Application of Norm Optimal Iterative Learning Control to Quadrotor Unmanned Aerial Vehicle for Monitoring Overhead Power System


Abstract
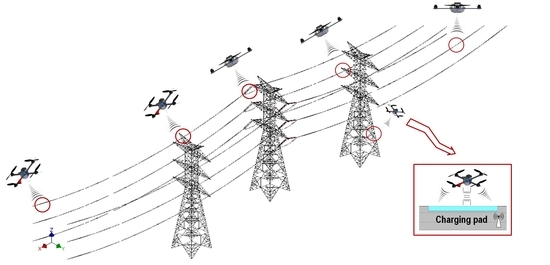
1. Introduction
2. ILC Controllers
2.1. Basic ILC
2.2. Optimal Approach ILCs
2.2.1. Gradient-Based Iterative Learning Control
2.2.2. Norm Optimal ILC
3. ILC Design and Application to Quadrotor
- I.
- The system is presumed to operate in a repetitive manner (iteratively) for both optimal algorithms, G-ILC and NO-ILC.
- II.
- At the end of every iteration, the state is reset operation toward a particular repetition that have independent initial condition to the next operation.
- III.
- A new control signal might be utilized during this time. A reference signal, , is presumed to be known and the ultimate control objective is to determine an input function such the output function on .
- IV.
- For G-ILC, the value of the learning gain is heuristically selected for the first step, and then calculated automatically using the the gain by establishing the varying gain equations. The established variable will be repeated again for NO-ILC, but with a different learning gain .
- V.
- To guarantee error convergence, the necessary conditions are .
3.1. Gradient-Based ILC (G-ILC)
3.2. Norm Optimal ILC (NO-ILC)
3.3. Application to Quadrotors
4. Experimental Platform Selection
4.1. Physical Parameters
4.2. Test Bed
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| COG | Center Of Gravity |
| DOF | Degrees Of Freedom |
| G-ILC | Gradient-based Iterative Learning Control |
| GPS | Global Positioning System |
| ILC | Iterative Learning Control |
| IMU | Inertial Measurement Unit |
| LiPo | Lithium Polymer |
| LQG | Linear Quadratic Regulation |
| MIMO | Multi Input Multi Output |
| MIT | Massachusetts Institute of Technology |
| MPC | Model Predictive control |
| NO-ILC | Norm Optimal Iterative Learning Control |
| PD | Proportional Derivative |
| PID | Proportional Integral Derivative |
| SISO | Single Input Single Output |
| SMC | Sliding Mode Control |
| UAV | Unmanned Aerial Vehicle |
References
- Dehghanian, P.; Aslan, S.; Dehghanian, P. Maintaining electric system safety through an enhanced network resilience. IEEE Trans. Ind. Appl. 2018, 54, 4927–4937. [Google Scholar] [CrossRef]
- Kogan, V.I.; Gursky, R.J. Transmission towers inventory. IEEE Trans. Power Deliv. 1996, 11, 1842–1852. [Google Scholar] [CrossRef]
- Moradkhani, A.; Haghifam, M.R.; Mohammadzadeh, M. Failure rate modelling of electric distribution overhead lines considering preventive maintenance. IET Gener. Transm. Distrib. 2014, 8, 1028–1038. [Google Scholar] [CrossRef]
- Na, H.J.; Yoo, S.J. PSO-based dynamic UAV positioning algorithm for sensing information acquisition in Wireless Sensor Networks. IEEE Access 2019, 7, 77499–77513. [Google Scholar] [CrossRef]
- Davis, E.; Pounds, P.E. Direct sensing of thrust and velocity for a quadrotor rotor array. IEEE Robot. Autom. Lett. 2017, 2, 1360–1366. [Google Scholar] [CrossRef]
- Zhong, M.; Cao, Q.; Guo, J.; Zhou, D. Simultaneous lever-arm compensation and disturbance attenuation of POS for a UAV surveying system. IEEE Trans. Instrum. Meas. 2016, 65, 2828–2839. [Google Scholar] [CrossRef]
- Wang, Q.; Xiong, H.; Qiu, B. The Attitude Control of Transmission Line Fault Inspection UAV Based on ADRC. In Proceedings of the International Conference on Industrial Informatics-Computing Technology, Intelligent Technology, Industrial Information Integration (ICIICII), Nicosia, Cyprus, 27–29 September 2017; pp. 186–189. [Google Scholar]
- Menéndez, O.; Pérez, M.; Auat Cheein, F. Visual-based positioning of aerial maintenance platforms on overhead transmission lines. Appl. Sci. 2019, 9, 165. [Google Scholar] [CrossRef]
- Jones, D. Power line inspection-a UAV concept. In Proceedings of the IEE Forum on Autonomous Systems, London, UK, 28 November 2005; p. 8. [Google Scholar]
- Bouabdallah, S.; Murrieri, P.; Siegwart, R. Design and control of an indoor micro quadrotor. IEEE Int. Conf. Robot. Autom. 2004, 5, 4393–4398. [Google Scholar]
- Ren, J.; Liu, D.X.; Li, K.; Liu, J.; Feng, Y.; Lin, X. Cascade PID controller for quadrotor. In Proceedings of the 2016 IEEE International Conference on Information and Automation (ICIA), Ningbo, China, 1–3 August 2016; pp. 120–124. [Google Scholar]
- Bouabdallah, S.; Noth, A.; Siegwart, R. PID vs. LQ control techniques applied to an indoor micro quadrotor. IEEE/RSJ Int. Conf. Intell. Robot. Syst. (IROS) 2004, 3, 2451–2456. [Google Scholar]
- Shaik, M.K.; Whidborne, J.F. Robust sliding mode control of a quadrotor. In Proceedings of the 2016 UKACC 11th International Conference on Control (CONTROL), Belfast, UK, 31 August–2 September 2016. [Google Scholar]
- Tan, L.; Lu, L.; Jin, G. Attitude stabilization control of a quadrotor helicopter using integral backstepping. In Proceedings of the International Conference on Automatic Control and Artificial Intelligence, Xiamen, China, 24–26 March 2012; pp. 573–577. [Google Scholar]
- Nandong, J. A unified design for feedback-feedforward control system to improve regulatory control performance. Int. J. Control Autom. Syst. 2015, 13, 91–98. [Google Scholar] [CrossRef]
- Ahn, H.S.; Chen, Y.; Moore, K.L. Iterative learning control: Brief survey and categorization. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2007, 37, 1099–1121. [Google Scholar] [CrossRef]
- Ke, C.; Ren, J.; Quan, Q. Saturated D-type ILC for Multicopter Trajectory Tracking Based on Additive State Decomposition. In Proceedings of the IEEE 7th Data Driven Control and Learning Systems Conference (DDCLS), Enshi, China, 25–27 May 2018; pp. 1146–1151. [Google Scholar]
- Dong, J.; He, B. Novel fuzzy PID-type iterative learning control for quadrotor UAV. Sensors 2019, 19, 24. [Google Scholar] [CrossRef] [PubMed]
- Koçan, O.; Manecy, A.; Poussot-Vassal, C. A Practical Method to Speed-up the Experimental Procedure of Iterative Learning Controllers. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 6411–6416. [Google Scholar]
- Li, X.; Ren, Q.; Xu, J.X. Precise Speed Tracking Control of a Robotic Fish Via Iterative Learning Control. IEEE Trans. Ind. Electron. 2016, 63, 2221–2228. [Google Scholar] [CrossRef]
- Meng, D.; Moore, K.L. Learning to cooperate: Networks of formation agents with switching topologies. Automatica 2016, 64, 278–293. [Google Scholar] [CrossRef]
- Chen, T.; Shan, J. Distributed control of multiple flexible manipulators with unknown disturbances and dead-zone input. IEEE Trans. Ind. Electron. 2019. [Google Scholar] [CrossRef]
- Bristow, D.A.; Tharayil, M.; Alleyne, A.G. A survey of iterative learning control. IEEE Control Syst. Mag. 2006, 26, 96–114. [Google Scholar]
- Moore, K.L. Iterative Learning Control for Deterministic Systems; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Gao, F.; Chen, W.; Li, Z.; Li, J.; Xu, B. Neural Network-Based Distributed Cooperative Learning Control for Multiagent Systems via Event-Triggered Communication. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 407–419. [Google Scholar] [CrossRef]
- He, W.; Meng, T.; He, X.; Sun, C. Iterative Learning Control for a Flapping Wing Micro Aerial Vehicle under Distributed Disturbances. IEEE Trans. Cybern. 2019, 49, 1524–1535. [Google Scholar] [CrossRef]
- Ren, J.; Quan, Q.; Liu, C.; Cai, K.-Y. Docking control for probe-drogue refueling: An additive-state-decomposition-based output feedback iterative learning control method. Chin. J. Aeronaut. 2019, 33, 1016–1025. [Google Scholar] [CrossRef]
- Hock, A.; Schoellig, A.P. Distributed iterative learning control for a team of quadrotors. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; pp. 4640–4646. [Google Scholar]
- Pipatpaibul, P.I.; Ouyang, P.R. Application of online iterative learning tracking control for quadrotor UAVs. ISRN Robot. 2013. [Google Scholar] [CrossRef]
- Zhaowei, M.; Tianjiang, H.; Lincheng, S.; Weiwei, K.; Boxin, Z.; Kaidi, Y. An iterative learning controller for quadrotor UAV path following at a constant altitude. In Proceedings of the 2015 34th Chinese Control Conference (CCC), Hangzhou, China, 28–30 July 2015; pp. 4406–4411. [Google Scholar]
- Giernacki, W. Iterative learning method for in-flight auto-tuning of UAV controllers based on basic sensory information. Appl. Sci. 2019, 9, 648. [Google Scholar] [CrossRef]
- Schoellig, A.P.; Mueller, F.L.; D’Andrea, R. Optimization-based iterative learning for precise quadrocopter trajectory tracking. Auton. Robots 2012, 33, 103–127. [Google Scholar] [CrossRef]
- Devasia, S. Iterative Machine Learning for Output Tracking. IEEE Trans. Control Syst. Technol. 2019, 27, 516–526. [Google Scholar] [CrossRef]
- Foudeh, H.A.; Luk, P.; Whidborne, J.F. Quadrotor System Design for a 3 DOF platform based on Iterative Learning Control. In Proceedings of the 2019 Workshop on Research, Education and Development of Unmanned Aerial Systems (RED UAS), Cranfield, UK, 25–27 November 2019; pp. 53–59. [Google Scholar]
- Altın, B.; Wang, Z.; Hoelzle, D.J.; Barton, K. Robust Monotonically Convergent Spatial Iterative Learning Control: Interval Systems Analysis via Discrete Fourier Transform. IEEE Trans. Control Syst. Technol. 2019, 27, 2470–2483. [Google Scholar] [CrossRef]
- Wang, Y.; Dassau, E.; Doyle, F.J., III. Closed-loop control of artificial pancreatic β-cell in type 1 diabetes mellitus using model predictive iterative learning control. IEEE Trans. Biomed. Eng. 2009, 57, 211–219. [Google Scholar] [CrossRef] [PubMed]
- Barton, K.; Van De Wijdeven, J.; Alleyne, A.; Bosgra, O.; Steinbuch, M. Norm optimal cross-coupled iterative learning control. In Proceedings of the IEEE Conference on Decision and Control, Cancun, Mexico, 9–11 December 2008; pp. 3020–3025. [Google Scholar]
- Yang, X.; Ruan, X. Reinforced gradient-type iterative learning control for discrete linear time-invariant systems with parameters uncertainties and external noises. IMA J. Math. Control. Inf. 2017, 34, 1117–1133. [Google Scholar] [CrossRef]
- Gu, P.; Tian, S.; Chen, Y. Iterative Learning Control Based on Nesterov Accelerated Gradient Method. IEEE Access 2019, 7, 115836–115842. [Google Scholar] [CrossRef]
- Liu, S.; Wu, T.J. Robust Iterative Learning Control Design Based on Gradient Method. IFAC Proc. Vol. 2004, 37, 613–618. [Google Scholar] [CrossRef]
- Li, X.; Ruan, X.; Liu, Y. Learning-Gain-Adaptive Iterative Learning Control to Linear Discrete-Time-Invariant Systems. IEEE Access 2019, 7, 98934–98945. [Google Scholar] [CrossRef]
- Lv, Y.; Chi, R. Data-driven adaptive iterative learning predictive control. In Proceedings of the 2017 6th Data Driven Control and Learning Systems (DDCLS), Chongqing, China, 26–27 May 2017; pp. 374–377. [Google Scholar]
- Ratcliffe, Y.; Ruan, X.; Li, X. Optimized Iterative Learning Control for Linear Discrete-Time-Invariant Systems. IEEE Access 2019, 7, 75378–75388. [Google Scholar]
- Karwoski, K. Quadrocopter Control Design and Flight Operation; NASA USRP—Internship Final Report; Marshall Space Flight Center: Huntsville, AL, USA, 2011.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Platform | AscTec HB. UAV |
| The Producer | AscTec GmbH + Intel |
| Take-off Weight | 480 g |
| Battery | 2100 mAh LiPo |
| Distance between motors | 34 cm |
| Propeller | Standard propellers (8), flexible (PP) plastics |
| Motors | HACKER Motors Germany (X-BL 52 s) |
| Motor Controllers | X-BLDC controllers |
| Transmitter | Futaba 2.4 GHz |
| Wireless Link | Xbee 2.4 GHz |
| Parameters | Description | Value | Unit |
|---|---|---|---|
| x axis-Moment Inertia | × | kg·m | |
| y axis-Moment of Inertia | × | kg·m | |
| z axis-Moment of Inertia | × | kg·m | |
| Rotor Inertia | 47 × | kg·m | |
| m | Mass | 0.547 | kg |
| l | Arm Length | 0.168 | m |
| g | Gravitational constant | 9.81 | ms |
| Maximum rotor speed | 200 | rad/s |
| ILC Approaches | Passes No. | ||
|---|---|---|---|
| G-ILC (without disturbance) | 1 | 1.92 | 1.92 |
| 3 | 1.38 | 1.38 | |
| 6 | 0.532 | 0.532 | |
| 16 | 0.309 | 0.303 | |
| NO-ILC (without disturbance) | 1 | 1.92 | 1.92 |
| 3 | 1.24 | 1.24 | |
| 6 | 0.476 | 0.476 | |
| 16 | 0.121 | 0.119 |
| ILC Approaches | Trial (1) | Trial (3) | Trial (7) | Trial (10) | ||||
|---|---|---|---|---|---|---|---|---|
| G-ILC + Disturbance Injection | 1.277 | 2.834 | 0.920 | 1.281 | 0.612 | 0.705 | 0.574 | 0.534 |
| NO-ILC + Disturbance Injection | 1.283 | 3.214 | 0.926 | 1.212 | 0.562 | 0.633 | 0.434 | 0.446 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Foudeh, H.A.; Luk, P.; Whidborne, J. Application of Norm Optimal Iterative Learning Control to Quadrotor Unmanned Aerial Vehicle for Monitoring Overhead Power System. Energies 2020, 13, 3223. https://doi.org/10.3390/en13123223
Foudeh HA, Luk P, Whidborne J. Application of Norm Optimal Iterative Learning Control to Quadrotor Unmanned Aerial Vehicle for Monitoring Overhead Power System. Energies. 2020; 13(12):3223. https://doi.org/10.3390/en13123223
Chicago/Turabian StyleFoudeh, Husam A., Patrick Luk, and James Whidborne. 2020. "Application of Norm Optimal Iterative Learning Control to Quadrotor Unmanned Aerial Vehicle for Monitoring Overhead Power System" Energies 13, no. 12: 3223. https://doi.org/10.3390/en13123223
APA StyleFoudeh, H. A., Luk, P., & Whidborne, J. (2020). Application of Norm Optimal Iterative Learning Control to Quadrotor Unmanned Aerial Vehicle for Monitoring Overhead Power System. Energies, 13(12), 3223. https://doi.org/10.3390/en13123223