1. Introduction
Doubtless, safe operation of the pitch system is a key to ensure power stability and reliable braking of wind turbines [
1]. The dynamic turbulence or unsteadiness gusts not only provide power for the pitch system, but also produces the most stress or dynamic loading on the blades [
2]. Historically, pitch system faults are largely caused by dynamic loading situations due to uncertainty in the wind resource intensity and duration [
3,
4]. Such situations have frequently led to tragic accidents, as well as casualties and asset losses. The pitch system, therefore, has to frequently change blade angles and adjust blade speed to avoid being destroyed [
5]. It is worth mentioning that a wind turbine has four working states: start-up, wind speed regulation, power regulation, and cut-out. The level of the wind speed is the decision-maker for state transitions, which leads to the coordinated action of the pitch system. When the wind speed varies over a wide range, the state switches and the pitch system will have an increased ability to ensure the safety of the turbine. Conversely, when the wind speed fluctuates within a small range, the state is locked, and the pitch system also performs small movements frequently to capture the maximum wind energy. Whether it is a large movement or a small one, the pitch movement often lags behind the wind speed [
6]. Once a failure occurs, it is difficult to find it timely and accurately. The existing Supervisory Control and Data Acquisition (SCADA) system can send an alarm after the faults, but it has no intelligent monitoring function to provide an early warning and accurate location information before the fault. The current way relies on operators to detect abnormal situations and make corrective decisions based on enough safety intelligence.
Generally, fault monitoring approaches are divided into model-based methods and data-driven methods. The model-based methods use explicit system dynamic models and control theories to generate residuals for fault monitoring. Alternatively, the data-driven methods use data mining techniques to capture discrepancies between observed data and that predicted by a model. Such discrepancies will reflect whether the machine is in normal or failure mode, which requires a classifier to judge. Recently, some Artificial Intelligent (AI) classifiers, such as neural networks [
7,
8,
9,
10,
11,
12], machine learning methods [
13,
14,
15], and deep learning methods [
16,
17], have been widely applied in classifying the incipient faults of wind turbines. These methods are really very effective for some faults within a certain working state, but it seems impossible for them to diagnose other faults under other working states. Considering actual demand, it is necessary to establish a systematic fault monitoring system that covers multiple dynamic working states. Moreover, a targeted analysis of what types of faults will occur in different states is critical to build the monitoring system.
Fortunately, an ensemble learning technique is a better method in solving the above problems and Boosting and Bagging are two common approaches of ensemble learning. Boosting [
18] is a cascade training method that uses the same data to train the ensemble members one-by-one. It requires a strong dependency from a series of ensemble members. Specifically, if the former members are not well trained, the latter members will be affected and show bad performance. Moreover, Boosting is easy to be interrupted during training when there is a small interference, leading to the overall failure of the training [
19]. Bagging is a separate training approach [
20] that requires multiple single ensemble members to perform the same task [
21,
22]. Using this training mode, the ensemble members are homogeneous or heterogeneous, and their alternative algorithms, such as support vector machine (SVM), artificial neural networks (ANN) and naive Bayes [
23], should be as simple and effective as possible. More importantly, the final result of the ensemble learning is a comprehensive decision output which is obtained by fusing the results of the multiple ensemble members based on a certain combination method [
24]. The use of an ensemble learning technique in monitoring pitch failures is still rare, however. Pashazadeh fused Multi-Layer Perceptron (MLP), Radial Basis Function (RBF), Decision Tree (DT), and K-Nearest Neighbor (KNN) classifiers can be used together to detect early faults in wind turbines [
25]. Dey compared three cascade fault diagnosis schemes to address the issue of fault detection and isolation for wind turbines [
26]. Concluded from the above-limited applications, the ensemble learning technique is indeed an efficient strategy to identify failures and improve classification performance. Additionally, the neural networks are often used as the alternative algorithms of the ensemble members, because the neural network is a “universal approximator” and has better capabilities in processing multidimensional nonlinear data [
27,
28,
29].
To achieve the higher fault diagnosis performance, the ensemble learning should have three basic principles. First, there must be enough data to train the ensemble members. The training data in this paper are recorded from a wind farm SCADA system for one year, and the Bootstrap sampling method is used to create samples by varying the data to solve the shortage problems in some data. Second, ensemble members should have different classification characteristics, which are not only diverse but also complementary. The small world neural networks (SWNN) [
30] are suitable to be the ensemble members because they are semi-random neural networks and easily can achieve excellent performance [
9,
31]. The probability
p is used to describe the degree of random reconnection of the SWNN’s structures. Most noteworthy is that the SWNNs randomly can produce diverse networks with different structures when probability
p is a deterministic value. Additionally, the SWNNs are rather easy to be trained by forwarding propagation and error feedback when using the same initial values. Third, a wise ensemble strategy also is required, depending on the types of ensemble members [
32]. Usually, for the ensemble members based on neural networks, the ensemble strategies use voting, weighted voting or meta-learning methods to obtain the final ensemble outputs [
33]. An advantage is the ensemble members are independent and irrelevant, which is helpful to improve the classification efficiency and accuracy.
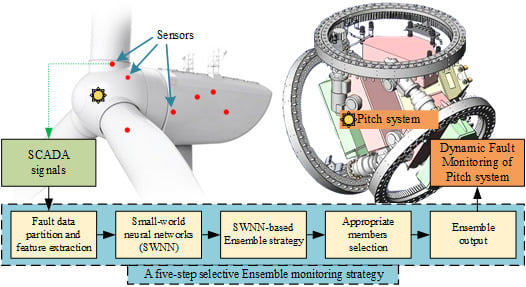
Consequently, a five-step selective ensemble strategy for dynamic fault monitoring of a pitch system is proposed. Taking the first step, the fault-causing data are partitioned according to the working states of the wind turbines, the Correlation Information Entropy (CIE) method is used to select correlation signals from the SCADA system and 10 indicators are designed to extract features of the partitioned data. Multiple SWNNs are established as ensemble members in the second step. During the third step, the features are randomly sampled to train the ensemble members. Regarding the fourth step, an improved global correlation method is used to select appropriate ensemble members. The selected members are fused to obtain a final result based on weighted integration approach in the fifth step. The final result is called the ensemble output. Considering testing and validation purposes, two case comparisons are used to verify the effectiveness of the proposed ensemble strategy.
The remaining Sections are organized as follows:
Section 2 gives the fault analysis of the pitch system under different working states;
Section 3 describes the novel selective-ensemble monitoring strategy and the entire process of its five steps;
Section 4 and
Section 5 give comparison examples to demonstrate the effectiveness of the proposed ensemble model. Finally,
Section 6 concludes this paper.
3. Selective Ensemble Monitoring Strategy Based on Small-World Neural Networks
A novel ensemble monitoring strategy is proposed to diagnose pitch faults by using multi-dimensional SCADA data. Such a strategy is a distributed diagnostic system, which takes four working states of the wind turbines as four parallel models. Each parallel model is a five-step selective ensemble model of SWNNs, in which the five steps are data partition, SWNN members’ creation, SWNN training, ensemble members’ selection, and ensemble output, respectively. It is noteworthy that, in the first step, the original SCADA data are divided into four sub-datasets according to the four working states of the wind turbine. To facilitate the description of the next steps, the architecture in the 2nd working state is selected as an example to display the proposed ensemble strategy, which is shown in
Figure 3.
3.1. Data Partition
Data processing is the decisive step in ensuring that the ensemble strategy can achieve excellent results.
Section 3.1.1 shows the original SCADA data is first partitioned into four subsets based on the four working states, respectively.
Section 3.1.2 explains how a Correlation Information Entropy (CIE) method is used to select correlation signals that are related to the faults from the multi-dimensional SCADA signals.
Section 3.1.3 discusses 10 indicators which are designed to extract fault-causing features and normal features from the correlation signals.
3.1.1. Data Classification Based on the Dynamic Working States
To establish the distributed diagnostic system, the original SCADA signals are divided into four groups based on the four working states of wind turbines.
Figure 4 gives the process of the data classification, where the wind speed is the decision-maker for state transitions. The labels of 1st, 2nd, 3rd and 4th represent the four working states respectively, and
C(
v) is the division criterion which is calculated by Equation (1). The divided signals are used for further data processing and feature extraction, because it avoids confusion with other irrelevant data, especially at the beginning of data processing.
where,
v(
t) is the current wind speed, and
C(
v) is the division criterion.
3.1.2. Correlation Signals Selection under Dynamic Working States Based on CIE
Following the data partition, there are still many signals remaining and, as mentioned at the end of
Section 2, not all of these signals are associated with the faults in a certain working state. It is necessary, therefore, to find the correlation signals related to the faults from the multi-dimensional SCADA signals. The Correlation Information Entropy (CIE) method is used to complete the above task.
CIE is an effective feature reduction approach. It can accurately measure the correlation between multiple signals on the basis of the high reliability with low calculations. Suppose that
P is the SCADA output sequences of
N signals within
T time. Prior to computing, each signal should be centralized and normalized to ensure that all values are in the same order of magnitude. The centralized and normalized values are obtained by Equations (2) and (3), respectively.
P can be expressed as Equation (4):
where,
P is the SCADA output sequences of the
nth signal,
yn(
t) is the output value of the
nth signal at time
t (
t = 1, 2, 3,…,
T).
R is a matrix of real numbers.
Subsequently, the correlation matrix
Q is generated by
P. It contains the correlation information between
N signals, which can be expanded as Equation (5):
where,
PT is the transposition matrix of
P.
qij (
qij ∈ [0, 1],
i ≠
j,
i = 1, 2,…,
n,
j = 1, 2,…,
n) donates the correlation degree of the
ith signal to the
jth signal. The 1 in the principal diagonal of
Q represents the self-correlation coefficient of the signals.
I is the autocorrelation matrix, and
is the co-correlation matrix that implies the overlap information of all signals.
The above correlation information in the
Q is the correlation degree between any two signals. Next, calculate the contribution of one signal to all signals. The
,
and
denote the eigenvalues of
Q,
I and
, respectively. The
CIE is defined as Equation (6), and its range is between [0, 1]. It is worth noting that the larger the correlation degree between signals, the smaller the corresponding
CIE.
To find the appropriate SCADA signals related to the pitch system, the following example lists 15 initial signals in
Table 2 and uses CIE to calculate the correlation of all the signals. Additionally, the 15 initial signals are all captured from different working states and each one contains 2000 samples of normal data.
Figure 5 shows the
CIE results of the 15 signals for different working states:
Viewing
Figure 5, select the signals with their
CIEs below 0.3 as the appropriate signals in different working states. The 1st and 4th working states have no appropriate signals because the pitch system is not working and is not associated with the monitoring signals. Found in the 2nd and 3rd working states, 7 signals and 8 signals are selected as the appropriate signals respectively, where the signal numbers are 2, 3, 4, 5, 7, 8, 12 and 5, 6, 7, 9, 10, 11, 12, 15. Form these selected signals into two sets of
X2 = {2, 3, 4, 5, 7, 8, 12} and
X3 = {5, 6, 7, 9, 10, 11, 12, 15}, in which
X2 and
X3 represent the 2nd and 3rd working states, respectively. Note that the 2nd and 3rd working states will continue to be studied in the following work, while the 1st and 4th working states are beyond the scope of this paper.
3.1.3. Discretized Fault Feature Extraction
Extracting fault features from the appropriate signals mainly is to find the changing characteristics from the time series. Specifically, it is the process of using discrete values to describe a limited sequence. A sliding window is used to intercept data from the appropriate signals. The abscissa of the window is a certain period of time, and the ordinate is the value of the signal. The intercepted data is called a “run”. Each run should have a label, which is a normal label or a fault label. Moreover, 10 kinds of time-domain indicators (TDIs) are designed to calculate the features of the run. The 10 TDIs are independent but closely related, which are shown in
Table 3. Actually, the runs with normal labels are the vast majority, and the runs with fault labels are the minority. This imbalanced distribution is undoubtedly counterproductive to further classification. A combination method combining over-sampling and under-sampling [
33] is used in this case to expand the number of fault runs.
According to the correlation signals selection in
Section 3.1.2, the signals of
X2 = {2, 3, 4, 5, 7, 8, 12} and
X3 = {5, 6, 7, 9, 10, 11, 12, 15} are selected as the appropriate signals for future diagnosing of the pitch failures. Taking the 2nd working state as an example, the process of discretizing feature extraction for the seven signals in
X2 is described as follows:
- (1)
Define a new dataset
Xt, including the
X2 = {2, 3, 4, 5, 7, 8, 12} and the label set of
yn(
Fi).
where,
t is the sampling size;
n is the
nth signal, which is shown in
Table 2.
xn(
t) represents the
tth value in the
nth signal.
yn(
Fi) is the label information,
Fi is the fault types which are shown in
Table 1.
- (2)
Calculate the features of the signals based on the 10 TDIs separately, then combine the features to obtain a simplified discrete data matrix of Xn(II), which is defined as Equation (9).
- (3)
Repeating the above two steps, the feature matrix of the 3rd working state can be calculated simultaneously. The discrete data matrix
Xn(III) is described in Equation (10).
Considering Xn(II) and Xn(III), n represents the nth signal in X2 and X3, respectively. The row vector represents the feature vector of the nth signal, including 10 TDI values and a label value. The column vector represents all correlation signals information for the 2nd and 3rd states. Specifically, there are 70 TDIs and 7 label values in the 2nd working state, 80 TDIs and 8 label values in the 3rd working state. These TDIs and label values will be used to train SWNNs.
3.2. SWNN Members Creation
Generally, if the ensemble members are accurate and diverse, the ensemble model will be more accurate than any of its individual members [
28], however, for neural network ensemble members, one drawback is that the initial situations almost determine the effect of the network. Such situations include initial parameters, training data, topology, and the learning process. Fortunately, SWNNs have been optimized in these initial situations and are well suited to be the ensemble members.
The SWNN is a middle ground neural network between regularity and disorder networks [
9,
35]. The probability
p (0 <
p <1) is used to probe the intermediate region. When
p = 0 or
p = 1, the SWNN are completely regular or completely random. While
p increases from 0 to 1, the SWNN becomes increasingly disordered and all connections between neurons are rewired randomly. Additionally, once the number of input, output and hidden layer neurons of the network are determined, there will be a definite value of
p to enable the whole network to achieve the highest clustering with the shortest characteristic path length. Quite the opposite, the SWNN also can randomly reconstruct diverse networks with different structures under the same value of probability
p. Compared with the traditional neural networks, the SWNN easily can obtain various network structures by modifying
p values rather than setting a large number of initial values or changing the number of neurons or layers.
The SWNN’s structure, topology and the detailed training formulas are based on the existing study [
9].
Figure 6 shows the example SWNN structure of the ensemble model in the 2nd working state, where the red thick lines are the rewiring edge, and the dashed lines are the rewired edges. The detailed parameters of the SWNN will be set in
Section 4.
When constructing the SWNN ensemble members for the 2nd working state, the number of input neurons is 70, which matches 70 TDIs in Equation (9). Three hidden layers are selected with 70 hidden neurons in each layer, and the activation function is a Logistic function. The number of output neurons is 10, representing 10 kinds of fault labels in Equation (9). Similarly, when constructing the SWNN ensemble members for the 3rd working state, the number of input hidden neurons are 80 to correspond the 80 TDIs in Equation (10). The training process of the SWNN will now be introduced.
3.3. SWNN Training
The SWNN ensemble members will be trained using different datasets. SWNN is a multi-layer forward neural network, which is trained by leaping forward-propagation and backward-propagation. Equation (11) shows the weight matrix of the SWNN, where the values on the diagonal line represent the weights of the regular network, while those not on the diagonal line represent the weights of random reconnection. The reconnection weights will determine the way of propagation, where Equation (11) gives the matrix space:
During the forward-propagation stage, suppose that
P samples are given to the input layer of the SWNN, and the network outputs are obtained based on the weight vector
W. The purpose is to minimize the error function
Etotal that is defined as:
where,
Ys is the actual output and
Vs is a desired one.
During the back-propagation stage, the gradient descent method is used to obtain the optimal solutions. The direction and magnitude change
can be computed as:
Each SWNN is trained by different datasets for training the ensemble members. Such datasets will be explained in the Experimental validation section. The above two stages are executed during each iteration of the back-propagation algorithm until Etotal converges.
3.4. Selecting Appropriate Ensemble Members
Following training, each individual SWNN member has generated its own result, however, if there are a great number of individual members, a subset of representatives to improve ensemble efficiency needs to be selected. Existing research has proven that the selective ensemble technique can discern
many members from
all to achieve better classification accuracy [
29]. An improved global correlation based on the Pearson Correlation Coefficient is proposed to select the appropriate SWNN members.
Suppose that there are
n ensemble members (
f1,
f2,…,
fn), and each member has
p forecast values. Then the total error matrix
Etotal can be represented by Equation (14):
where,
p = 10 represents the fault types in
Table 1.
epn is the
pth classification error of the
nth ensemble member.
According to the
Etotal, the mean
and the covariance
Vij are described by Equations (15) and (16), respectively.
where,
i and
j (
i,
j = 1, 2,…,
n) represent the
ith ensemble member
fi and the
jth ensemble member
fj.
Then, the correlation matrix
R can be calculated by Equation (17):
where,
rij is the correlation coefficient that describes the degree of correlation between
fi and
fj.
Vii and
Vjj are the variances of the two members, which comes from the autocorrelation coefficient
rii = 1 and
rjj = 1 (
i,
j = 1, 2,…,
n).
Further extended to calculate the global correlation, let
ρfi denote the correlation between
fi and (
f1,
f2,…,
fi-1,
fi+1,…,
fn).
R is a symmetric matrix whose expansion is shown in Equation (18):
Subsequently, the correlation matrix
R is represented by a block matrix as shown in Equation (19):
where,
R−i denotes the correlation matrix of lacking member
fi, and the transformation of
R is shown in
Figure 7:
Then, the plural-correlation coefficient can be calculated by Equation (20):
Regarding a pre-specified threshold
θ, if
, the member
fi is removed from the member group, otherwise, the member
fi is retained. The procedure is shown in
Figure 8. Additionally, the retained members can be re-selected by repeating the process until more satisfied members are obtained.
3.5. Integrating the Multiple Members into an Ensemble Output
During the previous steps, several appropriate ensemble members of SWNN have been selected. Regarding the subsequent task, a final decision value is obtained by combining the results of the selected members based on the weighted integration method.
Suppose that there are
m members retained, the outputs of the members could construct a column vector
fi according to the fault types in
Table 1.
fi can be represented as Equation (21):
where,
i = 1, 2,…,
m stands for the
ith ensemble member.
(
k = 1, 2,…,
p) is the predictive probability of the
kth output neurons in the
ith member, whose ranges is in [0, 1]. All the outputs, therefore, can be constructed by a matrix
f:
Take out the row vectors from
f and one-by-one and calculate the weight values of each row. Then, the calculated weight values are reconstructed into a row vector of
. Expand each
wk and construct a weight matrix
w with
k rows. The above processes are shown in Equations (23) and (24).
Combine the
w and
f to calculate the ensemble outputs of
F with the results obtained by Equations (25) and (26).
where,
(
k = 1, 2,…,
p) is the integrated probability of the
kth classification, whose ranges also are in [0, 1]. Set a threshold
σ = 0.5. When
, let
. When
, let
.
To summarize, the multistage reliability-based SWNN ensemble model can be concluded in the following steps:
- (1)
Pretreat the original SCADA data and extract its features to construct n training datasets, TR1, TR2,…, TRn.
- (2)
Train n SWNNs ensemble members with n training datasets.
- (3)
Select m appropriate members based on a weighted integration method.
- (4)
Fuse multiple SWNN members’ outputs into an aggregated value.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}