A New Scheme to Improve the Performance of Artificial Intelligence Techniques for Estimating Total Organic Carbon from Well Logs


Abstract
:1. Introduction
2. Theory and Methodology
2.1. Optimization of the Sample Data
2.1.1. Methodology of the Fuzzy c-Means Clustering Algorithm (FCM)
2.1.2. Methodology of the Simulated Annealing Algorithm (SA)
2.1.3. Methodology of the Genetic Algorithm (GA)
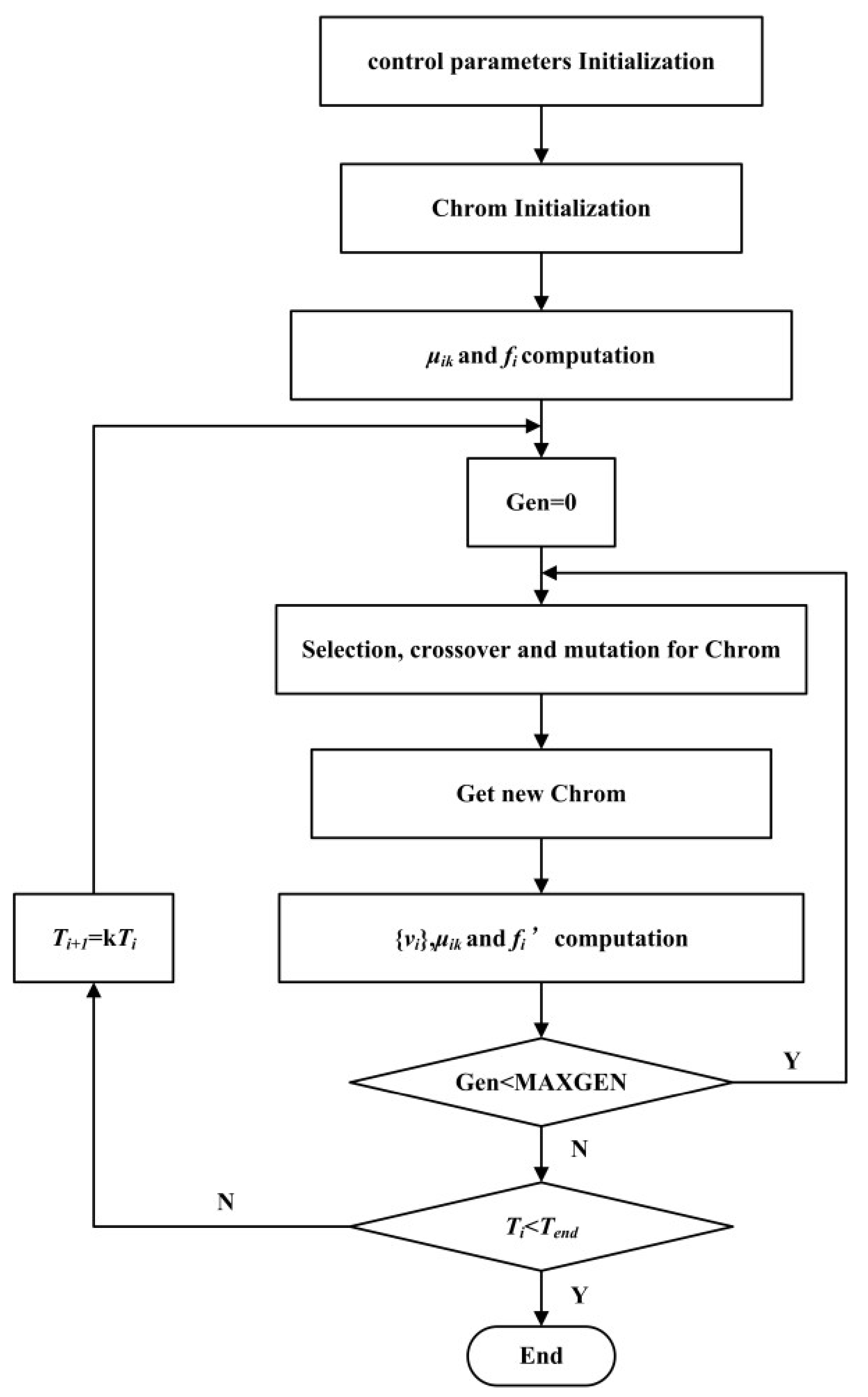
2.1.4. Flowchart of the SAGA-FCM Algorithm
2.2. Methodology of the Least Square Support Vector Machine
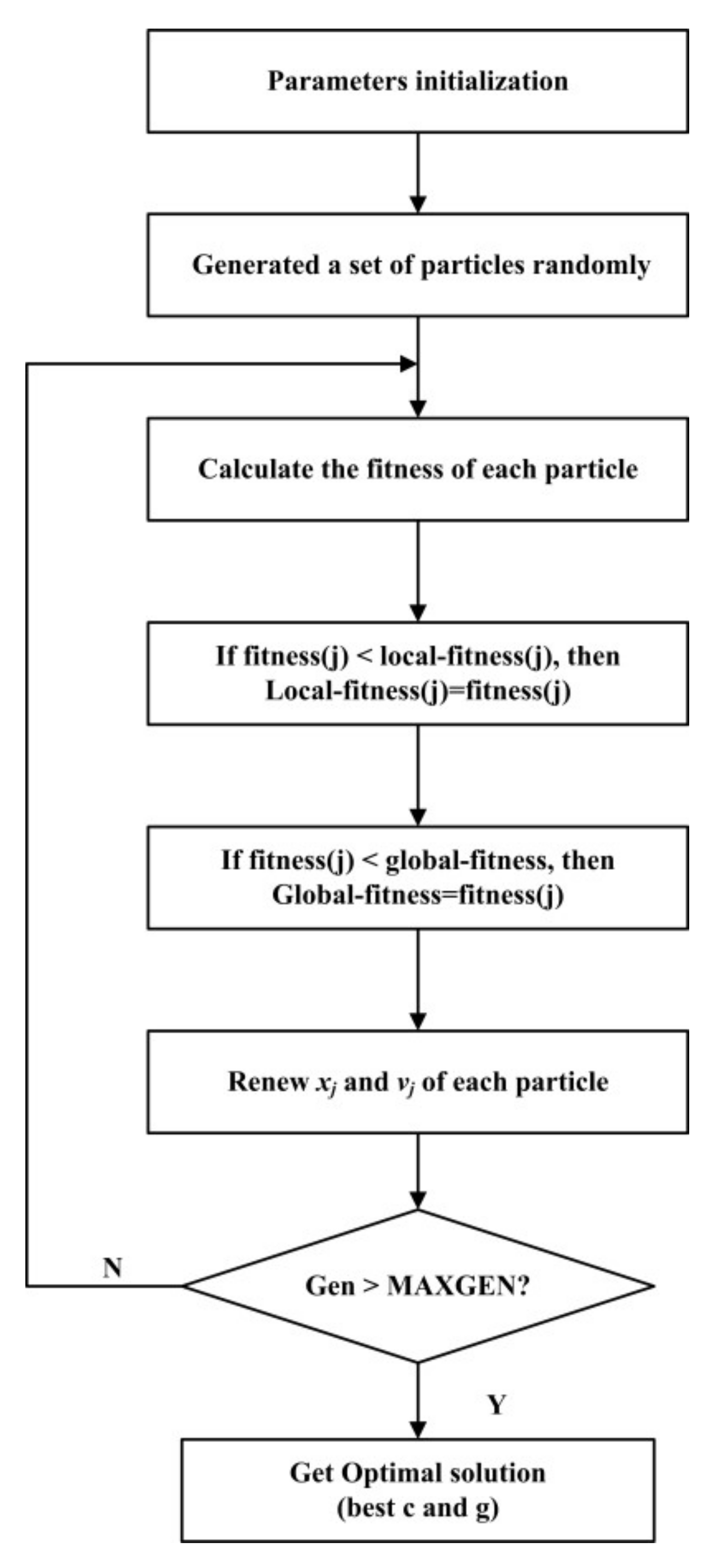
2.3. Methodology Parameter Optimization of the LSSVM
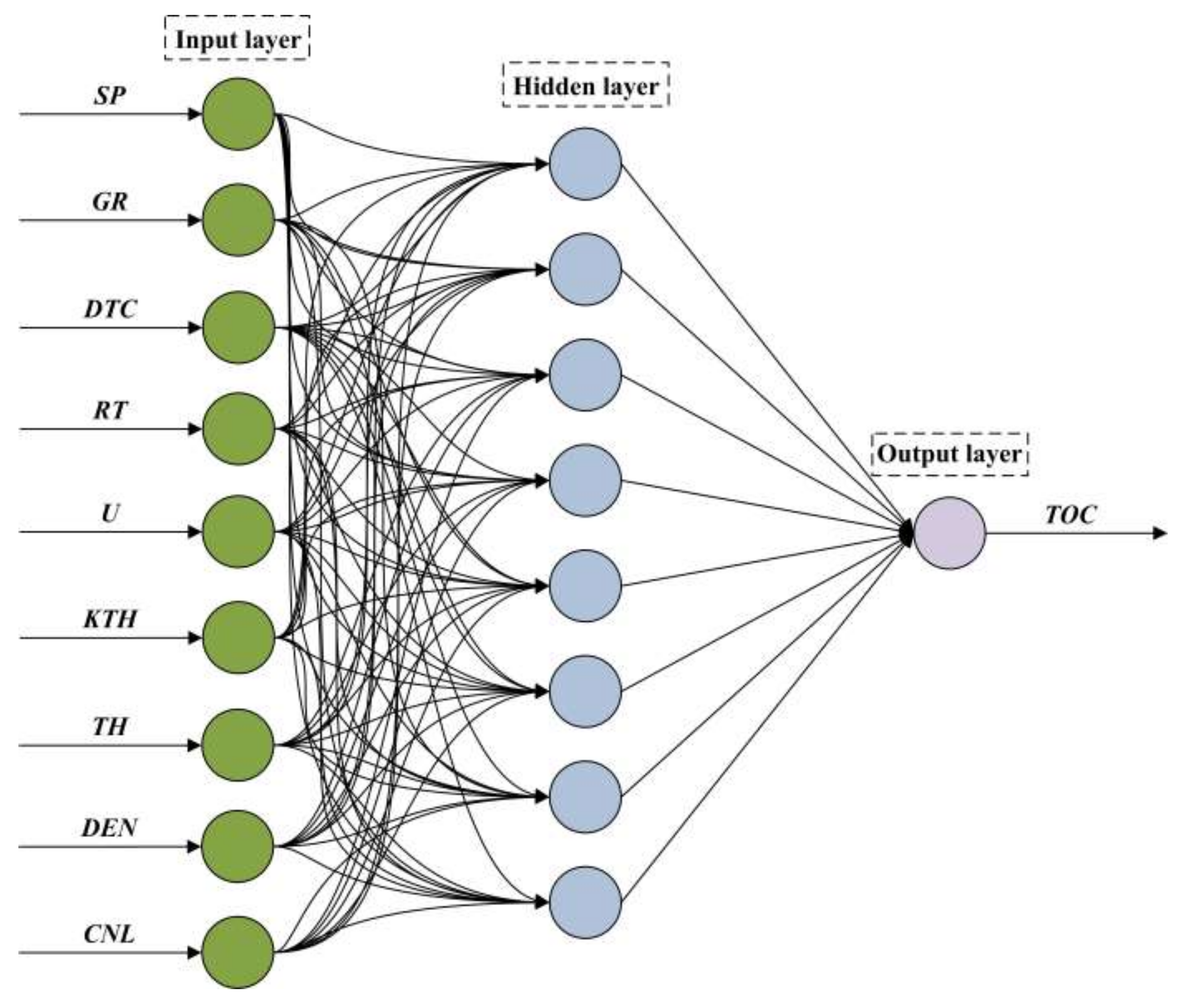
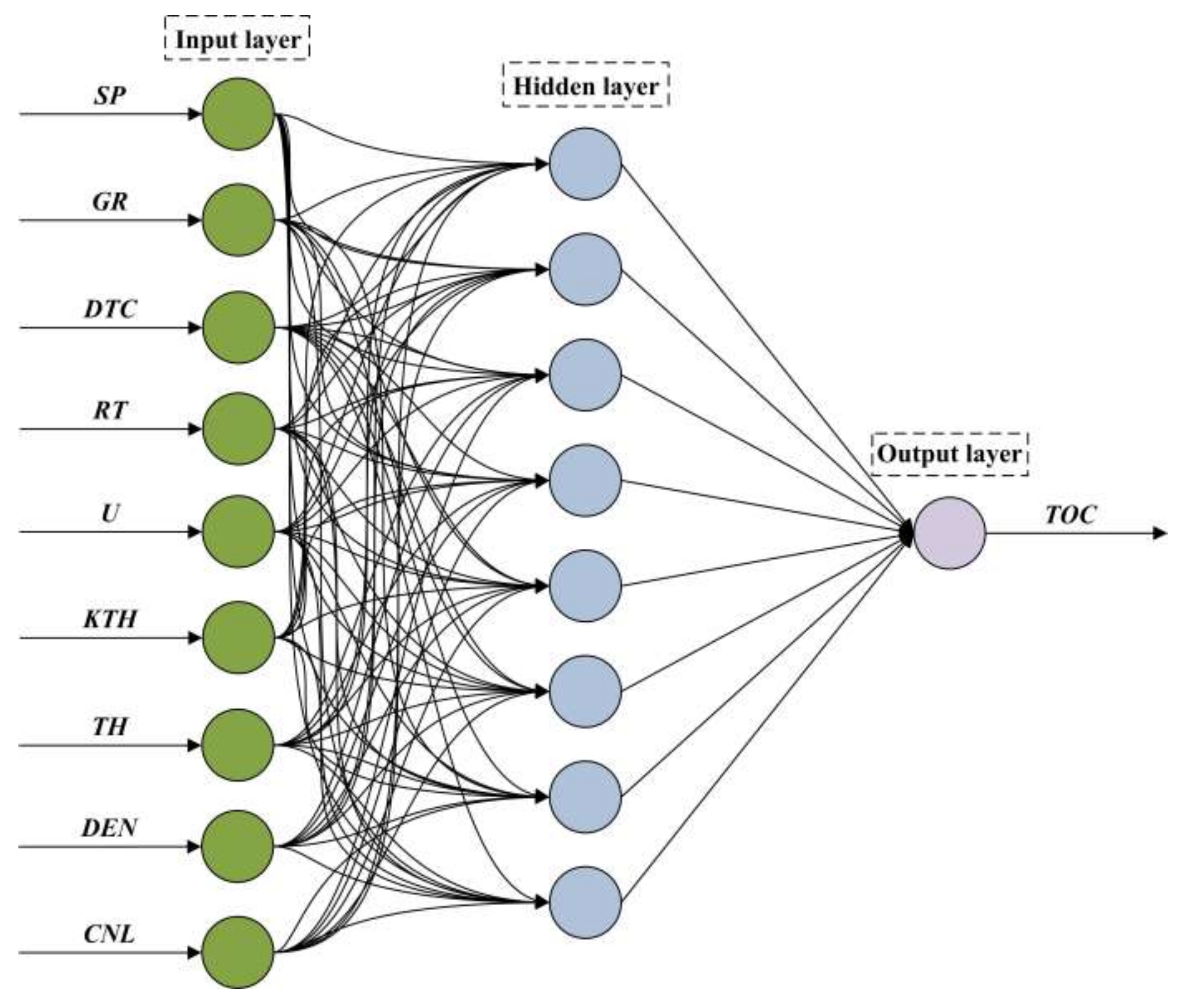
2.4. Methodology of the Back-Propagation Neural Network
3. Data Analysis and Optimization
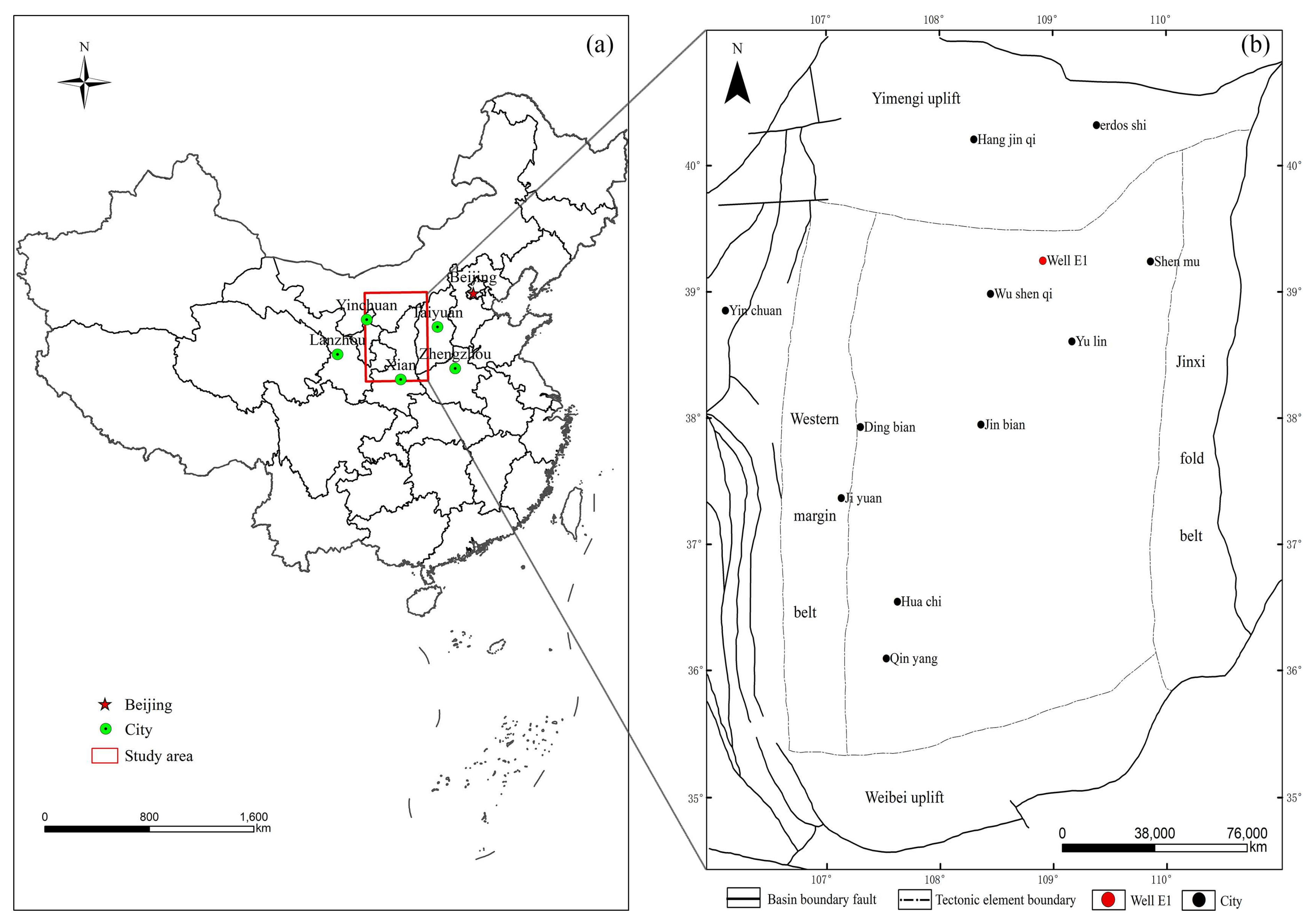
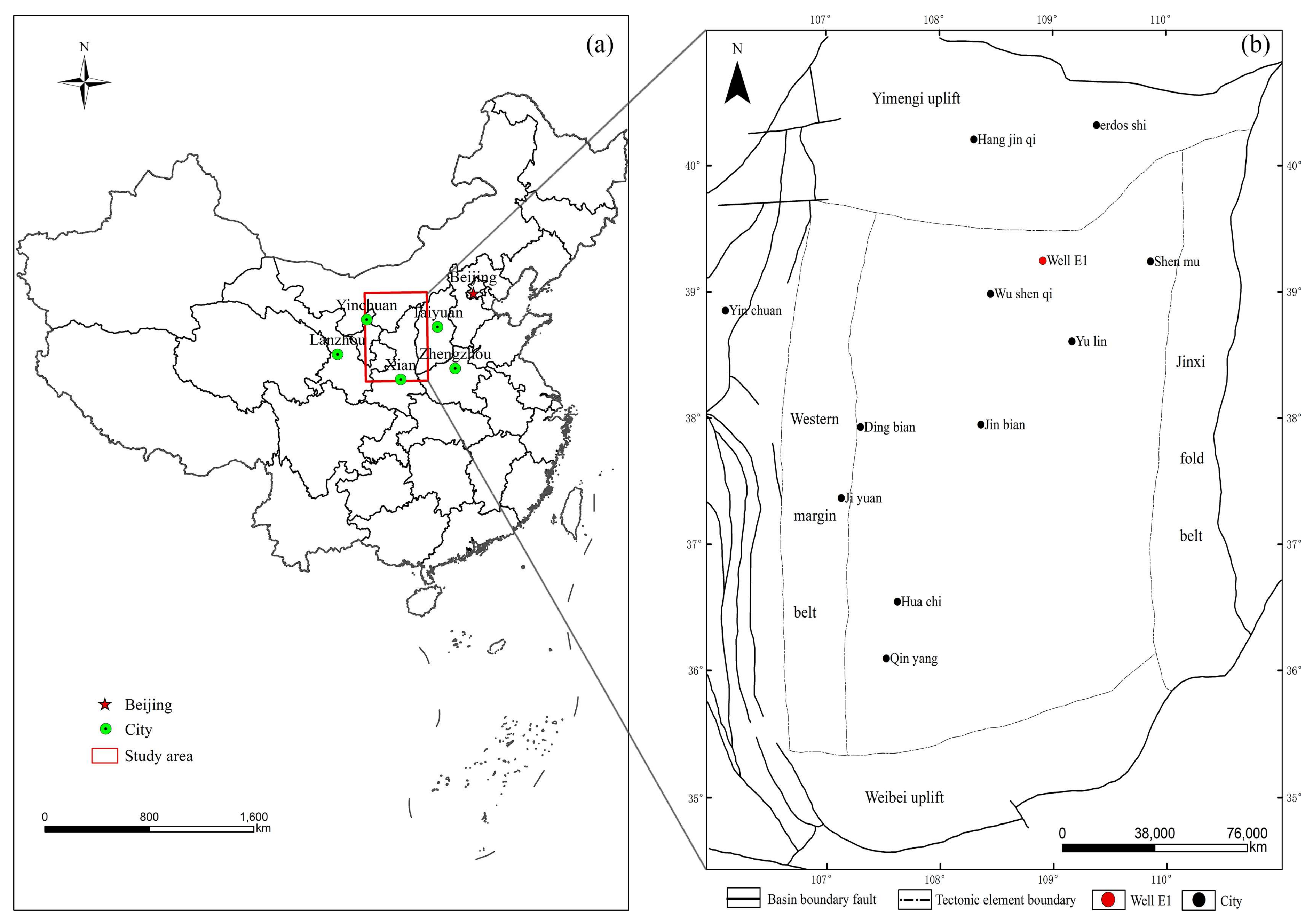
3.1. Study Area
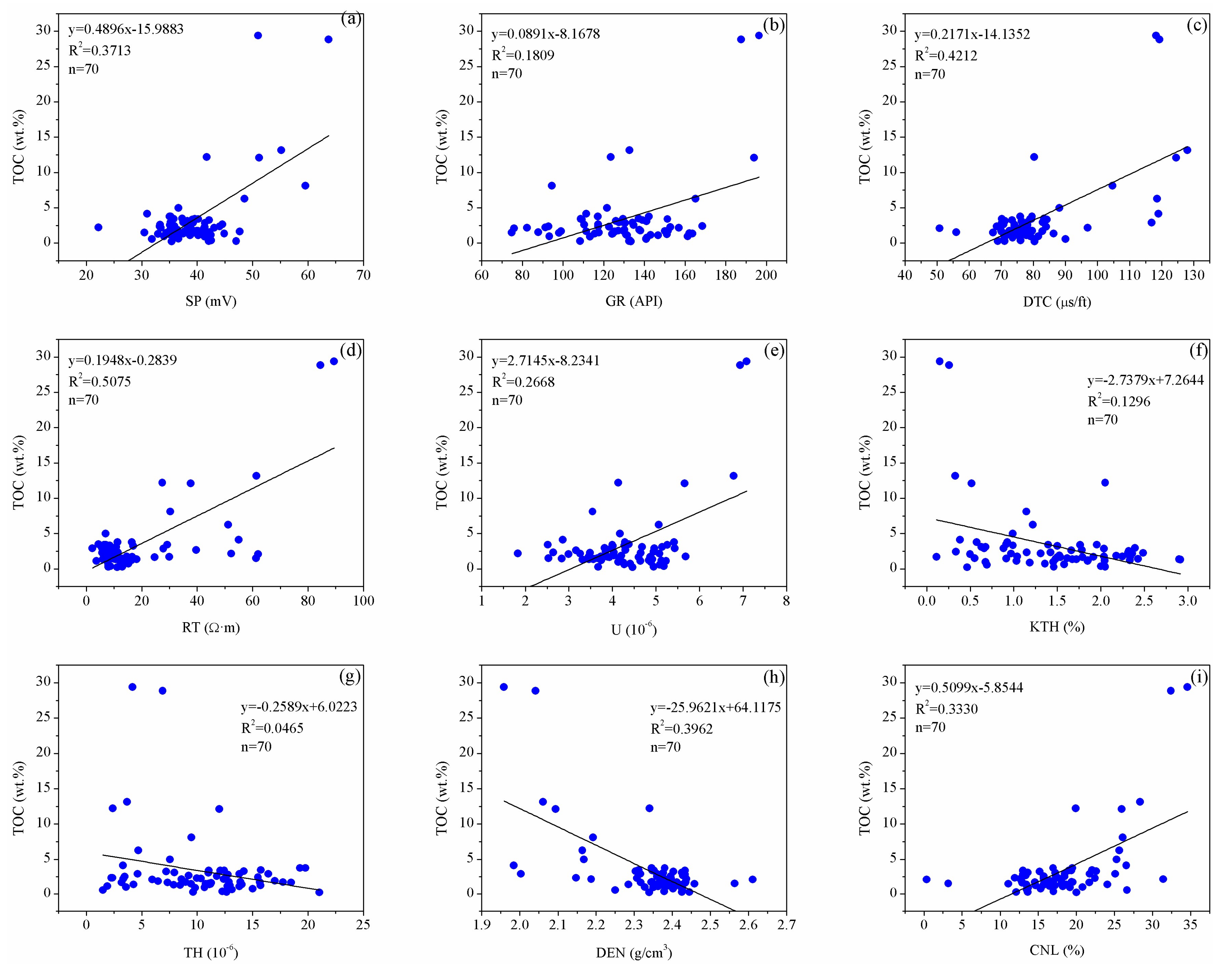
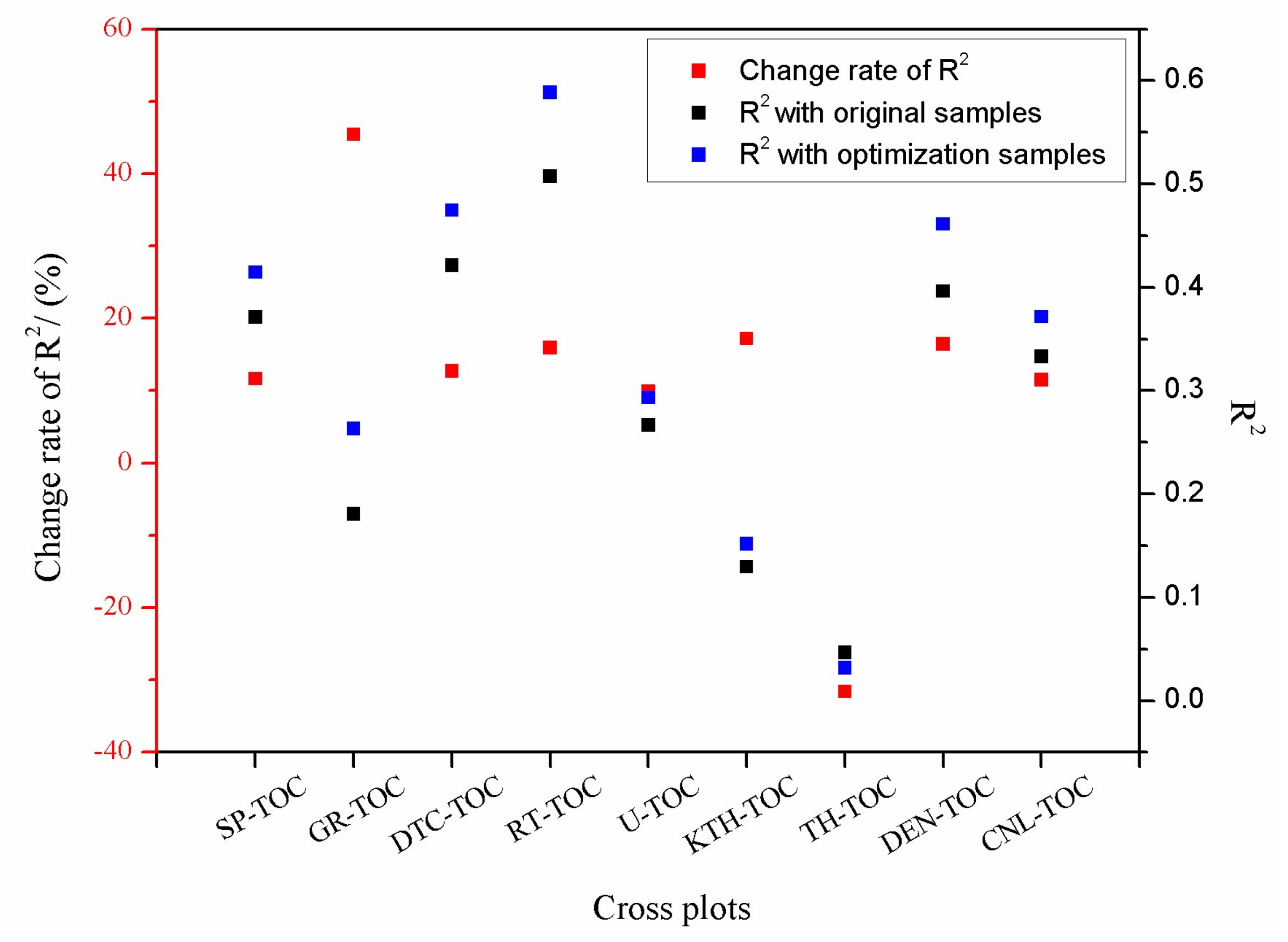
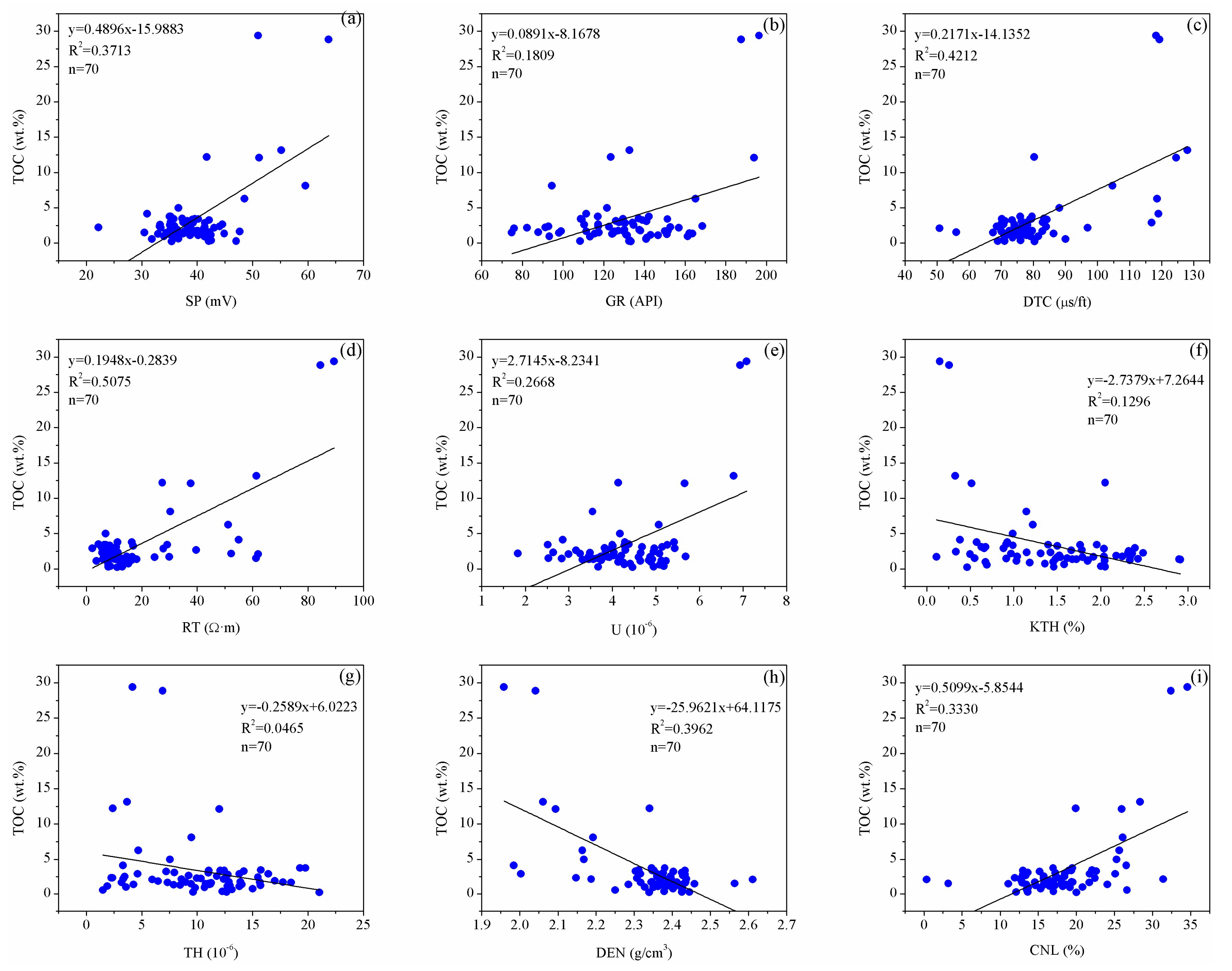
3.2. Data Analysis
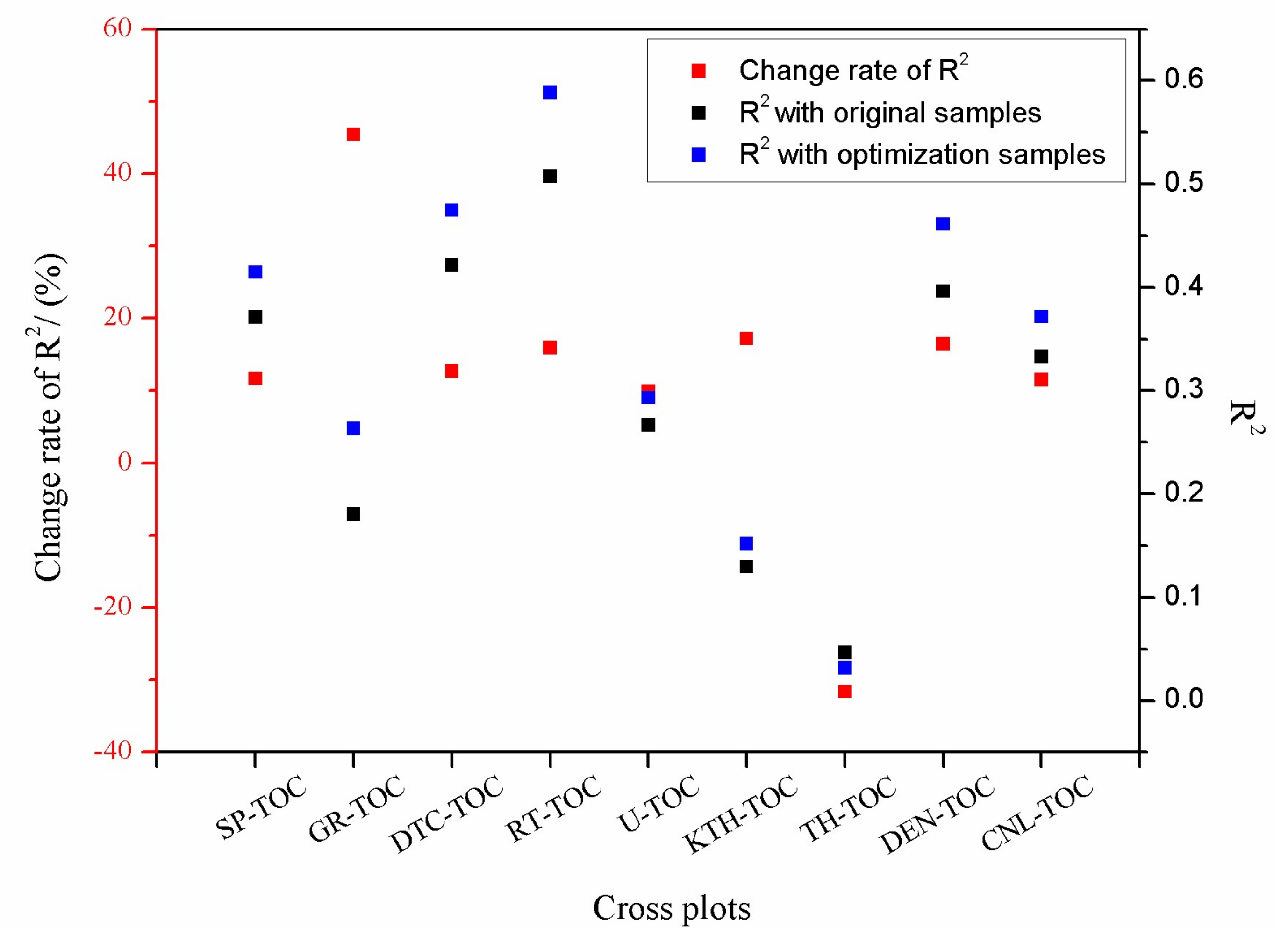
3.3. Data Optimization
4. Results
4.1. Model Establishment
4.1.1. LSSVM and PSO-LSSVM Models
4.1.2. Back-Propagation Neural Network Model
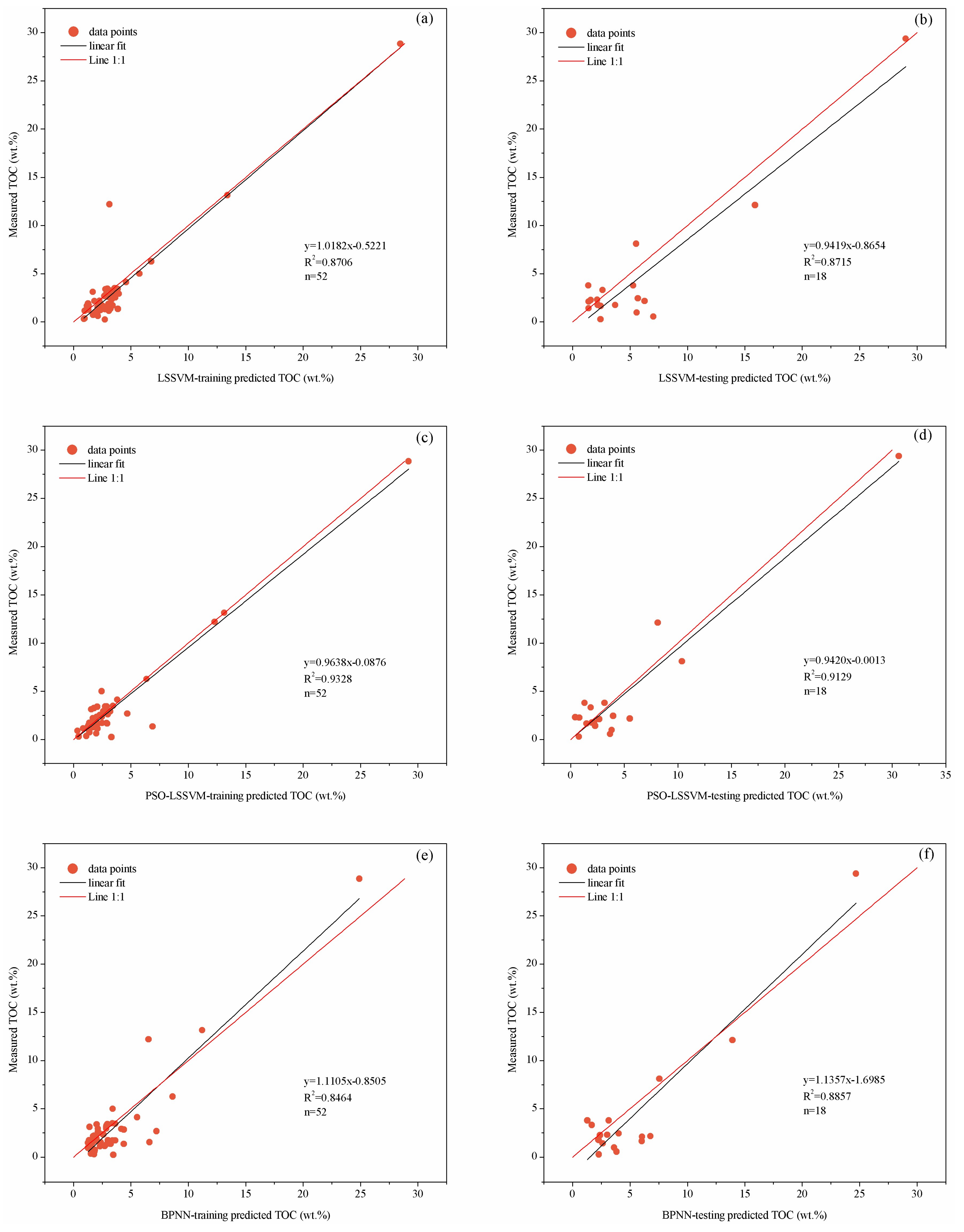
4.2. Model Performance
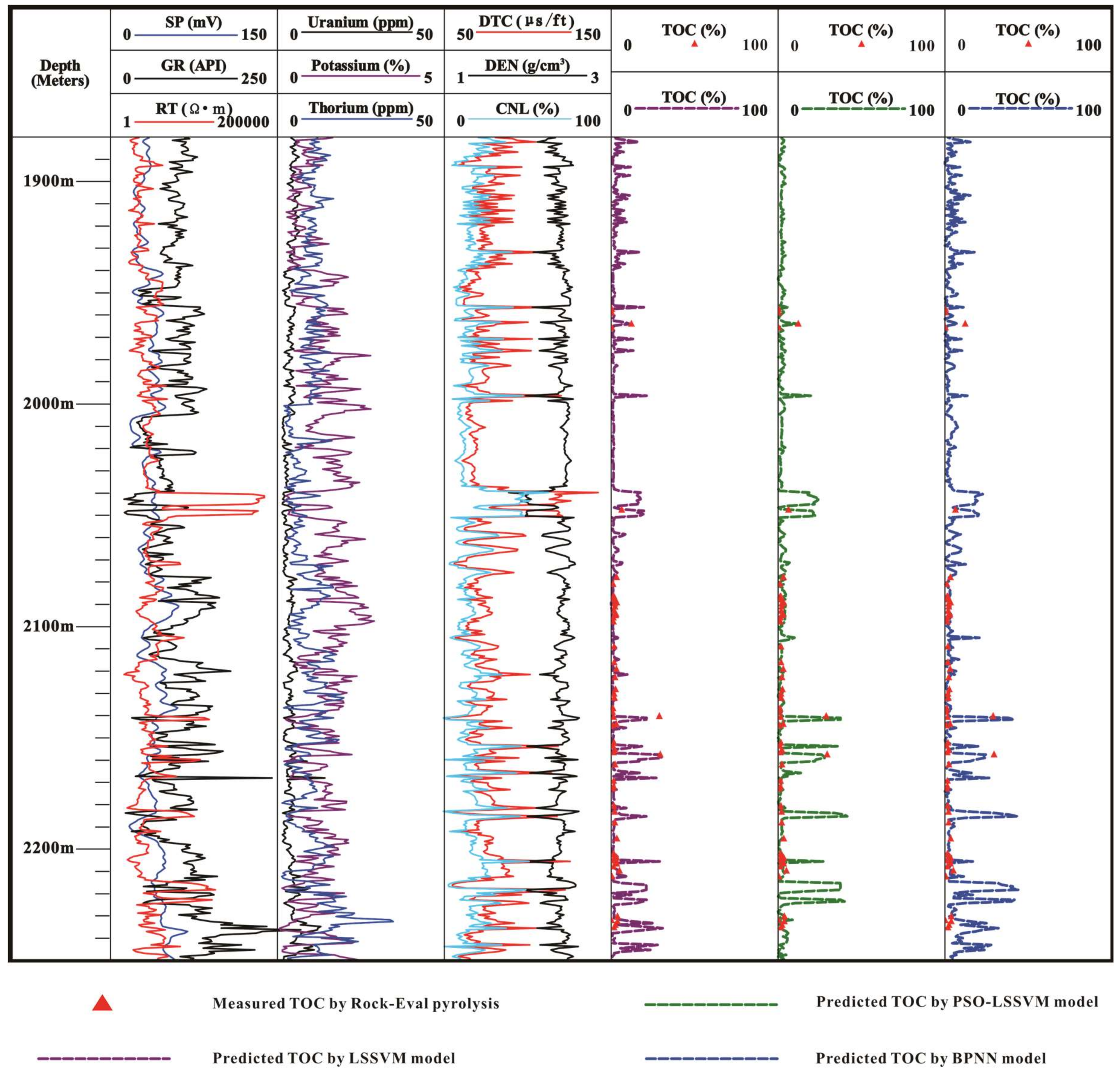
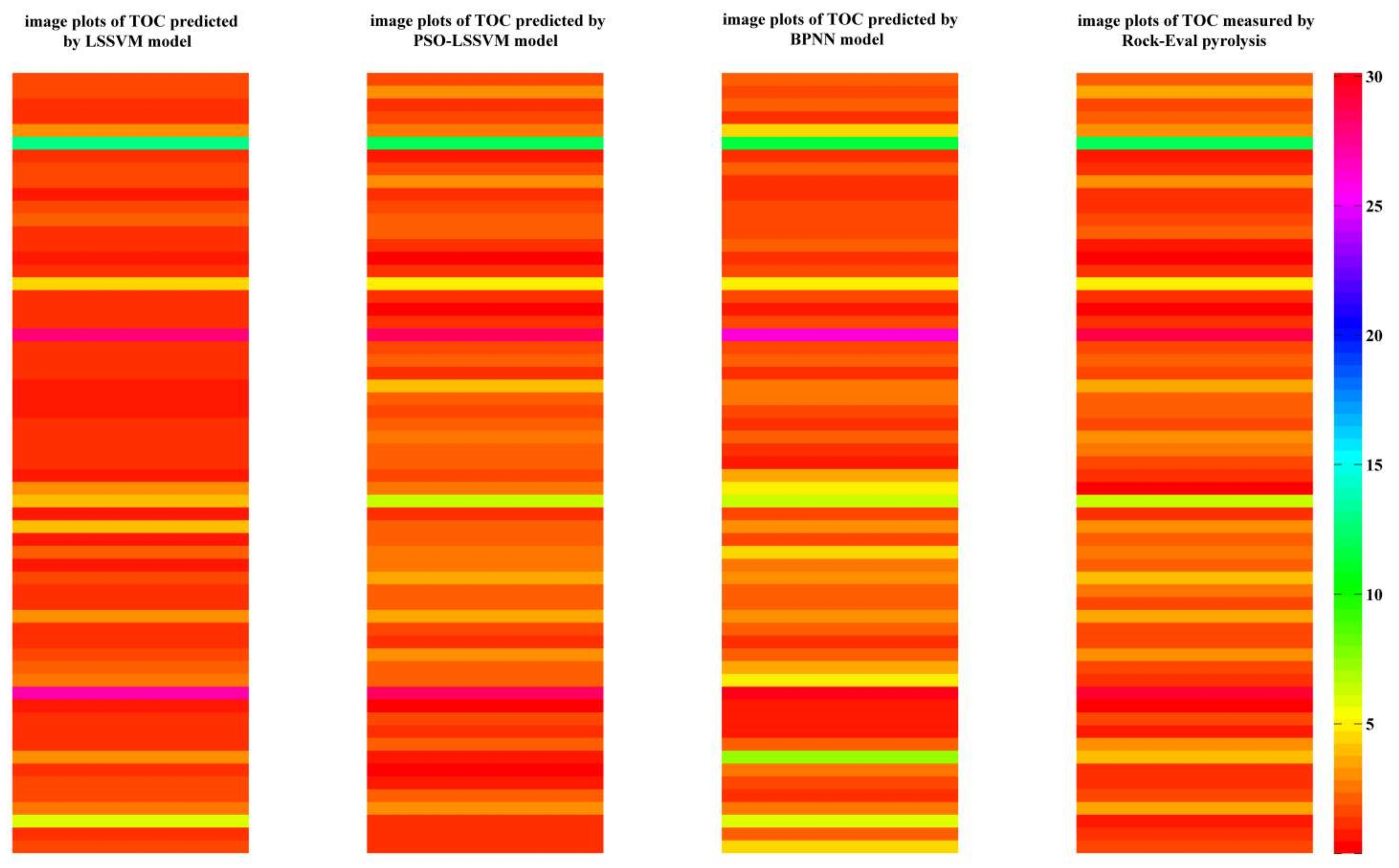
4.3. Model Validation
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- King, G. Thirty years of gas shale fracturing: What have we learned? J. Pet. Technol. 2010, 62, 88–90. [Google Scholar]
- Passey, Q.R.; Creaney, S.; Kulla, J.B.; Moretti, F.J.; Stroud, J.D. A practical model for organic richness from porosity and resistivity logs. AAPG Bull. 1990, 74, 1777–1794. [Google Scholar]
- Zhang, H.F.; Fang, C.L.; Gao, X.Z.; Zhang, Z.H.; Jiang, Y.L. Petroleum Geology; Petroleum Industry Press: Beijing, China, 1999; 345p. [Google Scholar]
- Heidari, Z.; Torres-Verdín, C.; Preeg, W.E. A quantitative method for estimating total organic carbon and porosity, and for diagnosing mineral constituents from well-logs in shale-gas formations. In Proceedings of the SPWLA 52nd Annual Logging Symposium, Colorado Springs, CO, USA, 14–18 May 2011. [Google Scholar]
- Hu, H.T.; Lu, S.F.; Liu, C.; Wang, W.M.; Wang, M.; Li, J.J.; Shang, J.H. Models for calculating organic carbon content from logging information: A comparison and analysis. Acta Sedimentol. Sin. 2011, 29, 1199–1205. [Google Scholar]
- Shi, X.; Wang, J.; Liu, G.; Yang, L.; Ge, X.M.; Jiang, S. Application of an extreme learning machine and neural networks in the total organic carbon content prediction of organic shale using wireline logs. J. Nat. Gas Sci. Eng. 2016, 33, 687–702. [Google Scholar] [CrossRef]
- Guo, L.; Chen, J.F.; Miao, Z.Y. The study and application of a new overlay method of TOC content. Nat. Gas. Geosci. 2009, 20, 951–956. [Google Scholar]
- Kamali, M.R.; Mirshady, A.A. Total organic carbon content determined from well-logs using ΔLogR and Neuro Fuzzy techniques. J. Pet. Sci. Eng. 2004, 45, 141–148. [Google Scholar] [CrossRef]
- Tan, M.J.; Song, X.D.; Yang, X.; Wu, Q.Z. Support-vector-regression machine technology for total organic carbon content prediction from wireline logs in organic shale: A comparative study. J. Nat. Gas Sci. Eng. 2015, 26, 792–802. [Google Scholar] [CrossRef]
- Jarvie, D.M.; Jarvie, B.M.; Weldon, D.; Maende, A. Geochemical assessment of in situ petroleum in unconventional resource systems. SPE178687. In Proceedings of the Unconventional Resources Technology Conference, San Antonio, TX, USA, 20–22 July 2015. [Google Scholar]
- Zhu, G.Y.; Jin, Q.; Zhang, L.Y. Using log information to analyze the geochemical characteristics of source rock in the Jiyang depression. Well Logging Technol. 2003, 27, 104–109. [Google Scholar]
- Beers, R.F. The radioactivity and organic content of some Paleozoic Shales. AAPG Bull. 1945, 29, 1–22. [Google Scholar]
- Schmoker, J.W. Determination of the organic content of Appalachian Devonian shale from formation-density logs: Geologic notes. AAPG Bull. 1979, 63, 1504–1509. [Google Scholar]
- Schmoker, J.; Hester, T. Organic carbon in Bakken formation of the United States’ portion of the Williston Basin. Am. Assoc. Pet. Geol. Bull. 1983, 67, 2165–2174. [Google Scholar]
- Meyer, B.L.; Nederlof, M.H. Identification of source rock on wireline logs by density/resistivity and sonic transit/resistivity cross-plots. AAPG Bull. 1984, 68, 121–129. [Google Scholar]
- Decker, A.D.; Hill, D.G.; Wicks, D.E. Log-based gas content and resource estimates for the Antrim shale of the Michigan Basin. In Proceedings of the Low Permeability Reservoirs Symposium, Denver, CO, USA, 26–28 April 1993; Society of Petroleum Engineers: Richardson, TX, USA, 1993. [Google Scholar]
- Autric, A.; Dumesnil, P. Resistivity radioactivity and sonic transit time logs to evaluate the organic content of low permeability rock. Log Anal. 1985, 26, 37–45. [Google Scholar]
- Wang, P.W.; Chen, Z.H.; Pang, X.Q.; Hu, K.Z.; Sun, M.L.; Chen, X. Revised models for determining the TOC in shale play: Example taken from the Devonian Duvernay shale of the Western Canada Sedimentary Basin. Mar. Pet. Geol. 2016, 70, 304–319. [Google Scholar] [CrossRef]
- Zhao, P.Q.; Ma, H.L.; Rasouli, V.; Liu, W.; Cai, J.C.; Huang, Z.H. An improved model for estimating the TOC in shale formations. Mar. Pet Geol. 2017, 83, 174–183. [Google Scholar] [CrossRef]
- Zhao, P.Q.; Mao, Z.Q.; Huang, Z.H.; Zhang, C.Z. A new method for estimating the total organic carbon content from well-logs. AAPG Bull. 2016, 100, 1311–1327. [Google Scholar] [CrossRef]
- Ebrahimi, E.; Monjezi, M.; Khalesi, M.R.; Armaghani, D.J. Prediction and optimization of back-break and rock fragmentation using an artificial neural network and a bee colony algorithm. Bull. Eng. Geol. Environ. 2016, 75, 27–36. [Google Scholar] [CrossRef]
- Mansouri, I.; Gholampour, A.; Kisi, O.; Ozbakkaloglu, T. Evaluation of peak and residual conditions of actively confined concrete using neuro-fuzzy and neural computing techniques. Neural Comput. Appl. 2018, 29, 873–888. [Google Scholar] [CrossRef]
- Nourani, V.; Alami, M.T.; Vousoughi, F.D. Self-organizing map clustering technique for ANN-based spatiotemporal modeling of groundwater quality parameters. J. Hydroinform. 2016, 18, 288–309. [Google Scholar] [CrossRef]
- AmiriBakhtiar, H.; Telmadarreie, A.; Shayesteh, M.; HeidariFard, M.H.; Talebi, H.; Shirband, Z. Estimating total organic carbon content and source rock evaluation, and applying ΔlogR and neural network methods: Ahwaz and Marun Oilfields, SW of Iran. Pet. Sci. Technol. 2011, 29, 1691–1704. [Google Scholar] [CrossRef]
- Huang, Z.H.; Williamson, M.A. Artificial neural network modelling as an aid to source rock characterization. Mar. Pet. Geol. 1996, 13, 277–290. [Google Scholar] [CrossRef]
- Sfidari, E.; Kadkhodaie-Ilkhchi, A.; Najjari, S. A comparison of intelligent and statistical clustering approaches to predicting total organic carbon using intelligent systems. J. Pet. Sci. Eng. 2012, 86–87, 190–205. [Google Scholar] [CrossRef]
- Dziegiel, M.H.; Nielsen, L.K.; Berkowicz, A. Detecting fetomaternal hemorrhage by flow cytometry. Curr. Opin. Hematol. 2006, 13, 490–495. [Google Scholar] [CrossRef] [PubMed]
- Pourazar, A.; Homayouni, A.; Rezaei, A.; Andalib, A.; Oreizi, F. The Assessment of Feto-Maternal Hemorrhage in an Artificial Model using an Anti-D and Anti-Fetal Hemoglobin Antibody by FCM. Iran. Biomed. J. 2008, 12, 43–48. [Google Scholar] [PubMed]
- Zainuddin, Z.; Pauline, O. An effective fuzzy C-means algorithm based on a symmetry similarity approach. Appl. Soft Comput. 2015, 35, 433–448. [Google Scholar] [CrossRef]
- Golden, B.L.; Skiscim, C.C. Using simulated annealing to solve routing and location problems. Nav. Res. Logist. 1986, 33, 261–279. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Suykens, J.A.K.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Eberhart, R.; Kennedy, J. A new optimizer using particle swarm theory. In Proceedings of the IEEE 6th International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995. [Google Scholar]
- Chen, L.H.; Chen, C.T.; Li, D.W. The application of integrated back-propagation network and self-organizing map for groundwater level forecasting. J. Water Resour. Plan. Manag. 2011, 137, 352–365. [Google Scholar] [CrossRef]
- Hsu, K.L.; Vijai, G.H.; Sorooshian, S. Artificial neural network modeling of the rainfall-runoff process. Water Resour. Res. 1995, 31, 2517–2530. [Google Scholar] [CrossRef]
- Lees, B.G. Neural network applications in the geosciences: An introduction. Comput. Geosci. 1996, 22, 955–957. [Google Scholar] [CrossRef]
- Ramadan, Z.; Hopke, P.K.; Johnson, M.J.; Scow, K.M. Application of PLS and back-propagation neural networks for the estimation of soil properties. Chemometr. Intell. Lab. Syst. 2005, 75, 23–30. [Google Scholar] [CrossRef]
- Shihab, K. A backpropagation neural network for computer network security. J. Comput. Sci. 2006, 2, 710–715. [Google Scholar] [CrossRef]
- Wang, H.B.; Sassa, K. Rainfall-induced landslide hazard assessment using artificial neural networks. Earth Surf. Process. Landfs. 2006, 31, 235–247. [Google Scholar] [CrossRef]
- Deng, X.Q.; Liu, X.S.; Li, S.X. The relationship between the compacting history and hydrocarbon accumulating history of the super-low permeability reservoirs in the Triassic Yanchang Formation of the Ordos Basin (China). Oil Gas Geol. 2009, 30, 156–261. [Google Scholar]
- Hou, G.T.; Wang, Y.X.; Hari, K.R. The Late-Triassic and Late-Jurassic stress fields and tectonic transmission of the North China Craton. J. Geodyn. 2010, 50, 318–324. [Google Scholar] [CrossRef]
- Yang, H.; Zhang, W.Z. Leading effect of the Seventh Member high-quality source rock of the Yanchang Formation in the Ordos Basin during the enrichment of low-penetrating oil-gas accumulation: The geology and geochemistry. Geochimica 2005, 34, 147–154. (In Chinese) [Google Scholar]
- Zhang, W.Z.; Yang, H.; Yang, Y.H.; Kong, Q.F.; Wu, K. The petrology and element geochemisty and development environment of the Yangchang Formation Chang-7 high quality source rock in the Ordos Basin. Geochimica 2008, 37, 59–64. (In Chinese) [Google Scholar]
- Zhang, W.Z.; Yang, H.; Li, J.F.; Ma, J. Leading effects of the high-class source rock of Chang7 in the Ordos Basin on the enrichment of low permeability oil-gas accumulation: Hydrocarbon generation and expulsion mechanism. Pet. Explor. Dev. 2006, 33, 289–293. (In Chinese) [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistical indicators | Depth (m) | SP (mV) | GR (API) | TDC (μs/ft) | RT (Ω·m) | U (ppm) | KTH (%) | TH (ppm) | DEN (g/cm3) | CNL (%) | TOC (wt.%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Miv | 1957.04 | 22.19 | 74.77 | 50.82 | 2.20 | 1.83 | 0.11 | 1.48 | 1.96 | 0.35 | 0.23 |
| Mav | 2234.87 | 63.74 | 196.41 | 128.03 | 89.39 | 7.08 | 2.91 | 21.03 | 2.61 | 34.56 | 29.39 |
| average | 2133.27 | 39.55 | 129.54 | 80.68 | 18.80 | 4.28 | 1.42 | 10.21 | 2.34 | 18.11 | 3.38 |
| SD | 65.92 | 6.42 | 25.09 | 15.38 | 18.76 | 0.99 | 0.70 | 4.83 | 0.12 | 5.85 | 5.09 |
| Parameters | TOC | SP | GR | DTC | RT | U | KTH | TH | DEN | CNL |
|---|---|---|---|---|---|---|---|---|---|---|
| TOC | 1 | |||||||||
| SP | 0.6093 | 1 | ||||||||
| GR | 0.4253 | 0.332 | 1 | |||||||
| DTC | 0.649 | 0.4729 | 0.3846 | 1 | ||||||
| RT | 0.7124 | 0.5709 | 0.0462 | 0.4623 | 1 | |||||
| U | 0.5165 | 0.5057 | 0.758 | 0.4908 | 0.1883 | 1 | ||||
| KTH | −0.36 | −0.16 | −0.1096 | −0.3937 | −0.3651 | −0.2429 | 1 | |||
| TH | −0.2156 | −0.0807 | 0.0404 | −0.1692 | −0.2885 | 0.068 | −0.1013 | 1 | ||
| DEN | −0.6294 | −0.3362 | −0.3052 | −0.9278 | −0.3895 | −0.4042 | 0.3887 | 0.2266 | 1 | |
| CNL | 0.5771 | 0.3306 | 0.3736 | 0.8782 | 0.2506 | 0.4717 | −0.3028 | −0.1046 | −0.8706 | 1 |
| Well Logs | Physical Interpretation |
|---|---|
| Spontaneous potential and resistivity | (1) Due to the fact that the stratum that was rich in organic carbon had a higher degree of mineralization than the surrounding rock, the potential differences resulting from the diffusion and adsorption between the drilling fluid and interlayer water increased. (2) The organic matter contained in the source rock consisted of non-conductive media, and the enrichment of the organic content led to the growth of the resistivity. |
| Natural gamma ray and spectral gamma | (1) The TOC content influenced the logging value of the natural gamma ray because of the source rock’s fine grains, large specific surface areas, and strong adsorption of organic matter into the radioactive elements. (2) The content of the potassium and thorium is associated with clay minerals. So, there is a weak correlation between the well logs of the potassium and thorium and the TOC content. |
| Sonic logs | The organic matter in the source rock with a high acoustic time difference led to the abnormal high value of the acoustic time difference. |
| Density logs | Since solid-state organic matter is characterized by light weight in terms of the surrounding rock, and its density is close to the density of water. Strata with high TOC generally have low density. |
| Compensated neutron logs | The hydrocarbon in the source rocks is rich in hydrogen element, which leads to an abnormally high neutron log value. Thus, the total organic carbon content in the source rock was closely related to the neutron log value. |
| Parameters | b | N | D | Sizepop | MAXGEN | Pc | Pm | T0 | k | Tend |
|---|---|---|---|---|---|---|---|---|---|---|
| Value | 2 | 10 | 1 × 10−6 | 100 | 100 | 0.7 | 0.01 | 100 | 0.8 | 1 |
| Sample No. | HQ | PQ | Results | Sample No. | HQ | PQ | Results | Sample No. | HQ | PQ | Results |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.6279 | 0.3721 | Y | 25 | 0.7116 | 0.2884 | Y | 49 | 0.6402 | 0.3598 | Y |
| 2 | 0.5652 | 0.4348 | Y | 26 | 0.4171 | 0.5829 | N | 50 | 0.3595 | 0.6405 | N |
| 3 | 0.5542 | 0.4458 | Y | 27 | 0.6699 | 0.3301 | Y | 51 | 0.6685 | 0.3315 | Y |
| 4 | 0.6654 | 0.3346 | Y | 28 | 0.7314 | 0.2686 | Y | 52 | 0.5602 | 0.4398 | Y |
| 5 | 0.5443 | 0.4557 | Y | 29 | 0.7134 | 0.2866 | Y | 53 | 0.4618 | 0.5382 | N |
| 6 | 0.4225 | 0.5775 | N | 30 | 0.5694 | 0.4306 | Y | 54 | 0.6129 | 0.3871 | Y |
| 7 | 0.7253 | 0.2747 | Y | 31 | 0.6908 | 0.3092 | Y | 55 | 0.6727 | 0.3273 | Y |
| 8 | 0.4237 | 0.5763 | N | 32 | 0.553 | 0.447 | Y | 56 | 0.7801 | 0.2199 | Y |
| 9 | 0.7173 | 0.2827 | Y | 33 | 0.5611 | 0.4389 | Y | 57 | 0.5927 | 0.4073 | Y |
| 10 | 0.3935 | 0.6065 | N | 34 | 0.5249 | 0.4751 | Y | 58 | 0.5529 | 0.4471 | Y |
| 11 | 0.4786 | 0.5214 | N | 35 | 0.719 | 0.281 | Y | 59 | 0.6544 | 0.3456 | Y |
| 12 | 0.3991 | 0.6009 | N | 36 | 0.7561 | 0.2439 | Y | 60 | 0.5819 | 0.4181 | Y |
| 13 | 0.7062 | 0.2938 | Y | 37 | 0.5281 | 0.4719 | Y | 61 | 0.5284 | 0.4716 | Y |
| 14 | 0.709 | 0.291 | Y | 38 | 0.5646 | 0.4354 | Y | 62 | 0.6731 | 0.3269 | Y |
| 15 | 0.6707 | 0.3293 | Y | 39 | 0.5458 | 0.4542 | Y | 63 | 0.5364 | 0.4636 | Y |
| 16 | 0.7056 | 0.2944 | Y | 40 | 0.7183 | 0.2817 | Y | 64 | 0.5743 | 0.4257 | Y |
| 17 | 0.7236 | 0.2764 | Y | 41 | 0.5302 | 0.4698 | Y | 65 | 0.6157 | 0.3843 | Y |
| 18 | 0.6861 | 0.3139 | Y | 42 | 0.6671 | 0.3329 | Y | 66 | 0.681 | 0.319 | Y |
| 19 | 0.7151 | 0.2849 | Y | 43 | 0.6554 | 0.3446 | Y | 67 | 0.6137 | 0.3863 | Y |
| 20 | 0.6742 | 0.3258 | Y | 44 | 0.6618 | 0.3382 | Y | 68 | 0.7294 | 0.2706 | Y |
| 21 | 0.5096 | 0.4904 | Y | 45 | 0.5288 | 0.4712 | Y | 69 | 0.6422 | 0.3578 | Y |
| 22 | 0.4975 | 0.5025 | N | 46 | 0.6303 | 0.3697 | Y | 70 | 0.7155 | 0.2845 | Y |
| 23 | 0.6239 | 0.3761 | Y | 47 | 0.5978 | 0.4022 | Y | ||||
| 24 | 0.5892 | 0.4108 | Y | 48 | 0.6608 | 0.3392 | Y |
| Parameters | TOC | SP | GR | DTC | RT | U | KTH | TH | DEN | CNL |
|---|---|---|---|---|---|---|---|---|---|---|
| TOC | 1 | |||||||||
| SP | 0.6438 | 1 | ||||||||
| GR | 0.5129 | 0.5297 | 1 | |||||||
| DTC | 0.6889 | 0.5065 | 0.6024 | 1 | ||||||
| RT | 0.7672 | 0.6146 | 0.2173 | 0.357 | 1 | |||||
| U | 0.5415 | 0.5791 | 0.7921 | 0.6014 | 0.2458 | 1 | ||||
| KTH | −0.3897 | −0.1801 | −0.0911 | −0.2821 | −0.3394 | −0.2542 | 1 | |||
| TH | −0.1783 | −0.1139 | 0.0806 | −0.0922 | −0.2083 | 0.0199 | −0.0485 | 1 | ||
| DEN | −0.6792 | −0.3814 | −0.4887 | −0.9094 | −0.2744 | −0.5198 | 0.2786 | 0.0939 | 1 | |
| CNL | 0.6094 | 0.3286 | 0.5748 | 0.8819 | 0.1035 | 0.5922 | −0.1976 | −0.1103 | −0.8625 | 1 |
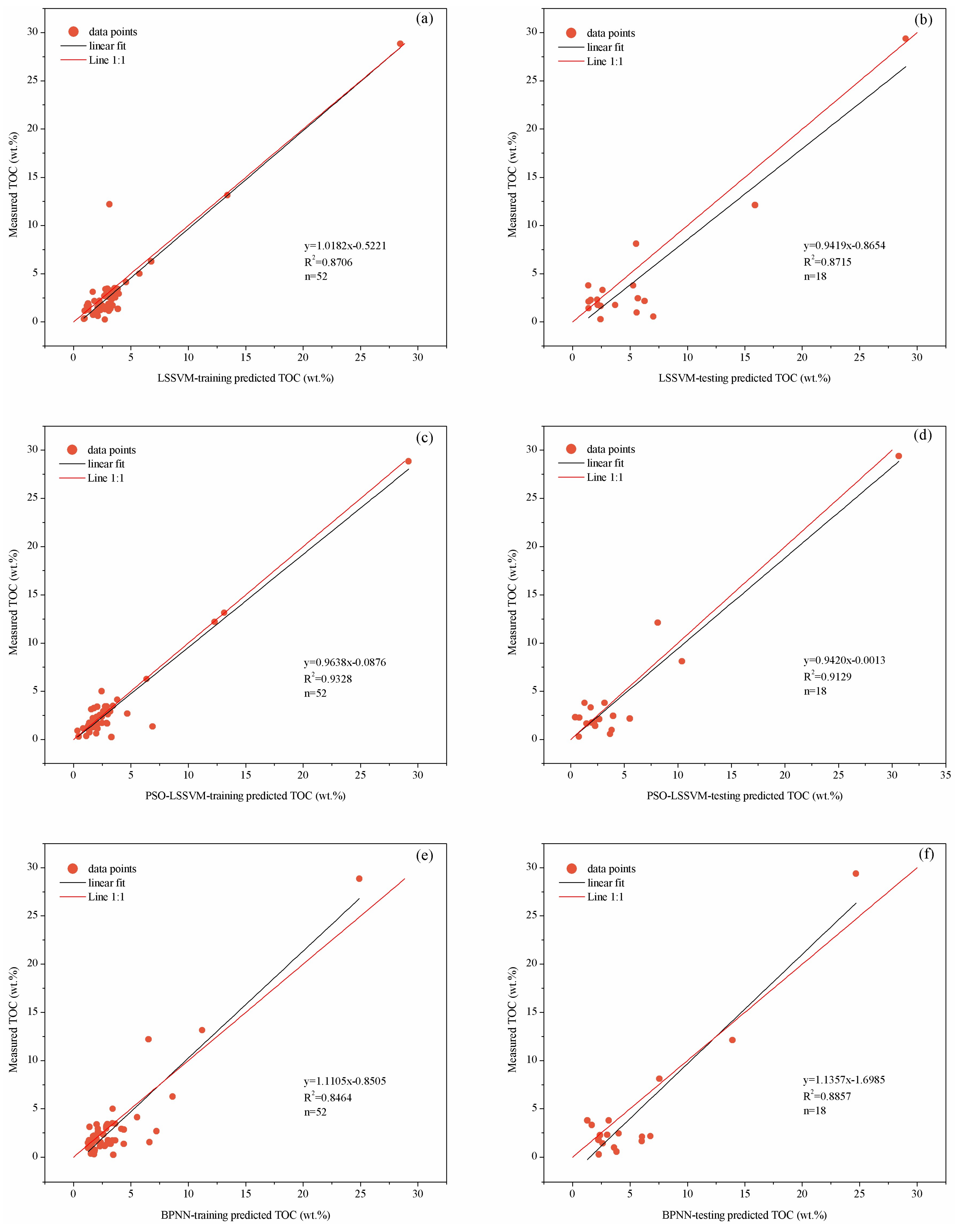
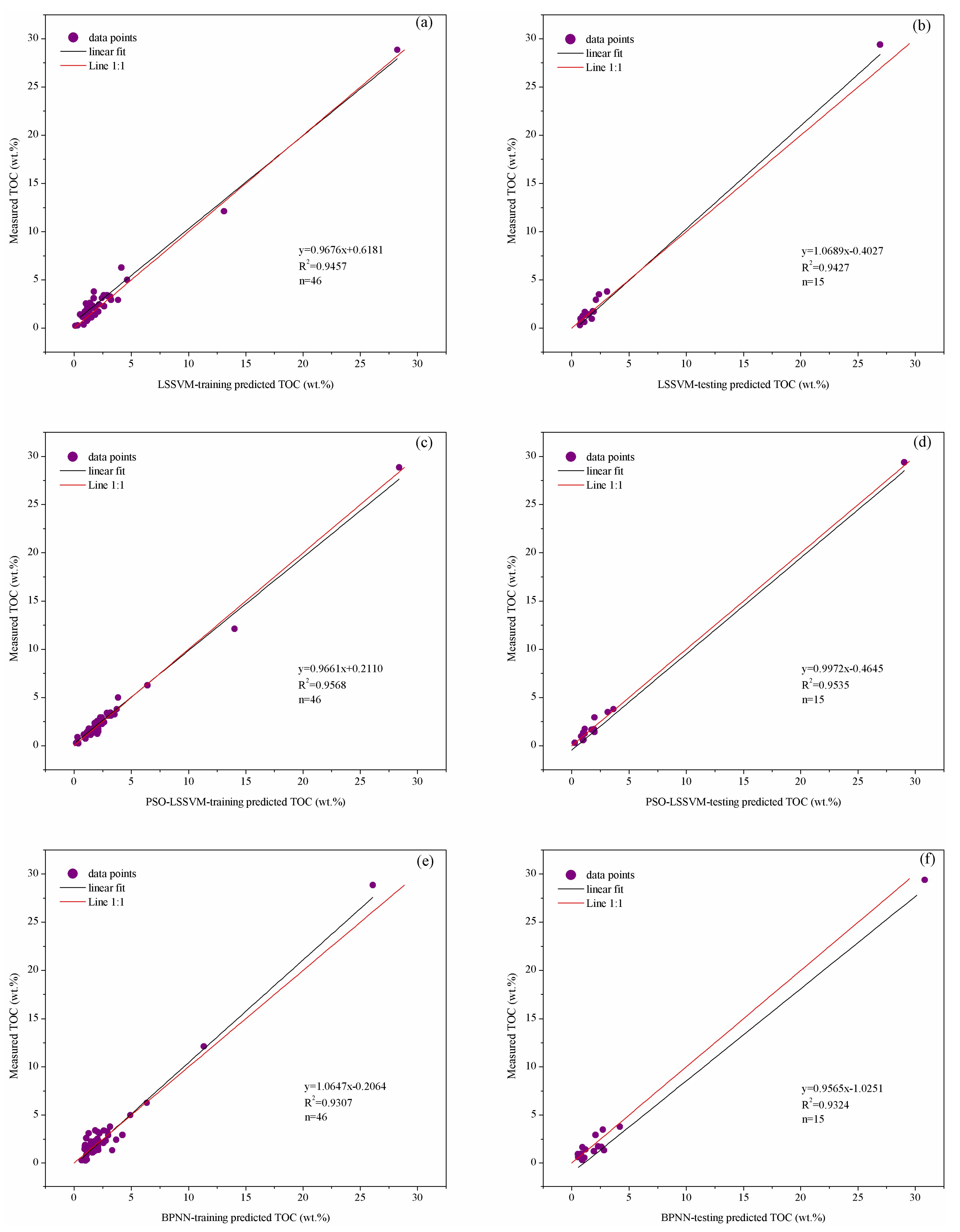
| Data Set | Performance Indicator | LSSVM Model | PSO-LSSVM Model | BPNN Model |
|---|---|---|---|---|
| Original samples data training part | R2 | 0.8706 | 0.9328 | 0.8464 |
| RMSE | 1.6187 | 1.1464 | 1.7964 | |
| VAF | 84.5567 | 93.1765 | 76.3963 | |
| Original samples data testing part | R2 | 0.8715 | 0.9129 | 0.8857 |
| RMSE | 1.6943 | 1.2055 | 2.0593 | |
| VAF | 86.5811 | 91.2362 | 81.5052 | |
| Optimization samples data training part | R2 | 0.9457 | 0.9568 | 0.9307 |
| RMSE | 0.4142 | 0.3125 | 0.5061 | |
| VAF | 94.5206 | 95.6682 | 91.1356 | |
| Optimization samples data testing part | R2 | 0.9427 | 0.9535 | 0.9324 |
| RMSE | 0.4082 | 0.3675 | 0.5177 | |
| VAF | 92.5779 | 94.1615 | 93.1739 |
| Model | R2 | RMSE | VAF |
|---|---|---|---|
| LSSVM | 0.9316 | 0.4094 | 93.4207 |
| PSO-LSSVM | 0.9451 | 0.3383 | 94.1019 |
| BPNN | 0.9184 | 0.5119 | 91.2551 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, P.; Peng, S. A New Scheme to Improve the Performance of Artificial Intelligence Techniques for Estimating Total Organic Carbon from Well Logs. Energies 2018, 11, 747. https://doi.org/10.3390/en11040747
Wang P, Peng S. A New Scheme to Improve the Performance of Artificial Intelligence Techniques for Estimating Total Organic Carbon from Well Logs. Energies. 2018; 11(4):747. https://doi.org/10.3390/en11040747
Chicago/Turabian StyleWang, Pan, and Suping Peng. 2018. "A New Scheme to Improve the Performance of Artificial Intelligence Techniques for Estimating Total Organic Carbon from Well Logs" Energies 11, no. 4: 747. https://doi.org/10.3390/en11040747
APA StyleWang, P., & Peng, S. (2018). A New Scheme to Improve the Performance of Artificial Intelligence Techniques for Estimating Total Organic Carbon from Well Logs. Energies, 11(4), 747. https://doi.org/10.3390/en11040747