

Early Warning of Infectious Disease Outbreaks Using Social Media and Digital Data: A Scoping Review

 , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Protocol and Definitions
2.2. Eligibility Criteria
- They report methods and results on digital surveillance of infectious diseases (e.g., influenza, COVID-19, RSV, dengue, etc.).
- They describe study design characteristics, digital data sources, detection methods, temporal advantages, accuracy, and correlations with traditional surveillance systems.
- They are published in peer-reviewed journals and available as full-text, without language restrictions.
- Did not provide empirical data or focus exclusively on theoretical models lacking validation.
- Focused solely on traditional surveillance without integrating digital data.
- Presented unclear or insufficient results for extracting the required information.
2.3. PCC (Population, Concept, Context) Question
- Population (P): Studies that involve the use of digital data (e.g., social media, search engines, mobile applications) for disease surveillance in human populations.
- Concept (C): The characteristics, performance, and methods of digital disease surveillance; variables to be extracted include study design, data sources, detection methods, temporal advantages, detection rates, accuracy, among others.
- Context (C): Studies published in peer-reviewed scientific journals addressing digital surveillance of outbreaks or epidemics at local, regional, national, or global levels.
2.4. Search Strategy
2.5. Study Selection and Data Extraction
- Author and Year
- Study Design
- Digital Data Sources
- Comparison Method Employed
- Geographical Scope of the Study
- Techniques or Algorithms Used for Digital Signal Detection
- Temporal Advantage in Detection
- Reported Detection Indicators or Rates
- Measures of Precision and Performance
- Data Collection Period
- Type of Disease or Outbreak
- Specific Digital Platforms and Tools
- Data Preprocessing Methods
- Analytical Algorithms or Techniques
- Statistical and Performance Metrics
- Spatial Resolution and Temporal Granularity
- Integration with Traditional Surveillance Systems
- Keyword Selection Process
- Measurement of Media Impact
- Demographic and Usage Characteristics
2.6. Statistical Analysis
3. Results
3.1. General Study Information
3.2. Data Sources and Digital Platforms
3.3. Methods and Analytical Techniques
3.4. Performance and Early Detection
3.5. Complementary and Specific Aspects
4. Discussion
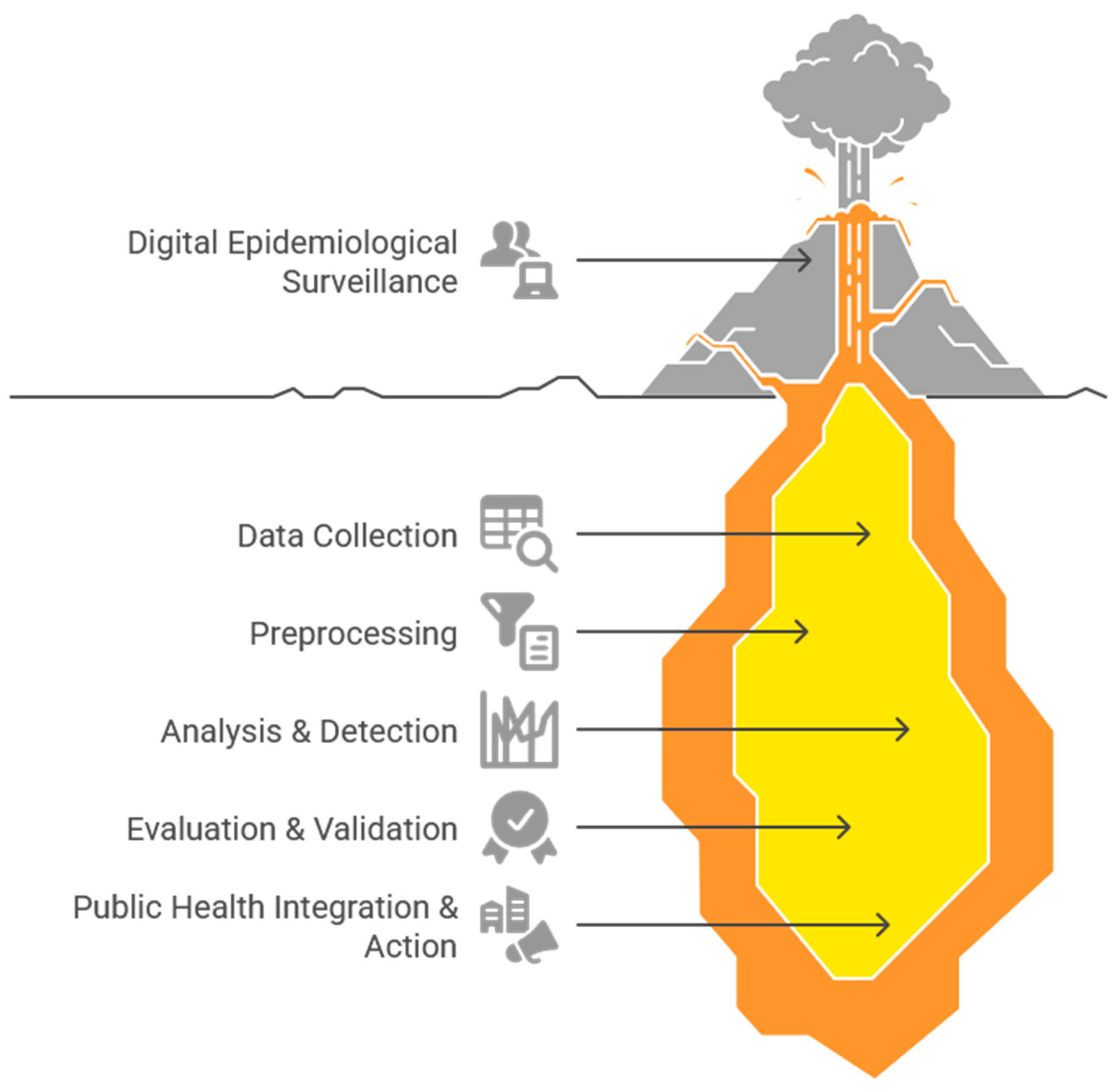
4.1. Main Findings and Methodological Evolution
4.1.1. Data Sources and Collection: The Core of Digital Syndromic Surveillance
4.1.2. Analysis and Performance: From Raw Data to Actionable Signals
4.1.3. Public Health Integration and Challenges
4.2. Comparison with Previous Literature
- Methodological Novelty: Our study integrates multiple digital sources and applies advanced machine learning techniques and time series modeling, thereby surpassing the limited scope of research focused on specific geographical or technological contexts.
- Practical Application: Systematic validation against official data and the consideration of media impact and demographic variables reinforce the operational utility of our approach, enabling early outbreak alerts with advantages of up to several weeks.
- Contextualization of Limitations: Whereas previous studies point out limitations in generalization and methodological heterogeneity, our work links these shortcomings with previous empirical evidence and proposes specific strategies (such as improved keyword selection and multi-source integration) to overcome them in future research.
4.3. Methodological Considerations
4.3.1. Discussion of Specific Techniques
4.3.2. Clarity in the Integration Process
4.3.3. Keyword Selection and Management of Media Impact
4.4. Study Limitations
4.5. Clinical Implications and Recommendations for Future Research
4.5.1. Clear and Actionable Recommendations
- Use of Emerging Technologies: The adoption of artificial intelligence tools and advanced techniques, such as metagenomic analysis, could optimize outbreak detection. It is recommended to implement automated classification and filtering techniques to analyze large volumes of data, thereby increasing the sensitivity and predictive capacity of digital systems, particularly when combined with traditional surveillance sources [68].
- Mitigation of Media-Driven Noise: To counteract the effects of the infodemic, models should be designed to distinguish between general “chatter” and true symptom-related signals. This could involve multi-stream analysis that compares symptom searches against news trends or the integration of data sources less susceptible to media influence, such as participatory surveillance systems.
- Longitudinal Evaluations: It is suggested to conduct long-term follow-up studies that evaluate the efficacy, stability, and cost-effectiveness of digital systems in various epidemiological contexts. This approach would not only provide robust evidence on the sustainability of digital surveillance but also help refine and improve predictive models over time.
4.5.2. Interdisciplinary Perspective
- Integrating Technical and Contextual Knowledge: Technology specialists can optimize algorithms and predictive models, while epidemiologists contribute their understanding of disease dynamics and social scientists provide insights into cultural, demographic, and behavioral factors that are essential for interpreting digital signals.
- Designing Adapted and Equitable Interventions: This collaborative approach will facilitate the design of public health interventions that are both precise and adapted to local realities, maximizing the impact on outbreak prevention and control.
- Developing Holistic Solutions: By combining skills and knowledge from various disciplines, it is possible to develop comprehensive solutions that address both operational and ethical aspects, ensuring that digital surveillance is implemented responsibly and with high standards of effectiveness.
4.6. From Prediction to Action: Early Warning Mechanisms and Their Impact
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CDC | Centers for Disease Control and Prevention |
| HPA | Health Protection Agency |
| PAHO | Pan American Health Organization |
| WHO | World Health Organization |
| API | Application programming interface |
| GPHIN | Global Public Health Intelligence Network |
| MEM | Moving epidemic method |
| RT-PCR | Reverse transcription-polymerase chain reaction |
| NPIs | Non-pharmaceutical interventions |
| DON | Disease Outbreak News |
| ANOVA | Analysis of variance |
| LASSO | Least absolute shrinkage and selection operator |
| LOESS | Locally estimated scatterplot smoothing |
| ROC | Receiver operating characteristic |
| AIC | Akaike information criterion |
| SSD | Sum of squared differences |
| ARIMA | Autoregressive integrated moving average |
| ARIMA | ARIMA with exogenous variables |
| SVM | Support vector machine |
| OLS | Ordinary least squares |
| RMSE | Root mean square error |
| MAE | Mean absolute error |
| MAPE | Mean absolute percentage error |
| AUC | Area under the curve |
| R2 | Coefficient of determination |
| ρ (rho) | Correlation coefficient |
| Re | Effective reproduction number |
References
- Fallatah, D.; Adekola, H.A. Digital Epidemiology: Harnessing Big Data for Early Detection and Monitoring of Viral Outbreaks. Infect. Prev. Pract. 2024, 6, 100382. [Google Scholar] [CrossRef]
- MacIntyre, C.R.; Lim, S.; Gurdasani, D.; Miranda, M.; Metcalf, D.; Quigley, A.L.; Hutchinson, D.; Burr, A.; Heslop, D.J. Early Detection of Emerging Infectious Diseases—Implications for Vaccine Development. Vaccine 2023, 42, 1826–1830. [Google Scholar] [CrossRef] [PubMed]
- O’Shea, J. Digital Disease Detection: A Systematic Review of Event-Based Internet Biosurveillance Systems. Int. J. Med. Inform. 2017, 101, 15–22. [Google Scholar] [CrossRef]
- Shausan, A.; Nazarathy, Y.; Dyda, A. Emerging Data Inputs for Infectious Diseases Surveillance and Decision Making. Front. Digit. Health 2023, 5, 1131731. [Google Scholar] [CrossRef]
- Dai, Y.; Wang, J. Identifying the Outbreak Signal of COVID-19 before the Response of the Traditional Disease Monitoring System. PLoS Negl. Trop. Dis. 2020, 14, e0008758. [Google Scholar] [CrossRef] [PubMed]
- Kogan, N.E.; Clemente, L.; Liautaud, P.; Kaashoek, J.; Link, N.B.; Nguyen, A.T.; Lu, F.S.; Huybers, P.; Resch, B.; Havas, C.; et al. An Early Warning Approach to Monitor COVID-19 Activity with Multiple Digital Traces in near Real Time. Sci. Adv. 2021, 7, eabd6989. [Google Scholar] [CrossRef] [PubMed]
- Perlaza, C.L.; Cruz Mosquera, F.E.; Moreno Reyes, S.P.; Tovar Salazar, S.M.; Cruz Rojas, A.F.; España Serna, J.D.; Liscano, Y. Sociodemographic, Clinical, and Ventilatory Factors Influencing COVID-19 Mortality in the ICU of a Hospital in Colombia. Healthcare 2024, 12, 2294. [Google Scholar] [CrossRef]
- Shin, S.-Y.; Seo, D.-W.; An, J.; Kwak, H.; Kim, S.-H.; Gwack, J.; Jo, M.-W. High Correlation of Middle East Respiratory Syndrome Spread with Google Search and Twitter Trends in Korea. Sci. Rep. 2016, 6, 32920. [Google Scholar] [CrossRef]
- Poirel, L.; Vuillemin, X.; Kieffer, N.; Mueller, L.; Descombes, M.-C.; Nordmann, P. Identification of FosA8, a Plasmid-Encoded Fosfomycin Resistance Determinant from Escherichia Coli, and Its Origin in Leclercia Adecarboxylata. Antimicrob. Agents Chemother. 2019, 63, 10–1128. [Google Scholar] [CrossRef]
- Samaras, L.; García-Barriocanal, E.; Sicilia, M.-A. Comparing Social Media and Google to Detect and Predict Severe Epidemics. Sci. Rep. 2020, 10, 4747. [Google Scholar] [CrossRef]
- Budd, J.; Miller, B.S.; Manning, E.M.; Lampos, V.; Zhuang, M.; Edelstein, M.; Rees, G.; Emery, V.C.; Stevens, M.M.; Keegan, N.; et al. Digital Technologies in the Public-Health Response to COVID-19. Nat. Med. 2020, 26, 1183–1192. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Rosen, R.; Grace, W.; Alden, D. Case Report: A Case of Adult Nesidioblastosis. HPB 2022, 24, S328. [Google Scholar] [CrossRef]
- Dhewantara, P.W.; Lau, C.L.; Allan, K.J.; Hu, W.; Zhang, W.; Mamun, A.A.; Soares Magalhães, R.J. Spatial Epidemiological Approaches to Inform Leptospirosis Surveillance and Control: A Systematic Review and Critical Appraisal of Methods. Zoonoses Public Health 2019, 66, 185–206. [Google Scholar] [CrossRef]
- Nageshwaran, G.; Harris, R.C.; Guerche-Seblain, C.E. Review of the Role of Big Data and Digital Technologies in Controlling COVID-19 in Asia: Public Health Interest vs. Privacy. Digit. Health 2021, 7, 20552076211002953. [Google Scholar] [CrossRef] [PubMed]
- Villanueva Parra, I.; Muñoz Diaz, V.; Martinez Guevara, D.; Cruz Mosquera, F.E.; Prieto-Alvarado, D.E.; Liscano, Y. A Scoping Review of Angiostrongyliasis and Other Diseases Associated with Terrestrial Mollusks, Including Lissachatina Fulica: An Overview of Case Reports and Series. Pathogens 2024, 13, 862. [Google Scholar] [CrossRef]
- Aiello, A.E.; Renson, A.; Zivich, P.N. Social Media- and Internet-Based Disease Surveillance for Public Health. Annu. Rev. Public Health 2020, 41, 101–118. [Google Scholar] [CrossRef]
- Ibrahim, N.K. Epidemiologic Surveillance for Controlling COVID-19 Pandemic: Types, Challenges and Implications. J. Infect. Public Health 2020, 13, 1630–1638. [Google Scholar] [CrossRef]
- Zhao, I.Y.; Ma, Y.X.; Yu, M.W.C.; Liu, J.; Dong, W.N.; Pang, Q.; Lu, X.Q.; Molassiotis, A.; Holroyd, E.; Wong, C.W.W. Ethics, Integrity, and Retributions of Digital Detection Surveillance Systems for Infectious Diseases: Systematic Literature Review. J. Med. Internet Res. 2021, 23, e32328. [Google Scholar] [CrossRef]
- Munn, Z.; Barker, T.H.; Moola, S.; Tufanaru, C.; Stern, C.; McArthur, A.; Stephenson, M.; Aromataris, E. Methodological Quality of Case Series Studies: An Introduction to the JBI Critical Appraisal Tool. JBI Evid. Synth 2020, 18, 2127–2133. [Google Scholar] [CrossRef]
- Tricco, A.C.; Lillie, E.; Zarin, W.; O’Brien, K.K.; Colquhoun, H.; Levac, D.; Moher, D.; Peters, M.D.J.; Horsley, T.; Weeks, L.; et al. PRISMA Extension for Scoping Reviews (PRISMA-ScR): Checklist and Explanation. Ann. Intern. Med. 2018, 169, 467–473. [Google Scholar] [CrossRef]
- Chiolero, A.; Buckeridge, D. Glossary for Public Health Surveillance in the Age of Data Science. J. Epidemiol. Community Health 2020, 74, 612–616. [Google Scholar] [CrossRef] [PubMed]
- Hong, R.; Walker, R.; Hovan, G.; Henry, L.; Pescatore, R. The Power of Public Health Surveillance. Dela. J. Public Health 2020, 6, 60–63. [Google Scholar] [CrossRef] [PubMed]
- Guerra, J.; Acharya, P.; Barnadas, C. Community-Based Surveillance: A Scoping Review. PLoS ONE 2019, 14, e0215278. [Google Scholar] [CrossRef] [PubMed]
- Southall, E.; Brett, T.S.; Tildesley, M.J.; Dyson, L. Early Warning Signals of Infectious Disease Transitions: A Review. J. R. Soc. Interface 2021, 18, 20210555. [Google Scholar] [CrossRef]
- Wang, R.; Jiang, Y.; Michael, E.; Zhao, G. How to Select a Proper Early Warning Threshold to Detect Infectious Disease Outbreaks Based on the China Infectious Disease Automated Alert and Response System (CIDARS). BMC Public Health 2017, 17, 570. [Google Scholar] [CrossRef]
- Yousefinaghani, S.; Dara, R.; Mubareka, S.; Sharif, S. Prediction of COVID-19 Waves Using Social Media and Google Search: A Case Study of the US and Canada. Front. Public Health 2021, 9, 656635. [Google Scholar] [CrossRef]
- Haddaway, N.R.; Page, M.J.; Pritchard, C.C.; McGuinness, L.A. PRISMA2020: An R Package and Shiny App for Producing PRISMA 2020-Compliant Flow Diagrams, with Interactivity for Optimised Digital Transparency and Open Synthesis. Campbell Syst. Rev. 2022, 18, e1230. [Google Scholar] [CrossRef]
- Lampos, V.; Majumder, M.S.; Yom-Tov, E.; Edelstein, M.; Moura, S.; Hamada, Y.; Rangaka, M.X.; McKendry, R.A.; Cox, I.J. Tracking COVID-19 Using Online Search. NPJ Digit. Med. 2021, 4, 17. [Google Scholar] [CrossRef]
- Timpka, T.; Spreco, A.; Dahlström, Ö.; Eriksson, O.; Gursky, E.; Ekberg, J.; Blomqvist, E.; Strömgren, M.; Karlsson, D.; Eriksson, H.; et al. Performance of eHealth Data Sources in Local Influenza Surveillance: A 5-Year Open Cohort Study. J. Med. Internet Res. 2014, 16, e116. [Google Scholar] [CrossRef]
- Van De Belt, T.H.; Van Stockum, P.T.; Engelen, L.J.L.P.G.; Lancee, J.; Schrijver, R.; Rodríguez-Baño, J.; Tacconelli, E.; Saris, K.; Van Gelder, M.M.H.J.; Voss, A. Social Media Posts and Online Search Behaviour as Early-Warning System for MRSA Outbreaks. Antimicrob. Resist. Infect. Control 2018, 7, 69. [Google Scholar] [CrossRef]
- Lampos, V.; Cristianini, N. Tracking the Flu Pandemic by Monitoring the Social Web. In Proceedings of the 2010 2nd International Workshop on Cognitive Information Processing, Elba, Italy, 14–16 June 2010; IEEE: Elba Island, Italy, 2010; pp. 411–416. [Google Scholar]
- McGough, S.F.; Brownstein, J.S.; Hawkins, J.B.; Santillana, M. Forecasting Zika Incidence in the 2016 Latin America Outbreak Combining Traditional Disease Surveillance with Search, Social Media, and News Report Data. PLoS Neglected Trop. Dis. 2017, 11, e0005295. [Google Scholar] [CrossRef] [PubMed]
- Wittwer, S.; Paolotti, D.; Lichand, G.; Leal Neto, O. Participatory Surveillance for COVID-19 Trend Detection in Brazil: Cross-Sectional Study. JMIR Public Health Surveill. 2023, 9, e44517. [Google Scholar] [CrossRef]
- Yan, S.J.; Chughtai, A.A.; Macintyre, C.R. Utility and Potential of Rapid Epidemic Intelligence from Internet-Based Sources. Int. J. Infect. Dis. 2017, 63, 77–87. [Google Scholar] [CrossRef]
- Strauss, R.A.; Castro, J.S.; Reintjes, R.; Torres, J.R. Google Dengue Trends: An Indicator of Epidemic Behavior. The Venezuelan Case. Int. J. Med. Inform. 2017, 104, 26–30. [Google Scholar] [CrossRef]
- Chunara, R.; Andrews, J.R.; Brownstein, J.S. Social and News Media Enable Estimation of Epidemiological Patterns Early in the 2010 Haitian Cholera Outbreak. Am. Soc. Trop. Med. Hyg. 2012, 86, 39–45. [Google Scholar] [CrossRef] [PubMed]
- Barboza, P.; Vaillant, L.; Le Strat, Y.; Hartley, D.M.; Nelson, N.P.; Mawudeku, A.; Madoff, L.C.; Linge, J.P.; Collier, N.; Brownstein, J.S.; et al. Factors Influencing Performance of Internet-Based Biosurveillance Systems Used in Epidemic Intelligence for Early Detection of Infectious Diseases Outbreaks. PLoS ONE 2014, 9, e90536. [Google Scholar] [CrossRef]
- Verma, M.; Kishore, K.; Kumar, M.; Sondh, A.R.; Aggarwal, G.; Kathirvel, S. Google Search Trends Predicting Disease Outbreaks: An Analysis from India. Healthc. Inform. Res. 2018, 24, 300. [Google Scholar] [CrossRef] [PubMed]
- Santillana, M.; Nguyen, A.T.; Dredze, M.; Paul, M.J.; Nsoesie, E.O.; Brownstein, J.S. Combining Search, Social Media, and Traditional Data Sources to Improve Influenza Surveillance. PLoS Comput. Biol. 2015, 11, e1004513. [Google Scholar] [CrossRef]
- Majumder, M.S.; Santillana, M.; Mekaru, S.R.; McGinnis, D.P.; Khan, K.; Brownstein, J.S. Utilizing Nontraditional Data Sources for Near Real-Time Estimation of Transmission Dynamics During the 2015–2016 Colombian Zika Virus Disease Outbreak. JMIR Public Health Surveill. 2016, 2, e30. [Google Scholar] [CrossRef]
- Li, L.; Gao, L.; Zhou, J.; Ma, Z.; Choy, D.F.; Hall, M.A. Can Social Media Data Be Utilized to Enhance Early Warning: Retrospective Analysis of the U.S. COVID-19 Pandemic 2021. medRxiv 2021. [Google Scholar] [CrossRef]
- Feldman, J.; Thomas-Bachli, A.; Forsyth, J.; Patel, Z.H.; Khan, K. Development of a Global Infectious Disease Activity Database Using Natural Language Processing, Machine Learning, and Human Expertise. J. Am. Med. Inform. Assoc. 2019, 26, 1355–1359. [Google Scholar] [CrossRef] [PubMed]
- Sharpe, J.D.; Hopkins, R.S.; Cook, R.L.; Striley, C.W. Evaluating Google, Twitter, and Wikipedia as Tools for Influenza Surveillance Using Bayesian Change Point Analysis: A Comparative Analysis. JMIR Public Health Surveill. 2016, 2, e161. [Google Scholar] [CrossRef]
- Porcu, G.; Chen, Y.X.; Bonaugurio, A.S.; Villa, S.; Riva, L.; Messina, V.; Bagarella, G.; Maistrello, M.; Leoni, O.; Cereda, D.; et al. Web-Based Surveillance of Respiratory Infection Outbreaks: Retrospective Analysis of Italian COVID-19 Epidemic Waves Using Google Trends. Front. Public Health 2023, 11, 1141688. [Google Scholar] [CrossRef] [PubMed]
- Lu, F.S.; Hou, S.; Baltrusaitis, K.; Shah, M.; Leskovec, J.; Sosic, R.; Hawkins, J.; Brownstein, J.; Conidi, G.; Gunn, J.; et al. Accurate Influenza Monitoring and Forecasting Using Novel Internet Data Streams: A Case Study in the Boston Metropolis. JMIR Public Health Surveill. 2018, 4, e4. [Google Scholar] [CrossRef]
- Chan, E.H.; Sahai, V.; Conrad, C.; Brownstein, J.S. Using Web Search Query Data to Monitor Dengue Epidemics: A New Model for Neglected Tropical Disease Surveillance. PLoS Negl. Trop. Dis. 2011, 5, e1206. [Google Scholar] [CrossRef]
- Wang, D.; Guerra, A.; Wittke, F.; Lang, J.C.; Bakker, K.; Lee, A.W.; Finelli, L.; Chen, Y.-H. Real-Time Monitoring of Infectious Disease Outbreaks with a Combination of Google Trends Search Results and the Moving Epidemic Method: A Respiratory Syncytial Virus Case Study. Trop. Med. Infect. Dis. 2023, 8, 75. [Google Scholar] [CrossRef] [PubMed]
- Alessa, A.; Faezipour, M. Flu Outbreak Prediction Using Twitter Posts Classification and Linear Regression With Historical Centers for Disease Control and Prevention Reports: Prediction Framework Study. JMIR Public Health Surveill. 2019, 5, e12383. [Google Scholar] [CrossRef]
- Broniatowski, D.A.; Paul, M.J.; Dredze, M. National and Local Influenza Surveillance through Twitter: An Analysis of the 2012-2013 Influenza Epidemic. PLoS ONE 2013, 8, e83672. [Google Scholar] [CrossRef]
- Shen, C.; Chen, A.; Luo, C.; Zhang, J.; Feng, B.; Liao, W. Using Reports of Symptoms and Diagnoses on Social Media to Predict COVID-19 Case Counts in Mainland China: Observational Infoveillance Study. J. Med. Internet. Res. 2020, 22, e19421. [Google Scholar] [CrossRef]
- Broniatowski, D.A.; Dredze, M.; Paul, M.J.; Dugas, A. Using Social Media to Perform Local Influenza Surveillance in an Inner-City Hospital: A Retrospective Observational Study. JMIR Public Health Surveill. 2015, 1, e5. [Google Scholar] [CrossRef]
- Eysenbach, G. How to Fight an Infodemic: The Four Pillars of Infodemic Management. J. Med. Internet. Res. 2020, 22, e21820. [Google Scholar] [CrossRef] [PubMed]
- Klimiuk, K.B.; Balwicki, Ł.W. What is infodemiology? An overview and its role in public health. Przegl. Epidemiol. 2024, 78, 81–89. [Google Scholar] [CrossRef]
- Menz, B.D.; Modi, N.D.; Sorich, M.J.; Hopkins, A.M. Health Disinformation Use Case Highlighting the Urgent Need for Artificial Intelligence Vigilance: Weapons of Mass Disinformation. JAMA Intern. Med. 2024, 184, 92–96. [Google Scholar] [CrossRef] [PubMed]
- Boyd, A.D.; Gonzalez-Guarda, R.; Lawrence, K.; Patil, C.L.; Ezenwa, M.O.; O’Brien, E.C.; Paek, H.; Braciszewski, J.M.; Adeyemi, O.; Cuthel, A.M.; et al. Potential Bias and Lack of Generalizability in Electronic Health Record Data: Reflections on Health Equity from the National Institutes of Health Pragmatic Trials Collaboratory. J. Am. Med. Inform. Assoc. 2023, 30, 1561–1566. [Google Scholar] [CrossRef]
- Al-Kenane, K.; Boy, F.; Alsaber, A.; Nafea, R.; AlMutairi, S. Digital Epidemiology of High-Frequency Search Listening Trends for the Surveillance of Subjective Well-Being during COVID-19 Pandemic. Front. Psychol. 2024, 15, 1442303. [Google Scholar] [CrossRef] [PubMed]
- Melo, C.L.; Mageste, L.R.; Guaraldo, L.; Paula, D.P.; Wakimoto, M.D. Use of Digital Tools in Arbovirus Surveillance: Scoping Review. J. Med. Internet. Res. 2024, 26, e57476. [Google Scholar] [CrossRef]
- Jia, P.; Liu, S.; Yang, S. Innovations in Public Health Surveillance for Emerging Infections. Annu. Rev. Public Health 2023, 44, 55–74. [Google Scholar] [CrossRef]
- Salathé, M.; Bengtsson, L.; Bodnar, T.J.; Brewer, D.D.; Brownstein, J.S.; Buckee, C.; Campbell, E.M.; Cattuto, C.; Khandelwal, S.; Mabry, P.L.; et al. Digital Epidemiology. PLoS Comput. Biol. 2012, 8, e1002616. [Google Scholar] [CrossRef]
- Shakeri Hossein Abad, Z.; Kline, A.; Sultana, M.; Noaeen, M.; Nurmambetova, E.; Lucini, F.; Al-Jefri, M.; Lee, J. Digital Public Health Surveillance: A Systematic Scoping Review. NPJ Digit. Med. 2021, 4, 41. [Google Scholar] [CrossRef]
- Shaweno, D.; Karmakar, M.; Alene, K.A.; Ragonnet, R.; Clements, A.C.; Trauer, J.M.; Denholm, J.T.; McBryde, E.S. Methods Used in the Spatial Analysis of Tuberculosis Epidemiology: A Systematic Review. BMC Med. 2018, 16, 193. [Google Scholar] [CrossRef]
- Sulaiman, F.; Yanti, N.S.; Lesmanawati, D.A.S.; Trent, M.J.; Macintyre, C.R.; Chughtai, A.A. Language Specific Gaps in Identifying Early Epidemic Signals—A Case Study of the Malay Language. Glob. Biosecurity 2019, 1, 1–10. [Google Scholar] [CrossRef]
- Cho, P.J.; Yi, J.; Ho, E.; Shandhi, M.M.H.; Dinh, Y.; Patil, A.; Martin, L.; Singh, G.; Bent, B.; Ginsburg, G.; et al. Demographic Imbalances Resulting From the Bring-Your-Own-Device Study Design. JMIR Mhealth Uhealth 2022, 10, e29510. [Google Scholar] [CrossRef] [PubMed]
- Ragnedda, M.; Ruiu, M.L.; Calderón-Gómez, D. Examining the Interplay of Sociodemographic and Sociotechnical Factors on Users’ Perceived Digital Skills. MaC 2024, 12, 8167. [Google Scholar] [CrossRef]
- Kostkova, P.; Saigí-Rubió, F.; Eguia, H.; Borbolla, D.; Verschuuren, M.; Hamilton, C.; Azzopardi-Muscat, N.; Novillo-Ortiz, D. Data and Digital Solutions to Support Surveillance Strategies in the Context of the COVID-19 Pandemic. Front. Digit. Health 2021, 3, 707902. [Google Scholar] [CrossRef] [PubMed]
- Brancato, V.; Esposito, G.; Coppola, L.; Cavaliere, C.; Mirabelli, P.; Scapicchio, C.; Borgheresi, R.; Neri, E.; Salvatore, M.; Aiello, M. Standardizing Digital Biobanks: Integrating Imaging, Genomic, and Clinical Data for Precision Medicine. J. Transl. Med. 2024, 22, 136. [Google Scholar] [CrossRef]
- Jacobson, L.P.; Parker, C.B.; Cella, D.; Mroczek, D.K.; Lester, B.M.; on behalf of program collaborators for Environmental influences on Child Health Outcomes; Smith, P.B.; Newby, K.L.; Catellier, D.J.; Gershon, R.; et al. Approaches to Protocol Standardization and Data Harmonization in the ECHO-Wide Cohort Study. Pediatr. Res. 2024, 95, 1726–1733. [Google Scholar] [CrossRef]
- Syrowatka, A. Leveraging Artificial Intelligence for Pandemic Preparedness and Response: A Scoping Review to Identify Key Use Cases. NPJ Digit. Med. 2021, 4, 96. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author and Year | Study Design | Data Collection Period | Location | Type of Disease or Outbreak |
|---|---|---|---|---|
| Dai et al. (2020) [5] | Quantitative comparative empirical | 2015–2020 | China | COVID-19 |
| Lampos et al. (2010) [31] | Quantitative empirical | 2009 | United Kingdom | Influenza (H1N1) |
| Lampos et al. (2021) [28] | Observational/modeling | 2011–2020 | USA, United Kingdom, Australia, etc. | COVID-19 |
| Van de Belt et al. (2018) [30] | Comparative exploratory | 2015–2017 | Netherlands | MRSA |
| Timpka et al. (2014) [29] | Open cohort | 2007–2012 | Sweden | Influenza |
| McGough et al. (2017) [32] | Retrospective multivariable forecasting | 2015–2016 | Latin America | Zika |
| Yousefinaghani et al. (2021) [26] | Observational, retrospective, and predictive | 2020 | USA and Canada | COVID-19 |
| Wittwer et al. (2023) [33] | Cross-sectional comparative | 2020 | Brazil | COVID-19 |
| Shin et al. (2016) [8] | Observational correlational | 2015 | South Korea | MERS |
| Yan et al. (2017) [34] | Systematic review | 2006–2016 | International | Various |
| Strauss et al. (2017) [35] | Observational correlational | 2004–2014 | Venezuela | Dengue |
| Chunara et al. (2012) [36] | Observational | 2011 | Haiti | Cholera |
| Barboza et al. (2014) [37] | Quantitative evaluation | 2010 | International | Various |
| Kogan et al. (2021) [6] | Early warning | 2020 | USA | COVID-19 |
| Verma et al. (2018) [38] | Cross-sectional correlational | 2016 | India | Dengue, malaria, etc. |
| Santillana et al. (2015) [39] | Machine learning | 2013–2015 | USA | Influenza (ILI) |
| Majumder et al. (2016) [40] | Retrospective | 2015–2016 | Colombia | Zika |
| Samaras et al. (2020) [10] | Comparative | Influenza season | Greece | Influenza |
| Li et al. (2021) [41] | Retrospective | 2020 | USA | COVID-19 |
| Feldman et al. (2019) [42] | Database development | 10 months | Global | 114 diseases |
| Sharpe et al. (2016) [43] | Retrospective comparative | 2012–2015 | USA | Influenza (ILI) |
| Porcu et al. (2023) [44] | Retrospective | 2020–2021 | Italy | COVID-19 |
| Lu et al. (2018) [45] | Retrospective observational | 2012–2016 | Boston, USA | Influenza |
| Chan et al. (2011) [46] | Real-time monitoring | 2003–2010 | Bolivia, Brazil, India, etc. | Dengue |
| Wang et al. (2023) [47] | Outbreak prediction | 5 years | Japan, Germany, Belgium | RSV |
| Alessa and Faezipour (2019) [48] | Retrospective observational | 2018 | USA (Connecticut) | Influenza |
| Broniatowski et al. (2013) [49] | Observational infoveillance | 2012–2013 | USA (National and NYC) | Influenza |
| Shen et al. (2020) [50] | Retrospective observational | 2019–2020 | China | COVID-19 |
| Broniatowski et al. (2015) [51] | Retrospective observational study | 20 November 2011—16 March 2014 | Baltimore, Maryland, USA (inner-city hospital) | Influenza |
| Author and Year | Specific Digital Platforms and Tools | Integration with Traditional Surveillance Systems |
|---|---|---|
| Dai et al. (2020) [5] | Baidu Search Engine | Comparison with the traditional case reporting system |
| Lampos et al. (2010) [31] | X | Calibration of the “flu-score” with HPA data |
| Lampos et al. (2021) [28] | Google Search and news data | Comparison with official case and death data |
| Van de Belt et al. (2018) [30] | Coosto (social media monitoring) and Google Trends | Comparison with official notifications in the SO ZI/AMR system |
| Timpka et al. (2014) [29] | Google Flu Trends, Healthcare Direct/1177, Google Analytics | Comparison with clinical and laboratory data on influenza |
| McGough et al. (2017) [32] | Google Search, X, HealthMap | Integration with Zika data reported by PAHO and health ministries |
| Yousefinaghani et al. (2021) [26] | X API and Google Trends | Comparison with official data (Johns Hopkins COVID-19) |
| Wittwer et al. (2023) [33] | Brazil Sem Corona and GitHub data | Integration with PS and TS data to improve prediction |
| Shin et al. (2016) [8] | Google Trends, Topsy | Comparison with official MERS data |
| Yan et al. (2017) [34] | Google Flu Trends, Google Trends, Baidu, X, ProMED-mail, HealthMap | Discussion on complementarity with traditional systems |
| Strauss et al. (2017) [35] | Google Dengue Trends | Comparison and proposal for complementarity with the surveillance system |
| Chunara et al. (2012) [36] | HealthMap and X | Comparison with official data from the MSPP |
| Barboza et al. (2014) [37] | Argus, BioCaster, GPHIN, HealthMap, MedISys, ProMED-mail | Comparative evaluation with official BHI data |
| Kogan et al. (2021) [6] | Google Trends, X, UpToDate, GLEAM, Apple Mobility, Cuebiq, Kinsa Thermometer | Integration of digital proxies with cases, deaths, and ILI |
| Verma et al. (2018) [38] | Google Trends and Google Correlate | Comparison with the IDSP surveillance system |
| Santillana et al. (2015) [39] | Google Trends, X, athenahealth, FluNearYou | Comparison of predictions with CDC reports |
| Majumder et al. (2016) [40] | HealthMap and Google Trends | Validation with official INS data |
| Samaras et al. (2020) [10] | Google Trends, X API (Tweepy and Pytrends) | Comparison with official influenza data in Europe |
| Li et al. (2021) [41] | X Standard Search API | Comparison with official systems based on searches and news |
| Feldman et al. (2019) [42] | GDELT Global Knowledge Graph and Google Translate API | Comparison with WHO (DON) reports |
| Sharpe et al. (2016) [43] | Google Flu Trends, HealthTweets, Wikipedia | Comparison with CDC official reports |
| Porcu et al. (2023) [44] | Google Trends | Validation with RT-PCR data |
| Lu et al. (2018) [45] | Google Trends, X, athenahealth, Flu Near You | Validation with data from the Boston Public Health Commission |
| Chan et al. (2011) [46] | Google Search queries | Comparison with data from ministries of health and WHO |
| Wang et al. (2023) [47] | Google Trends | Complement for clinical surveillance |
| Alessa and Faezipour (2019) [48] | X | Validation with CDC and hospital data |
| Broniatowski et al. (2013) [49] | X API (HealthTweets and Google Flu Trends) | Validation with CDC and NYC Department of Health reports |
| Shen et al. (2020) [50] | Comparison with official data from the China CDC | |
| Broniatowski et al. (2015) [51] | X (HealthTweets) | Comparison with hospital data (laboratory cases and ILI in ED) |
| Author and Year | Comparison Method | Detection Method | Preprocessing | Analytical Techniques |
|---|---|---|---|---|
| Dai et al. (2020) [5] | Correlation analysis between anomalous peaks and official reports | Abnormal increase in ILI and searches (e.g., “pneumonia”, “SARS”) | Smoothing (7-day moving average) | ANOVA, linear regression, correlation |
| Lampos et al. (2010) [31] | Comparison of “flu-score” in tweets versus ILI rates | Calculation of “flu-score” from tweets | Stop word removal, stemming, smoothing | Linear regression, LASSO, supervised learning |
| Lampos et al. (2021) [28] | Comparison of online queries with official COVID-19 data | Unsupervised models and transfer learning with symptoms | Normalization and weighting of symptoms | Elastic net, Gaussian processes, correlation |
| Van de Belt et al. (2018) [30] | Comparison of outbreaks detected on social networks with official reports | Detection on social media and Google Trends | Thresholds in social media and Google Trends | Descriptive statistics, ROC analysis, correlation |
| Timpka et al. (2014) [29] | Comparison of eHealth data with clinical and laboratory cases | Correlation of eHealth data with clinical data | Weekly adjustment, detrending | Linear regression, autoregressive models, correlation |
| McGough et al. (2017) [32] | Predictive models of Zika cases with digital data | Case prediction using digital signals | Log transformations and normalization | Elastic net, cross-validation, autoregressive models |
| Yousefinaghani et al. (2021) [26] | Comparison of digital time series with COVID-19 cases | Anomaly analysis in tweets and searches | Keyword filtering and geolocation | Anomaly analysis, regression, validation |
| Wittwer et al. (2023) [33] | Comparison of self-reported infection rates with official data | Estimation of infection rates from self-reports | LOESS smoothing of fluctuations | Autoregressive models, AIC, variable combination |
| Shin et al. (2016) [8] | Correlation between digital data and official cases | Lag correlation between digital data and cases | Normalization and word selection | Spearman and lag analysis |
| Yan et al. (2017) [34] | Correlation analysis and detection of digital signals | Detection of digital signals in official reports | Categorization and noise elimination | Correlation, Bayesian algorithms, signal detection |
| Strauss et al. (2017) [35] | Comparison of digital surveillance with reported dengue cases | Digital surveillance based on dengue searches | Normalization and volume conversion | Linear regression, correlation analysis |
| Chunara et al. (2012) [36] | Correlation analysis between tweets and cholera reports | Analysis of HealthMap and X reports | Filtering and selection of key terms | Exponential fit, Euler–Lotka equation |
| Barboza et al. (2014) [37] | Evaluation of biosurveillance with media signals | Media searches validated by human assessment | Manual filtering and duplicate removal | Poisson regression, rate calculations |
| Kogan et al. (2021) [6] | Comparison of digital proxies with case and death data | Modeling digital proxies and official data | Smoothing and scaling of digital proxies | Exponential growth, harmonic mean, correlation |
| Verma et al. (2018) [38] | Correlation between search patterns and outbreaks in India | Identification of terms in Google Correlate | Selection of terms in Google Correlate | Correlation analysis and time series analysis |
| Santillana et al. (2015) [39] | Prediction of ILI by combining multiple digital sources | Prediction of ILI activity using multiple proxies | Normalization and mapping of digital sources | LASSO regression, SVM, AdaBoost |
| Majumder et al. (2016) [40] | Estimation of Zika transmission using digital data | Modeling Zika transmission with IDEA | Scaling and smoothing of Google Trends | Non-linear optimization, SSD minimization |
| Samaras et al. (2020) [10] | Predictive modeling of influenza with ARIMA | Epidemic activity prediction using ARIMA | Elimination of duplicates in X | ARIMA(X) models, predictive analysis |
| Li et al. (2021) [41] | Classification of COVID-19 tweets and lead time analysis | Classification of tweets as COVID-19 alerts | Tokenization and lemmatization of tweets | Supervised classification and sentiment analysis |
| Feldman et al. (2019) [42] | Validation of outbreak detection with WHO reports | Outbreak detection in news articles | Automatic translation and tag-based filtering | Naïve Bayes, SVM, bidirectional LSTM |
| Sharpe et al. (2016) [43] | Detection of changes in time series using Bayesian methods | Identification of change points in time series | Normalization and weekly grouping | Bayesian change point models |
| Porcu et al. (2023) [44] | Detection of outliers in searches using ARMA and EWMA | Detection of epidemic signals in searches | Scaling adjustment from 0 to 100 | ARMA, EWMA, outlier detection |
| Lu et al. (2018) [45] | Comparison of ARGO models vs. simple autoregressives | Prediction of influenza with ensemble models | Filtering out irrelevant terms | Multivariable regression and ensemble methods |
| Chan et al. (2011) [46] | Fitting linear models to dengue searches | Univariate linear regression with dengue searches | Replacement of spurious peaks | Univariate linear regression |
| Wang et al. (2023) [47] | Correlation between Google Trends and clinical surveillance | Definition of thresholds with the Moving Epidemic Method | Exclusion of atypical years (2020–2021) | Moving Epidemic Method (MEM) |
| Alessa and Faezipour (2019) [48] | Classification of tweets with FastText and linear regression | Regression and classification of tweets | Stemming and stop word removal | FastText and linear regression |
| Broniatowski et al. (2013) [49] | Tweet filtering for influenza detection | Supervised classification of influenza tweets | Filtering in tweet stages | SVM, logistic regression |
| Shen et al. (2020) [50] | Granger causality analysis between “sick posts” and case counts | Case prediction using Granger causality and supervised models | Classification into “sick” versus others | Random forest classifier and OLS regression |
| Broniatowski et al. (2015) [51] | Estimation of influenza prevalence using tweets and counts | Estimation of ILI prevalence from X | Normalization of tweet volumes | ARIMAX analysis and logistic regression |
| Author and Year | Lead Time | Detection Rate | Precision |
|---|---|---|---|
| Dai et al. (2020) [5] | 20 days before the official alert | High correlations; no specific rate reported | High correlation coefficients |
| Lampos et al. (2010) [31] | Tweets within hours; HPA takes 1–2 weeks | Correlations 81.78–85.56% | Cross-validation ~89–94% |
| Lampos et al. (2021) [28] | Cases: 16.7 days before, deaths: 22.1 days before | Correlation r ≈ 0.82–0.85 | Evaluated with AUC and MAE |
| van de Belt et al. (2018) [30] | Outbreaks detected 1–2 days earlier | Sensitivity 20%, specificity 96% | AUC, sensitivity, specificity |
| Timpka et al. (2014) [29] | GFT 2 weeks earlier; telenursing varies | GFT r = 0.96, telenursing r ≈ 0.95–0.97 | Pearson r, RMSE |
| McGough et al. (2017) [32] | Forecasts 1–3 weeks earlier | Measured by predictive error (rRMSE) | RMSE, rRMSE, Pearson ρ |
| Yousefinaghani et al. (2021) [26] | 83% of waves detected 1 week early | 100% of symptoms detected in US Category I | RMSE, MAE, correlations > 75% |
| Wittwer et al. (2023) [33] | Lead time depends on participation | High correlation in cities with good participation | RMSE, MAE, Pearson correlation |
| Shin et al. (2016) [8] | 3–4 days prior to confirmation | Correlations > 0.7, up to 0.9 | Significant correlations (p < 0.05) |
| Yan et al. (2017) [34] | 1–12 days before official reports | Alerts 1–12 days early, variable correlation | Moderate to high depending on the method |
| Strauss et al. (2017) [35] | Early alert before update | r = 0.87 during epidemic weeks | R2 = 0.75 in regression |
| Chunara et al. (2012) [36] | Daily updates; official data delayed 1–2 days | ρ ≈ 0.80 during growth phases | Variability in Re (1.54 to 6.89) |
| Barboza et al. (2014) [37] | Detects events before publication | C-DR 83–95%, I-DR 47–92% | Statistical differences in I-Se |
| Kogan et al. (2021) [6] | Case increases 2–3 weeks earlier | Combined sensitivity up to 0.75 | Precision 0.90–0.98 in proxies |
| Verma et al. (2018) [38] | Google Trends anticipates 2–3 weeks | r > 0.80 for chikungunya and dengue | Chikungunya r = 0.82–0.87 |
| Santillana et al. (2015) [39] | Prediction up to 4 weeks before | Real-time prediction r = 0.989 | RMSE 0.176% ILI, reduced MAPE |
| Majumder et al. (2016) [40] | Near real-time estimates | No detection rate reported; estimation of R0 | Good SSD model fit |
| Samaras et al. (2020) [10] | Searches and tweets anticipate 2–3 weeks | Pearson R ≈ 0.933–0.943 | MAPE ≈ 18.7–22.6% |
| Li et al. (2021) [41] | Detects signals 16 days in advance | Signal strategy identifies alerts | High classification precision |
| Feldman et al. (2019) [42] | Outbreaks detected on average 43.4 days earlier | 94% of outbreaks detected before WHO | Recall 88.8%, precision 86.1% |
| Sharpe et al. (2016) [43] | Google alerts changes 1–2 weeks earlier | Google: sensitivity 92%, PPV 85% | Google shows the best performance |
| Porcu et al. (2023) [44] | Epidemics detected 7–8 weeks before | PPV 80% in Lombardy, <50% in Marche | High correlation in areas with high connectivity |
| Lu et al. (2018) [45] | Nowcasting and forecasting 1 week ahead | Correlations of 0.98 (nowcast) and 0.94 (forecast) | Low RMSE, MAE, and MAPE |
| Chan et al. (2011) [46] | Real-time available data | Correlations 0.82–0.99 | Good correlation fit |
| Wang et al. (2023) [47] | Almost immediate data | Japan r = 0.87, Germany r = 0.65 | Good threshold estimation |
| Alessa and Faezipour (2019) [48] | Almost real-time | 96.29% correlation with CDC | F-measure 89.9% |
| Broniatowski et al. (2013) [49] | Tweets available up to 2 weeks in advance | National r = 0.93, municipal r = 0.88 | Lower MAE in the infection model |
| Shen et al. (2020) [50] | Predicts cases 14 days earlier | Sick posts explain 12.8% of variance | High standardized coefficients |
| Broniatowski et al. (2015) [51] | Tweets ahead of official data | High correlation at the municipal level | 85% accuracy in trend prediction |
| Author and Year | Spatial Resolution and Temporal Granularity | Keyword Selection Process | Measurement of Media Impact | Demographic and Usage Characteristics |
|---|---|---|---|---|
| Dai et al. (2020) [5] | Regional (Wuhan, China); daily and weekly data | Manual selection (“pneumonia”, “SARS”) | Not evaluated | Not specified |
| Lampos et al. (2010) [31] | Urban centers (10 km radius); daily and weekly aggregation | Manual selection and LASSO | Not directly measured | 5.5 million X users (United Kingdom) |
| Lampos et al. (2021) [28] | National; daily data | 19 symptom-based sets | Minimizes panic effect in the autoregressive model | Application in multiple countries, no demographic details |
| Van de Belt et al. (2018) [30] | Provinces; daily data | Boolean searches in Google Trends | Not explicitly evaluated | Geographic information by province |
| Timpka et al. (2014) [29] | County; daily data | ICD-10 and grouping in telenursing | Correlation between media coverage and GFT | Age distribution in RIR |
| McGough et al. (2017) [32] | National; weekly data | LASSO and penalized regression | Not measured; low influence mentioned | Data profiles by country, no demographics |
| Yousefinaghani et al. (2021) [26] | States/provinces; weekly data | Predefined symptom lists | Indirect impact by comparing preventive term usage | Geolocation of tweets by state/province |
| Wittwer et al. (2023) [33] | Municipalities; daily data | Questionnaire based on COVID-19 symptoms | Impact of media campaigns on participation | Participation rates and urban differences |
| Shin et al. (2016) [8] | National; daily data | Basic and extended terms (“MERS”, “hospital”) | Recognizes media noise | Aggregated search and tweet data |
| Yan et al. (2017) [34] | Local/global; daily to weekly data | Relevance and specificity-based selection | Evaluation of media noise | Lack of detailed user data |
| Strauss et al. (2017) [35] | National; weekly data | Spanish terms for dengue | Annual variation in searches vs. incidence | Impact of internet penetration |
| Chunara et al. (2012) [36] | Departments and arrondissements; daily data | Searches for “cholera” and hashtags | Media amplification effect | Geographic and demographic biases |
| Barboza et al. (2014) [37] | Country-level events; monthly data | Defined by epidemiologists | Comparison of media and official source signals | Language distribution and regional impact |
| Kogan et al. (2021) [6] | States; daily data | COVID-19-related terms | Analysis of bias in digital proxies | Differences in activity and adherence to NPIs |
| Verma et al. (2018) [38] | States; weekly data | Terms with high correlation (Google Correlate) | Search explosion preceding the report | Internet penetration in Haryana and Chandigarh |
| Santillana et al. (2015) [39] | National; weekly data | Terms based on previous studies | Captures media effects in search variation | Aggregated national level, no demographic details |
| Majumder et al. (2016) [40] | National; aggregated data | Keyword “Zika” in Google Trends | Comparison of curves, not evaluating noise | Aggregated data, no demographic details |
| Samaras et al. (2020) [10] | National (Greece); aggregated data | Terms in Greek | Media bias in searches and tweets | Limitations in tweet geolocation |
| Li et al. (2021) [41] | State-level (USA); daily data | Keyword “coronavirus” | Signal ratio as an indicator of public opinion | Filtered by location in the USA |
| Feldman et al. (2019) [42] | Global; updates every 15 min | Filtering by GDELT and name databases | Lead time of 43.4 days and 94% outbreak coverage | No demographic characteristics; only media data |
| Sharpe et al. (2016) [43] | National; weekly data | Implicit terms in each source | Evaluation of discrepancies in changes | Aggregated data, no demographic details |
| Porcu et al. (2023) [44] | Regions (Italy); weekly data | Italian translation of symptoms | Search volume as a proxy for alerts | Variability in internet access by region |
| Lu et al. (2018) [45] | City; weekly data | Specific terms for Boston | Media influence in method comparison | Emergency room visits (age, gender, ethnicity) |
| Chan et al. (2011) [46] | National; weekly/monthly data | Selection based on correlation with official data | Not reported | Not reported |
| Wang et al. (2023) [47] | National and regional; weekly data | Term “RSV” or “RS virus” | Mitigation of media impact with MEM | No specific details reported |
| Alessa and Faezipour (2019) [48] | State (Connecticut); weekly data | 11 verified keywords | Not directly measured | No demographic characteristics detailed |
| Broniatowski et al. (2013) [49] | Municipal, regional, and national; weekly data | Keyword list and previous models | Sensitive to media “chatter” | Possible biases due to underrepresentation of users |
| Shen et al. (2020) [50] | National and provincial; daily data | 167 keywords per daily observation | Comparison between “sick posts” and other posts | User pool with age and gender composition |
| Broniatowski et al. (2015) [51] | Municipal (hospital); weekly data | 269 health-related terms filtered in stages | Filtering to reduce media “chatter” | Data from pediatric and adult patients |
| Use Case/ Purpose | Typical Platforms | Common Diseases | Contextual Considerations (High vs. Low Resources) |
|---|---|---|---|
| Real-Time Monitoring (“Nowcasting”) | X API, participatory systems (FluNearYou), news data (GDELT) | Influenza, COVID-19, Cholera | High resource: Integration of multiple real-time data streams. Low resource: Reliance on free social media platforms. |
| Retrospective Analysis and Modeling | Google Trends archives, historical social media data | Dengue, Zika, MERS | High and low resource: Accessible in both contexts, as historical data are often freely available. |
| Predictive Forecasting | Combination of multiple sources (search queries, social media, clinical data) | Influenza, COVID-19, RSV | High resource: Requires high-quality longitudinal data and computational power for complex ML models. Low resource: More challenging; often relies on simpler time series models. |
| Authors/Study | Objective/Scope | Methodology/ Techniques | Data Sources | Key Findings | Impact/ Context | Advantages/ Disadvantages |
|---|---|---|---|---|---|---|
| This study (2025) | To evaluate the use of social media and digital sources for early detection of infectious disease outbreaks. | Retrospective and predictive analysis; use of machine learning, correlations, and time series analysis. | X, Google Trends, health forums, news databases, epidemiological records. | Outbreaks anticipated several weeks in advance; high correlation with official reports. | Impact of media context and digital penetration on data quality. | ✔ Integration of multiple digital sources; validation with official data. ✘ Variability in data representativeness depending on region and digital access. |
| Al-Kenane et al. (2024) [56] | Relationship between Google Trends searches and government response in Kuwait. | Time series analysis; Pearson and bootstrap. | Google Trends (English and Arabic). | High correlation (R ~ 0.71); anticipates policy changes. | Incorporates bilingual analysis and effects of government measures. | ✔ Innovative and robust approach. ✘ Limited to Kuwait and psychological variables. |
| Melo et al. (2024) [57] | To evaluate digital tools for arbovirus surveillance and early detection. | Review with comparative analysis; ANOVA and correlations. | Google Trends, X, apps, social media, and official data. | Early detection (days to weeks); high precision in outbreak prediction. | Considers media influence and spatial data resolution. | ✔ Comprehensive comparison of tools and contexts. ✘ High variability between studies. |
| Peng Jia et al. (2023) [58] | Review of technological innovations (AI, GIS, digital twins) in epidemiological surveillance. | Synthesis in Annual Review of Public Health. | Geospatial data, EHRs, big data, electronic reporting. | Improved accuracy, timeliness, and real-time detection. | Impact of smart devices and digital evolution in public health. | ✔ Highlights key advances in surveillance. ✘ Study heterogeneity; requires integration with other systems. |
| Zhao et al. (2021) [18] | Ethical analysis of digital surveillance in infectious diseases. | Systematic review with theoretical focus on privacy and civil rights. | Big data, EHRs, digital surveillance. | Assesses ethical risks vs. benefits; correlation with official reports. | Emphasizes the need to balance surveillance and privacy. | ✔ Strong theoretical framework on digital surveillance ethics. ✘ Does not address operational metrics. |
| Salathé et al. (2012) [59] | Impact of big data and social media on digital epidemiology. | Narrative review and Editors’ Outlook. | Social media, mobile phones, online searches. | Reduced outbreak detection times. | Potential for early alerts vs. technical and bias challenges. | ✔ Pioneer in digital epidemiology. ✘ Lacks detailed error metrics. |
| Method/Technique | Strengths | Limitations | Ideal Use Case and Examples |
|---|---|---|---|
| Correlation and Linear Regression [56,57] | Simple, interpretable—Low computational cost | Assumes linearity—Sensitive to outliers (e.g., media panic spikes) | Initial validation of digital data relevance in disease monitoring. |
| Time Series Models (e.g., ARIMA) [10,51] | Strong for forecasting—Handles seasonality | Less flexible to sudden changes—Requires data transformation | Short-term forecasts for diseases with seasonal patterns (e.g., flu, RSV). |
| Supervised ML (e.g., SVM, LASSO, RF) [18,39,58] | Captures complex patterns—Variable selection (e.g., LASSO) | Risk of overfitting—Opaque (“black box”)—Needs large datasets | Integrating diverse sources (searches, mobility, social media) into predictive models. |
| Natural Language Processing (NLP) [42,57] | Extracts insights from unstructured text—Captures context and nuance | Sensitive to slang/errors—Ambiguity in word meaning | Sentiment and symptom mining from social media for real-time public health signals. |
| Bayesian Methods [43] | Quantifies uncertainty—Updates with new evidence | Computationally intensive—Sensitive to prior assumptions | Change-point detection in disease trends, e.g., outbreak onset. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liscano, Y.; Anillo Arrieta, L.A.; Montenegro, J.F.; Prieto-Alvarado, D.; Ordoñez, J. Early Warning of Infectious Disease Outbreaks Using Social Media and Digital Data: A Scoping Review. Int. J. Environ. Res. Public Health 2025, 22, 1104. https://doi.org/10.3390/ijerph22071104
Liscano Y, Anillo Arrieta LA, Montenegro JF, Prieto-Alvarado D, Ordoñez J. Early Warning of Infectious Disease Outbreaks Using Social Media and Digital Data: A Scoping Review. International Journal of Environmental Research and Public Health. 2025; 22(7):1104. https://doi.org/10.3390/ijerph22071104
Chicago/Turabian StyleLiscano, Yamil, Luis A. Anillo Arrieta, John Fernando Montenegro, Diego Prieto-Alvarado, and Jorge Ordoñez. 2025. "Early Warning of Infectious Disease Outbreaks Using Social Media and Digital Data: A Scoping Review" International Journal of Environmental Research and Public Health 22, no. 7: 1104. https://doi.org/10.3390/ijerph22071104
APA StyleLiscano, Y., Anillo Arrieta, L. A., Montenegro, J. F., Prieto-Alvarado, D., & Ordoñez, J. (2025). Early Warning of Infectious Disease Outbreaks Using Social Media and Digital Data: A Scoping Review. International Journal of Environmental Research and Public Health, 22(7), 1104. https://doi.org/10.3390/ijerph22071104