Wind energy is one of the main renewable energy sources [
1,
2]. It is harvested using wind turbines and to be converted into electric power. With the increase of installed wind power capacity, more and more attention has been paid to the reduction of operation and maintenance cost. The operation and maintenance cost of wind turbines in the whole life cycle accounts for 25–30% of the total cost, e.g., Reference [
3]. Failure of critical components in wind turbine operation may cause costly repairs and increased downtime. It is, therefore, that fault diagnosis and prediction has become very important. It is expected that a fault is to be detected at an earlier stage or to be predicted before it occurs [
4]. The fault diagnosis and prediction are based on available data, including condition monitoring data usually collected through condition monitoring system (CMS), and control and operation data collected through the Supervisory Control and Data Acquisition (SCADA) system. CMS provides direct information reflecting a mechanical fault or failure, whereas SCADA system provides all other auxiliary information which assists in improving the efficiency and accuracy of the fault diagnosis and detection. SCADA system, for example, is an important subsystem in an energy management system which helps reduce the system operation and maintenance costs [
5].
Electrical and electronic control systems in wind turbines are considered to be prone to failure, but gearbox and generator failures result in the longest downtime. In general, in large wind turbines, there are three the most vulnerable subsystems identified. They are pitch system, frequency converter and yaw system [
6]. As a core component of a wind turbine, the pitch system’s failure rate is even higher than other mechanical subsystems, such as gearbox in some cases. The damage to the pitch system not only increases the operation and maintenance cost, but also reduces the production efficiency of the wind turbine [
7]. In recent years, there are a number of studies reported on fault diagnosis and prediction for wind turbine pitch system, e.g., References [
7,
8,
9,
10,
11,
12,
13,
14]. Based on literature survey, it is found that the published studies can be generally classified into two categories: One is physical model-based approach, e.g., References [
12,
13,
14,
15] and the other is based on measurement data, e.g., References [
16,
17,
18,
19,
20]. The physical model-based approach is mainly used for fault mechanism analysis, and the data-based studies are for condition assessment and prediction. Asgari [
8] uses the unknown input observer combined with the actual operating data of the 660KW wind turbine, and detects and isolates the fault of the pitch system actuator and the generator rotor temperature rise fault in the MATLAB/Simulink environment. In Reference [
9], the identification algorithm of a variable forgetting factor is introduced. Through the idea of parameter estimation, the natural frequency and damping coefficient of the variable pitch system actuator are identified and estimated, and the system fault is diagnosed by the change of parameters. Kusiak and Verma [
10] established a system prediction model that is based on data mining technology for fault diagnosis of actuator failure of wind turbine pitch system. Based on the analysis of the fault characteristics of the hydraulic pitch system, Han [
11] established the fault tree model of the hydraulic pitch system, and used the combination of quantitative and qualitative analysis to realize fault diagnosis. At present, the failure of the pitch system is mostly diagnosed for the mechanical failure of the system, and the diagnosis of the electrical failure of the pitch system needs to be further studied. In Reference [
12], a combined adaptive and parameter estimation scheme and its application to fault prediction for wind turbines is proposed, which is based on the dynamic wind turbine and pitch system model. A set of possible faults affecting system dynamics is described. In Reference [
13], a model-based variable pitch actuator fault detection method is proposed. When the pitch actuator is dynamically changed, the normalized gradient method is used to estimate the parameters of the pitch actuator and obtain the residual signal. Based on the wind farm SCADA data, Reference [
14] proposed a generalized model of wind turbine anomaly identification. The fuzzy comprehensive evaluation method is used to synthesize the results of the selected wind turbine condition parameter prediction model. Reference [
15] gave a method for diagnosing faults in the wind turbine pitch actuator that causes a change in pitch angle. The interval prediction algorithm is combined with recursive subspace recognition based on the variable forgetting factor algorithm. Reference [
16] proposes to select more important variables in the SCADA system to improve the prediction accuracy, and adopts an index based on the exponentially weighted moving average model to eliminate the autocorrelation in the data. In Reference [
17], an adaptive neural fuzzy inference system based on prior knowledge (APK-ANFIS) is proposed to analyze wind turbine SCADA data to realize automatic detection of significant pitch faults. An 85.50% classification accuracy was achieved in Reference [
18] through 14 human-readable rules generated by the RIPPER induction rule learner. Of these rules, 11 were described as “useful and intuitive” by independent domain experts, and further, expert systems were developed using the model and domain knowledge. In Reference [
19], for the slip ring pollution and the pitch controller failure, a novel pitch fault detection method based on performance curve (PC) normal behavior model (NBMs) is proposed. The power-generator speed (P-N) and pitch angle-generator speed (PA-N) curves were selected to establish NBMs, and behavioral curves were used to analyze behavioral differences for fault prediction. A model-based fault detection and isolation scheme for wind turbine variable pitch systems is presented in Reference [
20] to detect faults in electric pitch actuators and sensors, where an Extended Kalman Filter (EKF) based multi-model adaptive estimation (MMAE) is designed to estimate the state of the system. In Reference [
21], a designed algorithm based on the H2 norm optimization technique is proposed to detect blade and pitch system faults, and to repair false positive rate and detection speed as needed. In Reference [
22], the fault diagnosis method of an innovative stochastic gradient algorithm based on the observer is proposed for the characteristics of wind turbine variable pitch system failure, which causes system parameters to change. The use of similar functions combined with Kohonen neural network for fault diagnosis is discussed in Reference [
23] where the fuzzy clustering based on Kohonen neural network is used to solve the problem, and the optimized samples are used as input to the Kohonen network to obtain various types of standard fault models.

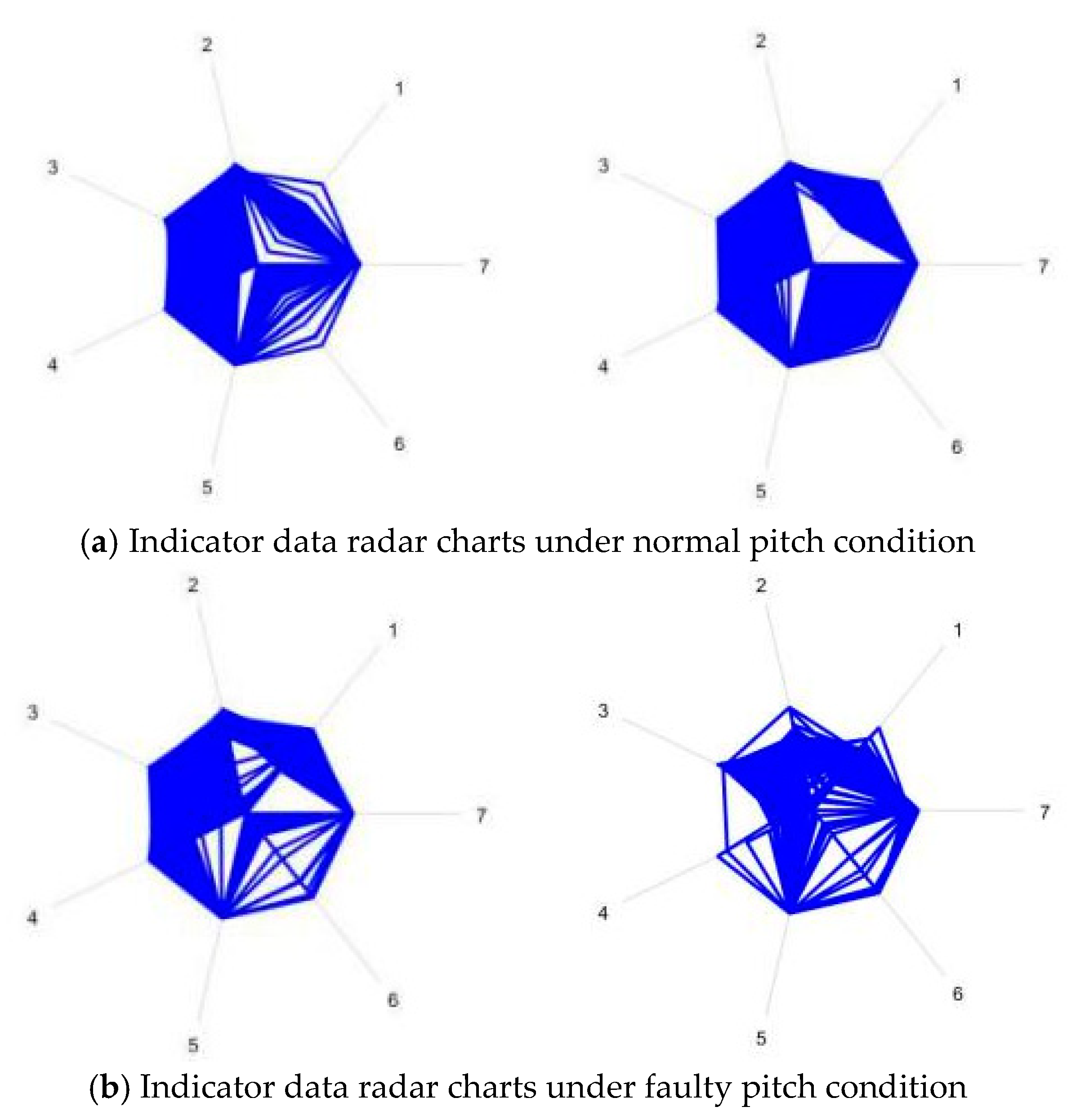








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}