1. Introduction
Wind power is one of the most significant recycled energy resources presently being applied [
1]. Recently, due to the pollution of the global environment, recyclable energy [
2] and non-polluting sources such as wind energy have been gaining extensive attention [
3]. Wind energy, which is one of the most promising and active recyclable sources, is providing an increasingly strong supplement to traditional energy sources [
4]. When it comes to the accurate forecasting of wind speed and its wide use in wind power, we encounter great challenges, because the wind is a periodical phenomenon [
5] with a nonlinear, anomalistic, and stochastic nature. Wind speed forecasting is applied in several domains, for instance, target tracking, shipping, weather forecasting, agricultural production, and electric load forecasting. To dispatch wind energy before wind power grid integration, it is very important for a wind farm operator to accurately determine the wind speed. This is because the local wind speed is always the foremost factor affecting wind power generation, and can be used for wind turbine selection and for wind farm layout [
6]. In addition, wind speed can enhance the power system’s schedule and strengthen resource configuration, promoting the reliability of the power grid. Predictions made with higher precision can allow power system operators to dispatch power efficiently in order to properly meet the demands of consumers [
7].
Given a more precise wind speed value, the power operator is able to forecast power delivery. This is extremely helpful for power systems in terms of optimizing storage capacity, making sensible and proper programs, and dispatching electric energy well. Because of the wind’s irregularity and complex fluctuations, variations in wind speed forecasting may result in quick changes in the prediction results of wind power. This feature indicates that accurate wind speed forecasting is highly important. The wind speed forecast plays a vital role in utilizing wind power appropriately and efficiently. Various methods have been proposed to promote the accuracy of wind speed prediction. Three of the most extensively used methods are the physical forecasting method, the conventional statistical method, and the artificial intelligence method. Given a series of meteorological parameters, the physical forecasting method uses physical variables to derive a time series forecast. Therefore, higher prediction accuracy can be obtained using this method [
8]. However, their extremely intricate computations always lead to it being largely a waste of time. Numerical weather forecasting is one of the most widely used physical forecasting methods, consisting of a computer program that aims to solve questions through meteorological data processing and describe how the atmosphere changes as time goes on [
9]. In addition, the traditional approaches include the regression analysis method, the auto-regressive integrated moving average (ARIMA) [
10] model, the non-parametric estimation method, exponential smoothing [
11], the state-space model [
12], Box-Jenkins models [
13], the spatial correlation model, and the difference method. Furthermore, support vector machines (SVMs) [
14] such as non-neural networks are also frequently applied in wind speed forecasting.
Among the above methods, artificial neural networks (ANNs) have been frequently and widely applied. By imitating the human brain in handling information with a sequence of neurons, ANNs obtain a distinguished capacity for mapping, and their complex and highly nonlinear input and output modes with making nothing of the type of real model can establish some simple models and compose different networks depending on different connections. Therefore, ANNs demonstrate the following advantages: high adaptability, excellent ability to learn using cases, and ability to summarize. It is well known that the multi-layered perceptron (MLP) is one of the most broadly used ANN methods. The vast majority of available methods that can be used to train ANNs pay close attention only to the alteration of connection weights in a certain topology, which usually leads to defective results.
MLPs are prosperously applied in many fields, such as pattern classification [
15], digit recognition [
16], image processing, coal price prediction [
17], function approximation, measurement of object shape [
18], and adaptation control. The back-propagation (BP) algorithm [
19] performs most effectively of all training algorithms for MLP methods. The selection of a suitable structure for the forecasting question and the alteration of connection weights of the network constitute the two parts of training MLPs for the problem. Several studies have been successfully used to solve these issues.
A great deal of research has been conducted to precisely forecast the wind energy and the local value of wind speed. Wind power and speed forecast is a fundamental problem for wind farm operation, best power flow between the electric system and wind power plant, market price, electric power system dispatching, and wind power resource reserve, and storage programming and dispatching. Over the last few decades, the ANN [
20,
21] has been the superior model, and has frequently been applied to forecast time series.
The ANN is a pragmatic calculation method, similar to the human biological neuron. Various improvable neural networks exist, of which the following two are the most frequently employed: feed forward neural networks and feedback neural networks. Feed forward neural networks have no feedback. On the contrary, feedback neural networks possess a feedback. Back-propagation (BP) neural networks, perceptrons, and radial basis function (RBF) networks play an important role in feed forward networks. Recurrent Neural Networks (RNNs) [
22] and pulsed neural networks are two important models of feedback networks. The feedback networks mainly consist of RNN and spiking neural networks [
23]. In this paper, we pay more attention to feed forward neural networks [
24].
The BP algorithm has various significant advantages; for example, it can help to roughly estimate a great many functions, it is relatively simple to implement, and it can be used as a reference method. In addition, its most effective characteristic is that the momentum parameter and the learning rate factor can be altered, thereby enhancing the innovation speed of the traditional BP algorithm.
To gain good forecasting accuracy and low deviation, many studies [
25,
26,
27,
28,
29,
30,
31,
32] have been conducted to determine the optimal weights of neural networks. However, an original hybrid model system—a traditional hybrid method based on the rapid searching theory developed by Xiao et al. [
33]—has been put into use. An extensive study was conducted by Xiao et al. [
33] using four test functions to evaluate the optimization algorithm’s capacity for development, searching, avoiding partial optima, and convergence velocity, and the results of this experiment demonstrated that the modified method is more sufficient and excellent than the original algorithm. In recent years, a number of developmental optimization algorithms have been applied to help confirm the threshold values of a prediction method. Particle swarm optimization (PSO) was applied by Liu et al. [
25] to optimize the parameters of the prediction technique for short-term electric load prediction in micro-grids. Wang et al. [
26] employed a modified PSO to optimize the weight distribution of their proposed combined model developed for electric load prediction. The cuckoo search (CS) algorithm [
27,
28,
29] was applied to determine the parameters of the proposed model for electric load forecasting. Wang et al. [
30] modified the CS method to optimize the parameters of multi-step-ahead wind speed forecasting models. Xiao et al. [
31] applied the genetic algorithm (GA) to optimize the parameters of the proposed model. In the present paper, a highly valid optimization method, the Broyden-Fletcher-Goldfarb-Shanno-Firefly Algorithm (BFGS-FA), is used to determine the parameters of the proposed hybrid model.
Recently, numerous continuous and novel improvements have been made to promote the effectiveness of the FA for optimizing neural networks, including the binary, Gaussian, firefly, high-dimensional firefly, Lévy flight, simultaneous firefly, and chaos-based FA [
34,
35]. Though most of these improvements to the FA enhance its performance successfully, few of them have been introduced to optimize the parameters of hybrid models. This paper intends not only to enhance the research and development abilities of the FA, but also to minimize the drawback of the partial optima seeking capacity, which appeared in the CS algorithm. On the basis of the BFGS quasi-Newton method, an original improvement of the FA was proposed to enhance the diversity of species of fireflies. Obviously, increasing the convergence standard may result in individual fireflies likely being caught in partial optima; however, it decreased when this optimized algorithm was used. Of course, the decomposition of the original wind sequence is a significant process for data filtering. This can always effectively promote the prediction accuracy of the model to obtain better forecast results [
36]. Important techniques, such as empirical mode decomposition (EMD) [
37], wavelet decomposition (WD) [
38], and singular spectrum analysis (SSA) are often applied to remove the noise series. However, the wavelet de-noising algorithm is sensitive to the determination of the threshold, and the EMD may lead to mode confusion [
39], which may result in a badly decomposed performance. In addition, SSA has many advantages, and overcomes the disadvantages of EMD and WD in terms of decomposition. Moreover, we analyzed some articles in the literature [
40,
41,
42,
43,
44] that deal with wind forecasting by applying neural networks, and that are in line with the theme of the present paper. From these studies, we found that some data preprocessing or optimization algorithms are insufficient, and the details are listed in
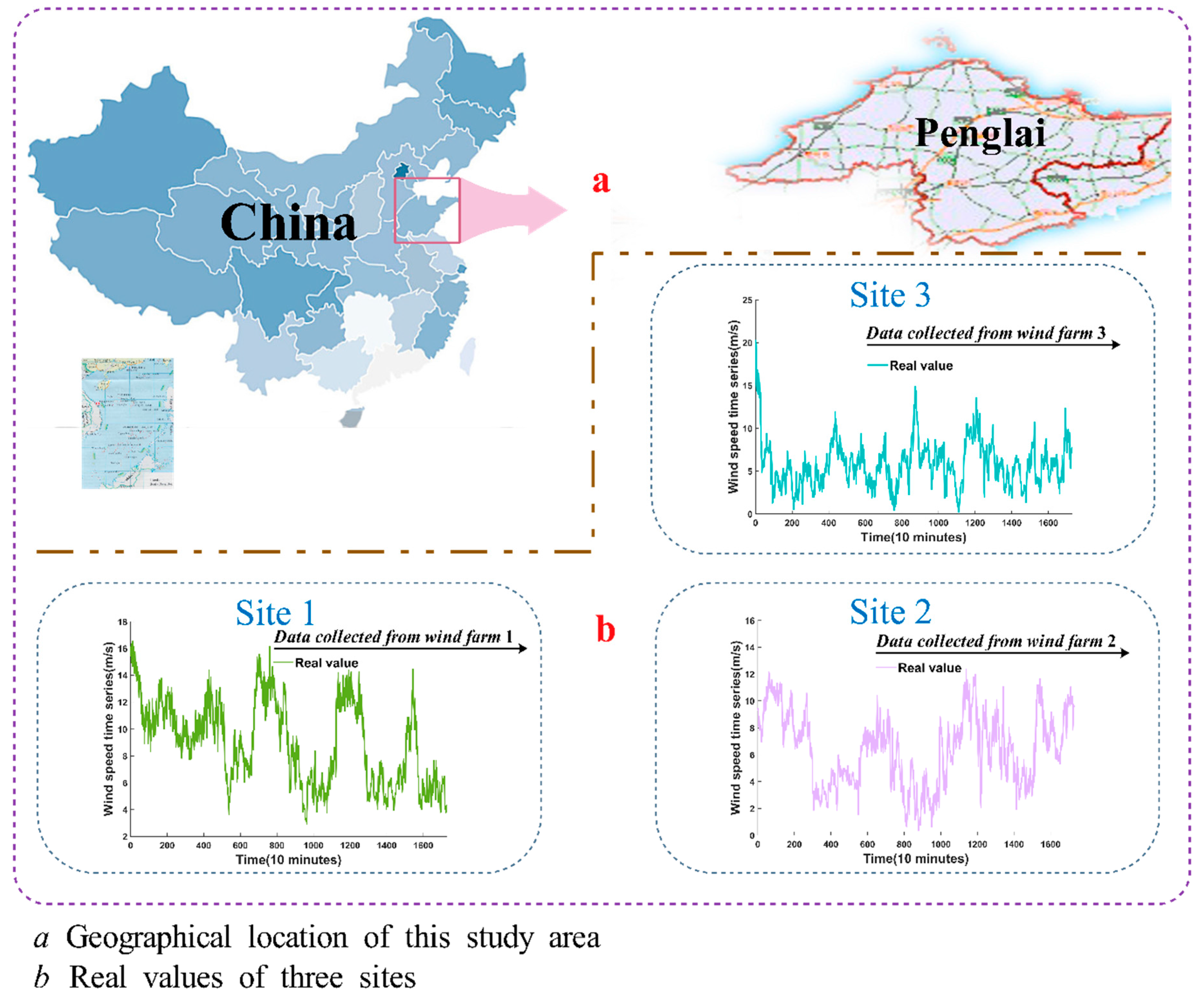
Table 1. Therefore, based on the discussed limitations, this manuscript proposes a characteristic hybrid model that unites the BP algorithm, SSA theory, and BFGS-FA. Ten-minute wind speed values collected from Penglai city, Shandong province, China, were applied to verify the unique hybrid model. The results of tests and practices in this study indicate that the hybrid model considerably outperformed the other three models. This demonstrates that the hybrid method could be applied to calculate wind speeds, which would be beneficial for enabling wind power system to make optimal decisions, such as providing better sites of wind power, taking early measures to reduce losses that can be caused due to bad weather, reducing production costs, and minimizing energy consumption (coal, etc.). This model is also useful for helping wind power companies to make correct decisions in real life. Thus, the hybrid forecasting method with high accuracy represents a model that will have potential application in the near future. Furthermore, the practical hybrid model can also be applied to other forecasting domains, such as target tracking, stock index forecasting, environment forecasting, shipping, weather forecasting, agricultural production, and electric load forecasting.
The primary contributions and novelties of this manuscript are listed as follows: (a) The BFGS-FA method, back propagation neural network (BPNN), and the concept of the de-noising algorithm were combined to form two new models: singular spectrum analysis-back propagation (SSA-BP), and singular spectrum analysis-Broyden-Fletcher-Goldfarb-Shanno-Firefly Algorithm-back propagation (SSA-BFGS-FA-BP). (b) This paper evaluates the developed models on the basis of two aspects: forecasting accuracy and stability. The results indicate that BFGS-FA-BP is a better model when considering accuracy only, but the hybrid SSA-BFGS-FA-BP is a better model overall: even with the low cost of calculation, the accuracy remained high. (c) The novel combined BFGS-FA algorithm successfully avoids the shortcomings of FA while optimizing, during the later period, the low velocity and the poor convergence performance. (d) The proposed hybrid approach integrates the advantages of other individual models. (e) A time sequence pre-processing method was applied to de-noise the raw data successfully.
The remainder of this paper is designed as follows.
Section 2 presents the single prediction method developed according to the BPNN and the hybrid forecasting method theory. This section also describes the optimization algorithms BFGS, FA, and their combination BFGS-FA, which are applied to confirm the parameters of the hybrid forecasting model. SSA theory and the Diebold-Mariano (DM) test, which can help to determine the forecasting effectiveness of the developed hybrid method, are introduced at the end of
Section 2. In
Section 3, the wind speed time sequences collected from three separate sites are used to test the proposed hybrid model. Subsequently, the wind resources and the evaluation criteria of the forecasting model are described. In
Section 4, we give a discussion about this study. In the end,
Section 5 concludes this paper.
2. Methodology
Since McCulloch and Pitts [
45] proposed the neural network mathematical model in 1943, ANNs have been applied in numerous fields, including signal processing, market analysis and forecasting, pattern recognition, and automatic control. In this part, separate theories of this innovative hybrid model will be introduced in detail.
2.1. BP Algorithm
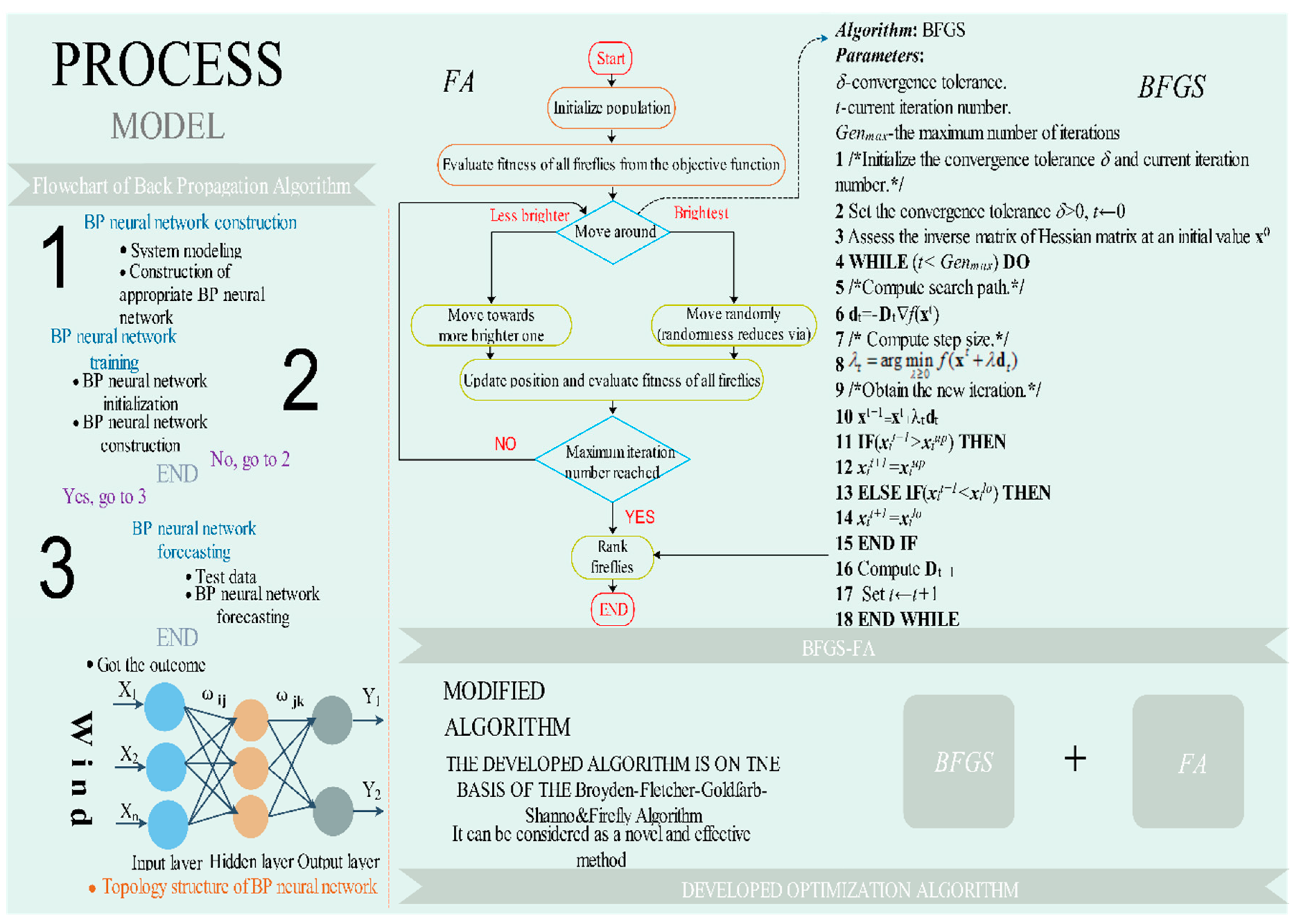
In mathematically simulating the human brain system, the BP algorithm benefits from its underlying processes, fuzzy information processing, and chaotic performance. On account of the error BP algorithm and the multilayer neural network, the BP neural network performs excellently in training ANNs. An input layer, one or more hidden layers, and an output layer constitute a representative BP network. The BP algorithm is always applied to adjust the thresholds, in which the errors from the output are propagated back into the network, transforming the thresholds as it goes, in order to keep the error [
46] from emerging again. Its topology and flow structure are as follows:
The main procedures of the BP algorithm can be generalized as follows:
Step 1. We obtain the wind speed time sequence and corresponding parameter values from the wind power plant. The inputs have exhaustive information on historical values. The input value is often affected by the site, surrounding temperature, air pressure, time, and even the collectors. Our primary task is to make full use of four different parameters collected from the wind power plant.
Step 2. We transform the original value into the requested form (0 to 1). The normalization method is summarized as follows:
Step 3. We build the BP algorithm and set its parameters, which include the number of neurons in the input layer, hidden layer, and output layer; the learning rate; the maximum training times; and training requirement accuracy. The training can be summarized as learning from the historical values to discover the implied information among the previous time series data, which can be applied to forecast the future wind speed.
Step 4. We use the testing set to assess the effectiveness of the trained BP network.
Step 5. In the end, the future wind speed value (output) is forecast by the neural network.
The key parameters that emerged in this study are not sensitive in small intervals; therefore, the key parameters of these algorithms are determined by repeated trails. The corresponding experimental parameters of the method are summarized in
Table 2 and
Table 3.
2.2. Broyden-Fletcher-Goldfarb-Shanno
The BFGS [
47] algorithm is an excellent method, and one of the most useful nonlinear quasi-Newton procedures.
Definition 1. Let xt be the consequence at the representative iteration t and be a recursive function in which λt is the step size. The hunting path is , in which Dt is an positive certain symmetric matrix as a proximity of the inverse matrix of the real Hessian matrix at xt.
Definition 2. The new path of BFGS can be designed as follows:where In addition, the primary BFGS algorithm is generalized in Appendix A. 2.3. Firefly Algorithm
The FA was first proposed by Xin-She Yang in 2008 [
48]. The FA was inspired by the flashing nature of fireflies [
49,
50]. The firefly will be shining while flying, which can be regarded as a signal to attract other companions. The method has three regulations:
- (1)
All fireflies are unisexual; in addition, any firefly can be attracted by others.
- (2)
Attraction is directly proportional to their brightness; that is, for any two fireflies, the less bright one will be attracted by the brighter one, and will move towards it; the brightness will decrease as the distance between them increases.
- (3)
If there are no brighter fireflies around a known firefly, it will fly at random. The brightness of the firefly must be tightly related to the objective function.
The experimental set points of the FA are described in
Table 3.
The FA is a developed computational method that is also used to optimize controller parameters. Each firefly in the FA indicates a solution to the problem, which is defined on the basis of position. In a d-dimensional vector space, the present location of the ith firefly is acquired by
. The random positions of
m fireflies are initialized within the specified range. The position updating equation for the ith firefly, which is attracted to move to a brighter firefly
j, is given as follows:
In addition, the position updating equation for the brightest firefly is given as follows:
where the first terms
xi(t) and
xbesti(t) of Equations (4) and (5) are the current positions of a less bright firefly and the brightest firefly, respectively. The second term in Equation (4) is the firefly’s attraction to light intensity.
β0 is the original attraction at
r = 0,
γ is the absorption parameter in the range [0, 1], and
is the distance between any two fireflies
i and
j, at position
and
, respectively, and can be formulated as a Cartesian or Euclidean distance as follows:
where
and
are the position vectors for fireflies
i and
j, respectively, with
representing the position value for the dimension, and the third term in Equation (4) and the second term in Equation (5) are used to reduce the randomness; that is, the movement of the fireflies is gradually reduced according to
α =
α0δt, where
α0 is in the range [0, 1].
δ is the random reduction parameter where 0 <
δ <1, and
t is the iteration number. Every new position must be evaluated by a fitness function, which is assumed to be integral square error. The flow chart of the FA is presented in
Figure 1, and the original FA algorithm is summarized in
Appendix B.
2.4. BFGS-FA
FA possesses good global optimization and development capacities; however, it will usually be manifest a low velocity and poor convergence performance while optimizing in the later stage. Therefore, as shown in
Figure 1, the BFGS is applied while FA renews the answers after a generation to search for a sub-optimization solution, which can be used to promote the partial optimization capacity and the rate of partial convergence of the total method. The primary method of BFGS-FA is generalized in
Appendix C.
2.5. Singular Spectrum Analysis (SSA)
In America and England, SSA has been exploited separately based on singular spectrum analysis, whereas in Russia, it was proposed under the name Caterpillar-SSA [
51]. SSA possesses the superiority of statistics and probability theory; meanwhile, it assimilates the knowledge of power systems and signal processing ideas.
Suppose that
is a time sequence with
T elements. The SSA method contains two parts: decomposition and reconstruction [
52,
53].
2.5.1. Decomposition
In decomposition, an observed unidimensional time series data is converted into its trajectory matrix. Subsequently, and its corresponding singular value decomposition (SVD) are computed. This can be divided into two steps: embedding and SVD.
Step 1. The primary aim of this step is to propose the concept of the trajectory matrix or deferred edition of the initial time sequence
y. The main purpose of this step is to propose the concept of a trajectory matrix or a hysteretic version of the initial time sequence
y. The resulting matrix has a window width
W (
W ≤ T/2), which is usually determined by the operator. Suppose that
P = T − W + 1, the trajectory matrix is denoted as follows:
In fact, this trajectory matrix is a Hankel matrix; that is, all the elements of the diagonal
i +
j = const are equal [
54].
Step 2. We obtain the covariance matrix
from
X.
processed by the SVD will result in a group of
L eigenvalues
and their corresponding eigenvectors
U1,
U2, …,
UL, which are often defined by empirical orthogonal functions. Therefore, the SVD of the trajectory matrix could be denoted as
, where
,
d is the rank of
(the total amount of non-zero characteristic values) and
V1,
V2,…,
Vd are the corresponding principal components, which are denoted by
. The set (
,
Ui,
Vi) is the ith eigenvalue of the matrix
X. Suppose that
, then
—the ratio of the variance of
X—which is defined by
Ei:
E1, has the highest contribution [
55], and
Ed has the minimum contribution. The SVD will consume more elapsed time if the length of the time sequence is long enough (i.e.,
T > 1000).
2.5.2. Reconstruction
We compute and its SVD to obtain its L eigenvalues: and its corresponding eigenvectors. Each signal, as represented by the eigenvalue, is analyzed and assembled to reconstruct the new time series. This section can be resolved into two steps: grouping and averaging.
Step 1. Here, the designer chooses r out of d eigenvalues. Define to be a set of r chosen eigenvalues and , in which is connected to the “information” of y; nevertheless, the remaining (d–r) eigenvalues, which are not selected, represent the error term ε.
Step 2. The set of r elements chosen from the foregoing section is then applied to regroup the definitive elements of the time sequence. The fundamental concept is to convert each of the terms into the reconstructed data time series by using the Hankelization process H(Z) or diagonal averaging: assume Zij is an element of the ordinary matrix Z, then the kth term of the rebuilt time sequence could be acquired by averaging Zij, on the precondition of i + j = k + 1. Obviously, H(Z) is a time sequence with T elements rebuilt by matrix Z.
After averaging, we can obtain the approximation of
y, which is the regrouped time series, and is given as follows:
From the whole time series, a singular eigenvalue will be reconstructed as suggested by Alexandrov and Golyandina. This indicates that SSA is not an awkward algorithm, and is therefore strong to abnormal values.
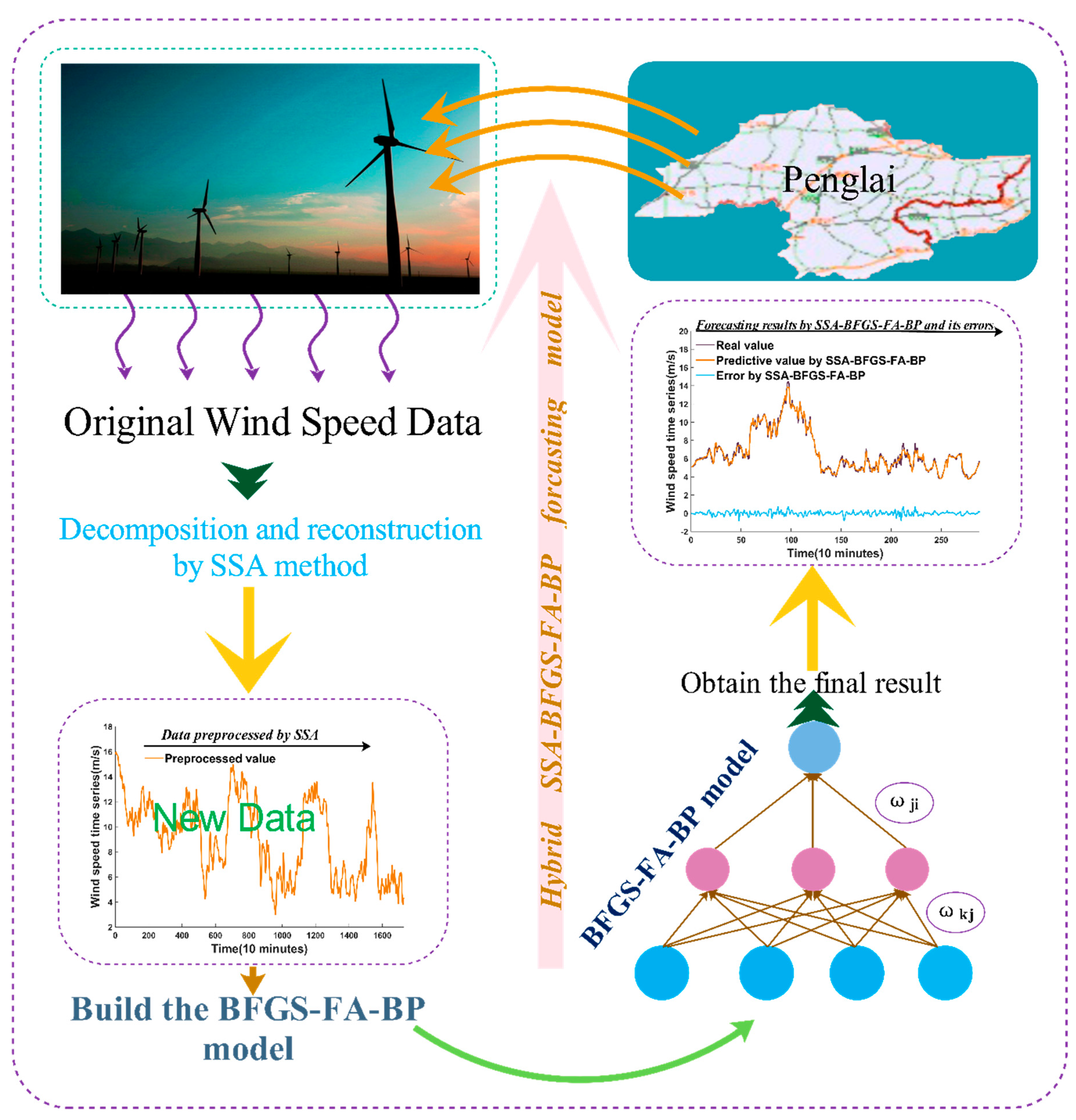
In addition, as shown in
Figure 2, the original wind speed preprocessed by SSA is forecast by the BP algorithm, and its parameters are optimized by BFGS-FA.
2.6. Proposed Hybrid Model
The BP algorithm is selected as the forecasting method to forecast the wind speed time series in this paper. However, because of its unstable structure, we could not obtain more accurate forecasting results with minor error; therefore, it is important to determine the optimal parameters and threshold values of the BP network to promote the predictive effectiveness. BFGF-FA is proposed to determine the weight and threshold. In addition, large amounts of noise present in the original wind sequence will lead to a poor forecasting performance. Therefore, we choose the SSA to remove the noise from the raw time sequence. The corresponding basic procedures are presented as follows, and are depicted in
Figure 2.
Step 1. SSA is used to remove the noise from the raw data. It also aims to remove the high frequency of the original sequence after decomposing, and then reconstructs them into new experimental data.
Step 2. BFGS-FA is used to determine the weight and threshold of the BP neural network. Thus, the ability of the global optimization of the BP algorithm is greatly promoted.
Step 3. The optimized BP neural network is applied to predict the wind speed time sequence.
Step 4. The proposed hybrid model indeed outperforms the single models in forecasting time sequences based on historical values. Multi-step forecasting also proves that the proposed hybrid method has a higher effectiveness, and their forms can be described as follows:
- (1).
One-step prediction: The predictive value is calculated on the basis of the past time sequence , where t is the sample size of the wind speed time sequence.
- (2).
Two-step prediction: The predictive value is calculated on the basis of the past time sequence and the former predictive value .
- (3).
Three-step prediction: The predictive value is calculated on the basis of the past time sequence and the former predictive value and .
- (4).
Higher-step forecasting value will be obtained on the basis of the above form.
2.7. Testing Method
In this paper, we also employed a testing method called the Diebold-Mariano (DM) test to estimate the proposed model.
The Diebold-Mariano (DM) test [
56], which is focused on predictive accuracy, compares and evaluates the predictive effectiveness of the proposed hybrid method with other simple models. In practical applications, there will be two or more time sequence models available for predicting a specific variable of interest.
The prediction errors according to the two models can be described as follows:
and:
The precision of each forecasting model is evaluated by an appropriate loss function, .
The most widespread and available loss function is square error loss, and its formulation is as follows:
The DM test statistic assesses the prediction according to the random loss function
L(
p):
where
S2 is the estimated value of the variance of
, and the null hypothesis is:
in contrast, the alternative hypothesis is:
Under the null hypothesis, the two predictions possess uniform precision. In contrast, the alternative hypothesis has different standards, namely, the two predictions differ in accuracy. If the null hypothesis is right, the Diebold-Mariano statistic will be an asymptotically standard normal distribution
N(0,1). The null hypothesis should not be refused if the calculation of DM statistic falls inside the interval [−
Zα/2,
Zα/2], otherwise we must reject it; that is, the reject region is (−∞,−
Zα/2)&(
Zα/2,+∞), which is defined as follows:
where
Zα/2 is the positive
Z-value from the standard normal table according to half of the confidence level
of the experiment.
5. Conclusions and Future Work
As a kind of non-polluting and renewable energy source, wind energy has been increasingly applied in the development of industry and agriculture, and its forecasting is becoming increasingly important for wind farms. Recently, academia and wind farm projects have been gradually paying more attention to wind speed forecasting. Perfect prediction can not only reduce costs and enhance personal safety, but also help wind farm management develop more effective programs. The accuracy of a model is as important as its stability in forecasting. It is of great interest to propose an outstanding method for wind speed prediction with high accuracy and long-term stability. Nevertheless, wind speed prediction has been generally considered a challenging task in terms of the effects of various intangible factors, such as temperature, location, tides, atmospheric pressure, and other factors. In this paper, to overcome these difficulties, a hybrid model that combines the SSA approach, BFGS-FA algorithm, and BP method is presented.
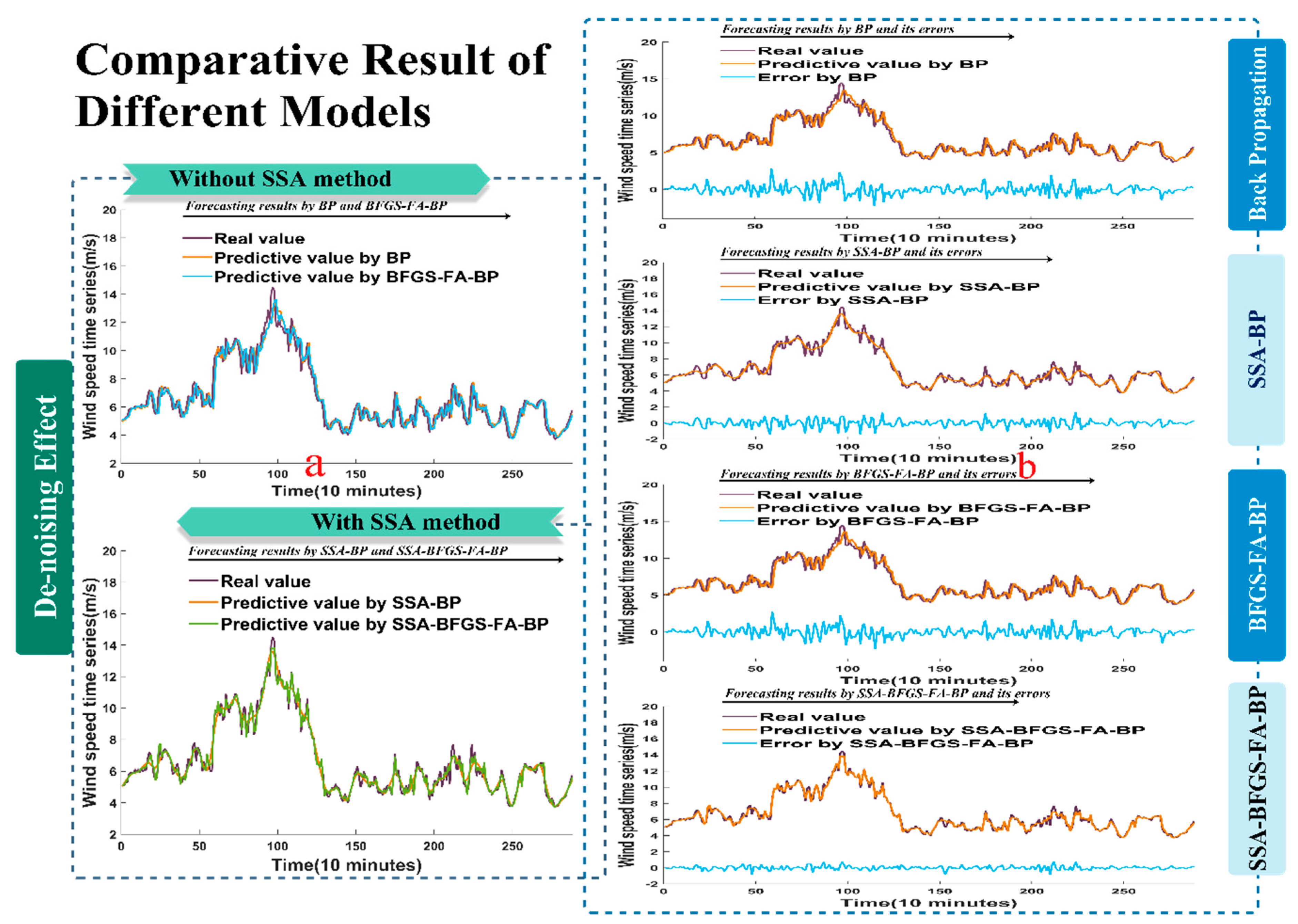
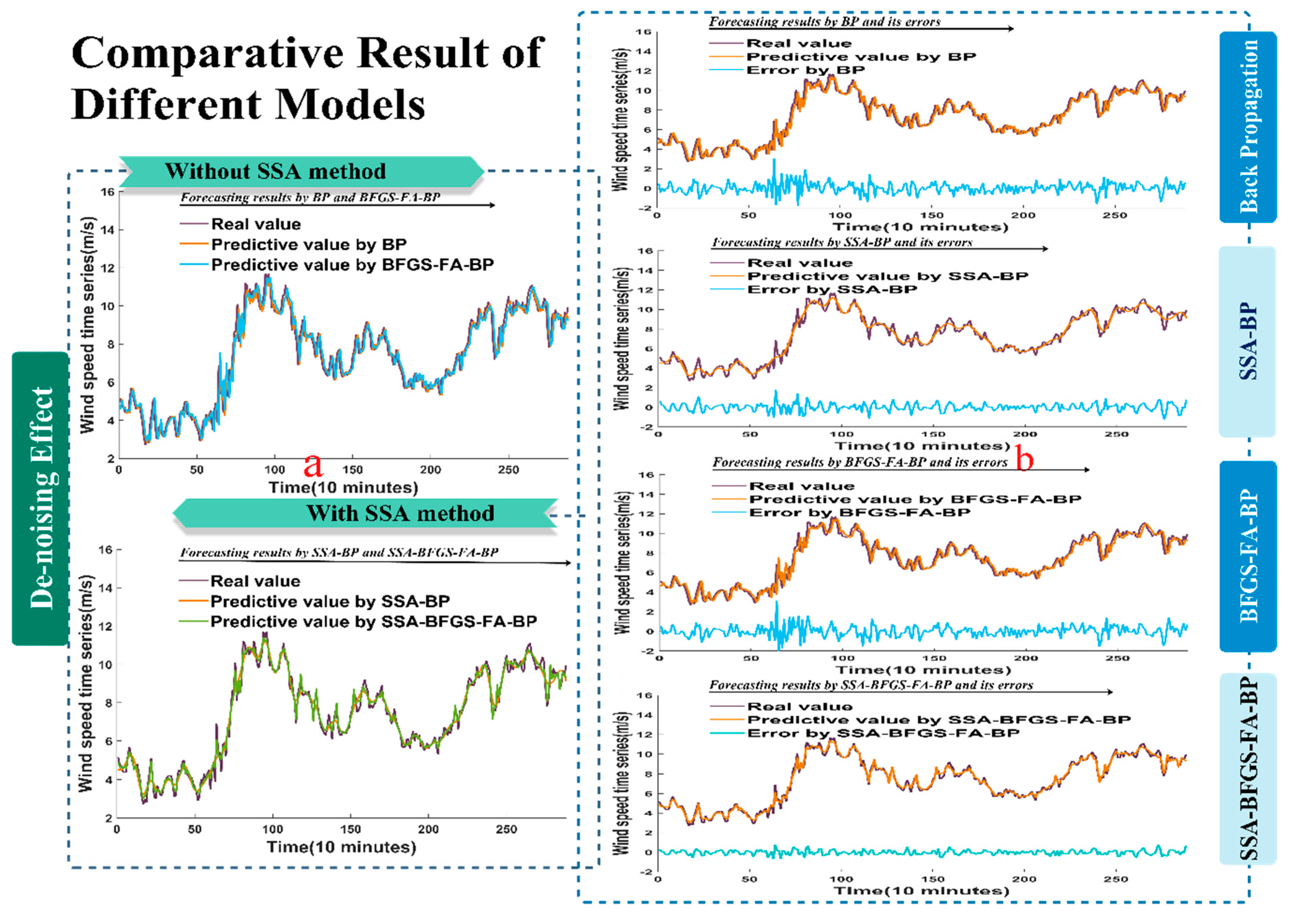
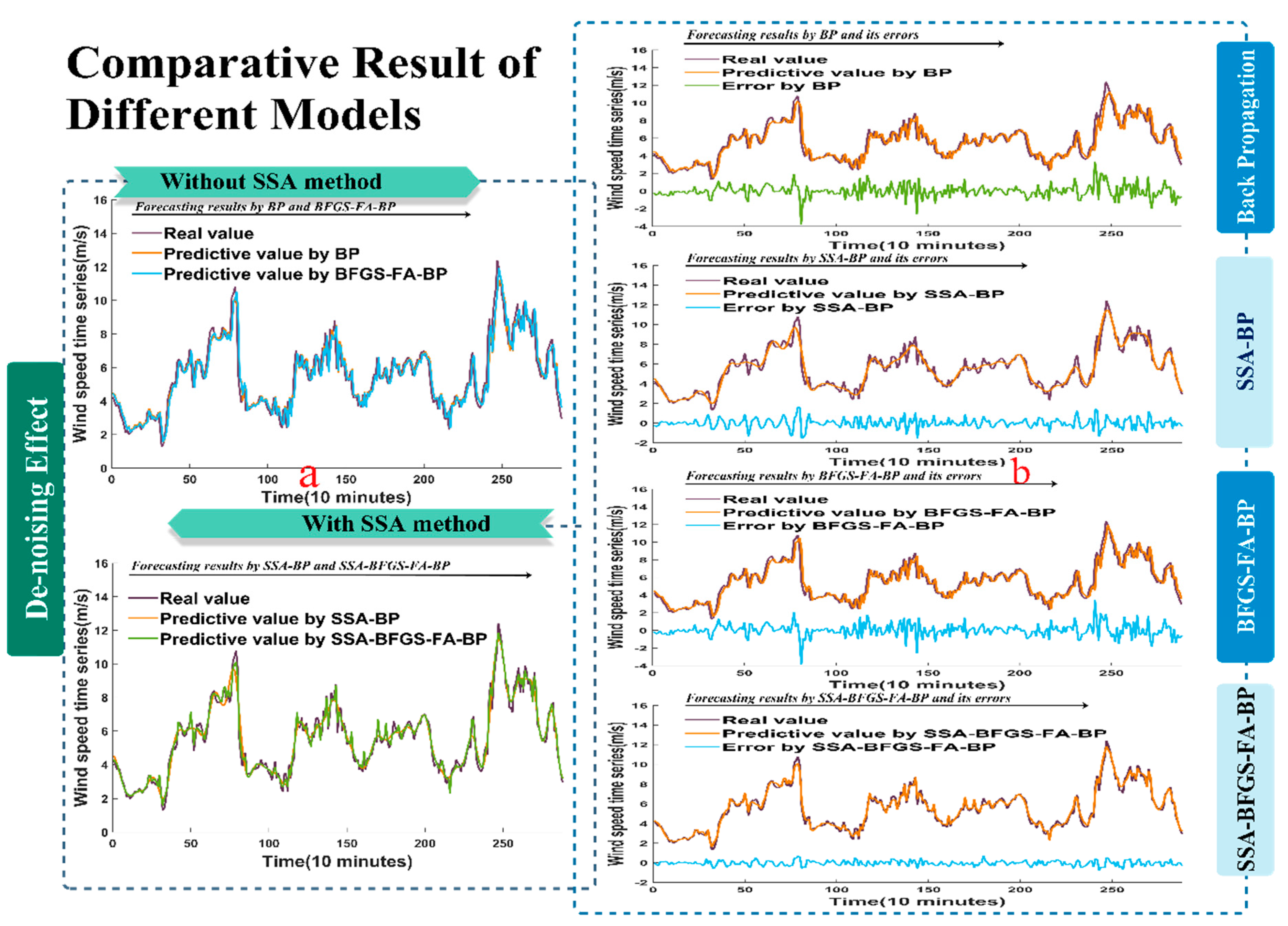
The results based on evaluation criteria such as the MAE, RMSE, MAPE and a statistical test are shown in a sequence of charts, in which the superior qualities of the developed hybrid method are revealed most vividly. From the data in the tables and figures, we can draw the conclusion that the proposed hybrid method achieves the best forecasting effectiveness and a higher stability and reliability.
SSA is a practical decomposition approach, which can remove the noise from the raw data, leaving the principal component for forecasting. The BP model, based on feed forward neural networks, has increasingly turned into a fairly distinguished tool. It is shown that the BP model can get its final predictive results in a remarkably short time.
In brief, the hybrid model always has the lowest MAPE value compared with other single forecasting methods, which implies that the hybrid method has the best performance and higher reliability. Improvements in forecasting accuracy and stability can not only help to save large amounts of energy and money, but also help to reduce the time the system requires. The experiments performed in the present study show that the developed hybrid method is a potential algorithm with high accuracy. In addition, the hybrid method could be applied to other fields of practical engineering, such as electric load forecasting, stock price prediction, and solar resource forecasting.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}