1. Introduction
With the never ending increase in world fuel demand, biodiesel has emerged in recent decades as one of the main alternatives to petroleum diesel [
1]. Biodiesel can be used in conventional diesel engines. Engine performance is comparable to that that provided by petroleum. No changes to fuel handling or the delivery systems are required. Diesel fuel is known as a substitute for, or an additive to, diesel fuel. Nevertheless, it is normally produced from fats and oils of plants and animals [
2,
3]. In addition, waste cooking oil is a potential sustainable alternative for vegetable oils, as it solves the disposal problem and reduces the cost of raw material [
4,
5]. A vast quantity of waste cooking oil is generated annually. The methods by which it is disposed of pose a problem, and may result in contamination of water in the environment. Thus, using waste cooking oil to produce biodiesel is an excellent way to use it economically, efficiently, and in an eco-friendly manner [
6].
Biodiesel is produced from vegetable oils by direct transesterification. Triglycerides react with short-chain alcohols in the process. An alkaline catalyst, usually sodium hydroxide (NaOH) or potassium hydroxide (KOH) is used in the process to improve the solubility and hasten the reaction. (KOH) [
7,
8,
9]; this increases the solubility and speed of the reaction.
The common method to produce biodiesel is by transesterification. In this method, according to stoichiometry, one mole of triglyceride and three moles of alcohol react in the presence of Sodium Hydroxide (NaOH) to produce a mixture of glycol and fatty acid alkali esters (biodiesel) [
10,
11] (
Figure 1). This transesterification process is influenced by several variables that can be optimized. However, expensive and time-consuming laboratory tests are required to optimize those variables in an experimental fashion. The biodiesel yield is affected by such variables as process temperature, type and dosage of catalyst, agitation time and speed, water content and impurities [
12,
13,
14]. Also, the type and quantity of products that are created during frying affect the biodiesel properties and transesterification reaction. For example, the methyl ester yield is affected by the water that is contained in waste cooking oil; this aids in the saponification reaction [
15,
16,
17]. Pretreating the line prior to transesterification is necessary to remove the undesirable compounds that waste cooking oil contains.
Transesterification of waste cooking oil was involved in the present work. The process used NaOH as a base catalyst. Soft computing and machine learning formed the basis of the optimization process; these are useful in solving problems in engineering and optimization [
18,
19]. Biodiesel production is influenced by several parameters. Therefore, the determination of the optimum values of these parameters is crucial for biodiesel production performance and scaling up. Mathematical and statistical-based models can provide vital information for the understanding, analysis and prediction of transesterification processes and are required for the optimization of parameters of these processes to improve biodiesel properties. Modelling and optimizing biodiesel production processes will contribute to a greater understanding of the transesterification process features like yield and production rate [
20].
A successful optimization study for biodiesel manufacturing process could assist manufacturers in the future development of mass production facilities. Traditionally, modelling and optimizing biodiesel have been carried out using Design of Experiments (DoE) [
21] and optimization techniques [
22,
23,
24,
25]. These approaches have been used extensively and their concepts and limitations are well known. For example, the factorial DoE has been shown to be unappealing, since it is time consuming, resource demanding and requires intensive work when the numbers of input factors are increased [
26].
To date, most of the methods used in studies to optimize biodiesel production process conditions are based on Response Surface Methodology (RSM) and Artificial Neural Networks (ANN). However, regression models that have been based on Support Vector Machines (SVM) have also been implanted in recent years. They have been used for the study of the study biodiesel production process conditions and alcoholysis reactions [
27]. Following this approach, some researchers modeled and optimized various factors that affect the transesterification process by using regression models that are based on data mining techniques. For example, the molar ratio, reaction temperature and amount of catalyst in biodiesel production were examined in Moradi, et al. [
28] as operational conditions with the biodiesel yield estimated with the use of ANN. Fernandez et al. [
29] used Genetic Algorithm (GA) and ANN to optimize biodiesel production process parameters. Both works used experimental data as the basis for modelling and optimizing. Corral et al. [
23] employed RSM to optimize the biodiesel from waste cooking oil. Mumtaz et al. [
24] used RSM to optimize biodiesel that was produced from rice bran and sunflower oil. RSM was used by Mansourpoor and Shariati [
25] to optimize biodiesel from sunflower oil. Yuan et al. [
21] examined the production of biodiesel from waste rapeseed oil that had a high level of free fatty acids for use as feedstock for biodiesel production. They optimize with RSM the conditions necessary for maximum conversion to biodiesel. They also sought to understand the importance of factors that are relevant to biodiesel production and their interaction.
In addition, many studies have proposed machine learning model approaches, such as ANN or SVM, as alternative methods to solve complex and ill-defined problems [
30]. ANN has become popular due to its usefulness in prediction capability, even with small databases. This methodology could be employed in simulators to control and optimize processes. For example, Moradi et al. [
28] used ANN to obtain the optimal combination of inputs or process variables in biodiesel yield. Yuste and Dorado developed an ANN model to simulate biodiesel production by the transesterification of used frying olive oil [
18]. In addition to proposing the use of ANN for predicting aspects of biodiesel production, various studies have presented ANN combined with an optimization technique for different optimization purposes. For example, Rajendra et al. [
29] used hybrid ANN-GA to optimize biodiesel production. In this case, the input parameters for the ANN to generalize the pretreatment process were catalyst concentration, methanol to oil molar ratio, the initial acid value of vegetable oil and reaction time. The output parameter was the final acid value of biodiesel. Betiku and Taiwo [
31] used RSM and ANN to optimize bioethanol production using breadfruit as a potential substrate. Mathematical models were also employed in forecasting the bioethanol yield. More recently, Betiku et al. [
2] used ANN, combined with GA and RSM, to model and optimize the process parameters of biodiesel production from the Shea tree (Vitellaria paradoxa).
However, although extensively used, both ANN and GA have deficiencies and other techniques can improve the results. Thus, more advances in the hybridization of prediction and optimization algorithms are still required to optimize the transesterification reaction of biodiesel. In one study, Kusumu et al. [
27] investigated the variables that affect the acid-catalyzed transesterification process of Ceiba Pentandra oil, using the SVM approach to optimize five aspects of transesterification (catalyst weight, the molar ratio of methanol to oil, reaction temperature, agitation speed, and reaction time) in order to achieve a high yield, and reduce production costs.
The literature contains numerous studies concerning the production of biodiesel using waste cooking oil. However, there are few studies concerning the use of SVM models to model mathematically transesterification process conditions and subsequent optimization using GA. For this reason, the present work examines the effectiveness of using regression techniques that are based on SVM to find and identify the best combination of transesterification process characteristics when waste cooking is used for various biodiesel production optimization scenarios. In this work, process temperature, mixing time, mixing speed, impurities and humidity of waste cooking oil and dosage of catalyst, were considered to be input features. Density, viscosity, turbidity, high heating value, and yield were considered to be outputs features. (
Figure 1).
Based on the dataset obtained from the proposed biodiesel production process, SVM regression techniques were applied with different kernels to model the final biodiesel properties features that were selected. Also, a comparison of ordinary Linear Regression (LR) and the previous nonlinear technique was made to determine the influence on non-linearity. Training of these regression models used the data that were obtained by following the DoE that was proposed and used repeated cross-validation [
32,
33]. Next, the proposed models were tested to determine their degree of generalization. The additional data that were selected at random complete the range of possibilities.
2. Materials and Methods
2.1. Materials
Waste domestic cooking oils were collected from local restaurants to provide raw material for the production of biodiesel by transesterification using NaOH as the catalyst. The synthesis used the following methanol 98% (GR for analysis, Merck, Darmstadt, Germany) and NaOH (GR for analysis, Merck, Darmstadt, Germany) as reagents.
2.2. Design of Experiments and Design Matrix
A DoE is an experimentation method that is structured and systematized and in which all factors vary simultaneously throughout a set of experimental runs. This enables the determination of the relationship between factors that affect dependent responses of the process. DoE [
34] is used to minimize the number of experiments required and to obtain sufficient detail to support a hypothesis. It is generally hypothesized that there are a number of variables that decide the value of responses (outputs) that have a differentiable function. These include independent and controllable variables (inputs or design factors) and uncontrollable variables (noise factors). The method that is proposed for development of the DoE entails constructing a design matrix (factor and levels) and measuring experimentally the responses [
35]. The input features in this study, and the experimentally selected optimization factors that were used were the following: the quantity of the NaOH catalyst (
C), the methanol/oil molar ratio (
M), the temperature of the reaction (
T), the humidity (
H), the stirring speed (
S), time (
t), and impurities (
I). The outputs that were examined were: turbidity (
Turb), yield (
η), viscosity (
µ), density (
ρ), and high heating value (
HHV). On the basis of the features that were selected, the DoE (
Table 1) was undertaken with a Box–Behnken design [
36]. The latter consists of a fractional, three-level design that requires fewer experiments than a full three-level design. The reduction in the number of experiments saves time and expense. In addition, it lessens the difficultly in preparing the initial samples for each experiment.
The DoE that is defined in
Table 1 indicates that a design matrix was generated with 56 experiments and their corresponding factors and levels (
Table 2). The variable levels that appear in
Table 1 address the intervals that commonly appear in the literature in regards to biodiesel production [
37,
38,
39,
40,
41].
2.3. Experimental Procedure
To remove insoluble impurities, the waste cooking oils that were collected were filtered. Then, they were heated to 100 °C to remove moisture. Experiments on a laboratory scale setup were conducted. The oil was heated to the necessary temperature by a water bath. A magnetic hot plate stirrer that had a temperature controller was used. A constant stirring speed was maintained during each experiment. Then, NaOH and methanol were added. When the reaction had reached the predetermined time, heating and stirring were ended. The biodiesel that was produced was transferred into glass containers and later analyzed to determine the ρ, µ, Turb, HHV and η.
The biodiesel yield was determined by Equation (1) [
42].
In addition, the following variables were measured in the final biodiesel product: Turbidity by a 2100Q Turbidimeter (HACH, Loveland, CO, USA) and kinematic viscosity by a Cannon–Fenske viscometers (Cannon Instrument Co., State College, PA, USA
) at 40 °C per the standard American Society of Testing Materials (ASTM) D445 method [
43]. Density was established by a pycnometer following ASTM D941 [
44]. The biodiesel HHV was determined by a PARR 1351 bomb calorimeter following the ASTM D240 standard method [
45].
2.4. Support Vector Machines
SVM is one of the numerous nonlinear regression techniques. Studied intensively, it is applied for its use as a universal approximation [
46,
47,
48]. A kernel-based algorithm is the basis of this method. SVM has sparse solutions. Its predictions for new inputs depend on the kernel function evaluation at a subcategory of occurrences during a training stage. The objective of this method is to find a function to minimize the final error in Equation (2).
where
y(
x) is the predicted value, w is the vector with parameters that define the model, b is the value of the bias and
ϕ(
x) fixes the feature-space transformation. In this method, the error function that appears in the simple linear regression (Equation (3)) is replaced by an
insensitive error function (Equation (4)). The latter assigns a zero to values when
exceeds the difference between the target and the predicted value. If the difference is not less than
, the error function maintains its value. (The foregoing appears to be a contradiction.) In order to minimize Equation (5), a cost (C) is also assigned to the difference between the target and predicted values.
where
y(
x) is the value that Equation (2) predicts,
t is the searched target function, ϵ is the margin where the function does not penalize, and
C is the penalty. The process is optimized, but the initial function (Equation (2)) increases in complexity (Equation (6)).
where α is one solution for the optimization problem that Lagrangian Theory makes possible. The data is transformed by the function to a higher dimensional feature space. This increases the accuracy of the nonlinear problem. Thus, the final function resembles Equation (7).
This case uses functions of three kernels. They are linear (Equation (8)), polynomial (Equation (9)) and Gaussian Radial Basis Function (RBF) (Equation (10)).
To program the methodology that was proposed, generate the design matrix and develop the regression models, R statistical software was selected [
20].
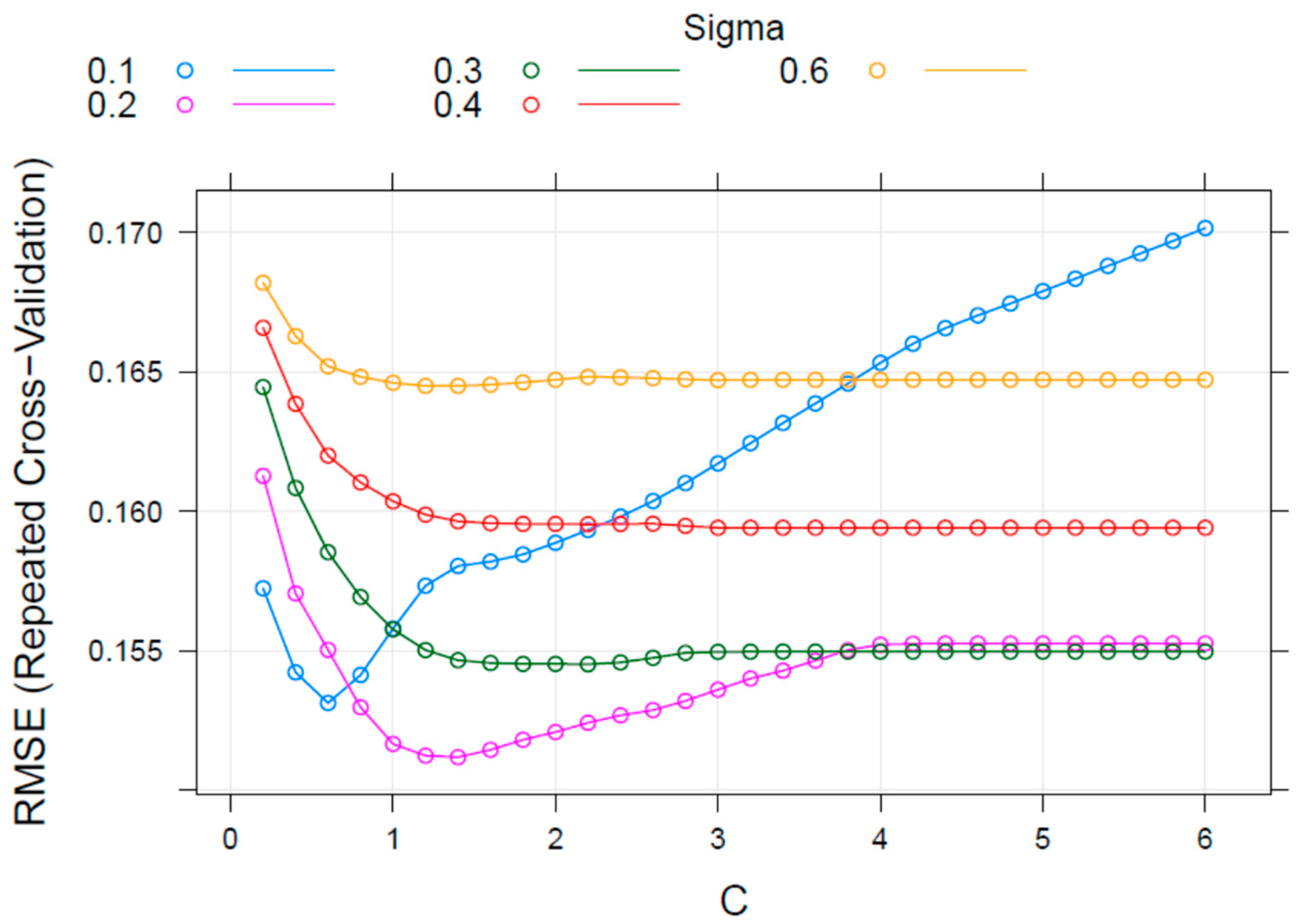
To undertake this part of the method, the SVM models were trained by using 50 times repeated 10fold cross-validation. Their calculation times were not long. This made possible the use of the entire training dataset that came from the DoE, and was formed by 56 entries to create the models. However, it was necessary to first divide the initial database into 10 subsets, using nine subsets to build the model and using the tenth subset to calculate the error. Other errors were obtained when the procedure was repeated an additional 50 times. Finally, the arithmetic mean of all errors of the process was calculated. In addition, the various algorithms were trained, significant parameters for each algorithm were tuned, and their values that produced the best predictive performance were identified. The accuracy of the predictions were judged by means of the Root Mean Square Error (RMSE) and the correlation of real and predicted values.
Finally, after the most accurate models were built, selected and trained, they were tested in the laboratory in nine experiments and with new samples, to determine their real degree of generalization.
3. Genetic Algorithms for Optimization of Biodiesel Production Features
Regression models that had the best generalization capacity were selected to identify the best combinations of transesterification attributes that would yield desirable biodiesel production properties. The intention was to study and optimize nine different scenarios in biodiesel production from waste cooking oil. These were: maximizing
η, minimizing
Turb, minimizing
ρ and
µ, maximizing the
HHV, minimizing
C, minimizing
S, minimizing t and minimizing M. The search for the best combination used GA-based evolutionary optimization techniques. Using these techniques for the optimization of industrial processes and devices [
49,
50,
51,
52,
53,
54] has been proven previously in the literature. GA conducts optimization with a population of several individuals in a way that resembles the behavior of biological process. The resulting solution approximates in general the global minimum of all possibilities [
55]. The optimization using GA involves the six following steps, (see
Figure 2), [
56,
57].
- (1)
Coding/decoding: The information from feature values for each individual is changed to binary codes that join to form chromosomes, and vice versa. Values that are out of the range proposed by DoE is replaced.
- (2)
Population initialization: The initial population is generated by a random set of individuals.
- (3)
Evaluation: The responses of models are evaluated by a fitness function to determinate the individuals that will be part of the next generation.
- (4)
Selection: Sorting of individuals uses the criterion that the fitness function provides. The top 25% of individuals are selected for the next generation.
- (5)
Crossover: Portions of two parents of the current generation have been combined to form a new offspring. These portions have been selected on the basis of two positions and two longitudes. The majority (60%) of the new population consists of new offspring who were created by crossovers from selected parents and h the crossovers consisting of a change in a random number of bits of chromosomes of, alternatively, two randomly selected best individuals.
- (6)
Mutation: Several individuals were selected from the 25% who had been chosen and the 60% who had been, were created by crossovers. This was done on the basis of a uniform probability and a random element of the chromosome that was flipped to create a new individual. Mutation is responsible for 15% of the new population.
The optimization process that provides in each scenario the best combination of transesterification attributes was the following: First, 1000 individuals transesterification parameters (
M,
C,
T,
S,
t,
H,
I) or combinations thereof were randomly generated corresponding to the range that appears in
Table 1. These first individuals or combinations formed the initial generation, generation 0. Based on these individuals, the variables that define biodiesel properties were predicted by the regression models that had the best generalization capacity in each case (SVM or LR models). Based on this prediction, an error obtained from a defined fitness function (
J1) permitted the selection of the individuals for the subsequent generations. In this case, the fitness function that was developed considered the maximization or minimization of the studied features, and the weights of the different proposed scenarios (Equation (11)).
where
are the weights that are applied to each component in the fitness function
J1, and
defines the objective sought for each of the features.
These weights
were so defined that the above-mentioned optimization scenarios would be achieved.
Table 3 shows the weights
of each variable that are part of the fitness function
J1 to optimize the biodiesel production process for the nine different optimization scenarios.
After selecting 25% of the best individuals (i.e., 250) according to the fitness function (
J1) and the optimization scenarios that were selected, the crossover process was undertaken. It was first necessary for two selected parents to provide two complete chromosomes. Each chromosome was then coded in binary code. Then, a random number of crossings (1, 2, 3, or 4) was selected. Also, a number was randomly selected for each crossing to define for each crossing the initial bit’s position. The longitude of the number of bits in the chromosome’s crossing part was selected similarly. This information was used in selecting some of the first parent’s bits. The second parent donated the remaining bits to create a new chromosome and generation. Positions 1 and 2 appear in
Figure 2.
Figure 2 also shows the lengths (longitude 1) and (longitude 2) that were used to cross two individuals from generation “0”. Positions 1 and 2 were equal to “10” and “47” respectively. Longitudes 1 and 2 were equal to “9” and “10” respectively. (Values of all positions and longitudes are in bits). Finally, the binary code of new chromosomes was decoded in order to generate new individuals. The latter were formed by parameters that required adjustment to complete 60% of the new population (i.e., generation 1), namely 600 individuals. The remaining individuals (i.e., 15% or 150 individuals) were generated randomly to complete the new generation (i.e., generation 0).
5. Conclusions
An alternative and useful combustible biodiesel can be derived from vegetable and waste oils. It is compatible with diesel engines as a substitute fuel or when blended with diesel. Thus, the knowledge of the process to produce biodiesel from waste cooking oil by transesterification using NaOH as the catalyst is highly significant. This paper presents a group of regression models based on SVM techniques to predict several biodiesel properties or (viscosity, density, turbidity, HHV and yield) from attributes of the transesterification process (dosage of catalyst, molar ratio, humidity and impurities, mixing speed, temperature, mixing time). Firstly, the experimental data was obtained according to a Box–Behnken DoE to study the effects of the process features on the production of biodiesel. Subsequently, several regression models were constructed using this experimental dataset. This was done to predict the biodiesel properties that were being studied and to obtain greater understanding of the process. The biodiesel property that was best predicted was turbidity (Turb), which presented an RMSE test of 10.43%, whereas the property that presented the greatest error was density (ρ) whose RMSE was 44.91%. The SVM models with Polynomial kernel and with RBF kernel were the regression models that were selected to model the stated biodiesel properties. Finally, evolutionary optimization techniques that are based on GA were used to search for optimum values in nine prefixed scenarios. This optimization showed how to control the transesterification process to manufacture biodiesel that has specific properties. From the results, it is noted that some of the attributes of the transesterification process show a more greatly reduced range than for any of the nine scenarios studied. Thus, for example, the range of values obtained for molar ratio was 6.0 to 8.4; for dosage of catalyst it was 1.00 to 1.38 wt %; and for time it was 20.00 to 26.94 min. In contrast, some of the attributes had a fairly wide range of values that almost encompass the range proposed in the initial DoE. For example, the range of values obtained for the mixing speed was from 500.00 to 999.99 rpm; for the temperature it was 28.75 to 37.5 °C; for the humidity it was 0 to 2.31 wt %; and for impurities it was 0 to 2.99 wt %. Also, the entire process was validated. The final error of 4.14% showed that the methodology was accurate and that the predicted values were very similar to the experimental data.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}