1. Introduction
Wind energy has become an attractive source of renewable energy, and its installed capacity worldwide has grown significantly in recent years [
1]. Offshore wind turbines have been installed many places, especially in the North Sea, and many new, larger wind farms are planned. Due to the harsh environmental conditions for offshore wind turbines, and the access difficulties for maintenance and repairs, it is very important to minimize failures of wind turbine components including fatigue failures of casted components [
2] in the wind turbine drivetrain.
Wind turbines are large structures exposed to wave excitations, highly dynamic wind loads and wakes from other wind turbines [
3]. Thus, wind turbine components are exposed to stochastic loads that are varying randomly during the design working life. Due to highly variable loads, the components may fail due to fatigue, wear and other deterioration processes [
3].
Casting defects are of high importance for the lifetime of structural casting. The fatigue life of cast iron components is often controlled by the growth of cracks initiated from defects such as shrinkage cavities and gas pores [
4]. Further, different manufacturers apply different manufacturing processes of cast components, resulting in different fatigue lives of the produced components.
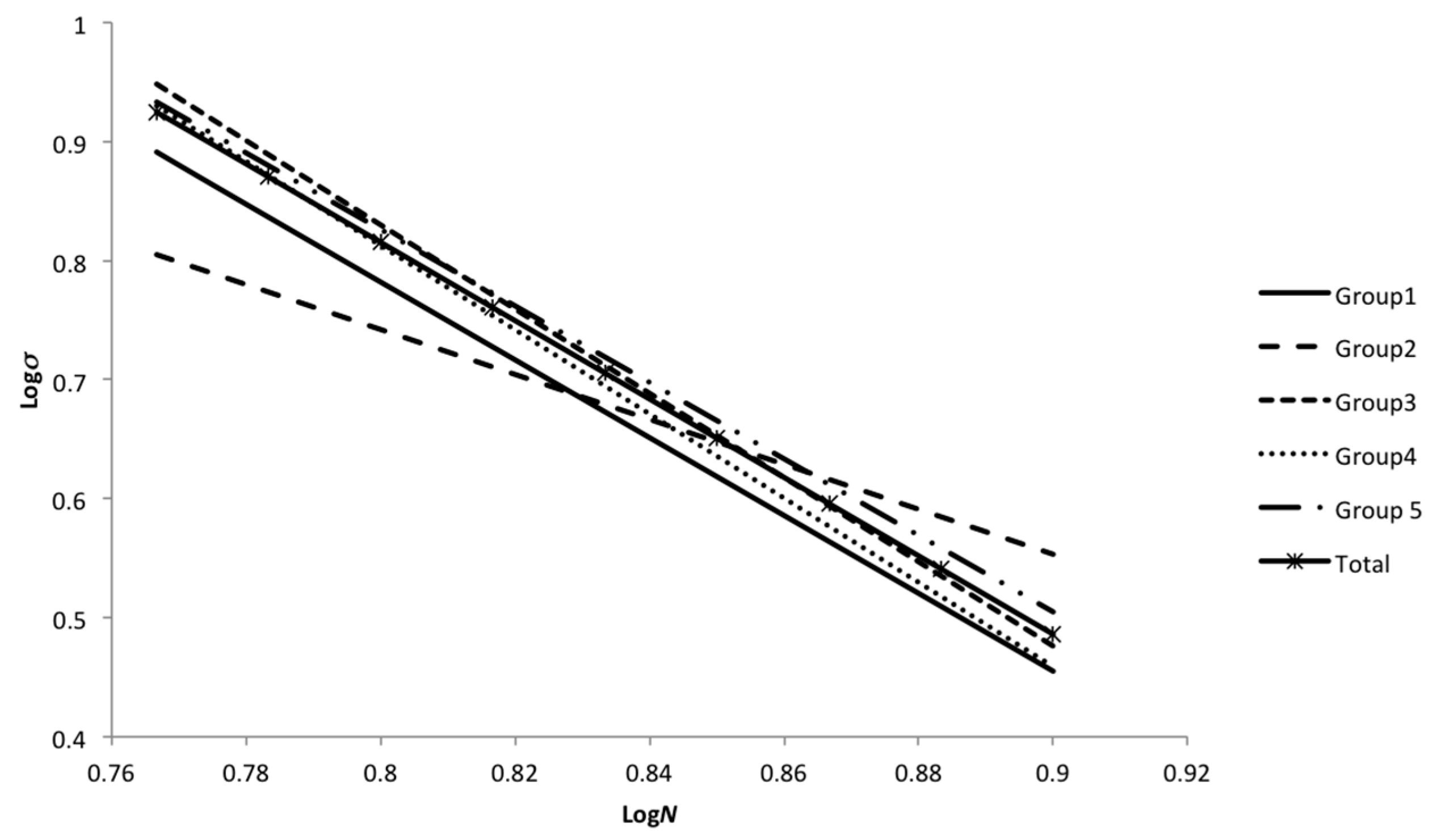
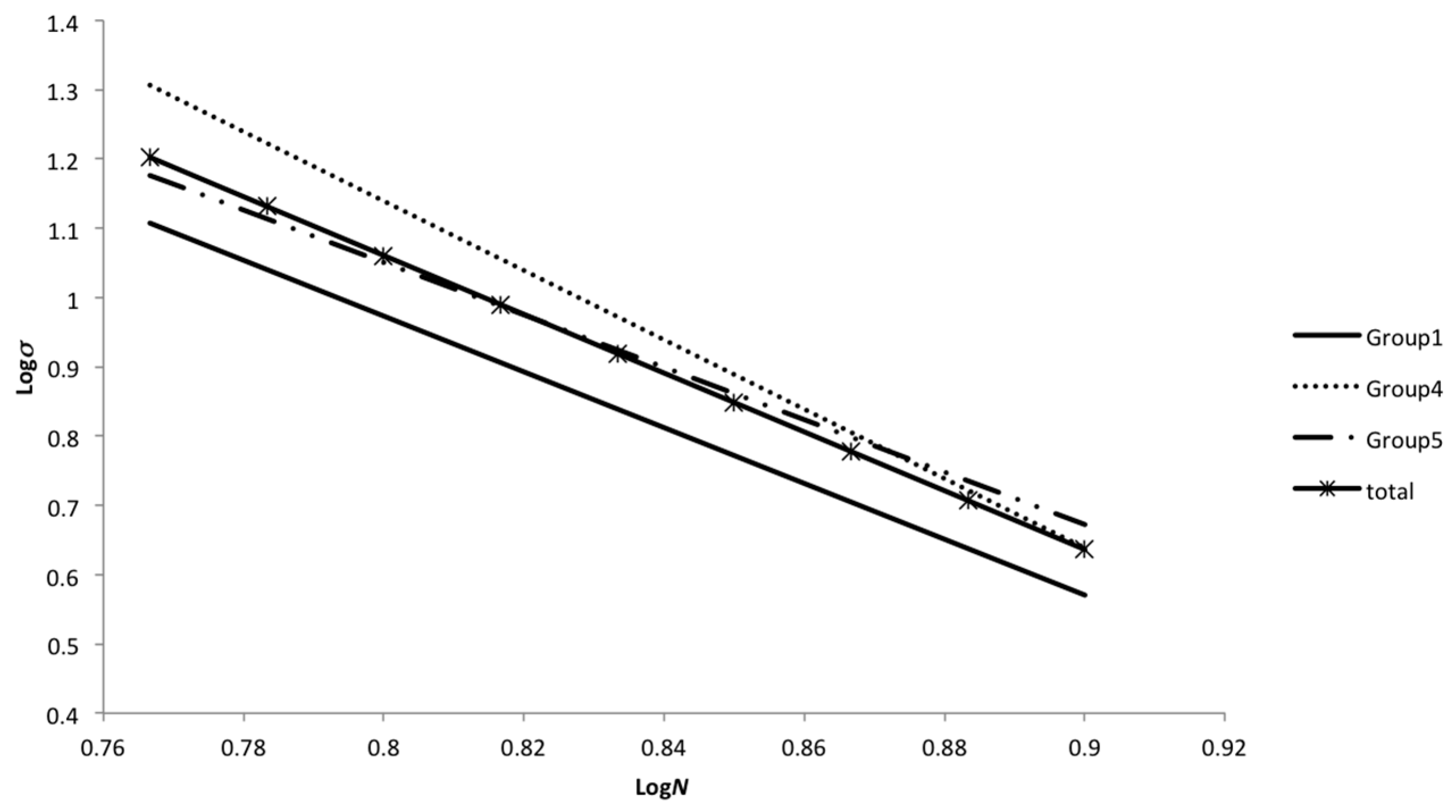
This paper focuses on using analysis of covariance (ANCOVA) for comparing different groups/manufacturing steps of specimens from the casted components. An advantage of ANCOVA is that this method is able to handle different numbers of tests for various groups [
5]. The result of ANCOVA is useful in decision-making processes for companies and manufacturers to choose the better manufacturing process. This will lead to a higher quality of the manufactured components and increase the reliability of the produced components. Further, the results of the ANCOVA analysis are used for the reliability assessment of wind turbine cast components. For this reason, the uncertainties related to model evaluation and the effect of each uncertainty on the reliability level of the components is evaluated. Moreover, a case study is presented to illustrate the application of ANCOVA to compare different manufacturing steps of casted components according to fatigue life results and also the reliability assessment of chosen cast components in wind turbine components based on the ANCOVA results.
3. Statistical Analysis of Fatigue Data Sets
A major challenge in statistical analysis of fatigue data is to establish a statistically homogeneous dataset to be applied as the basis for the statistical analyses. Analysis of variance (ANOVA) is a statistical method that can be used to analyze the differences between mean values of different groups of, e.g., suppliers. ANOVA could be used as a statistical test to investigate equality of the means of several groups, and hence generalizes the classical statistical
t-test to more than two groups [
9]. Based on hypothesis testing, the null hypothesis by the ANOVA method is that the mean values of several groups are equal, and on the other hand, the alternative hypothesis is that the mean values are not equal [
10]. The level of significance represents the probability of making a type I error and is denoted by
α. The level of significance should not be made too small, because the probability of making a type II error will then be increased. In this paper the value of
α = 0.05 is chosen.
ANOVAs are useful in comparing (testing) three or more groups. A decision of whether or not to accept the null hypothesis depends on a comparison of the computed values of the test statistics and the critical values. The ANOVA analysis can be performed computationally as follows; for further details see [
10].
Step 1: Formulation of hypothesis
If a problem involves
k groups, the following hypotheses are appropriate for comparing
k group means [
10]:
where
μ is the mean value in the above equation.
Step 2: Define the test statistic and its distribution
The hypotheses of Step 1 can be tested using the following test statistic:
in which
MSb and
MSw are the mean squares quantifying between and within variations, respectively, and
F is a random variable following an
F distribution with degrees of freedom of (
k − 1,
M −
k); for more details, see [
10]. The following table shows the calculation for the ANOVA. In
Table 1,
k is the number of groups,
mj is the number of data in
j-th group,
is the mean value of all data,
is the mean value of data in the
j-th group and
M is the total number of data [
10].
Step 3: The level of significance
The level of significance is chosen to α = 5% in this paper.
Step 4: Collect data and compute test statistic
The data should be collected and used to compute the value of the test statistics (F) in Equation (2). Each data value is categorized according to the different groups to be compared statistically to each other.
Step 5: Determine the critical value of the test statistic
The critical value is a function of the level of significance and the degrees of freedom. If the computed value of Step 4 is greater than the critical value, the null hypothesis of Equation (1) should be rejected and the alternative hypothesis of Equation (1) accepted.
In addition, the ANCOVA always involves at least three variables to be introduced: an independent variable, a dependent variable, and a covariate. The covariate is the variable likely to be correlated with the dependent variable. For application for fatigue data, these variables are chosen as:
The independent variable is the group types that we consider to compare to each other (for example, test facilities or suppliers);
The dependent variable is the fatigue life N and it is dependent on the test stress amplitude and the type of group;
The covariate is the test stress amplitude,
σ [
5].
The major distinction between the two analyses (ANOVA and ANCOVA) is that in ANOVA, the error term is related to the variation of log
N around individual group means, whereas the ANCOVA error term is based on variations of log
N scores around regression lines. The effect of the smaller within-group variation associated with ANCOVA is an increase of the power of the analysis. Note that the ANOVA distributions have a larger overlap than the ANCOVA distributions [
5]. The analysis of covariance is a combination of the linear models employed in the analysis of variance and regression [
11].
If it is assumed that data from
k groups is available, then the starting point for the ANCOVA is exactly the same as for the ANOVA; the total sum of squares is computed. It is noted that ANCOVA can be used for linear regression methods and therefore the analysis is carried out using the “logarithm of fatigue life (log
N)” and the “logarithm of test stress amplitude (log
σ)”. Hence, the covariate variable (
x) is log
σ and the dependent variable (
y) is log
N. Assuming that there is a linear relationship between the dependent variable and the covariate, we find that an appropriate statistical model is:
where log
Nij is the
i-th observation on the response variable in the
j-th group, log
σij is the measurement made on the covariate variable corresponding to log
Nij,
is the mean of the log
σij values,
μ is an overall mean,
τj is the effect/influence of the
j-th group,
β is a linear regression coefficient indicating the dependency of log
Nij on log
σij, and
εij is a random error component. It is assumed that the errors
εij are normally distributed with a mean value = 0 and a standard deviation of
σε. The null hypothesis is “the group effect is zero (
)” and if the null hypothesis is accepted, then log
σij is not affected by the groups.
3.1. Adjusted Mean
An adjusted mean is the mean dependent variable that would be expected or is predicted for each group, if the covariate variable mean is equal to the grand covariate mean. The grand covariate mean is a unique log
σu and the adjusted fatigue life in each group is estimated according to this stress amplitude. In this way, for each group there is a unique point (log
σu, log
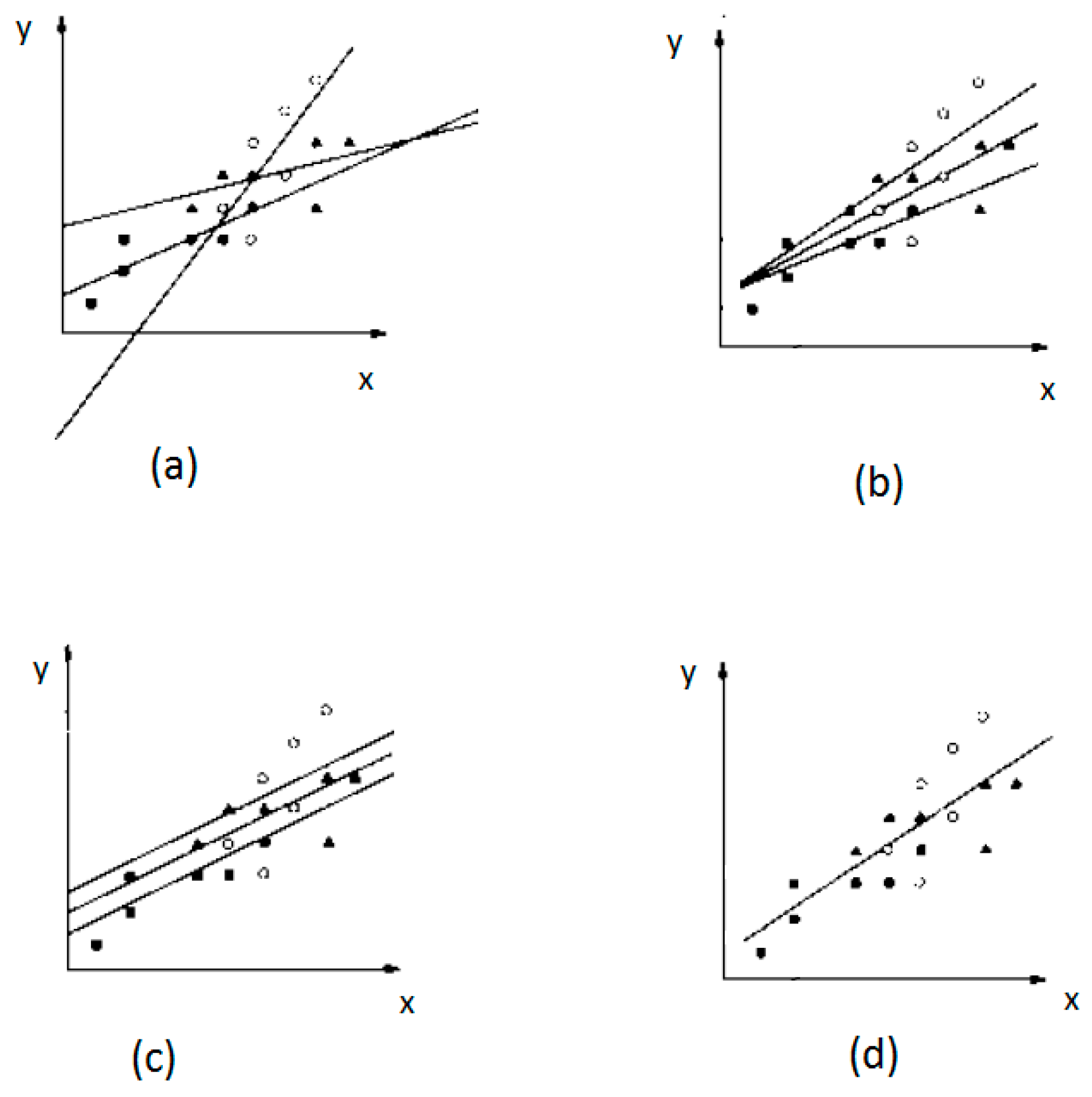
Nj,adj). This value would be different in different groups, and these values can be used to compare the state of the regression lines to each other. According to adjusted means and slopes of regression lines, there are four types of regression line configurations, as shown in
Figure 1 below.
By adjustment of the point and slope for each group, comparisons can be performed. As mentioned above, the purpose of the ANCOVA is to test the null hypothesis that two or more adjusted population means are equal. Alternatively, the purpose could be formulated as to test the equality of two or more regression intercepts. Under the assumption of parallel regression lines, the difference between intercepts must be equal to the difference between adjusted means. The formula for the computation of adjusted means is:
where
is the adjusted mean for the
j-th group;
is the unadjusted mean (mean of fatigue life) for the
j-th group;
bw is the pooled within-group regression coefficient (for details see [
5,
11]);
is the mean of the stress amplitude for the
j-th group;
is the mean of the log
σij values.
3.2. Testing the Homogeneity of Regression Slopes
An assumption underlying the use of ANCOVA is that the population regression slopes are equal. If the slopes are not equal, the “Type of groups” effects differ at different levels of the stress amplitude; consequently, the adjusted stress amplitudes can be misleading because they do not convey this important information. When the slopes are the same, the adjusted means are adequate descriptive measures because the differences of the fatigue life are the same at different levels of the stress amplitude.
If the slopes for the populations in an experiment are equal, that is,
, a reasonable way of estimating the value of this common slope from the samples is by computing an average of the sample
b1 values:
where from Equation (5) we have:
The slope
bw is the best estimate of the population slope
β1, which is the slope assumed to be common to all groups. As long as
, the estimate
bw is a useful statistical value to use. Now the problem is to decide whether all groups have the same slope. The homogeneity of the regression
F-test is designed to answer the question of the equality of the population slopes. The null hypothesis associated with this test is:
The steps involved in the computation of the test are described next:
Steps 1 and 2: Computation of within-group sum of squares and within-group residual sum of squares (SSresw)
This parameter can be evaluated by the following equation (for further details, see [
5,
11]):
Step 3: Computation of individual sum of squares residual (SSresi)
The third step involves the computation of the sum of squares residual for each group separately, and then adding these residuals to obtain the sum of the individual residual sum of squares (
SSresj). The difference in the computations of
SSresw and
SSresj is that
SSresw involves computing the residual sum of squares around the single
bw value whereas
SSresj involves the computation of the residual sum of squares around the
bj values fitted to each group separately (Equation (13)).
Step 4: Computation of heterogeneity of slopes sum of squares
The discrepancy between
SSresw and
SSresi reflects the extent to which the individual regression slopes are different from the within-group slope
bw; hence, the heterogeneity of slopes
SS is “
SShet =
SSresw −
SSresi”, see [
5].
Step 5. Computation of F-ratio
The summary table for the
F-test is as follows (
Table 2). If the obtained
F is equal to or greater than
, then the null hypothesis
is rejected.
In this method, diagnostic checking of the covariance model is based on residual analysis. Furthermore, the measure of uncertainty is not directly related to the uncertainty of the SN curve. The uncertainty of SN curves used in the next section has been evaluated by the maximum likelihood method (MLM) [
2].
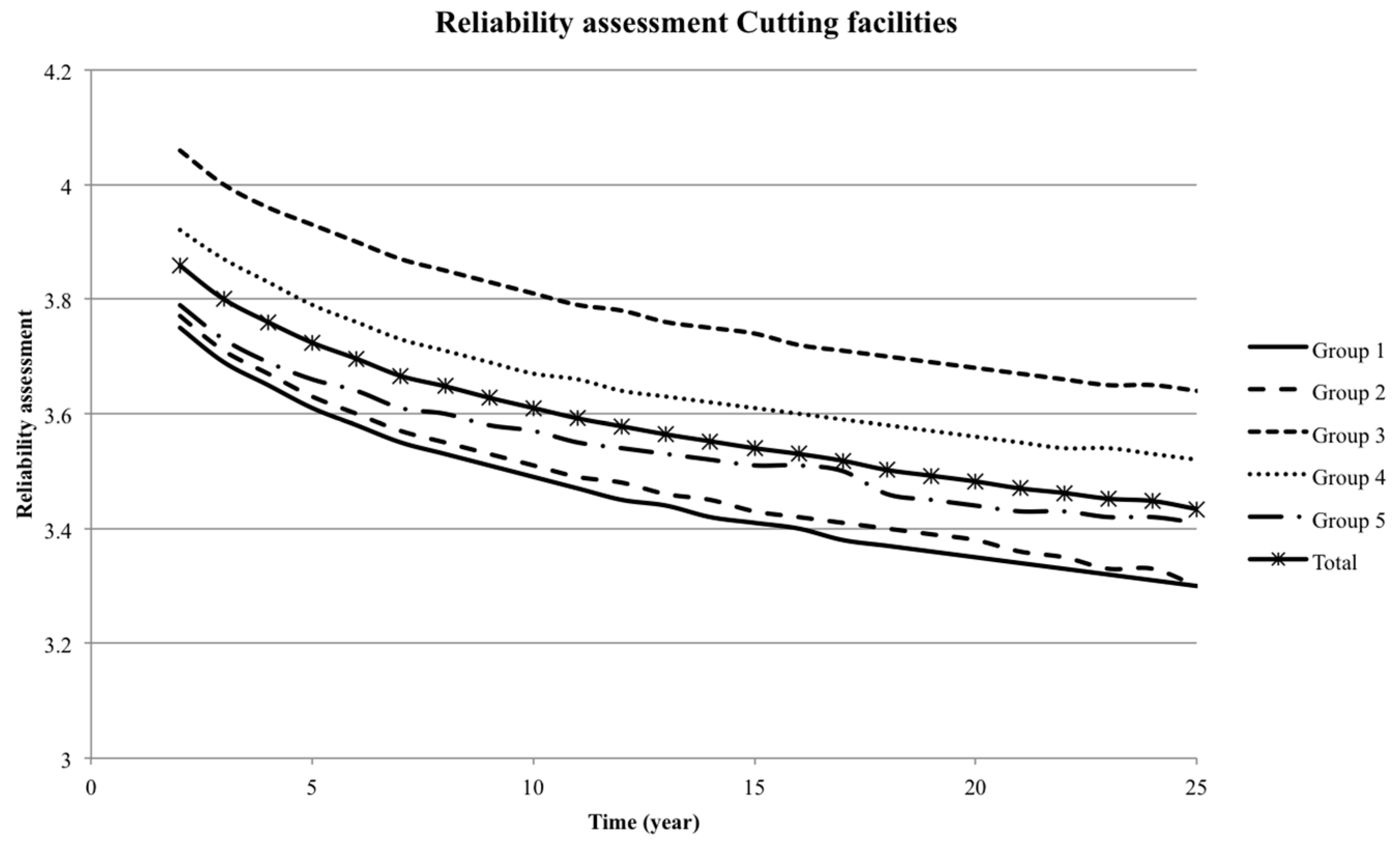
4. Reliability Assessment
The fatigue strength of metals is often assumed to follow the Basquin equation (the equation is based on fully reversed fatigue (
R = −1), i.e., the mean value is zero) and is written [
12]:
where
N is the number of stress cycles to failure with constant stress ranges Δ
σ;
K and
m are material parameters dependent on the fatigue critical detail. The fatigue strength Δ
σF may, e.g., be defined as the value of
S for, e.g.,
ND = 2 × 10
6 [
7]. If one fatigue critical detail is considered, then the annual probability of failure is obtained from:
where
P(fatigue failure in year t) is the probability of failure in year
t and
PCOL|FAT is the probability of collapse of the structure given fatigue failure—modeling the importance of the details/consequences of failure. The probability of failure in year
t given survival up to year
t is estimated by:
where the limit state equation is based on the application of SN curves and Miner’s rule for linear accumulation of fatigue damage, and by introducing stochastic variables accounting for uncertainties in fatigue loading and strength. Note that the probability of failure also depends on the repair and maintenance methods’ accuracy and protective methods that have been applied on the component. The design equation can be written as follows, if used in a deterministic code-based verification:
where
ni,S represents the number of cycles per year at a specific stress level and
TL is the design lifetime. It is assumed that for a wind turbine component, for a given fatigue life, the number of cycle according to the stress can be grouped as
nσ, where the number of excitation at the specific stress range
i is
ni,S per year. In this paper, the Level II reliability method is used to estimate the reliability of the components [
7]. The design parameter
z is obtained from Equation (17), assuming that the fatigue partial safety factors are given. Consequently, the reliability equation is normalized and it became a function of the partial safety factors and presumed that the component is designed to the limit according to the design parameter
z in the design equation.
For a deterministic design, the following partial safety factors are introduced [
13]:
a fatigue load partial safety factor multiplied by the fatigue stress ranges obtained by, e.g., rainflow counting.
a fatigue strength partial safety factor. The design value of the fatigue strength is obtained by dividing the characteristic fatigue strength by .
The characteristic fatigue strength can be defined in various ways, namely based on:
the mean minus two standard deviations of log K.
the 5% quantile of log K, i.e., the mean minus 1.65 times the standard deviation of log K.
the mean of log K.
The corresponding limit state equation to be used in the reliability analysis is written:
where
XW is a stochastic variable modeling model uncertainty related to the determination of fatigue loads and
XSCF is a stochastic variable modeling model uncertainty related to the determination of stresses given fatigue loads. In addition, Δ models model uncertainty related to Miner’s rule for linear damage accumulation [
2]. In Equation (18), Δ,
XW and
XSCF are assumed to be log-normal distributed with mean values equal to 1 and coefficients of variation
COVΔ,
COVW and
COVSCF, respectively, and
can be written as following equation:
The coefficients of variation are estimated partly subjectively, but generally following the recommendations used as a basis for the material partial safety factors in IEC 61400-1, and also considering information from, e.g., [
14]. The importance of the choices of the coefficients of variation is investigated by sensitivity analyses. It is noted that the reliability level obtained is in accordance with the target reliability corresponding to an annual probability failure of the order 5 × 10
−4 (annual reliability index 3.3) [
15]. In
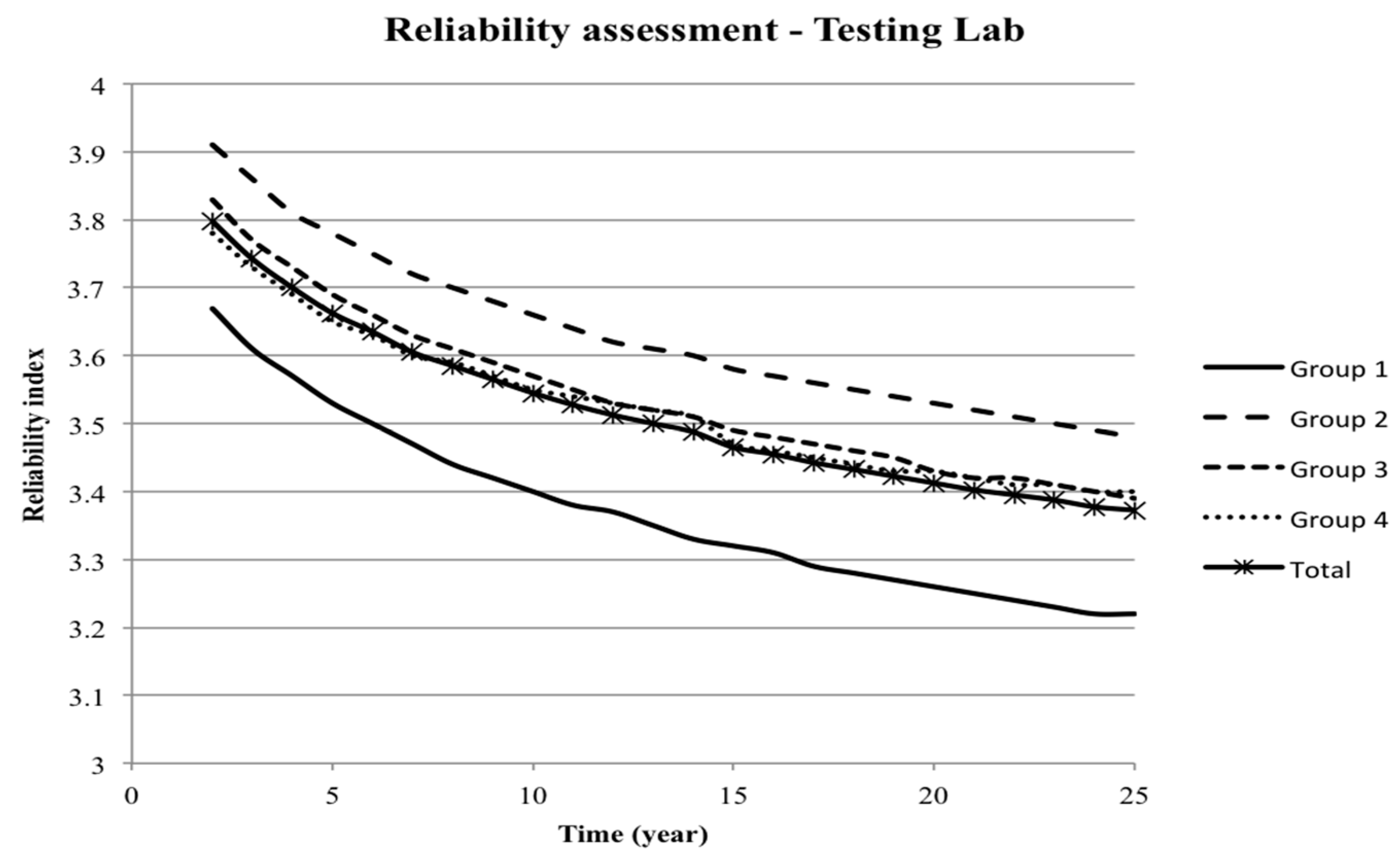
Table 3, the stochastic model is shown. It is noted that
m and Δ
σf are correlated with statistical parameters extracted from [
2]. The stochastic model is considered as representative for the fatigue strength represented by SN curves. It is assumed that the design lifetime is
TL = 25 year [
13].
If the SN curves are obtained by a limited number of tests, then statistical uncertainty has to be accounted for.
Table 4 shows indicative values of
for the target reliability index equal to 3.3 as a function of the total coefficient of variation of the fatigue load:
. It is noted that more fatigue test data should be investigated to validate the indicative values in
Table 4.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}