A Process to Implement an Artificial Neural Network and Association Rules Techniques to Improve Asset Performance and Energy Efficiency



Abstract
:1. Introduction
Problem Description
- The assets can perform in very diverse operating conditions (sometimes also diverse environmental conditions) over time;
- Assets’ condition is not feasible to be monitored, or simply doing it becomes a complex technical problem with a very troublesome and economically non-viable solution. This difficulty many times related to the asset specific functional location;
- Altogether could cause a lack of assets performance control and subsequent loss of expected performance efficiency.
2. Rational for the ANN and DM Techniques Selection
2.1. State of the Art: ANNs Applications in AM
2.2. State of the Art: AR Mining Applications in AM
3. Brief Background of the ANN-DM Techniques Selected
4. ANN-DM Combination Process and Sample Problem
4.1. Sample Problem Description
- A unique design allowing the pump to be installed inside the tank in a vertical column to remove the possibility of major tank leakage due to a pipe or connection problem.
- The pump and motor units are submerged, and the column acts as a guide to seat the pump during installation and performs as the discharge pipe from the pump.
- The plant information system shows operating conditions of the pump to detect any potential problem.
- The pump has very different possible operating conditions (resulting of very different tank levels, flow, pressure, LNG density, operating hours of the pump, etc.).
- It is very troublesome to establish a clear judgement about potential pump malfunctioning. Besides this, condition monitoring capabilities are limited to previously mention operating variables (for instance, no items vibration, bearing temperatures, motor temperatures are received).
- To generate a process and tool for the prediction of anomalies in the operation of the pumps with complex operation and supervision regime.
- To establish the guidelines for the practical implementation of the models and methodology.
- To generate enough information to prepare a Business Case for the company to implement the process if there is a demonstrated payback to the business.
- Some other secondary or complementary objectives were:
- To identify the operating regimes of the equipment so that anomalies are recorded.
- To obtain the loss of performance of the equipment when producing the anomalies detected.
4.2. Imput Data Processing Module
- (1)
- Asset case study definition: The first step of the procedure (IDEFØ1.1) is to choose the asset case study from organization asset portfolio (I1.1) so that it can be representative to extend the results to other similar equipment or systems of the plant. For the equipment selection, the organization must have good and consistent data for operation and maintenance history (C1.1) that allows obtaining the model of the same with success. In this step, it is convenient to collect all the technical information of the equipment (C1.3), referring to the maintenance and operation recommendations by the manufacturer. Each operation variable that is extracted from the control system of the equipment will have to be standardized based on the design standards. Additionally, another restriction to consider is the operational context, to understand how the equipment works in their environment and how they can be affected by external conditions and different modes of operation (C1.2). Singular case studies and the obtaining of a single model for single equipment can be given, or alternatively, the option of a sufficiently flexible model to be able to extend to similar equipment, and in this way, take advantage of the work and the dedicated effort. In many cases, the operational context may be completely different, because of location, altitude, external agents and other operational parameters that accelerate ageing and variation of performance. So, it is advisable to choose equipment that do not have the same operational context to obtain better accuracy in obtaining the model. The final decision to select the asset case study is approved by O&M Manager “R2”, based on the above comments. The following table shows all available variables and the origin of them (Table 1):
- (2)
- Selection of variables: Once the case study equipment has been chosen and the operational context described, as indicated in the previous paragraphs, the next step (IDEFØ 1.2) is to select the variables that are used for modeling and studying the behavior by ANN and association rules. All the variables must be part of the historical operation and maintenance, and to comply with the following requirements:
- Data must be consistent and without significant temporal breaks in the series.
- The frequency at which the information is extracted from different sources of information must be enough to capture the changes of state in each of the variables.
- The variables must be independent of each other, if some dependencies between variables are detected, those dependent variables for which less information is available will be discarded.
- At least one or more variable must be of operation (for example, flow, pressure, electric consumption, power consumed, speed, etc.).
- The other variables must be linked to the equipment condition, such as vibration, bearing temperature, etc. In addition, some variable must be related to the operational context and environment, such as outside temperature, required load, operation mode, etc.
- (3)
- Period selection and data recording frequency: Once the variables have been selected, it is necessary to define the period in which the study will be carried out (IDEFØ 1.3). It is advisable to choose a period in which all possible scenarios have been registered, for example, that the system has operated in all different operating modes, overhauls, corrective maintenance, etc. Likewise, in addition to selecting the period, it is also necessary to select the interval of data recording of the different information sources. As mentioned in step 2, this period must allow us to capture with enough detail, the change of state in the variables for its interpretation and study, with the objective of training the network faithfully and being able to identify anomalies in the behavior of the equipment (C1.4). At this point, it is convenient to carry out a study between the efforts required to obtain the data and the subsequent results for a model with a high level of precision. For a shorter sampling interval, higher levels of accuracy in the prediction of the model are obtained (for example, data/minute vs data/hours). In Table 3, the periods selected for the case study are shown. It is divided into three periods; the passage from one period to another is marked by an overhaul (OH) maintenance activity. The data recording frequency has been every calendar hour.
- (4)
- Data validation and processing: This step involves the validation and processing of the information (IDEFØ 1.4). This is one of the most important steps and usually the one that consumes more resources in the application of the methodology. Usually, there are errors in the information that must be reviewed and above all, the unification of the information from the different information sources in the same selected period. The importance of this step is essential to achieve results that are as close as possible to reality. Another measure to consider at this point is the revision of the consistency of the database, filtering the noise and erroneous information generated by the instrumentation installed in the assets. For this, it is necessary to use data validation tools “R1”, representations by dispersion diagrams, etc. Once the data has been normalized, the next step is the implementation in the artificial neural network to obtain the ideal model of system behavior. The model obtained, together with the real-time reading of the variables, can be compared with the real behavior of the system, so that in an ideal case, the deviation from the expected behavior can be detected.
- (5)
- Data normalization: Normalization is applied as part of data preparation for machine learning (IDEFØ 1.5). The goal of normalization is to change the values of different variables in the dataset to a common scale, without distorting differences in the ranges of values. For machine learning, every dataset does not require normalization. It is required only when features have different ranges. Each variable is normalized between 0 and 1, making use of the technical information collected in the first step of the procedure. For example, if a variable is by design limited between 250 and 700 m3/h, the values that are outside the range are not considered for the study, but the values within the range will be normalized between 0 for values close to 250 m3/h and 1 for values close to 700 m3/h. In the following table, the maximum (Vmax) and minimum (Vmin) values for each of the variables selected for the case study are shown in Table 4.
4.3. Prediction Model Module
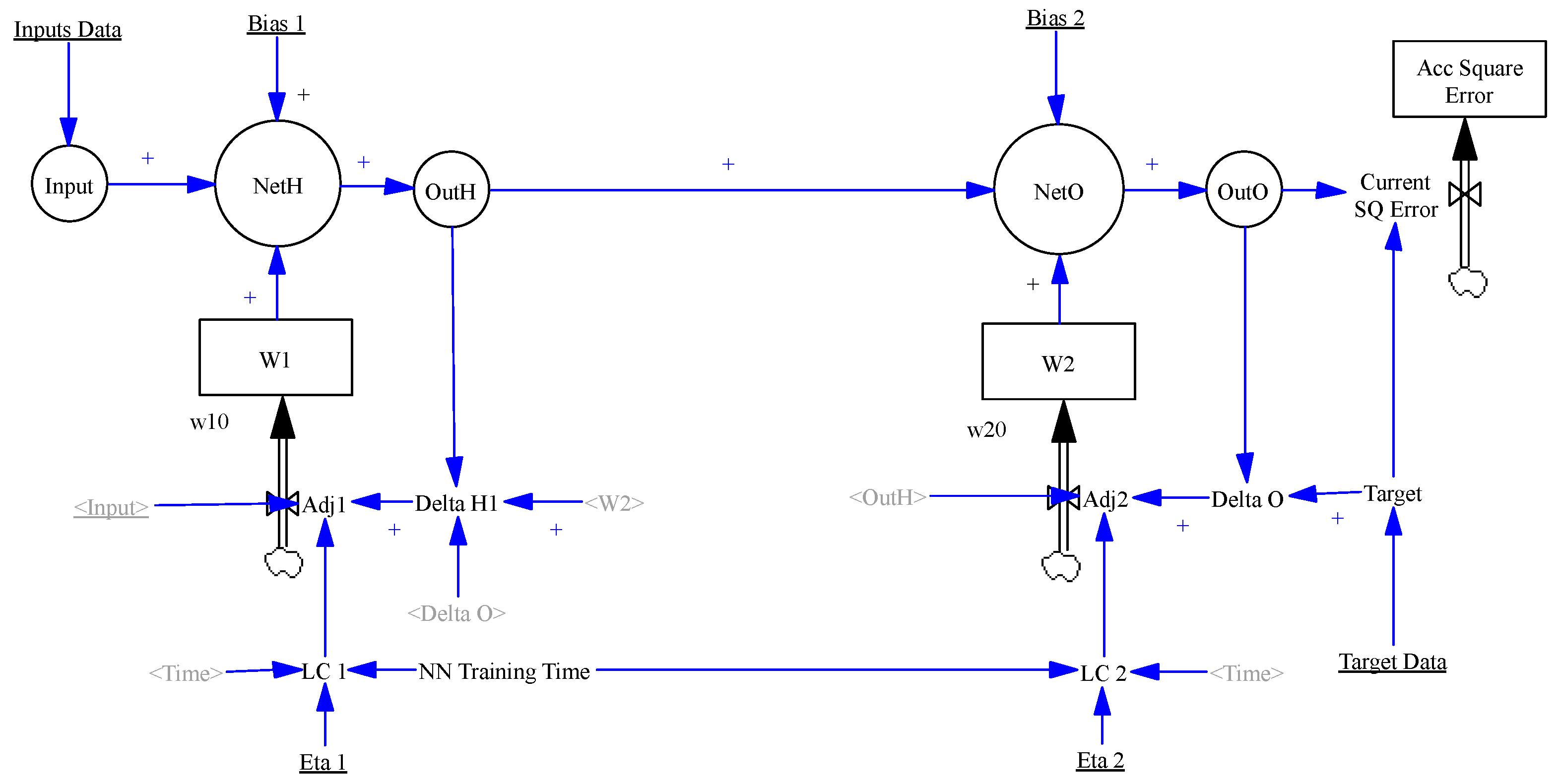
- The ANN structure (number of neurons per layer) can be easily changed by modifying the number of elements of the different subscripts, which correspond to the number of neurons of the network (in our initial model we have considered only one hidden layer and 20 neurons).
- The network has two bias parameter (hidden layer [Bias 1] and output layer [Bias 2]) and two learning coefficients or rates (hidden layer [LC 1 = Eta 1 during training time] and output layer [LC 2 = Eta 2 during training time]).
- Input Data (in our example values of flow, temperatures, tank levels, densities, and operating hours, to predict a pump energy consumption) and target data (values of energy consumption) are imported from plant information systems, to be uploaded automatically to Vensim (O2 in Figure 4). Input data goes to first layer neurons, while target data will be compared with the values predicted by the ANN output.
- ANN Training time is introduced as a parameter, once this time is reached in the simulation, the LC1 and LC2 are set to zero, and the learning process finished since the adjustments flows of the weights will be stopped.
| Min ∑t Current SQ Error t | with t = 1 … Final Simulation Time |
| −1 ≤ w10(i,j) ≤ 1 | with i = 1 … n inputs, j = 1 … m neurons in the HL |
| −1 ≤ w20(j) ≤ 1 | with j = 1 … m neurons in the HL |
| 0 < Eta 1 ≤ 1 | For the leaning coefficient of the HL |
| 0 < Eta 2 ≤ 1 | For the leaning coefficient of the Output Layer |
| BMin < Bias 1 ≤ BMax | with BMin y BMax to be selected (for instance −10, 10) |
| BMin < Bias 2 ≤ BMax | with BMin y BMax to be selected (for instance −10, 10) |
- Three layers
- Seven neurons in the input layer
- Twenty neurons in the hidden layer (previously tested between 5, 10, 15, 20 and 25)
- One output neuron
- (1)
- Connection with standard data in Excel provided by Plant Info Systems;
- (2)
- Training interval definition (first 70% of valid data points in Table 3, Period 1, in chronological order);
- (3)
- Basic tests of operation and validation of the ANN Model;
- (4)
- Optimization of ANN algorithm values optimizing a total of 164 parameters:
- Initial weight values w1 (i, j), i = 7, j = 20; 140 parameters
- Initial weight values w2 (j), j = 20; 20 parameters
- Parameters Bias 1 and Bias 2; 2 parameters
- Learning Coefficient Eta 1 and Eta 2; 2 parameters
- (5)
- Simulation with the backpropagation algorithm to find the final values for:
- Weight values w1 (i, j), i = 7, j = 20; 140 parameters
- Weight values w2 (j), j = 20; 20 parameters
- (6)
- The testing (30% remaining of valid data points in Table 3, Period 1, in chronological order) and calculation of the quadratic error of prediction;
- (7)
- The prediction error trend study.
- (1)
- Direct search techniques using the modified Powell method applied for the optimization of initial values of weights, biases and learning rate coefficients (in IDEFØ 2.1. in Figure 4).
- (2)
- Backpropagation algorithm for the optimization of the weights during the ANN training period (IDEFØ 2.2. in Figure 3), when we use initial values of weights, biases and learning rate coefficients optimized in IDEFØ 2.1.
4.4. Output Data Analysis and Control Module
- (1)
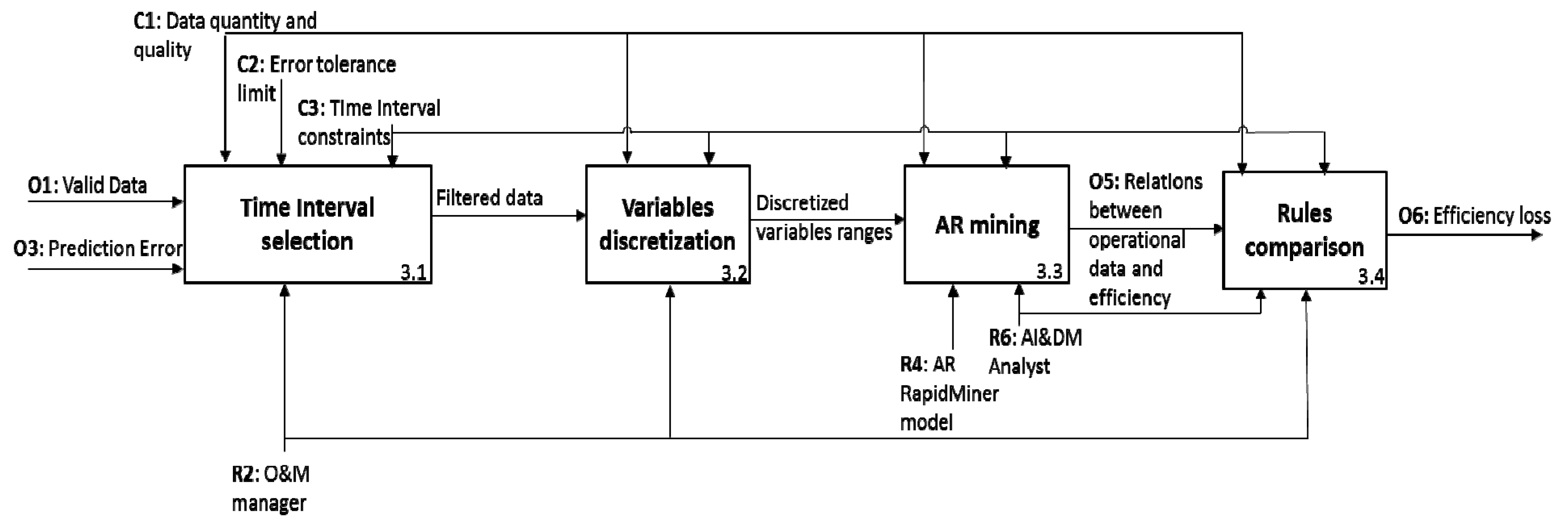
- Time interval selection (IDEFØ 3.1): in order to check for any possible performance loss, we may want to compare situations belonging to different time intervals (C3), such as the efficiency before and after an overhaul or a failure of the equipment. For instance, we could select all the available data to develop as complete as possible analysis or select a symmetric time window, e.g., 1000 working hours before and after an overhaul.
- (2)
- In our application, according to the O&M manager (R2), we decided to consider the whole dataset, in order not to lose any information on the asset performance and to study only the filtered data relevant for the aim of the Data Mining step. Specifically, we split the dataset into 3 periods (Table 7): the first one, starts from the beginning of the system monitoring and lasts until the preventive Overhaul. The entire period would be composed of 13,772 working hours, but due to missing data and low quality ones, only 3223 can be considered in this study. The second time window, instead, ranges from the Overhaul to the catastrophic failure of the system (4856 of the 5173 working hours can be analyzed). After the failure of the asset, only 92 working hours are recorded, of whom 49 can be studied.
- (3)
- Variable selection and discretization (IDEFØ 3.2): depending on the depth of the analysis, we could filter some of the valid data determined in the first step, or limit the study to a certain number of variables. In addition, if the selected variables are measured through continuous values, a discretization is necessary since the AR mining algorithm applies to discrete elements. In our application, the variables selected are pressure, flow-rate, impulsion temperature, aspiration temperature, tank level, and density; all of them are related to the efficiency of the system.
- (4)
- The discretization process is performed in accordance with the O&M manager (R2). Indeed, a tradeoff is needed in this step: on the one hand, in fact, the discretization ranges have to be small enough to represent a specific operating condition. On the other hand, instead, we wish to have the greatest interval size, so that the system frequently operates inside it. In other words, if the intervals are too small, the system could work inside each of them very rarely and, consequently, we may not profit from the data. In the next table (Table 8) we report the minimum and maximum values of the valid data and the size chosen for each interval.
- (5)
- AR mining (IDEFØ 3.3): the discretized variables ranges represent the input of AR mining stage; quality of the results depends on data quality and availability (C1) and the temporal constraints considered (C3). The resources necessary to deploy the data mining procedure are O&M manager (R2) and the AI&DM analyst (R6), together with AR RapidMiner model (R4). According to the methodology explained in Section 3, we have to analyze the rules having values of the efficiency as head (Δ), and values of all the other selected variables as body (Γ). Each AR is associated with a support and a confidence: the former represents the percentage of time units over the total in which the operating conditions and the efficiency have assumed the values expressed by the rule. The latter, instead, indicates the probability of having the efficiency expressed by the rule, given the values of the operating variables. For example, in Table 9, some of the rules extracted (O5) are reported. Column 1 to 6 (Flow rate, LNG Density, Tank level, Pressure, Intake Temperature, Impulsion Temperature) contain the body of the rule, while the seventh is the head (Efficiency); column 8 and 9, instead, respectively report the support and the confidence associated with each rule. The rules exemplified in Table 3, should be interpreted as follows (let’s consider, for instance, the first row): when the operating conditions of the system are characterized by a flow rate included in the range 478–508 m3/h, a density between 450 and 455 kg/m3, the tank level between 5900 and 6900 mm, the pressure inside the tank is between 10.5 and 11.5 kgf/cm3, the aspiration temperature (TAsp) is included in −159 °C and −158 °C and the impulsion temperature (TImp) is in −158 °C and −159 °C, in the 75% of the cases (confidence = 0.75), the efficiency of the system ranges between 59 and 60%; in the remaining 25% of the cases (see the second row of the table), instead, the efficiency range is 60–61%. The support associated with the former relation is 0.0006: this value indicates the probability of having the operating conditions values listed before and an efficiency level in 59–60%. Similarly, the rule associating the operating conditions values and the efficiency between 60–61% have a joint probability of occurrence, namely a support, of 0.0002.
- (6)
- Rules comparison (IDEFØ 3.4): The relations among the operating conditions and the efficiency (O5) mined in the previous step should be compared in order to verify the actual existence of an efficiency loss (O6) and the corresponding probabilities. To this end, we need to select rules presenting analogue values of the operating conditions but belonging to different time intervals, i.e., those identified in the first step of this stage. This activity has to be carried out both by the O&M manager (R2) and the DM&AI analyst (R6). In our study, three different time intervals have been selected and compared, as shown in Table 3. The highest number of comparable conditions characterizes TI 1 and TI 2: specifically, 58 common operating conditions have been identified in which the system under investigation works both before and after the overhaul (i.e., the milestone dividing TI 1 from TI 2). As shown in the following table (Table 10), in almost the totality of the rules there is a loss of efficiency. Comparing the remaining time intervals, there are less coincident operating conditions. In general, the efficiency of the TI3 is higher than the one of TI 2 and greater-equal than the one of TI 1.
4.5. Decision Support Module
5. Implementation Process Results for the Pump Example
- Concerning the prediction of anomalies in the operation of equipment with complex operation regime and poor monitoring of their condition through ANN AI-AR DM models:It was agreed that it is possible to model the behaviour of the pumps and detect anomalies in their operation by deviations from the prediction. For instance, it could be appreciated how a pump that suffered a catastrophic failure after its first overhaul, worked with anomalous behaviour throughout its second period of operation before the failure. Error accumulation was predicting this abnormal behaviour. Another clear appreciation was the punctual accumulations of error detected when the asset was reaching certain operating regimes.
- Concerning the guidelines for the practical implementation of the models in business systems:It was agreed that the systems are currently registering enough data to proceed with the implementation of this type of tools, and that it would be much more convenient to have all variables in a digital format and integrated the same information system, where the ANN algorithm is finally implemented. The implementation of the algorithm can be done by asset, for greater precision, without a significant increase in costs.
- Concerning the possibility to obtain information to build a business case:It was agreed that the integrated ANN-DM tool could avoid premature deterioration of equipment, verify the quality of its major maintenance intervention, ensure its operation at maximum energy efficiency, improve alarms and current interlocks for the operation of equipment, generate a new technical services to offer to potential clients, provide thoroughly understanding of the behaviour of pumps throughout their life cycle, adjust the periods of completion of major maintenance and estimate the health of the asset better (comparing with current available techniques).
- Concerning the identification and measurement of the asset´s loss of performance when anomalies are detected:It was agreed that the analysis of performance in similar operating regimes could be done properly. For instance, the measurement of the performance loss of the pump with the catastrophic failure, after its first overhaul could be done showing that the pump always operated with 4% to 6% lower performance. After the second overhaul, after the catastrophic failure, the pump recovered perfectly the initial performance.
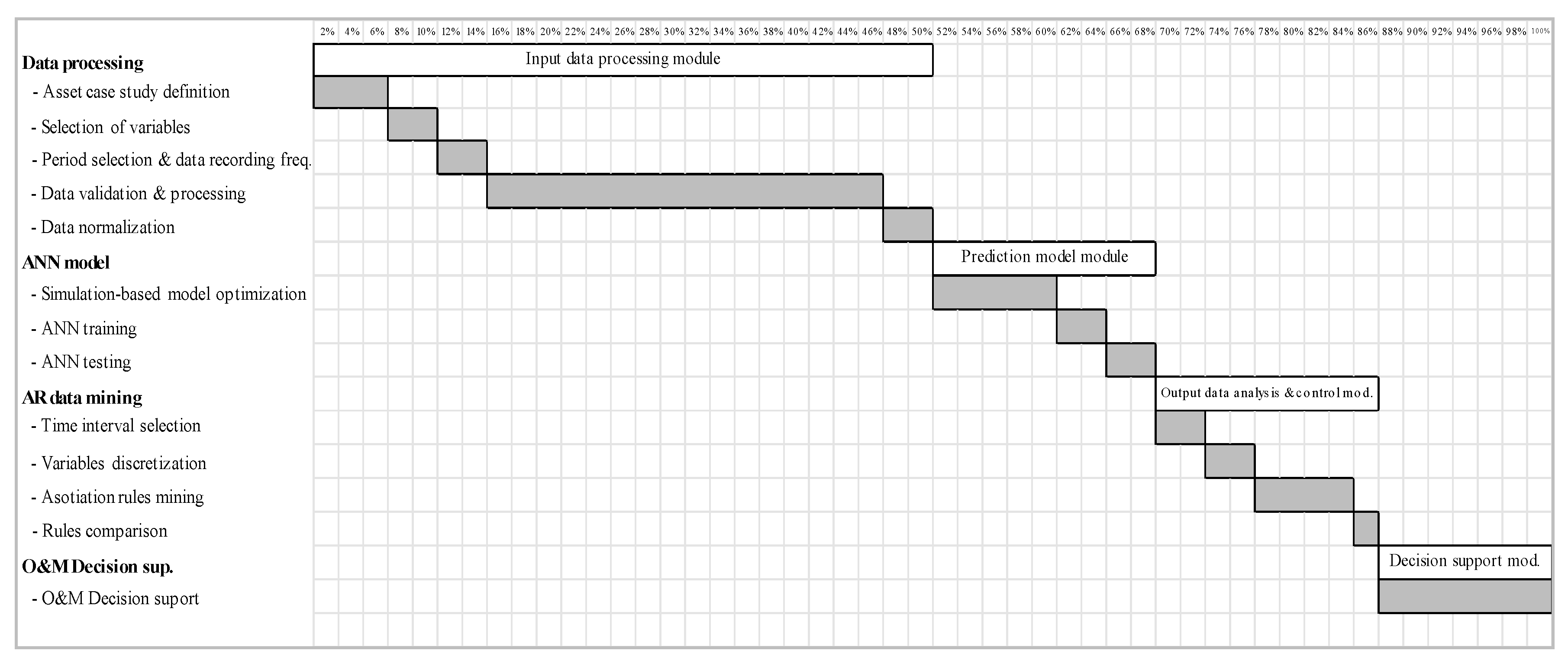
- The input data processing time resulted to be a 50% of the total project time in this initial implementation, as a result of the dispersion, different formats and quality of the data processed. The total time when replicating the study to a similar asset was reduced by 30%. Mainly impacting the input data processing module (20% time reduction), and the same impact in the next two modules (5% time reduction each).
- Time for data processing resulted longer than for prediction and data analysis modules together. This was shocking to the team involved in the project, even if the processing it is in line with the one indicated by the Cross Industry Standard Process for Data Mining (CRISP-DM), that consider it to be around the 70% of the total processing time [81]. The use of the AI-DM tools for the problem analysis was expected to be more time consuming than the data processing according to the complexity of the tools that were going to be used. However, two intermediate processes were really efficient and less dependent on circumstances out of the team control.
6. Conclusions and New Research Opportunities
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Borek, A.; Parlikad, A.K.; Woodall, P.; Tomasella, M. A risk based model for quantifying the impact of information quality. Comput. Ind. 2014, 65, 354–366. [Google Scholar] [CrossRef] [Green Version]
- Ouertani, Z.; Kumar, A.; McFarlane, D. Towards an Approach to Select an Asset Information Management Strategy. IJCSA 2008, 5, 25–44. [Google Scholar]
- Woodall, P.; Borek, A.; Parlikad, A.K. Data quality assessment: The Hybrid Approach. Inf. Manag. 2013, 50, 369–382. [Google Scholar] [CrossRef]
- Moore, W.J.; Starr, A.G. An intelligent maintenance system for continuous cost-based prioritisation of maintenance activities. Comput. Ind. 2006, 57, 595–606. [Google Scholar] [CrossRef] [Green Version]
- Kans, M.; Ingwald, A. Common database for cost-effective improvement of maintenance performance. Int. J. Prod. Econ. 2008, 113, 734–747. [Google Scholar] [CrossRef]
- Ashton, K. That ‘Internet of Things’ Thing. RFiD J. 2009, 22, 97–114. [Google Scholar]
- Atzori, L.; Iera, A.; Morabito, G. The Internet of Things: A survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Sarma, S.; Brock, D.; Ashton, K. The Networked Physical World; TR MIT-AUTOID-WH-001; MIT: Cambridge, MA, USA, 2000. [Google Scholar]
- Monostori, L.; Kádár, B.; Bauernhansl, T.; Kondoh, S.; Kumara, S.; Reinhart, G.; Sauer, O.; Schuh, G.; Sihn, W.; Ueda, K. Cyber-physical systems in manufacturing. CIRP Ann. 2016, 65, 621–641. [Google Scholar] [CrossRef]
- Davis, J.; Edgar, T.; Porter, J.; Bernaden, J.; Sarli, M. Smart manufacturing, manufacturing intelligence and demand-dynamic performance. Comput. Chem. Eng. 2012, 47, 145–156. [Google Scholar] [CrossRef]
- Lee, J.; Kao, H.A.; Yang, S. Service innovation and smart analytics for Industry 4.0 and big data environment. Procedia CIRP 2014, 16, 3–8. [Google Scholar] [CrossRef]
- Fayyad, U.M.; Irani, K.B. Multi-Interval Discretization of Continuous-Valued Attributes for Classification Learning. In Proceedings of the 13th International Joint Conference on Artificial Intelligence 1022–1027, Chambery, France, 28 August–3 September 1993. [Google Scholar]
- Diamantini, C.; Potena, D.; Storti, E. A virtual mart for knowledge discovery in databases. Inf. Syst. Front. 2013, 15, 447–463. [Google Scholar] [CrossRef]
- Shahbaz, M.; Srinivas, M.; Harding, J.A.; Turner, M. Product design and manufacturing process improvement using association rules. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2006, 220, 243–254. [Google Scholar] [CrossRef]
- Seng, N.Y.; Srinivasan, R. Data Mining for the Chemical Process Industry. In Encyclopedia of Data Warehousing and Mining, 2nd ed.; IGI Global: Hershey, PA, USA, 2009; pp. 458–464. [Google Scholar]
- Negri, E.; Fumagalli, L.; Macchi, M. A Review of the Roles of Digital Twin in CPS-Based Production Systems. Procedia Manuf. 2017, 11, 939–948. [Google Scholar] [CrossRef]
- European Committee for Standadization. EN13306: 2017, Maintenance Terminology; European Committee for Standadization: Brussels, Belgium, 2017. [Google Scholar]
- Niu, G.; Yang, B.S.; Pecht, M. Development of an optimized condition-based maintenance system by data fusion and reliability-centered maintenance. Reliab. Eng. Syst. Saf. 2010, 95, 786–796. [Google Scholar] [CrossRef]
- International Organization for Standardization. ISO 17359:2018—Condition Monitoring and Diagnostics of Machines—General Guidelines; International Organization for Standardization: Geneva, Switzerland, 2018. [Google Scholar]
- United States Army. ADS-79D-HDBK—Aeronautical Design Standard Handbook for Condition Based Maintenance Systems for US Army Aircraft; U.S. Army Aviation and Missile Research, Development and Engineering Center: Redstone Arsenal, AL, USA, 2013. [Google Scholar]
- Parra, C.; Crespo, A. Maintenance Engineering and Reliability for Assets Management; Ingeman: Seville, Spain, 2012. [Google Scholar]
- Jardine, A.; Lin, D.; Banjevic, D. A review on machinery diagnostics and prognostics implementing condition based maintenance. Mech. Syst. Signal Process. 2006, 20, 1483–1510. [Google Scholar] [CrossRef]
- Campos, J. Development in the application of ICT in condition monitoring and maintenance. Comput. Ind. 2009, 69, 1–20. [Google Scholar] [CrossRef]
- Lee, J.; Ghaffari, M.; Elmeligy, S. Self-maintenance and engineering immune systems: Towards smarter machines and manufacturing systems. Annu. Rev. Control 2011, 35, 111–122. [Google Scholar] [CrossRef]
- Vachtsevanos, G.; Lewis, F.; Roemer, M.; Hess, A.; Wu, B. Intelligent Fault Diagnosis and Prognosis for Engineering Systems; John Wiley and Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Zio, E. Review reliabilty engineering: old problems and new challenges. Reliab. Eng. Syst. Saf. 2009, 94, 125–141. [Google Scholar] [CrossRef]
- Willis, H.L. Power Distribution Planning Reference Book; CRC Press: Boca Raton, FL, USA, 2004. [Google Scholar]
- González-Prida, V.; Guillén, A.; Gómez, J.; Crespo, A.; De la Fuente, A. An Approach to Quantify Value Provided by an Engineered Asset According to the ISO 5500x Series of Standards. In Asset Intelligence through Integration and Interoperability and Contemporary Vibration Engineering Technologies; Springer: Cham, Switzerland, 2019; pp. 189–196. [Google Scholar]
- Basheer, I.A.; Hajmeer, M. Artificial neural networks: Fundamentals, computing, design, and application. J. Microbiol. Methods 2000, 43, 3–31. [Google Scholar] [CrossRef]
- Zhang, G.; Patuwo, B.E.; Hu, M.Y. Forecasting with artificial neural networks: The state of the art. Int. J. Forecast. 1998, 14, 35–62. [Google Scholar] [CrossRef]
- Curry, B.; Morgan, P.; Beynon, M. Neural networks and flexible approximations. IMA J. Manag. Math. 2000, 11, 19–35. [Google Scholar] [CrossRef]
- Kuo, C. Cost efficiency estimations and the equity returns for the US public solar energy firms in 1990–2008. IMA J. Manag. Math. 2010, 22, 307–321. [Google Scholar] [CrossRef]
- Polo, F.A.O.; Bermejo, J.F.; Fernández, J.F.G.; Márquez, A.C. Failure mode prediction and energy forecasting of PV plants to assist dynamic maintenance tasks by ANN based models. Renew. Energy 2015, 81, 227–238. [Google Scholar] [CrossRef]
- Gibert, K.; Swayne, D.; Yang, W.; Voinov, A.; Rizzoli, A.; Filatova, T. Choosing the Right Data Mining Technique: Classification of Methods and Intelligent Recommendation. In Proceedings of the 5th Biennial Conference of the International Environmental Modelling and Software Society, iEMSs 2010, Ottawa, ON, Canada, 5–8 July 2010; pp. 2457–2464. [Google Scholar]
- Buddhakulsomsiri, J.; Siradeghyan, Y.; Zakarian, A.; Li, X. Association rule-generation algorithm for mining automotive warranty data. Int. J. Prod. Res. 2006, 44, 2749–2770. [Google Scholar] [CrossRef]
- Bermejo, J.F.; Fernández, J.F.G.; Polo, F.O.; Márquez, A.C. A Review of the Use of Artificial Neural Networks Models for Energy and Reliability Prediction. A Study for the Solar PV, Hydraulic and Wind Energy Sources. Appl. Sci. 2019, 9, 1844. [Google Scholar] [CrossRef]
- Bangalore, P.; Tjernberg, L.B. An artificial neural network approach for early fault detection of gearbox bearings. IEEE Trans. Smart Grid 2015, 6, 980–987. [Google Scholar] [CrossRef]
- Tehrani, M.M.; Beauregard, Y.; Rioux, M.; Kenne, J.P.; Ouellet, R. A predictive preference model for maintenance of a heating ventilating and air conditioning system. IFAC-PapersOnLine 2015, 28, 130–135. [Google Scholar] [CrossRef]
- Vernekar, K.; Kumar, H.; Gangadharan, K.V. Engine gearbox fault diagnosis using machine learning approach. J. Qual. Maint. Eng. 2018, 24, 345–357. [Google Scholar] [CrossRef]
- Martínez-Martínez, V.; Gomez-Gil, F.J.; Gomez-Gil, J.; Ruiz-Gonzalez, R. An Artificial Neural Network based expert system fitted with Genetic Algorithms for detecting the status of several rotary components in agro-industrial machines using a single vibration signal. Expert Syst. Appl. 2015, 42, 6433–6441. [Google Scholar] [CrossRef]
- Trappey, A.J.C.; Trappey, C.V.; Ma, L.; Chang, J.C.M. Intelligent engineering asset management system for power transformer maintenance decision supports under various operating conditions. Comput. Ind. Eng. 2015, 84, 3–11. [Google Scholar] [CrossRef]
- Prashanth, B.; Kumar, H.S.; Pai, P.S.; Muralidhara, R. Use of MEMS based vibration data for REB fault diagnosis. Int. J. Eng. Technol. 2018, 7, 714–718. [Google Scholar]
- Lazakis, I.; Raptodimos, Y.; Varelas, T. Predicting ship machinery system condition through analytical reliability tools and artificial neural networks. Ocean Eng. 2018, 152, 404–415. [Google Scholar] [CrossRef] [Green Version]
- Eyoh, J.; Kalawsky, R.S. Reduction of impacts of oil and gas operations through intelligent maintenance solution. In Proceedings of the International Conference on Intelligent Science and Technology-ICIST ’18, London, UK, 30 June–2 July 2018; pp. 67–71. [Google Scholar]
- De Benedetti, M.; Leonardi, F.; Messina, F.; Santoro, C.; Vasilakos, A. Anomaly detection and predictive maintenance for photovoltaic systems. Neurocomputing 2018, 310, 59–68. [Google Scholar] [CrossRef]
- Protalinsky, O.; Khanova, A.; Shcherbatov, I. Simulation of Power Assets Management Process; Springer: Cham, Switzarland, 2019; pp. 488–501. [Google Scholar]
- Agrawal, R.; Imieliński, T.; Swami, A. Mining association rules between sets of items in large databases. ACM SIGMOD Rec. 1993, 22, 207–216. [Google Scholar] [CrossRef]
- Chen, W.C.; Tseng, S.S.; Wang, C.Y. A novel manufacturing defect detection method using association rule mining techniques. Expert Syst. Appl. 2005, 29, 807–815. [Google Scholar] [CrossRef]
- Kamsu-Foguem, B.; Rigal, F.; Mauget, F. Mining association rules for the quality improvement of the production process. Expert Syst. Appl. 2013, 40, 1034–1045. [Google Scholar] [CrossRef] [Green Version]
- Martínez-De-Pisón, F.J.; Sanz, A.; Martínez-De-Pisón, E.; Jiménez, E.; Conti, D. Mining association rules from time series to explain failures in a hot-dip galvanizing steel line. Comput. Ind. Eng. 2012, 63, 22–36. [Google Scholar] [CrossRef]
- Sammouri, W.; Come, E.; Oukhellou, L.; Aknin, P.; Fonlladosa, C.-E. Floating train data systems for preventive maintenance: A data mining approach. In Proceedings of the 2013 International Conference on Industrial Engineering and Systems Management (IESM), Rabat, Morocco, 28–30 October 2013; pp. 1–7. [Google Scholar]
- Bastos, P.; Lopes, I.D.; Pires, L. A maintenance prediction system using data mining techniques. World Congr. Eng. 2012, 3, 1448–1453. [Google Scholar]
- Djatna, T.; Alitu, I.M. An Application of Association Rule Mining in Total Productive Maintenance Strategy: An Analysis and Modelling in Wooden Door Manufacturing Industry. Procedia Manuf. 2015, 4, 336–343. [Google Scholar] [CrossRef] [Green Version]
- Antomarioni, S.; Bevilacqua, M.; Potena, D.; Diamantini, C. Defining a data-driven maintenance policy: An application to an oil refinery plant. Int. J. Qual. Reliab. Manag. 2019, 36, 77–97. [Google Scholar] [CrossRef]
- Antomarioni, S.; Pisacane, O.; Potena, D.; Bevilacqua, M.; Ciarapica, F.E.; Diamantini, C. A predictive association rule-based maintenance policy to minimize the probability of breakages: Application to an oil refinery. Int. J. Adv. Manuf. Technol. 2019. [Google Scholar] [CrossRef]
- Nisi, M.; Renga, D.; Apiletti, D.; Giordano, D.; Huang, T.; Zhang, Y.; Mellia, M.; Baralis, E. Transparently Mining Data from a Medium-Voltage Distribution Network: A Prognostic-Diagnostic Analysis. In Proceedings of the EDBT/ICDT 2019 Joint Conference, Lisbon, Portugal, 26–29 March 2019. [Google Scholar]
- Hu, L.; Liu, K.-Y.; Diao, Y.; Meng, X.; Sheng, W. Operational Reliability Evaluation Method Based on Big Data Technology. In Proceedings of the 2016 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Chengdu, China, 13–15 October 2016; pp. 341–344. [Google Scholar]
- Lawrence, S.; Giles, C.; Tsoi, A. What Size Neural Network Gives Optimal Generalization? Convergence Properties of Backpropagation; University of Maryland Libraries: College Park, MD, USA, 1996. [Google Scholar]
- Ali, S.; Smith, K.A. On learning algorithm selection for classification. Appl. Soft Comput. J. 2006, 6, 119–138. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning Long-Term Dependencies with Gradient Descent is Difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Lapedes, A.; Farber, R. Nonlinear Signal Processing Using Neural Networks: Prediction and System Modeling. In IEEE-Neural Networks; National Technical Information Service, U.S. Department of Commerce: Springfield, VA, USA, 1987. [Google Scholar]
- Han, J.; Cheng, H.; Xin, D.; Yan, X. Frequent pattern mining: current status and future directions. In Data Mining and Knowledge Discovery; Springer Science + Business Media: Berlin, Germany, 2007; pp. 55–86. [Google Scholar]
- Mata, J.; Alvarez, J.L.; Riquelme, J.C. An evolutionary algorithm to discover numeric association rules. In Proceedings of the 2002 ACM Symposium on Applied Computing, Madrid, Spain, 11–14 March 2003. [Google Scholar]
- Mirebrahim, S.H.; Shokoohi-Yekta, M.; Kurup, U.; Welfonder, T.; Shah, M. A Clustering-based Rule-mining Approach for Monitoring Long-term Energy Use and Understanding System Behavior. In Proceedings of the 4th ACM International Conference on Systems for Energy-Efficient Built Environments, Delft, The Netherlands, 8–9 November 2017; pp. 5:1–5:9. [Google Scholar]
- Jović, A.; Brkić, K.; Bogunović, N. An overview of free software tools for general data mining. In Proceedings of the 2014 37th International Convention on Information and Communication Technology, Electronics and Microelectronics, MIPRO 2014-Proceedings, Opatija, Croatia, 26–30 May 2014. [Google Scholar]
- Announcing the Standard for Integration Definition for Function Modeling (IDEF0); U.S. Department of Commerce: Springfield, VA, USA, 1993.
- Theodoridis, S. Probability and Stochastic Processes. In Probability and Stochastic Processes, Machine Learning; Academic Press: Cambridge, MA, USA, 2015; pp. 9–51, Chapter 2. [Google Scholar]
- Powell, M.J.D. An efficient method for finding the minimum of a function of several variables without calculating derivatives. Comput. J. 1964, 7, 155–162. [Google Scholar] [CrossRef]
- Powell, M.J.D. On the calculation of orthogonal vectors. Comput. J. 1968, 11, 302–304. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Rahman, S.M.; Vega, R.; Dong, B. A hierarchical approach using machine learning methods in solar photovoltaic energy production forecasting. Energies 2016, 9, 55. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.; Vapnik, V. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Chen, J.L.; Liu, H.B.; Wu, W.; Xie, D.T. Estimation of monthly solar radiation from measured temperatures using support vector machines—A case study. Renew. Energy 2011, 36, 413–420. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, L.; Qu, Y.; Zhao, G.; Guo, Z. Support vector regression based on grid-search method for short-term wind power forecasting. J. Appl. Math. 2014, 2014, 835791. [Google Scholar] [CrossRef]
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F. e1071: Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071); R Package Version 1.6-7; TU Wien: Vienna, Austria, 2015. [Google Scholar]
- Fan, R.E.; Chang, D.K.-W.; Hsieh, C.-J.; Wang, X.-R.; Lin, C.-J. LIBLINEAR: Una biblioteca para la Clasificación grande lineal. J. Mach. Learn Investig. 2008, 9, 1871–1874. [Google Scholar]
- Helleputte, T. LIBLINEAR: Modelos lineales predictivos basados en la LIBLINEAR C/C++ R library versión. 2015. [Google Scholar]
- Elyan, E.; Gaber, M.M. A genetic algorithm approach to optimising random forests applied to class engineered data. Inf. Sci. 2017, 384, 220–234. [Google Scholar] [CrossRef]
- Lin, Y.; Kruger, U.; Zhang, J.; Wang, Q.; Lamont, L.; Chaar, L.E. Seasonal analysis and prediction of wind energy using random forests and ARX model structures. IEEE Trans. Control Syst. Technol. 2015, 23, 1994–2002. [Google Scholar] [CrossRef]
- Moutis, P.; Skarvelis-Kazakos, S.; Brucoli, M. Decision tree aided planning and energy balancing of planned community microgrids. Appl. Energy 2016, 161, 197–205. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and regression by RandomForest. R News 2002, 2, 18–22. [Google Scholar]
- Chapman, P.; Clinton, J.; Kerber, R.; Khabaza, T.; Reinartz, T.; Shearer, C.; Wirth, R. The CRISP-DM user guide. In Proceedings of the 4th CRISP-DM SIG Workshop in Brussels in March (1999), Brussels, Belgium, 18 March 1999. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Corrective & Preventive Maintenance | Fluid Density | Flow | Intake Temperature & Output Temperature | Output Pressure | Tank Level | Power Consumption | Operation Modes | Hours Since Last Overhaul |
|---|---|---|---|---|---|---|---|---|---|
| GMAO | √ | ||||||||
| LNG Quality Registration | √ | ||||||||
| Plant Information System | √ | √ | √ | √ | √ | ||||
| Shift superintendent book | √ | ||||||||
| Pump horometers | √ |
| COVARIANCE | Flow | Output Pressure | Power Consumption | Intake Temperature | Output Temperature | Tank Level | Fluid Density | Hours Since Last Overhaul |
|---|---|---|---|---|---|---|---|---|
| Flow | 0.04100 | |||||||
| Output pressure | −0.01438 | 0.01096 | ||||||
| Power consumption | 0.03624 | −0.01337 | 0.03503 | |||||
| Intake temperature | −0.00531 | −0.00167 | −0.00562 | 0.014173 | ||||
| Output temperature | −0.01038 | 0.00208 | −0.01078 | 0.00905 | 0.02344 | |||
| Tank level | 0.00565 | 0.00538 | 0.00543 | −0.01025 | −0.00348 | 0.02418 | ||
| Fluid density | −0.00457 | 0.00241 | −0.00281 | −0.00077 | −0.00340 | −0.00315 | 0.01663 | |
| Hrs since last overhaul | −0.00844 | 0.00100 | −0.00922 | 0.00279 | 0.00428 | −0.00392 | 0.01136 | 0.08351 |
| Hours | Period before OH 1 | Period before OH 2 | Period before OH 3 | |||
|---|---|---|---|---|---|---|
| Operating hours | From 2.375 | To 16.147 | From 0 | To 5.173 | From 0 | To 94 |
| Valid data points | 10.082 | 4.857 | 49 | |||
| Variable | Vmin | Vmax |
|---|---|---|
| Flow (m3/h) | 250 | 700 |
| Intake Pressure (kgf/cm2) | 6 | 14 |
| Intake Temperature (TAsp) (°C) | −160.5 | −150 |
| Impulsion Temperature (TImp) (°C) | −160.5 | −153.5 |
| Tank Level (Nivel T) (mm) | 0 | 50,000 |
| LNG Density (Dens GNL) (kg/m3) | 430 | 465 |
| Hrs since last Overhaul (h) | 0 | 16.128 |
| Power (Kwh) | 200 | 350 |
| Metric | Training | Before the Overhaul 1 | After the Overhaul 1 |
|---|---|---|---|
| RMSE | 0.00030 | 0.00043 | 0.00222 |
| MAE | 0.01567 | 0.02297 | 0.05447 |
| MAPE | 0.02807 | 0.03963 | 0.12195 |
| Model | Data Set | RMSE |
|---|---|---|
| ANN Model | Before the Overhaul 1 | 0.00043 |
| After de Overhaul 1 | 0.00222 | |
| SVM non linear | Before the Overhaul 1 | 0.00045 |
| After de Overhaul 1 | 0.00230 | |
| SVM Linear (Liblinear) | Before the Overhaul 1 | 0.00052 |
| After de Overhaul 1 | 0.00269 | |
| Random Forest | Before the Overhaul 1 | 0.00038 |
| After de Overhaul 1 | 0.00201 |
| Time Intervals | Number of Hours | Milestone |
|---|---|---|
| TI 1 | 3223 | Overhaul |
| TI 2 | 4856 | Failure |
| TI 3 | 49 | Current date |
| Variable | Min Value | Max Value | Size |
|---|---|---|---|
| Flow rate [m3/h] | 328 | 668 | 30 |
| LNG Density [kg/m3] | 430 | 465 | 5 |
| Tank level [mm] | 1900 | 35,900 | 1000 |
| Intake Pressure [kg/cm2] | 6.5 | 13.5 | 1 |
| Intake Temperature [°C] | −160 | −157 | 1 |
| Impulsion Temperature [°C] | −160 | −153 | 1 |
| Efficiency [%] | 42 | 68 | 1 |
| Flow Rate | Density | Tank Level | Pressure | T Asp | T Imp | Efficiency | Support | Confidence |
|---|---|---|---|---|---|---|---|---|
| [478–508] | [450–455] | [5900–6900] | [10.5–11.5] | [−159–−158] | [−158–−157] | [59–60] | 0.0006 | 0.75 |
| [478–508] | [450–455] | [5900–6900] | [10.5–11.5] | [−159–−158] | [−158–−157] | [59–60] | 0.0002 | 0.25 |
| Time Intervals | Efficiency Comparison | Coincident Operating Conditions |
|---|---|---|
| TI 1 vs. TI 2 | Efficiency TI 1 > Efficiency TI 2 | 54 |
| Efficiency TI 1 ≤ Efficiency TI 2 | 4 | |
| TI 1 vs. TI 3 | Efficiency TI 1 ≤ Efficiency TI 3 | 16 |
| TI 2 vs. TI 3 | Efficiency TI 2 < Efficiency TI 3 | 3 |
| TI | Flow Rate | Density | Tank Level | Pressure | T Asp | T Imp | Efficiency | Support | Confidence |
|---|---|---|---|---|---|---|---|---|---|
| 1 | [508–538] | [445–450] | [27,900–28,900] | [11.5–12.5] | [−160–−159] | [−159–−158] | [64–65] | 0.0003 | 0.5 |
| [508–538] | [445–450] | [27,900–28,900] | [11.5–12.5] | [−160–−159] | [−159–−158] | [65–66] | 0.0003 | 0.5 | |
| 2 | [508–538] | [445–450] | [27,900–28,900] | [11.5–12.5] | [−160–−159] | [−159–−158] | [60–61] | 0.0002 | 0.5 |
| [508–538] | [445–450] | [27,900–28,900] | [11.5–12.5] | [−160–−159] | [−159–−158] | [61–62] | 0.0002 | 0.5 | |
| 3 | [508–538] | [445–450] | [27,900–28,900] | [11.5–12.5] | [−160–−159] | [−159–−158] | [64–65] | 0.0204 | 0.5 |
| [508–538] | [445–450] | [27,900–28,900] | [11.5–12.5] | [−160–−159] | [−159–−158] | [65–66] | 0.0204 | 0.5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Crespo Márquez, A.; de la Fuente Carmona, A.; Antomarioni, S. A Process to Implement an Artificial Neural Network and Association Rules Techniques to Improve Asset Performance and Energy Efficiency. Energies 2019, 12, 3454. https://doi.org/10.3390/en12183454
Crespo Márquez A, de la Fuente Carmona A, Antomarioni S. A Process to Implement an Artificial Neural Network and Association Rules Techniques to Improve Asset Performance and Energy Efficiency. Energies. 2019; 12(18):3454. https://doi.org/10.3390/en12183454
Chicago/Turabian StyleCrespo Márquez, Adolfo, Antonio de la Fuente Carmona, and Sara Antomarioni. 2019. "A Process to Implement an Artificial Neural Network and Association Rules Techniques to Improve Asset Performance and Energy Efficiency" Energies 12, no. 18: 3454. https://doi.org/10.3390/en12183454