXiv 2022. [Google Scholar] [CrossRef]
- Schmittmann, V.D.; Cramer, A.O.J.; Waldorp, L.J.; Epskamp, S.; Kievit, R.A.; Borsboom, D. Deconstructing the Construct: A Network Perspective on Psychological Phenomena. New Ideas Psychol. 2013, 31, 43–53. [Google Scholar] [CrossRef]
- Cramer, A.O.J.; van der Sluis, S.; Noordhof, A.; Wichers, M.; Geschwind, N.; Aggen, S.H.; Kendler, K.S.; Borsboom, D. Dimensions of Normal Personality as Networks in Search of Equilibrium: You Can’t like Parties If You Don’t like People. Eur. J. Pers. 2012, 26, 414–431. [Google Scholar] [CrossRef]
- Cramer, A.O.J. Why the Item “23 + 1” Is Not in a Depression Questionnaire: Validity from a Network Perspective. Measurement 2012, 10, 50–54. [Google Scholar] [CrossRef]
- McCrae, R.R.; Costa, P.T. Personality Trait Structure as a Human Universal. Am. Psychol. 1997, 52, 509–516. [Google Scholar] [CrossRef]
- Costantini, G.; Perugini, M. The Definition of Components and the Use of Formal Indexes Are Key Steps for a Successful Application of Network Analysis in Personality Psychology. Eur. J. Pers. 2012, 26, 434–435. [Google Scholar] [CrossRef]
- McDonald, R.P. Behavior Domains in Theory and in Practice. Alberta J. Educ. Res. 2003, 49, 212–230. [Google Scholar]
- Reise, S.P.; Moore, T.M.; Haviland, M.G. Bifactor Models and Rotations: Exploring the Extent to Which Multidimensional Data Yield Univocal Scale Scores. J. Pers. Assess. 2010, 92, 544–559. [Google Scholar] [CrossRef] [PubMed]
- Hallquist, M.N.; Wright, A.G.C.; Molenaar, P.C.M. Problems with Centrality Measures in Psychopathology Symptom Networks: Why Network Psychometrics Cannot Escape Psychometric Theory. Multivar. Behav. Res. 2021, 56, 199–223. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, B.; Horvath, S. A General Framework for Weighted Gene Co-Expression Network Analysis. Stat. Appl. Genet. Mol. Biol. 2005, 4, 17. [Google Scholar] [CrossRef] [PubMed]
- Golino, H.; Christensen, A.P. EGAnet: Exploratory Graph Analysis. A Framework for Estimating the Number of Dimensions in Multivariate Data Using Network Psychometrics. Available online: https://cran.r-project.org/package=EGAnet. (accessed on 15 April 2022).
- Fortunato, S. Community Detection in Graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef] [Green Version]
- Golino, H.F.; Epskamp, S. Exploratory Graph Analysis: A New Approach for Estimating the Number of Dimensions in Psychological Research. PLoS ONE 2017, 12, e0174035. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Epskamp, S.; Waldorp, L.J.; Mõttus, R.; Borsboom, D. The Gaussian Graphical Model in Cross-Sectional and Time-Series Data. Multivar. Behav. Res. 2018, 53, 453–480. [Google Scholar] [CrossRef] [Green Version]
- Lauritzen, S. Graphical Models; Clarendon Press: Oxford, UK, 1996. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. Sparse Inverse Covariance Estimation with the Graphical Lasso. Biostatistics 2008, 9, 432–441. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Massara, G.P.; Di Matteo, T.; Aste, T. Network Filtering for Big Data: Triangulated Maximally Filtered Graph. J. Complex Networks 2017, 5, 161–178. [Google Scholar] [CrossRef]
- Golino, H.; Shi, D.; Christensen, A.P.; Garrido, L.E.; Nieto, M.D.; Sadana, R.; Thiyagarajan, J.A.; Martínez-Molina, A. Investigating the Performance of Exploratory Graph Analysis and Traditional Techniques to Identify the Number of Latent Factors: A Simulation and Tutorial. Psychol. Methods 2020, 25, 292–320. [Google Scholar] [CrossRef] [Green Version]
- Pons, P.; Latapy, M. Computing Communities in Large Networks Using Random Walks. J. Graph Algorithms Appl. 2006, 10, 191–218. [Google Scholar] [CrossRef] [Green Version]
- Christensen, A.P.; Golino, H. On the Equivalency of Factor and Network Loadings. Behav. Res. Methods 2021, 53, 1563–1580. [Google Scholar] [CrossRef] [PubMed]
- Flora, D.B. Your Coefficient Alpha Is Probably Wrong, but Which Coefficient Omega Is Right? A Tutorial on Using R to Obtain Better Reliability Estimates. Adv. Methods Pract. Psychol. Sci. 2020, 3, 484–501. [Google Scholar] [CrossRef]
- Christensen, A.P.; Golino, H. Estimating the Stability of the Number of Factors via Bootstrap Exploratory Graph Analysis: A Tutorial. Psych 2021, 3, 479–500. [Google Scholar] [CrossRef]
- Epskamp, S.; Fried, E.I. A Tutorial on Regularized Partial Correlation Networks. Psychol. Methods 2018, 23, 617–634. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cohen, J.; Cohen, P.; West, S.G.; Aiken, L.S. Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences, 3rd ed.; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 2003. [Google Scholar]
- Haslbeck, J.M.B.; Waldorp, L.J. How Well Do Network Models Predict Observations? On the Importance of Predictability in Network Models. Behav. Res. Methods 2018, 50, 853–861. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Briganti, G.; Scutari, M.; McNally, R.J. A Tutorial on Bayesian Networks for Psychopathology Researchers. Psychol. Methods Online ahead of print 2021. [Google Scholar] [CrossRef] [PubMed]
- Asparouhov, T.; Muthén, B. Exploratory Structural Equation Modeling. Struct. Equ. Model. 2009, 16, 397–438. [Google Scholar] [CrossRef]
- Peters, G.-J.Y.; Gruijters, S. Ufs: A Collection of Utilities. 2021. Available online: https://r-packages.gitlab.io/ufs/ (accessed on 15 April 2022).
- Siegrist, J.; Li, J.; Montano, D. Psychometric Properties of the Effort-Reward Imbalance Questionnaire; Centre for Health and Society, Faculty of Medicine, Heinrich-Heine-University Duesseldorf: Duesseldorf, Germany, 2019. [Google Scholar]
- Magnavita, N. Two Tools for Health Surveillance of Job Stress: The Karasek Job Content Questionnaire and the Siegrist Effort Reward Imbalance Questionnaire. G. Ital. Med. Lav. Ergon. 2007, 29, 667–670. [Google Scholar] [PubMed]
- Sanne, B.; Torp, S.; Mykletun, A.; Dahl, A.A. The Swedish Demand-Control-Support Questionnaire (DCSQ): Factor Structure, Item Analyses, and Internal Consistency in a Large Population. Scand. J. Public Health 2005, 33, 166–174. [Google Scholar] [CrossRef] [PubMed]
- Goldberg, D.P.; Williams, P. A Users’ Guide to the General Health Questionnaire; GL Assessment: London, UK, 1988. [Google Scholar]
- Piccinelli, M.; Bisoffi, G.; Bon, M.G.; Cunico, L.; Tansella, M. Validity and Test-Retest Reliability of the Italian Version of the 12-Item General Health Questionnaire in General Practice: A Comparison between Three Scoring Methods. Compr. Psychiatry 1993, 34, 198–205. [Google Scholar] [CrossRef]
- Buysse, D.J.; Reynolds, C.F.; Monk, T.H.; Berman, S.R.; Kupfer, D.J. The Pittsburgh Sleep Quality Index: A New Instrument for Psychiatric Practice and Research. Psychiatry Res. 1989, 28, 193–213. [Google Scholar] [CrossRef]
- Curcio, G.; Tempesta, D.; Scarlata, S.; Marzano, C.; Moroni, F.; Rossini, P.M.; Ferrara, M.; De Gennaro, L. Validity of the Italian Version of the Pittsburgh Sleep Quality Index (PSQI). Neurol. Sci. 2013, 34, 511–519. [Google Scholar] [CrossRef] [PubMed]
- Netzer, N.C.; Stoohs, R.A.; Netzer, C.M.; Clark, K.; Strohl, K.P. Using the Berlin Questionnaire to Identify Patients at Risk for the Sleep Apnea Syndrome. Ann. Intern. Med. 1999, 131, 485–491. [Google Scholar] [CrossRef] [PubMed]
- Lombardi, C.; Carabalona, R.; Lonati, L.; Salerno, S.; Mattaliano, P.; Colamartino, E.; Gregorini, F.; Giuliano, A.; Castiglioni, P.; Agostoni, P.; et al. Hypertension and Obstructive Sleep Apnea: Is the Berlin Questionnaire a Valid Screening Tool? J. Hypertens. 2010, 28, e531. [Google Scholar] [CrossRef]
- Johns, M.W. A New Method for Measuring Daytime Sleepiness: The Epworth Sleepiness Scale. Sleep 1991, 14, 540–545. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vignatelli, L.; Plazzi, G.; Barbato, A.; Ferini-Strambi, L.; Manni, R.; Pompei, F.; D’Alessandro, R.; Brancasi, B.; Misceo, S.; Puca, F.; et al. Italian Version of the Epworth Sleepiness Scale: External Validity. Neurol. Sci. 2003, 23, 295–300. [Google Scholar] [CrossRef] [PubMed]
- Goldberg, D.; Bridges, K.; Duncan-Jones, P.; Grayson, D. Detecting Anxiety and Depression in General Medical Settings. BMJ 1988, 297, 897–899. [Google Scholar] [CrossRef] [Green Version]
- Magnavita, N. Anxiety and Depression at Work. The A/D Goldberg Questionnaire. G. Ital. Med. Lav. Ergon. 2007, 29, 670–671. [Google Scholar] [PubMed]
- Cattell, R.B. The Scree Test for the Number of Factors. Multivar. Behav. Res. 1966, 1, 245–276. [Google Scholar] [CrossRef] [PubMed]
- Horn, J.L. A Rationale and Test for the Number of Factors in Factor Analysis. Psychometrika 1965, 30, 179–185. [Google Scholar] [CrossRef]
- Velicer, W. Determining the Number of Components from the Matrix of Partial Correlations. Psychometrika 1976, 41, 321–327. [Google Scholar] [CrossRef]
- Buja, A.; Eyuboglu, N. Remarks on Parallel Analysis. Multivar. Behav. Res. 1992, 27, 509–540. [Google Scholar] [CrossRef] [PubMed]
- Longman, R.S.; Cota, A.A.; Holden, R.R.; Fekken, G.C. A Regression Equation for the Parallel Analysis Criterion in Principal Components Analysis: Mean and 95th Percentile Eigenvalues. Multivar. Behav. Res. 1989, 24, 59–69. [Google Scholar] [CrossRef] [PubMed]
- Cliff, N. The Eigenvalues-Greater-Than-One Rule and the Reliability of Components. Psychol. Bull. 1988, 103, 276–279. [Google Scholar] [CrossRef]
- Auerswald, M.; Moshagen, M. How to Determine the Number of Factors to Retain in Exploratory Factor Analysis: A Comparison of Extraction Methods under Realistic Conditions. Psychol. Methods 2019, 24, 468–491. [Google Scholar] [CrossRef] [PubMed]
- Revelle, W. Psych: Procedures for Psychological, Psychometric, and Personality Research. Available online: http://cran.r-project.org/package=psych. (accessed on 15 April 2022).
- Marsh, H.W.; Hau, K.-T.; Wen, Z. In Search of Golden Rules: Comment on Hypothesis-Testing Approaches to Setting Cutoff Values for Fit Indexes and Dangers in Overgeneralizing Hu and Bentler’s (1999) Findings. Struct. Equ. Model. 2004, 11, 320–341. [Google Scholar] [CrossRef]
- Rosseel, Y. Lavaan: An R Package for Structural Equation Modeling. J. Stat. Softw. 2012, 48, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Williams, D.R.; Rhemtulla, M.; Wysocki, A.C.; Rast, P. On Nonregularized Estimation of Psychological Networks. Multivar. Behav. Res. 2019, 54, 719–750. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Williams, D.R.; Rast, P.; Pericchi, L.R.; Mulder, J. Comparing Gaussian Graphical Models with the Posterior Predictive Distribution and Bayesian Model Selection. Psychol. Methods 2020, 25, 653–672. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Williams, D.R.; Rast, P. Back to the Basics: Rethinking Partial Correlation Network Methodology. Br. J. Math. Stat. Psychol. 2020, 73, 187–212. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Williams, D.R.; Mulder, J. BGGM: Bayesian Gaussian Graphical Models in R. J. Open Source Softw. 2020, 5, 2111. [Google Scholar] [CrossRef]
- Gelman, A. Scaling Regression Inputs by Dividing by Two Standard Deviations. Stat. Med. 2008, 27, 2865–2873. [Google Scholar] [CrossRef] [PubMed]
- Gelman, A. Don’t Do the Wilcoxon [Blog Post]. Available online: https://andrewgelman.com/2015/07/13/dont-do-the-wilcoxon/ (accessed on 15 April 2022).
- Jones, P. Networktools: Tools for Identifying Important Nodes in Networks. Available online: https://cran.r-project.org/package=networktools (accessed on 15 April 2022).
- DeVellis, R.F. Scale Development: Theory and Applications, 4th ed.; Sage: Thousand Oaks, CA, USA, 2017. [Google Scholar]
- Borsboom, D.; Cramer, A.O.J. Network Analysis: An Integrative Approach to the Structure of Psychopathology. Annu. Rev. Clin. Psychol. 2013, 9, 91–121. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Condon, D.M. The SAPA Personality Inventory: An Empirically-Derived, Hierarchically-Organized Self-Report Personality Assessment Model. PsyArXiv 2018. Preprints. [Google Scholar]
- Kruis, J.; Maris, G. Three Representations of the Ising Model. Sci. Rep. 2016, 6, 34175. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marsman, M.; Borsboom, D.; Kruis, J.; Epskamp, S.; Van Bork, R.; Waldorp, L.J.; Van Der Maas, H.L.J.; Maris, G. An Introduction to Network Psychometrics: Relating Ising Network Models to Item Response Theory Models. Multivar. Behav. Res. 2018, 53, 15–35. [Google Scholar] [CrossRef]
- Kan, K.J.; De Jonge, H.; Van Der Maas, H.L.J.; Levine, S.Z.; Epskamp, S. How to Compare Psychometric Factor and Network Models. J. Intell. 2020, 8, 35. [Google Scholar] [CrossRef]
- Schaufeli, W.B.; Bakker, A.B. Job Demands, Job Resources, and Their Relationship with Burnout and Engagement: A Multi-Sample Study. J. Organ. Behav. 2004, 25, 293–315. [Google Scholar] [CrossRef] [Green Version]
- Wysocki, A.C.; Lawson, K.M.; Rhemtulla, M. Statistical Control Requires Causal Justification. Adv. Methods Pract. Psychol. Sci. 2022, 5, 25152459221095823. [Google Scholar] [CrossRef]
- Mun, S.; Moon, Y.; Kim, H.; Kim, N. Current Discussions on Employees and Organizations During the COVID-19 Pandemic: A Systematic Literature Review. Front. Psychol. 2022, 13, 848778. [Google Scholar] [CrossRef]
- Magnavita, N.; Tripepi, G.; Chiorri, C. Telecommuting, off-Time Work, and Intrusive Leadership in Workers’ Well-Being. Int. J. Environ. Res. Public Health 2021, 18, 3330. [Google Scholar] [CrossRef] [PubMed]
- Palumbo, R. Let Me Go to the Office! An Investigation into the Side Effects of Working from Home on Work-Life Balance. Int. J. Public Sect. Manag. 2020, 33, 771–790. [Google Scholar] [CrossRef]
- Sousa-Uva, M.; Sousa-Uva, A.; e Sampayo, M.M.; Serranheira, F. Telework during the COVID-19 Epidemic in Portugal and Determinants of Job Satisfaction: A Cross-Sectional Study. BMC Public Health 2021, 21, 2217. [Google Scholar] [CrossRef] [PubMed]
- Hofstede, G.; Hofstede, G.J.; Minkov, M. Cultures and Organizations: Software of the Mind, Intercultural Cooperation and Its Importance for Survival; McGraw-Hill: New York, NY, USA, 2010. [Google Scholar]
- Beehr, T.A.; Glazer, S. A Cultural Perspective of Social Support in Relation to Occupational Stress. In Research in Occupational Stress and Well-Being; Perrewé, P.L., Ganster, D.C., Moran, J., Eds.; JAI Press: Greenwich, CT, USA, 2001; pp. 97–142. [Google Scholar]
- Steiger, J.H. Testing Pattern Hypotheses on Correlation Matrices: Alternative Statistics and Some Empirical Results. Multivariate Behav. Res. 1980, 15, 335–352. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Cohort 1 (n = 2226) | Cohort 2 (n = 655) |
|---|---|---|
| Age (M ± SD, range) | 47.61 ± 9.40 (19–75) | 44.00 ± 12.19 (20–67) |
| Female (%) | 32.34% | 63.49% |
| Working at night (%) | 8.89% | NA |
| ERI-SF—Effort (M ± SD, range, ω, AVE) | 2.25 ± 0.77 (1–4), 0.85 [0.84, 0.86], 0.65 | 2.34 ± 0.75 (1–4), 0.83 [0.81, 0.86], 0.63 |
| ERI-SF—Reward (M ± SD, range, ω, AVE) | 2.50 ± 0.55 (1–4), 0.77 [0.76, 0.78], 0.37 | 2.39 ± 0.54 (1–4), 0.76 [0.73, 0.79], 0.36 |
| ERI-SF—Overcommitment (M ± SD, range, ω, AVE) | 2.69 ± 0.62 (1–4), 0.83 [0.82, 0.84], 0.46 | 2.71 ± 0.63 (1–4), 0.84 [0.83, 0.86], 0.49 |
| DCSQ—Social support (M ± SD, range, ω, AVE) | 3.20 ± 0.56 (1–4), 0.89 [0.88, 0.90], 0.59 | 3.30 ± 0.53 (1–4), 0.89 [0.88, 0.91], 0.60 |
| GHQ (M ± SD, range, ω, AVE) | 2.00 ± 0.48 (1–4), 0.93 [0.92, 0.93], 0.54 | NA |
| Working capacity (M ± SD, range) | 8.43 ± 1.87 (0–10) | 8.03 ± 1.67 (0–10) |
| WAS—Working conditions (M ± SD, range, ω, AVE) | 6.06 ± 2.51 (0–10), 0.77 [0.75, 0.78], 40 | 5.47 ± 2.60 (0–10), 0.80 [0.78, 0.83], 0.45 |
| WAS—Cognitive demands (M ± SD, range, ω, AVE) | 2.28 ± 2.35 (0–10), 0.81 [0.79, 0.82], 51 | 1.90 ± 2.05 (0–10), 0.81 [0.78, 0.83], 0.51 |
| Job satisfaction (M ± SD, range) | 4.52 ± 1.49 (1–7) | 4.40 ± 1.55 (1–7) |
| Happiness (M ± SD, range) | 6.97 ± 1.86 (0–10) | 7.09 ± 1.91 (0–10) |
| GADS—Anxiety (M ± SD, range, ω, AVE) | NA | 3.84 ± 2.96 (0–9), 0.92 [0.91, 0.93], 0.61 0.61.6161 |
| GADS—Depression (M ± SD, range, ω, AVE) | NA | 2.69 ± 2.45 (0–9), 0.92 [0.91, 0.93], 0.58 |
| Physically assaulted at work (%) | 9.30% | NA |
| Threatened at work (%) | 14.87% | NA |
| Harassed at work (%) | 18.69% | NA |
| Stalked at work (%) | 5.88% | NA |
| Accident at work (%) | 7.50% | NA |
| Accident at home (%) | 11.86% | NA |
| Trauma (e.g., death of a beloved one) (%) | 32.08% | NA |
| Accident while driving (%) | 7.95% | NA |
| Came close to having an accident while driving (%) | 25.43% | NA |
| Sleeping while driving | ||
| Never or almost never | 93.22% | NA |
| 1–2 times a month | 3.86% | NA |
| 1–2 times a week | 1.48% | NA |
| 3–4 times a week | 0.63% | NA |
| Almost every day | 0.81% | NA |
| PSQI—Component 1: Subjective sleep quality (M ± SD, range) | 1.07 ± 0.81 (0–3) | NA |
| PSQI—Component 2: Sleep latency (M ± SD, range) | 0.64 ± 0.68 (0–3) | NA |
| PSQI—Component 3: Sleep duration (M ± SD, range) | 1.45 ± 1.00 (0–3) | NA |
| PSQI—Component 4: Habitual sleep efficiency (M ± SD, range) | 0.27 ± 0.68 (0–3) | NA |
| PSQI—Component 5: Sleep disturbances (M ± SD, range) | 1.17 ± 0.64 (0–3) | NA |
| PSQI—Component 6: Use of sleeping medication (M ± SD, range) | 0.25 ± 0.74 (0–3) | NA |
| PSQI—Component 7: Daytime dysfunction (M ± SD, range) | 0.79 ± 0.77 (0–3) | NA |
| BQ—Category 1: Snoring (M ± SD, range) | 23.36% | NA |
| BQ—Category 2: Daytime somnolence (M ± SD, range) | 18.69% | NA |
| ESS (M ± SD, range, omega, AVE) | 0.73 ± 0.52 (0–3), 0.88 [0.87, 0.88], 0.49 | NA |
| Underweight (%) | 2.64% | NA |
| Normal weight (%) | 54.69% | NA |
| Overweight (%) | 29.63% | NA |
| Obesity (%) | 13.05% | NA |
| Hypertension (%) | 16.58% | NA |
| Hypercholesterolemia (%) | 27.58% | NA |
| Hypertriglyceridemia (%) | 10.29% | NA |
| Hyperglycemia (%) | 5.03% | NA |
| Weekly physical activity | ||
| Never | 48.61% | NA |
| Once | 16.85% | NA |
| Twice | 16.85% | NA |
| Three or more times | 17.70% | NA |
| Low-fat, low-sugar, low-salt diet | ||
| Never | 19.27% | NA |
| In some meals | 28.98% | NA |
| In most meals | 33.38% | NA |
| Every meal | 18.37% | NA |
| Daily alcohol consumption (units) | ||
| None | 59.30% | NA |
| 1–7 | 36.97% | NA |
| 8–16 | 2.96% | NA |
| 17+ | 0.76% | NA |
| Smoking (%) | 33.85% | NA |
| Desired retirement age: Before 60 (%) | NA | 8.84% |
| Desired retirement age: Between 60 and 65 (%) | NA | 41.80% |
| Desired retirement age: After 65 (%) | NA | 17.52% |
| Desired retirement age: Don’t know (%) | NA | 31.83% |
| Elder-worker-hostile environment | ||
| Not at all | NA | 7.12% |
| A little | NA | 22.33% |
| Somewhat | NA | 41.75% |
| Much | NA | 20.23% |
| Very much | NA | 8.58% |
| Perceived health condition | ||
| Very bad | NA | 3.76% |
| Bad | NA | 31.77% |
| Neither good nor bad | NA | 7.36% |
| Good | NA | 43.97% |
| Very good | NA | 13.15% |
| Pattern Coefficients | Network Loadings | |||
|---|---|---|---|---|
| Item | F1 | F2 | D1 | D2 |
| was01 | 0.62 0.59 | 0.00 0.04 | 0.31 0.26 | 0.08 0.10 |
| was02 | 0.57 0.59 | 0.00 0.02 | 0.29 0.27 | 0.01 0.05 |
| was03 | 0.00 0.02 | 0.84 0.82 | 0.04 0.09 | 0.48 0.46 |
| was04 | 0.54 0.60 | 0.12 0.06 | 0.27 0.29 | 0.09 0.05 |
| was05 | −0.01 −0.11 | 0.87 0.94 | 0.04 0.01 | 0.51 0.50 |
| was06 | 0.04 0.09 | 0.60 0.58 | 0.04 0.06 | 0.26 0.26 |
| was07 | 0.67 0.80 | 0.07 0.00 | 0.35 0.42 | 0.12 0.15 |
| was08 | 0.78 0.79 | −0.15 −0.10 | 0.39 0.40 | 0.02 0.02 |
| was09 | 0.32 0.30 | 0.44 0.43 | 0.19 0.18 | 0.22 0.22 |
| F1 with F2 | 0.41 0.53 | |||
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1. Observed D1 | 0.976 | 0.987 | 0.489 | 0.506 | 0.665 | |
| 2. ESEM D1 | 0.976 | 0.997 | 0.598 | 0.590 | 0.748 | |
| 3. Network D1 | 0.986 | 0.994 | 0.593 | 0.591 | 0.746 | |
| 4. Observed D2 | 0.417 | 0.516 | 0.536 | 0.957 | 0.966 | |
| 5. ESEM D2 | 0.399 | 0.478 | 0.500 | 0.962 | 0.968 | |
| 6. Network D2 | 0.558 | 0.636 | 0.654 | 0.974 | 0.976 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Magnavita, N.; Chiorri, C. Development and Validation of a New Measure of Work Annoyance Using a Psychometric Network Approach. Int. J. Environ. Res. Public Health 2022, 19, 9376. https://doi.org/10.3390/ijerph19159376
Magnavita N, Chiorri C. Development and Validation of a New Measure of Work Annoyance Using a Psychometric Network Approach. International Journal of Environmental Research and Public Health. 2022; 19(15):9376. https://doi.org/10.3390/ijerph19159376
Chicago/Turabian StyleMagnavita, Nicola, and Carlo Chiorri. 2022. "Development and Validation of a New Measure of Work Annoyance Using a Psychometric Network Approach" International Journal of Environmental Research and Public Health 19, no. 15: 9376. https://doi.org/10.3390/ijerph19159376
APA StyleMagnavita, N., & Chiorri, C. (2022). Development and Validation of a New Measure of Work Annoyance Using a Psychometric Network Approach. International Journal of Environmental Research and Public Health, 19(15), 9376. https://doi.org/10.3390/ijerph19159376