1. Introduction
Energy saving measures (ESMs) usually aim to lower greenhouse gas (GHG) emissions in an attempt to mitigate climate change [
1,
2]. Energy efficiency also offers significant opportunities to lower the large financial costs associated with the use of fossil fuels [
3].
In order to accurately quantify energy savings, accurate measurements and agreed upon methodologies are needed. Various Measurement and Verification (M&V) guidelines, such as The International Performance Measurement and Verification Protocol (IPMVP, see [
3]), serve as industry-standards for energy M&V [
1]. Better M&V generally results in higher savings with an increased level of confidence, thereby encouraging investment in energy efficiency and renewable energy projects [
3]. Accurate quantification of savings is also important when considering tax-based incentives [
1]. A very important factor to consider when interpreting savings is the inherent uncertainty in the data. Hamer et al. [
1] reports that M&V calculations typically deviate from the actual observed savings by 10%. The IPMVP highlights instrumentation and modelling error as two quantifiable sources of inaccuracy in the M&V process and stresses the importance of reporting possible savings as well as a well-defined uncertainty [
3].
Carstens et al. [
4] rightfully points out that the traditional frequentist approach for obtaining well-defined uncertainty can lead to misinterpretation of the uncertainty it conveys. This creates an opportunity for the use of nonlinear Gaussian Process (GP) regression within the Bayesian paradigm for quantifying uncertainties in the M&V process [
5]. The probabilistic nature of Bayesian models means that uncertainty is well defined [
4]. GP regression can therefore provide true confidence in the calculated savings of energy efficiency projects and in that way provide more bankable figures and reliable retrofit campaigns.
Determining the parameters that govern typical energy demand models could become time-consuming and expensive. This is especially true for energy systems that have high sensitivity to complex external parameters and usage patterns (see [
6] for examples). GP regression, on the other hand, yields more robust predictions of energy use [
7]. The predictive power of GP regression will be illustrated in a forthcoming paper, as this paper mainly communicates a case study of energy management M&V that could benefit from GP regression.
Another attractive property of the Bayesian paradigm is that little knowledge of the underlying energy model is necessary, thus reducing the induced error associated with the model [
8]. The Bayesian paradigm allows the data to “speak for itself”, thus largely eliminating the modelling error in M&V [
4,
9].
To explain the GP without the use of technical statistical jargon, this paper makes use of the fundamental concept of inference. Inference, as used in this paper, refers to the concept of learning from a time-stamped data set that describes a specific energy driver associated with a building. To infer a mathematical structure that describes the dependencies and relationships between individual observations without prior knowledge of the governing parameters is the main purpose of the Bayes and GP paradigm. The inferred mathematical structure that describes the relationships between instances in the time series data set can be used to derive a set of evidence-based rules that could be useful for predictive purposes. M&V describes the process of determining the savings generated by an energy intervention and requires well-known uncertainty. The uncertainties associated with measured data (also called noisy evidence) are propagated forward by the GP and the GP thus generates a framework to predict system outputs using evidence in a probabilistic manner. The reader is referred to Reddy and Claridge [
8] for the technical details of uncertainty propagation in GP algorithms.
The Bayesian paradigm is mathematically formulated by Bayes’ Theorem:
Theorem 1. .
In Theorem 1, denotes probability, while | indicates conditional probability. When applied in the field of M&V, Theorem 1 provides the probability of savings given the measurements, . The uncertainty in savings is captured by , the uncertainty in measurement is given by , while the uncertainty in measurement given the savings is incorporated by . The fact that is well defined by Theorem 1 supports what is fundamentally required for M&V.
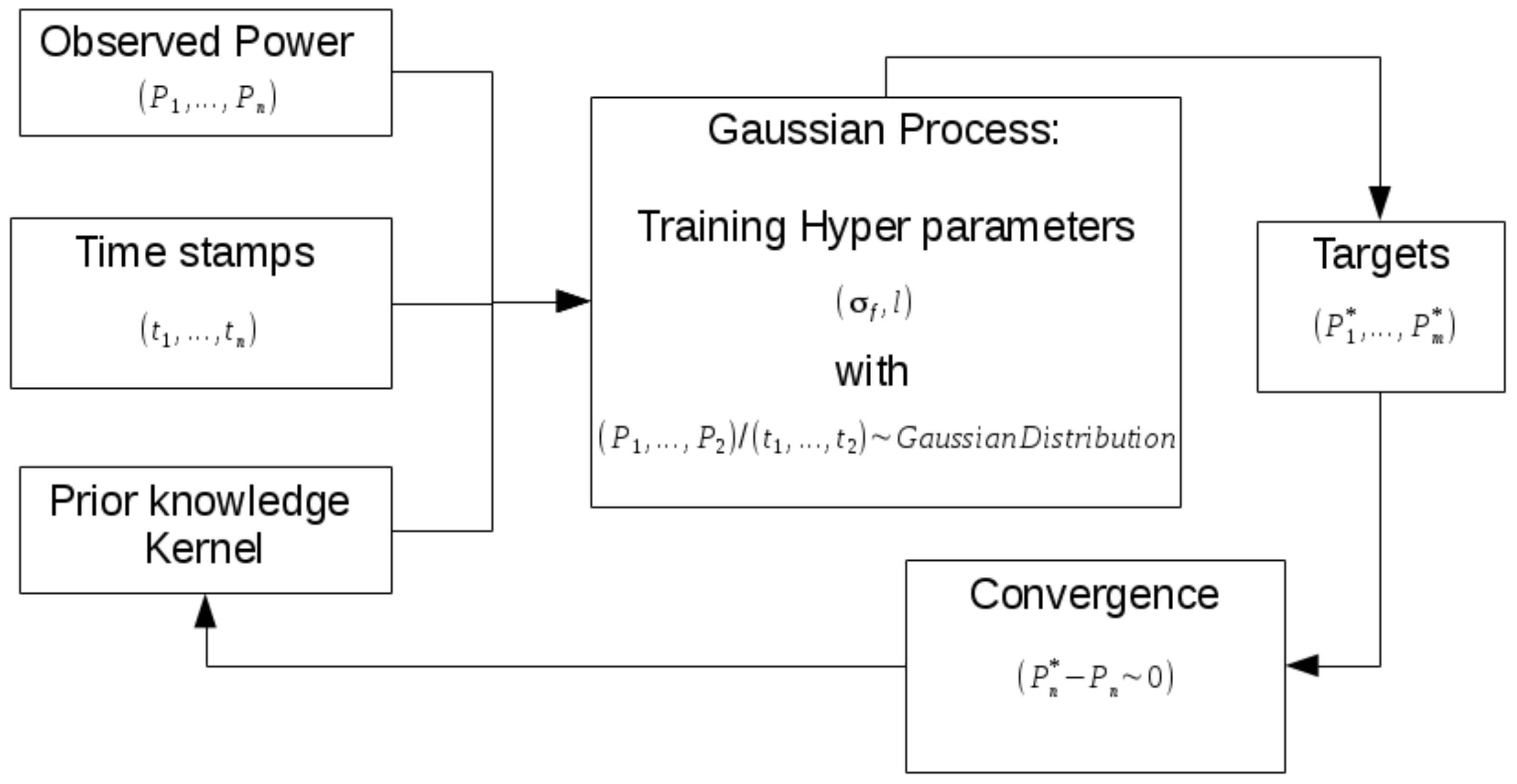
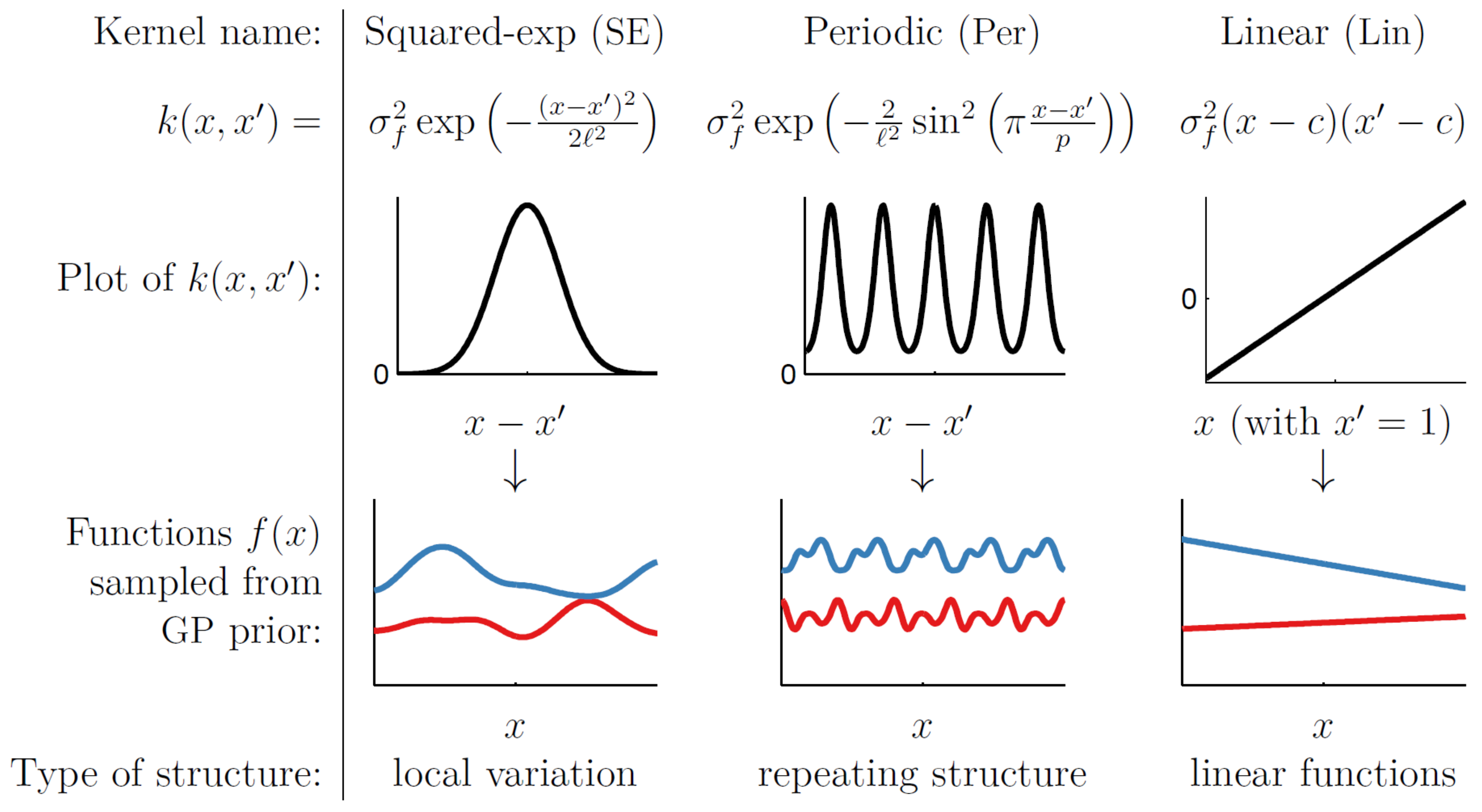
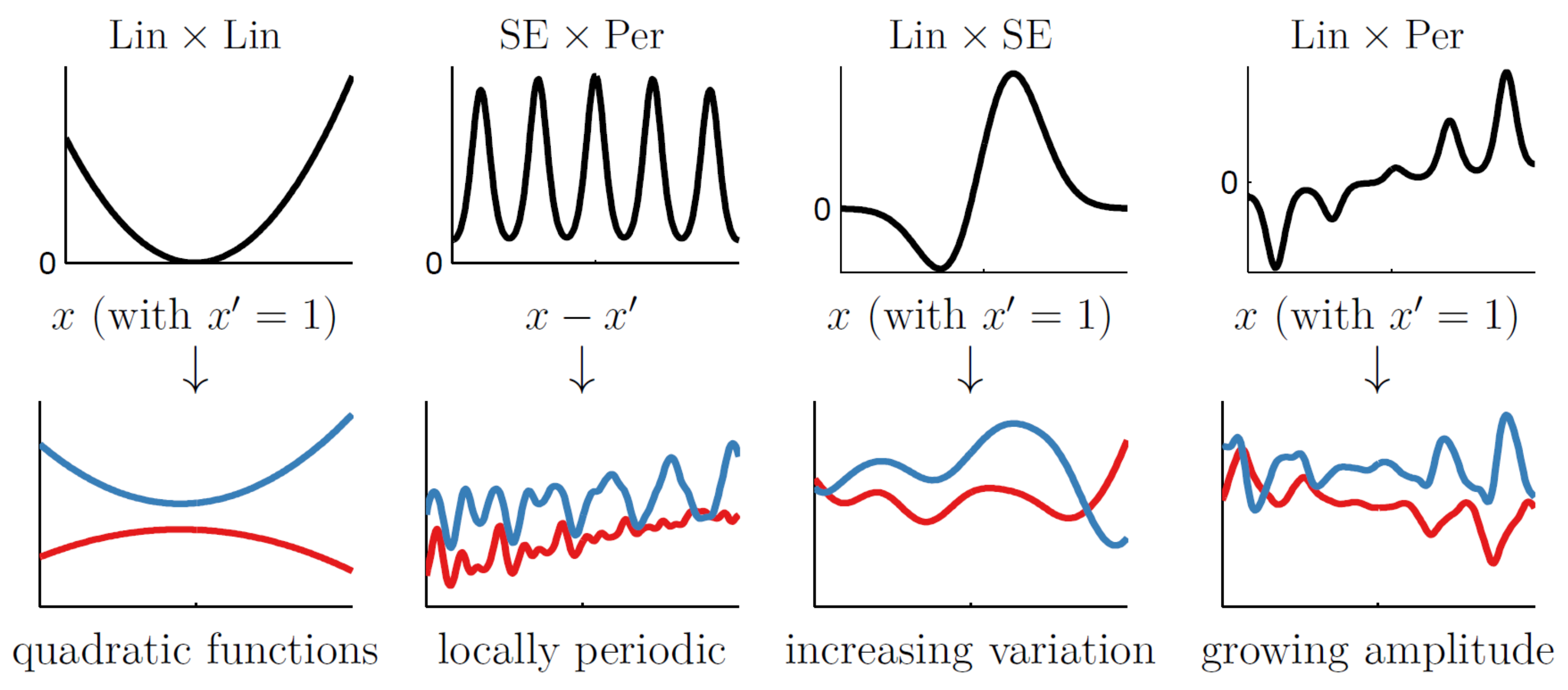
The GP is part of the Bayesian paradigm since both rely on the construction of a prior distribution. Rather than allocating a specific energy model (or function) to the data regression, the GP regresses data in a non-parametric, yet certain, way (see Rasmussen and Williams [
10], Carstens et al. [
4] and
Figure 1).
Figure 1 illustrates the structure of a typical GP algorithm for use in energy savings quantification.
GP is a supervised machine learning regime that requires the refinement of two statistical hyper-parameters: the variance (
) and step length (
l). This is done by specifying a prior (based on a carefully chosen kernel) and then refining the hyper-parameters iteratively based on a training set, in order to generate the posterior. If the kernel is chosen wisely, convergence will ensue and predictions (with well-defined uncertainty) can be made about the behaviour of the energy system and its parameters. Refer to the classical text Gaussian Processes for Machine Learning by Rasmussen and Williams [
10] for an in-depth study of Gaussian Processes.
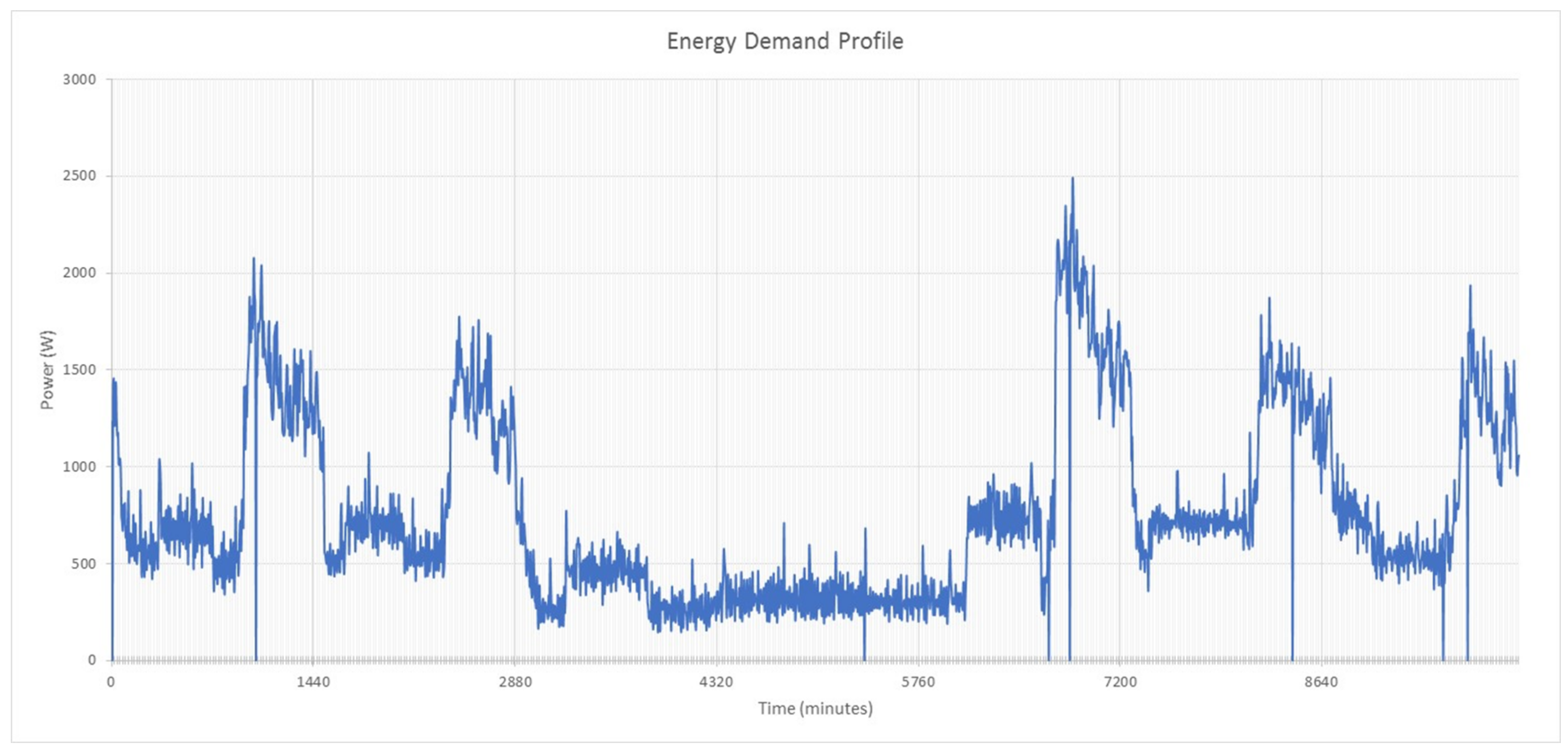
To conclude this introduction, the reader is referred to
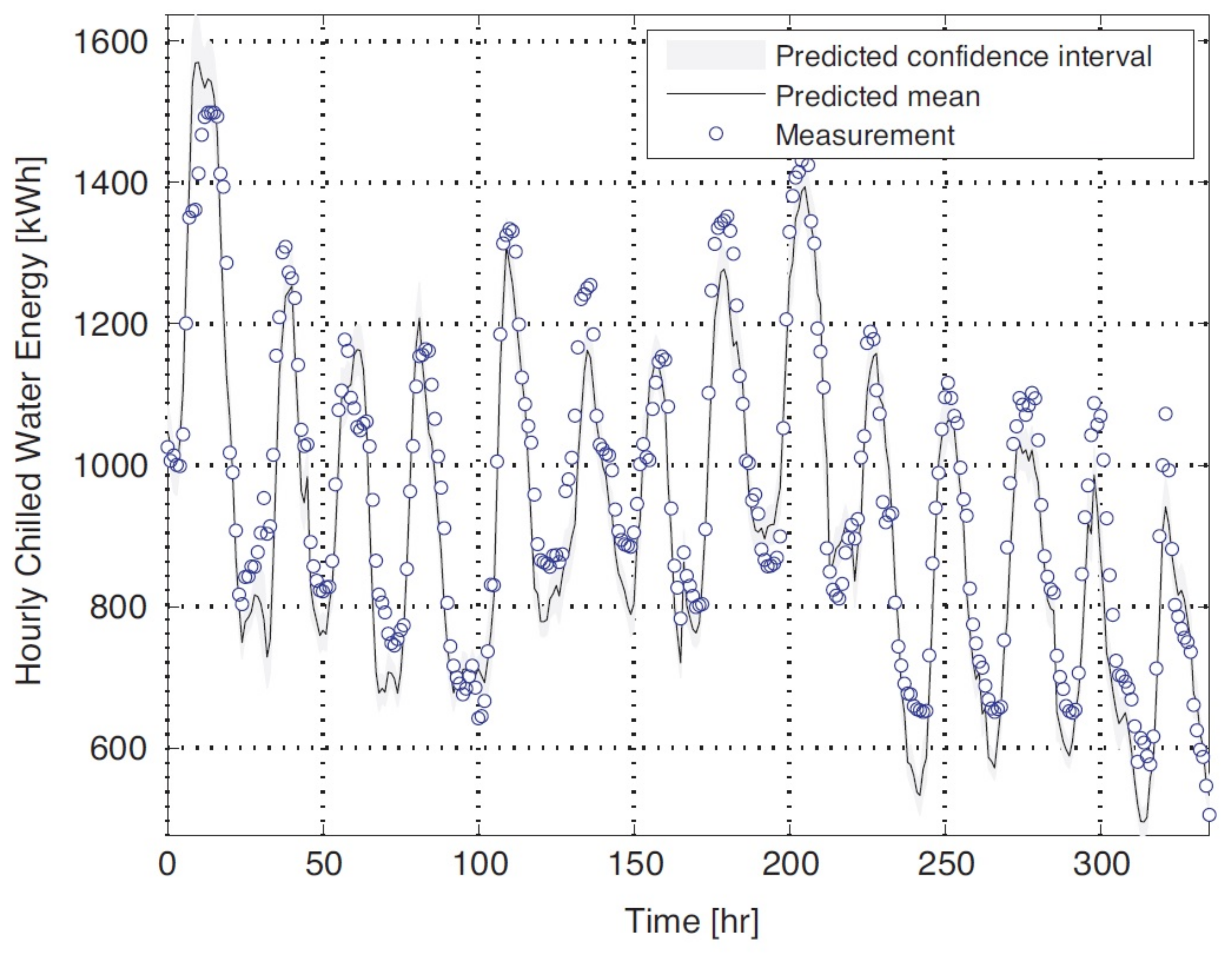
Figure 2, which illustrates a complex demand profile at an academic department for a period of one week. This academic department consists of various energy-consuming entities, such as offices, laboratories, lecture halls and kitchen facilities—all containing heating, ventilation and air conditioning (HVAC) systems. These entities are governed mostly by a human–building interaction, which automatically gives rise to periodicities in the demand profile (see
Figure 2) [
11]. Compiling an energy model to describe and predict this observed demand profile is difficult and can lead to misunderstandings and uncertainties. In this context, it would be useful to have the demand data construct its own model—to let the data ’speak for itself’. Notice also the following prominent signatures present in the demand profile (illustrated in
Figure 2):
Small, irregular variations,
Day/night variations, with energy usage peaking approximately at midday,
Low energy usage during weekends (between 2880 min and 5800 min in
Figure 2).
Because of these apparent periodicities in the energy demand profile, together with the fact that the energy model is mostly unknown, the GP is an attractive modelling tool and will be able to regress the profile trend for the purpose of investigating possible forecasting and quantification of savings. This regression capabilitiy of the GP is a powerful tool for analysing the impact of energy related retrofits. The possibility also exists that the GP will statistically highlight previously unnoticed length scales that govern the energy model.
Referring to
Figure 2, constructing the energy model that governs the observed profile can be done recursively: subtracting contributing factors (such as occupant behaviour and schedules) from the measured demand to reveal smaller and smaller model residuals until a random noise structure is achieved. However, interconnections of certain model parameters with each other and the global trend of the profile can prove difficult to find using this iterative process. What would be considered to be mere random noise could in fact be contributing energy factors. Thus, the GP provides a more holistic, more certain, method of finding the energy model that describes the system. This model is then ideal for the purpose of forecasting and saving quantification as induced by an energy management intervention or wastage anomaly.
This example serves to illustrate that GP regression can make a significant contribution within the energy M&V environment [
12]. Due to the cyclic variations, a kernel can be chosen that adheres to the day/night cycle, or daily usage patterns.
The benefits of an alternative regression model becomes evident in the example above (see
Figure 2), where the process of decomposing the demand profile to isolate primary parameters governing the system, is cumbersome and expensive. The usage patterns and governing dynamic systems are embedded in the energy model and warrant further exploration.
For further reference on the use of the GP modelling framework to determine energy savings, see Heo and Zavala [
13].
Article Layout
The article is arranged as follows:
Section 2 illustrates the usefulness of the GP regression by presenting a case study of the possible benefits that could be achieved by energy management interventions or energy wastage mitigation. In
Section 3, practical guidelines are provided for setting up the GP, with special attention given to choosing the kernel based on the available data. The accommodation of model and measurement uncertainties are also discussed. Attention is given to the particular data set used in this study. The use of performance monitoring mechanisms for GP regression is also discussed.
Section 4 outlines the experimental procedure followed to obtain the HVAC energy management case study (as presented in
Section 2). Finally,
Section 5 concludes with investigating the possibilities of applying GP analysis to demand management, incorporation of renewable energy alternatives, as well as its application to a green building index.
2. Results
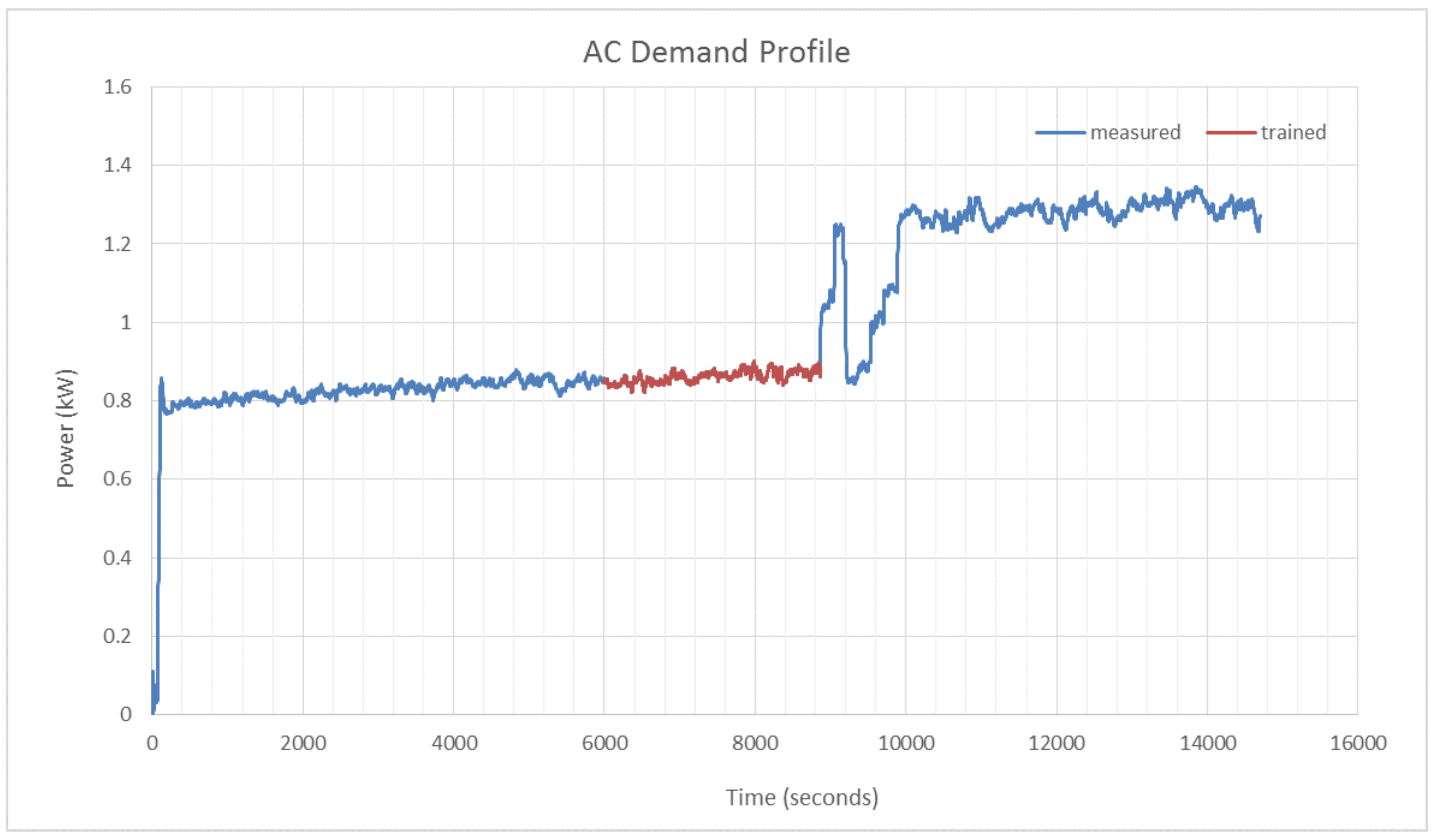
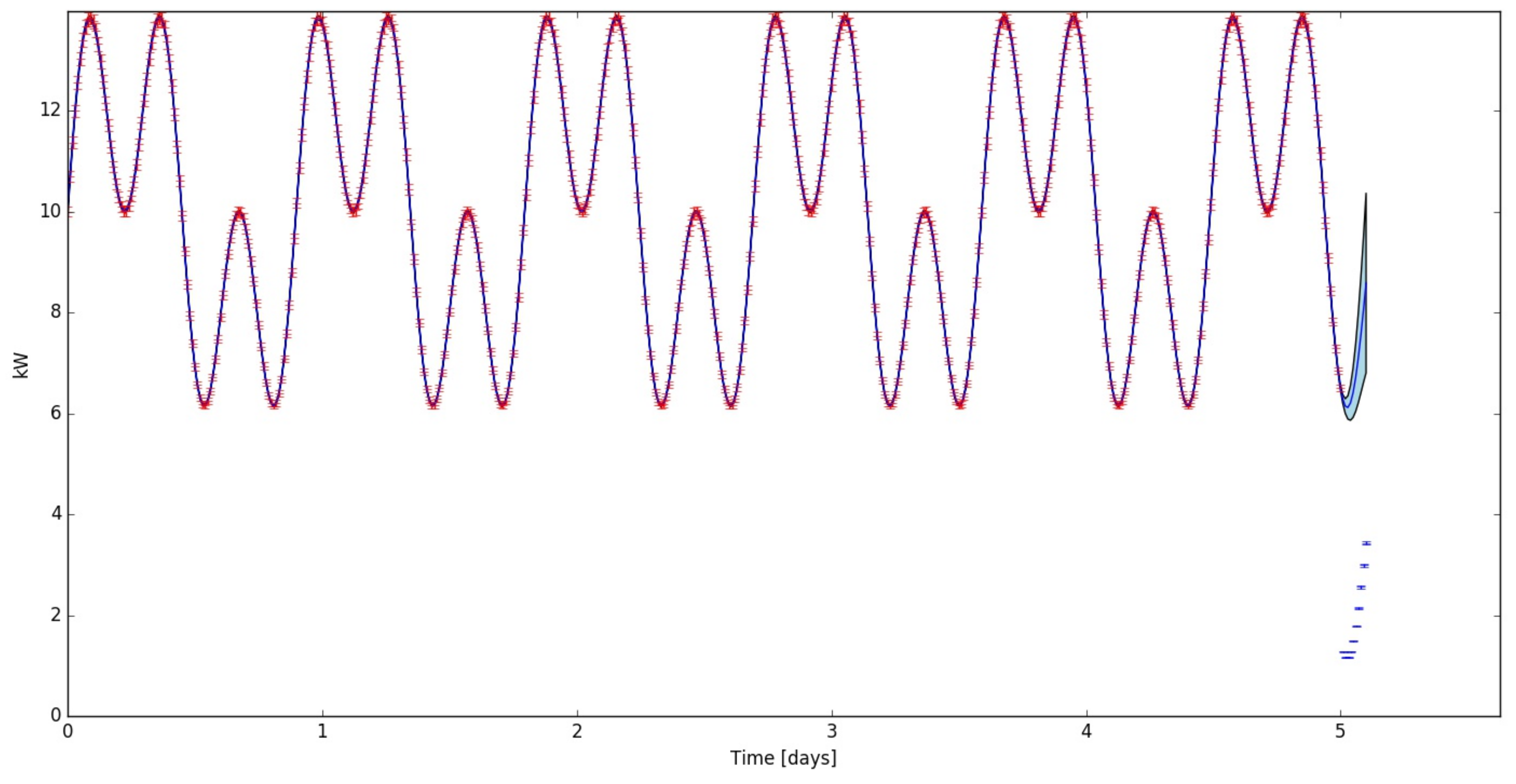
By making use of a GP regression, the energy model of an air conditioning (AC) system was inferred [
14] (see
Figure 3). A training set defined between
s and
s was used to train the hyper-parameters. After training, these optimized parameters were found to be
kW and
s. These parameter values are significant since they correspond to the mean set-point power consumption and possibly the switching time scales of the AC controller, respectively. Notice that the GP converged on hyper-parameters that can be linked directly to the physical nature of the energy system under consideration.
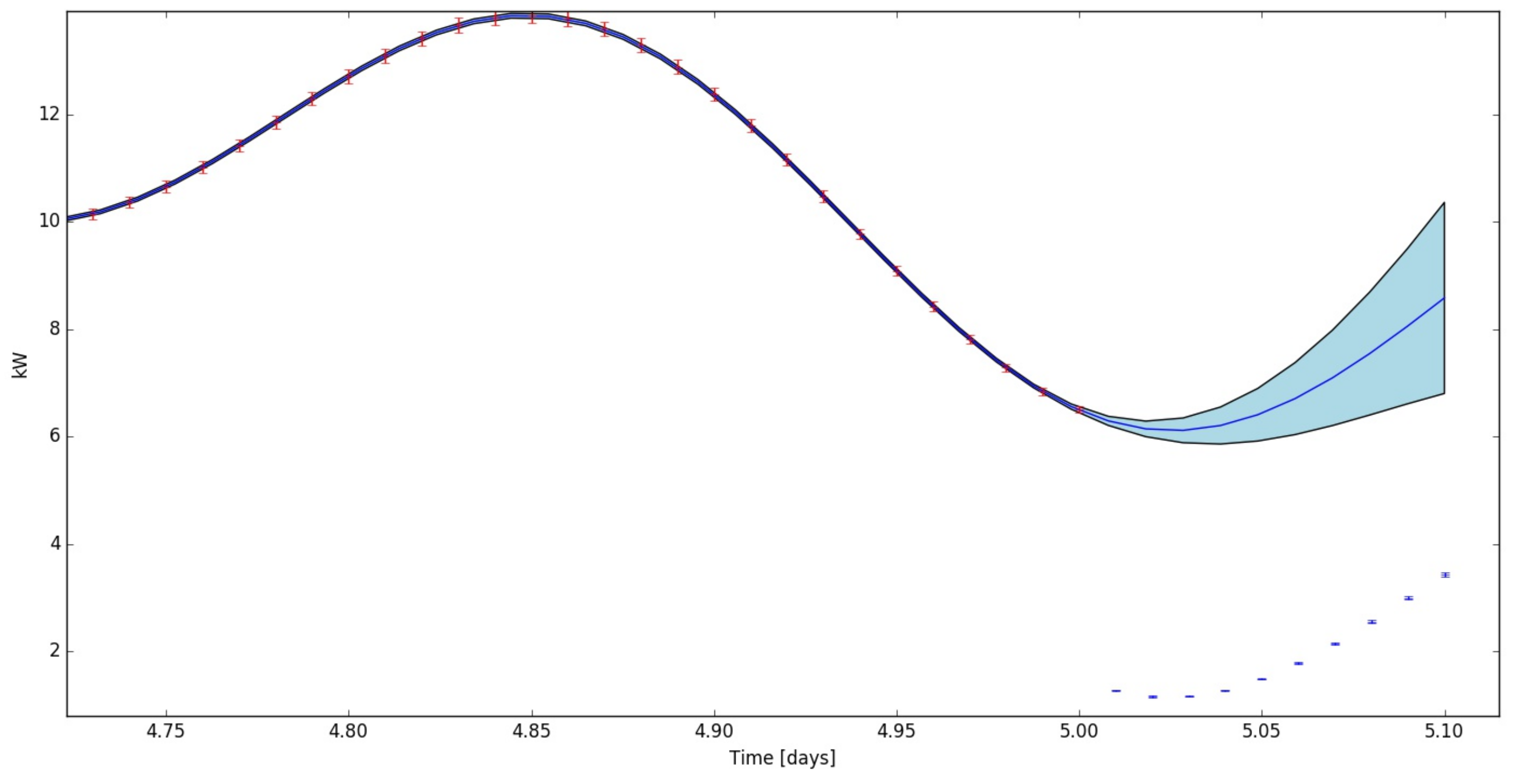
Figure 3 illustrates two distinct regions: a region of steadily increasing energy usage (from
to
s), which fluctuates slightly and periodically, and a region where the energy use rises abruptly (from
s onwards). The sudden rise in energy use is due to an opened office door that resulted in an influx of hot air. A forecast energy demand from the point of the hot air influx, therefore, will be an estimate of what the energy use would have been if the door had not been opened. This corresponds to the principle of baseline adjustment, as part of M&V. By calculating the difference between the real and predicted energy use, an estimate of the energy wastage due to the open door can be calculated (with well-defined uncertainty).
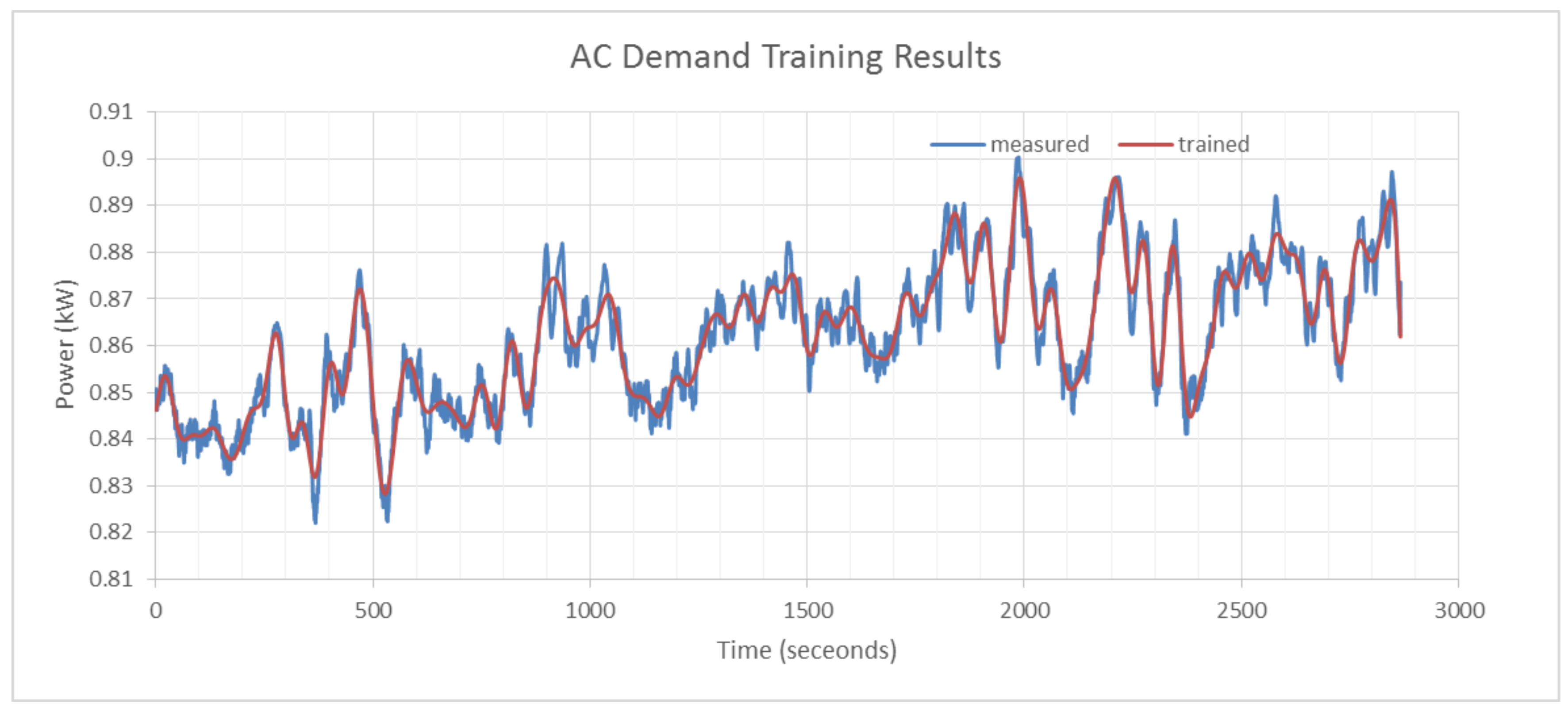
Figure 4 illustrates the training set (measured) and subsequent trained model of the AC demand profile.
Figure 4 therefore corresponds to the training section (
s to
s) in
Figure 3.
Figure 4 clearly illustrates the precision with which an energy demand profile can be trained using GP.
The quantitative forecasting of energy demand for the purposes of quantifying energy savings falls outside the scope of this specific case study and will be dealt with in detail in a forthcoming paper.
5. Conclusions
The case study presented in this paper acts as an example of Bayesian alternatives (GP regression) for standard M&V analysis. It illustrates the non-parametric regression of time series data, given measurements and initial probabilities. The applicability and usefulness of non-parametric GP regression for the proper quantification of uncertainties within the M&V realm was illustrated.
This paper can be used as a road map by energy managers and M&V professionals to give guidance in identifying the point of intervention/wastage, selecting the prior training set (before the energy intervention/wastage), and forecasting of the energy system as if no energy intervention/wastage ever occurred (also known as base-line adjustment). However, the actual forecasting and energy loss quantification are not addressed in this paper and will be analysed in future.
The process of forecasting the training set, from before the point of intervention/wastage towards the point of the energy saving query, while taking into account the propagation of uncertainty in data, allows the calculation of the savings realised by energy saving interventions. Once the forecasted energy system (based on training data without the energy interventions/wastage) is compared to actual measurements (taken after the intervention/wastage point), the actual savings can be calculated. The case study presented in this paper is intended to inspire further exploration of GP regression as a Bayesian alternative to M&V principles, specifically the process of base-line adjustment.
The predictive power of the GP regression could furthermore be applied to demand management, the analysis of ESMs, as well as the analysis of renewable alternatives in the field of green buildings and net-zero homes. Energy demand and supply forecasting, and subsequent energy management, is a powerful tool for improving the status of a building’s green building rating [
20].
The M&V principles associated with ESMs can be made more reliable, thereby improving the efficiency of tax incentives, green building rating systems and energy management campaigns. The GP regression could also be used to predict solar energy potential (supply side). Predicting the availability of renewable energy resources is critical in a holistic energy management plan. Since the GP updates its belief-system every time new data (or evidence) is added, it can easily be incorporated into real-time monitoring and management protocols.
The paradigm shift achieved by using the Bayesian approach can deliver a more robust method of energy data regression, which can include multi-dimensional data measurements for the entire system (power consumption, water usage and waste management).
The use of the GP therefore extends beyond M&V into the broader energy management sector.
Future work will include the training of a GP regression with weekly load cycles that include the features of day/night variation and weekends, by constructing the appropriate kernel. This training will be followed by the prediction of the load cycle and will demonstrate the full predictive power of GP regression by comparison to actual data.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}