Using a Local Framework Combining Principal Component Regression and Monte Carlo Simulation for Uncertainty and Sensitivity Analysis of a Domestic Energy Model in Sub-City Areas

Abstract
:1. Introduction
2. The Uncertainty Characterization
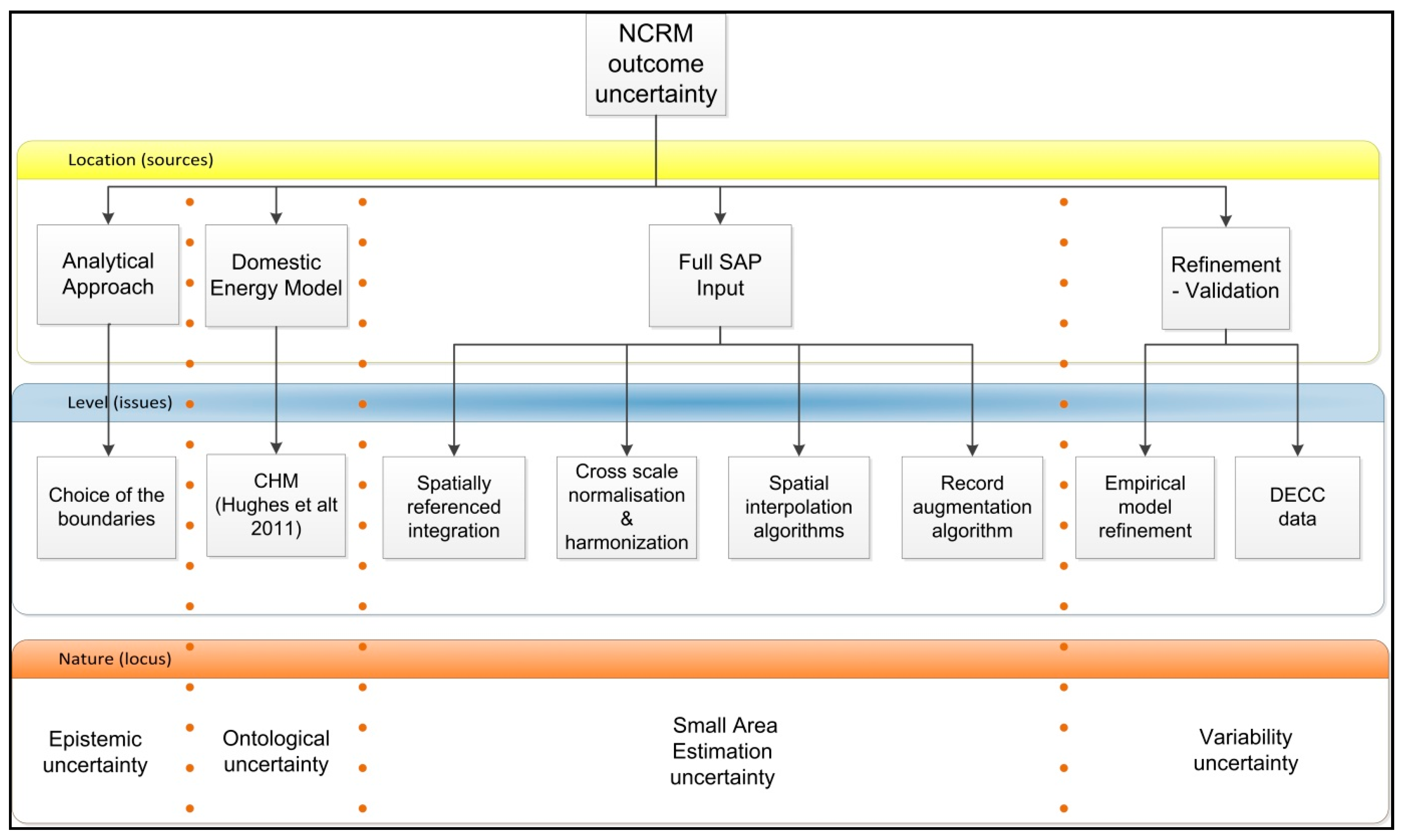
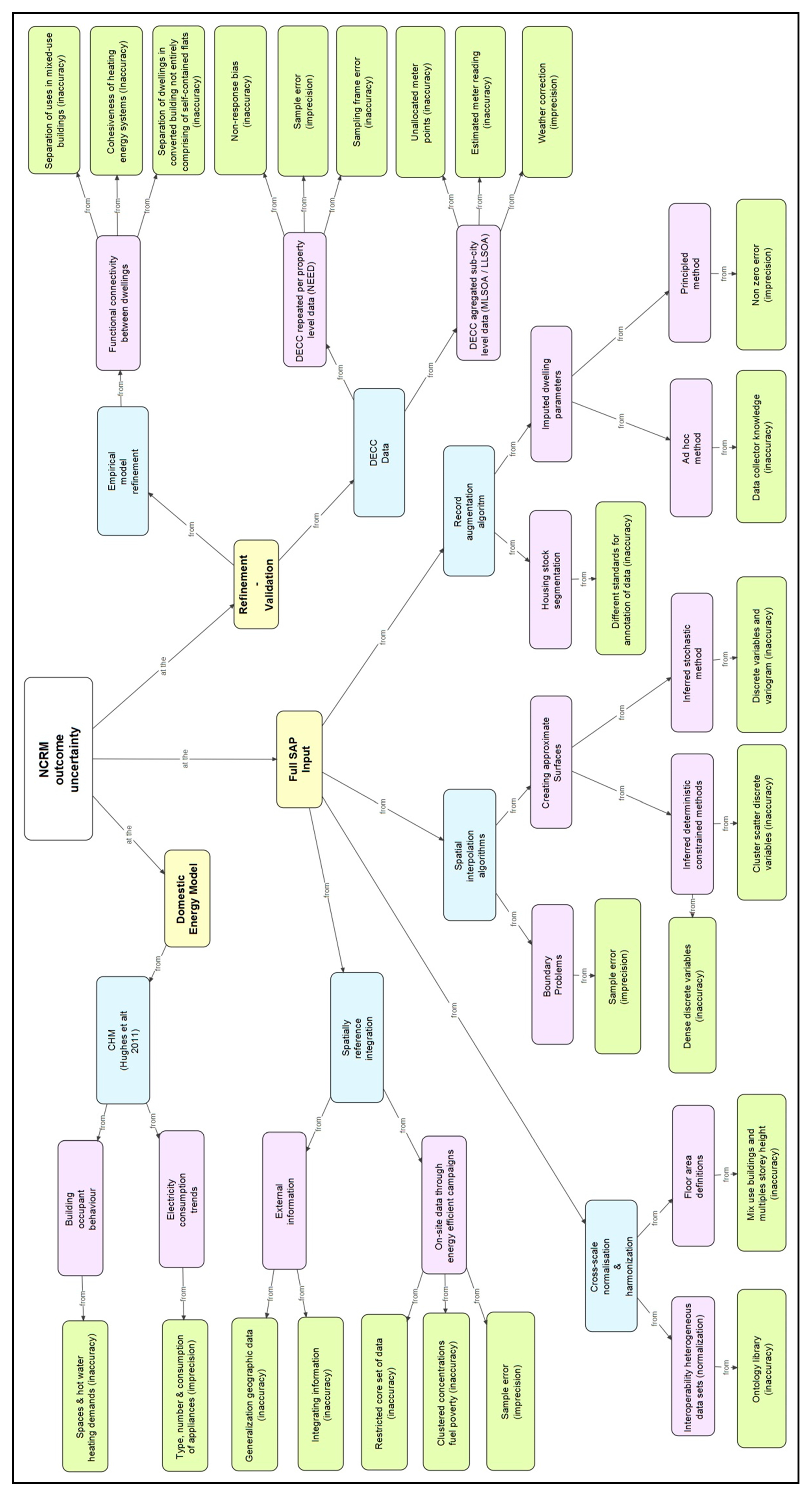
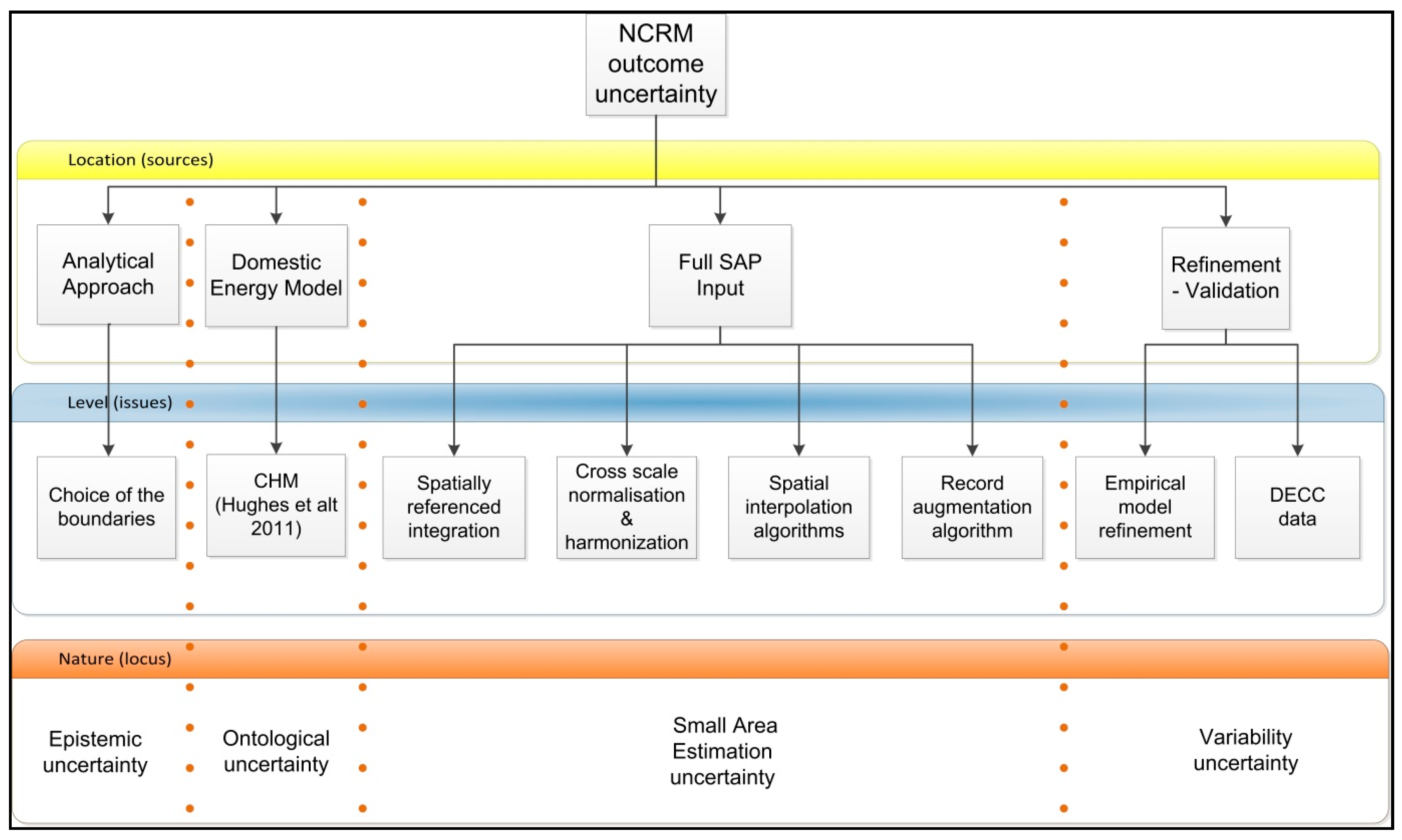
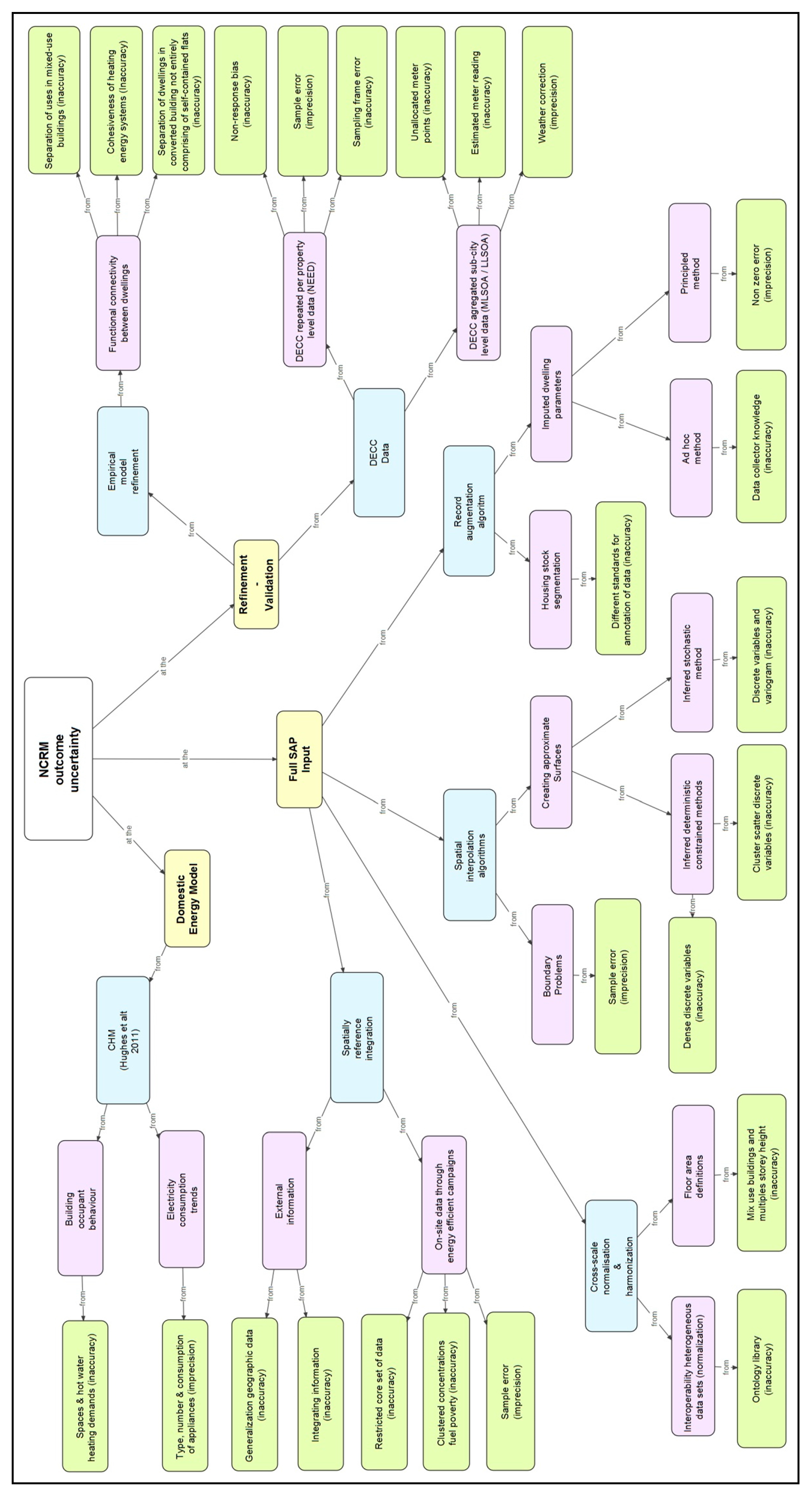
2.1. A Taxonomy of Key Uncertainties Using High-Level Frameworks
2.2. The NCRF Outcome Parametric Uncertainty Using a Concept Map
3. Framework Combining Principal Component Regression and Monte Carlo Simulation
3.1. Variables Used in the Monte Carlo Analysis
3.2. Principal Component Regression
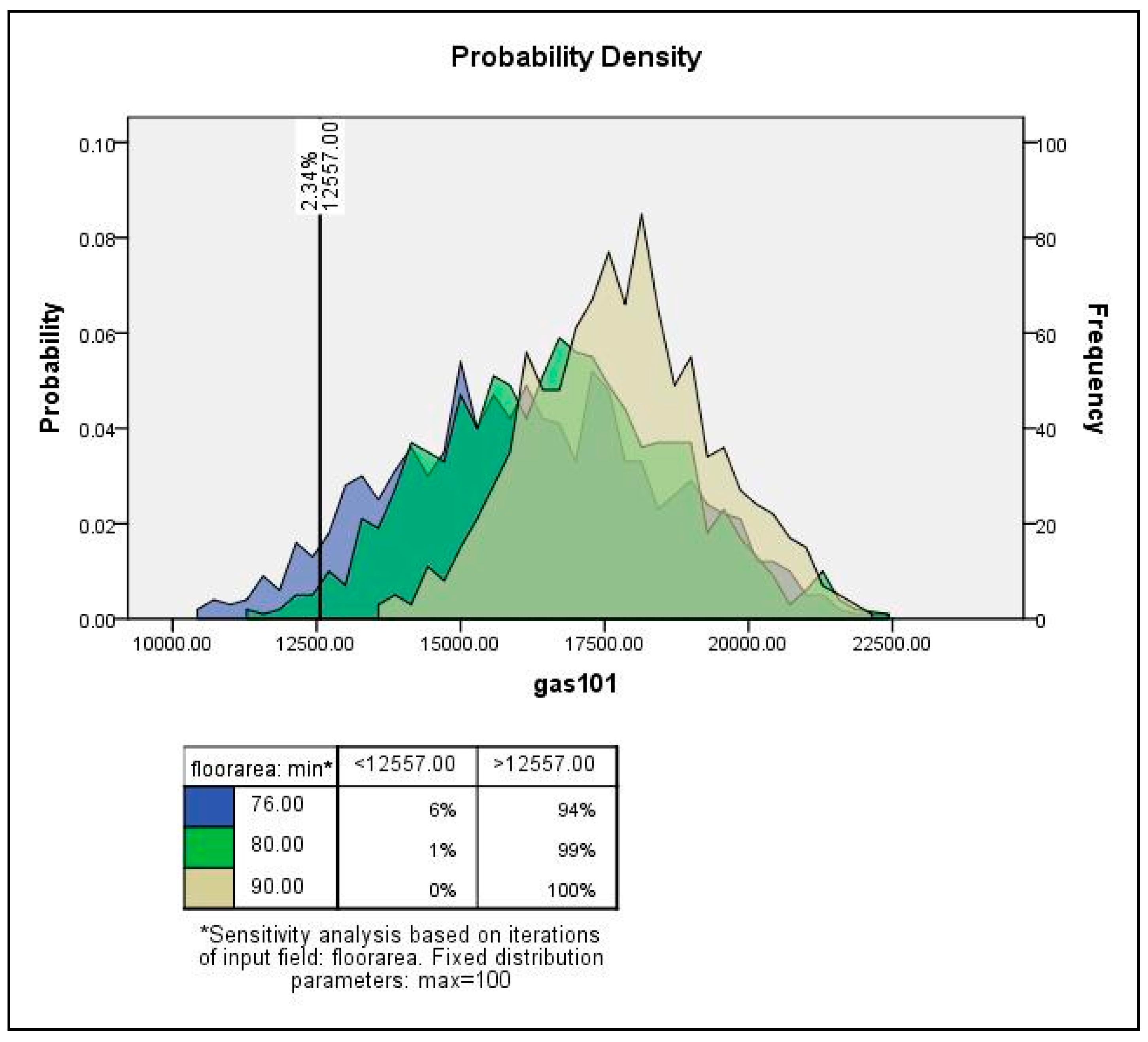
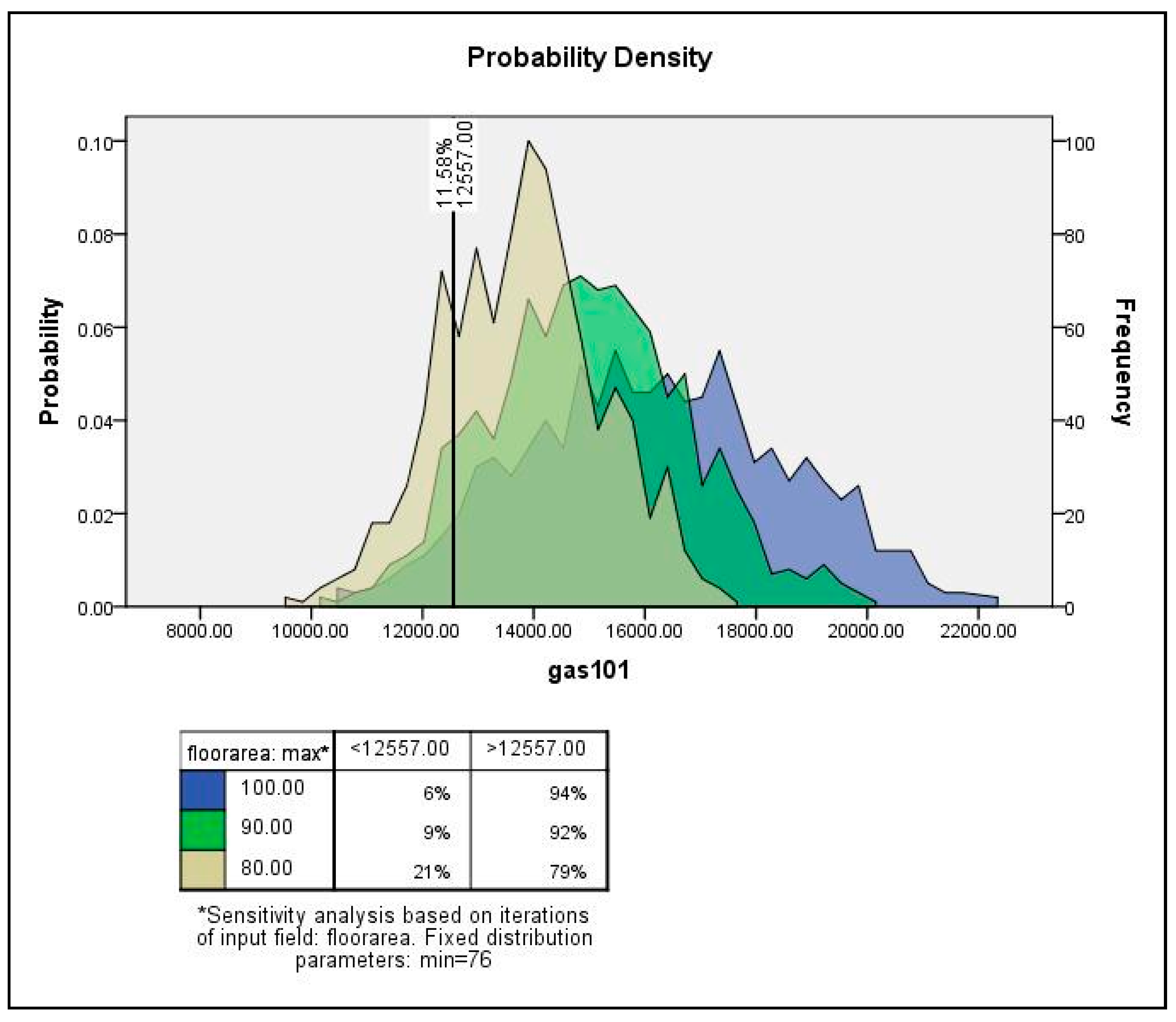
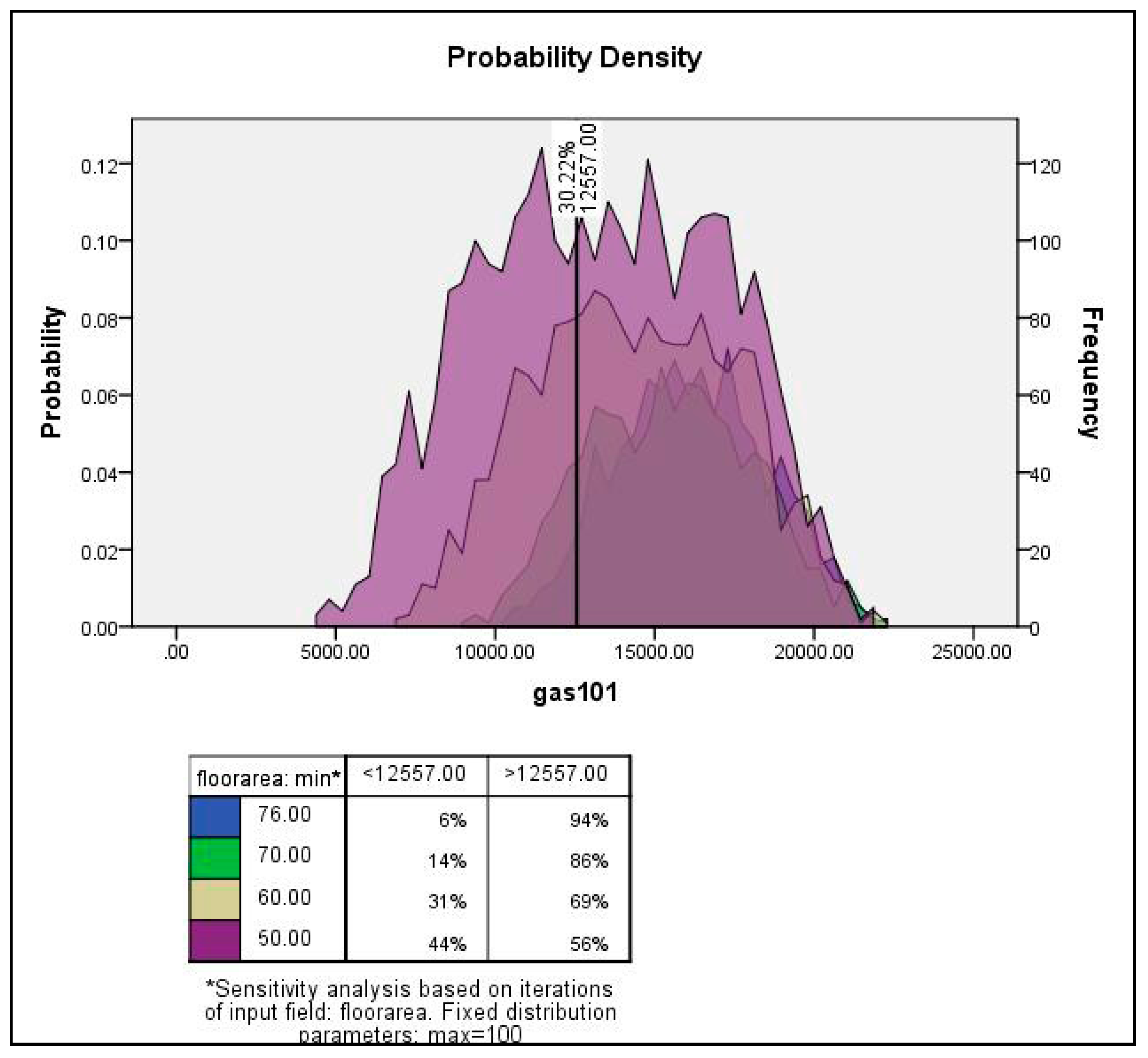
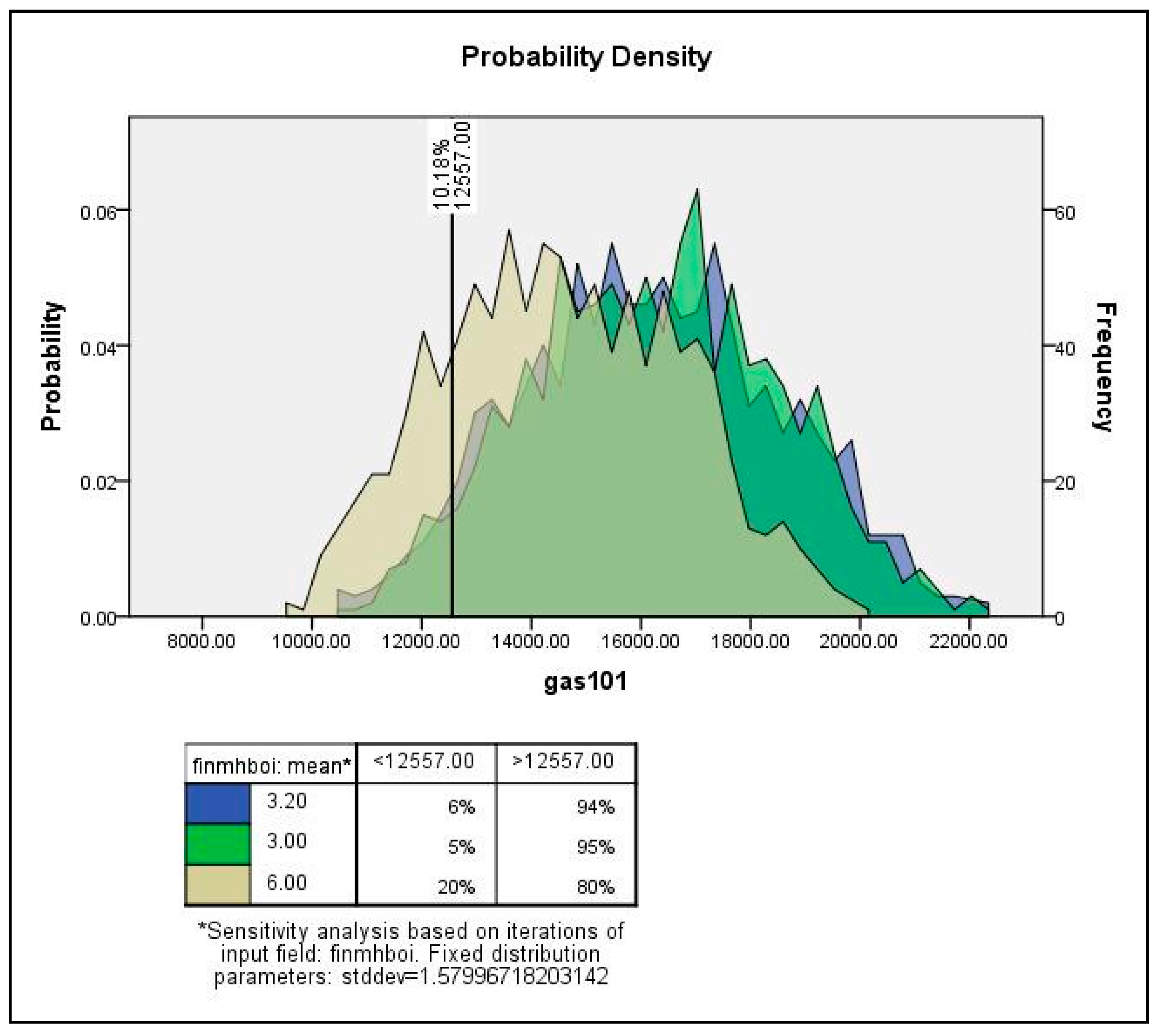
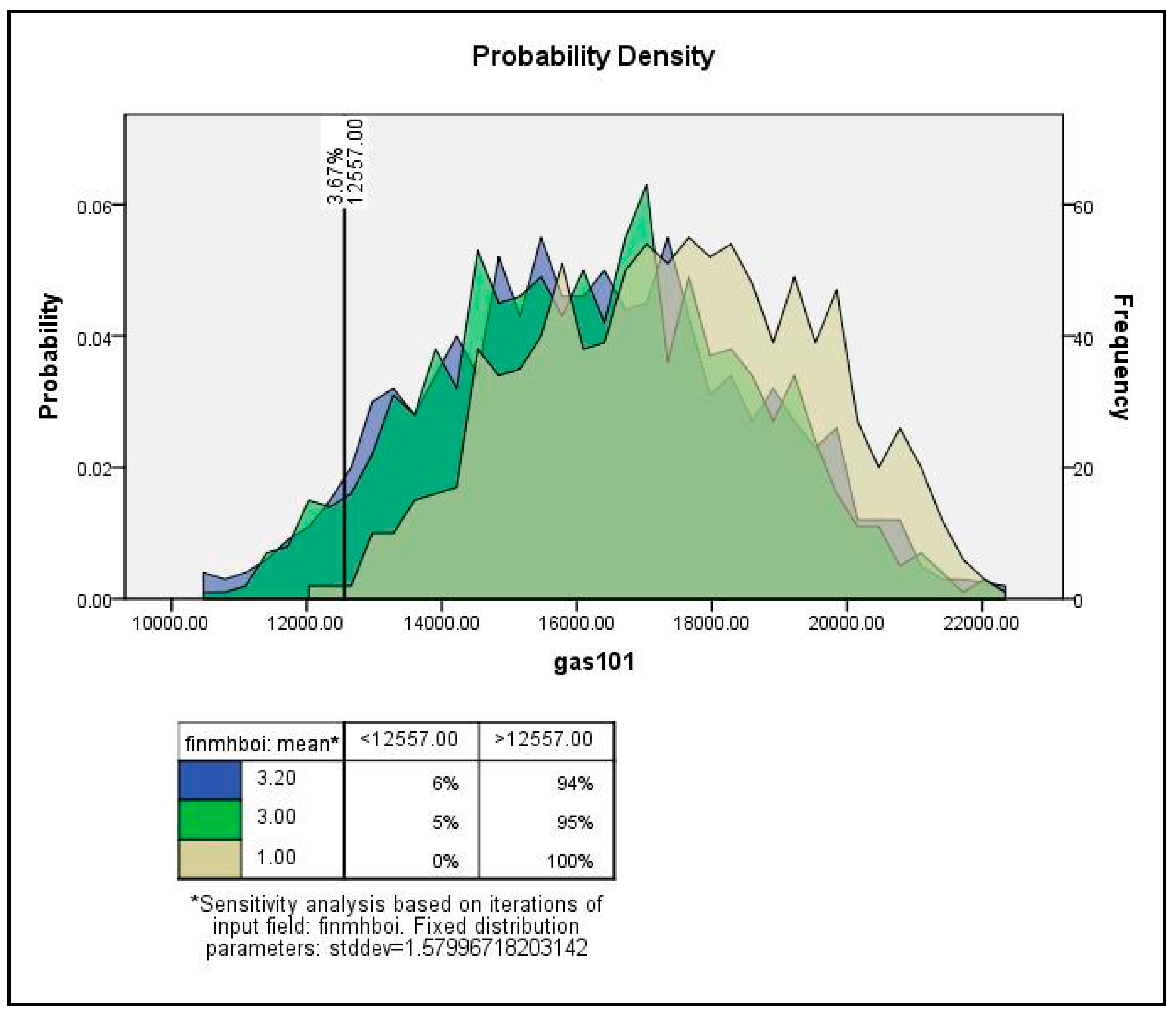
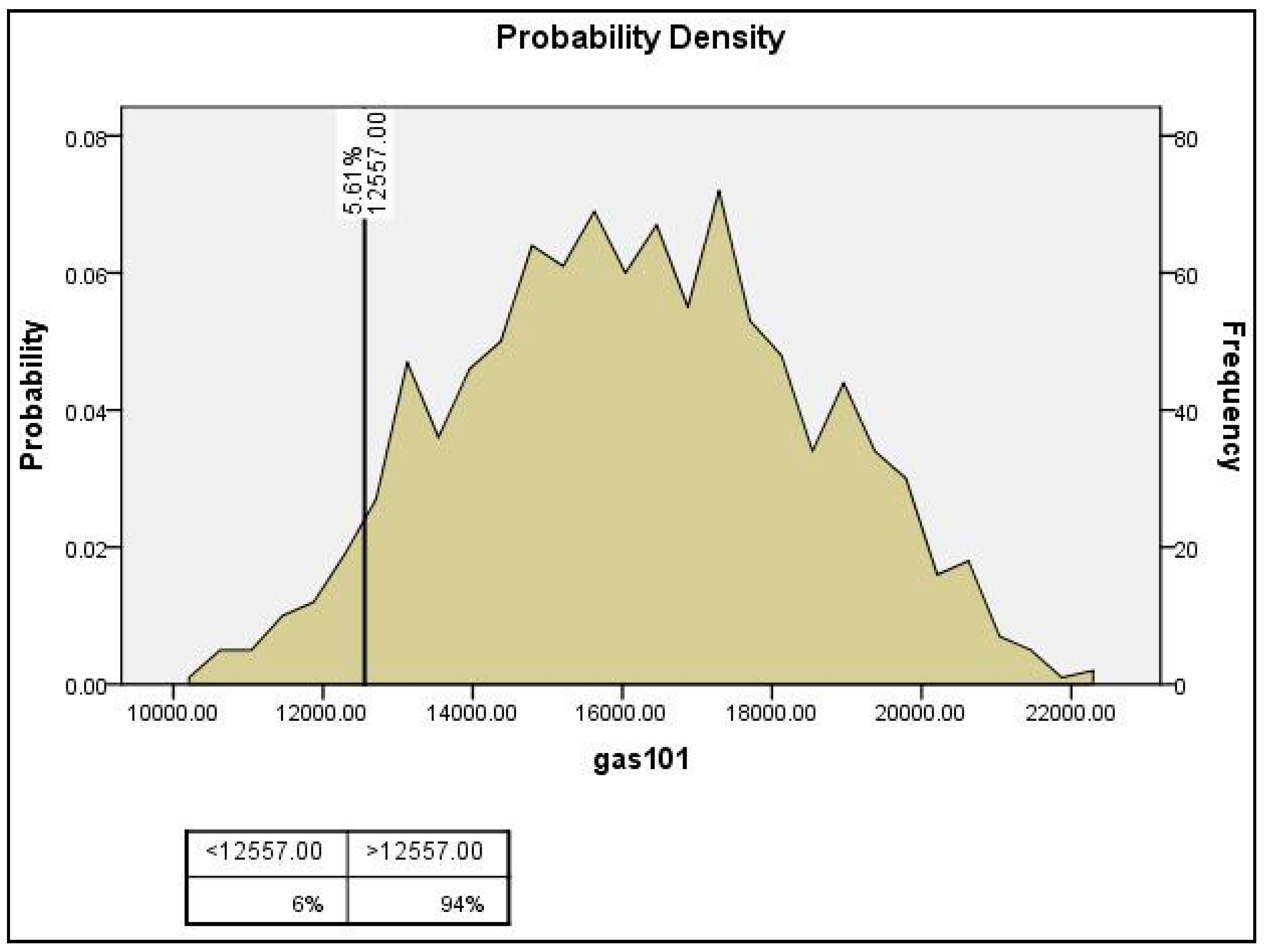
4. Monte Carlo Simulation and Sensitivity Analysis for Sub-City Samples
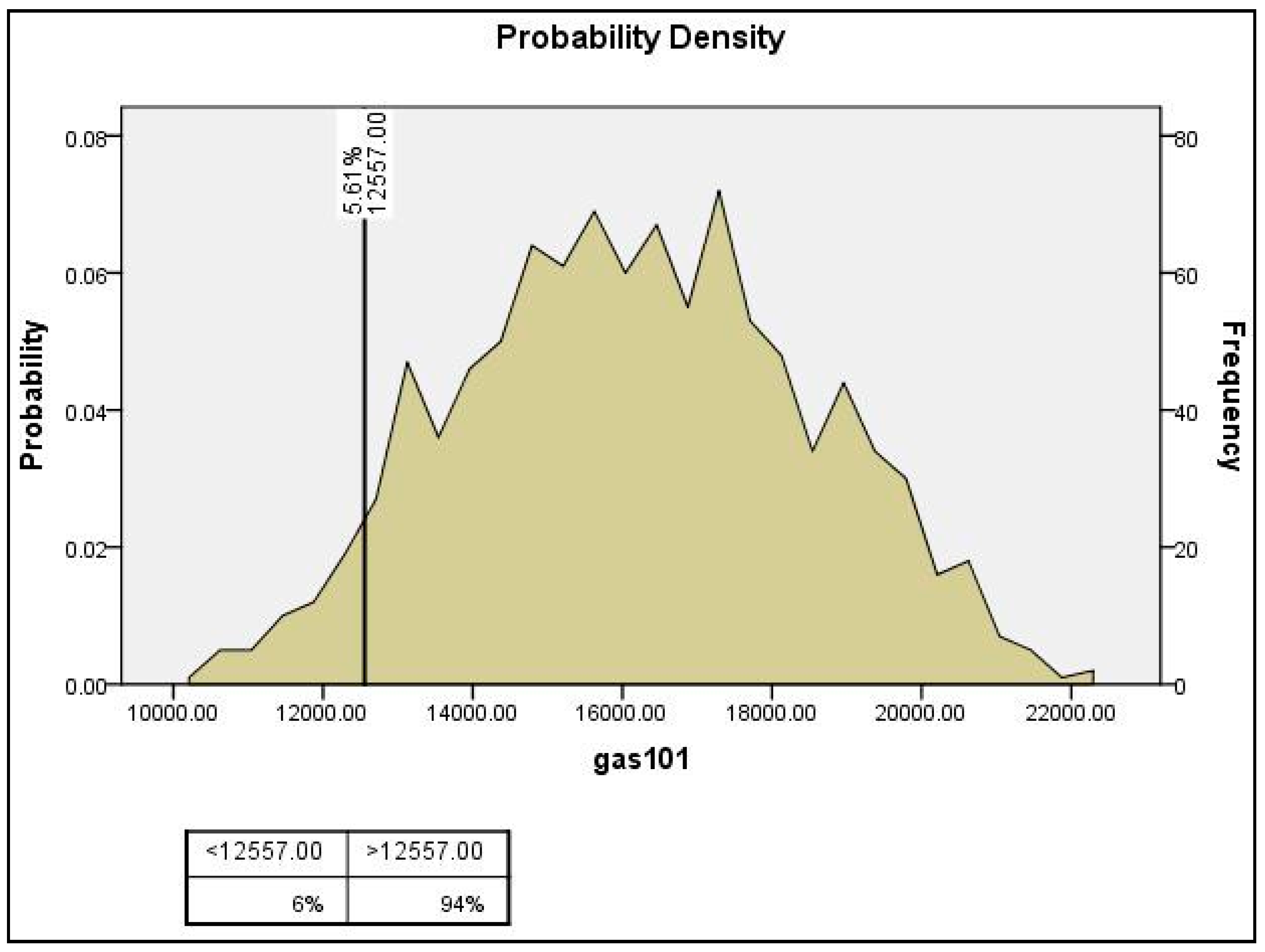
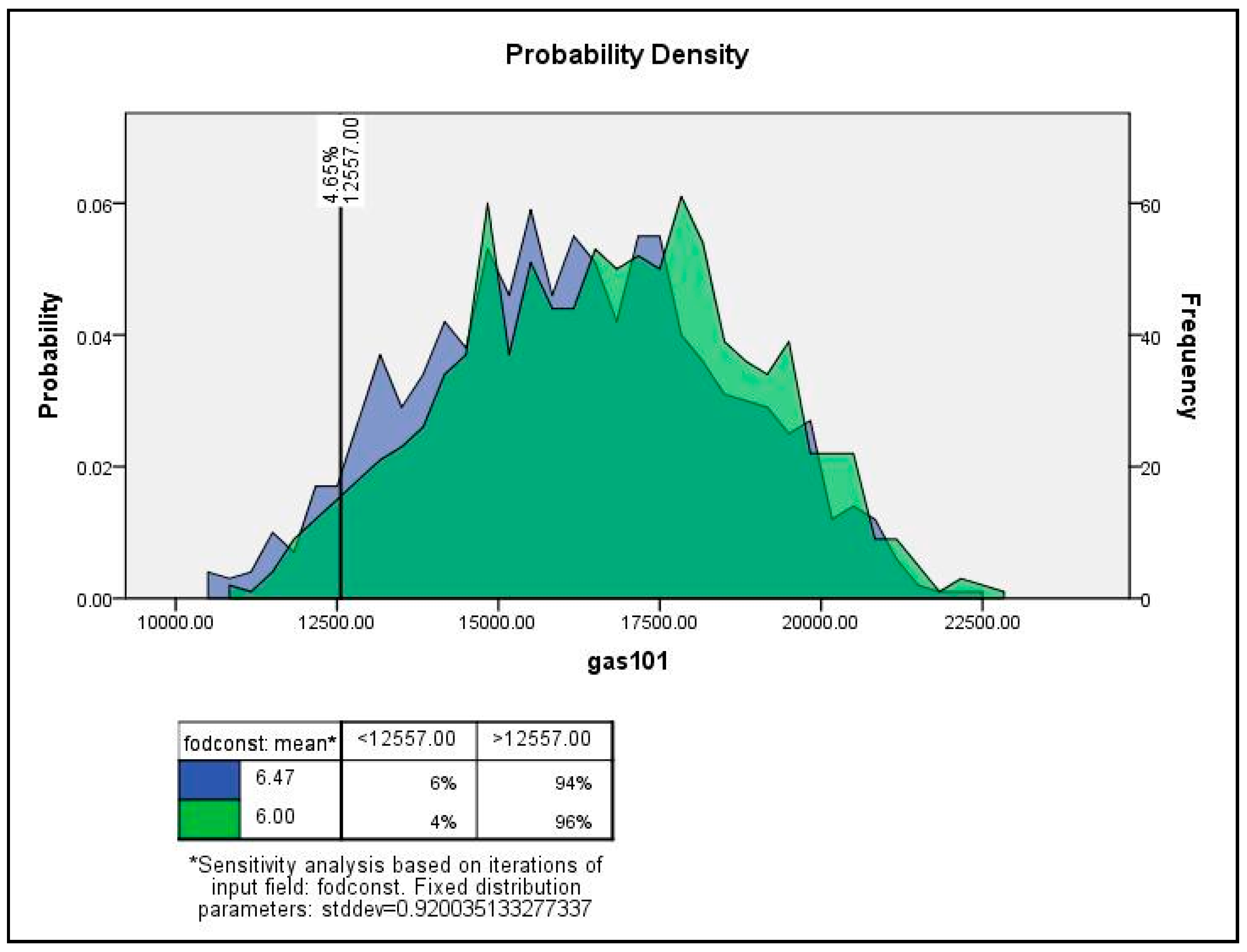
4.1. Sensitivity Analysis Framework
4.2. Monte Carlo Simulation and Sensitivity Analysis
5. Summary and Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
Nomenclature
| BRE | Building Research Establishment |
| CHM | Cambridge Housing Model |
| CM | Concep Map |
| DECC | Department of Energy and Climate Change |
| EHS | English House Survey |
| LLSOA | Lower Layer Super Output Area |
| MLSOA | Middle Layer Super Output Area |
| NCRF | Newcastle upon Tyne Carbon RouteMap Modelling Framework |
| NCRM | Newcastle Carbon Route Map |
| NEE | North East of England |
| NEED | National Energy Efficiency Data-Framework |
| OAT | One-at-time |
| OFAS | Office of Food Additive Safety |
| Probability Density Function | |
| SAP | Standard Assessment Procedure |
| SPSS | Statistical Package for the Social Sciences |
References
- Eisenhower, B.; O’Neill, Z.; Fonoberov, V.A.; Mezić, I. Uncertainty and sensitivity decomposition of building energy models. J. Build. Perform. Simul. 2012, 5, 171–184. [Google Scholar] [CrossRef]
- Grömping, U. Estimators of relative importance in linear regression based on variance decomposition. Am. Stat. 2007, 61, 139–147. [Google Scholar] [CrossRef]
- Nguyen, A.-T.; Reiter, S. A performance comparison of sensitivity analysis methods for building energy models. Build. Simul. 2015, 8, 651–664. [Google Scholar] [CrossRef]
- Summerfield, A.J.; Raslan, R.; Lowe, R.J.; Oreszczyn, T. (Eds.) How useful are building energy models for policy? A UK perspective. In Proceedings of the 12th Conference of International Building Performance Simulation Association, Sidney, Australia, 14–16 November 2011. [Google Scholar]
- Rubin, D.B. Multiple imputation after 18+ years. J. Am. Stat. Assoc. 1996, 91, 473–489. [Google Scholar] [CrossRef]
- Kessler, R.C. The Categorical versus dimensional assessment controversy in the sociology of mental illness. J. Health Soc. Behav. 2009, 43, 171–188. [Google Scholar] [CrossRef]
- Calderón, C.; James, P.; Urquizo, J.; McLoughlin, A. A GIS domestic building framework to estimate energy end-use demand in UK sub-city areas. Energy Build. 2015, 96, 236–250. [Google Scholar] [CrossRef]
- Calderón, C.; James, P.; Alderson, D.; McLoughlin, A.; Wagner, T. Data Availability and Repeatability for Urban Carbon Modelling: A CarbonRouteMap for Newcastle upon Tyne; Retrofit: Manchester, UK, 2012. [Google Scholar]
- Hickman, J.; Baybutt, P.; Bell, B.; Carlson, D.; Conradi, L.; Denning, R. PRA Procedures Guide: A Guide to the Performance of Probabilistic Risk Assessments for Nuclear Power Plants: Chapters 9–13 and Appendices A–G (NUREG/CR-2300, Volume 2); Report No.: NRC FIN G-1004; Office of Nuclear Regulatory Research, U.S. Nuclear Regulatory Commission: Washington, DC, USA, 1983.
- Macdonald, I.A.; Clarke, J.A. Applying uncertainty considerations to energy conservation equations. Energy Build. 2007, 39, 1019–1026. [Google Scholar] [CrossRef] [Green Version]
- Chapman, J. Data accuracy and model reliability. In Proceedings of the BEPAC Conference, Canterbury, UK, 10–11 April 1991; pp. 10–19. [Google Scholar]
- Unwin, S.; Moss, R.; Rice, J.M.S. Characterizing Uncertainty for Regional Climate Change Mitigation and Adaptation Decisions; Pacific Northwest National Laboratory, U.S. Department of Energy: Washington, DC, USA, 2011.
- Lin, G.; Engel, D.W.; Eslinger, P.W. Survey and Evaluate Uncertainty Quantification Methodologies; Contract No.: PNNL-20914; Pacific Northwest National Laboratory (PNNL): Richland, WA, USA, 2012.
- Han, P.K.J.; Klein, W.M.P.; Arora, N.K. Varieties of uncertainty in health care: A conceptual taxonomy. Med. Decis. Mak. 2011, 31, 828–838. [Google Scholar] [CrossRef] [PubMed]
- Myung, I.J. The importance of complexity in model selection. J. Math. Psychol. 2000, 44, 190–204. [Google Scholar] [CrossRef] [PubMed]
- Shapiro, S.C.; Eckroth, D. Encyclopedia of Artificial Intelligence; John Wiley & Sons, Inc.: New York, NY, USA, 1987. [Google Scholar]
- Novak, J.D.; Cañas, A.J. The Theory Underlying Concept Maps and How to Construct Them; Florida Institute for Human and Machine Cognition: Pensacola, FL, USA, 2006. [Google Scholar]
- Sowa, J.F. Semantic Networks. In Encyclopedia of Cognitive Science; John Wiley & Sons, Ltd.: New York, NY, USA, 2006. [Google Scholar]
- Hughes, M.; Palmer, J.; Cheng, V.; Shipworth, D. Sensitivity and uncertainty analysis of England’s housing energy model. Build. Res. Inf. 2013, 41, 156–167. [Google Scholar] [CrossRef]
- Cullen, A.; Frey, C. Probabilistic Techniques in Exposure Assessment: A Handbook for Dealing with Variability and Uncertainty in Models and Inputs; Springer: New York, NY, USA, 1999. [Google Scholar]
- U.S. Food and Drug Administration. Guidance for Industry: Estimating Dietary Intake of Substances in Food. 2015. Available online: http://www.fda.gov/RegulatoryInformation/Guidances/ucm074725.htm#ftn50 (accessed on 14 August 2015).
- Matthys, C.; Bilau, M.; Govaert, Y.; Moons, E.; De Henauw, S.; Willems, J.L. Risk assessment of dietary acrylamide intake in Flemish adolescents. Food Chem. Toxicol. 2005, 43, 271–278. [Google Scholar] [CrossRef] [PubMed]
- Helton, J.C.; Johnson, J.D.; Sallaberry, C.J.; Storlie, C.B. Survey of sampling-based methods for uncertainty and sensitivity analysis. Reliab. Eng. Syst. Saf. 2006, 91, 1175–1209. [Google Scholar] [CrossRef]
- Helton, J.C.; Johnson, J.D.; Oberkampf, W.L. An exploration of alternative approaches to the representation of uncertainty in model predictions. Reliab. Eng. Syst. Saf. 2004, 85, 39–71. [Google Scholar] [CrossRef]
- Cooke, R.M. Experts in Uncertainty: Opinion and Subjective Probability in Science; Oxford University Press: New York, NY, USA, 1991; 330p. [Google Scholar]
- Manache, G.; Melching, C.S. Identification of reliable regression- and correlation-based sensitivity measures for importance ranking of water-quality model parameters. Environ. Model. Softw. 2008, 23, 549–562. [Google Scholar] [CrossRef]
- International Energy Agency (IEA). Sensitivity and Uncertainty—Annex 31: Energy-Related Environmental Impact of Buildings; IEA: Otawa, ON, Canada, 2004. [Google Scholar]
- Boriah, S.; Chandola, V.; Kumar, V. Similarity Measures for Categorical Data: A Comparative Evaluation. In Proceedings of the SIAM Conference on Data Mining, Atlanta, GA, USA, 24–26 April 2008; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2008; pp. 243–254. [Google Scholar]
- Jolliffe, I.T. Principal Component Analysis; Springer: New York, NY, USA, 2002; Available online: http://www.springer.com/us/book/9780387954424 (accessed on 20 September 2017).
- Dougherty, C. Introduction to Econometrics, 3rd ed.; Oxford University Press Inc.: New York, NY, USA, 2007. [Google Scholar]
- Silverman, B.W. Density estimation for statistics and data analysis. In Monographs on Statistics and Applied Probability; Chapman and Hall: London, UK, 1986. [Google Scholar]
- Quinn, G.P.; Keough, M.J. Experimental Design and Data Analysis for Biologists. 2002. Available online: http://www.amazon.co.uk/Experimental-Design-Data-Analysis-Biologists/dp/0521009766 (accessed on 10 September 2017).
- Hughes, M. A Guide to the Cambridge Housing Model; The Department of Energy & Climate Change (DECC): London, UK, 2011.
- Saltelli, A.; Annoni, P. How to avoid a perfunctory sensitivity analysis. Environ. Model. Softw. 2010, 25, 1508–1517. [Google Scholar] [CrossRef]
- Confalonieri, R.; Bellocchi, G.; Tarantola, S.; Acutis, M.; Donatelli, M.; Genovese, G. Sensitivity analysis of the rice model WARM in Europe: Exploring the effects of different locations, climates and methods of analysis on model sensitivity to crop parameters. Environ. Model. Softw. 2010, 25, 479–488. [Google Scholar] [CrossRef]
- Ziehn, T.; Tomlin, A.S. GUI–HDMR—A software tool for global sensitivity analysis of complex models. Environ. Model. Softw. 2009, 24, 775–785. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Variance Explained | |||
|---|---|---|---|
| Component | Initial Eigenvalues | ||
| Total | % of Variance | Cumulative % | |
| 1 | 2217 | 37 | 37 |
| 2 | 1369 | 23 | 60 |
| Component Matrix a | ||
|---|---|---|
| Component | ||
| 1 | 2 | |
| age | −0.156 | 0.823 |
| number of floors | 0.879 | −0.006 |
| dwelling size | −0.693 | −0.073 |
| wall construction | 0.193 | 0.824 |
| building form | 0.888 | −0.080 |
| heating | 0.337 | −0.015 |
| Statistics | Dwelling Type | Construction Date | Cavity Wall Insulation | Primary Heating Systems | Boiler Type |
|---|---|---|---|---|---|
| Mean | 3.35 | 6.47 | 1.55 | 1.33 | 3.2 |
| Mode | 3 | 5 | 2 | 1 | 3 |
| Standard Deviation | 0.480 | 0.920 | 0.503 | 0.747 | 1.580 |
| Variance | 0.230 | 0.846 | 0.253 | 0.558 | 2.496 |
| Range | 1 | 4 | 1 | 2 | 5 |
| Minimum | 3 | 4 | 1 | 1 | 1 |
| Maximum | 3 | 4 | 2 | 3 | 6 |
| Sum | 184 | 356 | 85 | 73 | 176 |
| Percentile 25 | 3 | 6 | 1 | 1 | 3 |
| Percentile 50 | 3 | 6 | 2 | 1 | 3 |
| Percentile 75 | 4 | 7 | 2 | 1 | 3 |
| Variable | Distribution | Mean | Standard Deviation |
|---|---|---|---|
| Dwelling type | Normal | 3.35 | 0.480 |
| Construction date | Normal | 6.47 | 0.920 |
| Cavity wall insulation | Normal | 1.55 | 0.503 |
| Primary heating system—type of system | Normal | 1.33 | 0.747 |
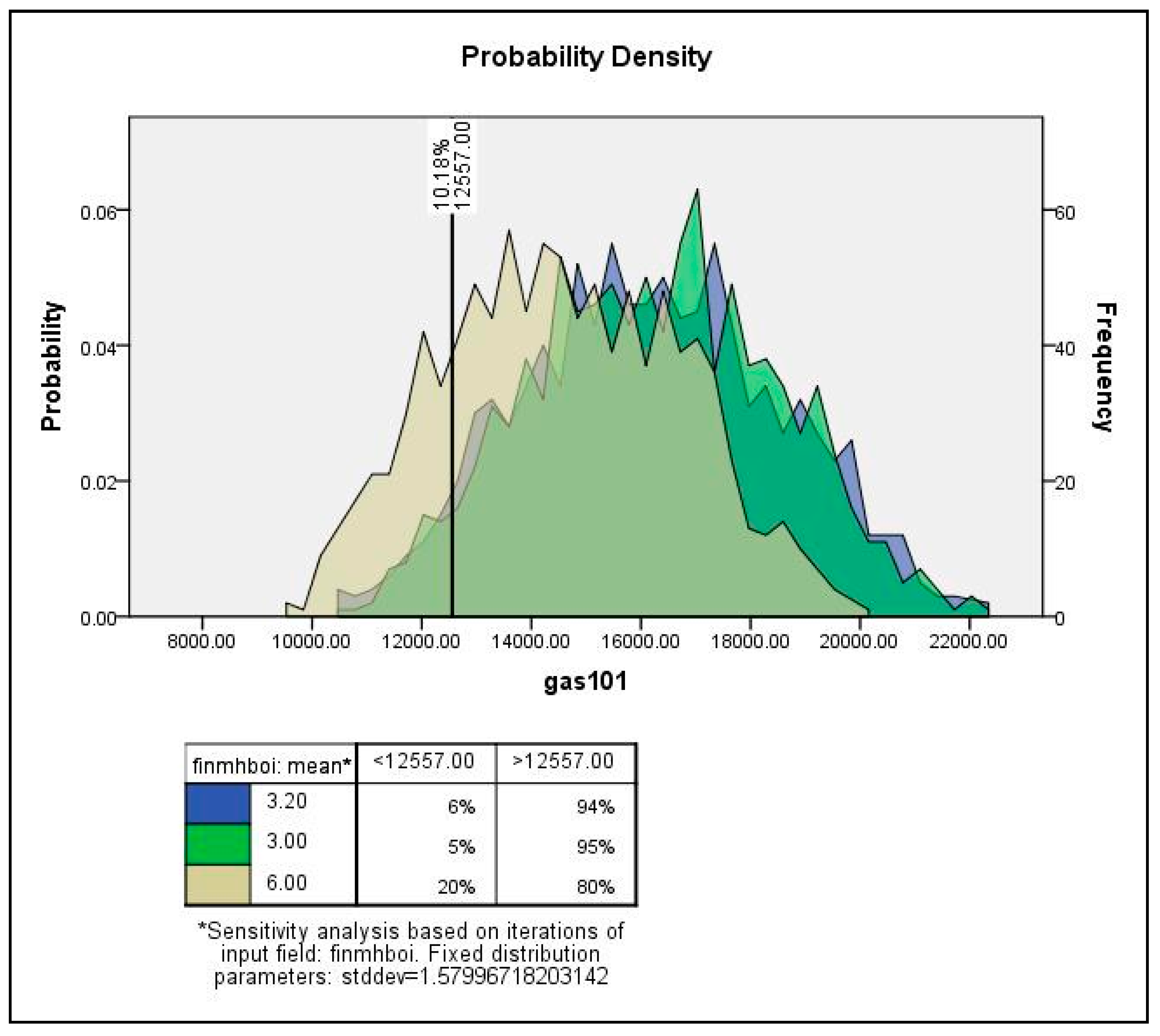
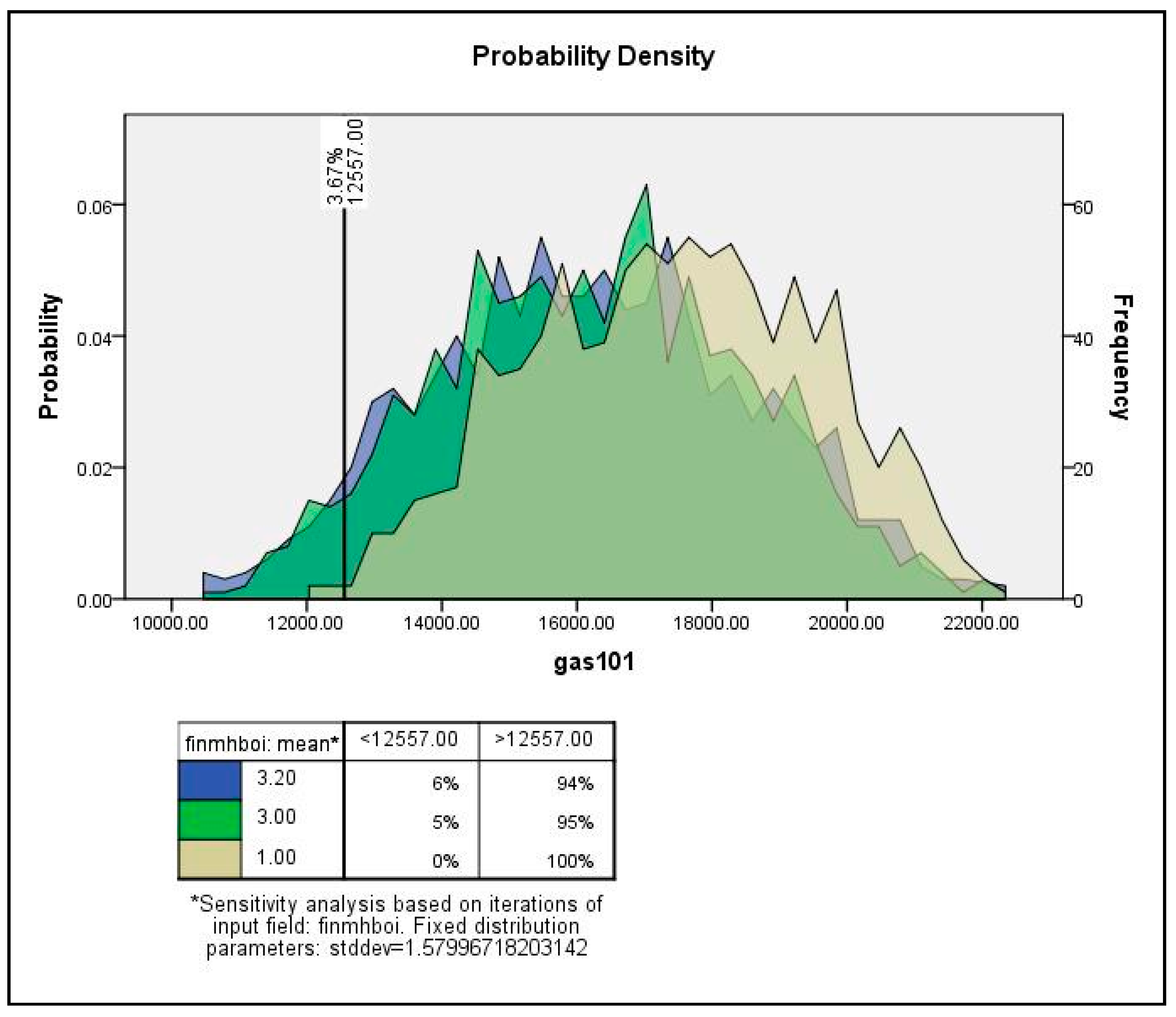
| Boiler type | Normal | 3.20 | 1.580 |
| - | - | Minimum | Maximum |
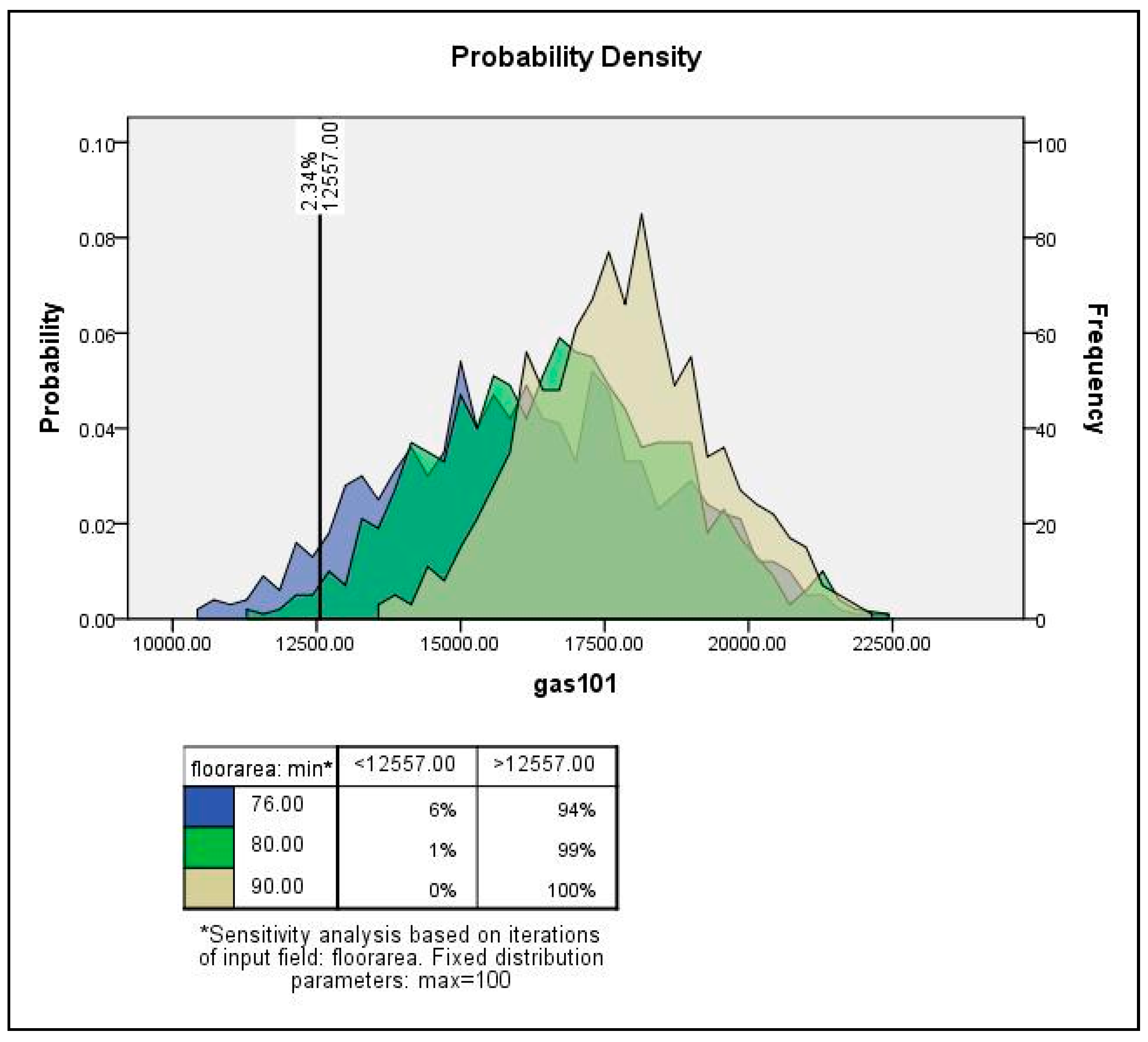
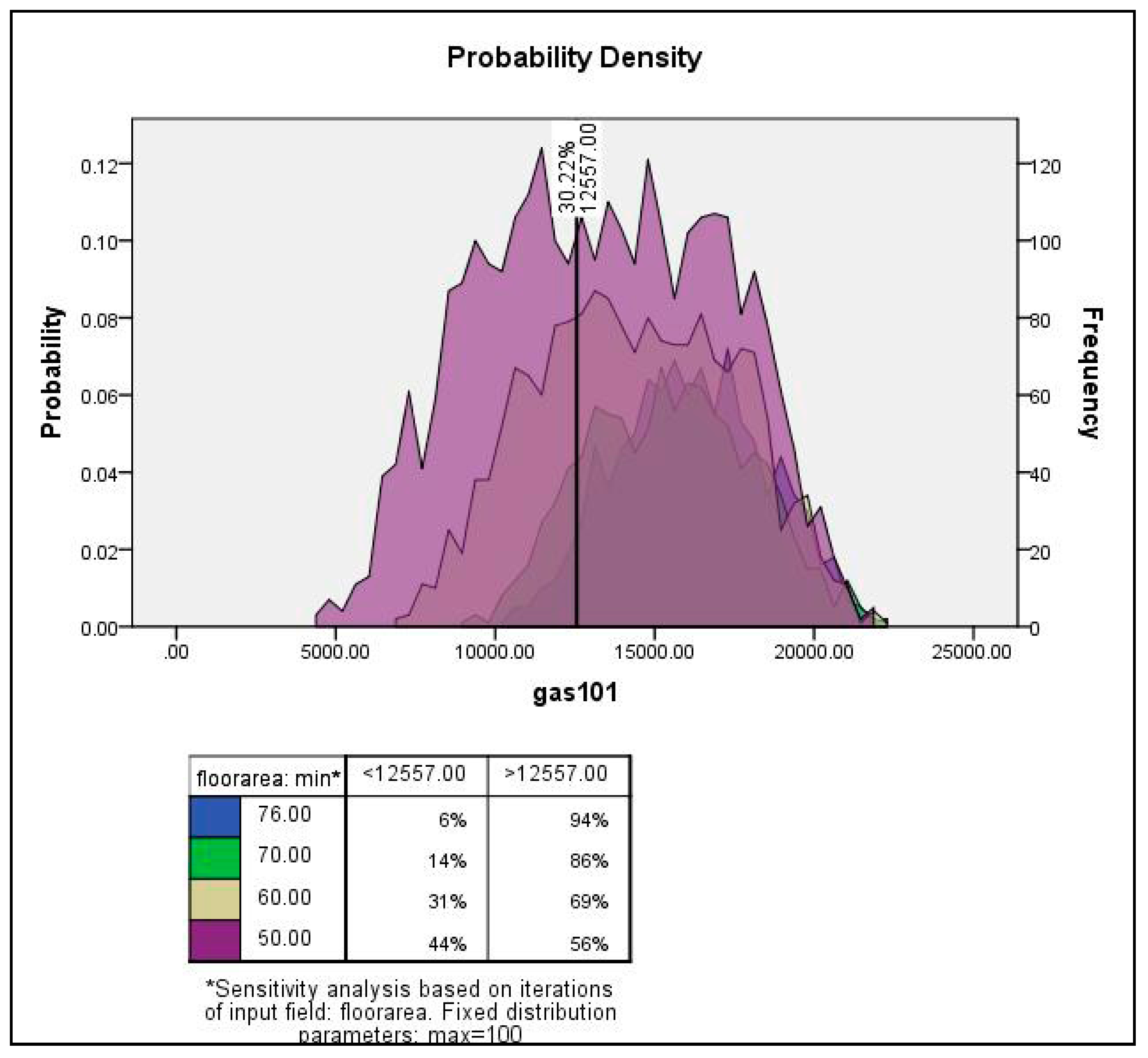
| Usable floor area | Uniform | 76 | 100 |
| Model | Unstandardized Coefficients | Standardized Coefficients | Inferential Statistical t-Test | Significance Probabilty | |
|---|---|---|---|---|---|
| Beta Coefficients | Standard Error | Beta Coefficients | |||
| (Constant) | −2972.591 | 8527.128 | - | −0.349 | 0.729 |
| Floor area | 249.533 | 68.817 | 0.452 | 3.626 | 0.001 |
| Dwelling type | 683.926 | 856.747 | 0.092 | 0.798 | 0.429 |
| Dwelling age | −719.608 | 495.683 | −0.186 | −1.452 | 0.153 |
| Cavity wall insulation | 1379.358 | 789.407 | 0.195 | 1.747 | 0.087 |
| Primary heating fuel | 889.723 | 862.686 | 0.187 | 1.031 | 0.308 |
| Boiler type | −1192.025 | 406.517 | −0.530 | −2.932 | 0.005 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Urquizo, J.; Calderón, C.; James, P. Using a Local Framework Combining Principal Component Regression and Monte Carlo Simulation for Uncertainty and Sensitivity Analysis of a Domestic Energy Model in Sub-City Areas. Energies 2017, 10, 1986. https://doi.org/10.3390/en10121986
Urquizo J, Calderón C, James P. Using a Local Framework Combining Principal Component Regression and Monte Carlo Simulation for Uncertainty and Sensitivity Analysis of a Domestic Energy Model in Sub-City Areas. Energies. 2017; 10(12):1986. https://doi.org/10.3390/en10121986
Chicago/Turabian StyleUrquizo, Javier, Carlos Calderón, and Philip James. 2017. "Using a Local Framework Combining Principal Component Regression and Monte Carlo Simulation for Uncertainty and Sensitivity Analysis of a Domestic Energy Model in Sub-City Areas" Energies 10, no. 12: 1986. https://doi.org/10.3390/en10121986
APA StyleUrquizo, J., Calderón, C., & James, P. (2017). Using a Local Framework Combining Principal Component Regression and Monte Carlo Simulation for Uncertainty and Sensitivity Analysis of a Domestic Energy Model in Sub-City Areas. Energies, 10(12), 1986. https://doi.org/10.3390/en10121986