
Multi-Regional Modeling of Cumulative COVID-19 Cases Integrated with Environmental Forest Knowledge Estimation: A Deep Learning Ensemble Approach

 ,
,  , ,
, , 

Abstract
:1. Introduction
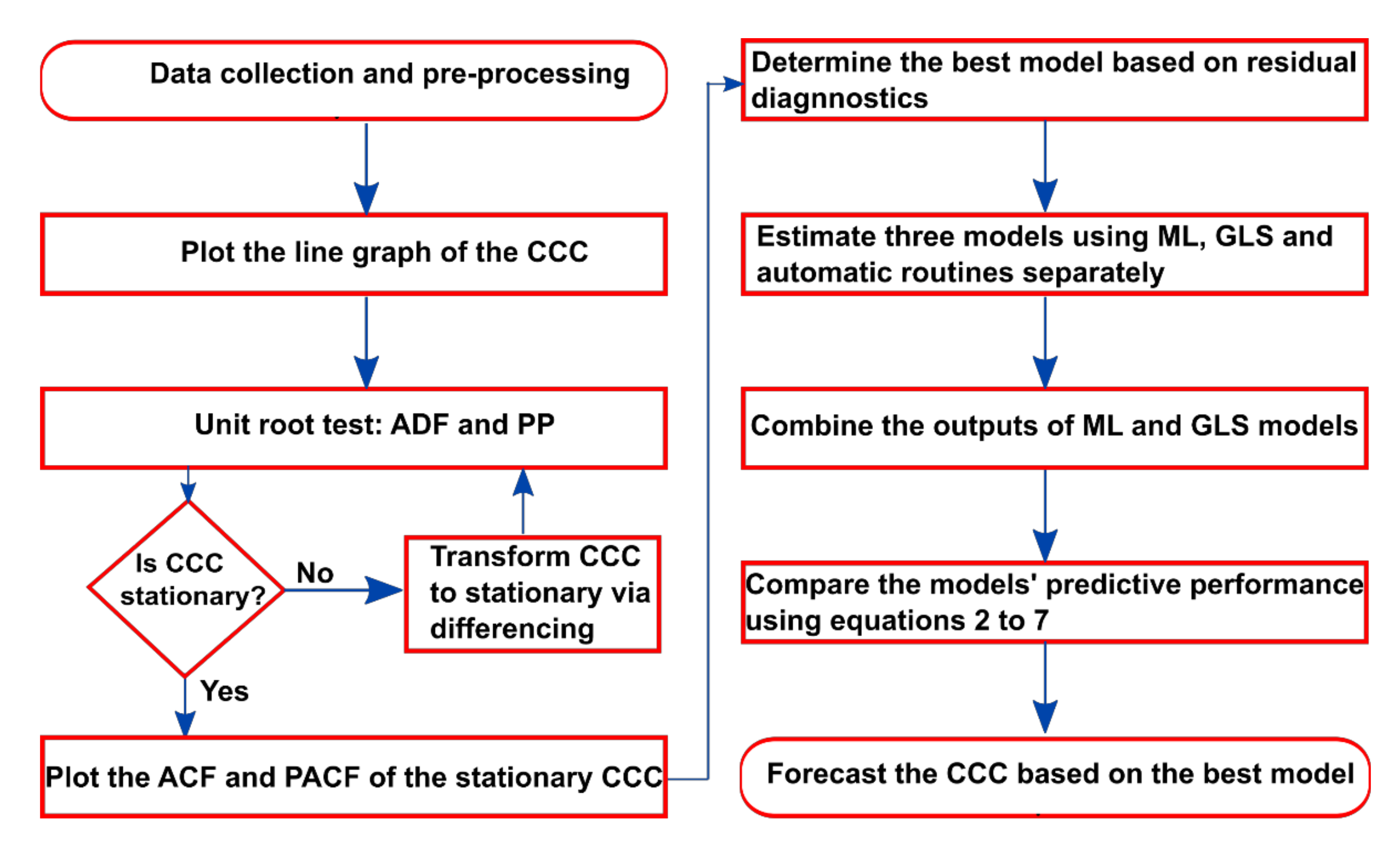
2. Materials and Methods
2.1. ARIMA Model
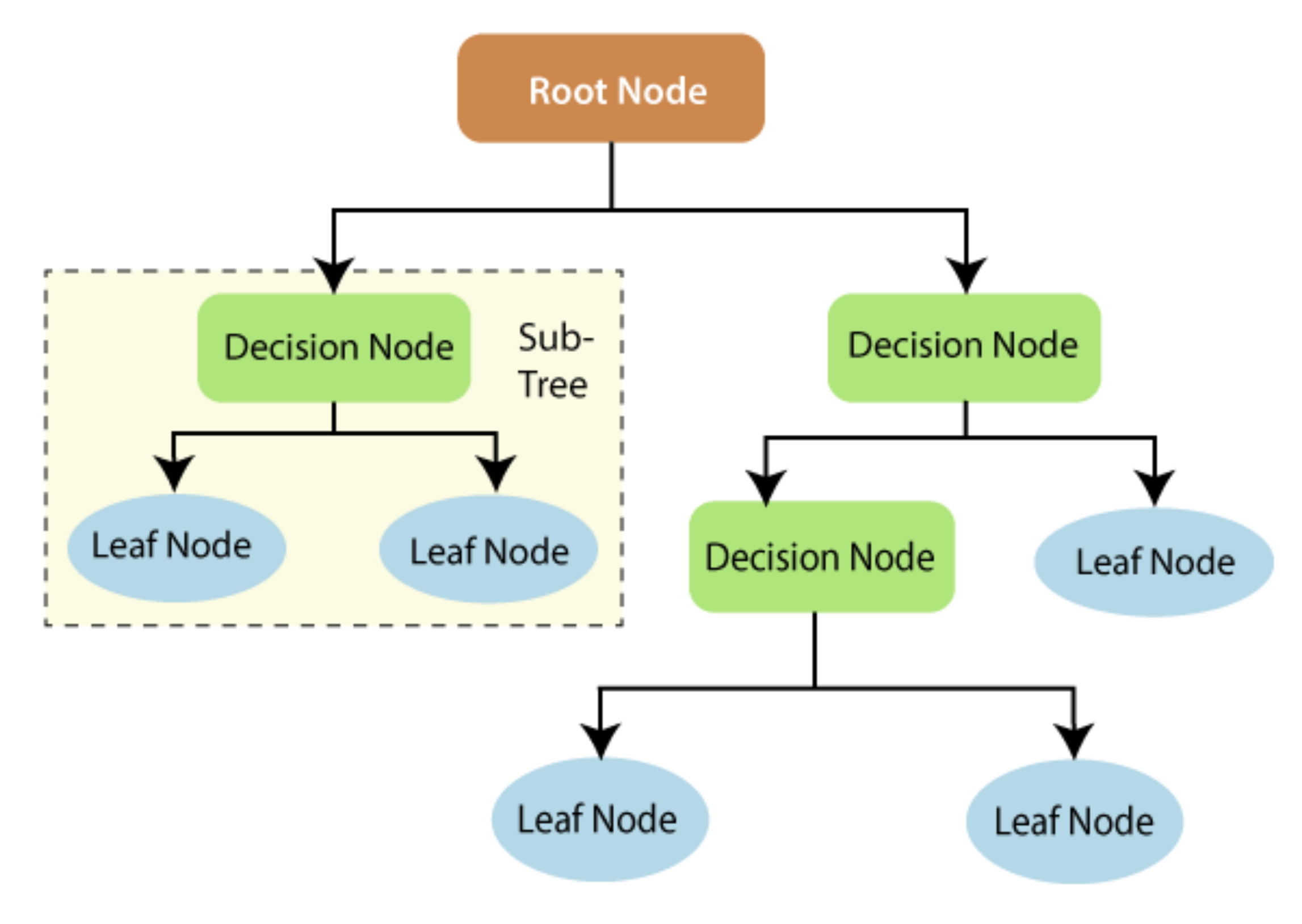
2.2. Random Forest (RF)
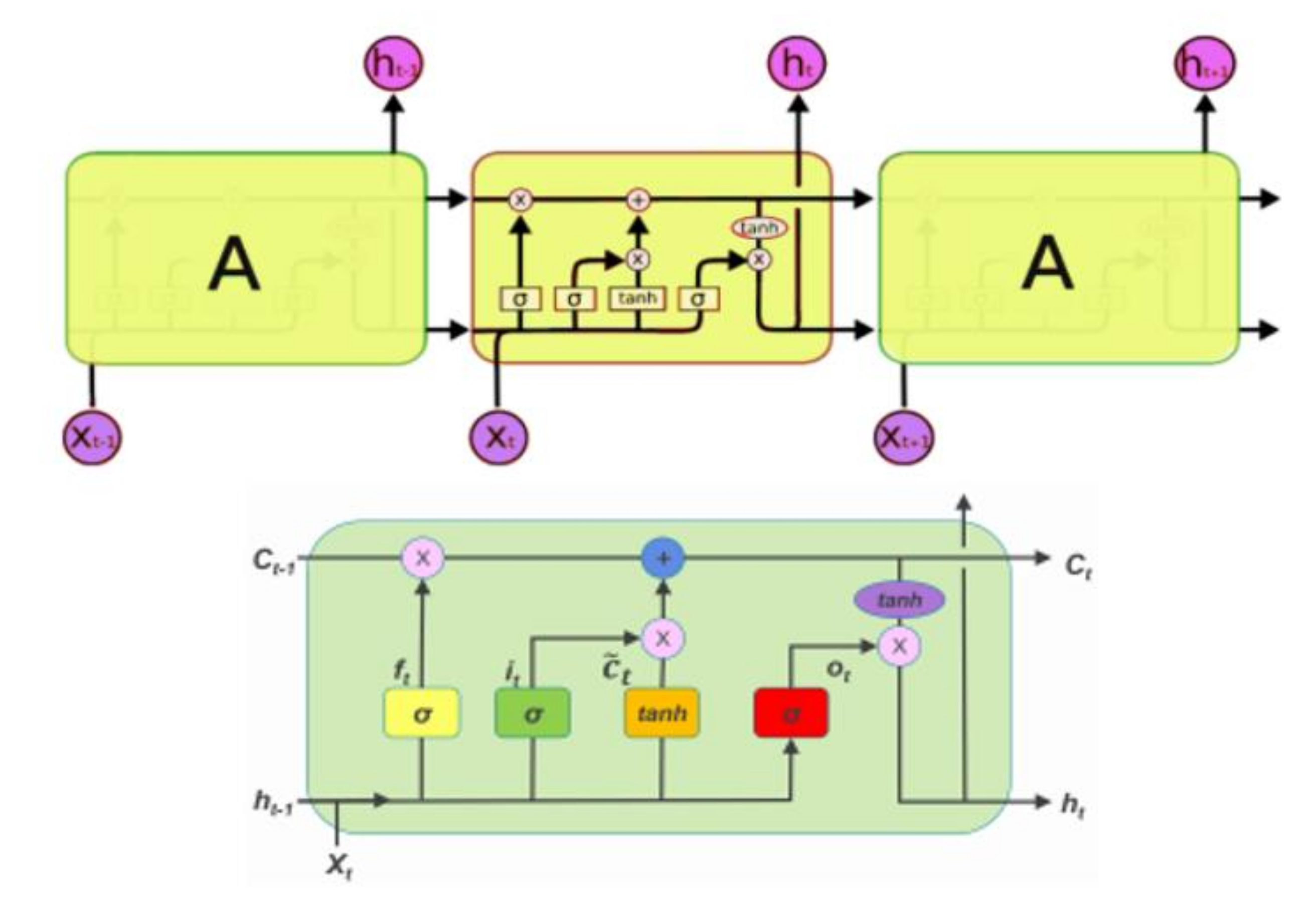
2.3. Long Short-Term Memory Neural Network (LSTM)
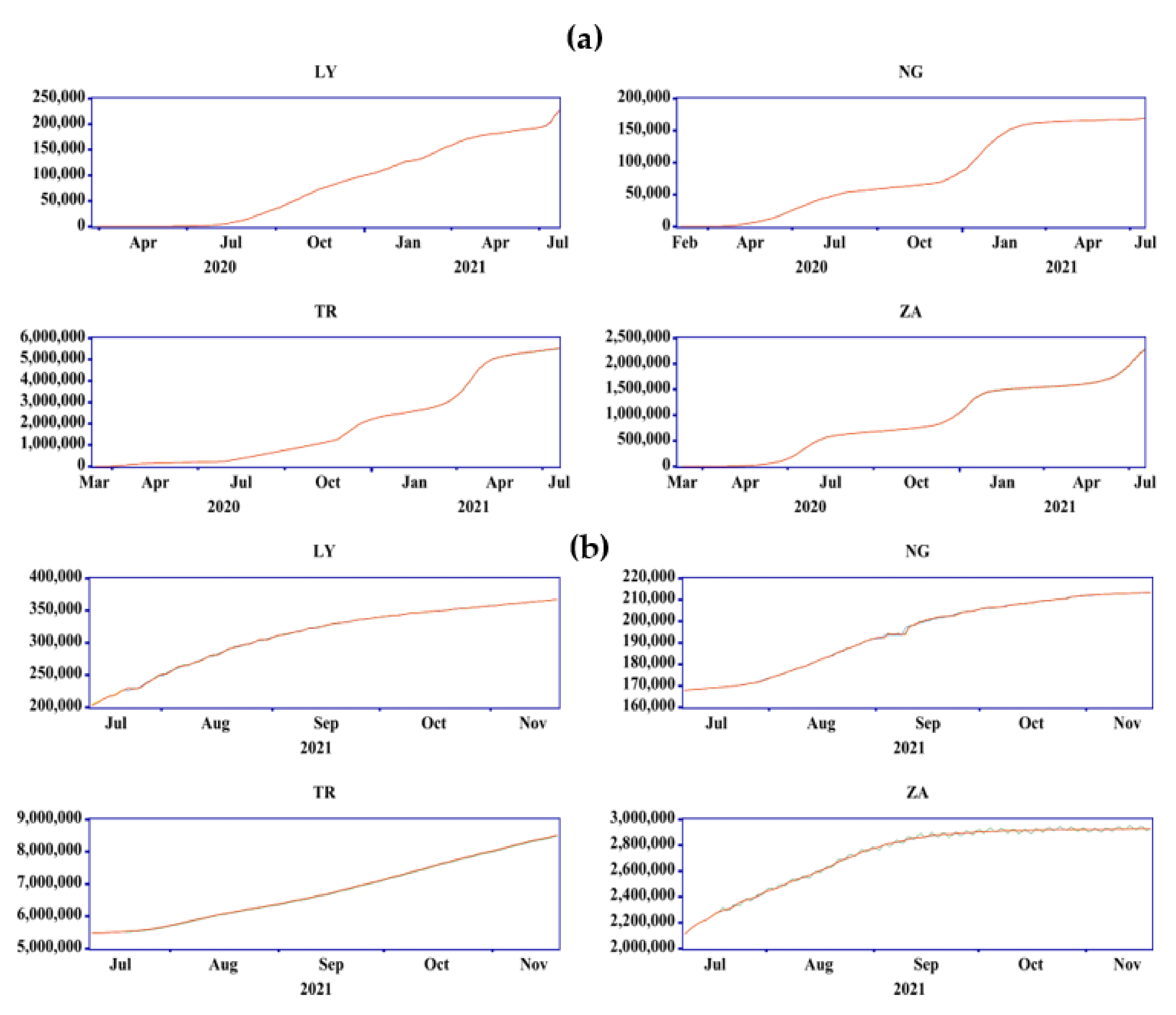
3. Data Processing and Validation
Evaluation Criteria
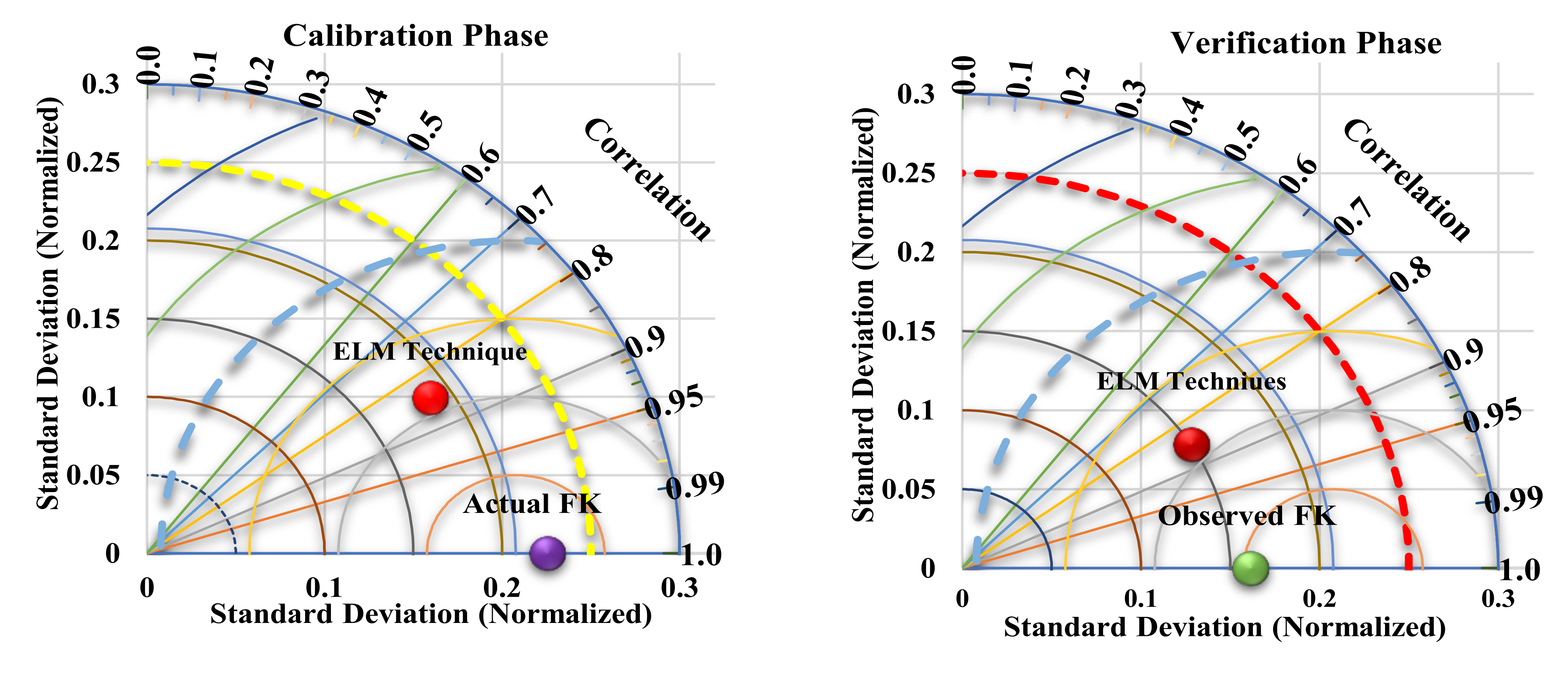
4. Results and Discussion
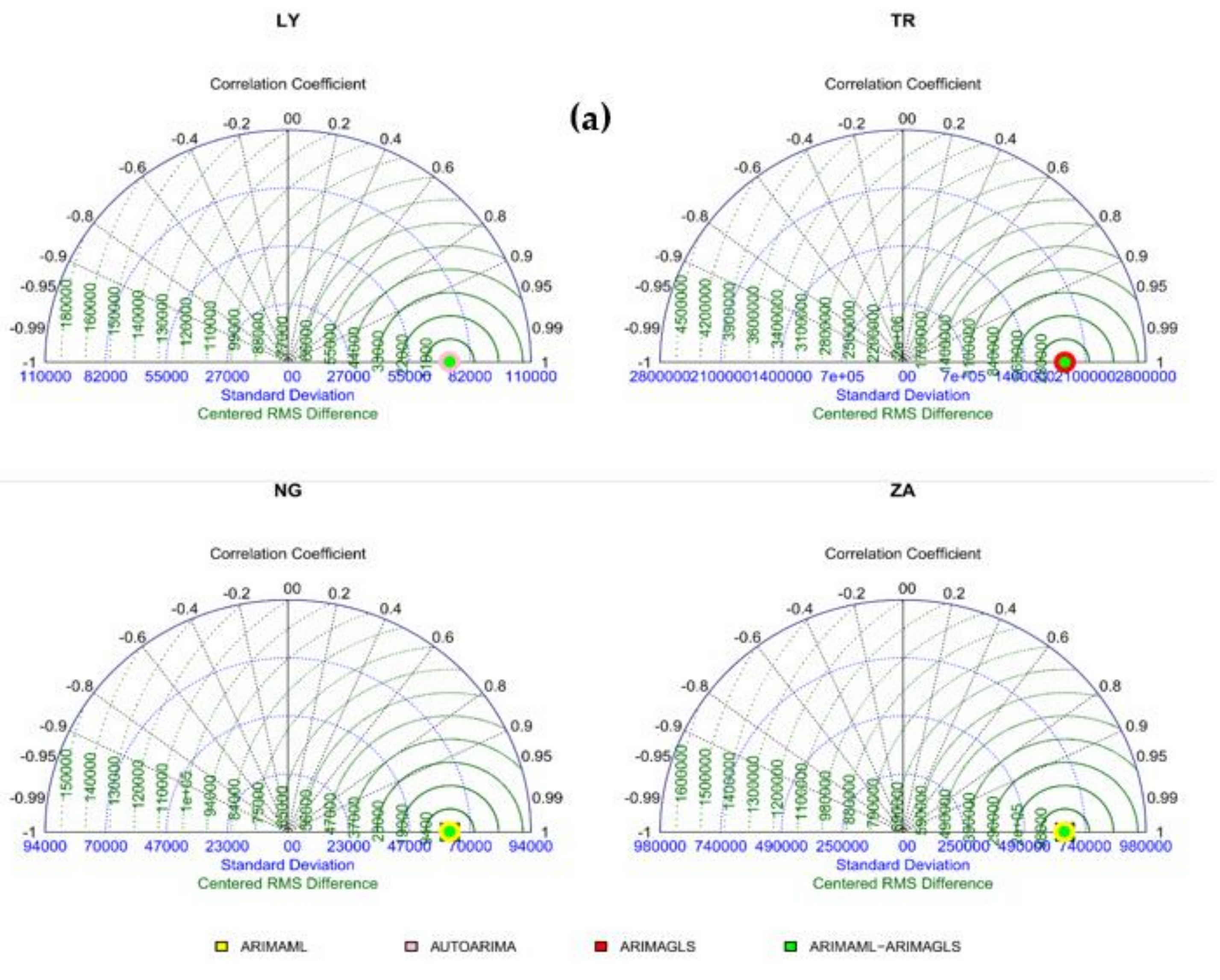
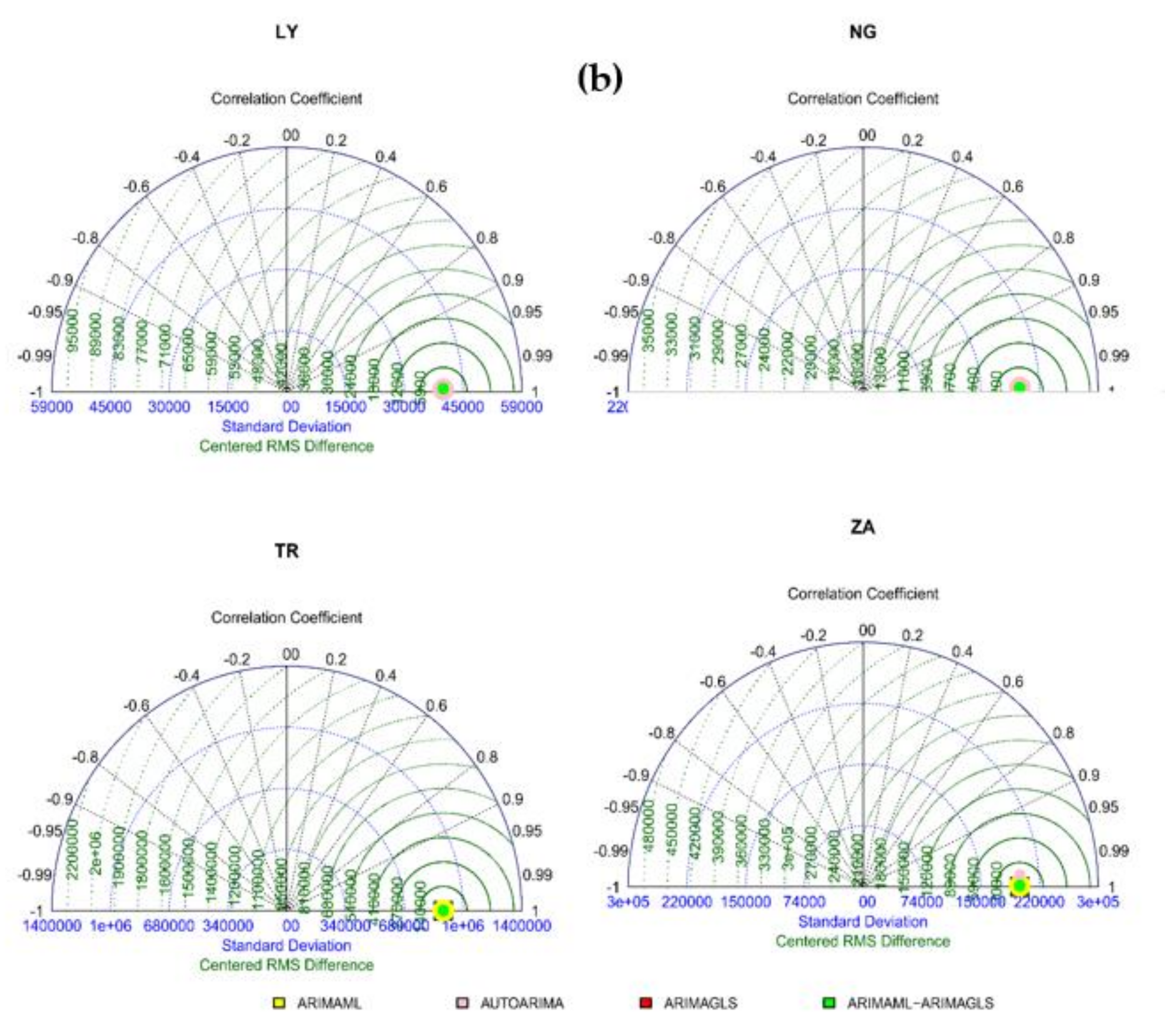
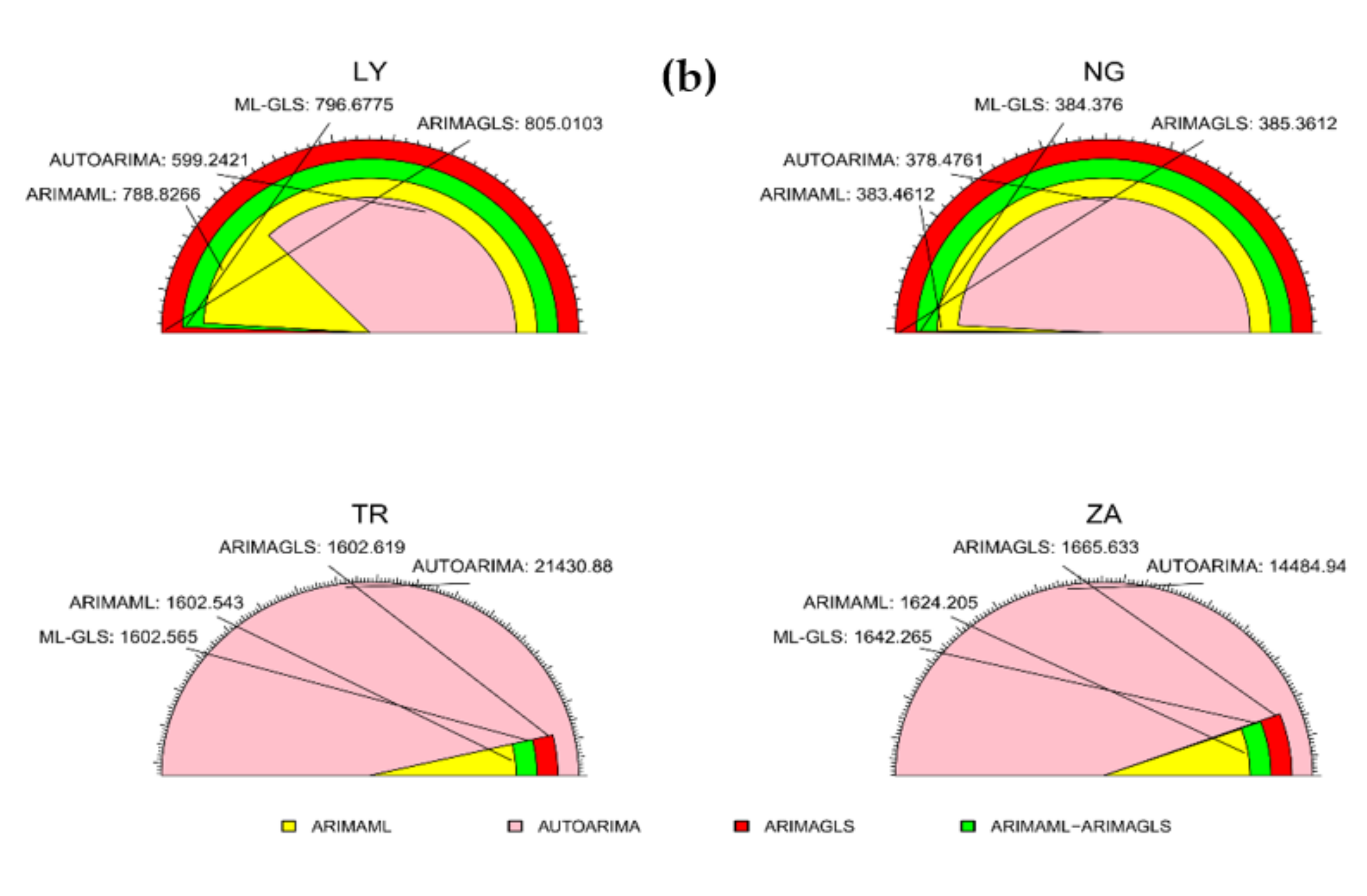
4.1. Result for Various Type of ARIMA
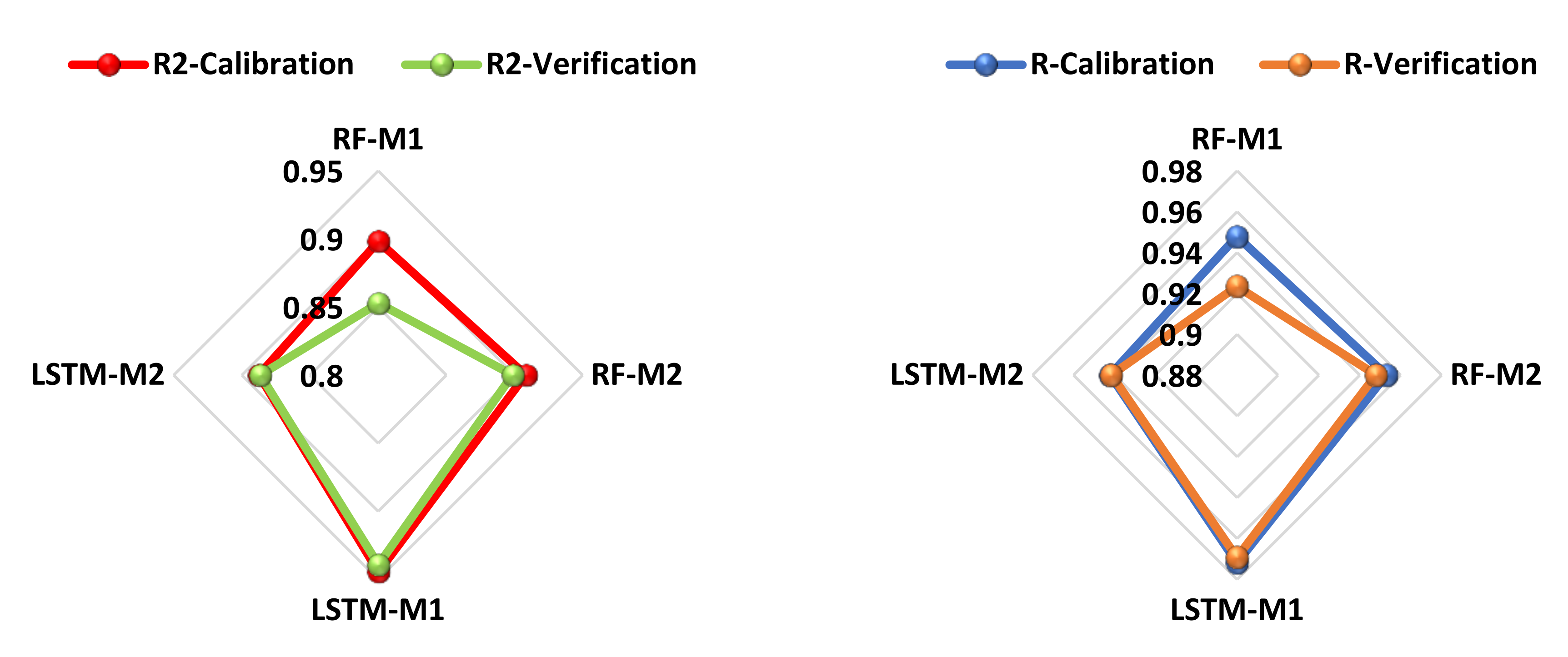
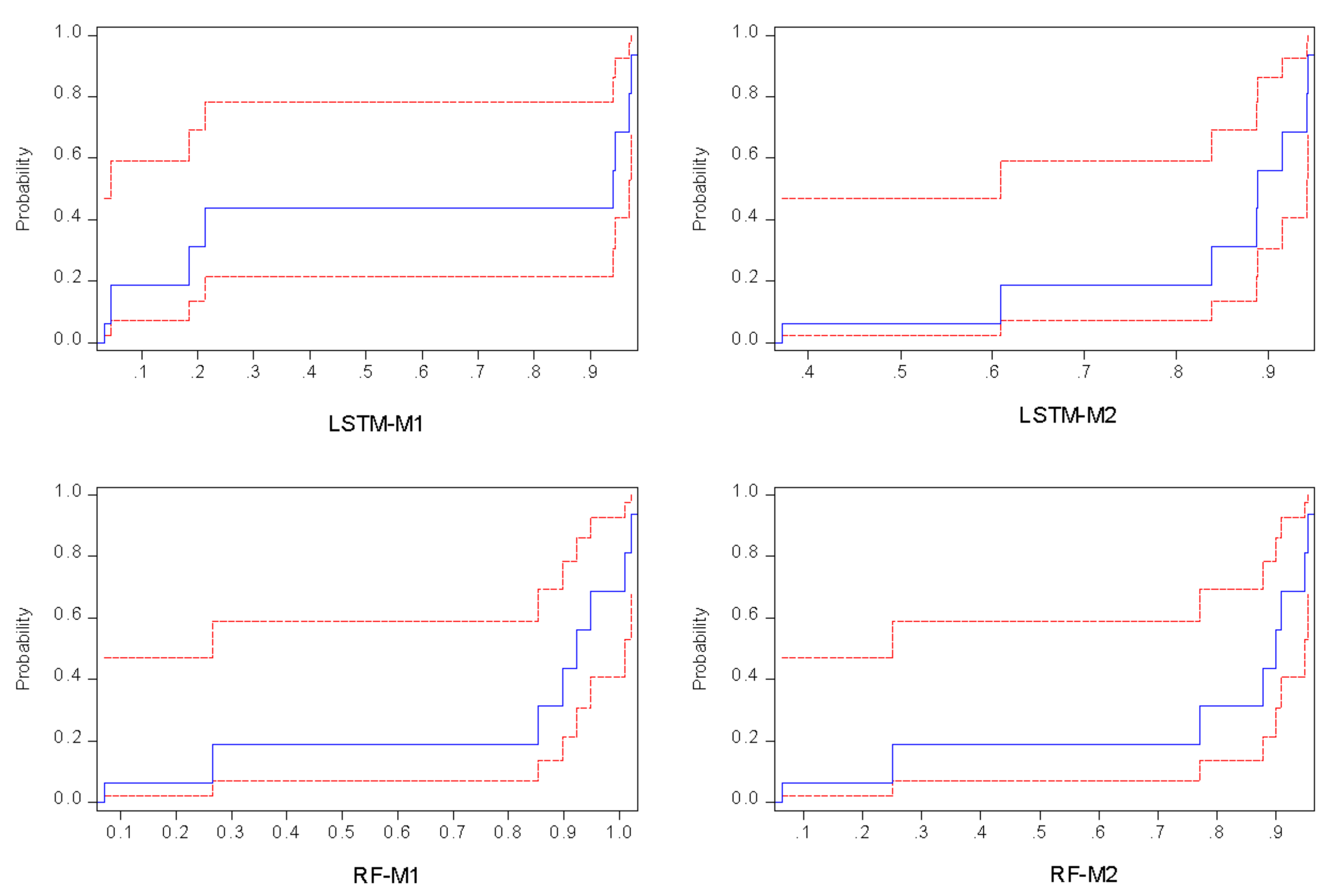
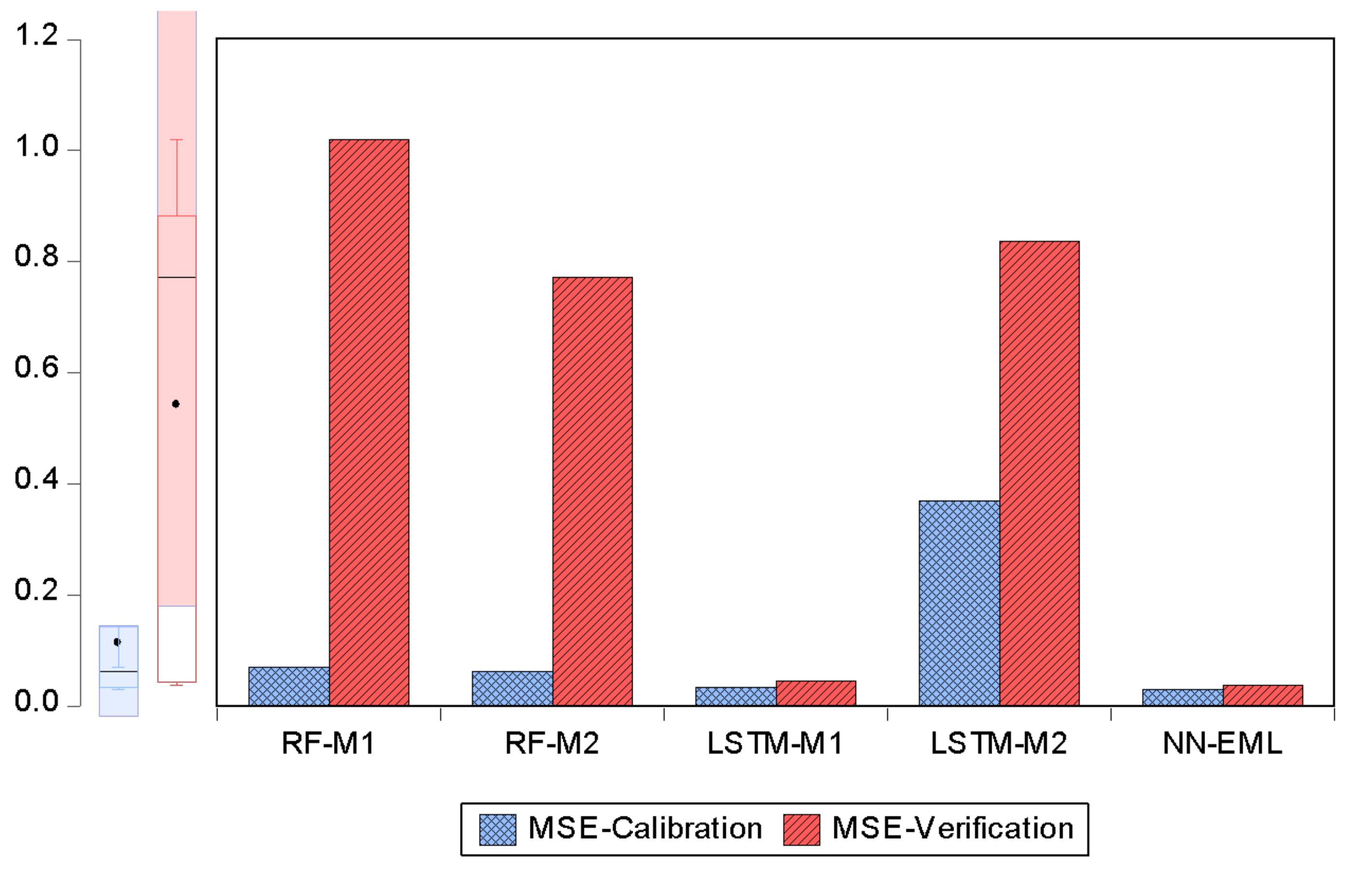
4.2. Result of Deep Learning Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lu, H.; Stratton, C.W.; Tang, Y.-W. Outbreak of pneumonia of unknown etiology in Wuhan, China: The mystery and the miracle. J. Med. Virol. 2020, 92, 401–402. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ajay, H.; Sahajal, D.; Inderpaul, S.; Ritesh Agarwal, S. Primary cavitary sarcoidosis: A case report, systematic review, and proposal of new diagnostic criteria. Lung India 2018, 35, 41–46. [Google Scholar] [CrossRef]
- Burki, T.K. Coronavirus in China. Lancet Respir. Med. 2020, 8, 238. [Google Scholar] [CrossRef]
- Yu, P.; Zhu, J.; Zhang, Z.; Han, Y. A Familial Cluster of Infection Associated With the 2019 Novel Coronavirus Indicating Possible Person-to-Person Transmission During the Incubation Period. J. Infect. Dis. 2020, 221, 1757–1761. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sohail, A.; Iftikhar, M.; Arif, R.; Ahmad, H.; Gepreel, K.A.; Iftikhar, S. Dengue control measures via cytoplasmic incompatibility and modern programming tools. Results Phys. 2021, 21, 103819. [Google Scholar] [CrossRef]
- Pang, N.T.P.; Kamu, A.; Kassim, M.A.M.; Ho, C.M. Monitoring the impact of Movement Control Order (MCO) in flattening the cummulative daily cases curve of Covid-19 in Malaysia: A generalized logistic growth modeling approach. Infect. Dis. Model. 2021, 6, 898–908. [Google Scholar] [CrossRef] [PubMed]
- ArunKumar, K.; Kalaga, D.V.; Kumar, C.M.S.; Chilkoor, G.; Kawaji, M.; Brenza, T.M. Forecasting the dynamics of cumulative COVID-19 cases (confirmed, recovered and deaths) for top-16 countries using statistical machine learning models: Auto-Regressive Integrated Moving Average (ARIMA) and Seasonal Auto-Regressive Integrated Moving Average (SARIMA). Appl. Soft Comput. 2021, 103, 107161. [Google Scholar] [CrossRef] [PubMed]
- Rostami-Tabar, B.; Rendon-Sanchez, J.F. Forecasting COVID-19 daily cases using phone call data. Appl. Soft Comput. 2021, 100, 106932. [Google Scholar] [CrossRef] [PubMed]
- Alabdulrazzaq, H.; Alenezi, M.N.; Rawajfih, Y.; Alghannam, B.A.; Al-Hassan, A.A.; Al-Anzi, F.S. On the accuracy of ARIMA based prediction of COVID-19 spread. Results Phys. 2021, 27, 104509. [Google Scholar] [CrossRef]
- Tang, Y.; Wang, S. Mathematic modeling of COVID-19 in the United States. Emerg. Microbes Infect. 2020, 9, 827–829. [Google Scholar] [CrossRef]
- Mati, S. Do as your neighbours do? Assessing the impact of lockdown and reopening on the active COVID-19 cases in Nigeria. Soc. Sci. Med. 2021, 270, 113645. [Google Scholar] [CrossRef]
- Shi, F.; Wang, J.; Shi, J.; Wu, Z.; Wang, Q.; Tang, Z.; He, K.; Shi, Y.; Shen, D. Review of Artificial Intelligence Techniques in Imaging Data Acquisition, Segmentation, and Diagnosis for COVID-19. IEEE Rev. Biomed. Eng. 2021, 14, 4–15. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, L.; Li, Z.; Zhou, J.; Li, H.; Chen, Y.; Huang, Y.; Xie, D.; Zhao, L.; Fan, M.; Hashmi, S.; et al. A Rapid, Accurate and Machine-Agnostic Segmentation and Quantification Method for CT-Based COVID-19 Diagnosis. IEEE Trans. Med. Imaging 2020, 39, 2638–2652. [Google Scholar] [CrossRef]
- Guleryuz, D. Forecasting outbreak of COVID-19 in Turkey; Comparison of Box–Jenkins, Brown’s exponential smoothing and long short-term memory models. Process. Saf. Environ. Prot. 2021, 149, 927–935. [Google Scholar] [CrossRef] [PubMed]
- Gong, Y. Advanced Bash-Scripting Guide An in-depth exploration of the art of shell scripting Table of Contents. Water Resour. Manag. 2013, 37, 2267–2274. [Google Scholar]
- Tiwari, M.K.; Adamowski, J. Urban water demand forecasting and uncertainty assessment using ensemble wavelet-bootstrap-neural network models. Water Resour. Res. 2013, 49, 6486–6507. [Google Scholar] [CrossRef]
- Pham, Q.B.; Gaya, M.; Abba, S.; Abdulkadir, R.; Esmaili, P.; Linh, N.T.T.; Sharma, C.; Malik, A.; Khoi, D.N.; Dung, T.D.; et al. Modelling of Bunus regional sewage treatment plant using machine learning approaches. Desalin. Water Treat. 2020, 203, 80–90. [Google Scholar] [CrossRef]
- Vandamme, J.-P.; Meskens, N.; Superby, J.-F. Predicting Academic Performance by Data Mining Methods. Educ. Econ. 2007, 15, 405–419. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, Y.; Zhang, X.; Ye, M.; Yang, J. Developing a Long Short-Term Memory (LSTM) based model for predicting water table depth in agricultural areas. J. Hydrol. 2018, 561, 918–929. [Google Scholar] [CrossRef]
- Pham, Q.B.; Abba, S.I.; Usman, A.G.; Linh, N.T.T.; Gupta, V.; Malik, A.; Costache, R.; Vo, N.D.; Tri, D.Q. Potential of Hybrid Data-Intelligence Algorithms for Multi-Station Modelling of Rainfall. Water Resour. Manag. 2019, 33, 5067–5087. [Google Scholar] [CrossRef]
- Wang, G.; Liu, X.; Li, C.; Xu, Z.; Ruan, J.; Zhu, H.; Meng, T.; Li, K.; Huang, N.; Zhang, S. A Noise-Robust Framework for Automatic Segmentation of COVID-19 Pneumonia Lesions from CT Images. IEEE Trans. Med. Imaging 2020, 39, 2653–2663. [Google Scholar] [CrossRef] [PubMed]
- Dickey, D.A.; Fuller, W.A. Distribution of the Estimators for Autoregressive Time Series with a Unit Root. J. Am. Stat. Assoc. 1979, 74, 427–431. [Google Scholar] [CrossRef]
- Musa, B.; Yimen, N.; Abba, S.I.; Adun, H.H.; Dagbasi, M. Multi-state load demand forecasting using hybridized support vector regression integrated with optimal design of off-grid energy Systems—A metaheuristic approach. Processes 2021, 9, 1166. [Google Scholar] [CrossRef]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Chichester, UK, 2015. [Google Scholar]
- Shi, X.Z.; Chen, Z.R.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28, 802–810. [Google Scholar]
- Liu, P.; Wang, J.; Sangaiah, A.K.; Xie, Y.; Yin, X. Analysis and Prediction of Water Quality Using LSTM Deep Neural Networks in IoT Environment. Sustainability 2019, 11, 2058. [Google Scholar] [CrossRef] [Green Version]
- Abba, S.; Hadi, S.J.; Sammen, S.S.; Salih, S.Q.; Abdulkadir, R.; Pham, Q.B.; Yaseen, Z.M. Evolutionary computational intelligence algorithm coupled with self-tuning predictive model for water quality index determination. J. Hydrol. 2020, 587, 124974. [Google Scholar] [CrossRef]
- Mubarak, A.; Esmaili, P.; Ameen, Z.; Abdulkadir, R.; Gaya, M.; Ozsoz, M.; Saini, G.; Abba, S. Metro-environmental data approach for the prediction of chemical oxygen demand in new Nicosia wastewater treatment plant. Desal. Water Treat. 2021, 221, 31–40. [Google Scholar] [CrossRef]
- Abba, S.I.; Linh, N.T.T.; Abdullahi, J.; Ali, S.I.A.; Pham, Q.B.; Abdulkadir, R.A.; Costache, R.; Anh, D.T. Hybrid machine learning ensemble techniques for modeling dissolved oxygen concentration. IEEE Access 2020, 8, 157218–157237. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 6, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hameed, H.I.A.; Seidu, R. Random forest tree for predicting fecal indicator organisms in drinking water supply. In Proceedings of the 2017 IEEE International Conference on Behavioral, Economic, Socio-cultural Computing (BESC), Krakow, Poland, 16–18 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Al-Mukhtar, M. Random forest, support vector machine, and neural networks to modelling suspended sediment in Tigris River-Baghdad. Environ. Monit. Assess. 2019, 191, 673. [Google Scholar] [CrossRef]
- Wunsch, A.; Liesch, T.; Broda, S. Groundwater Level Forecasting with Artificial Neural Networks: A Comparison of LSTM, CNN and NARX. Hydrol. Earth Syst. Sci. Discuss. 2020, 552, 1–23. [Google Scholar]
- Ismail, A.A.; Wood, T.; Bravo, H.C. Improving Long-Horizon Forecasts with Expectation-Biased LSTM NetWorks. 2018. Available online: http://arxiv.org/abs/1804.06776 (accessed on 10 November 2021).
- Zhang, D.; Hølland, E.S.; Lindholm, G.; Ratnaweera, H. Hydraulic modeling and deep learning based flow forecasting for optimizing inter catchment wastewater transfer. J. Hydrol. 2018, 567, 792–802. [Google Scholar] [CrossRef]
- Qin, H. Comparison of Deep Learning Models On Time Series Forecasting: A Case Study of Dissolved Oxygen Prediction. arXiv 2019, arXiv:1911.08414. [Google Scholar]
- Usman, A.G.; Işik, S.; Abba, S.I.; Meriçli, F. Chemometrics-based models hyphenated with ensemble machine learning for retention time simulation of isoquercitrin in Coriander sativum L. using high-performance liquid chromatography. J. Sep. Sci. 2021, 44, 843–849. [Google Scholar] [CrossRef]
- Abdullahi, H.U.; Usman, A.G.; Abba, S.I. Modelling the Absorbance of a Bioactive Compound in HPLC Method using Artificial Neural Network and Multilinear Regression Methods. DUJOPAS 2020, 6, 362–371. [Google Scholar]
- Toğa, G.; Atalay, B.; Toksari, M.D. COVID-19 prevalence forecasting using Autoregressive Integrated Moving Average (ARIMA) and Artificial Neural Networks (ANN): Case of Turkey. J. Infect. Public Health 2021, 14, 811–816. [Google Scholar] [CrossRef]
- Baba, M.N.; Makhtar, M.; Abdullah, S.; Awang, M.K. Current Issues in Ensemble Methods and its Ap-Plications. J. Theor. Appl. Inf. Technol. 2015, 81, 266–276. [Google Scholar]
- Nourani, V.; Elkiran, G.; Abba, S.I. Wastewater treatment plant performance analysis using artificial intelligence—An ensemble approach. Water Sci. Technol. 2018, 78, 2064–2076. [Google Scholar] [CrossRef] [PubMed]
- Kazienko, P.; Lughofer, E.; Trawiński, B. Hybrid and ensemble methods in machine learning J. UCS special issue. J. Univers. Comput. Sci. 2013, 19, 457–461. [Google Scholar]
- Abba, S.I.; Elkiran, G.; Nourani, V. Non-linear ensemble modeling for multi-step ahead prediction of treated cod in wastewater treatment plant. In Proceedings of the International Conference on Theory and Application of Soft Computing, Computing with Words and Perceptions; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Pham, Q.B.; Sammen, S.S.; Abba, S.I.; Mohammadi, B.; Shahid, S.; Abdulkadir, R.A. A new hybrid model based on relevance vector machine with flower pollination algorithm for phycocyanin pigment concentration estimation. Environ. Sci. Pollut. Res. 2021, 28, 32564–32579. [Google Scholar] [CrossRef]
- Abba, S.I.; Abdulkadir, R.A.; Sammen, S.S.; Usman, A.G.; Meshram, S.G.; Malik, A.; Shahid, S. Comparative implementation between neuro-emotional genetic algorithm and novel ensemble computing techniques for modelling dissolved oxygen concentration. Hydrol. Sci. J. 2021, 66, 1584–1596. [Google Scholar] [CrossRef]
- Sammen, S.S.; Ehteram, M.; Abba, S.I.; Abdulkadir, R.A.; Ahmed, A.N.; El-Shafie, A. A new soft computing model for daily streamflow forecasting. Stoch. Environ. Res. Risk Assess. 2021, 35, 2479–2491. [Google Scholar] [CrossRef]
- Abba, S.I.; Abdulkadir, R.A.; Sammen, S.S.; Pham, Q.B.; Lawan, A.A.; Esmaili, P.; Malik, A.; Al-Ansari, N. Integrating feature extraction approaches with hybrid emotional neural networks for water quality index modeling. Appl. Soft Comput. 2022, 114, 108036. [Google Scholar] [CrossRef]
- Shamshirband, S.; Esmaeilbeiki, F.; Zarehaghi, D.; Neyshabouri, M.; Samadianfard, S.; Ghorbani, M.A.; Mosavi, A.; Nabipour, N.; Chau, K.W. Comparative analysis of hybrid models of firefly optimization algorithm with support vector machines and multilayer perceptron for predicting soil temperature at different depths. Eng. Appl. Comput. Fluid Mech. 2020, 14, 939–953. [Google Scholar] [CrossRef]
- Taylor, K.E. Summarizing multiple aspects of model performance in a single diagram. J. Geophys. Res. 2001, 106, 7183–7192. [Google Scholar] [CrossRef]
- Areepong, Y.; Sunthornwat, R. Forecasting modeling of the number of cumulative COVID-19 cases with deaths and recoveries removal in Thailand. Sci. Eng. Health Stud. 2020, 15, 21020004. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N | ||||||
|---|---|---|---|---|---|---|
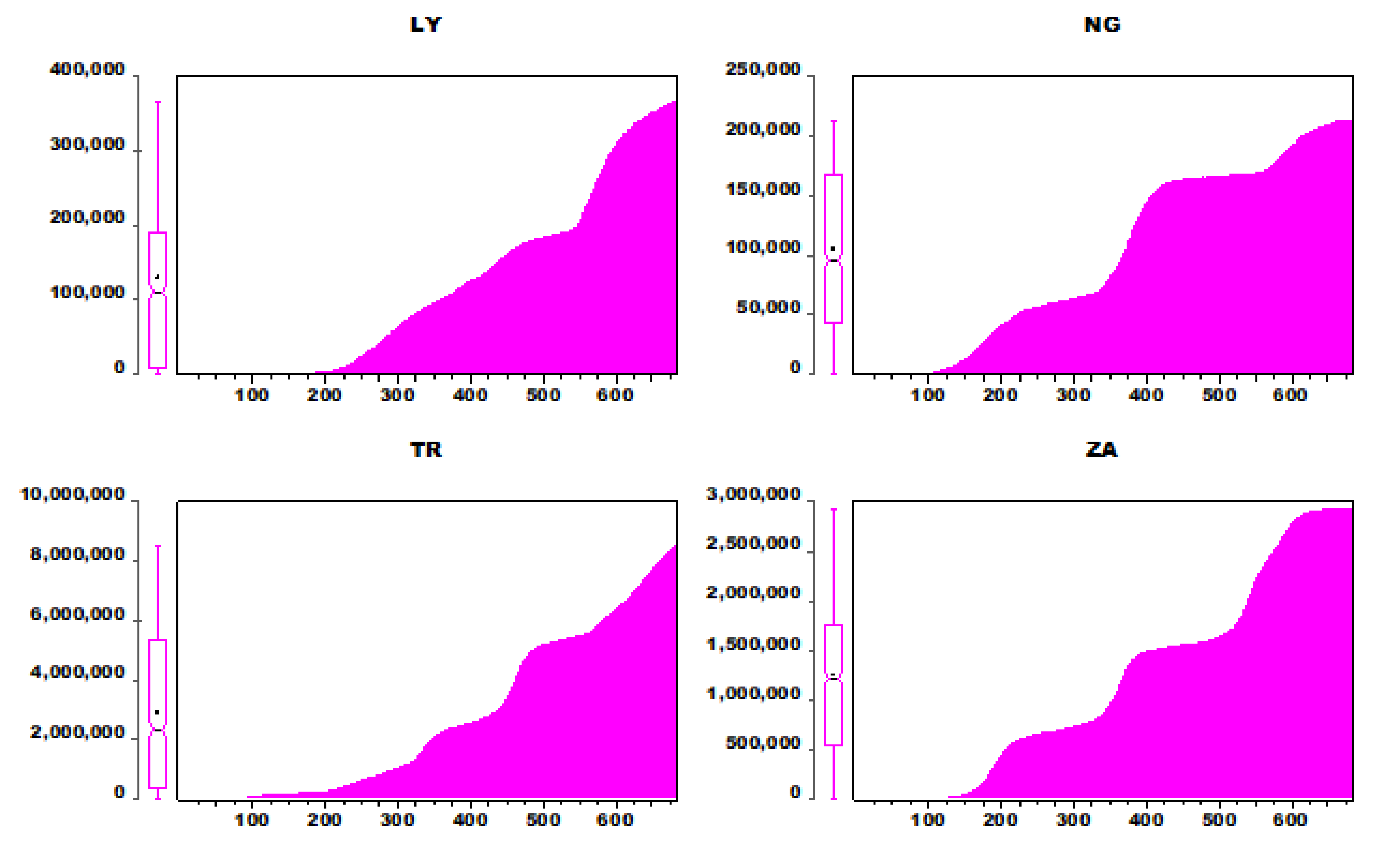
| LY | 129,333.3 | 111,124 | 366,789 | 1 | 116,504.4 | 605 |
| NG | 104,581.5 | 95,934 | 213,464 | 5 | 72,519.22 | 631 |
| TR | 2,906,611 | 2,355,839 | 8,503,220 | 1 | 2,635,359 | 619 |
| ZA | 1,252,298 | 1,231,597 | 2,927,499 | 5 | 960,752.1 | 625 |
| Variables | None | Constant | Constant and Trend | None | Constant | Constant and Trend | Decision |
|---|---|---|---|---|---|---|---|
| LY | 2.676 | 1.594 | −1.986 | −2.291 *** | −3.933 *** | −4.527 *** | I(1) |
| NG | 1.244 | −0.705 | −2.225 | −2.179 *** | −3.058 *** | −3.041 *** | I(1) |
| TR | 0.931 | 0.311 | −2.582 | −0.89 | −1.865 | −2.167 | I(2) |
| ZA | 0.929 | −0.444 | −3.166 | −1.72 | −2.368 | −2.277 | I(2) |
| LY | 7.204 | 3.413 | −1.797 | −10.572 *** | −17.217 *** | −20.344 *** | I(1) |
| NG | 3.755 | −0.116 | −1.627 | −11.264 *** | −17.258 *** | −17.263 *** | I(1) |
| TR | 7.839 | 3.865 | −1.414 | −0.907 | −1.882 | −2.143 | I(2) |
| ZA | 4.329 | 0.882 | −2.221 | −4.091 *** | −4.112 *** | −4.567 *** | I(1) |
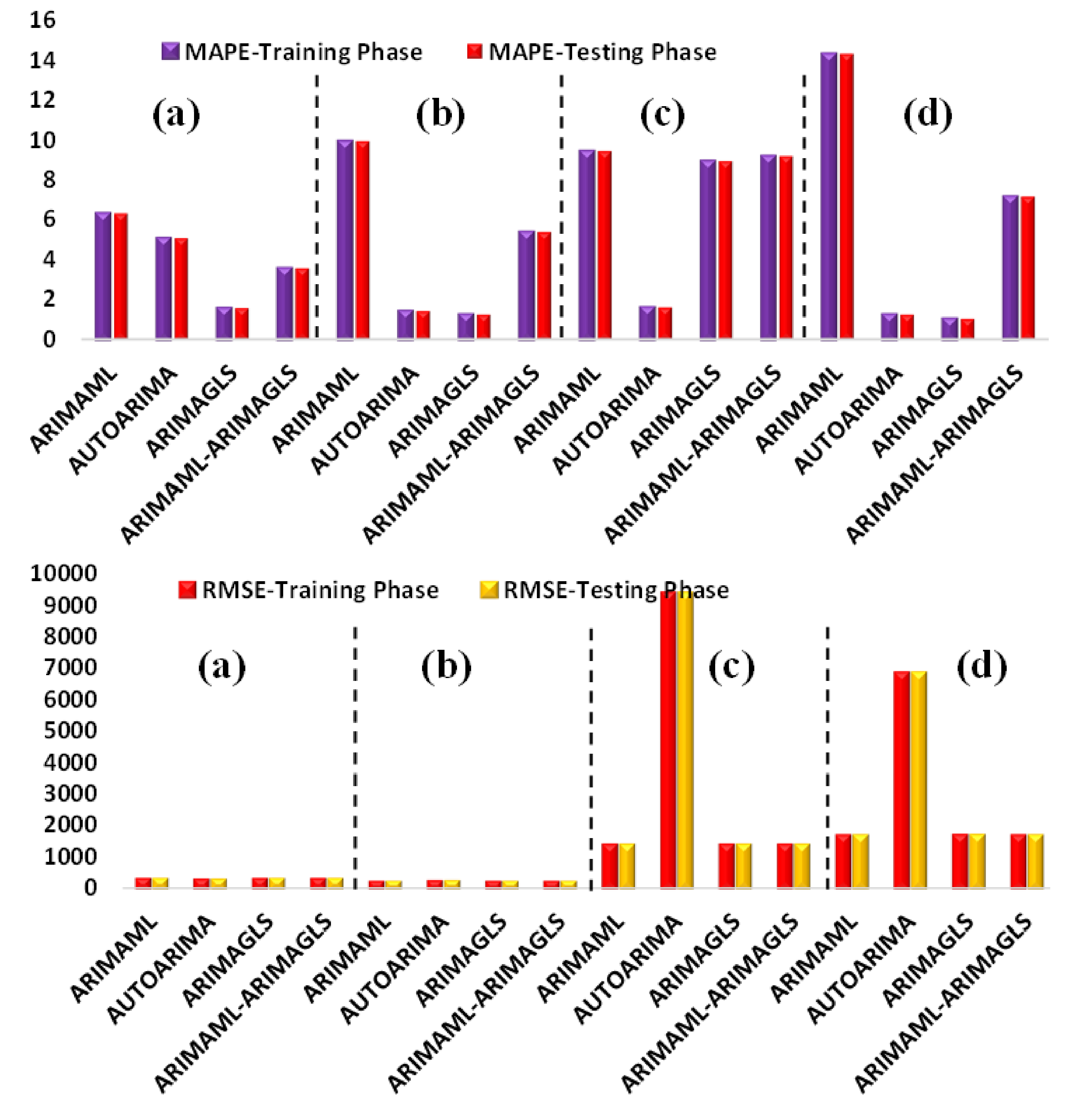
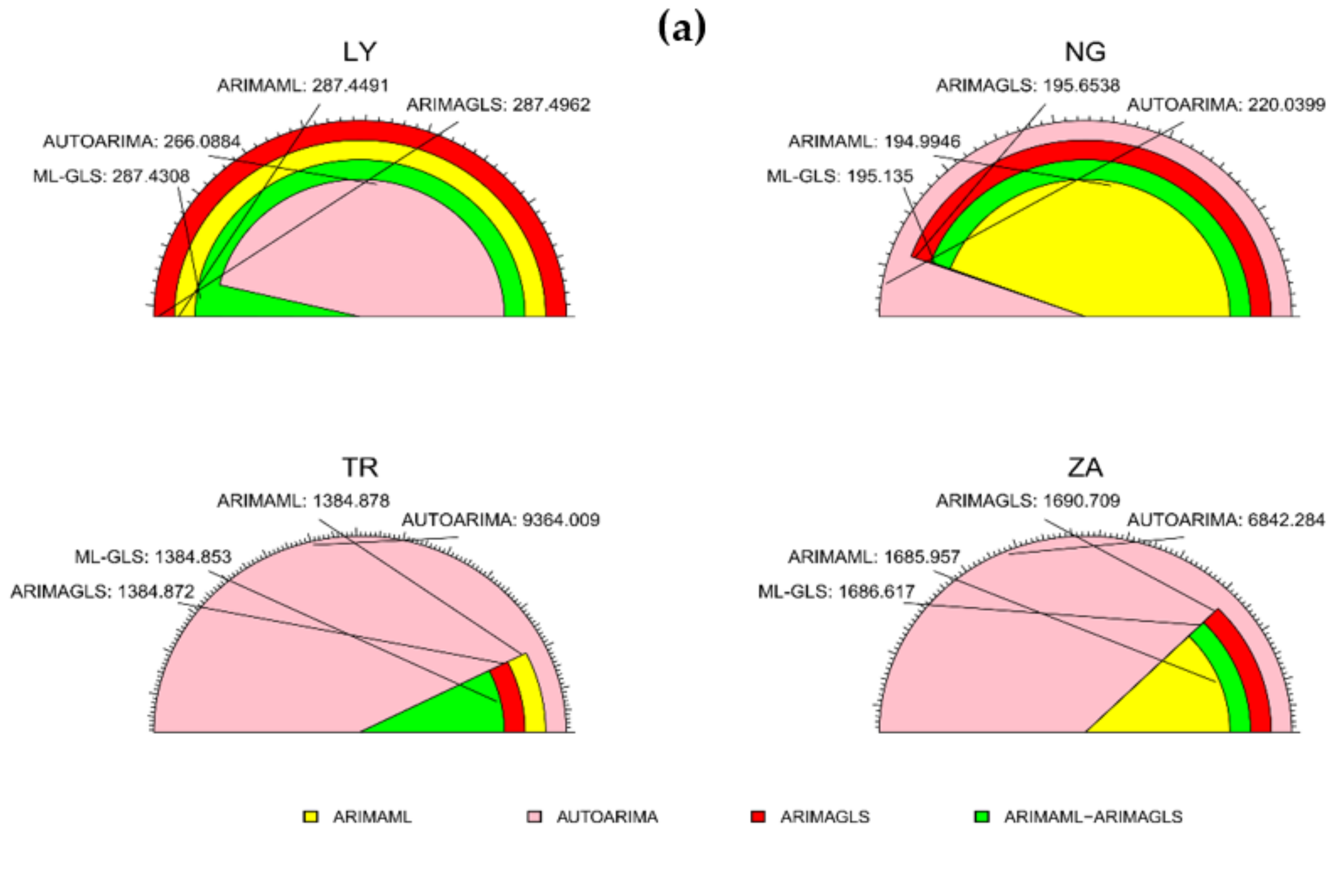
| Models | RMSE | MAE | MAPE | SMAPE | Theil U1 | Theil U2 |
|---|---|---|---|---|---|---|
| ARIMAML | 287.4491 | 171.1810 | 6.329595 | 4.651772 | 0.001302 | 4.456228 |
| AUTOARIMA | 266.0884 | 158.2471 | 5.097415 | 4.000233 | 0.001204 | 3.065781 |
| ARIMAGLS | 287.4962 | 170.3428 | 1.579800 | 1.613471 | 0.001302 | 0.904637 |
| ARIMAML-ARIMAGLS | 287.4308 | 170.5967 | 3.587180 | 3.010201 | 0.001302 | 2.431895 |
| ARIMAML | 194.9946 | 107.5219 | 9.913560 | 5.122160 | 0.000946 | 4.291490 |
| AUTOARIMA | 220.0399 | 124.1118 | 1.442778 | 1.494742 | 0.001067 | 0.834548 |
| ARIMAGLS | 195.6538 | 106.9622 | 1.257531 | 1.378221 | 0.000949 | 0.900122 |
| ARIMAML-ARIMAGLS | 195.1350 | 107.0657 | 5.410406 | 3.742184 | 0.000946 | 2.199975 |
| ARIMAML | 1384.8780 | 667.1446 | 9.421745 | 1.801850 | 0.000259 | 6.971105 |
| AUTOARIMA | 9364.0090 | 6847.1200 | 1.622860 | 1.533954 | 0.001748 | 0.715107 |
| ARIMAGLS | 1384.8720 | 666.1256 | 8.916807 | 1.775690 | 0.000259 | 6.619425 |
| ARIMAML-ARIMAGLS | 1384.8530 | 666.6342 | 9.169276 | 1.788919 | 0.000259 | 6.795260 |
| ARIMAML | 1685.9570 | 818.2752 | 14.266580 | 3.603760 | 0.000768 | 13.075140 |
| AUTOARIMA | 6842.2840 | 4613.7460 | 1.256974 | 1.241767 | 0.003113 | 0.538986 |
| ARIMAGLS | 1690.7090 | 819.5312 | 1.048277 | 1.105426 | 0.000770 | 0.673285 |
| ARIMAML-ARIMAGLS | 1686.6170 | 814.9397 | 7.180849 | 2.674733 | 0.000768 | 6.467583 |
| Models | RMSE | MAE | MAPE | SMAPE | Theil U1 | Theil U2 |
|---|---|---|---|---|---|---|
| ARIMAML | 287.4491 | 171.1810 | 6.329595 | 4.651772 | 0.001302 | 4.456228 |
| AUTOARIMA | 266.0884 | 158.2471 | 5.097415 | 4.000233 | 0.001204 | 3.065781 |
| ARIMAGLS | 287.4962 | 170.3428 | 1.579800 | 1.613471 | 0.001302 | 0.904637 |
| ARIMAML-ARIMAGLS | 287.4308 | 170.5967 | 3.587180 | 3.010201 | 0.001302 | 2.431895 |
| ARIMAML | 194.9946 | 107.5219 | 9.913560 | 5.122160 | 0.000946 | 4.291490 |
| AUTOARIMA | 220.0399 | 124.1118 | 1.442778 | 1.494742 | 0.001067 | 0.834548 |
| ARIMAGLS | 195.6538 | 106.9622 | 1.257531 | 1.378221 | 0.000949 | 0.900122 |
| ARIMAML-ARIMAGLS | 195.1350 | 107.0657 | 5.410406 | 3.742184 | 0.000946 | 2.199975 |
| ARIMAML | 1384.8780 | 667.1446 | 9.421745 | 1.801850 | 0.000259 | 6.971105 |
| AUTOARIMA | 9364.0090 | 6847.1200 | 1.622860 | 1.533954 | 0.001748 | 0.715107 |
| ARIMAGLS | 1384.8720 | 666.1256 | 8.916807 | 1.775690 | 0.000259 | 6.619425 |
| ARIMAML-ARIMAGLS | 1384.8530 | 666.6342 | 9.169276 | 1.788919 | 0.000259 | 6.795260 |
| ARIMAML | 1685.9570 | 818.2752 | 14.266580 | 3.603760 | 0.000768 | 13.075140 |
| AUTOARIMA | 6842.2840 | 4613.7460 | 1.256974 | 1.241767 | 0.003113 | 0.538986 |
| ARIMAGLS | 1690.7090 | 819.5312 | 1.048277 | 1.105426 | 0.000770 | 0.673285 |
| ARIMAML-ARIMAGLS | 1686.6170 | 814.9397 | 7.180849 | 2.674733 | 0.000768 | 6.467583 |
| Calibration Phase | Verification Phase | |||||||
|---|---|---|---|---|---|---|---|---|
| Models | R2 | MSE | R | RMSE | R2 | MSE | R | RMSE |
| RF-M1 | 0.8982 | 0.0705 | 0.9477 | 0.2655 | 0.8526 | 1.0205 | 0.9234 | 1.0102 |
| RF-M2 | 0.9082 | 0.0626 | 0.9530 | 0.2502 | 0.8985 | 0.7715 | 0.9479 | 0.8784 |
| LSTM-M1 | 0.9447 | 0.0336 | 0.9720 | 0.1833 | 0.9393 | 0.0450 | 0.9692 | 0.2121 |
| LSTM-M2 | 0.8876 | 0.3705 | 0.9421 | 0.6087 | 0.8864 | 0.8374 | 0.9415 | 0.9151 |
| NN-EML | 0.9776 | 0.0305 | 0.9881 | 0.1746 | 0.9694 | 0.0374 | 0.9845 | 0.1933 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alamrouni, A.; Aslanova, F.; Mati, S.; Maccido, H.S.; Jibril, A.A.; Usman, A.G.; Abba, S.I. Multi-Regional Modeling of Cumulative COVID-19 Cases Integrated with Environmental Forest Knowledge Estimation: A Deep Learning Ensemble Approach. Int. J. Environ. Res. Public Health 2022, 19, 738. https://doi.org/10.3390/ijerph19020738
Alamrouni A, Aslanova F, Mati S, Maccido HS, Jibril AA, Usman AG, Abba SI. Multi-Regional Modeling of Cumulative COVID-19 Cases Integrated with Environmental Forest Knowledge Estimation: A Deep Learning Ensemble Approach. International Journal of Environmental Research and Public Health. 2022; 19(2):738. https://doi.org/10.3390/ijerph19020738
Chicago/Turabian StyleAlamrouni, Abdelgader, Fidan Aslanova, Sagiru Mati, Hamza Sabo Maccido, Afaf. A. Jibril, A. G. Usman, and S. I. Abba. 2022. "Multi-Regional Modeling of Cumulative COVID-19 Cases Integrated with Environmental Forest Knowledge Estimation: A Deep Learning Ensemble Approach" International Journal of Environmental Research and Public Health 19, no. 2: 738. https://doi.org/10.3390/ijerph19020738
APA StyleAlamrouni, A., Aslanova, F., Mati, S., Maccido, H. S., Jibril, A. A., Usman, A. G., & Abba, S. I. (2022). Multi-Regional Modeling of Cumulative COVID-19 Cases Integrated with Environmental Forest Knowledge Estimation: A Deep Learning Ensemble Approach. International Journal of Environmental Research and Public Health, 19(2), 738. https://doi.org/10.3390/ijerph19020738