
Reward Uncertainty and Expected Value Enhance Generalization of Episodic Memory

Abstract
:1. Introduction
2. Experiment 1
2.1. Materials and Methods
2.1.1. Participants
2.1.2. Materials
2.1.3. Procedure
2.1.4. Data Analysis
2.2. Results and Discussion
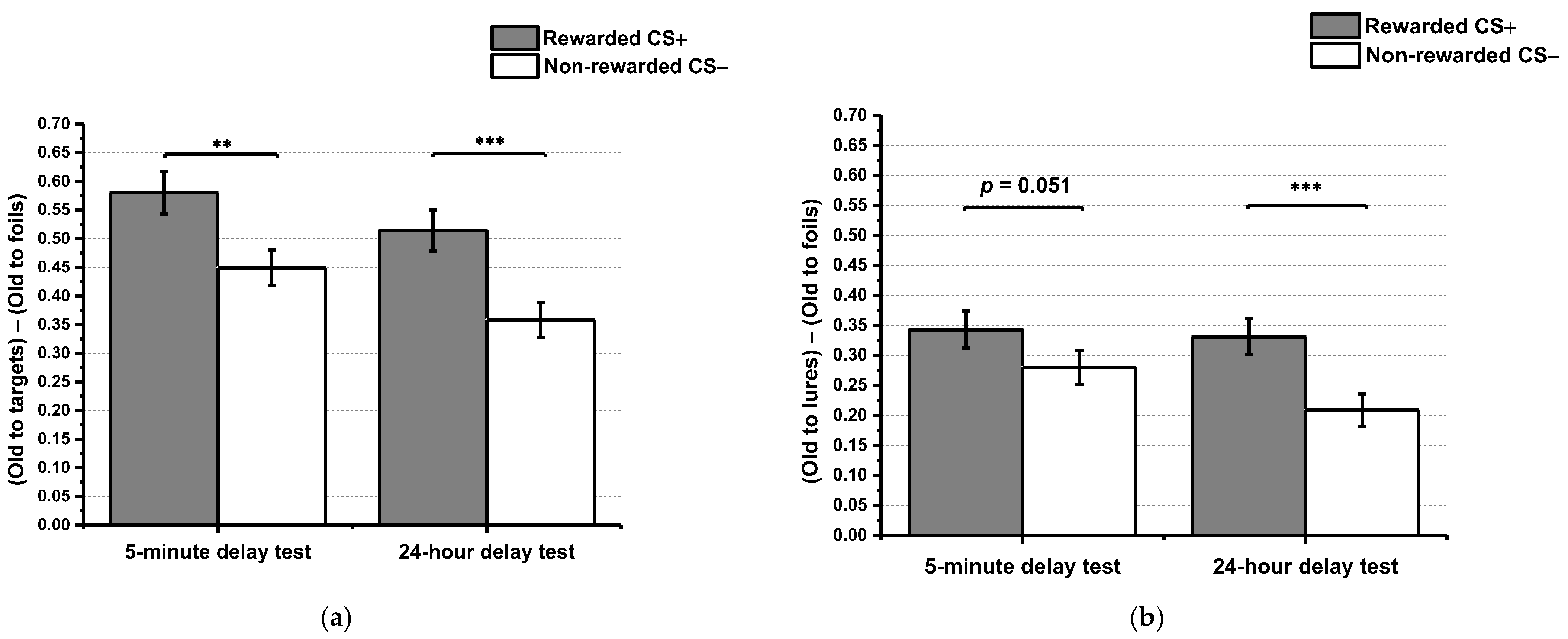
2.2.1. Effects of Reward Conditioning and Time Interval on Stimulus Recognition
2.2.2. Effects of Reward Conditioning and Time Interval on Episodic Memory Generalization
3. Experiment 2a
3.1. Materials and Methods
3.1.1. Participants
3.1.2. Procedure
3.1.3. Data Analysis
3.2. Results and Discussion
3.2.1. Effect of Reward Uncertainty on Stimulus Recognition and Episodic Memory Generalization
3.2.2. Trial-by-Trial Regression Analysis on Generalization
4. Experiment 2b
4.1. Materials and Methods
4.1.1. Participants
4.1.2. Procedure
4.1.3. Data analysis
4.2. Results and Discussion
4.2.1. Effect of Expected Value on Stimulus Recognition and Episodic Memory Generalization
4.2.2. Trial-by-Trial Regression Analysis on Generalization
5. Discussion
5.1. Reward Conditioning Promotes Episodic Memory Generalization
5.2. Uncertainty and Expected Value Are Positive Predictors of the Generalization of Episodic Memory
5.3. Unsigned Reward Prediction Error Worked as a Negative Predictor of Generalization of Episodic Memory
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- FeldmanHall, O.; Dunsmoor, J.E.; Tompary, A.; Hunter, L.E.; Todorov, A.; Phelps, E.A. Stimulus Generalization as a Mechanism for Learning to Trust. Proc. Natl. Acad. Sci. USA 2018, 115, E1690–E1697. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kumaran, D. What Representations and Computations Underpin the Contribution of the Hippocampus to Generalization and Inference? Front. Hum. Neurosci. 2012, 6, 157. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dunsmoor, J.E.; Kroes, M.C. Episodic Memory and Pavlovian Conditioning: Ships Passing in the Night. Curr. Opin. Behav. Sci. 2019, 26, 32–39. [Google Scholar] [CrossRef] [PubMed]
- Kahnt, T.; Park, S.Q.; Burke, C.J.; Tobler, P.N. How Glitter Relates to Gold: Similarity-Dependent Reward Prediction Errors in the Human Striatum. J. Neurosci. 2012, 32, 16521–16529. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kahnt, T.; Tobler, P.N. Dopamine Regulates Stimulus Generalization in the Human Hippocampus. eLife 2016, 5, e12678. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miendlarzewska, E.A.; Bavelier, D.; Schwartz, S. Influence of Reward Motivation on Human Declarative Memory. Neurosci. Biobehav. Rev. 2016, 61, 156–176. [Google Scholar] [CrossRef] [Green Version]
- Hanson, H.M. Effects of Discrimination Training on Stimulus Generalization. J. Exp. Psychol. 1959, 58, 321–334. [Google Scholar] [CrossRef]
- Starita, F.; Kroes, M.C.W.; Davachi, L.; Phelps, E.A.; Dunsmoor, J.E. Threat Learning Promotes Generalization of Episodic Memory. J. Exp. Psychol. Gen. 2019, 148, 1426–1434. [Google Scholar] [CrossRef]
- Murayama, K.; Kitagami, S. Consolidation Power of Extrinsic Rewards: Reward Cues Enhance Long-Term Memory for Irrelevant Past Events. J. Exp. Psychol. Gen. 2014, 143, 15–20. [Google Scholar] [CrossRef] [Green Version]
- Murty, V.P.; Dubrow, S.; Davachi, L. Decision-Making Increases Episodic Memory via Postencoding Consolidation. J. Cogn. Neurosci. 2018, 31, 1308–1317. [Google Scholar] [CrossRef]
- Braun, E.K.; Wimmer, G.E.; Shohamy, D. Retroactive and Graded Prioritization of Memory by Reward. Nat. Commun. 2018, 9, 4886. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gruber, M.J.; Ritchey, M.; Wang, S.F.; Doss, M.K.; Ranganath, C. Post-Learning Hippocampal Dynamics Promote Preferential Retention of Rewarding Events. Neuron 2016, 89, 1110–1120. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shohamy, D.; Adcock, R.A. Dopamine and Adaptive Memory. Trends Cogn. Sci. 2010, 14, 464–472. [Google Scholar] [CrossRef] [PubMed]
- Fiorillo, C.D.; Newsome, W.T.; Schultz, W. The Temporal Precision of Reward Prediction in Dopamine Neurons. Nat. Neurosci. 2008, 11, 966–973. [Google Scholar] [CrossRef]
- Mason, A.; Farrell, S.; Howard-Jones, P.; Ludwig, C.J.H. The Role of Reward and Reward Uncertainty in Episodic Memory. J. Mem. Lang. 2017, 96, 62–77. [Google Scholar] [CrossRef] [Green Version]
- Zweifel, L.S. Dopamine, Uncertainty, and Fear Generalization. Curr. Opin. Behav. Sci. 2019, 26, 157–164. [Google Scholar] [CrossRef]
- Faul, F.; Erdfelder, E.; Lang, A.G.; Buchner, A. G*Power 3: A Flexible Statistical Power Analysis Program for the Social, Behavioral, and Biomedical Sciences. Behav. Res. Methods 2007, 39, 175–191. [Google Scholar] [CrossRef]
- Oyarzún, J.P.; Packard, P.A.; de Diego-Balaguer, R.; Fuentemilla, L. Motivated Encoding Selectively Promotes Memory for Future Inconsequential Semantically-Related Events. Neurobiol. Learn. Mem. 2016, 133, 1–6. [Google Scholar] [CrossRef]
- Kirwan, C.B.; Stark, C.E.L. Overcoming Interference: An fMRI Investigation of Pattern Separation in the Medial Temporal Lobe. Learn. Mem. 2007, 14, 625–633. [Google Scholar] [CrossRef] [Green Version]
- Rouhani, N.; Niv, Y. Signed and Unsigned Reward Prediction Errors Dynamically Enhance Learning and Memory. eLife 2021, 10, e61077. [Google Scholar] [CrossRef]
- Dunsmoor, J.E.; Murty, V.P.; Davachi, L.; Phelps, E.A. Emotional Learning Selectively and Retroactively Strengthens Memories for Related Events. Nature 2015, 520, 345–348. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- R Development Core Team. R: The R Project for Statistical Computing. Available online: https://www.r-project.org (accessed on 28 October 2022).
- Kuhn, M. Building. Predictive Models in R Using the Caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Bates, D.; Mächler, M.; Bolker, B.M.; Walker, S.C. Fitting Linear Mixed-Effects Models Using Lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- Ripley, B. Package “MASS”-CRAN. Available online: https://cran.r-project.org/web/packages/MASS/index.html (accessed on 28 January 2022).
- Murty, V.P.; LaBar, K.S.; Adcock, R.A. Distinct Medial Temporal Networks Encode Surprise during Motivation by Reward versus Punishment. Neurobiol. Learn. Mem. 2016, 134, 55–64. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Patil, A.; Murty, V.P.; Dunsmoor, J.E.; Phelps, E.A.; Davachi, L. Reward Retroactively Enhances Memory Consolidation for Related Items. Learn. Mem. 2017, 24, 65–69. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carpenter, A.C.; Schacter, D.L. False Memories, False Preferences: Flexible Retrieval Mechanisms Supporting Successful Inference Bias Novel Decisions. J. Exp. Psychol. Gen. 2018, 147, 988–1004. [Google Scholar] [CrossRef]
- Wang, F.; Kahnt, T. Neural Circuits for Inference-Based Decision-Making. Curr Opin Behav Sci. 2021, 41, 10–14. [Google Scholar] [CrossRef]
- Lisman, J.; Grace, A.A.; Duzel, E. A NeoHebbian Framework for Episodic Memory; Role of Dopamine-Dependent Late LTP. Trends Neurosci. 2011, 34, 536–547. [Google Scholar] [CrossRef] [Green Version]
- Taylor, J.E.; Cortese, A.; Barron, H.C.; Pan, X.; Sakagami, M.; Zeithamova, D. How Do We Generalize? Neurons Behav. Data Anal. Theory. 2022, 1, 1–33. [Google Scholar] [CrossRef]
- Werchan, D.M.; Gómez, R.L. Generalizing Memories over Time: Sleep and Reinforcement Facilitate Transitive Inference. Neurobiol. Learn. Mem. 2013, 100, 70–76. [Google Scholar] [CrossRef]
- Zeithamova, D.; Bowman, C.R. Generalization and the Hippocampus: More than One Story? Neurobiol. Learn. Mem. 2020, 175, 107317. [Google Scholar] [CrossRef] [PubMed]
- Reyna, V.F.; Brainerd, C.J. Fuzzy-Trace Theory: An Interim Synthesis. Learn. Individ. Differ. 1995, 7, 1–75. [Google Scholar] [CrossRef]
- Bui, D.C.; Friedman, M.C.; McDonough, I.M.; Castel, A.D. False Memory and Importance: Can We Prioritize Encoding without Consequence? Mem. Cogn. 2013, 41, 1012–1020. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Swirsky, L.T.; Marinacci, R.M.; Spaniol, J. Reward Anticipation Selectively Boosts Encoding of Gist for Visual Objects. Sci. Rep. 2020, 10, 20196. [Google Scholar] [CrossRef] [PubMed]
- Liashenko, A.; Dizaji, A.S.; Melloni, L.; Schwiedrzik, C.M. Memory Guidance of Value-Based Decision Making at an Abstract Level of Representation. Sci. Rep. 2020, 10, 21496. [Google Scholar] [CrossRef] [PubMed]
- Poppenk, J.; Evensmoen, H.R.; Moscovitch, M.; Nadel, L. Long-Axis Specialization of the Human Hippocampus. Trends Cogn. Sci. 2013, 17, 230–240. [Google Scholar] [CrossRef]
- Adcock, R.A.; Thangavel, A.; Whitfield-Gabrieli, S.; Knutson, B.; Gabrieli, J.D.E. Reward-Motivated Learning: Mesolimbic Activation Precedes Memory Formation. Neuron 2006, 50, 507–517. [Google Scholar] [CrossRef] [Green Version]
- Krebs, R.M.; Heipertz, D.; Schuetze, H.; Duzel, E. Novelty Increases the Mesolimbic Functional Connectivity of the Substantia Nigra/Ventral Tegmental Area (SN/VTA) during Reward Anticipation: Evidence from High-Resolution fMRI. NeuroImage 2011, 58, 647–655. [Google Scholar] [CrossRef]
- Preuschoff, K.; Bossaerts, P.; Quartz, S.R. Neural Differentiation of Expected Reward and Risk in Human Subcortical Structures. Neuron 2006, 51, 381–390. [Google Scholar] [CrossRef] [Green Version]
- Rouhani, N.; Norman, K.A.; Niv, Y.; Bornstein, A.M. Reward Prediction Errors Create Event Boundaries in Memory. Cognition 2020, 203, 104269. [Google Scholar] [CrossRef] [PubMed]
- Bein, O.; Duncan, K.; Davachi, L. Mnemonic Prediction Errors Bias Hippocampal States. Nat. Commun. 2020, 11, 3451. [Google Scholar] [CrossRef] [PubMed]
- Frank, D.; Montemurro, M.A.; Montaldi, D. Pattern Separation Underpins Expectation-Modulated Memory. J. Neurosci. 2020, 40, 3455–3464. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
| Predictor | Description | Expt. 1 Value | Expt. 2a Value | Expt. 2b Value |
|---|---|---|---|---|
| Expected Value (EV) | Probability of obtaining a reward multiplied by the reward magnitude | 5, or 0 | 5, or 5 | 8, or 2 |
| Outcome (O) | The predetermined value of the picture that participants could learn from the feedback | 10, 0, or 0 | 10, 0, or 5 | 10, 0, or 0, 10 |
| Signed Reward Prediction Error (SRPE) | The reward outcome minus the expected value | 5, −5 or 0 | 5, −5, or 0 | 2, −8, or −2, 8 |
| Unsigned Reward Prediction Error (URPE) | The absolute value of reward prediction error | 5, or 0 | 5, or 0 | 2, 8, or 2, 8 |
| Uncertainty (U) | The entropy of reward probability (the log base is 2) | 1, or 0 | 1, or 0 | 0.72, or 0.72 |
| Stimulus Type | Targets | Lures | Foils | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Response Type | Old | Sim | New | Old | Sim | New | Old | Sim | New | ||
| Exp 1 | 5 min delay | CS+ * | 0.66 (0.03) | 0.15 (0.02) | 0.19 (0.02) | 0.41 (0.03) | 0.34 (0.03) | 0.25 (0.03) | 0.07 (0.02) | 0.11 (0.02) | 0.82 (0.03) |
| CS− | 0.56 (0.03) | 0.18 (0.03) | 0.26 (0.03) | 0.39 (0.03) | 0.28 (0.03) | 0.33 (0.03) | 0.11 (0.02) | 0.10 (0.02) | 0.79 (0.03) | ||
| 24 h delay | CS+ | 0.64 (0.03) | 0.15 (0.02) | 0.21 (0.02) | 0.46 (0.03) | 0.24 (0.03) | 0.30 (0.03) | 0.13 (0.02) | 0.08 (0.02) | 0.79 (0.03) | |
| CS− | 0.48 (0.03) | 0.17 (0.03) | 0.35 (0.03) | 0.33 (0.03) | 0.24 (0.03) | 0.44 (0.03) | 0.12 (0.02) | 0.13 (0.02) | 0.75 (0.03) | ||
| Expt. 2a (U) | 24 h delay | U (1) | 0.62 (0.03) | 0.18 (0.02) | 0.20 (0.02) | 0.47 (0.03) | 0.26 (0.03) | 0.27 (0.02) | 0.13 (0.01) | 0.12 (0.02) | 0.75 (0.03) |
| U (0) | 0.50 (0.03) | 0.17 (0.03) | 0.33 (0.03) | 0.33 (0.02) | 0.25 (0.03) | 0.42 (0.03) | 0.13 (0.01) | 0.14 (0.03) | 0.73 (0.03) | ||
| Expt. 2b (EV) | 24 h delay | EV (8) | 0.61 (0.03) | 0.17 (0.02) | 0.22 (0.03) | 0.43 (0.03) | 0.26 (0.02) | 0.31 (0.03) | 0.11 (0.01) | 0.09 (0.01) | 0.80 (0.02) |
| EV (2) | 0.52 (0.03) | 0.19 (0.02) | 0.29 (0.03) | 0.33 (0.02) | 0.28 (0.03) | 0.39 (0.03) | 0.09 (0.01) | 0.11 (0.02) | 0.80 (0.02) | ||
| Expt. 2b (URPE) | 24 h delay | URPE (8) ** | 0.59 (0.03) | 0.17 (0.02) | 0.24 (0.03) | 0.36 (0.03) | 0.32 (0.03) | 0.32 (0.03) | |||
| URPE (2) | 0.56 (0.02) | 0.18 (0.01) | 0.26 (0.02) | 0.39 (0.02) | 0.26 (0.02) | 0.35 (0.02) | |||||
| Model (M) | Old, Similar, and New Responses to Lures | Old and Similar Response to Lures | ||
|---|---|---|---|---|
| BIC | BF B − M | BIC | BF B − M | |
| Baseline (b) | 3253.60 | 1.77 × 1011 | 2057.80 | 984,609.11 |
| U + (1|subject) | 3214.00 | 445.86 | 2059.50 | 2,303,637.61 |
| U + (1+U|subject) * | 3201.80 | 1 | 2030.20 | 1 |
| Model (M) | Old, Similar, and New Responses to Lures | Old and Similar Response to Lures | ||
|---|---|---|---|---|
| BIC | BF B − M | BIC | BF B − M | |
| Baseline(b) | 3974.10 | 34,012,706,080 | 2585.40 | 417,585,553.60 |
| EV + URPE + (1|subject) | 3953.50 | 1,143,952.58 | 2576.80 | 5,666,034.23 |
| EV + URPE + (1+EV|subject) | 3930.20 | 9.97 | 2545.70 | 1 |
| EV + URPE + (1+EV|subject) + (1+URPE|subject) * | 3951.50 | 420,836.64 | 2567.1 | 44,355.85 |
| EV + (1|subject) | 3948.70 | 103,777.04 | 2579.70 | 24,154,952.75 |
| EV + (1+ EV |subject) | 3925.60 | 1 | 2549.30 | 6.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, Y.; Jiang, Y.; Zhou, F.; Jiang, Y.; Long, Y.; Wang, K. Reward Uncertainty and Expected Value Enhance Generalization of Episodic Memory. Int. J. Environ. Res. Public Health 2022, 19, 14389. https://doi.org/10.3390/ijerph192114389
Yue Y, Jiang Y, Zhou F, Jiang Y, Long Y, Wang K. Reward Uncertainty and Expected Value Enhance Generalization of Episodic Memory. International Journal of Environmental Research and Public Health. 2022; 19(21):14389. https://doi.org/10.3390/ijerph192114389
Chicago/Turabian StyleYue, Yang, Yingjie Jiang, Fan Zhou, Yuantao Jiang, Yiting Long, and Kaiyu Wang. 2022. "Reward Uncertainty and Expected Value Enhance Generalization of Episodic Memory" International Journal of Environmental Research and Public Health 19, no. 21: 14389. https://doi.org/10.3390/ijerph192114389