Thermal-Aware Virtual Machine Allocation for Heterogeneous Cloud Data Centers


Abstract
:1. Introduction
- Creating a formal definition of optimal thermal-aware VM allocation by considering both computing and cooling energy consumption and providing a novel heuristic based on a genetic algorithm to obtain a near-optimal solution in less computing time;
- Designing a trade-off between the power-aware consolidation techniques and thermal-aware load balancing approaches to obtain higher energy savings in Cloud data centers;
- An extensive simulation-based evaluation and performance analysis of the proposed algorithm.
2. Related Work
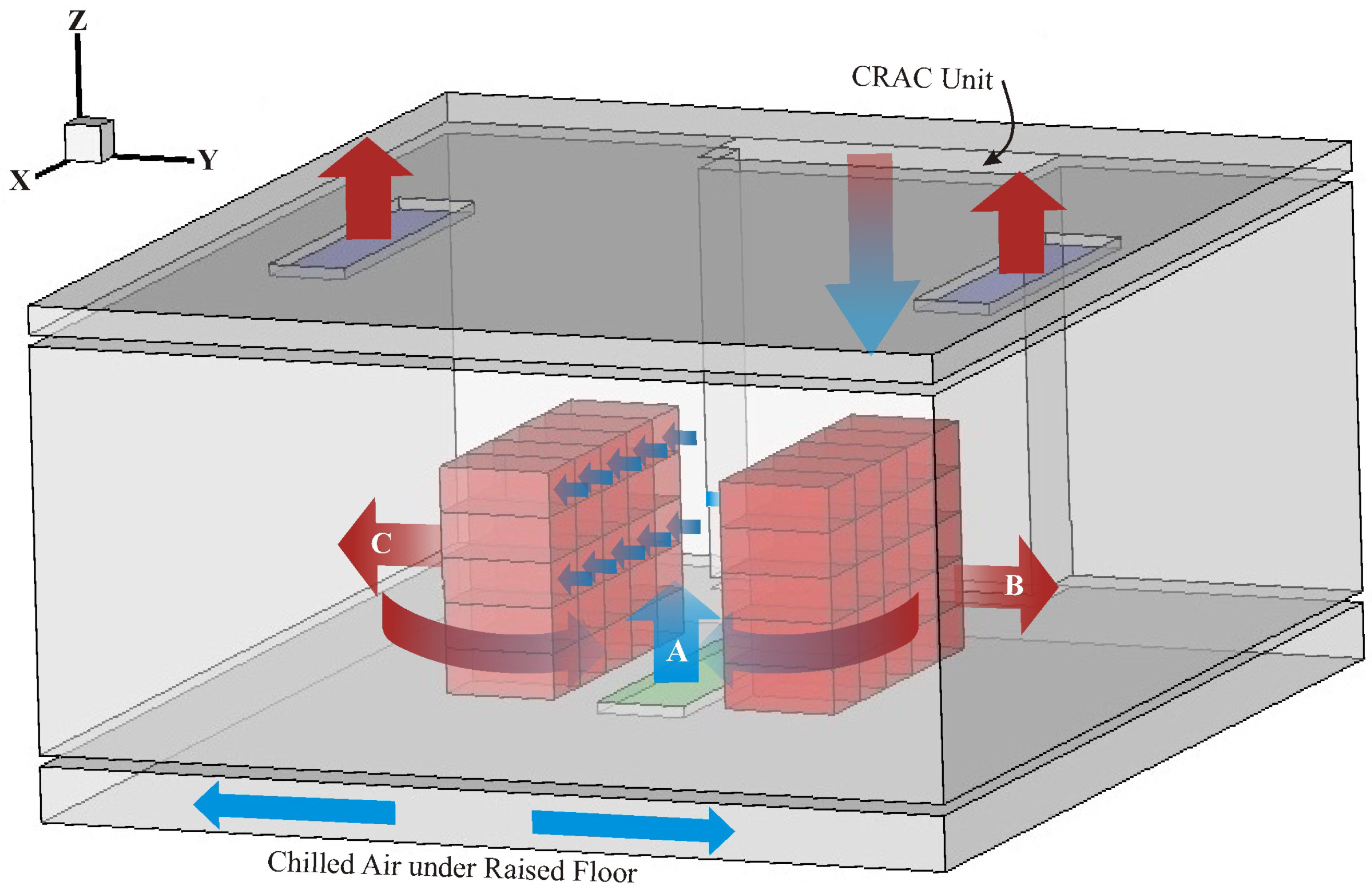
3. System Model
3.1. Layout of Data Center
3.2. Heat Recirculation Phenomena
3.3. Preliminaries
3.3.1. Cooling Efficiency of the CRAC Unit
3.3.2. VM Allocation and Power Model
3.3.3. Total Energy Consumption
4. Problem Formulation
5. The MITEC-GA Algorithm
- Selection: The roulette-wheel selection method is used to randomly select two parents from current population;
- Crossover: The new parents are generated by mixing selected chromosomes together and obtaining new allocations for some randomly selected VMs (lines 15–24);
- Mutation: The new solutions are formed by changing the new parents in a random way (lines 25–39).
| Algorithm 1 MITEC-GA |
|
6. Simulation Results
6.1. Simulation Setup
6.2. Simulation Results
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Senyo, P.K.; Addae, E.; Boateng, R. Cloud computing research: A review of research themes, frameworks, methods and future research directions. Int. J. Inf. Manag. 2018, 38, 128–139. [Google Scholar] [CrossRef] [Green Version]
- Amoretti, M.; Zanichelli, F.; Conte, G. Efficient autonomic cloud computing using online discrete event simulation. J. Parallel Distrib. Comput. 2013, 73, 767–776. [Google Scholar] [CrossRef]
- Basmadjian, R. Flexibility-Based Energy and Demand Management in Data Centers: A Case Study for Cloud Computing. Energies 2019, 12, 3301. [Google Scholar] [CrossRef] [Green Version]
- Georgilakis, P.S. Review of Computational Intelligence Methods for Local Energy Markets at the Power Distribution Level to Facilitate the Integration of Distributed Energy Resources: State-of-the-art and Future Research. Energies 2020, 13, 186. [Google Scholar] [CrossRef] [Green Version]
- Shuja, J.; Gani, A.; Shamshirband, S.; Ahmad, R.W.; Bilal, K. Sustainable cloud data centers: A survey of enabling techniques and technologies. Renew. Sustain. Energy Rev. 2016, 62, 195–214. [Google Scholar] [CrossRef]
- Sebastio, S.; Trivedi, K.S.; Alonso, J. Characterizing machines lifecycle in google data centers. Perform. Eval. 2018, 126, 39–63. [Google Scholar] [CrossRef]
- Hameed, A.; Khoshkbarforoushha, A.; Ranjan, R.; Jayaraman, P.P.; Kolodziej, J.; Balaji, P.; Zeadally, S.; Malluhi, Q.M.; Tziritas, N.; Vishnu, A.; et al. A survey and taxonomy on energy efficient resource allocation techniques for cloud computing systems. Computing 2016, 98, 751–774. [Google Scholar] [CrossRef]
- Malla, S.; Christensen, K. A survey on power management techniques for oversubscription of multi-tenant data centers. ACM Comput. Surv. (CSUR) 2019, 52, 1–31. [Google Scholar] [CrossRef]
- Avgerinou, M.; Bertoldi, P.; Castellazzi, L. Trends in data centre energy consumption under the european code of conduct for data centre energy efficiency. Energies 2017, 10, 1470. [Google Scholar] [CrossRef]
- Diouani, S.; Medromi, H. Survey: An Optimized Energy Consumption of Resources in Cloud Data Centers. Int. J. Comput. Sci. Inf. Secur. (IJCSIS) 2018, 16. [Google Scholar]
- Yeo, S.; Lee, H.H. Using mathematical modeling in provisioning a heterogeneous cloud computing environment. Computer 2011, 44, 55–62. [Google Scholar]
- Wu, C.J. Architectural thermal energy harvesting opportunities for sustainable computing. IEEE Comput. Archit. Lett. 2014, 13, 65–68. [Google Scholar] [CrossRef]
- Naserian, E.; Ghoreyshi, S.M.; Shafiei, H.; Mousavi, P.; Khonsari, A. Cooling aware job migration for reducing cost in cloud environment. J. Supercomput. 2015, 71, 1018–1037. [Google Scholar] [CrossRef]
- Lee, E.K.; Viswanathan, H.; Pompili, D. Proactive thermal-aware resource management in virtualized HPC cloud datacenters. IEEE Trans. Cloud Comput. 2017, 5, 234–248. [Google Scholar] [CrossRef]
- Liu, L.; Li, C.; Sun, H.; Hu, Y.; Xin, J.; Zheng, N.; Li, T. Leveraging heterogeneous power for improving datacenter efficiency and resiliency. IEEE Comput. Archit. Lett. 2015, 14, 41–45. [Google Scholar] [CrossRef]
- Li, Y.; Wang, X.; Luo, P.; Pan, Q. Thermal-aware hybrid workload management in a green datacenter towards renewable energy utilization. Energies 2019, 12, 1494. [Google Scholar] [CrossRef] [Green Version]
- Nada, S.; Said, M. Effect of CRAC units layout on thermal management of data center. Appl. Therm. Eng. 2017, 118, 339–344. [Google Scholar] [CrossRef]
- Bai, Y.; Gu, L. Chip temperature-based workload allocation for holistic power minimization in air-cooled data center. Energies 2017, 10, 2123. [Google Scholar] [CrossRef] [Green Version]
- Moazamigoodarzi, H.; Gupta, R.; Pal, S.; Tsai, P.J.; Ghosh, S.; Puri, I.K. Modeling temperature distribution and power consumption in IT server enclosures with row-based cooling architectures. Appl. Energy 2020, 261, 114355. [Google Scholar] [CrossRef]
- He, Z.; He, Z.; Zhang, X.; Li, Z. Study of hot air recirculation and thermal management in data centers by using temperature rise distribution. In Building Simulation; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9, pp. 541–550. [Google Scholar]
- Patel, C.D.; Bash, C.E.; Belady, C.; Stahl, L.; Sullivan, D. Computational fluid dynamics modeling of high compute density data centers to assure system inlet air specifications. In Proceedings of the Pacific Rim ASME International Electronic Packaging Technical Conference and Exhibition (IPACK), Kauai, HI, USA, 8–13 July 2001; pp. 8–13. [Google Scholar]
- Moore, J.; Chase, J.S.; Ranganathan, P. Weatherman: Automated, online and predictive thermal mapping and management for data centers. In Proceedings of the IEEE International Conference on Autonomic Computing (ICAC), Dublin, Ireland, 13–16 June 2006; pp. 155–164. [Google Scholar]
- Sharma, R.K.; Bash, C.E.; Patel, R.D. Dimensionless Parameters For Evaluation Of Thermal Design And Performance Of Large-Scale Data Centers. In Proceedings of the 8th ASME/AIAA Joint Thermophysics and Heat Transfer Conference, St Louis, MO, USA, 24–26 June 2002; pp. 1–11. [Google Scholar]
- Ferreto, T.C.; Netto, M.A.S.; Calheiros, R.N.; De Rose, C.A.F. Server consolidation with migration control for virtualized data centers. J. Future Gener. Comput. Syst. 2011, 27, 1027–1034. [Google Scholar] [CrossRef]
- Cioara, T.; Anghel, I.; Salomie, I. Methodology for energy aware adaptive management of virtualized data centers. Energy Effic. 2017, 10, 475–498. [Google Scholar] [CrossRef]
- Raj, V.M.; Shriram, R. Power management in virtualized datacenter–A survey. J. Netw. Comput. Appl. 2016, 69, 117–133. [Google Scholar] [CrossRef]
- Rosikiewicz, J.; McKelvey, R.T.; Mittell, A.D. Virtual Machine Data Replication. U.S. Patent 8,135,748, 2012. [Google Scholar]
- Li, H.; Zhu, G.; Cui, C.; Tang, H.; Dou, Y.; He, C. Energy-efficient migration and consolidation algorithm of virtual machines in data centers for cloud computing. Computing 2016, 98, 303–317. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Di Francesco, M.; Yla-Jaaski, A. Virtual machine consolidation with multiple usage prediction for energy-efficient cloud data centers. IEEE Trans. Serv. Comput. 2017. [Google Scholar]
- Farahnakian, F.; Pahikkala, T.; Liljeberg, P.; Plosila, J.; Hieu, N.T.; Tenhunen, H. Energy-aware VM consolidation in cloud data centers using utilization prediction model. IEEE Trans. Cloud Comput. 2016. [Google Scholar] [CrossRef]
- Shirvani, M.H.; Rahmani, A.M.; Sahafi, A. A survey study on Virtual Machine migration and server consolidation techniques in DVFS-enabled cloud datacenter: Taxonomy and challenges. J. King Saud-Univ. Comput. Inf. Sci. 2020, 32, 267–286. [Google Scholar]
- Wang, S.; Qian, Z.; Yuan, J.; You, I. A DVFS based energy-efficient tasks scheduling in a data center. IEEE Access 2017, 5, 13090–13102. [Google Scholar] [CrossRef]
- Ghoreyshi, S.M. Energy-efficient resource management of cloud datacenters under fault tolerance constraints. In Proceedings of the 2013 International Green Computing Conference Proceedings, Arlington, VA, USA, 27–29 June 2013; pp. 1–6. [Google Scholar]
- Pakbaznia, E.; Pedram, M. Minimizing data center cooling and server power costs. In Proceedings of the 14th ACM/IEEE International Symposium on Low Power Electronics and Design, San Fancisco, CA, USA, 19–21 August 2009; pp. 145–150. [Google Scholar]
- Lin, M.; Wierman, A.; Andrew, L.L.; Thereska, E. Dynamic right-sizing for power-proportional data centers. In Proceedings of the 2011 IEEE INFOCOM, Shanghai, China, 10–15 April 2011; pp. 1098–1106. [Google Scholar]
- Chen, Y.; Das, A.; Qin, W.; Sivasubramaniam, A.; Wang, Q.; Gautam, N. Managing server energy and operational costs in hosting centers. In Proceedings of the 2005 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems, Banff, AB, Canada, 6–10 June 2005; pp. 303–314. [Google Scholar]
- Lucchese, R. Cooling Control Strategies in Data Centers for Energy Efficiency and Heat Recovery; Luleå University of Technology: Luleå, Sweden, 2019. [Google Scholar]
- Beitelmal, A.H.; Patel, C.D. Thermo-fluids provisioning of a high performance high density data center. J. Distrib. Parallel Databases 2007, 21, 227–238. [Google Scholar] [CrossRef]
- Moore, J.D.; Chase, J.S.; Ranganathan, P.; Sharma, R.K. Making scheduling "Cool": Temperature-aware workload placement in data centers. In Proceedings of the 2005 USENIX Annual Technical Conference, Anaheim, CA, USA, 10–15 April 2005; pp. 61–75. [Google Scholar]
- Patel, C.D.; Bash, C.E.; Sharma, R.; Beitelmal, M.; Friedrich, R. Smart Cooling of Data Centers. In Proceedings of the Pacific RIM/ASME International Electronics Packaging Technical Conference and Exhibition (IPACK), Maui, HI, USA, 6–11 July 2003; pp. 129–137. [Google Scholar]
- Bash, C.E.; Patel, C.D.; Sharma, R.K. Efficient thermal management of data centers—Immediate and long-term research needs. J. HVAC&R Res. 2003, 9, 137–152. [Google Scholar]
- Sharma, R.K.; Bash, C.E.; Patel, C.D.; Friedrich, R.J.; Chase, J.S. Balance of power: Dynamic thermal management for Internet data centers. IEEE Internet Comput. 2005, 9, 42–49. [Google Scholar] [CrossRef] [Green Version]
- Tang, Q.; Mukherjee, T.; Gupta, S.K.S.; Cayton, P. Sensor-based fast thermal evaluation model for energy efficient high-performance datacenters. In Proceedings of the Fourth International Conference on Intelligent Sensing and Information Processing (ICISIP), Bangalore, India, 15–18 December 2006; pp. 203–208. [Google Scholar]
- Tang, Q.; Gupta, S.K.; Varsamopoulos, G. Energy-efficient thermal-aware task scheduling for homogeneous high-performance computing data centers: A cyber-physical approach. IEEE Trans. Parallel Distrib. Syst. 2008, 19, 1458–1472. [Google Scholar] [CrossRef]
- Pakbaznia, E.; Ghasemazar, M.; Pedram, M. Temperature-aware dynamic resource provisioning in a power-optimized datacenter. In Proceedings of the Conference on Design, Automation and Test in Europe (DATE), Dresden, Germany, 8–12 March 2010; pp. 124–129. [Google Scholar]
- Abbasi, Z.; Varsamopoulos, G.; Gupta, S.K.S. Thermal aware server provisioning and workload distribution for internet data centers. In Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing (HPDC), Chicago, IL, USA, 21–25 June 2010; pp. 130–141. [Google Scholar]
- Tang, X.; Liao, X.; Zheng, J.; Yang, X. Energy efficient job scheduling with workload prediction on cloud data center. Clust. Comput. 2018, 21, 1581–1593. [Google Scholar] [CrossRef]
- Sun, X.; Su, S.; Xu, P.; Jiang, L. Optimizing multi-dimensional resource utilization in virtual data center. In Proceedings of the 2011 4th IEEE International Conference on Broadband Network and Multimedia Technology, Shenzhen, China, 28–30 October 2011; pp. 395–400. [Google Scholar]
- Sun, X.; Su, S.; Xu, P.; Chi, S.; Luo, Y. Multi-dimensional resource integrated scheduling in a shared data center. In Proceedings of the 2011 31st International Conference on Distributed Computing Systems Workshops, Minneapolis, MN, USA, 20–24 June 2011; pp. 7–13. [Google Scholar]
- Mukherjee, T.; Banerjee, A.; Varsamopoulos, G.; Gupta, S.K.S.; Rungta, S. Spatio-temporal thermal-aware job scheduling to minimize energy consumption in virtualized heterogeneous data centers. J. Comput. Netw. 2009, 53, 2888–2904. [Google Scholar] [CrossRef]
- Beloglazov, A.; Buyya, R. Optimal online deterministic algorithms and adaptive heuristics for energy and performance efficient dynamic consolidation of virtual machines in Cloud data centers. J. Concurr. Comput. Pract. Exp. 2012, 24, 1397–1420. [Google Scholar] [CrossRef]
- Rasmussen, N. Implementing Energy Efficient Data Centers; American Power Conversion: South Kingstown, RI, USA, 2006. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of VMs | MinSumDTinlet | MinMaxTinlet | SimplePower | MinTinlet | LRH | MITEC-GA |
|---|---|---|---|---|---|---|
| 300 | 25 | 25 | 25 | 25 | 25 | 23 |
| 340 | 22 | 22 | 22 | 22 | 22 | 20 |
| 380 | 19 | 19 | 19 | 18 | 19 | 17 |
| 420 | 15 | 15 | 15 | 15 | 15 | 13 |
| 460 | 12 | 12 | 12 | 12 | 12 | 10 |
| 500 | 9 | 9 | 9 | 9 | 9 | 7 |
| 540 | 5 | 5 | 5 | 5 | 5 | 4 |
| 580 | 2 | 2 | 2 | 2 | 2 | 0 |
| 620 | 1 | 1 | 1 | 1 | 1 | 0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akbari, A.; Khonsari, A.; Ghoreyshi, S.M. Thermal-Aware Virtual Machine Allocation for Heterogeneous Cloud Data Centers. Energies 2020, 13, 2880. https://doi.org/10.3390/en13112880
Akbari A, Khonsari A, Ghoreyshi SM. Thermal-Aware Virtual Machine Allocation for Heterogeneous Cloud Data Centers. Energies. 2020; 13(11):2880. https://doi.org/10.3390/en13112880
Chicago/Turabian StyleAkbari, Abbas, Ahmad Khonsari, and Seyed Mohammad Ghoreyshi. 2020. "Thermal-Aware Virtual Machine Allocation for Heterogeneous Cloud Data Centers" Energies 13, no. 11: 2880. https://doi.org/10.3390/en13112880