An Integrated Methodology for Rule Extraction from ELM-Based Vacuum Tank Degasser Multiclassifier for Decision-Making



Abstract
1. Introduction
2. Brief of Related Soft Computing Algorithms
2.1. Extreme Learning Machine
2.2. Classification and Regression Trees
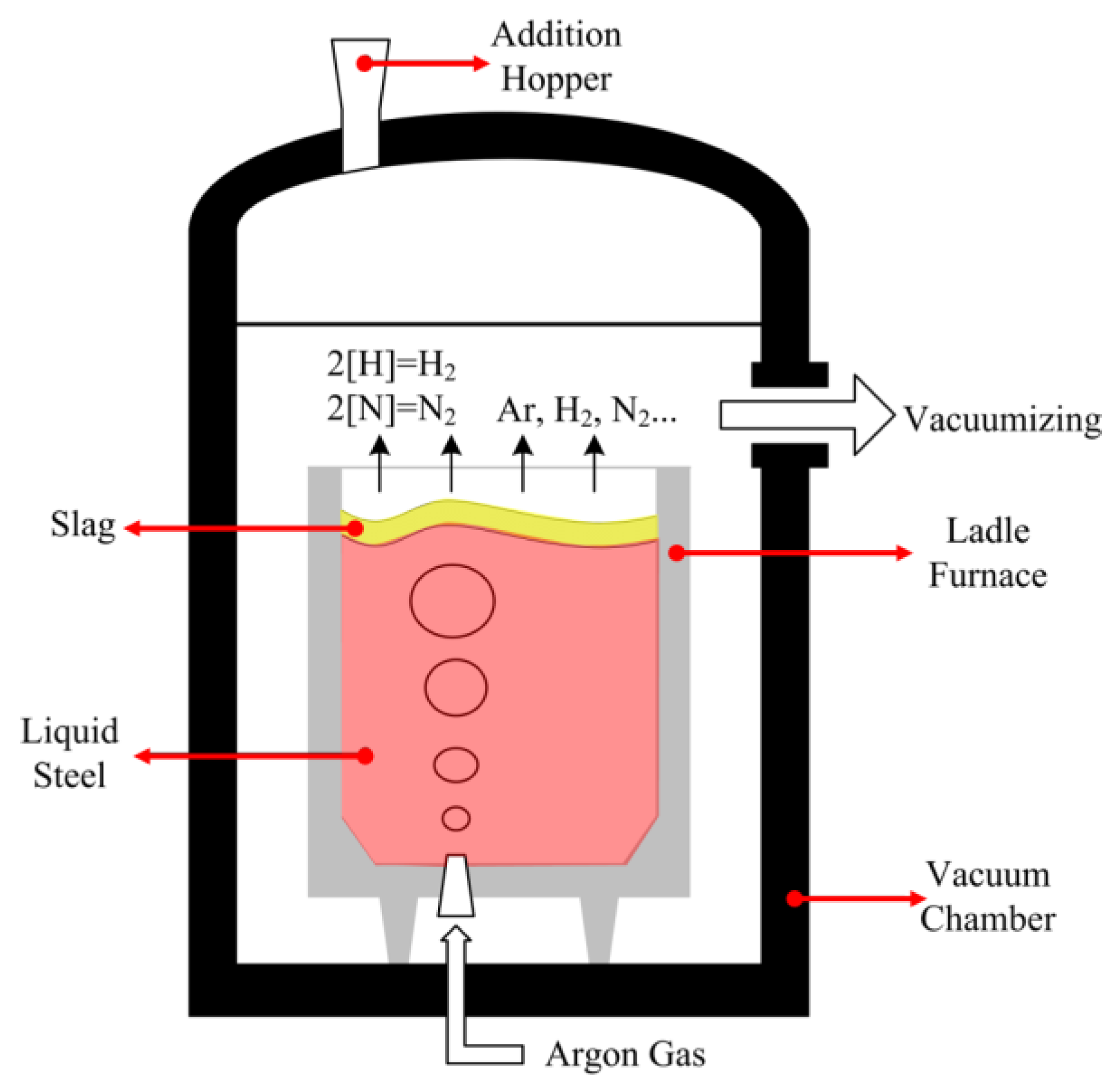
3. ELM-Based Classification for VTD
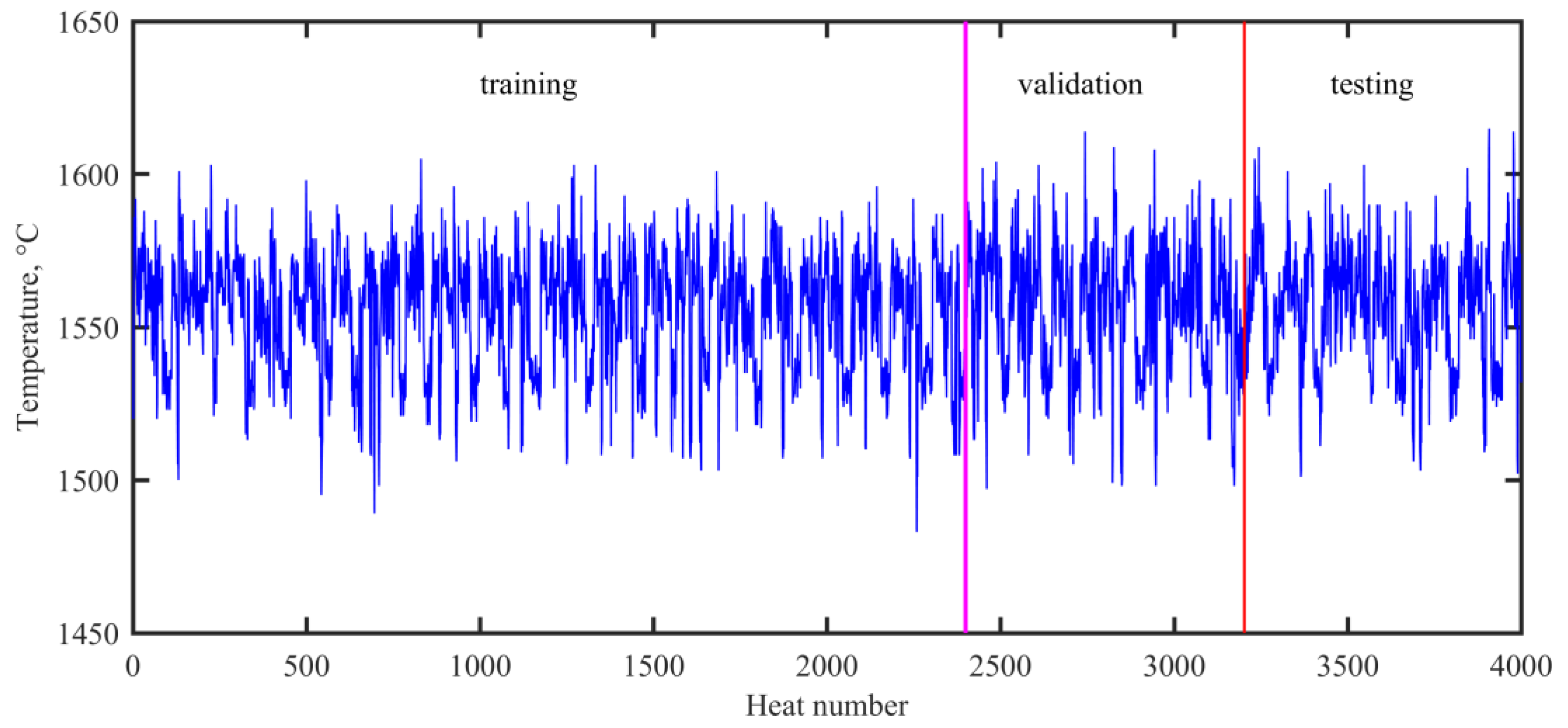
3.1. Production Data
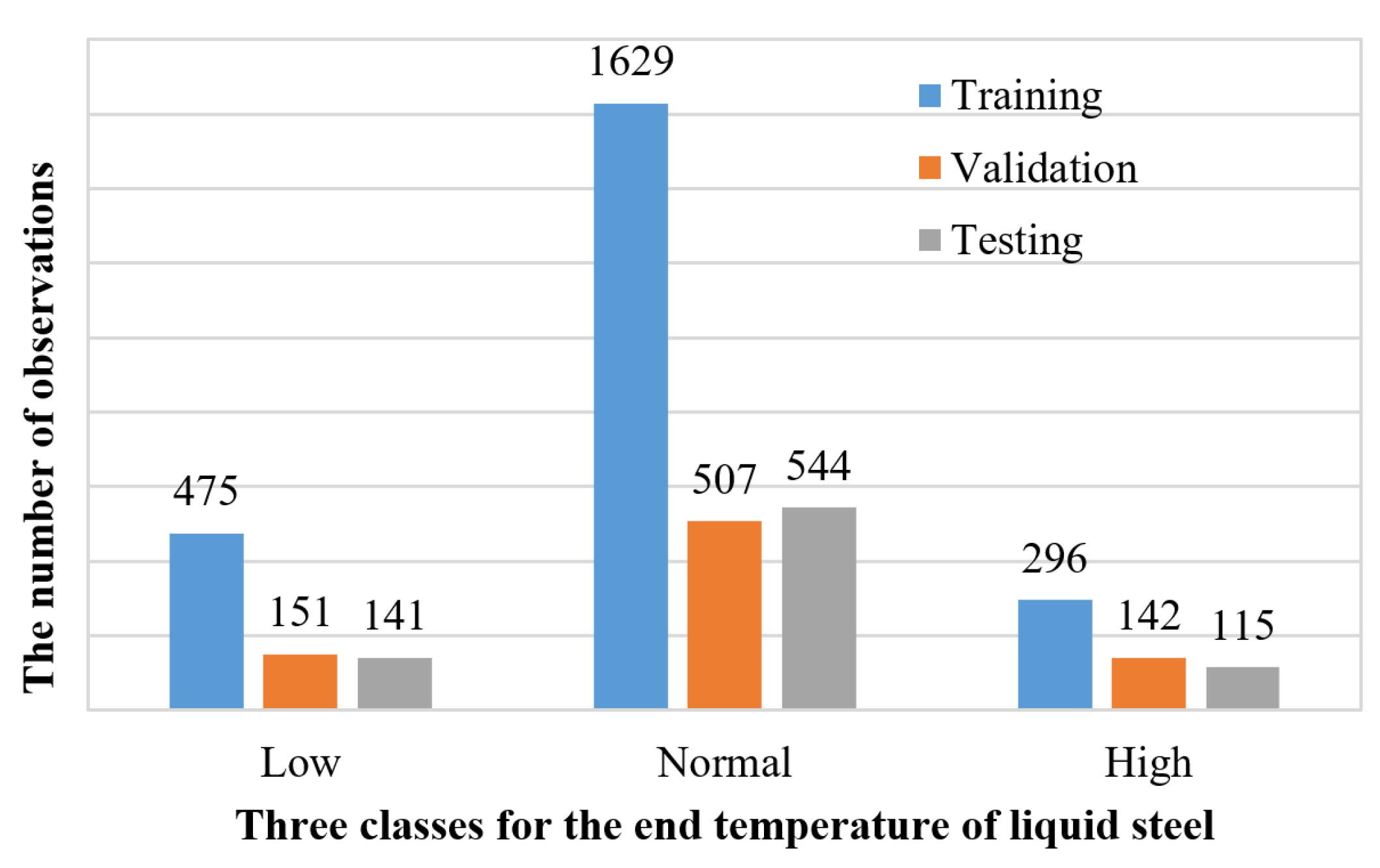
3.2. Three-Class of the End Temperature
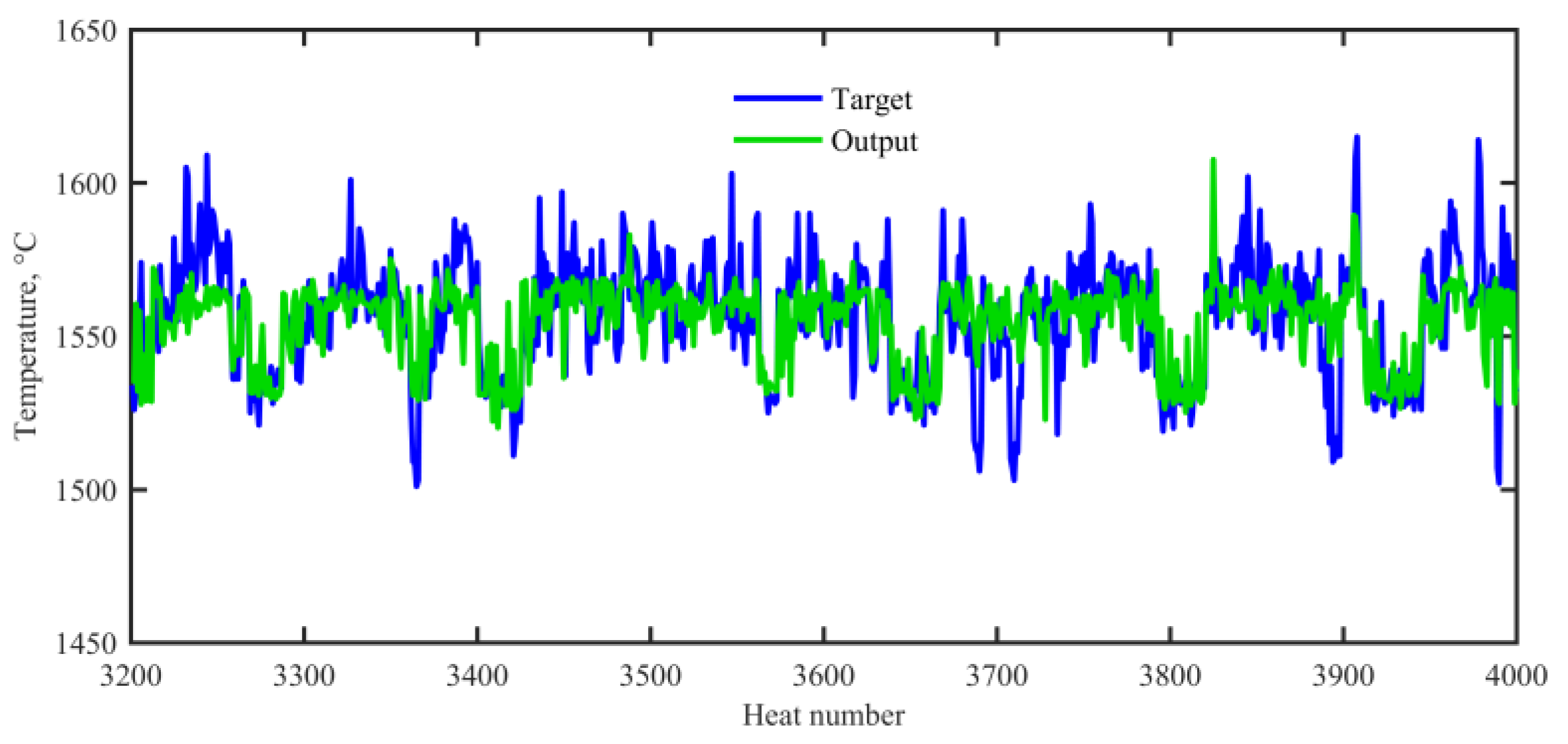
3.3. ELM-Based Three-Class Classification of the End Temperature
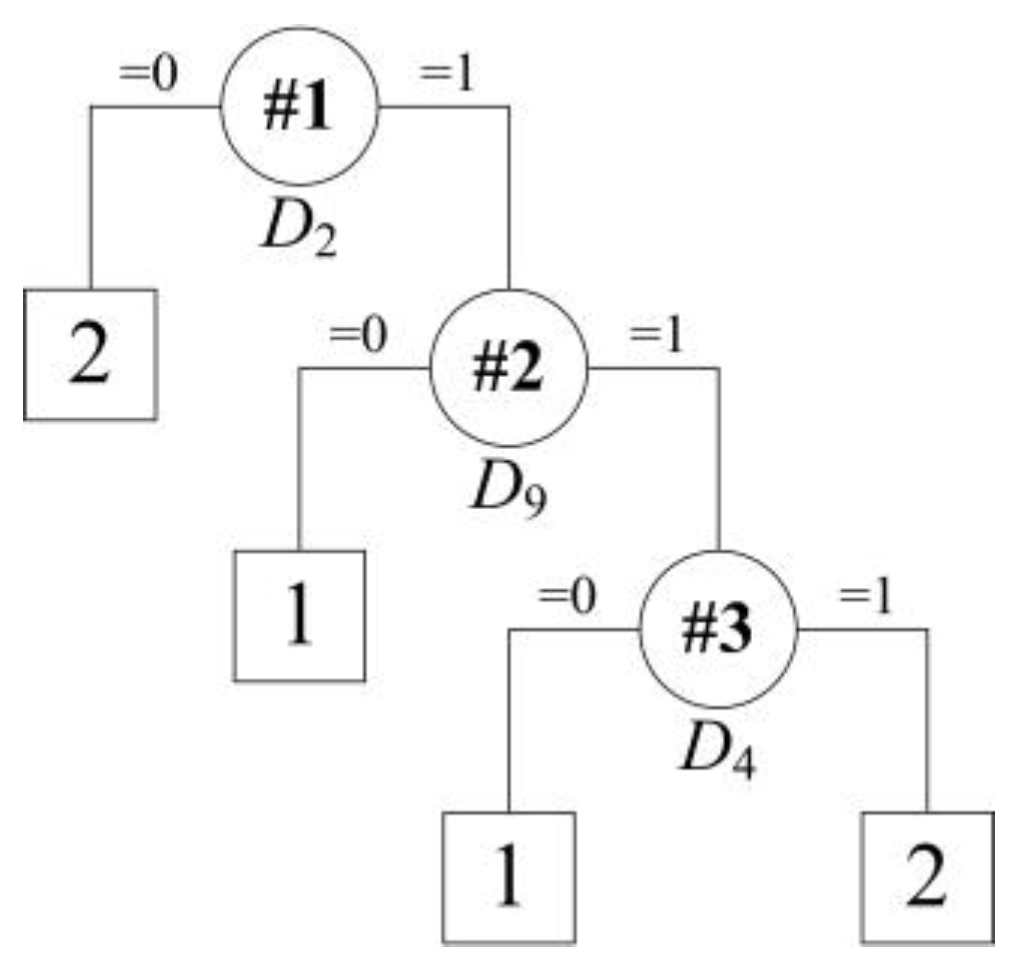
4. Rules Extraction for VTD
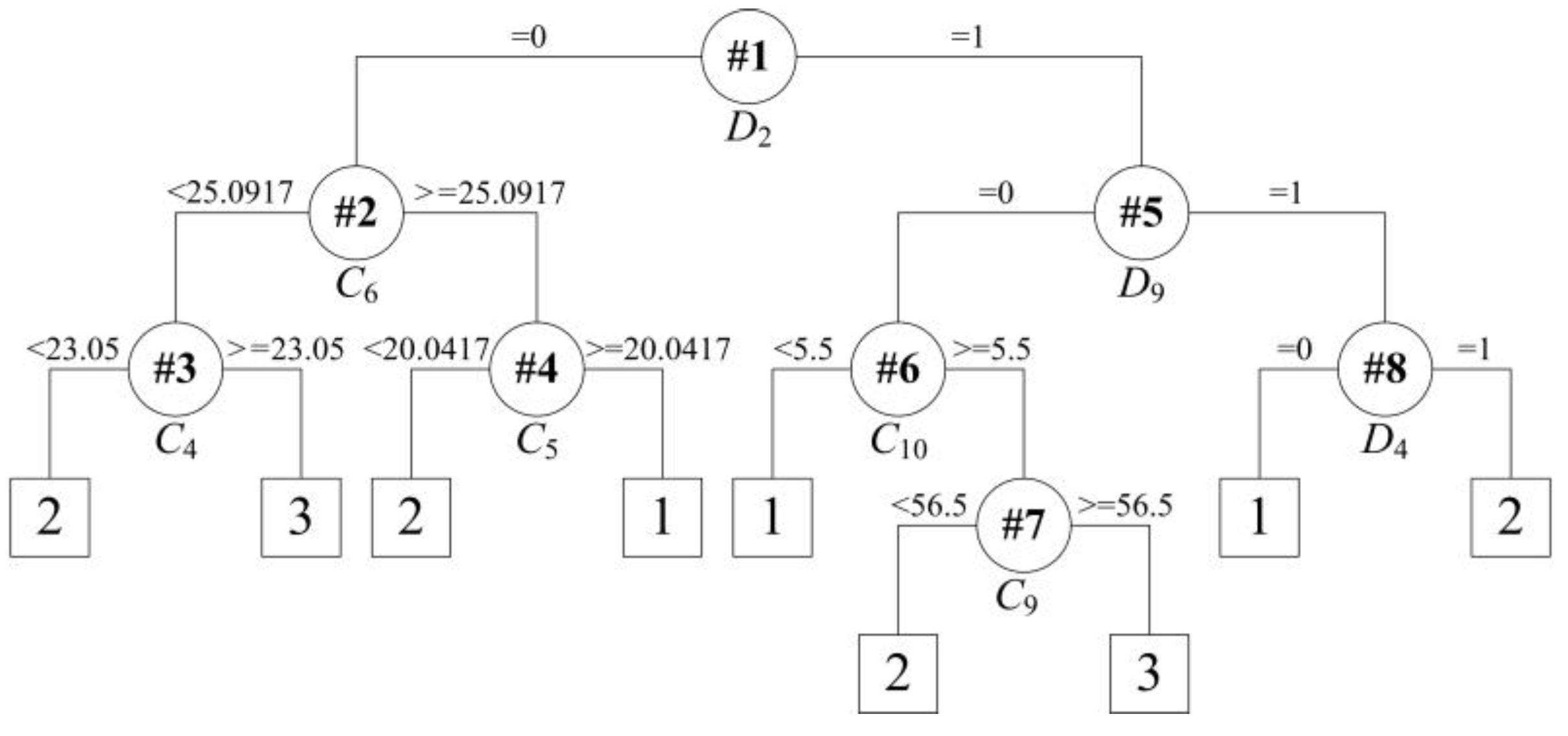
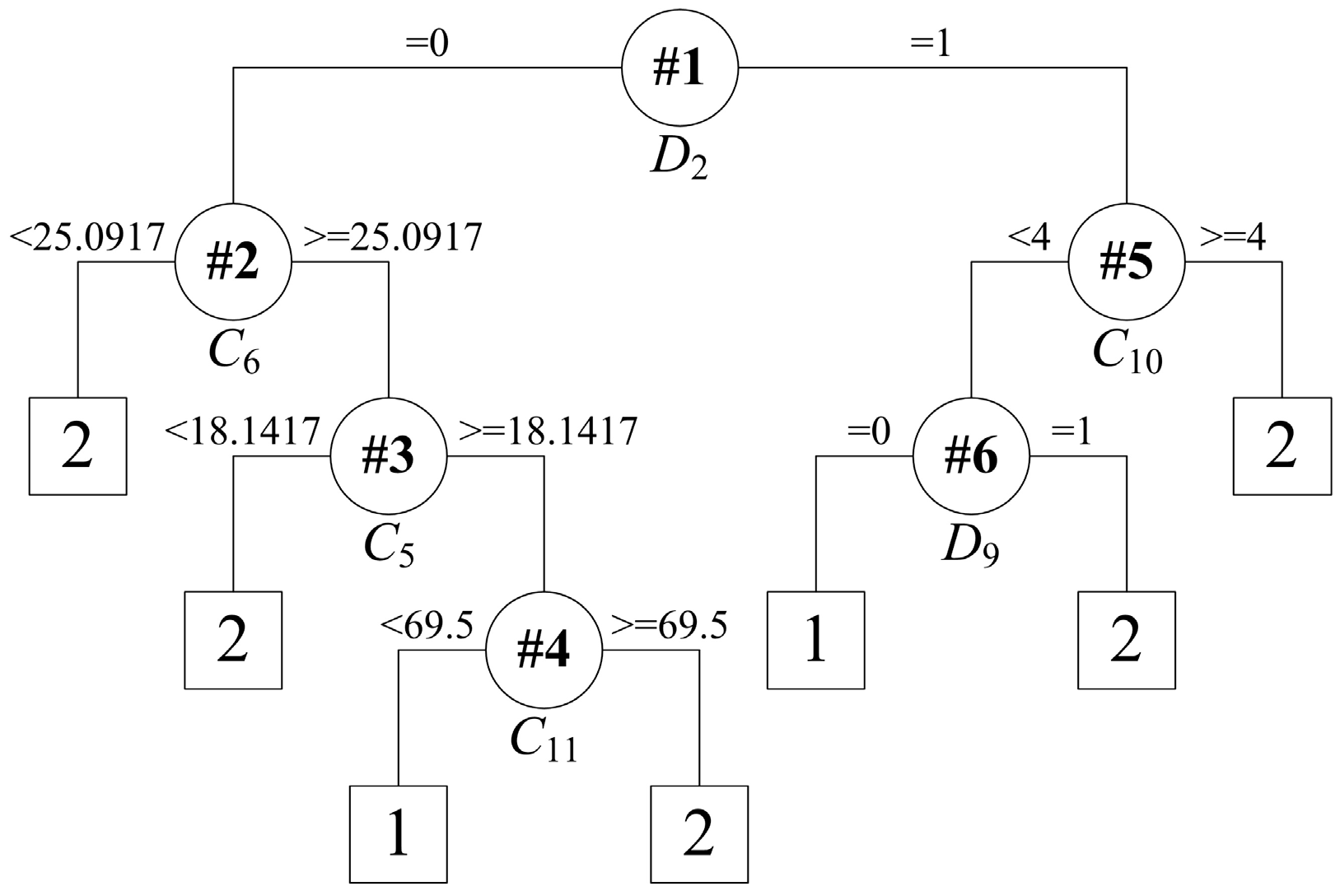
- Rule R1: IF D2 = 0, THEN the predict class = 2;
- Rule R2: IF D2 = 1 and D9 = 0, THEN the predict class = 1;
- Rule R3: IF D2 = 1 and D9 = 1 and D4 = 0, THEN the predict class = 1;
- Rule R4: IF D2 = 1 and D9 = 1 and D4 = 1, THEN the predict class = 2.
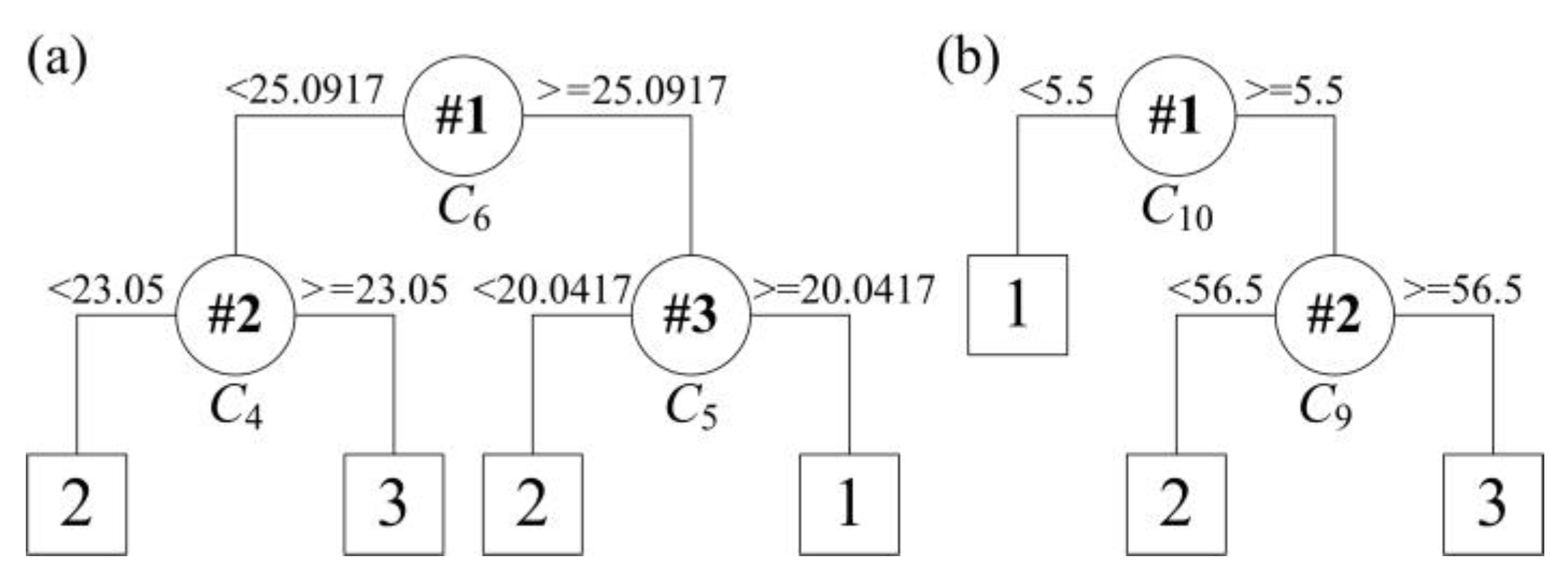
- Rule R1a: IF C6 < 25.0917 and C4 < 23.05, THEN predict class = 2;
- Rule R1b: IF C6 < 25.0917 and C4 ≥ 23.05, THEN predict class = 3;
- Rule R1c: IF C6 ≥ 25.0917 and C5 < 20.0417, THEN predict class = 2;
- Rule R1d: IF C6 ≥ 25.0917 and C5 ≥ 20.0417, THEN predict class = 1;
- Rule R2a: IF C10 < 5.5, THEN predict class = 1;
- Rule R2b: IF C10 ≥ 5.5 and C9 < 56.5, THEN predict class = 2;
- Rule R2c: IF C10 ≥ 5.5 and C9 ≥ 56.5, THEN predict class = 3;
| Algorithm 1: Rule extraction from ELM classification |
| Input: Training data set S = {(xi, ti)}, i = 1, 2, …, N, xi∈Rn, ti∈R, with discrete attributes D and continuous attributes C. |
| Output: A set of classification rules. |
| 1: Calculate the expected value μ and the standard deviation σ of the target series |
| 2: for i = 1 to N do |
| 3: if ti < μ − σ, then, yi = 1. |
| 4: if μ − σ ≤ ti ≤ μ + σ, then, yi = 2. |
| 5: if ti > μ + σ, then, yi = 3. |
| 6: end for |
| 7: Switch the discrete attributes D into binary inputs with the use of the one-hot encoding method. |
| 8: Normalize the continuous attributes C into [0, 1]. |
| 9: Train an ELM using the data set S with all its attributes D and C. |
| 10: Prune the ELM classifier to obtain the new D’ and C’. Let S’ be the set of samples that are correctly classified by the pruned ELM network. |
| 11: If D’ = ϕ, then generate a binary tree using the continuous attributes C’ and stop. |
| 12: Otherwise, generate binary tree rules R using only the D’ with the data set S’. |
| 13: for each rule Ri do |
| 14: if support(Ri) > δ1 and error(Ri) > δ2, then |
| 15: Generate binary tree rules using continuous attributes C’ with the data set Si’ that satisfy the condition of rule Ri. |
| 16: end for |
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Thapliyal, V.; Lekakh, S.N.; Peaslee, K.D.; Robertson, D.G.C. Novel modeling concept for vacuum tank degassing. In Proceedings of the Association for Iron & Steel Technology Conference, Atlanta, GA, USA, 7–10 May 2012; pp. 1143–1150. [Google Scholar]
- Yu, S.; Louhenkilpi, S. Numerical simulation of dehydrogenation of liquid steel in the vacuum tank degasser. Metall. Mater. Trans. B-Process Metall. Mater. Process. Sci. 2013, 44, 459–468. [Google Scholar] [CrossRef]
- Yu, S.; Miettinen, J.; Shao, L.; Louhenkilpi, S. Mathematical modeling of nitrogen removal from the vacuum tank degasser. Steel Res. Int. 2015, 86, 466–477. [Google Scholar] [CrossRef]
- Gajic, D.; Savic-Gajic, I.; Savic, I.; Georgieva, O.; di Gennaro, S. Modelling of electrical energy consumption in an electric arc furnace using artificial neural networks. Energy 2016, 108, 132–139. [Google Scholar] [CrossRef]
- Kordos, M.; Blachnik, M.; Wieczorek, T. Temperature prediction in electric arc furnace with neural network tree. In Proceedings of the International Conference on Artificial Neural Networks, Espoo, Finland, 11–14 June 2011; pp. 71–78. [Google Scholar]
- Fernandez, J.M.M.; Cabal, V.A.; Montequin, V.R.; Balsera, J.V. Online estimation of electric arc furnace tap temperature by using fuzzy neural networks. Eng. Appl. Artif. Intell. 2008, 21, 1001–1012. [Google Scholar] [CrossRef]
- Rajesh, N.; Khare, M.R.; Pabi, S.K. Feed forward neural network for prediction of end blow oxygen in LD converter steel making. Mater. Res. Ibero-Am. J. Mater. 2010, 13, 15–19. [Google Scholar] [CrossRef]
- Wang, X.J.; You, M.S.; Mao, Z.Z.; Yuan, P. Tree-structure ensemble general regression neural networks applied to predict the molten steel temperature in ladle furnace. Adv. Eng. Inform. 2016, 30, 368–375. [Google Scholar] [CrossRef]
- Frechét, M. Sur les fonctionnelles continues. Annales Scientifiques de l’École Normale Supérieure 1910, 27, 193–216. [Google Scholar] [CrossRef]
- Doyle, F.J.; Pearson, R.K.; Ogunnaike, B.A. Identification and Control Using Volterra Models; Springer: London, UK, 2002; pp. 79–103. [Google Scholar]
- Gao, C.H.; Jian, L.; Liu, X.Y.; Chen, J.M.; Sun, Y.X. Data-Driven Modeling Based on Volterra Series for Multidimensional Blast Furnace System. IEEE Trans. Neural Netw. 2011, 22, 2272–2283. [Google Scholar] [PubMed]
- Sidorov, D. Integral Dynamical Models: Singularities, Signals & Control. World Scientific Series on Nonlinear Science Series A; Chua, L.O., Ed.; World Scientific Publishing: Singapore, 2015. [Google Scholar]
- Duch, W.; Setiono, R.; Zurada, J.M. Computational intelligence methods for rule-based data understanding. Proc. IEEE 2004, 92, 771–805. [Google Scholar] [CrossRef]
- Barakat, N.; Bradley, A.P. Rule extraction from support vector machines a review. Neurocomputing 2010, 74, 178–190. [Google Scholar] [CrossRef]
- Chen, Y.C.; Pal, N.R.; Chung, I.F. An integrated mechanism for feature selection and fuzzy rule extraction for classification. IEEE Trans. Fuzzy Syst. 2012, 20, 683–698. [Google Scholar] [CrossRef]
- De Falco, I. Differential evolution for automatic rule extraction from medical databases. Appl. Soft Comput. 2013, 13, 1265–1283. [Google Scholar] [CrossRef]
- Gao, C.H.; Ge, Q.H.; Jian, L. Rule extraction from fuzzy-based blast furnace SVM multiclassifier for decision-making. IEEE Trans. Fuzzy Syst. 2014, 22, 586–596. [Google Scholar] [CrossRef]
- Chakraborty, M.; Biswas, S.K.; Purkayastha, B. Recursive rule extraction from NN using reverse engineering technique. New Gener. Comput. 2018, 36, 119–142. [Google Scholar] [CrossRef]
- Zhou, J.T.; Li, X.Q.; Wang, M.W.; Niu, R.; Xu, Q. Thinking process rules extraction for manufacturing process design. Adv. Manuf. 2017, 5, 321–334. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.M.; Ding, X.J.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B-Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.Y.; Gao, C.H.; Li, P. A comparative analysis of support vector machines and extreme learning machines. Neural Netw. 2012, 33, 58–66. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Chapman & Hall: London, UK, 1984. [Google Scholar]
- Zimmerman, R.K.; Balasubramani, G.K.; Nowalk, M.P.; Eng, H.; Urbanski, L.; Jackson, M.L.; Jackson, L.A.; McLean, H.Q.; Belongia, E.A.; Monto, A.S.; et al. Classification and regression tree (cart) analysis to predict influenza in primary care patients. BMC Infect. Dis. 2016, 16, 1–11. [Google Scholar] [CrossRef]
- Salimi, A.; Faradonbeh, R.S.; Monjezi, M.; Moormann, C. TBM performance estimation using a classification and regression tree (cart) technique. Bull. Eng. Geol. Environ. 2018, 77, 429–440. [Google Scholar] [CrossRef]
- Cheng, R.J.; Yu, W.; Song, Y.D.; Chen, D.W.; Ma, X.P.; Cheng, Y. Intelligent safe driving methods based on hybrid automata and ensemble cart algorithms for multihigh-speed trains. IEEE Trans. Cybern. 2019, 49, 3816–3826. [Google Scholar] [CrossRef]
- Ng, S.C.; Cheung, C.C.; Leung, S.H. Magnified gradient function with deterministic weight modification in adaptive learning. IEEE Trans. Neural Netw. 2004, 15, 1411–1423. [Google Scholar] [CrossRef] [PubMed]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers: Los Altos, CA, USA, 1993. [Google Scholar]
- Setiono, R.; Baesens, B.; Mues, C. Recursive neural network rule extraction for data with mixed attributes. IEEE Trans. Neural Netw. 2008, 19, 299–307. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute Name | Unit | Input Attributes |
|---|---|---|
| Liquid steel weight | t | |
| Tap temperature | °C | |
| Tap to vacuum time | min | |
| Arrive high vacuum time | min | |
| Keep vacuum time | min | |
| Soft stirring time | min | |
| Refining time | min | |
| Argon consumption | m3 | |
| Wire feed consumption | kg | , , , C12 |
| Alloy consumption | kg | , C14, , |
| Ladle material | - | D1, , |
| Refractory life | - | , D5, |
| Heat status | - | , D8, |
| Inputs | Distribution | End Temperature (°C) | TRA | VSA | TEA | ||
|---|---|---|---|---|---|---|---|
| Low | Normal | High | (%) | (%) | (%) | ||
| 25 | true | 141 | 544 | 115 | 80.33 | 63.75 | 71.88 |
| prediction | 154 | 622 | 24 | ||||
| correct | 95 | 472 | 8 | ||||
| 19 | prediction | 152 | 627 | 21 | 79.54 | 66.13 | 72.75 |
| correct | 97 | 478 | 7 | ||||
| Rules | #Samples | Correct | Wrong | Support | Error |
|---|---|---|---|---|---|
| Classification | Classification | (%) | (%) | ||
| R1 | 1510 | 1412 | 98 | 79.10 | 6.49 |
| R2 | 322 | 266 | 56 | 16.87 | 17.39 |
| R3 | 8 | 6 | 2 | 0.42 | 25.00 |
| R4 | 69 | 63 | 6 | 3.61 | 8.70 |
| All rules | 1909 | 1747 | 162 | 100 | 8.49 |
| Method | Attributes | Rules | Accuracy (%) | Fidelity (%) |
|---|---|---|---|---|
| Proposed | 8 | 9 | 75 | 89.75 |
| CART | 6 | 7 | 74 | 88.50 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Li, H.; Zhang, Y.; Zou, Z. An Integrated Methodology for Rule Extraction from ELM-Based Vacuum Tank Degasser Multiclassifier for Decision-Making. Energies 2019, 12, 3535. https://doi.org/10.3390/en12183535
Wang S, Li H, Zhang Y, Zou Z. An Integrated Methodology for Rule Extraction from ELM-Based Vacuum Tank Degasser Multiclassifier for Decision-Making. Energies. 2019; 12(18):3535. https://doi.org/10.3390/en12183535
Chicago/Turabian StyleWang, Senhui, Haifeng Li, Yongjie Zhang, and Zongshu Zou. 2019. "An Integrated Methodology for Rule Extraction from ELM-Based Vacuum Tank Degasser Multiclassifier for Decision-Making" Energies 12, no. 18: 3535. https://doi.org/10.3390/en12183535
APA StyleWang, S., Li, H., Zhang, Y., & Zou, Z. (2019). An Integrated Methodology for Rule Extraction from ELM-Based Vacuum Tank Degasser Multiclassifier for Decision-Making. Energies, 12(18), 3535. https://doi.org/10.3390/en12183535