Detection and Analysis of Multiple Events Based on High-Dimensional Factor Models in Power Grid


Abstract
:1. Introduction
2. Problem Formulation
2.1. Data Processing
2.2. High-Dimensional Factor Models
3. High-Dimensional Factor Model Analysis
3.1. Empirical Spectral Distribution
3.2. Theoretical Spectral Distribution
- The cross-correlations are effectively removed by subtracting p principal components, where p is the true number of factors, and the residual has sufficiently negligible cross-correlations: .
- The autocorrelations of are exponentially decreasing. That is, is in the form of exponential decays with respect to time lags, as: , where is the distance between time i and time j, . This is equivalent to modeling the residual as an autoregressive model, i.e., the AR(1) process: , where . When , the AR(1) process degenerates into Gaussian white noise.
3.3. Distance Measure
4. Case Studies
4.1. Case Study with Simulated Data
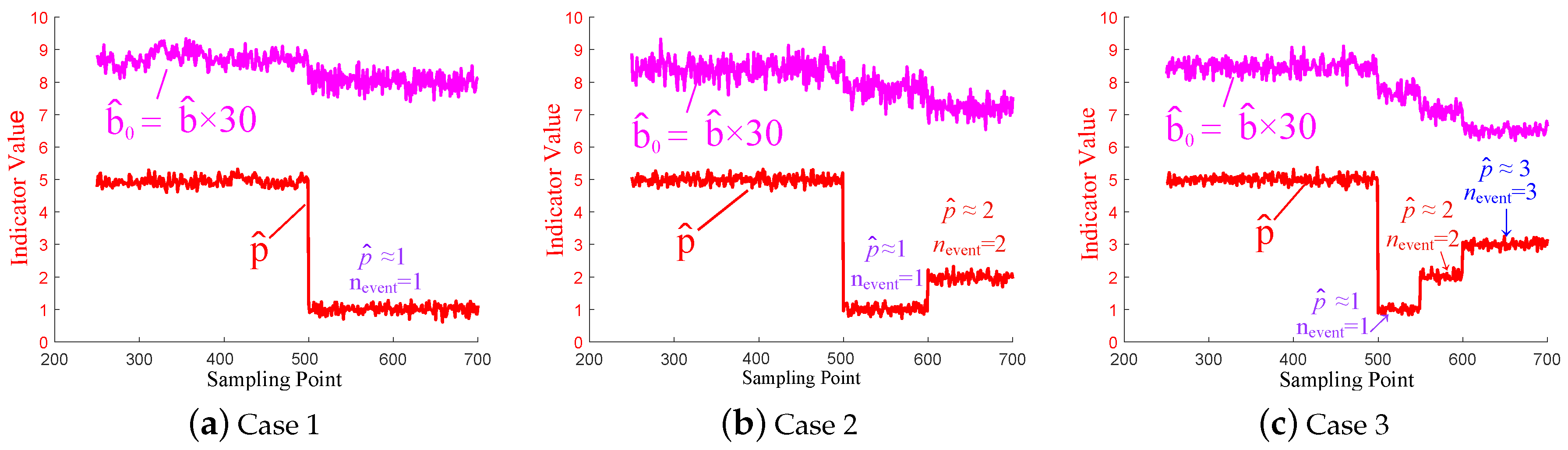
4.1.1. Case 1—A Single Event
- During the sampling time (250 = 1 (the beginning of the signal) + 250 (length of the split-window) − 1). and remain steady.
- At = 500, starts to decline to around 1. Also, declines slightly.
4.1.2. Case 2—A Multiple Event with Two Constituent Components
- During the sampling time , and remain steady, which is consistent with Table 3: no events occur.
- At = 500, starts to decline and then keeps around 1 till = 599. For the split-window to , there exists a single event (the short-circuit fault at Bus 64 at = 500) and 1 factor, i.e., 1 event, .
- At = 600, starts to raise and then keeps around 2. For the split-window to , there exist two constituent components (a short-circuit fault at Bus 64 at = 500 and a disconnection fault at the line connected by Bus 23 and Bus 24 at = 600) and 2 factors, i.e., 2 constituent components, .
4.1.3. Case 3—A Multiple Event with Three Constituent Components
- During the sampling time , and remain steady, which is consistent with Table 4: no events occur.
- At = 500, starts to decline and then keeps around 1 till = 549. For the split-window to , there exists a single event (a short-circuit fault at Bus 64 at = 500) and 1 factor, i.e., 1 event, .
- At = 550, starts to raise and then keeps around 2 till = 599. For the split-window to , there exist two constituent components (a short-circuit fault at Bus 64 at = 500 and a disconnection fault at the line connected by Bus 23 and Bus 24 at = 550) and 2 factors, i.e., 2 constituent components, .
- At = 600, raises again and then keeps around 3. For the split-window to , there exist three constituent components (a short-circuit fault at Bus 64 at = 500, a disconnection fault at the line connected by Bus 23 and Bus 24 at = 550, and a generator tripping event at Bus 107 at = 600) and 3 factors, i.e., 3 constituent components, .
4.1.4. More Discussions of
- At = 400, no spikes (factors) are observed. It is noted that remains almost at 5 in Figure 2c when no events occur. The most likely explanation is that some normal fluctuations of active load create several weak factors. Our approach is sensitive to weak factors under normal operating conditions. However, this phenomenon does not interfere with the judgment of the number of constituent components in a multiple event, because the number of factors is stable under normal conditions, whereas when a multiple event occurs, the change of the number of factors has a regularity.
- At = 520, one spike (factor) is observed. It is caused by the single event in the window, which is consistent with the results in Table 5.
- At = 570, two spikes (factors) are observed. They are caused by the two constituent components of a multiple event in the window.
- At = 620, three spikes (factors) are observed. They are caused by the three constituent components in the multiple event.
4.1.5. More Discussions of
4.2. Case Study with Real Data
- From 60.00 s to 65.38 s, the values of and remain steady, indicating that no events occur during this period. It is noted that the value of stays around 7 rather than 5 as it is in the simulated data. One explanation is that even though noise with an SNR of 22 dB is added to the simulated data, it is still difficult to accurately mimic the fluctuations of real PMU data. The normal fluctuations of real power flow data cause some weak factors, which are detected by our algorithm.
- At 65.40 s, decreases to 1 and remains at 1 until 69.68 s. One factor is detected during this period, indicating that the first constituent component is observed in the split-window.
- From 69.70 s to 72.98 s, two factors are observed. We can speculate that at 69.70 s, the second constituent component of the multiple event occurs.
- At 73.30 s, the value of increases by 1, indicating that the third constituent component of the multiple event occurs at this moment.
5. Comparisons and Discussions
5.1. Comparison with Deep Learning
5.2. Comparison with Principal Component Analysis (PCA)
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Key Concepts and Derivation Details
References
- Dagle, J.E. Data management issues associated with the August 14, 2003 blackout investigation. In Proceedings of the Power Engineering Society General Meeting, Denver, CO, USA, 6–10 June 2004; Volume 2, pp. 1680–1684. [Google Scholar]
- Lai, L.L.; Zhang, H.T.; Lai, C.S.; Xu, F.Y.; Mishra, S. Investigation on July 2012 Indian blackout. In Proceedings of the International Conference on Machine Learning and Cybernetics, Lanzhou, China, 13–16 July 2014; pp. 92–97. [Google Scholar]
- Roman, R.C.; Precup, R.E.; David, R.C. Second order intelligent proportional-integral fuzzy control of twin rotor aerodynamic systems. Proc. Comput. Sci. 2018, 139, 372–380. [Google Scholar] [CrossRef]
- Han, J.; Wang, H.; Jiao, G.; Cui, L.; Wang, Y. Research on active disturbance rejection control technology of electromechanical actuators. Electronics 2018, 7, 174. [Google Scholar] [CrossRef]
- Rafferty, M.; Liu, X.; Laverty, D.M.; Mcloone, S. Real-time multiple event detection and classification using moving window PCA. IEEE Trans. Smart Grid 2016, 7, 2537–2548. [Google Scholar] [CrossRef]
- Bykhovsky, A.; Chow, J.H. Power system disturbance identification from recorded dynamic data at the Northfield substation. Int. J. Electr. Power Energy Syst. 2003, 25, 787–795. [Google Scholar] [CrossRef]
- Wang, W.; He, L.; Markham, P.; Qi, H. Detection, recognition, and localization of multiple attacks through event unmixing. In Proceedings of the IEEE International Conference on Smart Grid Communications, Vancouver, BC, Canada, 21–24 October 2013; pp. 73–78. [Google Scholar]
- Song, Y.; Wang, W.; Zhang, Z.; Qi, H.; Liu, Y. Multiple event detection and recognition for large-scale power systems through cluster-based sparse coding. IEEE Trans. Power Syst. 2017, 32, 4199–4210. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, C.; Ruj, S.; Stojmenovic, M.; Nayak, A. Modeling cascading failures in smart power grid using interdependent complex networks and percolation theory. In Proceedings of the Industrial Electronics and Applications, Melbourne, VIC, Australia, 19–21 June 2013; pp. 1023–1028. [Google Scholar]
- Soltan, S.; Mazauric, D.; Zussman, G. Cascading failures in power grids: analysis and algorithms. In Proceedings of the 5th International Conference on Future Energy Systems, Cambridge, UK, 11–13 June 2014; pp. 195–206. [Google Scholar]
- He, X.; Ai, Q.; Qiu, R.C.; Huang, W.; Piao, L.; Liu, H. A big data architecture design for smart grids based on random matrix theory. IEEE Trans. Smart Grid 2017, 8, 674–686. [Google Scholar] [CrossRef]
- Chu, L.; Qiu, R.C.; He, X.; Ling, Z.; Liu, Y. Massive streaming PMU data modeling and analytics in smart grid state evaluation based on multiple high-dimensional covariance tests. IEEE Trans. Big Data 2016, 4, 55–64. [Google Scholar] [CrossRef]
- He, X.; Qiu, R.C.; Ai, Q.; Chu, L.; Xu, X.; Ling, Z. Designing for situation awareness of future power grids: An indicator system based on linear eigenvalue statistics of large random matrices. IEEE Access 2016, 4, 3557–3568. [Google Scholar] [CrossRef]
- Qiu, R.C.; Antonik, P. Smart Grid and Big Data: Theory and Practice; Wiley: Hoboken, NJ, USA, 2017. [Google Scholar]
- Chakhchoukh, Y.; Vittal, V.; Heydt, G.T. PMU based state estimation by integrating correlation. IEEE Trans. Power Syst. 2014, 29, 617–626. [Google Scholar] [CrossRef]
- Hassanzadeh, M.; Evrenosoğlu, C.Y.; Mili, L. A short-term nodal voltage phasor forecasting method using temporal and spatial correlation. IEEE Trans. Power Syst. 2016, 31, 3881–3890. [Google Scholar] [CrossRef]
- Yeo, J.; Papanicolaou, G. Random matrix approach to estimation of high-dimensional factor models. arXiv, 2016; arXiv:1611.05571. [Google Scholar]
- Forni, M.; Giovannelli, A.; Lippi, M.; Soccorsi, S. Dynamic factor model with infinite-dimensional factor space: Forecasting. J. Appl. Econ. 2018, 33, 625–642. [Google Scholar] [CrossRef] [Green Version]
- Sun, Z.; Liu, X.; Wang, L. A hybrid segmentation method for multivariate time series based on the dynamic factor model. Stoch. Environ. Res. Risk Assess. 2017, 31, 1291–1304. [Google Scholar] [CrossRef]
- Burda, Z.; Jarosz, A.; Nowak, M.A.; Snarska, M. A random matrix approach to VARMA processes. New J. Phys. 2010, 12, 075036. [Google Scholar] [CrossRef] [Green Version]
- Lixin, Z. Spectral Analysis of Large Dimentional Random Matrices. Ph.D. Thesis, National University of Singapore, Singapore, 2007. [Google Scholar]
- Zimmerman, R.D.; Murillo-Sánchez, C.E.; Thomas, R.J. MATPOWER: Steady-state operations, planning, and analysis tools for power systems research and education. IEEE Trans. Power Syst. 2011, 26, 12–19. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Dumitru, M.A.K.R.M.; Pieter, E.B.K.S.D.; Kindermans, J.; Schütt, K.T. Learning how to explain neural networks: Patternnet and patternattribution. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why should i trust you? Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lee, K.; Lee, H.; Lee, K.; Shin, J. Training confidence-calibrated classifiers for detecting out-of-distribution samples. arXiv, 2017; arXiv:1711.09325. [Google Scholar]
- Liang, S.; Li, Y.; Srikant, R. Enhancing the reliability of out-of-distribution image detection in neural networks. arXiv, 2017; arXiv:1706.02690. [Google Scholar]
- Amodei, D.; Olah, C.; Steinhardt, J.; Christiano, P.; Schulman, J.; Mané, D. Concrete problems in AI safety. arXiv, 2016; arXiv:1606.06565. [Google Scholar]
- Jolliffe, I. Principal Component Analysis; Springer: Berlin, Germany, 2011. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (1) Calculate : each row of which is the j-th principal component of ; denote as: . |
| (2) Calculate least squares regression of on : . |
| (3) Calculate the p-level residual: . |
| (4) Calculate the covariance matrix of the p-level residual: . |
| (5) Calculate the empirical spectral distribution of . |
| Bus | Sampling Time | Assumed Events |
|---|---|---|
| 64 | A short-circuit fault |
| Bus | Sampling Time | Assumed Events |
|---|---|---|
| 64 | A short-circuit fault | |
| 23, 24 | A disconnection fault at the line connected by Bus 23 and Bus 24 |
| Bus | Sampling Time | Assumed Events |
|---|---|---|
| 64 | A short-circuit fault | |
| 23, 24 | A disconnection fault at the line connected by Bus 23 and Bus 24 | |
| 107 | A generator tripping event |
| Case | Split-Window | ||
|---|---|---|---|
| 1 | 1 | 1 | |
| 2 | 1 | 1 | |
| 2 | 2 | 2 | |
| 3 | 1 | 1 | |
| 3 | 2 | 2 | |
| 3 | 3 | 3 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, F.; Qiu, R.C.; Ling, Z.; He, X.; Yang, H. Detection and Analysis of Multiple Events Based on High-Dimensional Factor Models in Power Grid. Energies 2019, 12, 1360. https://doi.org/10.3390/en12071360
Yang F, Qiu RC, Ling Z, He X, Yang H. Detection and Analysis of Multiple Events Based on High-Dimensional Factor Models in Power Grid. Energies. 2019; 12(7):1360. https://doi.org/10.3390/en12071360
Chicago/Turabian StyleYang, Fan, Robert C. Qiu, Zenan Ling, Xing He, and Haosen Yang. 2019. "Detection and Analysis of Multiple Events Based on High-Dimensional Factor Models in Power Grid" Energies 12, no. 7: 1360. https://doi.org/10.3390/en12071360
APA StyleYang, F., Qiu, R. C., Ling, Z., He, X., & Yang, H. (2019). Detection and Analysis of Multiple Events Based on High-Dimensional Factor Models in Power Grid. Energies, 12(7), 1360. https://doi.org/10.3390/en12071360