
DLKN-MLC: A Disease Prediction Model via Multi-Label Learning


Abstract
:1. Introduction
2. Materials and Methods
2.1. Datasets
2.2. DLKN-MLC Model
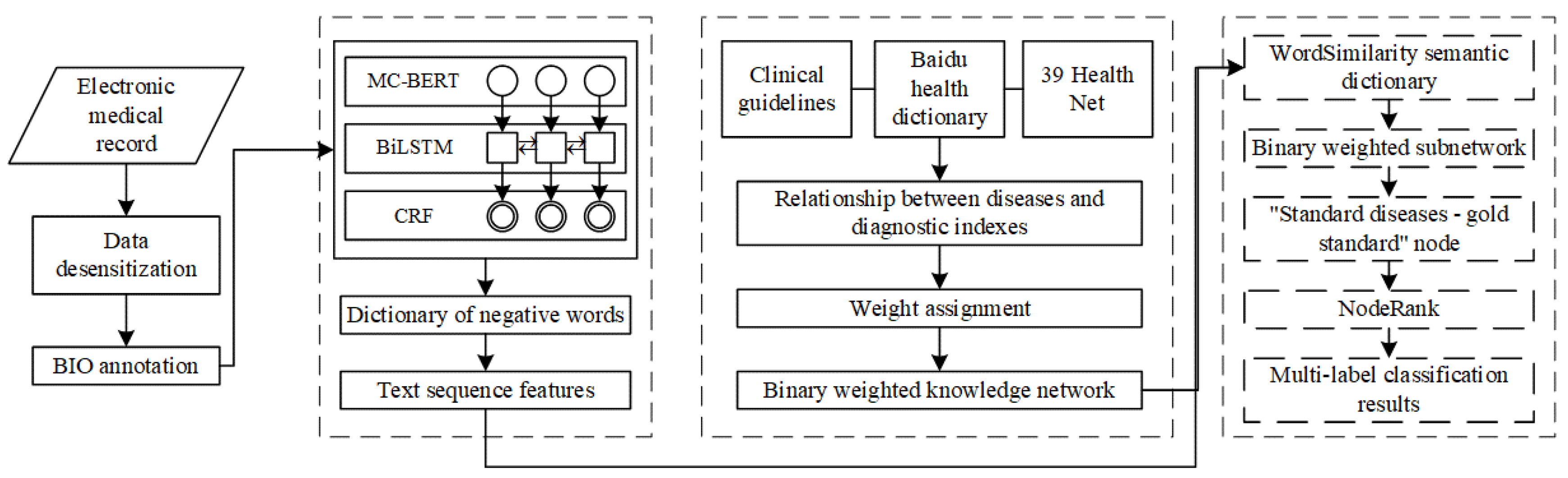
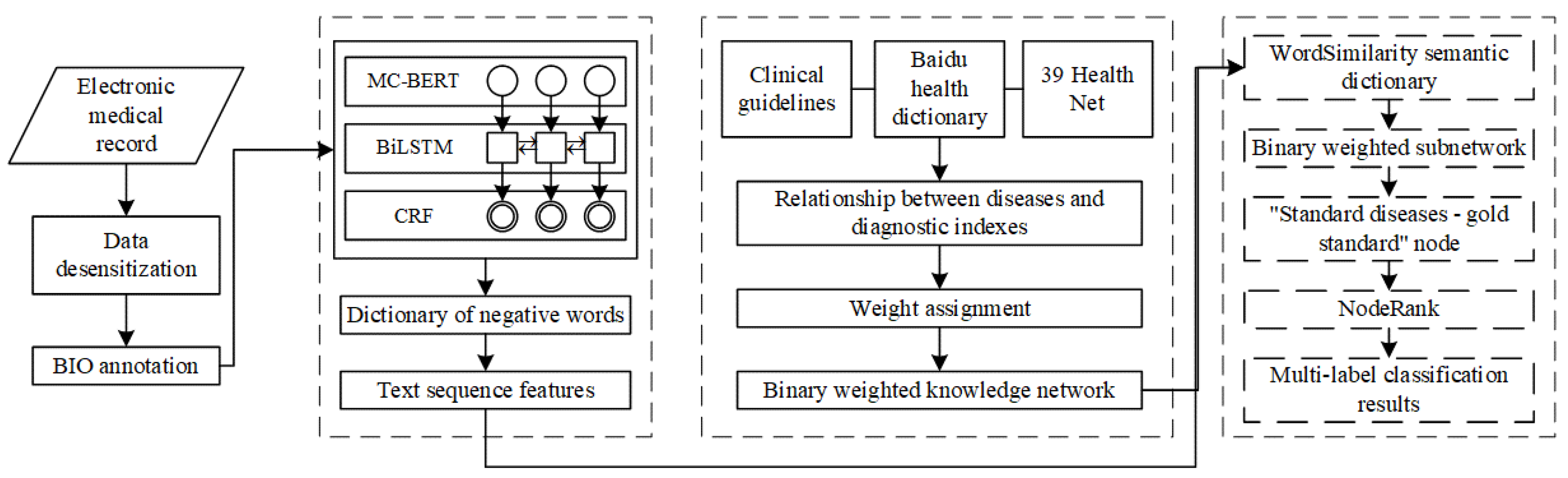
2.2.1. Overview of DLKN-MLC Model
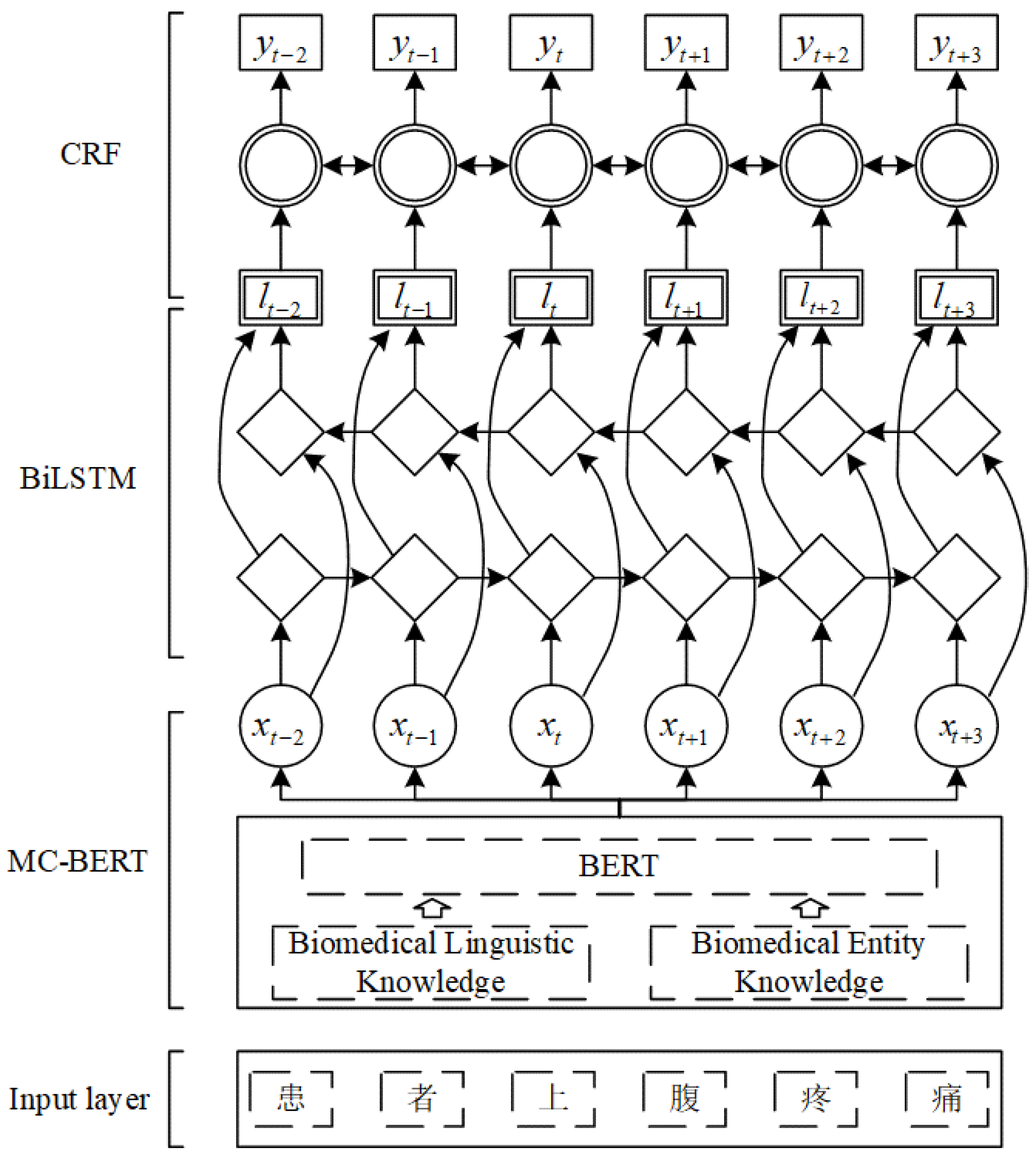
2.2.2. DL-Based Text Sequence Feature Extraction
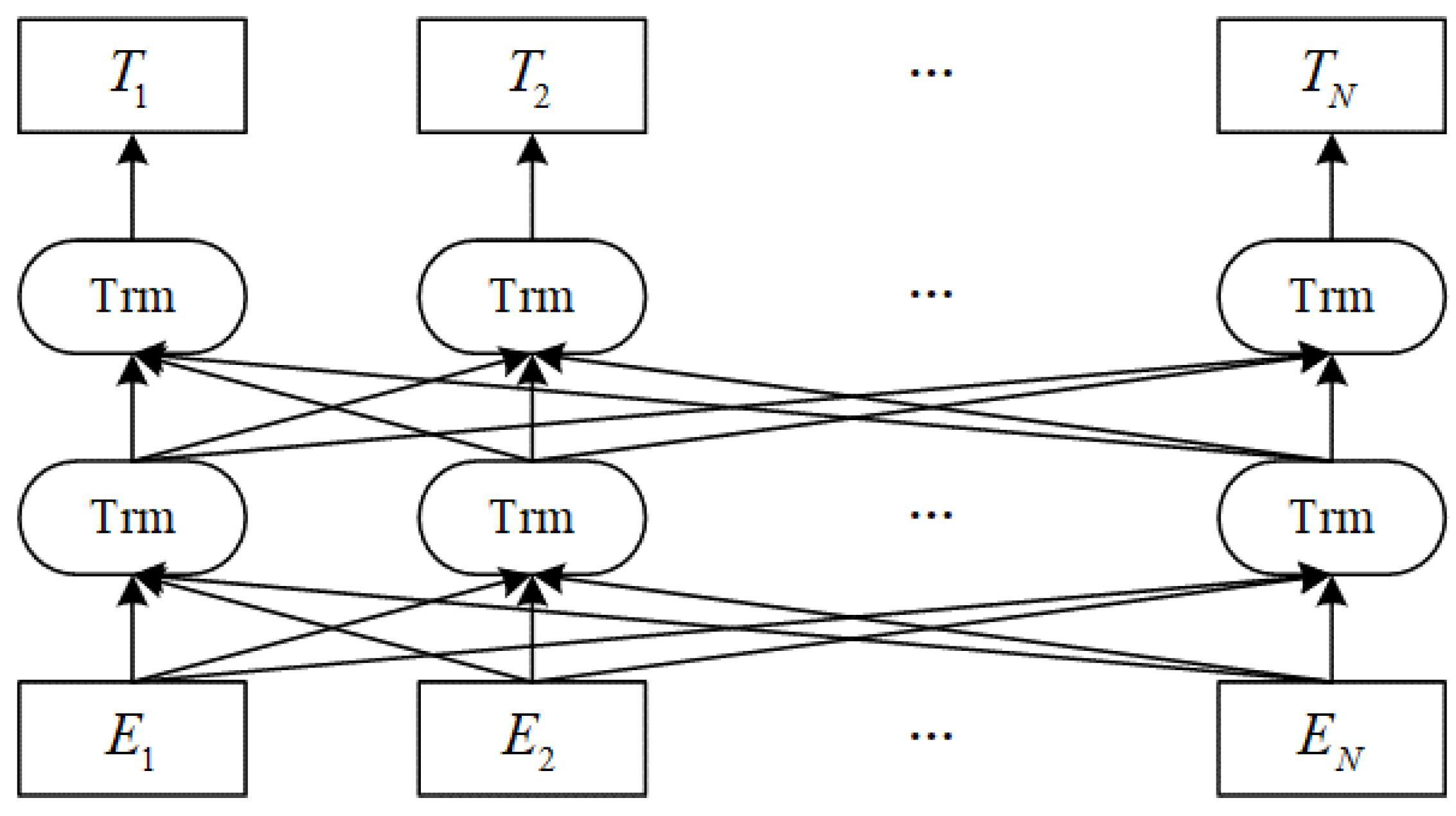
MC-BERT
BiLSTM
CRF
2.2.3. Construction of Binary-Weighted Disease KN
2.2.4. MLC Based on NodeRank
3. Results
3.1. Evaluation Metrics
3.2. Comparison Results of Different Weighting Values
3.3. Experimental Results
4. Discussion
4.1. Influence of Different Weights on Model Performance
4.2. Comparison Algorithm Selection
4.3. Analysis of Comparison Model Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, Q.; Liu, Y.; Liu, G.; Zhao, G.; Qu, Z.; Yang, W. An automatic diagnostic system based on deep learning, to diagnose hyperlipidemia. Diabetes Metab. Syndr. Obes. Targets Ther. 2019, 12, 637. [Google Scholar] [CrossRef] [Green Version]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Bright, T.J.; Wong, A.; Dhurjati, R.; Bristow, E.; Bastian, L.; Coeytaux, R.R.; Samsa, G.; Hasselblad, V.; Williams, J.W.; Musty, M.D. Effect of clinical decision-support systems: A systematic review. Ann. Intern. Med. 2012, 157, 29–43. [Google Scholar] [CrossRef] [PubMed]
- Gui, H.; Tseng, B.; Hu, W.; Wang, S.Y. Looking for low vision: Predicting visual prognosis by fusing structured and free-text data from electronic health records. Int. J. Med. Inform. 2022, 159, 104678. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Yin, H.; Chen, H.; Chen, T.; Cui, L.; Yang, F. Disease prediction via graph neural networks. IEEE J. Biomed. Health Inform. 2020, 25, 818–826. [Google Scholar] [CrossRef] [PubMed]
- Han, H.; Huang, M.; Zhang, Y.; Yang, X.; Feng, W. Multi-label learning with label specific features using correlation information. IEEE Access 2019, 7, 11474–11484. [Google Scholar] [CrossRef]
- Lv, J.; Wu, T.; Peng, C.; Liu, Y.; Xu, N.; Geng, X. Compact learning for multi-label classification. Pattern Recognit. 2021, 113, 107833. [Google Scholar] [CrossRef]
- Luaces, O.; Díez, J.; Barranquero, J.; del Coz, J.J.; Bahamonde, A. Binary relevance efficacy for multilabel classification. Prog. Artif. Intell. 2012, 1, 303–313. [Google Scholar] [CrossRef] [Green Version]
- Sim, J.-K.; Kim, G.H.; Choi, M.-T. Binary-Relevance Classification of Depression and Anxiety in the Elderly Using Low-Cost Activity Trackers. J. Med. Imaging Health Inform. 2020, 10, 1423–1428. [Google Scholar] [CrossRef]
- Liu, W.; Tsang, I. On the optimality of classifier chain for multi-label classification. In Advances in Neural Information Processing Systems 28; Neural Information Processing Systems: La Jolla, CA, USA, 2015. [Google Scholar]
- Read, J.; Pfahringer, B.; Holmes, G.; Frank, E. Classifier chains for multi-label classification. Mach. Learn. 2011, 85, 333–359. [Google Scholar] [CrossRef] [Green Version]
- Boutell, M.R.; Luo, J.; Shen, X.; Brown, C.M. Learning multi-label scene classification. Pattern Recognit. 2004, 37, 1757–1771. [Google Scholar] [CrossRef] [Green Version]
- Tsoumakas, G.; Katakis, I. Multi-label classification: An overview. Int. J. Data Warehous. Min. 2007, 3, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Gao, S.; Wu, W.; Lee, C.-H.; Chua, T.-S. A MFoM learning approach to robust multiclass multi-label text categorization. In Proceedings of the Twenty-First International Conference on Machine Learning, New York, NY, USA, 4–8 July 2004; p. 42. [Google Scholar]
- Xu, Y.; Yang, Y.; Wang, Z.; Shao, Y. Prediction of Acetylation and Succinylation in Proteins Based on Multilabel Learning RankSVM. Lett. Org. Chem. 2019, 16, 275–282. [Google Scholar] [CrossRef]
- Zhou, Y.; Ji, Z.; Wang, K. A Parallel Decision Tree Based Algorithm on MPI for Multi-label Classification Learning. In Proceedings of the 2nd International Conference on Control, Automation and Artificial Intelligence (CAAI 2017), Sanya, China, 25–26 June 2017; Atlantis Press: Amsterdam, The Netherlands, 2017; pp. 366–369. [Google Scholar]
- Shi, C.; Kong, X.; Yu, P.S.; Wang, B. Multi-label ensemble learning. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Bilbao, Spain, 13–17 September 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 223–239. [Google Scholar]
- Nam, J.; Kim, J.; Loza Mencía, E.; Gurevych, I.; Fürnkranz, J. Large-scale multi-label text classification—Revisiting neural networks. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Nancy, France, 15–19 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 437–452. [Google Scholar]
- Yang, P.; Sun, X.; Li, W.; Ma, S.; Wu, W.; Wang, H. SGM: Sequence generation model for multi-label classification. arXiv 2018, arXiv:1806.04822. [Google Scholar]
- Gong, J.; Teng, Z.; Teng, Q.; Zhang, H.; Du, L.; Chen, S.; Bhuiyan, M.Z.A.; Li, J.; Liu, M.; Ma, H. Hierarchical graph transformer-based deep learning model for large-scale multi-label text classification. IEEE Access 2020, 8, 30885–30896. [Google Scholar] [CrossRef]
- Lin, J.; Su, Q.; Yang, P.; Ma, S.; Sun, X. Semantic-unit-based dilated convolution for multi-label text classification. arXiv 2018, arXiv:1808.08561. [Google Scholar]
- Yang, P.; Luo, F.; Ma, S.; Lin, J.; Sun, X. A deep reinforced sequence-to-set model for multi-label classification. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5252–5258. [Google Scholar]
- Fan, S.; Zhao, Y.; An, X.; Wu, Q. Research on medical entity relationship classification model based on convolution neural network. Data Anal. Knowl. Discov. 2021, 5, 75–84. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zhang, N.; Jia, Q.; Yin, K.; Dong, L.; Gao, F.; Hua, N. Conceptualized representation learning for Chinese biomedical text mining. arXiv 2020, arXiv:2008.10813. [Google Scholar]
- Sundermeyer, M.; Alkhouli, T.; Wuebker, J.; Ney, H. Translation modeling with bidirectional recurrent neural networks. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 14–25. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Duarte, F.; Martins, B.; Pinto, C.S.; Silva, M.J. Deep neural models for ICD-10 coding of death certificates and autopsy reports in free-text. J. Biomed. Inform. 2018, 80, 64–77. [Google Scholar] [CrossRef] [PubMed]
- Lafferty, J.; Mccallum, A.; Pereira, F. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the 18th International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001. [Google Scholar]
- Dun, X.; Zhang, Y.; Yang, K. Fine—Grained emotion analysis based on microblog Data analysis and knowledge discovery. Data Anal. Knowl. Discov. 2017, 1, 61–72. [Google Scholar]
- Chen, W.; Lin, X.; Yin, Z. Research on multi tag emotion prediction based on neural network fusion tag correlation. Chin. J. Inf. 2021, 35, 104–112. [Google Scholar]
- Wang, J.; Zhao, J.; Zhang, C.; Zhang, Y.; Jiang, N.; Wei, X.; Wang, J.; Yu, J. Comorbidity, lifestyle factors, and sexual satisfaction among Chinese cancer survivors. Cancer Med. 2021, 10, 6058–6069. [Google Scholar] [CrossRef]
- Jia, J. Research on the Mechanism of Rare Diseases Based on Multiomics Integration and Network Analysis. Ph.D. Thesis, East China Normal University, Shanghai, China, 2019. [Google Scholar]
- Li, P.; Qiu, X. NodeRank: An algorithm to assess state enumeration attack graphs. In Proceedings of the 8th International Conference on Wireless Communications, Networking and Mobile Computing, Limassol, Cyprus, 27–31 August 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1–5. [Google Scholar]
- Zhou, L.; Lin, J. Research on product feature extraction based on noderank algorithm. Data Anal. Knowl. Discov. 2018, 2, 90–98. [Google Scholar]
- Azarbonyad, H.; Dehghani, M.; Marx, M.; Kamps, J. Learning to rank for multi-label text classification: Combining different sources of information. Nat. Lang. Eng. 2021, 27, 89–111. [Google Scholar] [CrossRef] [Green Version]
- Sorower, M.S. A Literature Survey on Algorithms for Multi-Label Learning; Oregon State University: Corvallis, OR, USA, 2010; Volume 18, pp. 1–25. [Google Scholar]
- Tsoumakas, G.; Katakis, I.; Vlahavas, I. Mining multi-label data. In Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2009; pp. 667–685. [Google Scholar]
- Zhang, M.-L.; Zhou, Z.-H. A review on multi-label learning algorithms. IEEE Trans. Knowl. Data Eng. 2013, 26, 1819–1837. [Google Scholar] [CrossRef]
- Zhang, Y.; Wallace, B. A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification. arXiv 2015, arXiv:1510.03820. [Google Scholar]
- Chen, G.; Ye, D.; Xing, Z.; Chen, J.; Cambria, E. Ensemble application of convolutional and recurrent neural networks for multi-label text categorization. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, Alaska, 14–19 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2377–2383. [Google Scholar]
- Chang, W.-C.; Yu, H.-F.; Zhong, K.; Yang, Y.; Dhillon, I.S. Taming pretrained transformers for extreme multi-label text classification. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020; pp. 3163–3171. [Google Scholar]
- Li, T.; Zhang, B.; Lv, H.; Hu, S.; Xu, Z.; Tuergong, Y. CAttSleepNet: Automatic End-to-End Sleep Staging Using Attention-Based Deep Neural Networks on Single-Channel EEG. Int. J. Environ. Res. Public Health 2022, 19, 5199. [Google Scholar] [CrossRef]
- Zhou, L.; Meng, X.; Huang, Y.; Kang, K.; Zhou, J.; Chu, Y.; Li, H.; Xie, D.; Zhang, J.; Yang, W. An interpretable deep learning workflow for discovering subvisual abnormalities in CT scans of COVID-19 inpatients and survivors. Nat. Mach. Intell. 2022, 4, 494–503. [Google Scholar] [CrossRef]
- Devnath, L.; Summons, P.; Luo, S.; Wang, D.; Shaukat, K.; Hameed, I.A.; Aljuaid, H. Computer-Aided Diagnosis of Coal Workers’ Pneumoconiosis in Chest X-ray Radiographs Using Machine Learning: A Systematic Literature Review. Int. J. Environ. Res. Public Health 2022, 19, 6439. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Environment | Experimental Configuration |
|---|---|
| GPU | GTX 1050TI |
| CPU | E5-2678V3 |
| Development environment | Python3.7.3 TensorFlow1.15.2 |
| Epoch | 20 |
| Optimizer | Adam |
| LSTM learning rate | 0.001 |
| Dropout | 0.5 |
| Confusion Matrix | Predictive Value | ||
|---|---|---|---|
| Positive | Negative | ||
| Actual value | Positive | TP | FN |
| Negative | FP | TN | |
| Group | <113> | <123> | <135> | <137> | <139> |
|---|---|---|---|---|---|
| occasional clinical manifestations | 1 | 1 | 1 | 1 | 1 |
| common clinical manifestations | 1 | 2 | 3 | 3 | 3 |
| auxiliary diagnostic results | 3 | 3 | 5 | 7 | 9 |
| HL↓ | OE↓ | RL↓ | AP↑ | Micro-F1↑ | |
|---|---|---|---|---|---|
| <113> | 0.3076 ± 0.005634 | 0.2412 ± 0.008233 | 0.3153 ± 0.009842 | 0.8623 ± 0.005285 | 0.8496 ± 0.003933 |
| <123> | 0.2966 ± 0.005754 | 0.2357 ± 0.009018 | 0.2962 ± 0.009632 | 0.8642 ± 0.005021 | 0.8522 ± 0.003828 |
| <135> | 0.2687 ± 0.004982 | 0.2257 ± 0.008721 | 0.2276 ± 0.010223 | 0.8786 ± 0.004692 | 0.8672 ± 0.003468 |
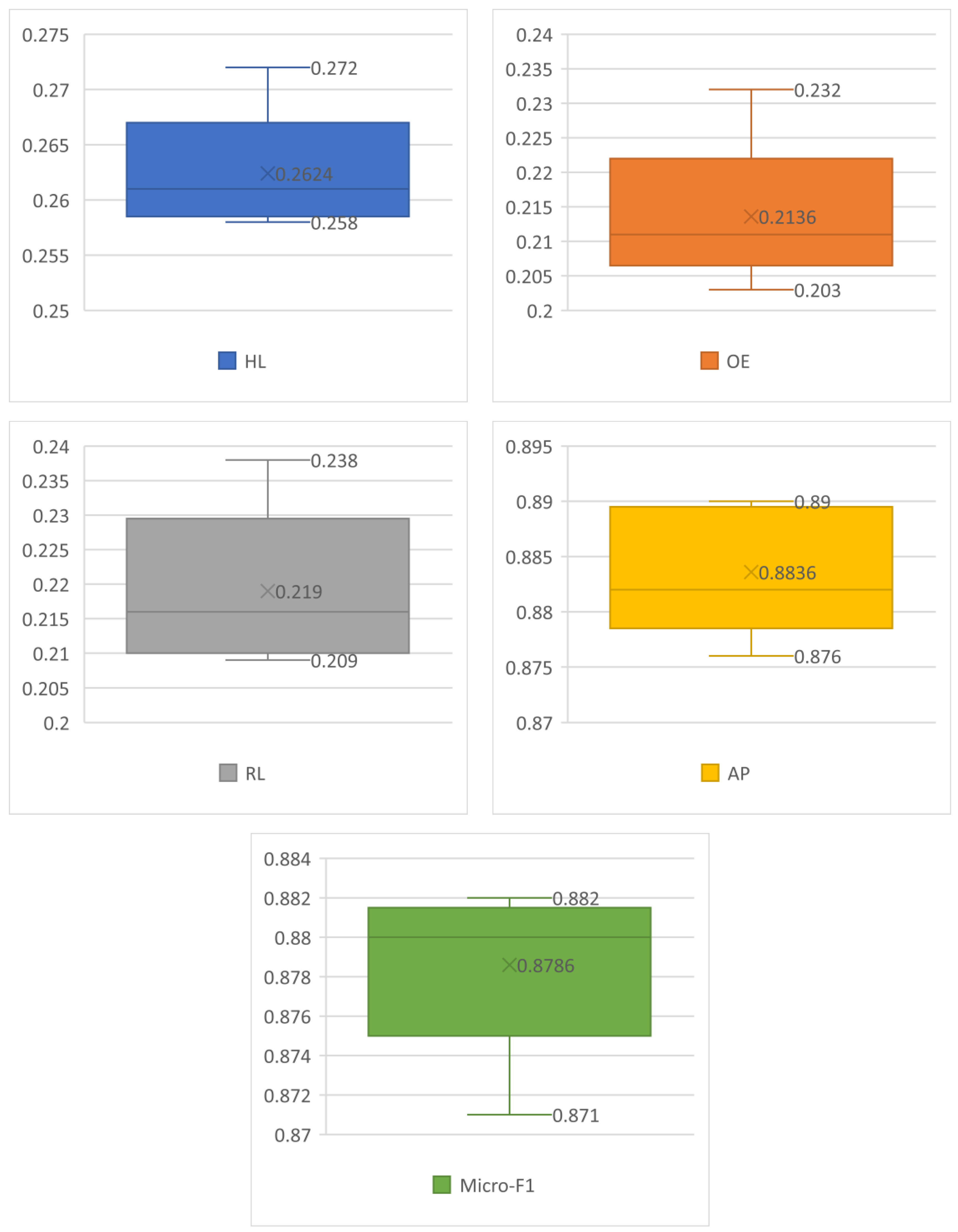
| <137> | 0.2624 ± 0.005004 | 0.2136 ± 0.009728 | 0.2190 ± 0.010373 | 0.8821 ± 0.004782 | 0.8786 ± 0.003587 |
| <139> | 0.2695 ± 0.005229 | 0.2085 ± 0.009536 | 0.2162 ± 0.010648 | 0.8754 ± 0.004724 | 0.8654 ± 0.003622 |
| Comparison Model | Model Description |
|---|---|
| Text-CNN | On the basis of CNN, many sliding windows of different sizes are added, and the feature extraction is carried out by a convolution kernel. |
| CNN-RNN | CNN and RNN are combined to extract the local features of the text, and RNN is used to obtain the sequence features and high-order tag correlation of the text. |
| X-BERT | At the same time, tags and input text are used to generate semantic tag clusters to make better use of the dependency relationship between tags for modeling. |
| HL↓ | OE↓ | RL↓ | AP↑ | Micro-F1↑ | |
|---|---|---|---|---|---|
| Text-CNN | 0.3672 ± 0.009621 | 0.3112 ± 0.008635 | 0.2922 ± 0.013585 | 0.7838 ± 0.005145 | 0.7838 ± 0.005785 |
| CNN–RNN | 0.2914 ± 0.006888 | 0.2598 ± 0.009537 | 0.2454 ± 0.008639 | 0.8204 ± 0.005848 | 0.8058 ± 0.007243 |
| X-BERT | 0.2788 ± 0.006675 | 0.2412 ± 0.006431 | 0.2494 ± 0.009972 | 0.8528 ± 0.007514 | 0.8362 ± 0.004946 |
| Our method | 0.2624 ± 0.005004 | 0.2136 ± 0.009728 | 0.2190 ± 0.010373 | 0.8821 ± 0.004782 | 0.8786 ± 0.003587 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, B.; Zhang, Y.; Wu, X. DLKN-MLC: A Disease Prediction Model via Multi-Label Learning. Int. J. Environ. Res. Public Health 2022, 19, 9771. https://doi.org/10.3390/ijerph19159771
Li B, Zhang Y, Wu X. DLKN-MLC: A Disease Prediction Model via Multi-Label Learning. International Journal of Environmental Research and Public Health. 2022; 19(15):9771. https://doi.org/10.3390/ijerph19159771
Chicago/Turabian StyleLi, Bocheng, Yunqiu Zhang, and Xusheng Wu. 2022. "DLKN-MLC: A Disease Prediction Model via Multi-Label Learning" International Journal of Environmental Research and Public Health 19, no. 15: 9771. https://doi.org/10.3390/ijerph19159771
APA StyleLi, B., Zhang, Y., & Wu, X. (2022). DLKN-MLC: A Disease Prediction Model via Multi-Label Learning. International Journal of Environmental Research and Public Health, 19(15), 9771. https://doi.org/10.3390/ijerph19159771