
The Use of Machine Learning for Inferencing the Effectiveness of a Rehabilitation Program for Orthopedic and Neurological Patients

 , , , ,
, , , ,  , ,
, ,
Abstract
:1. Introduction
- To the best of our knowledge, this is the first study that attempts to predict functional improvement from ADR data which represents real-world scenarios registered in Italy.
- We study the applicability of machine learning in assessing the rehabilitation outcome in advance.
- An in-depth analysis of how different models and combination affects the accuracy with which the proposed algorithms predict the target variable.
2. Materials and Methods
2.1. Dataset
2.2. Input Features
2.3. Outcome Variable
2.4. Machine Learning Algorithms
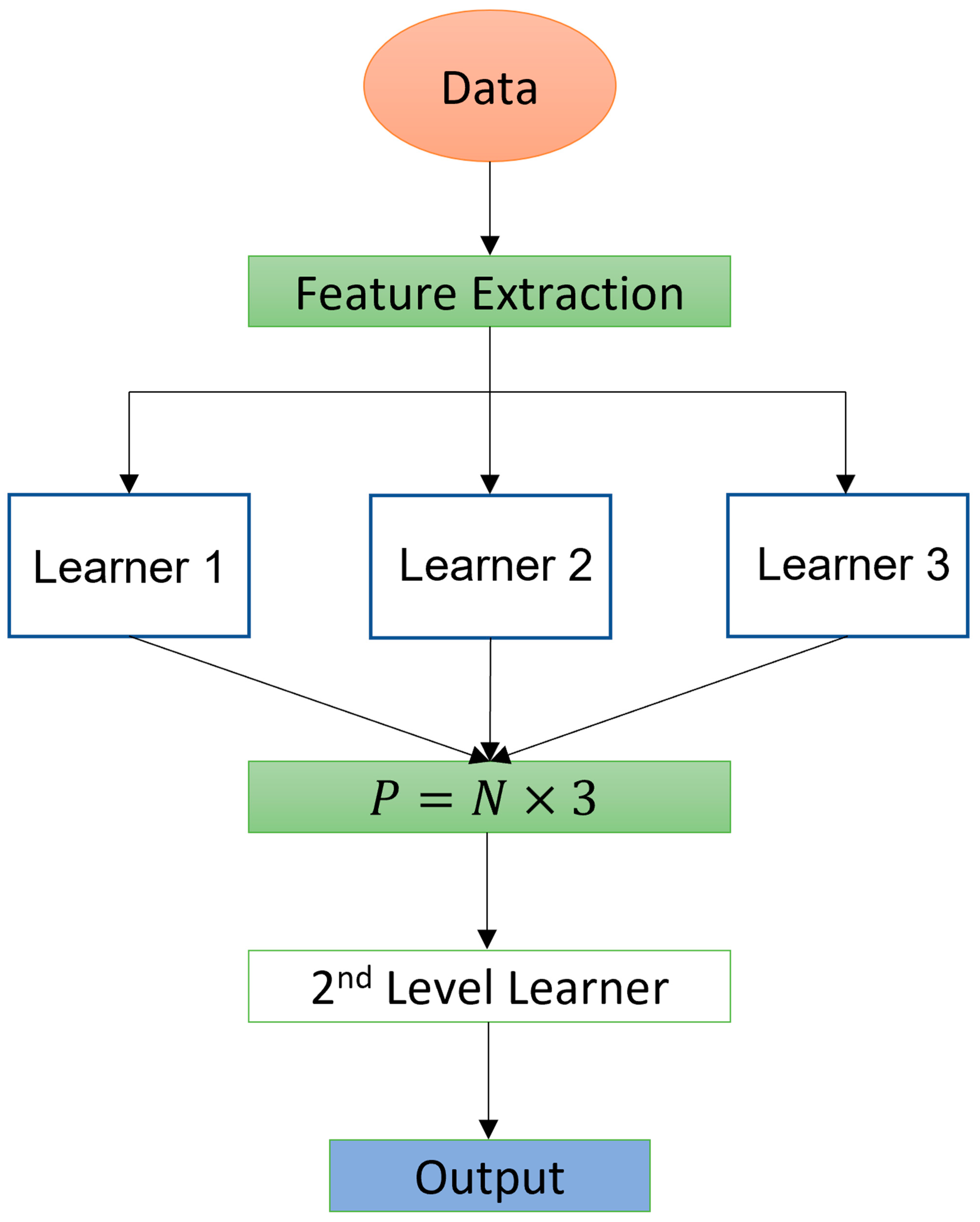
2.5. Customized Machine Learning Algorithm
2.6. Outcome Statistical Analysis
3. Results
3.1. Data Extraction
3.2. Variable Importance Ranking
3.3. Prediction Accuracy and Analysis
3.4. Ablation Study
4. Discussion
4.1. Study Strengths and Limitations
4.2. Machine Learning Feasibility and Implications
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Clifford, J. The UN Disability Convention and its impact on European Equality Law. Equal Rights Trust. 2011, 6, 11–25. [Google Scholar]
- Heinemann, A.W.; Roth, E.J.; Cichowski, K.; Betts, H.B. Multivariate analysis of improvement and outcome following stroke rehabilitation. Arch. Neurol. 1987, 44, 1167–1172. [Google Scholar] [CrossRef] [PubMed]
- Denti, L.; Agosti, M.; Franceschini, M. Outcome predictors of rehabilitation for first stroke in the elderly. Eur. J. Phys. Rehabil. Med. 2008, 44, 3–11. [Google Scholar] [PubMed]
- Shah, S.; Vanclay, F.; Cooper, B. Efficiency, effectiveness, and duration of stroke rehabilitation. Stroke 1990, 21, 241–246. [Google Scholar] [CrossRef]
- Koh, G.C.; Chen, C.H.; Petrella, R.; Thind, A. Rehabilitation impact indices and their independent predictors: A systematic review. BMJ Open 2013, 3, e003483. [Google Scholar] [CrossRef]
- Koh, G.C.-H.; Chen, C.; Cheong, A.; Choo, T.B.; Pui, C.K.; Phoon, F.N.; Ming, C.K.; Yeow, T.B.; Petrella, R.; Thind, A.; et al. Trade-offs between effectiveness and efficiency in stroke rehabilitation. Int. J. Stroke 2012, 7, 606–614. [Google Scholar] [CrossRef] [PubMed]
- Chow, P.; Chen, C.; Cheong, A.; Fong, N.P.; Chan, K.M.; Tan, B.Y.; Menon, E.; Ee, C.H.; Lee, K.K.; Koh, D.; et al. Factors and trade-offs with rehabilitation effectiveness and efficiency in newly disabled older persons. Arch. Phys. Med. Rehabil. 2014, 95, 1510–1520.e4. [Google Scholar] [CrossRef] [PubMed]
- Damiani, C.; Mangone, M.; Paoloni, M.; Goffredo, M.; Franceschini, M.; Servidio, M.; Pournajaf, S.; Santilli, V.; Agostini, F.; Bernetti, A. Trade-offs with rehabilitation Effectiveness (REs) and Efficiency (REy) in a sample of Italian disabled persons in a in post-acuity rehabilitation unit. Ann. Ig. 2020, 32, 327–335. [Google Scholar] [CrossRef] [PubMed]
- Collin, C.; Wade, D.T.; Davies, S.; Horne, V. The Barthel ADL Index: A reliability study. Int. Disabil. Stud. 1988, 10, 61–63. [Google Scholar] [CrossRef] [PubMed]
- Wade, D.T.; Collin, C. The Barthel ADL Index: A standard measure of physical disability? Int. Disabil. Stud. 1988, 10, 64–67. [Google Scholar] [CrossRef]
- Hsueh, I.P.; Lin, J.H.; Jeng, J.S.; Hsieh, C.L. Comparison of the psychometric characteristics of the functional independence measure, 5 item Barthel index, and 10 item Barthel index in patients with stroke. J. Neurol. Neurosurg. Psychiatry 2002, 73, 188–190. [Google Scholar] [CrossRef] [PubMed]
- Harari, Y.; O’Brien, M.K.; Lieber, R.L.V.; Jayaraman, A. Inpatient stroke rehabilitation: Prediction of clinical outcomes using a machine-learning approach. J. Neuroeng. Rehabil. 2020, 17, 71. [Google Scholar] [CrossRef] [PubMed]
- Franceschini, M.; Fugazzaro, S.; Agosti, M.; Sola, C.; Di Carlo, A.; Cecconi, L.; Ferro, S. Acute Phase Predictors of 6-Month Functional Outcome in Italian Stroke Patients Eligible for in-Hospital Rehabilitation. Am. J. Phys. Med. Rehabil. 2018, 97, 467–475. [Google Scholar] [CrossRef] [PubMed]
- Lu, L.; Tan, Y.; Klaic, M.; Galea, M.P.; Khan, F.; Oliver, A.; Mareels, I.; Oetomo, D.; Zhao, E. Evaluating Rehabilitation Progress Using Motion Features Identified by Machine Learning. IEEE Trans. Biomed. Eng. 2021, 68, 1417–1428. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; ISBN 978-0-387-31073-2. [Google Scholar]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Volume 3951, pp. 430–443. [Google Scholar]
- Bradski, G.; Kaehler, A. Learning OpenCV: Computer Vision with the OpenCV Library; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2008; ISBN 0596516134. [Google Scholar]
- Khan, W.; Daud, A.; Nasir, J.A.; Amjad, T. A survey on the state-of-the-art machine learning models in the context of NLP. Kuwait J. Sci. 2016, 43, 95–113. [Google Scholar]
- Magoulas, G.D.; Prentza, A. Machine Learning in Medical Applications. In Machine Learning and Its Applications: Advanced Lectures; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2049. [Google Scholar]
- Erickson, B.J.; Korfiatis, P.; Akkus, Z.; Kline, T.L. Machine Learning for Medical Imaging. Radiographics 2017, 37, 505–515. [Google Scholar] [CrossRef] [PubMed]
- Churpek, M.M.; Yuen, T.C.; Winslow, C.; Meltzer, D.O.; Kattan, M.W.; Edelson, D.P. Multicenter Comparison of Machine Learning Methods and Conventional Regression for Predicting Clinical Deterioration on the Wards. Crit. Care Med. 2016, 44, 368–374. [Google Scholar] [CrossRef]
- Lin, W.-Y.; Chen, C.-H.; Tseng, Y.-J.; Tsai, Y.-T.; Chang, C.-Y.; Wang, H.-Y.; Chen, C.-K. Predicting post-stroke activities of daily living through a machine learning-based approach on initiating rehabilitation. Int. J. Med. Inform. 2018, 111, 159–164. [Google Scholar] [CrossRef] [PubMed]
- Wojtusiak, J.; Asadzadehzanjani, N.; Levy, C.; Alemi, F.; Williams, A.E. Computational Barthel Index: An automated tool for assessing and predicting activities of daily living among nursing home patients. BMC Med. Inform. Decis. Mak. 2021, 21, 17. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Adv. Neural. Inf. Process. Syst. 2017, 30, 3149–3157. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. Catboost: Unbiased boosting with categorical features. In Proceedings of the 32nd Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 6638–6648. [Google Scholar] [CrossRef]
- Seccia, R.; Boresta, M.; Fusco, F.; Tronci, E.; Di Gemma, E.; Palagi, L.; Mangone, M.; Agostini, F.; Bernetti, A.; Santilli, V.; et al. Data of patients undergoing rehabilitation programs. Data Brief. 2020, 30, 105419. [Google Scholar] [CrossRef]
- Von Elm, E.; Altman, D.G.; Egger, M.; Pocock, S.J.; Gøtzsche, P.C.; Vandenbroucke, J.P. The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) statement: Guidelines for reporting observational studies. Lancet 2007, 370, 1453–1457. [Google Scholar] [CrossRef]
- Tallon-Ballesteros, J.A.; Riquelme, J.C. Deleting or Keeping Outliers for Classifier Training? In Proceedings of the 2014 Sixth World Congress on Nature and Biologically Inspired Computing, Porto, Portugal, 30 July–1 August 2014. [Google Scholar]
- Kwakkel, G.; Veerbeek, J.M.; Harmeling-van der Wel, B.C.; van Wegen, E.; Kollen, B.J.; Early Prediction of functional Outcome after Stroke (EPOS) Investigators. Diagnostic accuracy of the Barthel Index for measuring activities of daily living outcome after ischemic hemispheric stroke: Does early poststroke timing of assessment matter? Stroke 2011, 42, 342–346. [Google Scholar] [CrossRef] [PubMed]
- Opitz, D.; Maclin, R. Popular ensemble methods: An empirical study. J. Artif. Intell. Res. 1999, 11, 169–198. [Google Scholar] [CrossRef]
- Polikar, R. Ensemble based systems in decision making. IEEE Circuits Syst. Mag. 2006, 6, 3. [Google Scholar] [CrossRef]
- Rokach, L. Ensemble-based classifiers. Artif. Intell. Rev. 2010, 33, 1–39. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquauxc, G.; Gramfort, A.; Michel, V.; Thirion, B. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)? Geosci. Model. Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Cameron, A.C.; Windmeijer, F.A.G. An R-squared measure of goodness of fit for some common nonlinear regression models. J. Econom. 1997, 77, 329–342. [Google Scholar] [CrossRef]
- Shai, S.S.; Shai, B.D. Decision Trees. In Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: Cambridge, UK, 2014; pp. 212–218. [Google Scholar]
- Louppe, G.; Wehenkel, L.; Sutera, A.; Geurts, P. Understanding variable importances in forests of randomized trees. In Proceedings of the 27nd Conference on Neural Information Processing Systems, Stateline, NV, USA, 5–19 December 2013; Volume 26, pp. 431–439. [Google Scholar]
- Poulos, C.J.; Magee, C.; Bashford, G.; Eagar, K. Determining level of care appropriateness in the patient journey from acute care to rehabilitation. BMC Health Serv. Res. 2011, 11, 291. [Google Scholar] [CrossRef]
- Pellicciari, L.; Agosti, M.; Goffredo, M.; Pournajaf, S.; Le Pera, D.; De Pisi, F.; Franceschini, M.; Damiani, C. Factors Influencing Functional Outcome at Discharge: A Retrospective Study on a Large Sample of Patients Admitted to an Intensive Rehabilitation Unit. Am. J. Phys. Med. Rehabil. 2021, 100, 483–491. [Google Scholar] [CrossRef] [PubMed]
- Sessions, V.; Valtorta, M. The Effects of Data Quality on Machine Learning Algorithms. In Proceedings of the 11th International Conference on Information Quality, Cambridge, MA, USA, 10–12 November 2006; Volume 11, pp. 10–12. [Google Scholar]
- Roh, Y.; Heo, G.; Whang, S.E. A Survey on Data Collection for Machine Learning. IEEE Trans. Knowl. Data Eng. 2021, 33, 1328–1347. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Demographic Data | Neurology Patients | Orthopedic Patients |
|---|---|---|
| Number of patients | ||
| Mean age | ||
| Mean mBI at admission | ||
| Mean mBI at discharge | ||
| Mean mBI change | ||
| Mean length of hospitalization | ||
| Gender: Male% | ||
| Gender: Female% | ||
| Nationality: Italian% | ||
| Nationality: Other% |
| ADR Code | Variable Name | Type | Possible Values |
|---|---|---|---|
| COD_52 | mBI at admission | Quantitative | [0–100] |
| Age | Age | Quantitative | [18–97] |
| Gender | Gender | Categorical | {0 (M), 1 (F)} |
| COD_26 | Pathology subject to rehabilitation | Categorical | ICD9-CM |
| COD_27 | Base pathology associated to intervention | Categorical | ICD9-CM [710–739, 320–389] |
| COD_28-35 | Associated pathologies | Categorical | ICDM9-CM |
| COD_36 | Cognitive impairment | Categorical | [0 (N), 1 (Y)] |
| COD_37 | Behavior impairment | Categorical | [0 (N), 1 (Y)] |
| COD_38 | Communication/Language impairment | Categorical | [0 (N), 1 (Y)] |
| COD_39 | Sensory impairment | Categorical | [0 (N), 1 (Y)] |
| COD_40 | Manipulation impairment | Categorical | [0 (N), 1 (Y)] |
| COD_41 | Balance impairment | Categorical | [0 (N), 1 (Y)] |
| COD_42 | Locomotion impairment | Categorical | [0 (N), 1 (Y)] |
| COD_43 | Cardiovascular impairment | Categorical | [0 (N), 1 (Y)] |
| COD_44 | Respiratory system impairment | Categorical | [0 (N), 1 (Y)] |
| COD_45 | Ulcer | Categorical | [0 (N), 1 (Y)] |
| COD_46 | Sphincter control impairment | Categorical | [0 (N), 1 (Y)] |
| COD_47 | Urinary system impairment | Categorical | [0 (N), 1 (Y)] |
| COD_48 | Nutrition impairment | Categorical | [0 (N), 1 (Y)] |
| CatBoost | LightGBM | XGB |
|---|---|---|
| mBI at admission | mBI at admission | mBI at admission |
| Age | Cognitive impairment | No associated pathologies |
| No associated pathologies | Ulcer impairment | Age |
| Handling impairment | Age | Handling impairment |
| Behavior impairment | Amputees | Cognitive impairments |
| Cognitive impairments | Organ or tissue replaced by other means | Behavior impairment |
| Nutrition impairment | Urinary impairment | Nutrition impairment |
| Hypertension | No associated pathologies | Communication impairment |
| Vertebral pathology | Femur osteosynthesis | Gender |
| Control impairment | Behavior impairment | Hypertension |
| CatBoost | LightGBM | XGB |
|---|---|---|
| mBI at admission | mBI at admission | mBI at admission |
| Age | Cognitive impairment | No associated pathologies |
| No associated pathologies | Ulcers impairment | Age |
| Handling impairment | Age | Handling impairment |
| Behavior impairment | Parkinson | Cognitive impairment |
| Cognitive impairment | Organ or tissue replaced by other means | Behavior impairment |
| Nutrition impairment | Urinary impairment | Nutrition impairment |
| Hypertension | No associated pathologies | Communication impairment |
| Parkinson | Non-traumatic myelo-radiculopathies | Gender |
| Sphincter control impairment | Behavior impairments | Hypertension |
| Model | RMSE for OP | Bias | R-Squared | CI (95%) | p-Value | RMSE CV |
|---|---|---|---|---|---|---|
| xGBT | 6.71 | 4.42 | 0.862 | 78.15–83.1 | 0.77 | 6.01 |
| LightGBM | 6.59 | 4.41 | 0.868 | 79.1–82.9 | 0.79 | 5.95 |
| CatBoost | 6.8 | 4.62 | 0.84 | 78.6–83.27 | 0.76 | 6.21 |
| Our model | 6.58 | 4.5 | 0.837 | 79.21–82.92 | 0.79 | 5.91 |
| Model | RMSE for NP | Bias | R-Squared | CI (95%) | p-Value | RMSE CV |
|---|---|---|---|---|---|---|
| xGBT | 8.9 | 5.78 | 0.85 | 67.81–73.98 | 0.79 | 7.11 |
| LightGBM | 9.23 | 5.99 | 0.835 | 66.8–73.07 | 0.61 | 8.02 |
| CatBoost | 9.09 | 5.92 | 0.84 | 67.79–73.1 | 0.72 | 8.1 |
| Our model | 8.66 | 5.81 | 0.836 | 67.78–72.71 | 0.81 | 6.87 |
| First Layer | Second Layer | RMSE NP | RMSE OP |
|---|---|---|---|
| xGBT | - | 8.9 | 6.71 |
| LightGBM | - | 9.23 | 6.59 |
| CatBoost | - | 9.09 | 6.8 |
| G. Boosting | - | 9.18 | 6.91 |
| SVR | - | 11.2 | 9.17 |
| xGBT + CatBoost + LightGBM | Weighting | 9.32 | 6.77 |
| xGBT + CatBoost + G. Boosting | Weighting | 9.2 | 6.84 |
| xGBT + CatBoost + SVR | Weighting | 10.1 | 8.21 |
| xGBT + CatBoost + LightGBM | Lasso | 9.28 | 6.78 |
| xGBT + CatBoost + G. Boosting | Lasso | 9.11 | 6.81 |
| xGBT + CatBoost + SVR | Lasso | 9.91 | 8.14 |
| xGBT + CatBoost + LightGBM | Ridge | 9.01 | 6.58 |
| xGBT + CatBoost + G. Boosting | Ridge | 8.85 | 6.77 |
| xGBT + CatBoost + SVR | Ridge | 9.42 | 8.21 |
| xGBT + CatBoost + LightGBM | Kernel Ridge | 8.87 | 6.59 |
| xGBT + CatBoost + G. Boosting | Kernel Ridge | 8.66 | 6.69 |
| xGBT + CatBoost + SVR | Kernel Ridge | 9.21 | 7.92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Santilli, V.; Mangone, M.; Diko, A.; Alviti, F.; Bernetti, A.; Agostini, F.; Palagi, L.; Servidio, M.; Paoloni, M.; Goffredo, M.; et al. The Use of Machine Learning for Inferencing the Effectiveness of a Rehabilitation Program for Orthopedic and Neurological Patients. Int. J. Environ. Res. Public Health 2023, 20, 5575. https://doi.org/10.3390/ijerph20085575
Santilli V, Mangone M, Diko A, Alviti F, Bernetti A, Agostini F, Palagi L, Servidio M, Paoloni M, Goffredo M, et al. The Use of Machine Learning for Inferencing the Effectiveness of a Rehabilitation Program for Orthopedic and Neurological Patients. International Journal of Environmental Research and Public Health. 2023; 20(8):5575. https://doi.org/10.3390/ijerph20085575
Chicago/Turabian StyleSantilli, Valter, Massimiliano Mangone, Anxhelo Diko, Federica Alviti, Andrea Bernetti, Francesco Agostini, Laura Palagi, Marila Servidio, Marco Paoloni, Michela Goffredo, and et al. 2023. "The Use of Machine Learning for Inferencing the Effectiveness of a Rehabilitation Program for Orthopedic and Neurological Patients" International Journal of Environmental Research and Public Health 20, no. 8: 5575. https://doi.org/10.3390/ijerph20085575