1. Introduction
The emergence of smart grids has resulted in new business models and applications, featuring short-term forecasts of electricity demand at a local scale ranging from households to feeders. These kinds of forecasts are requested by different actors and applications: i.e., by Home Energy Management Systems to manage smart homes, and by aggregators or retailers to optimize the supply cost for a group of consumers in their portfolio. Aggregators can also offer flexibility to network operators based on their pool of individual clients. Efficiently predicting household demand is important for these actors to optimize the cost of supplying their customers and to anticipate energy purchases. Retailers can offer electricity flexibility to network operators based on their pool of individual clients. Businesses usually rely on the day-ahead electricity market—such as the EPEX or Nord Pool spots. For this reason, the focus in this paper is hourly day-ahead forecasts of household electricity demand. The development of such forecasting models has been feasible in recent years thanks to the availability of data from smart meters. In Europe, the European Parliament has enacted the roll-out of smart meters, with a landmark of 80% deployment by 2020 in most countries [
1]. Individual smart meters record the electricity consumption of a household during a fixed period, e.g., one hour. Collecting such data is seen as a key factor to reach the EU energy policy goals, because it enables precise evaluation of action plans [
2] and empowers consumers with detailed feedback about their electricity consumption [
3].
Although a wealth of literature exists on load forecasting at regional and national scales, few studies examine load forecasting at customer level. Forecasting household demand is not straightforward. Different households have very different electricity usage profiles depending on the number of inhabitants, their lifestyle, the floor area, and other factors. Moreover, consumption in each household varies considerably from one day to the next due to house occupancy and activities, weather conditions etc.
The literature on load forecasting at local scale has grown in the last few years. The models proposed look for the most informative inputs—such as quantifying the temperature influence [
4] and identifying the relevant household characteristics [
5]—to make use of mature statistical methods—such as kernel density estimator [
6] and copulae [
7]; machine-learning techniques—such as neural networks [
8] and support vector machines [
9]; and original hybrid methods—such as household activity pattern modelling coupled with standard forecasting techniques [
10]. A recent review of forecasting methods at the smart-meter level is proposed by Yildiz et al. [
11]. This anticipation of the future electricity demand of a household is then required by other applications, such as to optimize the operation of a microgrid [
12,
13], or to manage smart homes through an aggregator [
14]. The required forecasting horizons range from a few hours to few days ahead depending on the application. Hereafter, we consider a day-ahead horizon which is typical for applications related to electricity markets.
In most of the literature, the forecasting quality is assessed in an offline context, i.e., the forecasters work with a fixed dataset over which they have total control. In particular, the data selection is often non-detailed and follows the forecaster’s own rules, such as household choice, removal of absurd values etc. While this kind of selection is necessary to highlight the interest of the forecasting models, it does not necessarily reflect the real-life situations. In the real world, the availability of smart-meter data collection is far from perfect due to faulty meters and communication issues. Some studies [
15] present efficient methods to fill in the incomplete data at the aggregated level, whereby a central agent gathers and manages the data. However, in the absence of a central agent, i.e., in a distributed context, other standalone strategies need to be employed.
The European project SENSIBLE demonstrates the use of energy storage for buildings and communities. It requires the deployment, for each household, of a day-ahead electricity demand forecasting model [
16]. Since the performance of demand forecasting is known to be quite poor at the household level—state-of-the-art errors range from 5% to 60% [
11]—a probabilistic output is employed to quantify the uncertainty, following a current trend in the forecasting literature [
17]. In the frame of SENSIBLE, an operational load forecasting platform was set up to predict the consumption of each household at the demonstration site of the city of Évora in Portugal. The platform retrieves information from the smart meters at each household through appropriate application programming interfaces (APIs). The outputs of the forecasting models are then transmitted to other applications to be used as inputs, such as Home Energy Management Systems [
18]. Hereafter, we focus on the day-ahead horizon. Specifically, our model should provide the probabilistic forecasts at 12:00 on day
of the future demand expected on day
D at 0:00, 1:00, ⋯, and 23:00, i.e., for horizons of 12, 13, ⋯, and 35 h. In such a use case, several features are required for the forecasting model to be implemented:
High robustness: demand forecasts are required at all times in all situations, e.g., new house, faulty meter, etc., with reasonable performance.
Fast computation: the model should carry out demand forecasts in a reasonable time for a potentially large number of households than can range from hundreds to thousands.
Easy replicability: the model should be easily replicable for many household typologies and demand profiles.
Remote control: no direct intervention is possible in situ.
Easy interpretation: finally, among two competitive models with equivalent performance, some end-users may have preference for a model that is understandable by anyone, instead of a black-box approach.
To address these requirements, in
Section 2, we introduce 5 forecasting models—and a reference model based on machine learning—at the household level. These are combined in a hierarchical framework so that they can always provide a forecast output. In
Section 3, we (1) analyze the respective performance of each model with an offline dataset and (2) identify the possible situations preventing the usage of a specific forecasting model to (3) propose a hierarchical framework to design a foolproof forecasting model. After deployment in 2018 at the demonstration site, the field experience is used to evaluate the performance of the forecasting hierarchical framework. A comparison between this online performance and the offline performance is drawn and discussed in
Section 4.
The key contributions of this paper lie in the proposal of a probabilistic approach for forecasting household electricity consumption. Given the operational requirement for high availability in the forecasts, a robust approach is proposed based on the operation of alternative models of varying complexity combined through a hierarchical approach. In contrast to most academic approaches in the literature, here we compare the simulation results under ideal conditions (i.e., in terms of input data availability) with field tests featuring erroneous or missing data. This provides a realistic view of the level of load predictability at local scale.
3. Hierarchical Forecasting Framework
We first select a subset of 20 households with high-quality smart-meter data to assess the performance of each forecasting model. Then, we identify the problematic situations occurring in practice, before finally designing a hierarchical forecasting framework combining the models based on their respective performance and robustness to problematic situations.
3.1. Offline Forecasting Performance of a Subset of Households
For each household, we have 6 alternative day-ahead forecasting models, , , , , , and .
Based on their respective level of complexity and the forecasting literature, we expect similar performance from and , and that both will outperform , then , then , and then . We wish to assess their respective performance during the test period going from 1 October to 31 December 2015. To perform this evaluation, we select a subset of households based on two criteria:
A subset of only 20 out of the 226 households fulfill the two criteria, later denoted subset . In fact, most of the 226 households exhibit abrupt changes in their demand patterns that are quite difficult to anticipate, and that do not reflect the intrinsic performance of the forecasting model.
For the 20 households in the subset
, we compute the Reliability and the Normalized Quantile Score, see
Section 2.4, for the 6 models introduced. The average results are shown in
Figure 1, and in
Table 1.
When examining the reliability ratio, we observe that the specific models are reasonably calibrated but that the average models are not. The whole forecast distribution of the latter either overestimates or underestimates the demand. Consequently, providing point forecasts of the demand of an unknown household is reasonably efficient—NMAE around 31.1%—but providing average probabilistic forecasts makes no sense and requires specific measurements of the corresponding household.
The quantile score curves, visible on the right panel in
Figure 1, depict the performance at different quantile levels, i.e., for different parts of the forecast distribution. The values of the NMAE scores are readable at quantile level 50% and indicate which forecasting model is better to provide point forecasts.
We see that the performance of each model is ordered as expected, with a top performance of 27.2% for
. The hypothesis that all 5 models have similar performance is rejected according to the Friedman statistical test (
p-value of
) [
32]. Additionally, we note that the most efficient proposed model M
has similar performance to the reference model
: the nonparametric Wilcoxon test does not reject the null hypothesis claiming similar performance (
p-value of 0.54) [
33]. On average, the models specifically trained for households decrease the errors by around 10% in comparison with the average models. This relative improvement is intensified when considering the distribution tails. The curves crossings between the models suggest that forecasters should use the additive model for lower quantile levels (10–60%) and then switch to the specific climatology model for higher levels. This observation highlights that it is, perhaps surprisingly, more efficient to carry out conservative forecasts for the upper part of the forecast distribution. However, this conclusion should be adapted depending on the household considered. For instance, for about one third of the households, the models with a temperature input, i.e., M
and M
, clearly outperform the climatology M
at all levels. Identifying these households that benefit from the temperature input is quite straightforward: they are equipped with heating or cooling electrical devices, i.e., they have clear thermal sensitivity [
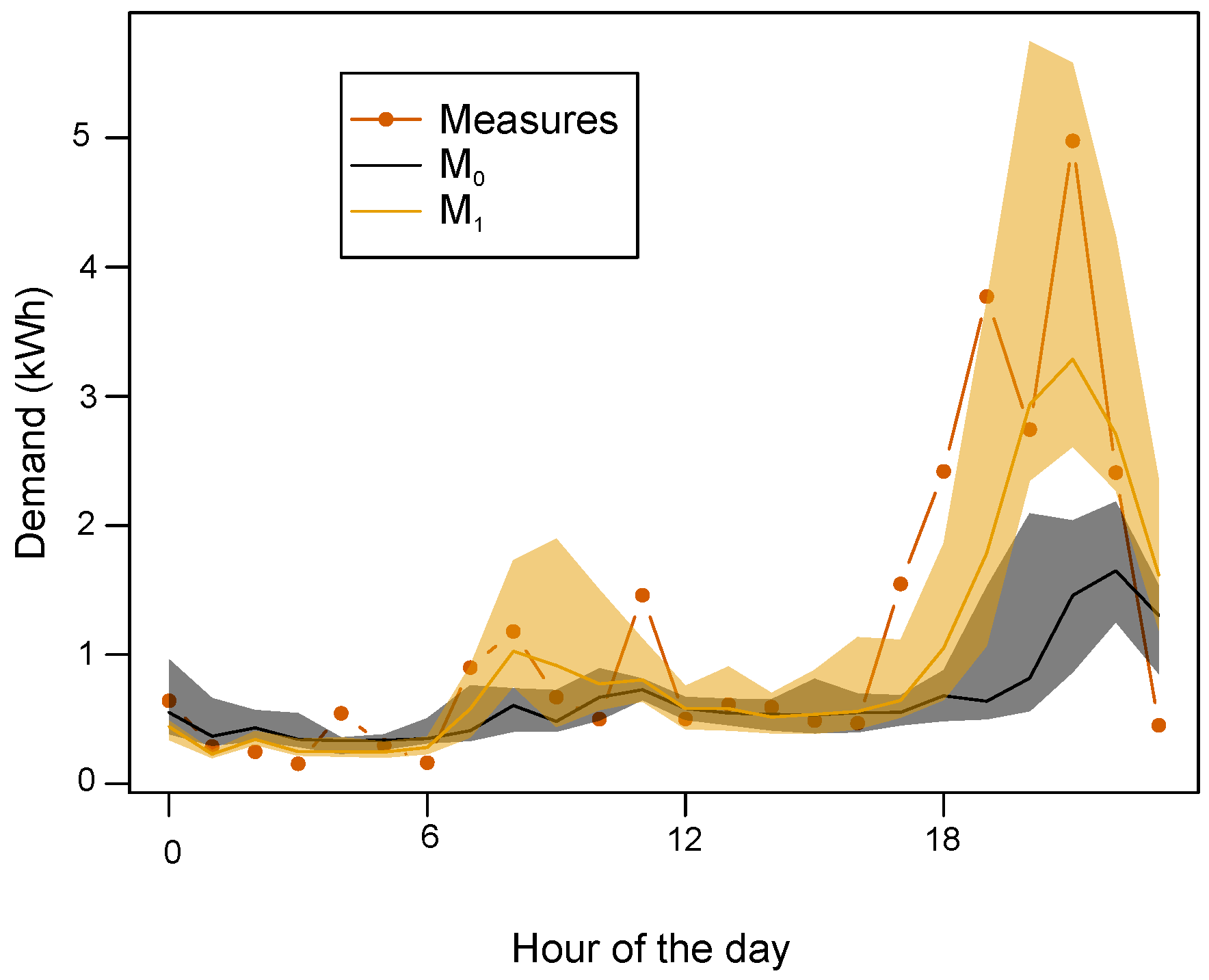
34]. This sensitivity is measured by retrieving the correlation between the electricity demand and the outside temperature. Thermal sensitivity is defined as the squared correlation and so a high (resp. low) sensitivity depicts a strong (resp. weak) demand–temperature correlation. The households with high sensitivity show a clear increase in electricity demand when it is cold outside. In these cases, the forecasts are more accurate as illustrated in
Figure 2, where the evening demand is well anticipated by the temperature-dependent model M
(orange) since it is a cold day, but not by the climatology model M
(black).
3.2. Problematic Situations
Although the additive model provides the best performance, it is also the least robust model and several problematic situations occasionally prevent its usage. This is often the case for similar type of models based on time-series approach. The following situations are identified to be problematic when forecasting the demand of household :
No data in the training period. There is no way to create the specific models , , and .
No temperature forecast. Models making use of the temperature , , and are missing an input and cannot properly carry out a forecast.
No recent measurements. Input values or are then unavailable, meaning that cannot operate.
Unknown situation. A drawback of the smoothing splines is that extrapolation is known to perform poorly, affecting the activation of A, M, and M. For instance, if recently observed demand values have never been this low in the training set, it is better to refrain from using the additive model .
3.3. Hierarchical Framework
3.3.1. Flowchart
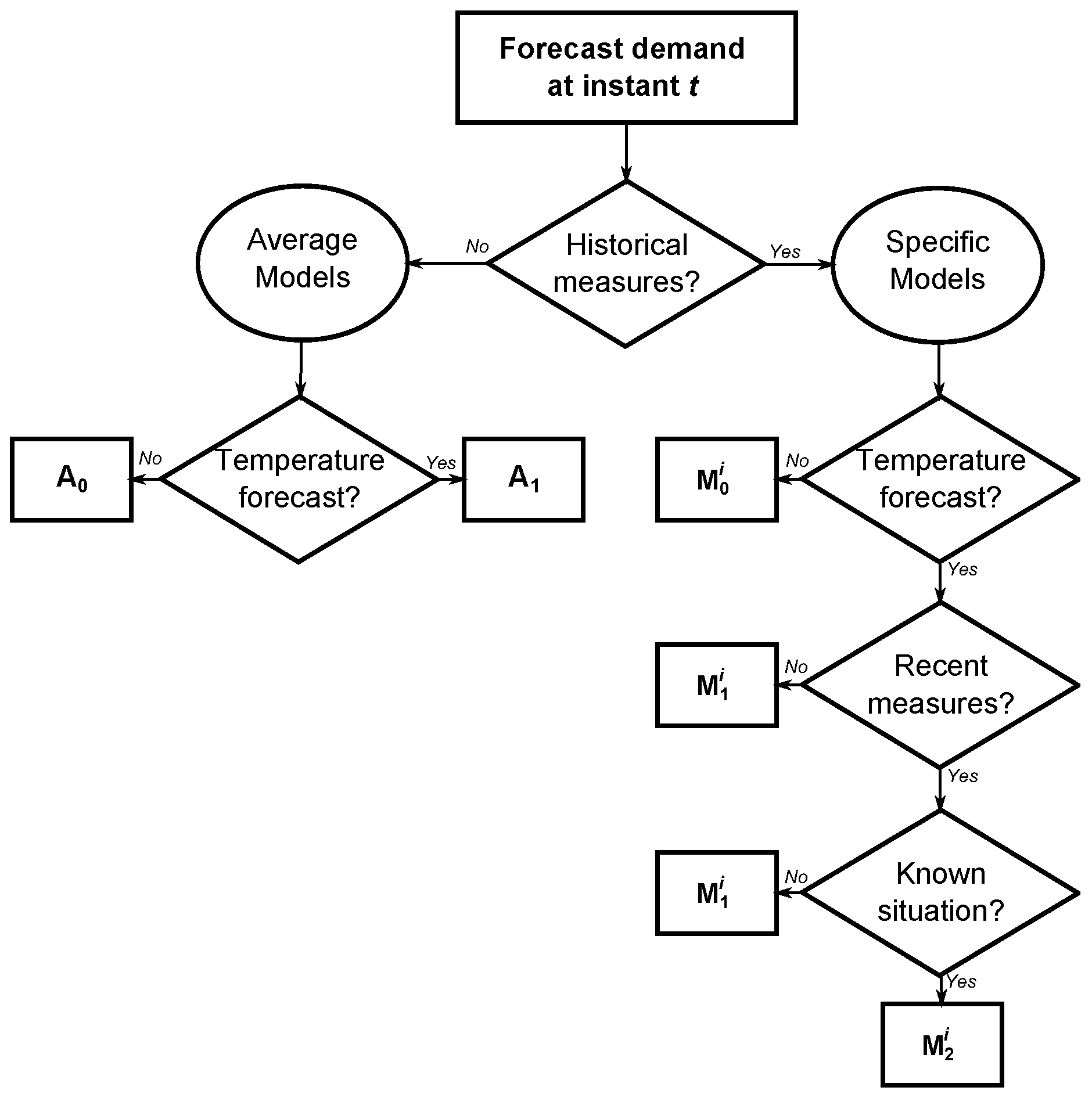
The respective performance of each model coupled with the identification of problematic situations enable us to design a forecast hierarchical framework represented in
Figure 3. In the implementation, when producing a forecast for instant
t for a household
i, we successively check:
Are there historical measures specific to this household?
Is there a temperature forecast available?
Are the recent measures and available?
Is the future situation known, i.e., do the inputs values extrapolate from the ones that occurred during the training period?
3.3.2. Performance
We implement the hierarchical framework for each of the 226 households in the neighborhood. The flowchart detailing the model usage according to the situation allows us to always provide day-ahead probabilistic forecasts for each hour of the day in the test period—from 1 October to 31 December 2015. We assess the performance by comparing these forecasts to the available data. Since some households have missing demand measurements, the length of the test period is not the same for all the households. For instance, one household has no measurement at all in December and so the performance is estimated with a test subperiod going from 1st October to 30 November.
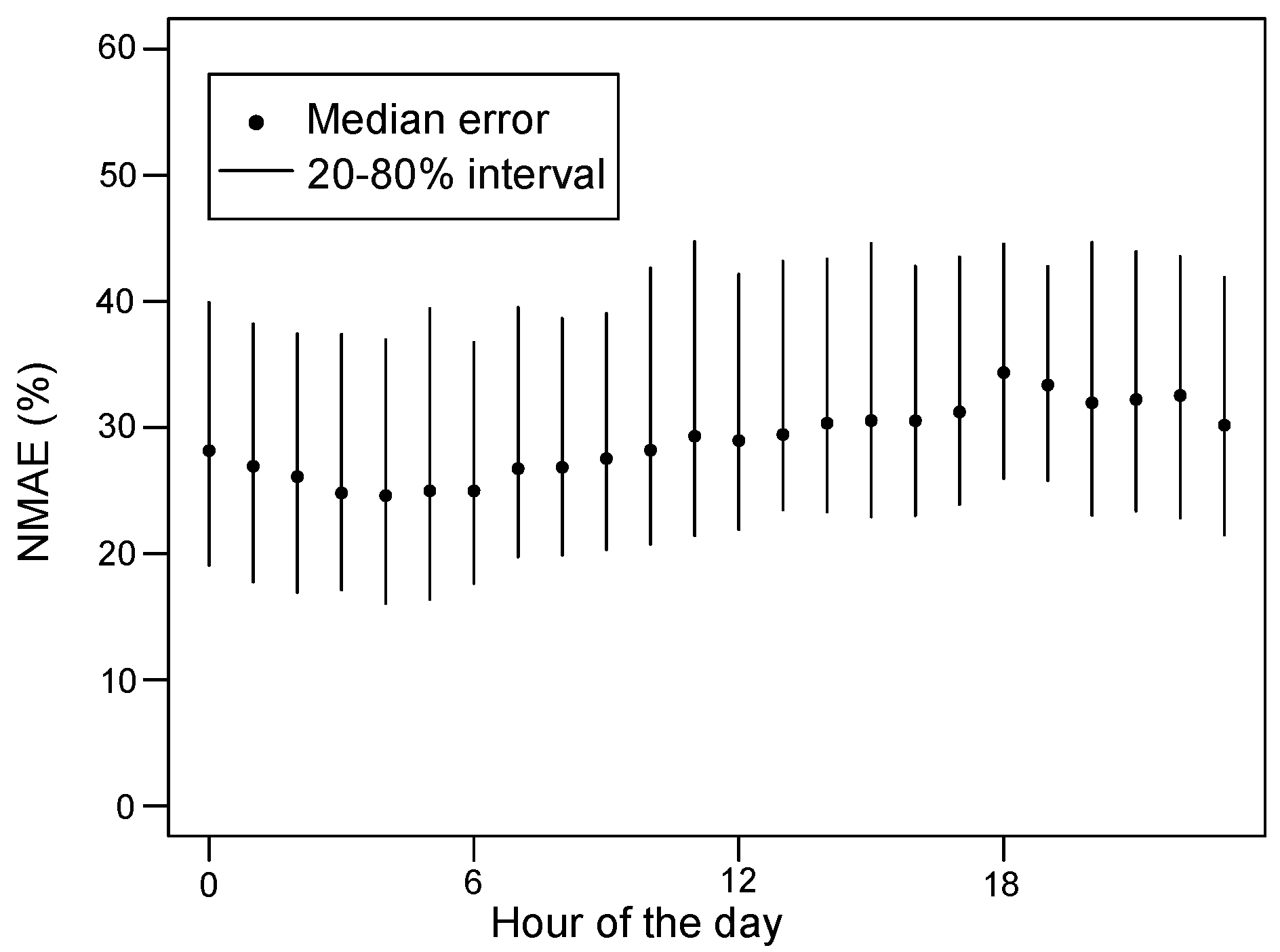
Figure 4 depicts the NMAE observed for each hour of the day among all the 226 households. The points show the median NMAE, and the segments show the variation 20–80% among households. The errors follow the same trend as the actual demand values: lower in the nighttime, and higher in the evening. However, the fluctuation throughout the day is minor. Since all the forecasts are carried out at 12:00 on the previous day, forecasts for a specific hour of the day represents a specific horizon. It means that errors at 0:00 correspond to a forecasting horizon of 12 hours, errors at 1:00 correspond to a forecasting horizon of 13 h, and so on.
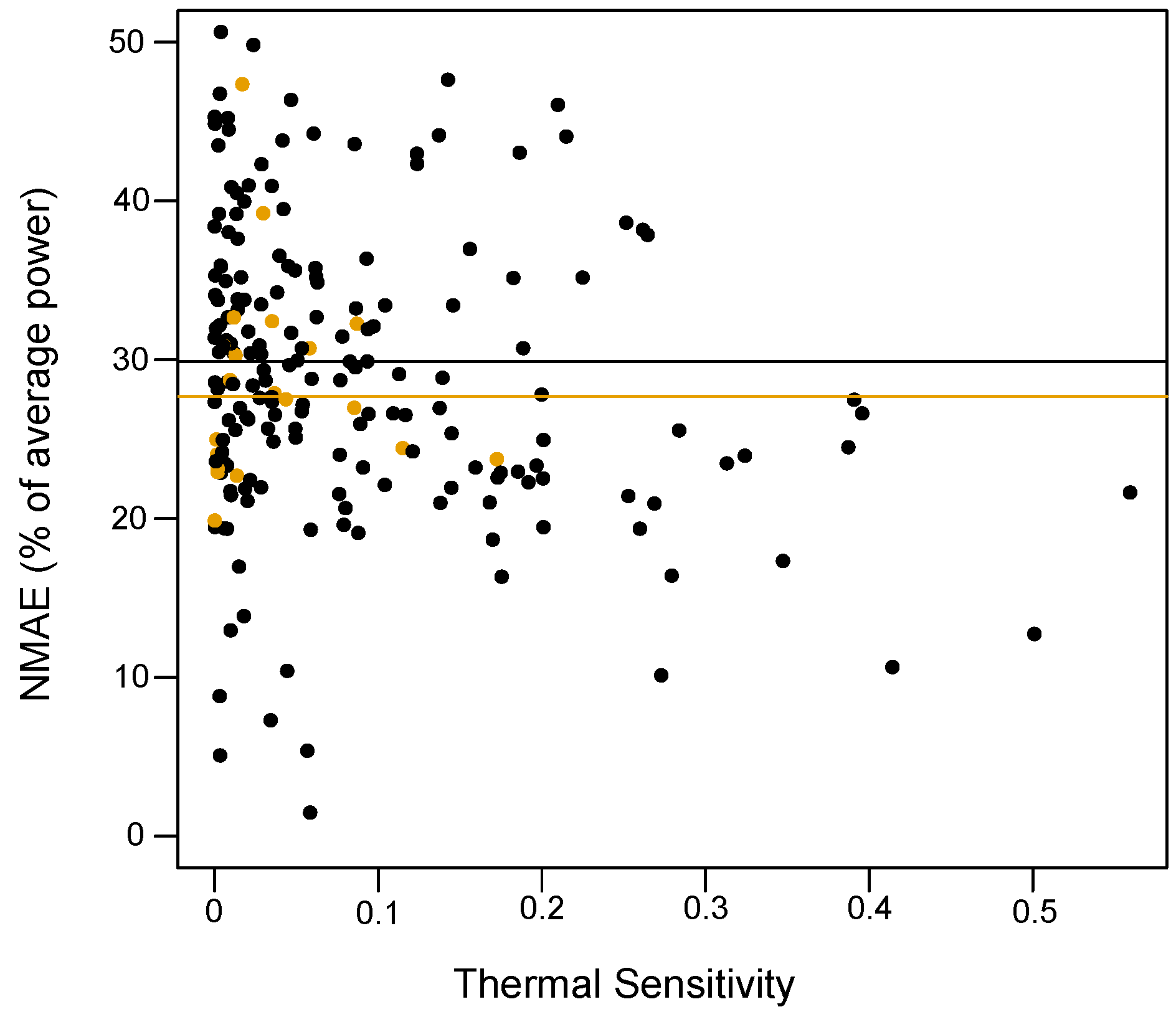
We then represent the NMAE, averaged over the 24 h, as a function of the thermal sensitivity in
Figure 5.
The households in the subset are represented by the orange dots, and the rest by black dots. We can see that the model performs slightly better on the subset : the median NMAE decreases from 29.9% to 27.7%. The graph also logically shows that households with greater thermal sensitivity are easier to forecast. Additionally, we can see that performances greatly vary between households with similar sensitivity: errors range from 2% to 51% for low sensitivity (below 0.1). This is due to the unknown behaviors of the householders and other cultural factors, e.g., the number of appliances in the house. It highlights that anticipating a forecasting performance for a different use case should be done with caution.
4. Offline and Online Performances
We first draw a household-by-household comparison of the offline and online forecasting performances. Then, we discuss and quantify in detail the factors that cause a noticeable performance degradation with precise test cases.
4.1. Performance Comparison
The hierarchical forecasting framework is implemented at the Évora demonstration site. The forecasts produced and smart-meter measurements are retrieved, providing a recent online dataset. This dataset is made up of two parts: a training period going from July to December 2017, and a test period from April to August 2018.
We first analyze the frequency with which each one of the 5 models that compose the framework, depicted in the flowchart in
Figure 3, are activated as a function of the available data. The results are given in
Table 2. It is noted that, at each instant, a single model produces the final forecast, according to the situation. The most efficient model M
is activated in about three quarters of the cases. We observe similar model activation frequencies in the online and offline cases.
The online data is collected from the 20 households of the
subset introduced in
Section 3.1.
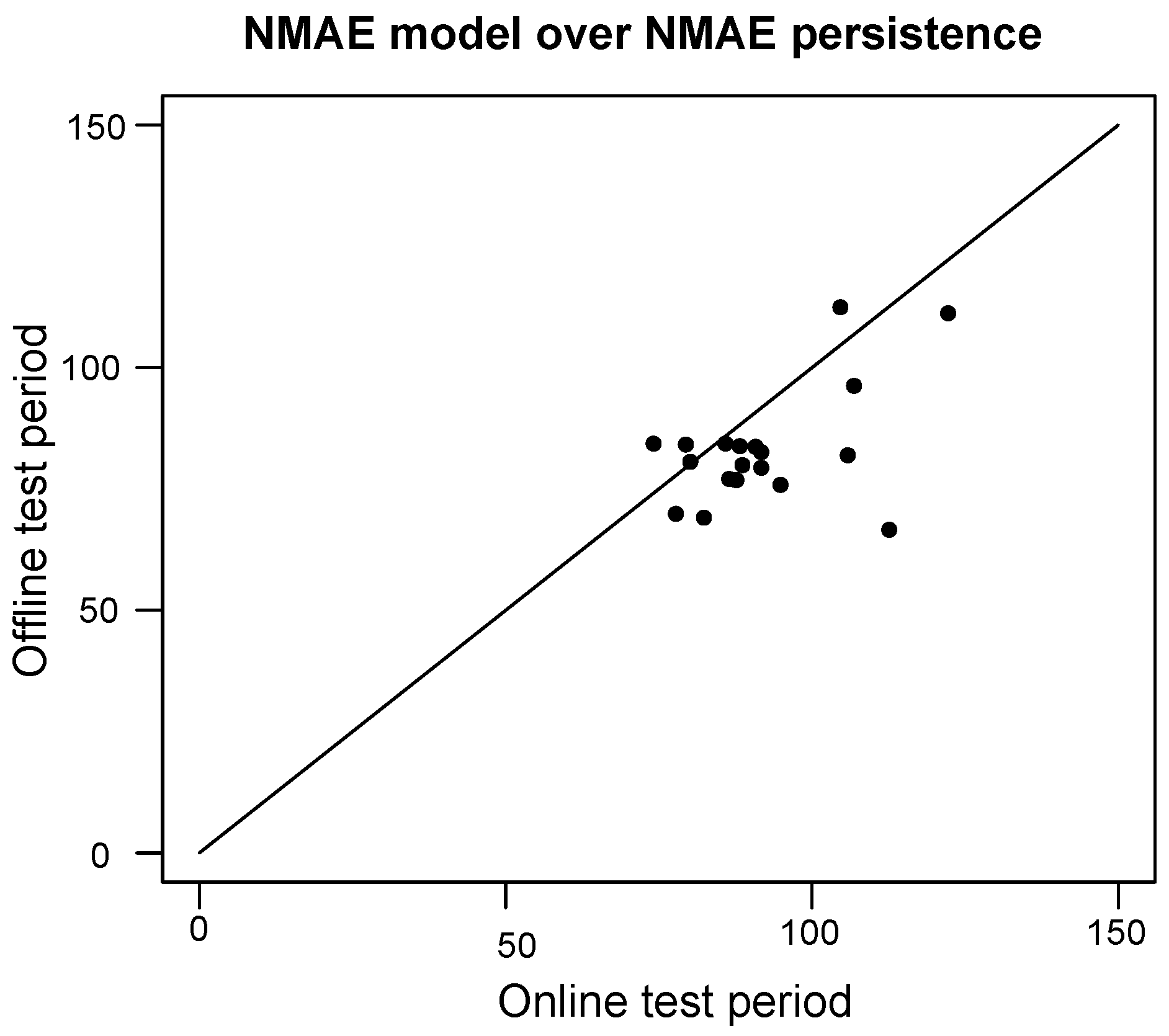
Figure 6 compares the performance of these 20 households obtained during online test period—1 April to 31 August 2018—and during the offline test period—1 October to 31 December 2015. We compare the NMAE obtained during the two periods. with our forecasting framework and divide this error by the NMAE obtained with a 1-day persistence model. Note that the normalization in the NMAE score comes from the mean value observed from the sets studied, and so the normalization value evolves between the offline and online test sets. For most households, the errors made by our model is lower than the persistence errors (average of 0.90 offline and 0.97 online). Furthermore, for 17 out of 20 households, the individual NMAE obtained offline is lower than online, meaning that the model performance has decreased between the two test cases. We also provide in
Figure 7 the NMAE computed over a single day. Each point, in black for the offline case and in orange for the online test, represents the ratio between the NMAE of our forecasting framework and the NMAE of the persistence model (
y-axis). The daily demand of the day (in kWh) is represented on the
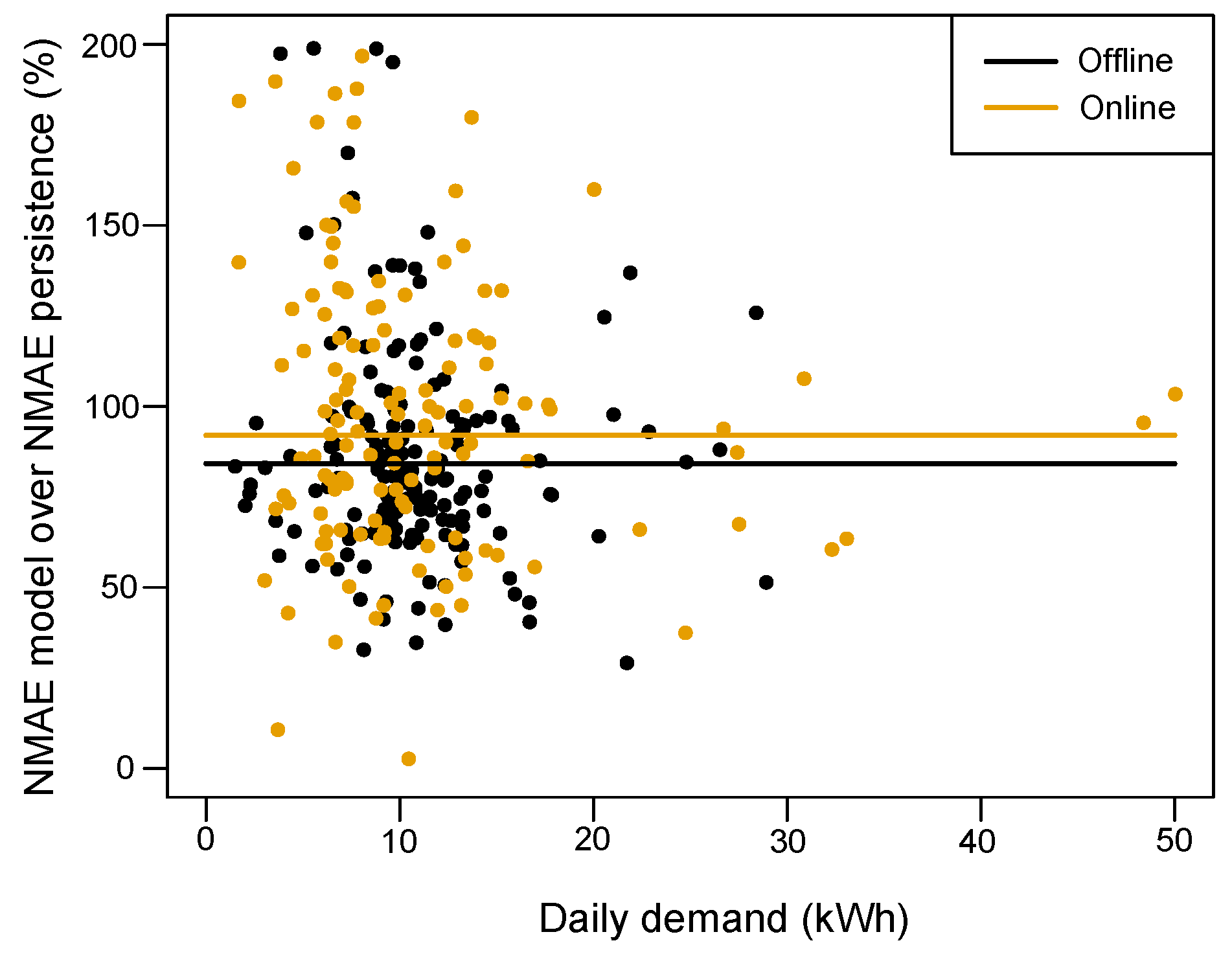
x-axis. We see that the daily performance is more volatile when the demand of the day is low than when this demand is important. In fact, this performance volatility is due to the persistence forecasts performance that also widely range for low-demand day: performance is either very good (when the previous day is also a low-demand day) or very poor (when the previous day is not a low-demand day). The improvement over persistence is clearer for high-demand days in online and offline cases.
On average, the online performance is worse than the offline performance. In absolute values, the average NMAE goes from 34.8% on the offline test to 58.5% on the online test. This comes from the demand characteristics that are quite different between two cases.
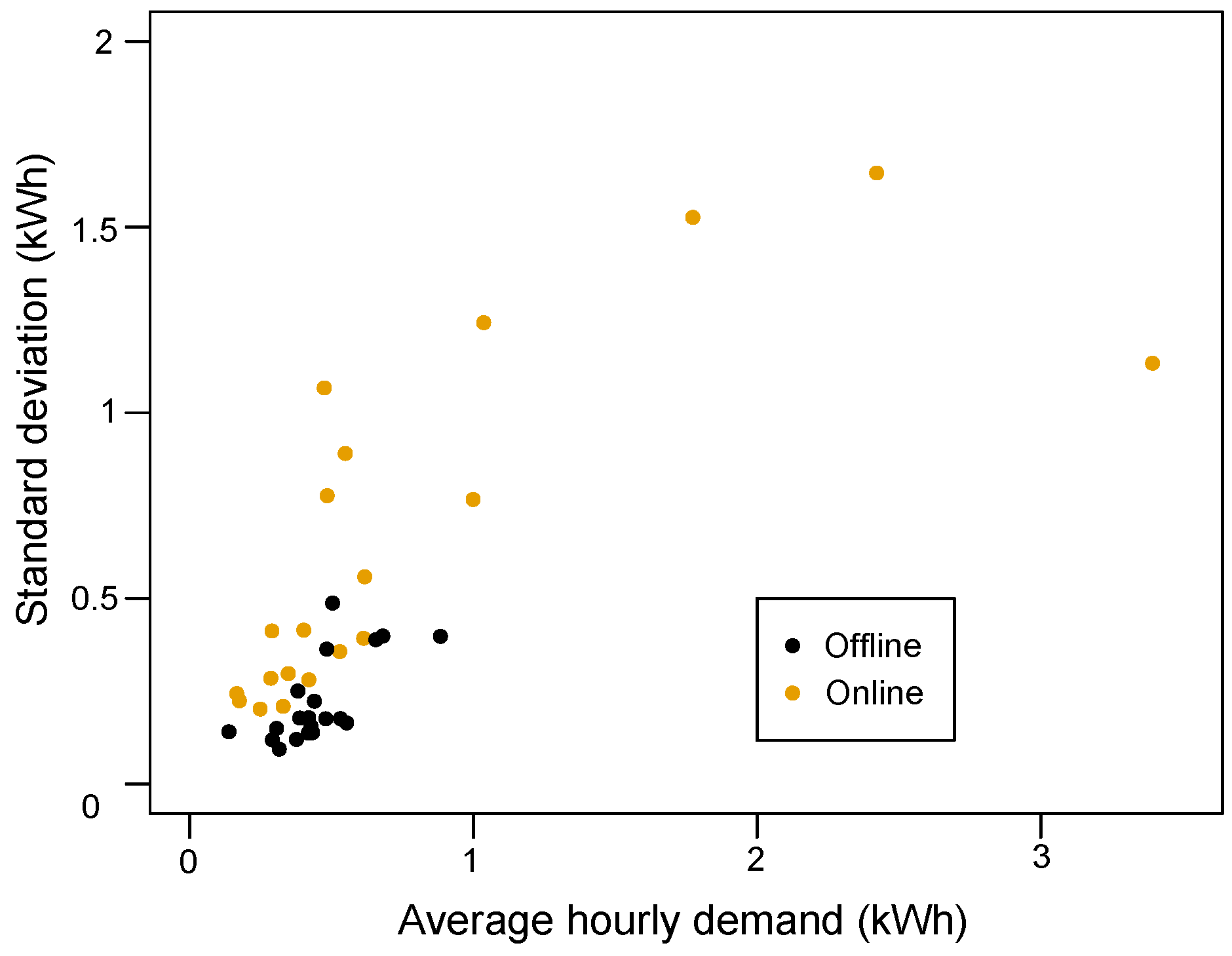
Figure 8 provides an indicative illustration. For the same set of households in the two cases, one point represents the average hourly electricity demand of the household (
x-axis) and its standard deviation (
y-axis). Both the mean and deviation largely increase between the two cases. This evolution directly influences the forecasting performance since it denotes the usage of more appliances, hence more demand volatility and forecasting complexity.
4.2. Discussion
We investigate the possible reasons for the performance degradation between the offline and online tests: the evolution of the demand time series, the availability rate in the test period, the duration and recency of the training period, the position during the year of the test period. The subsequent tests are made using our offline 2015 dataset with the subset of 20 households to quantify the possible performance degradation.
4.2.1. Evolution of the Demand
Since there is a considerable time gap between the offline test, in 2015, and the online test, in 2018, the behaviors of the householders living in the 20 households have evolved: new people, new appliances, new habits, etc. This evolution is reflected in the electricity demand patterns which modify the intrinsic complexity of the forecasting task. Defining this complexity is not straightforward: we examine the performance of a 1-day persistence model—by which we use the demand measured on the current day to provide point forecasts for the next day. We observe that this persistence model has an average NMAE of 45% from April to August 2015, and this error increases to 69% from April to August 2018. This means that forecasting the 2018 time series is roughly 50% more difficult than forecasting the 2015 time series.
4.2.2. Availability Rate in the Test Period
For each one of the 20 households in the
subset, we randomly discard a certain amount of available measurements in the test set, obtaining an availability rate between 0 and 1. This mimics the case when a specific hourly observation is missing, and so the forecast cannot be compared to the actual observation. We compute the forecasting performance of M
with the NMAE and
indices on the available subperiod. In
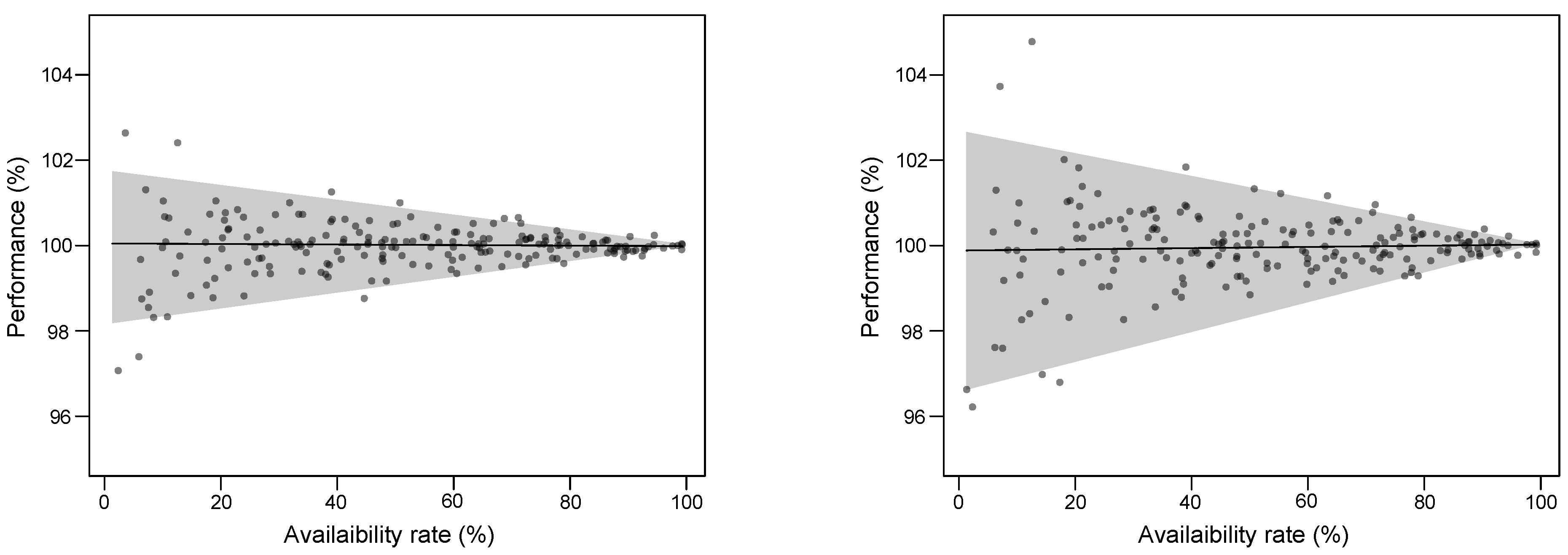
Figure 9, we represent the performance fluctuation (in %) regarding the availability rate. Logically, we see that the average performance is constant, i.e., at a reference level of 100%, whatever the availability rate. However, note that the missing values introduce variability in the performance evaluation. This variability logically increases when the availability rate decreases. It goes up to 2% when examining the NMAE. This effect is emphasized for the distribution tails, as seen on the
going up to 4 % for low rates, that are more difficult to estimate accurately.
We conclude that missing values in a test set induces limited performance fluctuation. However, the missing values here are assumed to be uniformly spread throughout the period, which is the case in the actual online dataset retrieved. Another use case may result in different missing value distribution, e.g., when a smart meter is disconnected during a contiguous period of time.
4.2.3. Training Period Position
For each of the 20 households in the
subset, we train the forecasting models M
and G
at quantile level 50% with different training periods.
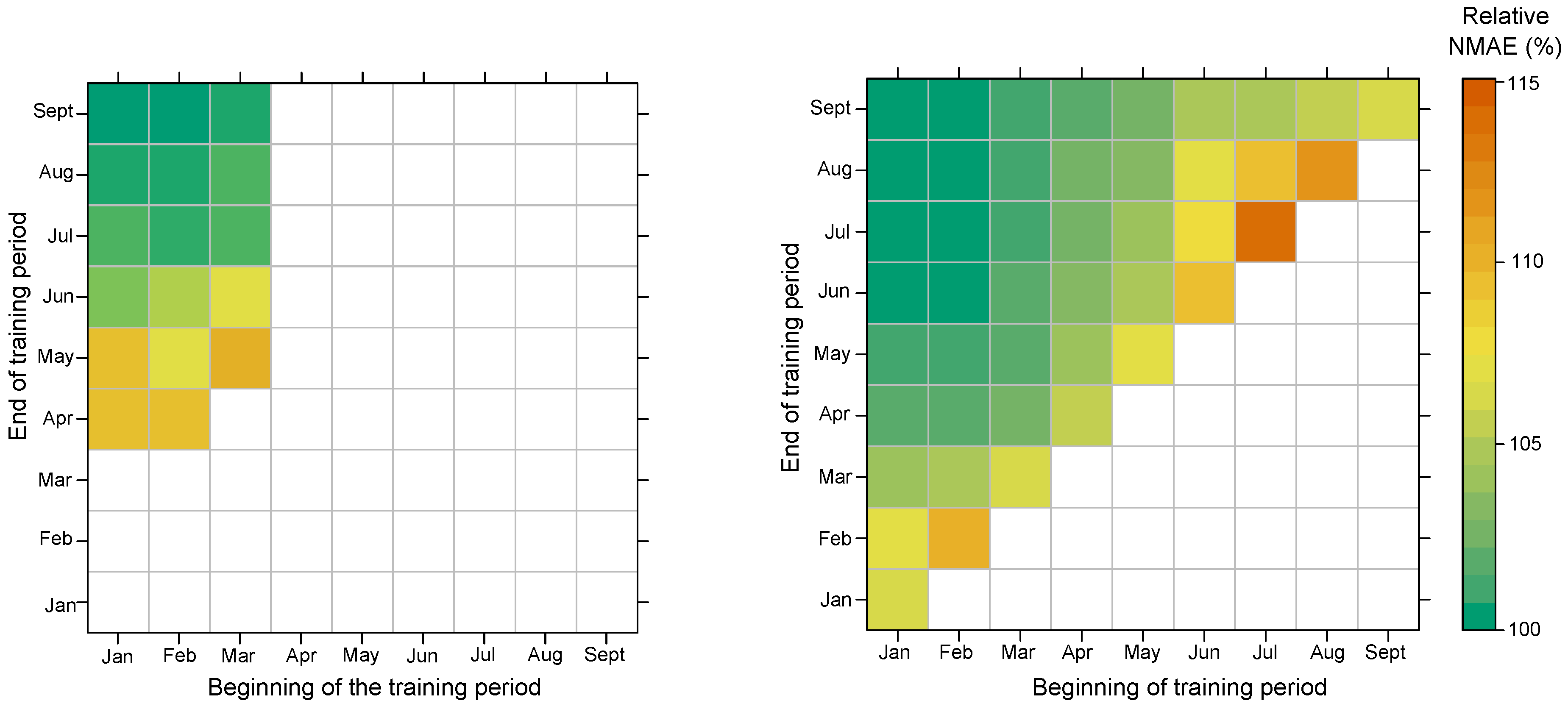
Figure 10 represents the average NMAE achieved on the test period, fixed from 1 October to 31 December 2015, relatively to the minimal NMAE obtained with the longest training period going from January to September. The beginning of the training period is selected on the
x-axis, and the end is selected on the
y-axis. The left panel represents the performance with the M
model while the right panel represents the performance with the G
. Since the additive model M
is not designed for extrapolation, the training period necessarily should include the first months of the year, to observe similar temperature as during the test period, to produce forecasts. It means that only a limited range of training periods could be evaluated. On the other hand, the machine-learning model G
is designed for such extrapolation, so we can extend the performance on more diverse training periods. While both models produce the same performance when using the 9 months (January to September) as training sets, we see that G
does a better job with reduced periods. We logically see that reducing the duration of the period damage the performance of both models. We see that the degradation can be up to 10% for M
when the period lasts only 3 months (February to April) with a time gap between training and test, instead of 9 months (January to September).
We conclude that training with the all the data, and using as recent data as possible, is the best way to grasp the various recent demand patterns. Furthermore, we stress the importance of using data collected during similar situations to those to be forecast, especially regarding the temperature. For instance, to efficiently forecast summer 2018 ideally means training the model with data collected in summer 2017.
4.2.4. Test Period Position
The test period’s position in the year impacts the performance.
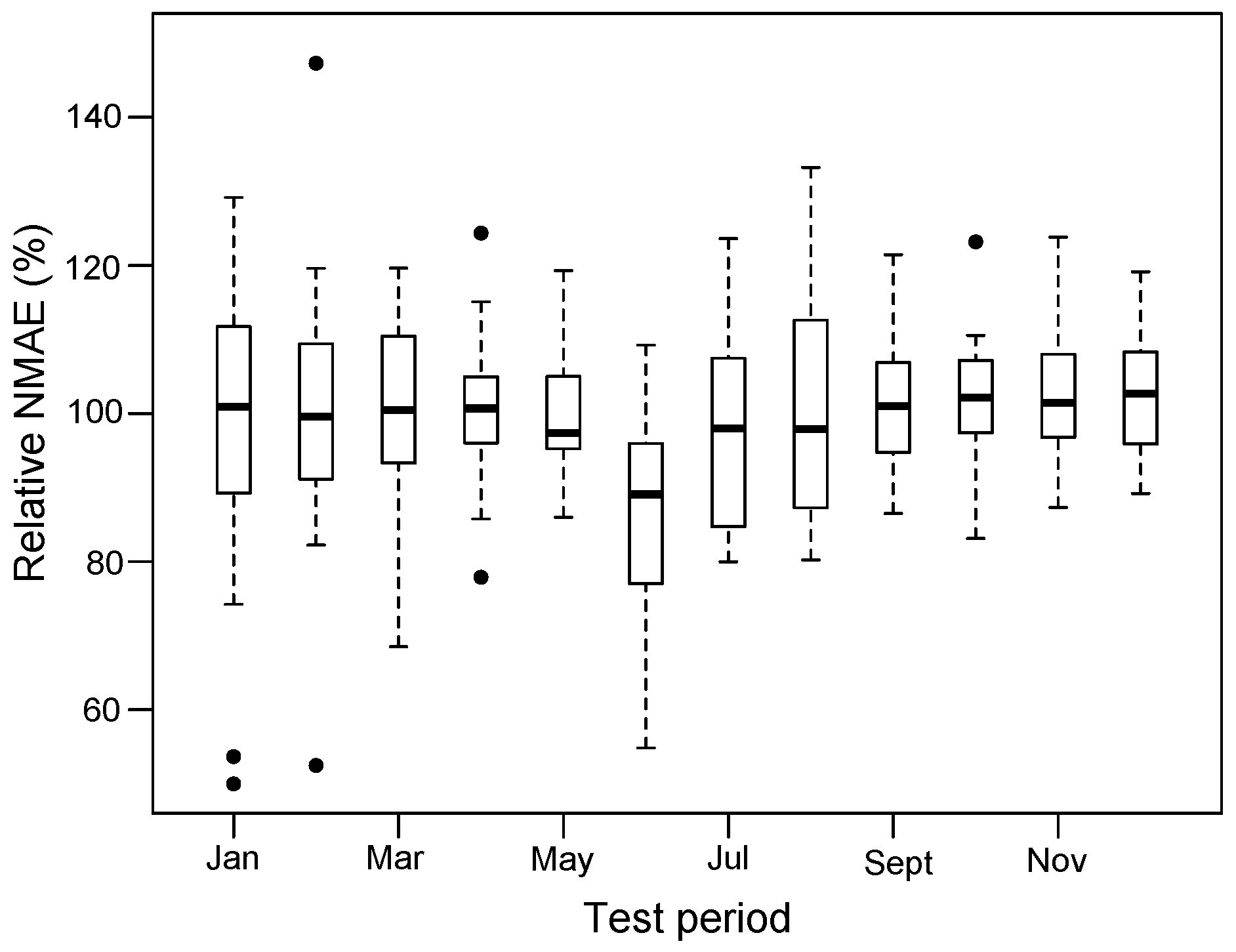
Figure 11 represents the forecasting performance with model M
obtained using, in turn, each month of the year 2015 as the test period, using the remainder as the training period. This framework implies that, while the test period is always out-of-sample, it is surrounded by the training period, which prevents any major deviation, possible in a real case. For each household in the
subset, the NMAE obtained for each month of the year is divided by the average over the whole year, to obtain a relative NMAE. The boxplot representation indicates the variation in the subset. We can see that, on average, the summer period, i.e., June to August, produces a slightly better performance than the other months, with a NMAE decrease of around 5%.
4.3. Summary
As a reminder: (1) the offline training period goes from 1 January to 30 September 2015, the offline test period from 1 October to 31 December 2015, and the offline NMAE is 34.8%; (2) the online training period goes from 1 July to 31 December 2017, the online test period from 1 April to 31 August 2018, and the offline NMAE is 58.5%.
We identify that the main cause of this 68% relative performance degradation is due to the intrinsic evolution of the time series. Thanks to a simple persistence forecasting model, we assess that the demand time series in the online case are roughly 50% more difficult to forecast than those of the offline case. To a great extent, we remove this intrinsic time-series evolution by analyzing the performance improvement of the forecasting framework over the persistence model. On average, we have seen that the NMAE is reduced to 90% of the persistence NMAE in the offline dataset, but only 97% in the online dataset. This remaining relative performance discrepancy of 8% is due to the mismatch of the training and test period positions in the online case. In fact, the models are trained with fall data, but tested with spring data, which causes a relative degradation of around 15%. This effect is counterbalanced by around 5% due to the position of the test period, since the spring period (online case) is easier to predict than the fall period (offline case).
5. Conclusions
We present 5 probabilistic forecasting models that employ small input sets—day of the week, hour of the day, recent smart-meter data, temperature prediction—to produce day-ahead forecasts of electricity demand at the household level. We compare the performance of the models on an offline dataset collected at a demonstration site in a Portuguese neighborhood. We observe that the more flexible, and thus more complex, model logically results in better overall performance, similar to that of a machine-learning benchmark.
However, many problematic situations arise and prevent the usage of this flexible model in real time. We therefore propose a hierarchical forecasting framework, combining the 5 models introduced, that addresses the following requirements: high robustness, fast computation, easy replicability, remote control, and easy interpretation. These requirements are essential for deployment of a forecasting model for a large number of households in real-world applications. After deployment in 2018, in the demonstrator in the frame of SENSIBLE project, the feedback data collected at the demonstration site are analyzed to provide an online forecasting performance. A household-by-household comparison with the performance assessed using an offline dataset shows a considerable relative degradation. We quantify the possible reasons for this degradation. Although it is due, in part, to the mismatch between the online training and test periods, the main cause is the evolution of the demand. From the distance in time between the initial offline testing of the model and its implementation for real operation, we observed an evolution of the characteristics of the physical process itself. The complexity of the demand pattern has greatly increased, meaning that the forecasting task is found to be about 50% intrinsically more complex during the online test. This observation highlights the fact that assessing forecasting performance at the household level is challenging. While forecasting performance was observed to vary greatly between two households, even when located in the same neighborhood, our experimental feedback shows that this performance also significantly evolves with time. This evolution is caused by unknown abrupt characteristics changes in the household, such as new people, additional appliances, changing habits of the householders, etc.
This raises the question of the adaptability of forecasting models at the household scale. We recommend incorporating the most recent data into a training period, to which the forecasting models are regularly fitted. The regularity of this training process can be quite coarse, e.g., every month, since most recent demand patterns are only slight deviations of older ones. Such a framework still implies a degree of model maintenance, such as reviewing the validity of the most recent smart-meter data recorded and starting the training process. A more intricate issue is caused by occasional abrupt changes in demand patterns. These changes are difficult to observe solely from the electricity demand time series. We advise using external input information about such changes, e.g., moving-in of new householders, to discard obsolete data and train using only smart-meter data recorded after the changes.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}