Leveraging Large Language Models for High-Quality Lay Summaries: Efficacy of ChatGPT-4 with Custom Prompts in a Consecutive Series of Prostate Cancer Manuscripts

 ,
,  , , , , , ,
, , , , , ,  and
and 
Abstract
1. Introduction
2. Materials and Methods
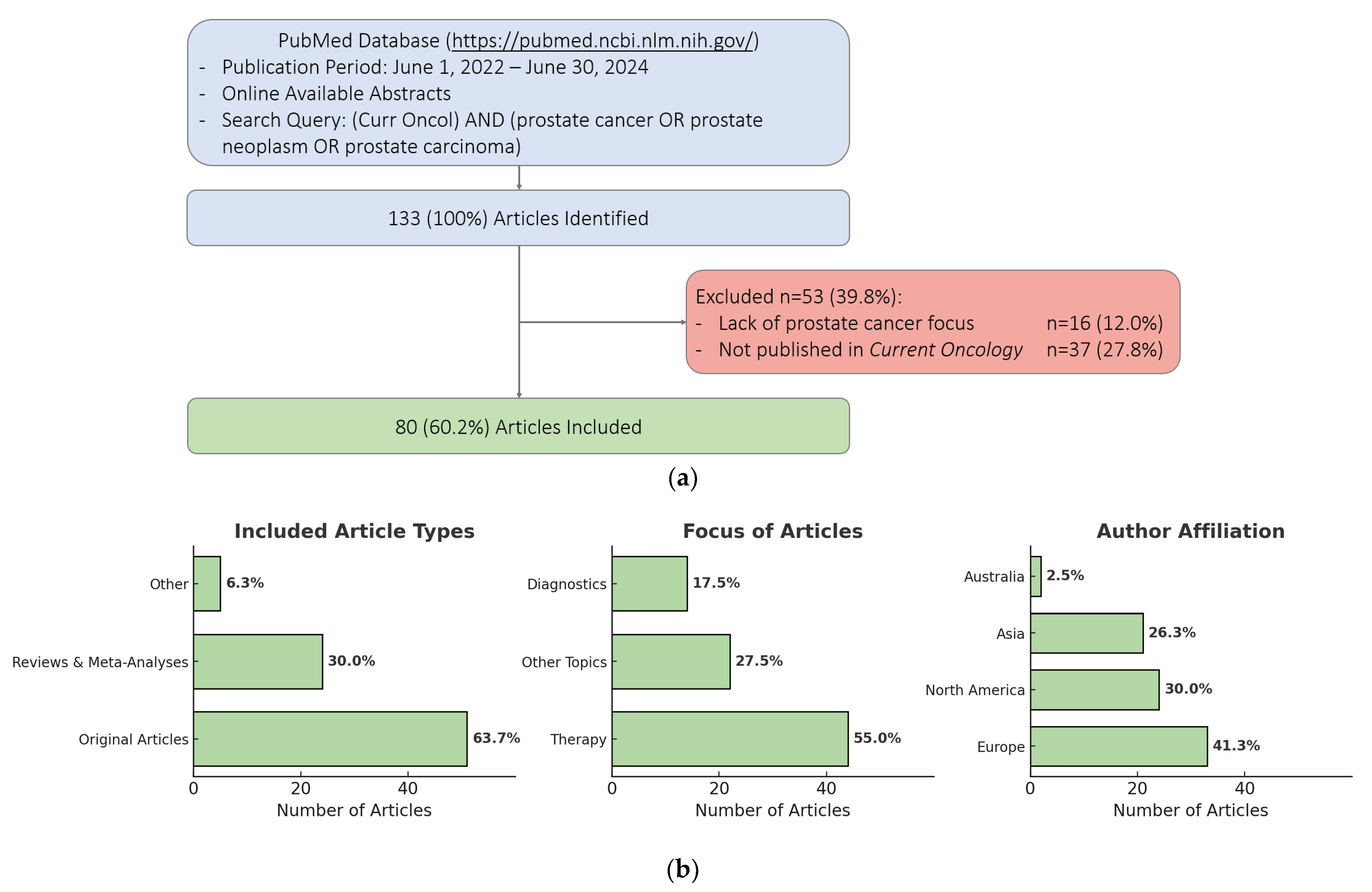
2.1. Article Selection
2.2. Development of Standardized Prompts for Data Input into ChatGPT-4
2.3. Readability Assessment
2.4. Content Assessment of the Lay Summaries and Final Evaluation
2.5. Statistical Analysis
3. Results
3.1. Article Characteristics
3.2. Evaluation of the Lay Summaries
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Barnes, A.; Patrick, S. Lay Summaries of Clinical Study Results: An Overview. Pharmaceut. Med. 2019, 33, 261–268. [Google Scholar] [CrossRef] [PubMed]
- Tenti, E.; Simonetti, G.; Bochicchio, M.T.; Martinelli, G. Main changes in European Clinical Trials Regulation (No 536/2014). Contemp. Clin. Trials Commun. 2018, 11, 99–101. [Google Scholar] [CrossRef] [PubMed]
- Guide for Authors—European Urology. Available online: https://www.europeanurology.com/guide-for-authors (accessed on 24 November 2024).
- Cancers—Instructions for Authors. Available online: https://www.mdpi.com/journal/cancers/instructions (accessed on 24 November 2024).
- European Commission. Summaries of Clinical Trial Results for Laypersons. Recommendations of the Expert Group on Clinical Trials for the Implementation of Regulation (EU) No 536/2014 on Clinical Trials on Medicinal Products for Human Use; European Commission: Brussels, Belgium, 2021. [Google Scholar]
- Ganjavi, C.; Eppler, M.B.; Ramacciotti, L.S.; Cacciamani, G.E. Clinical Patient Summaries Not Fit for Purpose: A Study in Urology. Eur. Urol. Focus 2023, 9, 1068–1071. [Google Scholar] [CrossRef] [PubMed]
- Wissing, M.D.; Tanikella, S.A.; Kaur, P.; Tomlin, H.R.; Cornfield, L.J.; Porter, A.C.; D’Cruz, S.C.; Alcala, A.M.; Capasso-Harris, H.; Tabas, L. Medical terminology and interpretation of results in plain language summaries published by oncology journals. J. Clin. Oncol. 2023, 41, e18653. [Google Scholar] [CrossRef]
- Kirkpatrick, E.; Gaisford, W.; Williams, E.; Brindley, E.; Tembo, D.; Wright, D. Understanding Plain English summaries. A comparison of two approaches to improve the quality of Plain English summaries in research reports. Res. Involv. Engagem. 2017, 3, 17. [Google Scholar] [CrossRef] [PubMed]
- Gainey, K.M.; O’Keeffe, M.; Traeger, A.C.; Muscat, D.M.; Williams, C.M.; McCaffrey, K.J.; Kamper, S.J. What instructions are available to health researchers for writing lay summaries? A scoping review. medRxiv 2021. [Google Scholar] [CrossRef]
- Rodler, S.; Maruccia, S.; Abreu, A.; Murphy, D.; Canes, D.; Loeb, S.; Malik, R.D.; Bagrodia, A.; Cacciamani, G.E. Readability Assessment of Patient Education Materials on Uro-oncological Diseases Using Automated Measures. Eur. Urol. Focus, 2024; in press. [Google Scholar] [CrossRef]
- Bromme, R.; Nueckles, M.; Rambow, R. Adaptivity and anticipation in expert-laypeople communication. In Psychological Models of Communication in Collaborative Systems; Brennan, S.E., Giboin, A., Traum, D., Eds.; AAAI Fall Symposion Series; AAAI: Menlo Park, CA, USA, 1999; pp. 17–24. [Google Scholar]
- OpenAI. GPT-4o System Card. Available online: https://cdn.openai.com/gpt-4o-system-card.pdf (accessed on 15 September 2024).
- Eppler, M.B.; Ganjavi, C.; Knudsen, J.E.; Davis, R.J.; Ayo-Ajibola, O.; Desai, A.; Ramacciotti, L.S.; Chen, A.; De Castro Abreu, A.; Desai, M.M.; et al. Bridging the Gap Between Urological Research and Patient Understanding: The Role of Large Language Models in Automated Generation of Layperson’s Summaries. Urol. Pract. 2023, 10, 436–443. [Google Scholar] [CrossRef] [PubMed]
- Shyr, C.; Grout, R.W.; Kennedy, N.; Akdas, Y.; Tischbein, M.; Milford, J.; Tan, J.; Quarles, K.; Edwards, T.L.; Novak, L.L.; et al. Leveraging artificial intelligence to summarize abstracts in lay language for increasing research accessibility and transparency. J. Am. Med. Inform. Assoc. 2024, 31, 2294–2303. [Google Scholar] [CrossRef] [PubMed]
- Goldsack, T.; Scarton, C.; Shardlow, M.; Lin, C. Overview of the biolaysumm 2024 shared task on the lay summarization of biomedical research articles. arXiv 2024, arXiv:2408.08566. [Google Scholar]
- OpenAI. Six Strategies for Getting Better Results. Available online: https://platform.openai.com/docs/guides/prompt-engineering/six-strategies-for-getting-better-results (accessed on 1 February 2025).
- You, Z.; Radhakrishna, S.; Ming, S.; Kilicoglu, H. UIUC_BioNLP at BioLaySumm: An Extract-then-Summarize Approach Augmented with Wikipedia Knowledge for Biomedical Lay Summarization. In Proceedings of the 23rd Workshop on Biomedical Natural Language Processing, Bangkok, Thailand; Demner-Fushman, D., Ananiadou, S., Miwa, M., Roberts, K., Tsujii, J., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 132–143. [Google Scholar] [CrossRef]
- Kim, H.; Raj Kanakarajan, K.; Sankarasubbu, M. Saama Technologies at BioLaySumm: Abstract based fine-tuned models with LoRA. In Proceedings of the 23rd Workshop on Biomedical Natural Language Processing, Bangkok, Thailand; Demner-Fushman, D., Ananiadou, S., Miwa, M., Roberts, K., Tsujii, J., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 786–792. [Google Scholar] [CrossRef]
- Bao, S.; Zhao, R.; Zhang, S.; Zhang, J.; Wang, W.; Ru, Y. Ctyun AI at BioLaySumm: Enhancing Lay Summaries of Biomedical Articles Through Large Language Models and Data Augmentation. In Proceedings of the 23rd Workshop on Biomedical Natural Language Processing, Bangkok, Thailand; Demner-Fushman, D., Ananiadou, S., Miwa, M., Roberts, K., Tsujii, J., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 837–844. [Google Scholar] [CrossRef]
- Eppler, M.; Ganjavi, C.; Ramacciotti, L.S.; Piazza, P.; Rodler, S.; Checcucci, E.; Rivas, J.G.; Kowalewski, K.F.; Belenchón, I.R.; Puliatti, S.; et al. Awareness and Use of ChatGPT and Large Language Models: A Prospective Cross-sectional Global Survey in Urology. Eur. Urol. 2024, 85, 146–153. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
| Simple Prompt | Extended Prompt |
|---|---|
| Dear ChatGPT-4, I kindly request your assistance in crafting a Simple Summary as part of a scientific study. The Simple Summary must adhere to the following guidelines: It should be written in one paragraph, in layman’s terms, to explain why the research is being suggested, what the authors aim to achieve, and how the findings from this research may impact the research community. Please use as few abbreviations as possible, and do not cite references in the Simple Summary. The Simple Summary should not exceed 150 words. | Dear ChatGPT-4, I kindly request your assistance in crafting a Simple Summary as part of a scientific study. The Simple Summary must adhere to the following guidelines: It should be written in one paragraph, in layman’s terms, to explain why the research is being suggested, what the authors aim to achieve, and how the findings from this research may impact the research community. Please use as few abbreviations as possible, and do not cite references in the Simple Summary. The Simple Summary should not exceed 150 words. |
| The Simple Summary should be crafted with a focus on maximizing readability, aiming for the highest possible Flesch Kincaid Reading Ease score. | |
| To provide you with the necessary context for creating this Simple Summary, I will supply you with the study title, a scientifically accurate abstract (not in Layman’s terms), and the relevant keywords. Study title: “…” Scientifically accurate abstract: “…” Keywords: “…” | To provide you with the necessary context for creating this Simple Summary, I will supply you with the study title, a scientifically accurate abstract (not in Layman’s terms), and the relevant keywords. Study title: “…” Scientifically accurate abstract: “…” Keywords: “…” |
| Please note: Summarize this unstructured abstract (simple summary) with at most 150 words in lay language, highlighting the study purpose, methods, key findings, and practical importance of these findings for the general public. Additionally, be aware that the Simple Summary should not exceed 150 words, but it should make the most of this limit. | Please note: Summarize this unstructured abstract (simple summary) with at most 150 words in lay language at a 6th grade reading level, highlighting the study purpose, methods, key findings, and practical importance of these findings for the general public. Additionally, be aware that the Simple Summary should not exceed 150 words, but it should make the most of this limit. |
| Score | Explanation |
|---|---|
| 1—very poor | The lay summary contains significant factual errors and/or diverges substantially from the scientific abstract. Essential information is missing, which severely compromises its clarity and accuracy. |
| 2—poor | The lay summary has multiple factual inaccuracies and diverges in certain areas from the scientific abstract. Some key information is missing, diminishing its overall effectiveness. |
| 3—acceptable | The lay summary is mostly accurate but contains minor factual inaccuracies or omissions. It generally aligns with the scientific abstract, though some details could be more precise or comprehensive. |
| 4—good | The lay summary is factually accurate and largely consistent with the scientific abstract. Only minor, non-essential information may be missing or slightly simplified. |
| 5—excellent | The lay summary is completely accurate, fully aligns with the scientific abstract, and includes all essential information. It conveys the content clearly and effectively, without omitting any important details. |
| Parameter | ChatGPT-4 Simple Prompt | ChatGPT-4 Extended Prompt | p-Values | |
|---|---|---|---|---|
| Text length metrics | ||||
| Sentences; median (IQR) | 6 (5–6) | 6 (6–7) | <0.001 | |
| Words; median (IQR) | 135 (126–140) | 130 (121.3–138) | <0.001 | |
| Complex words; median (IQR) | 29 (25–32) | 23 (16.3–26) | <0.001 | |
| Percent of complex words; median (IQR) | 21.1 (18.1–24.2) | 17.4 (13.4–20.5) | <0.001 | |
| Average words per sentence; median (IQR) | 23.8 (21.2–26.2) | 21.1 (19.3–23.2) | <0.001 | |
| Average syllables per word; median (IQR) | 1.8 (1.7–1.9) | 1.7 (1.6–1.8) | <0.001 | |
| Readability Scores | ||||
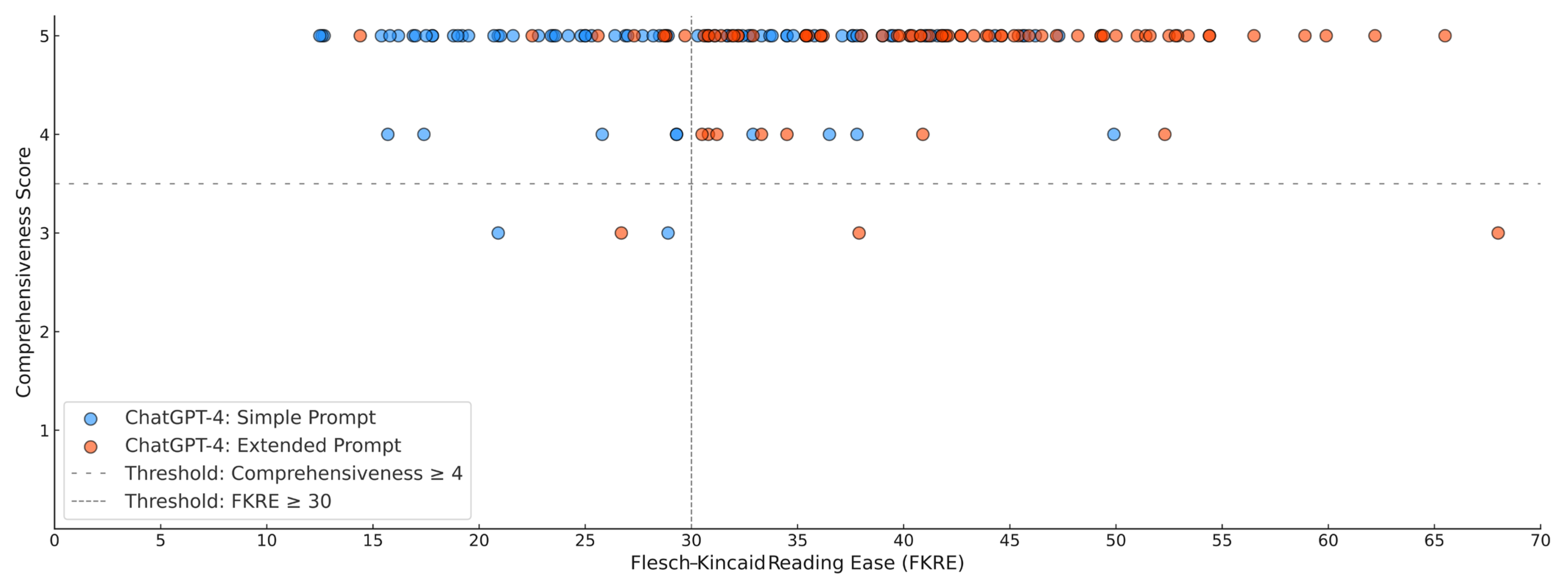
| Flesch–Kincaid Reading Ease (FKRE); median (IQR) | 29.1 (20.9–37) | 40.9 (32.2–49) | <0.001 | |
| Flesch–Kincaid Grade Level; median (IQR) | 14.8 (13.8–16.5) | 12.8 (11.8–14.1) | <0.001 | |
| Gunning Fog Score; median (IQR) | 17.6 (16.3–19.6) | 15.3 (13.7–16.7) | <0.001 | |
| Smog Index; median (IQR) | 12.7 (11.8–14.1) | 11.1 (9.8–12) | <0.001 | |
| Coleman–Liau Index; median (IQR) | 17.3 (15.9–18.7) | 15.6 (14.5–17.1) | <0.001 | |
| Automated Readability Index; median (IQR) | 16.9 (15.3–18.6) | 14 (13.1–16.1) | <0.001 | |
| Reading age in years; median (IQR) | 21.5 (20.5–22.9) | 19.5 (18.5–20.5) | <0.001 | |
| Content quality and overall evaluation | ||||
| Comprehensiveness score; median (IQR) | 5 (5-5) | 5 (5-5) | 0.963 | |
| Comprehensiveness score < 4; n (%) | 2 (2.5) | 3 (3.8) | 0.564 | |
| FKRE < 30; n (%) | 42 (52.5) | 9 (11.3) | <0.001 | |
| Wrong word count; n (%) | 1 (1.3) | 1 (1.3) | 1.000 | |
| Insufficient quality of the patient summary; n (%) | 42 (52.5) | 11 (13.8) | <0.001 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rinderknecht, E.; Schmelzer, A.; Kravchuk, A.; Goßler, C.; Breyer, J.; Gilfrich, C.; Burger, M.; Engelmann, S.; Saberi, V.; Kirschner, C.; et al. Leveraging Large Language Models for High-Quality Lay Summaries: Efficacy of ChatGPT-4 with Custom Prompts in a Consecutive Series of Prostate Cancer Manuscripts. Curr. Oncol. 2025, 32, 102. https://doi.org/10.3390/curroncol32020102
Rinderknecht E, Schmelzer A, Kravchuk A, Goßler C, Breyer J, Gilfrich C, Burger M, Engelmann S, Saberi V, Kirschner C, et al. Leveraging Large Language Models for High-Quality Lay Summaries: Efficacy of ChatGPT-4 with Custom Prompts in a Consecutive Series of Prostate Cancer Manuscripts. Current Oncology. 2025; 32(2):102. https://doi.org/10.3390/curroncol32020102
Chicago/Turabian StyleRinderknecht, Emily, Anna Schmelzer, Anton Kravchuk, Christopher Goßler, Johannes Breyer, Christian Gilfrich, Maximilian Burger, Simon Engelmann, Veronika Saberi, Clemens Kirschner, and et al. 2025. "Leveraging Large Language Models for High-Quality Lay Summaries: Efficacy of ChatGPT-4 with Custom Prompts in a Consecutive Series of Prostate Cancer Manuscripts" Current Oncology 32, no. 2: 102. https://doi.org/10.3390/curroncol32020102
APA StyleRinderknecht, E., Schmelzer, A., Kravchuk, A., Goßler, C., Breyer, J., Gilfrich, C., Burger, M., Engelmann, S., Saberi, V., Kirschner, C., Winning, D. v., Mayr, R., Wülfing, C., Borgmann, H., Buse, S., Haas, M., & May, M. (2025). Leveraging Large Language Models for High-Quality Lay Summaries: Efficacy of ChatGPT-4 with Custom Prompts in a Consecutive Series of Prostate Cancer Manuscripts. Current Oncology, 32(2), 102. https://doi.org/10.3390/curroncol32020102