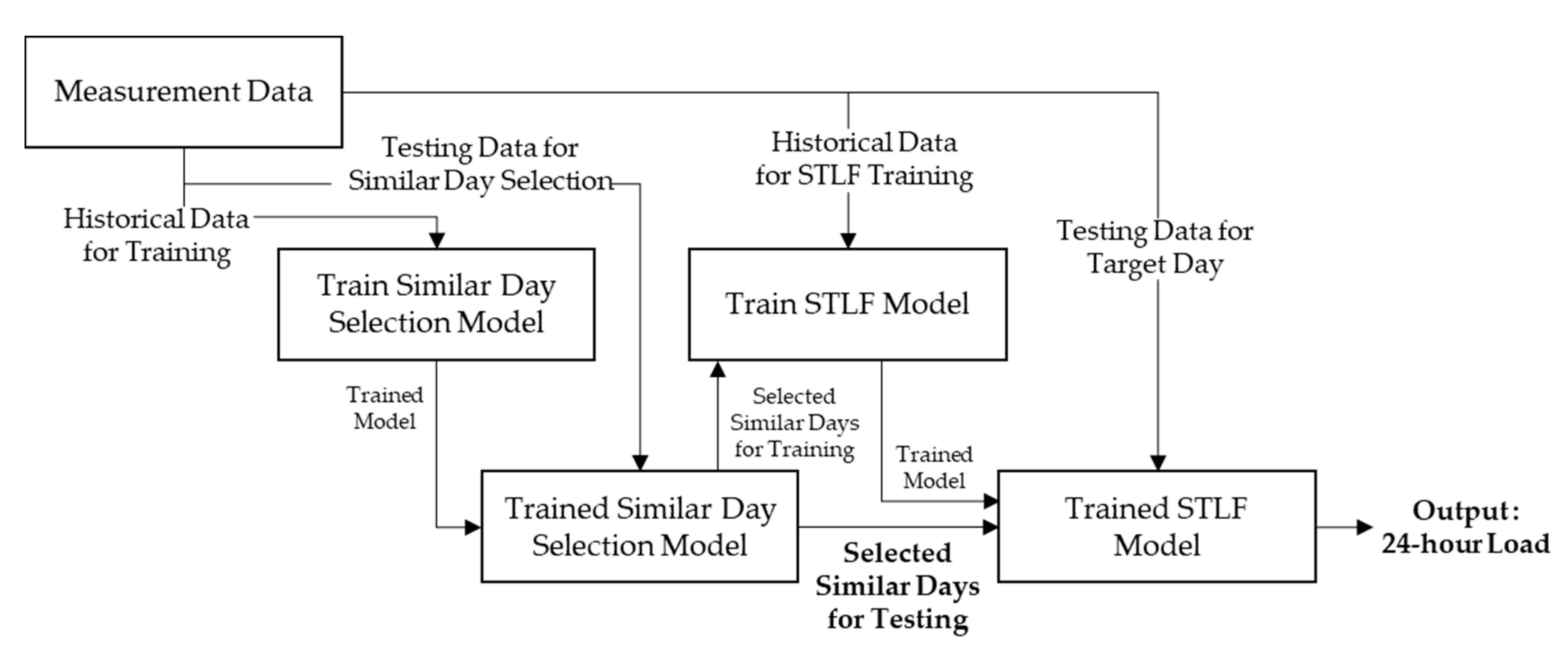
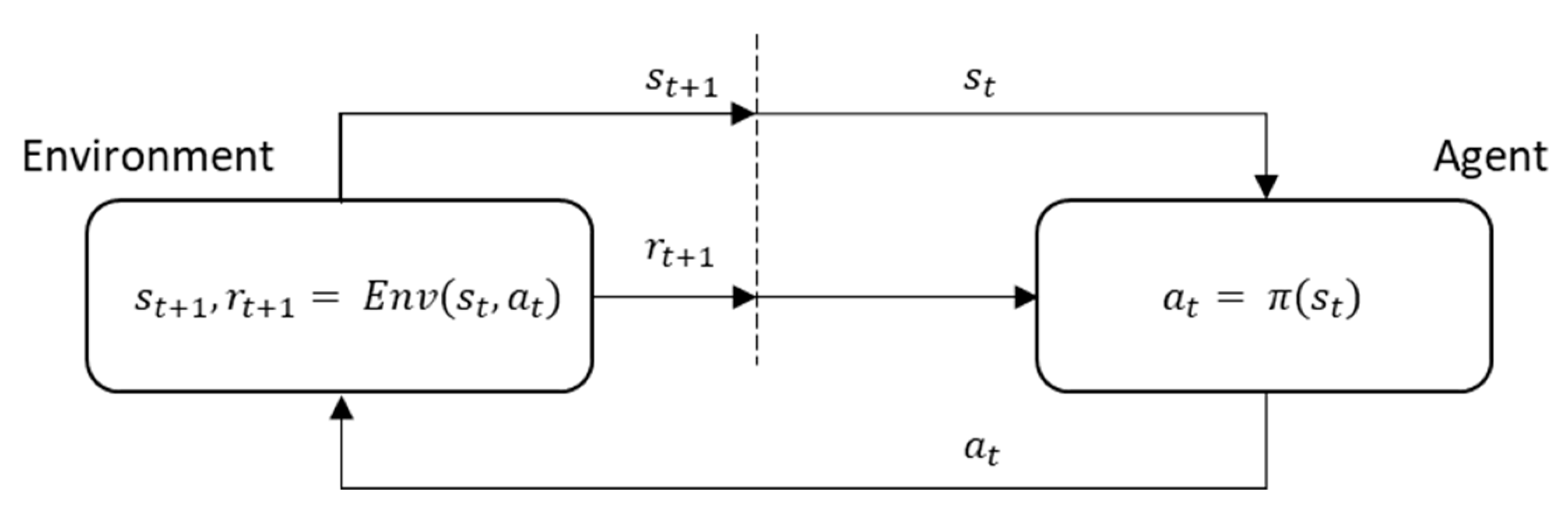
The application of the reinforcement learning algorithm to solve a problem in the real world starts with the mathematical definition of the problem. This mathematical expression is the same as the expression of the MDP, and it can be expressed by state, action, reward, and cost functions in the finite MDP problem [
34]. Furthermore, the interaction between the agent and environment should be defined. In addition, the Q-function to explain the action of the agent and the learning method with the corresponding data should be presented.
The reinforcement learning algorithm can be explained as the discrete stochastic version of the optimal control problem [
34]. This implies that an optimal selection should be made through the interactions that occur at the sequential timesteps in a particular timeline. If this reinforcement learning algorithm is applied to the problem of similar day selection, it can be described as the problem of selecting the best similar day for STLF whenever the target day changes. This interaction is performed between the agent, which is subject to action, and the environment that responds according to the action. For timestep
, the agent selects action
according to the observed state
from the environment, and then, the action
is forwarded to the environment. The environment communicates changed status
along with prospective reward
by reacting to action
. This continuously repeated process is referred to as agent–environment interaction, which is demonstrated in
Figure 5.
In these repetitive interactions, the agent has a rule that determines the action to be performed depending on the observed state, and this rule is referred to as a policy. If the policy of the agent always makes the best selection for the expected cumulative reward for the future, then the policy can be assumed to be optimal. Thus, to mathematically represent the reinforcement learning algorithm, the state, action, and rewards must be defined according to the problem. Subsequently, the agent–environment interactions and the learning method of the policy of the agent should be designed.
3.1. Formulation of the Reinforcement Learning Algorithm
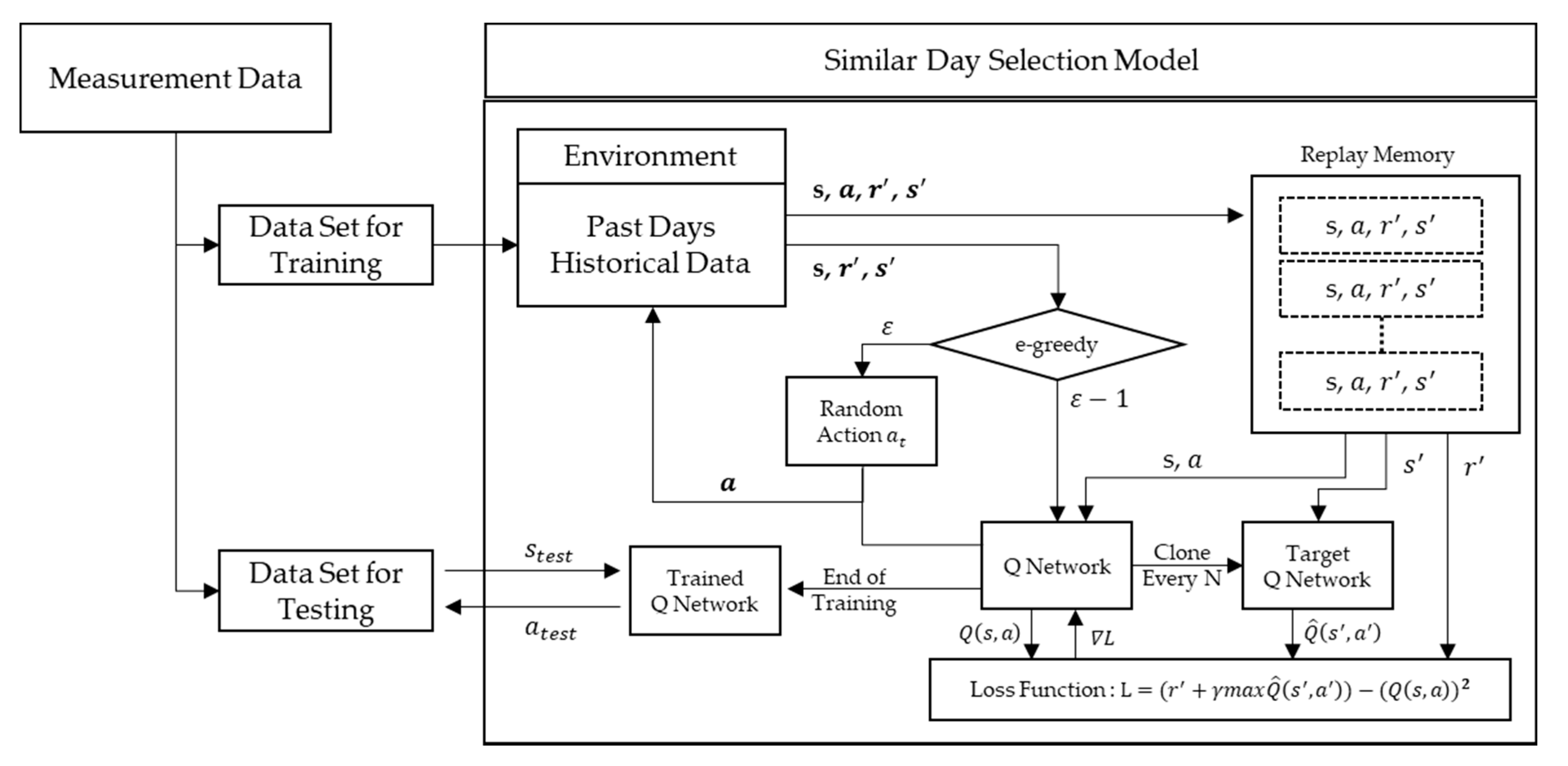
As previously described, the input variables for the similar day selection model use the calendar and meteorological factors. The purpose of the similar day selection model is to select the most similar date for the EDS, which can be calculated using Equation (4). From the agent’s perspective, the policy selects a specific date wherein the EDS is the highest, which is available for only the observation range. The observable states for the agent are the load, the calendar factors, the meteorological factors of the past days, and the action of selecting one of the past days as a similar day. Assuming that the target day changes for each timestep, the agent should be designed to perform the action of selecting a similar day that is based on the historical information for each target day.
The environment should output the reward at timestep and the state at timestep according to the action of the agent performed at timestep . The reward at timestep is obtained by calculating the EDS of the load between the target day and similar days, which is determined by the action of the agent at timestep . In addition, the state at timestep t + 1 is designed to be the state by moving the forecasted target day by one day.
The interaction between the environment and agent is reliable, as demonstrated in Equation (5), where
is the universal set of the state, which is one of the environment’s output variables,
is the state at timestep
, which is an element of
.
is the universal set of the action determined by the agent,
. This is the action at timestep
, which is an element of
.
State
is determined by the historical data that the agent can observe for each timestep. Assuming that the number of elements of the state is M and the number of observation days of the agent is N at timestep
, state
can be determined from Equation (6) as follows:
where
is the index of the target day,
is the index of the past day,
is the index of the elements of the state,
is the distance between target day
and past day
,
is the Euclidean distance between the 24-h temperature for target day
and past day
,
is the Euclidean distance between the 24-h sun irradiation for target day
and past day
, and
is the Euclidean distance between the 24-h raindrops for target day
and past day
. The meteorological factors contain 24 elements that consider the difference in time series characteristics; thus, the total number of elements, m, in one past day is 73. In addition, the observation range should be set depending on the target system. The observation range for the proposed algorithm is set to be 90 days, which includes the past 30 days and 60 days from the previous year. Therefore, the total number of states for the output variables of the environment during timestep
is 6570 elements.
The agents for finding similar days are learned using historical data. In the process of learning using past days, the environment already knows the information of past data, such as the load and meteorological data. Thus, it is possible to calculate the similarity between the loads of the target day and selected similar days from the agent. The learning of the agent to find similar days is a deterministic environment because it is limited in scope according to the target day and uses historical data. Therefore, the status of step t does not depend on the decision of the agent. In addition, the environment only reads the state information according to the timestep
of the sequence and forwards it to the agent.
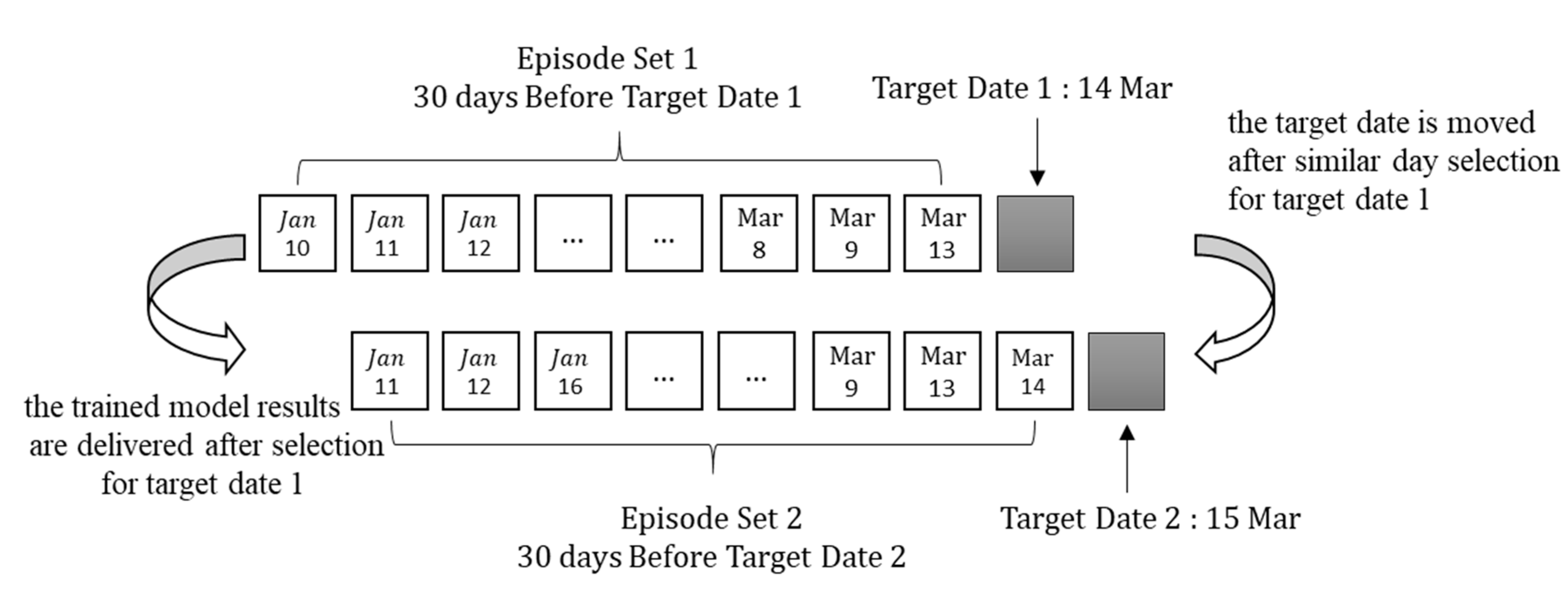
Figure 6 illustrates the range of episodes according to the target date.
An episode is a period for learning the policy of the agent, which is expressed in the form of the DQN. In the example shown in
Figure 5, if the target date is 14 March 2018, the initial timestep of the episode is 10 January 2018, which is 30 days before the target day, excluding special days. Furthermore, the terminal date is 13 March 2018. The agent receives the state information from the environment at each timestep. The state information comprises the calendar and meteorological factors of 90 days before each timestep. As the action of the agent in a deterministic environment does not affect the state transition, the state transition from the selected actions for similar days is not considered.
The number for the universal action set is the same as the observation range,
, and it can be expressed by the following equation:
Here, element
is a digit value, which implies that it is either zero or one. This indicates that a selected day can be expressed as one. One or more similar days can be selected depending on the manner in which they are used. The output of agent
could consist of a number of combinations,
, depending on the number of selected days,
, according to the following equation:
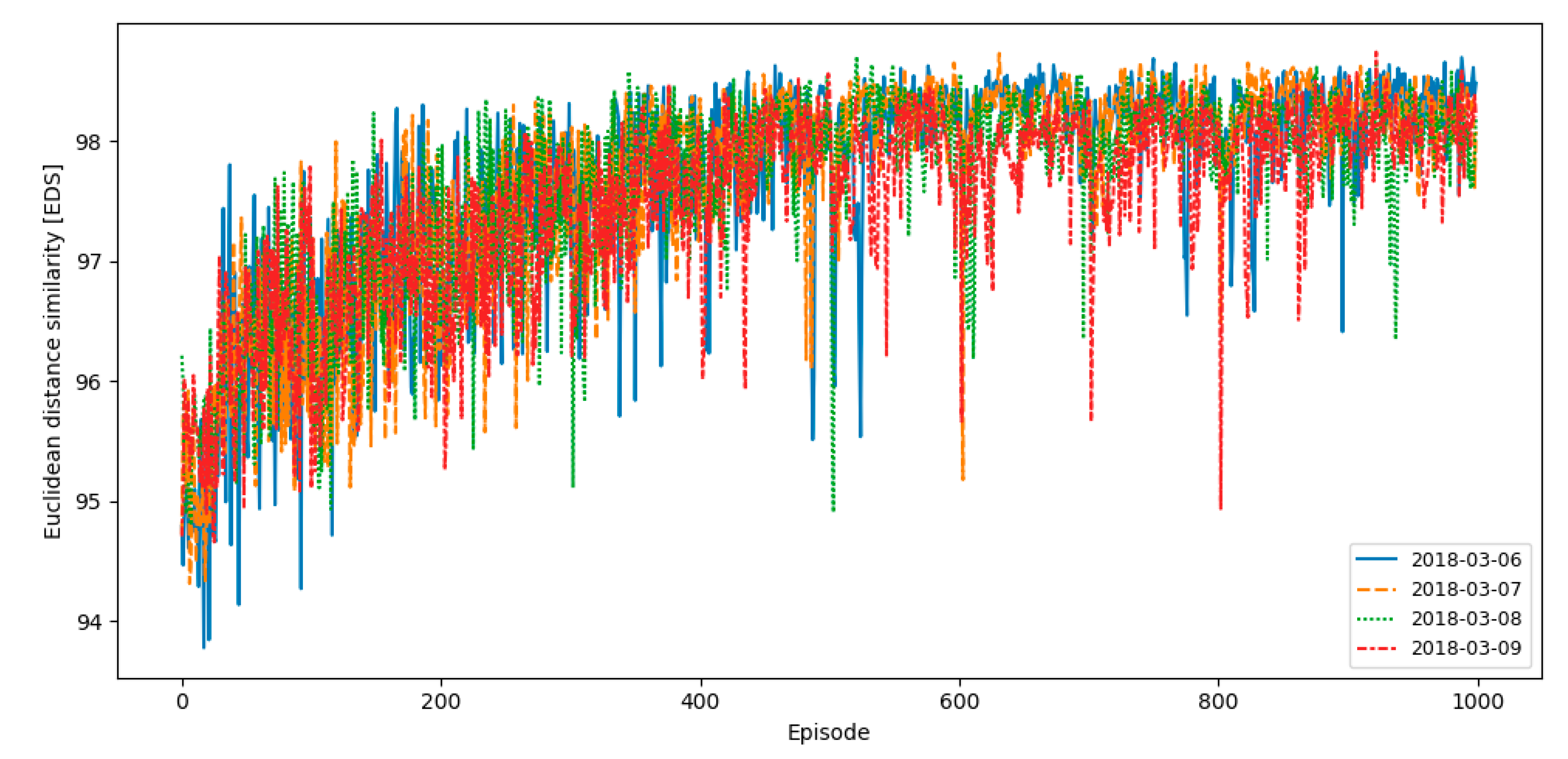
A reward should be provided if the loads of the target day and selected days are similar and should not be provided if the loads are not similar. The EDS is calculated using the loads of the target day and selected days from Equation (4). In the proposed algorithm, the environment calculates the EDS from the past few days. A reward may or may not be provided, depending on whether a selected day is in the top three selected days.
3.2. Deep Q-Network Training Algorithm
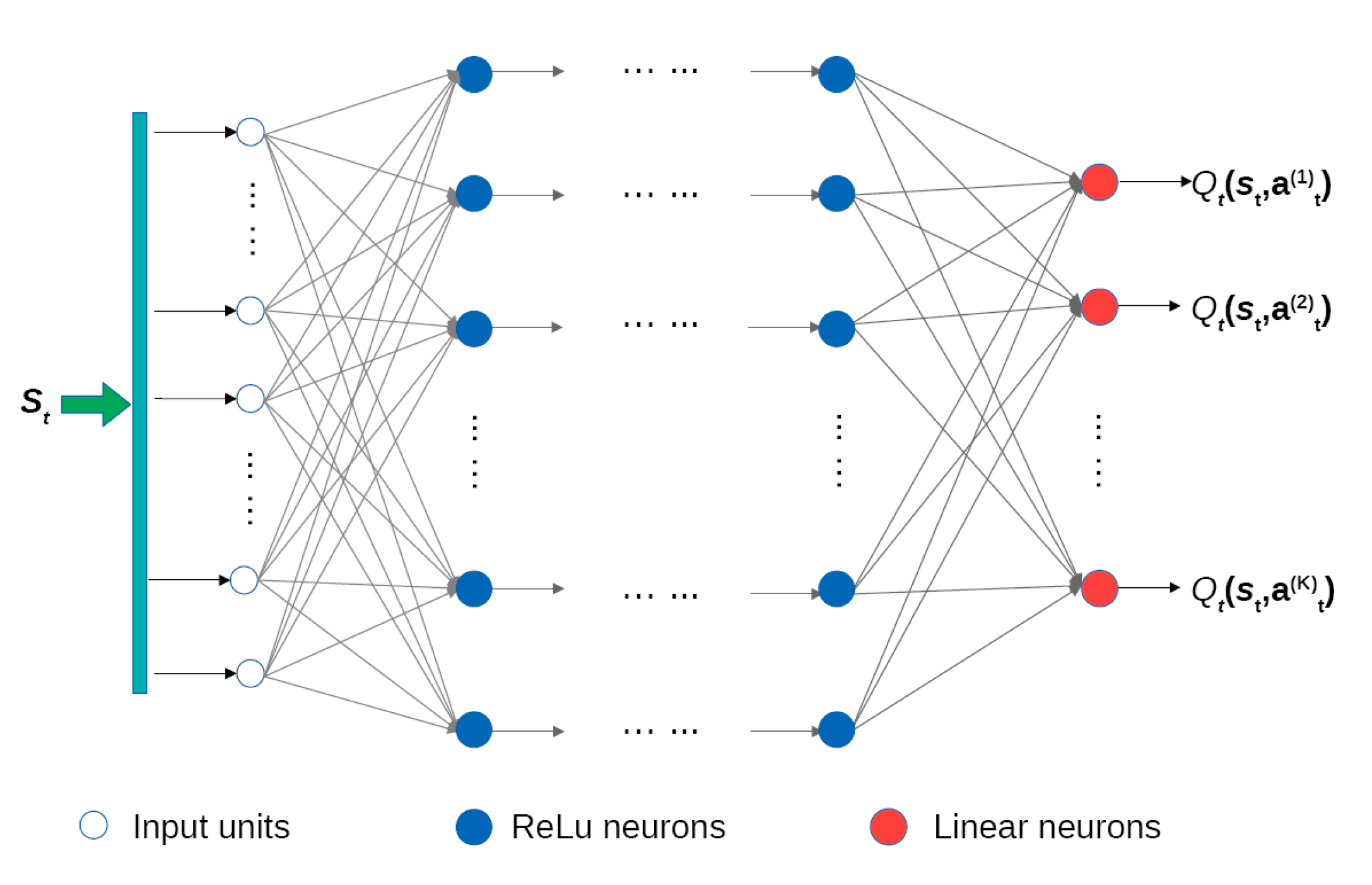
In this section, the DQN used to select a similar day is defined and an explanation is provided for the training method of the DQN. The proposed method is developed based on the DQN approach, among a number of different reinforcement methods. The DQN algorithm uses the Q-function as a state–action value function that can be approximated by the deep feedforward neural network structure [
30]. The state–action value function expresses the expected cumulative reward, Q. This occurs when the agent selects action
according to policy
in current state
. Policy π denotes a rule of the agent that determines which action to perform depending on the observed state.
Figure 7 illustrates the structure of the deep feed forward neural network used to express the expected cumulative reward, Q, according to action
for state
.
The cumulative reward,
, can be expressed by applying Equation (9) with the reward at the current timestep,
, and the expected reward at the next timestep,
.
If the present value of the reward is higher than the reward expected in the future, Equation (9) can be expressed as Equation (10) by applying the discount factor:
If
is expressed as
when selecting the action to maximize the expected cumulative reward at timestep
, Equation (10) can be expressed as Equation (11) using the Bellman Equation [
34].
By assuming that an optimal cumulative reward,
, exists,
, can be expressed as Equation (12):
To make the random Q-function closer to the optimal Q-function through learning, the minimized loss function is defined as the difference between the Q-function and optimal Q-function. Loss function
can be determined using Equation (13):
As the optimal Q-function is unknown, it is replaced with the target Q-function. The target Q-function uses the random variables at the beginning of training. Then, it is periodically replaced with the best Q-function that is found during the learning period. If the target Q-function is denoted as
, the loss function can be expressed by Equation (14):
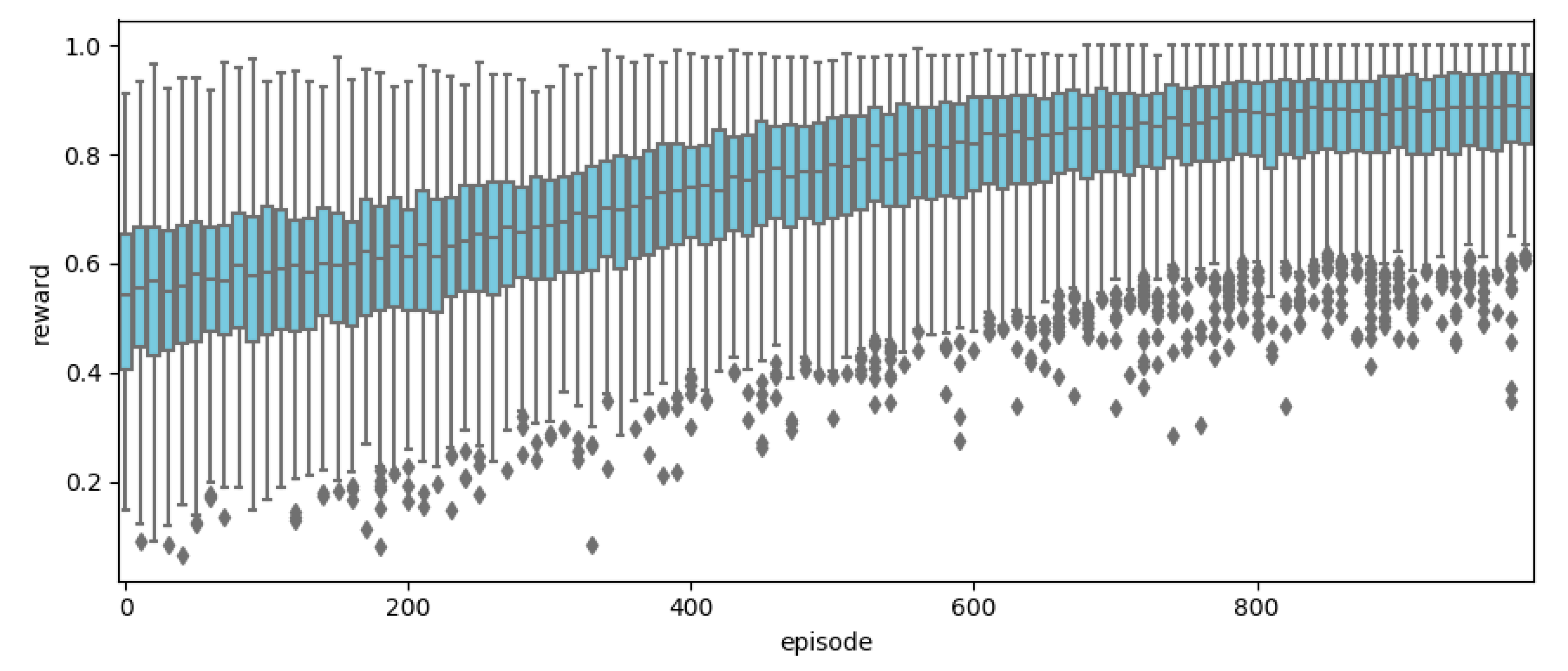
The epsilon-greedy exploration method is used because it is not possible to find the value of an unexperienced action if the agent is operated by the Q-function. This is the agent that typically works with the Q-function; however, the agent selects a random action according to the probability of epsilon ε. The epsilon of the proposed algorithm starts with a value of 0.3, and then it converges to zero as the learning progresses.
The performance of the agent is reduced by performing repetitive learning with only highly relevant samples; hence, an experience replay method is used. This method is conceptually similar to a minibatch, which is a method of storing the previous history of samples in memory. Random samples are selected and used during the learning period. The pseudocode of the proposed DQN algorithm is as follows:
| Algorithm 1. Q-network training algorithm for a similar day |
| Initialize: Replay memory D to capacity N |
| Initialize: Action Q-network with random weights |
| Initialize: Action Q-network with random weights |
| for episode = 1, M do |
| observe initial state use formulation (5) |
| for t = 1, T do |
| select an action a |
| with probability select a random action |
| else select action |
| observe and use formulation (4) |
| store experience <, , , > in replay memory D |
| sample random transitions <, , , > from D |
| set |
| train using as loss function |
| end for |
| update every 20th step |
| end for |

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}