1. Introduction
There are generally two typical integration forms of wind power into power systems: centralized and distributed. Distributed wind farms do not transport wind power over large-scale long-distance transmission lines, they are directly provided to the load center of the power system [
1,
2], and the generated electricity is consumed locally. Distributed wind power (DWP) has become an effective solution for improving China’s environmental issues, and it will be an important form of wind power integration into the power grid.
For the development and construction of DWP projects, China’s 2018 document [
3] presented that the DWP needs to be locally consumed through a 110 kV network with no power delivery at higher voltage levels, and the installed DWP capacity limit should be based on the lowest consumption of load. There is no doubt that this capacity planning principle for DWP will reduce the use rate of wind power greatly, lead to waste of wind resources, and decrease the revenue of wind power industries, further hindering the development of DWP.
At present, many effective models and algorithms for wind power planning in distribution networks have been explored [
4,
5,
6]. A multi-objective DWP planning model was proposed in [
7] to meet the operation of unbalanced distribution systems, and the decision framework provided in [
8] could optimize DWP planning through technology selection. These studies provide a good reference for further development of wind power in the distribution system.
To comply with the regulations under the premise of local consumption in the distribution system without reverse power flow, it is necessary to further investigate the correlation between DWP and load. At present, Nataf inverse transformation [
9,
10] and the correlation coefficient matrix method [
11] are usually employed for multivariable correlation analysis. However, the correlation feature or correlation matrix between random variables must be determined in advance. When the correlation between variables is complex or the features are not obvious, the fitting effect with the above commonly used models is usually not good. In addition, it is also necessary to take into consideration different scenarios of DWP and load because of their stochastic characteristics [
12,
13,
14]. In [
15], the correlation among historical wind, photovoltaic power and electricity demand and the random moments is captured by generating a scenario matrix, but the variable structure is not sufficiently considered. In view of the above issues, copula theory [
16] is employed in this work to better describe the correlation between DWP and load, and at different time segments, a variable-structure copula model is established to construct the correlation between DWP and load.
To follow the principle of no reverse power flow to higher voltage level and make the best consumption of renewable resources, one effective way is to bring in the energy storage system (ESS) at the planning stage [
17,
18,
19]. A joint optimization in [
17] was proposed to plan the capacity and location of ESS, and distributed generating units in a stand-alone micro-grid were presented. These studies mainly implement collaborative planning from the perspective of economics and pricing-based demand response [
20], thus providing a good reference for this paper. Still, the consideration of construction investment, system line loss cost and the maintenance cost of ESS as part of the model’s objective requires further improvement. Based on the above research, this paper takes the network line loss, the investment operation cost and environmental income, and the time-of-day tariff into the objective functions of the planning strategy, and prospectively proposes a feasible collaborative capacity planning model of DWP and ESS. This paper contributes as follows:
(1) To describe the tail correlation and the change of correlation between DWP and load, a variable- structure copula model is employed. In this paper, the variable-structure copula models are constructed using two different time division methods (monthly and quarterly), and strategies are evaluated by constructing an empirical copula model.
(2) Based on the correlation model of the variable-structure copula, the typical scenarios containing correlation information are obtained through the clustering method, and then the DWP capacity planning model is constructed under the typical scenarios. Furthermore, in order to increase the consumption of DWP, a collaborative planning model is established for wind storage, and the consumption of wind power and the quality of voltage level are analyzed based on a typical schedule day.
The structure of this paper is as follows. In
Section 2, the autoregressive moving average model (ARMA) model for data prediction of DWP and load is introduced, the correlation of DWP and load based on the variable-structure copula is investigated, and joint typical scenarios are generated using the clustering method. In
Section 3, a novel capacity planning model of DWP is proposed under typical scenarios, and a collaborative capacity planning model is further established for DWP and ESS to increase the consumption of wind power. A case study is then carried out in
Section 4 based on practical data for wind farm and load.
Section 5 summarizes the findings.
2. Correlation Analysis between DWP and Load Based on a Variable-Structure Copula
The wind power output of a distributed wind farm should be consumed by its local load. Since DWP has the characteristics of intermittency and inverse peak shaving, the correlation between DWP and load consumption should be carefully investigated. In this section, a variable-structure copula model is employed to describe the joint density of DWP and local load. This method can well capture the nonlinear, asymmetry and tail correlation characteristics among variables, it can analyze the marginal distribution of each random variable individually, and can also illustrate the varied correlated structure between variables.
2.1. Data Preparation Based on an ARMA Model
To carry out the correlation study between DWP and load, the predicted data of DWP and local load in the planning stage are first obtained by ARMA model. The ARMA short-term prediction model includes the autoregressive part and the moving average part, and its formula is:
where
Yt is the value of DWP or load at point
t of series;
εt and
εt−i are the prediction error term at
t and
i time points ahead of
t, respectively;
α is the correlation coefficient, which reflects the dependence of the prediction error at different segments;
Yt−i is the value with
i time points ahead of
t;
β is the correlation coefficient;
p is the order of autoregressive process; and
q is the order of moving average process.
The order of the ARMA model can be determined by calculating the Akaike Information Criterion (AIC) value of the ARMA with different (p, q) pairs. The optimal ARMA (p, q) model is selected when the AIC value is the smallest.
For cases where there is no historical data of DWP in the local area, the centralized wind power data near the area can be used as a reference, since they have a similar wind source, and the data can be converted proportionally into the DWP capacity for prediction and planning analysis.
2.2. Theory of Copula Function
Based on the predicted time series of DWP and load at the planning stage, in this subsection, this paper proposes a variable-structure copula to depict the correlation between DWP and load.
2.2.1. The Definition and Properties of the Copula Function
Because DWP and load have the characteristics of fluctuation, and DWP also has the characteristic of inverse peak shaving, the correlation between wind power and load is very complicated, and correlation under extreme conditions (tail correlation) cannot be ignored. Therefore, the copula is a useful tool for characterizing nonlinear correlation and tail correlation [
21,
22] between DWP and load.
Copula theory states that there must exist a copula function that satisfies
[
23], where
is a 2-dimensional cumulative distribution function,
is a distribution function of two-element copula function,
x and
y are the samples of DWP and load (MW), respectively, and
,
are the marginal probability density functions of DWP and load, respectively. To simplify, let
u =
F1(x), v = F2(y), and vector
ui and
vi are the values of
F1(x) and
F2(y) at point
i.As a result, to construct a copula model, the first step is to estimate the marginal distribution of DWP and load. Next, a copula function should be carefully selected to fit the correlation between marginal distributions based on some evaluation indices.
2.2.2. Evaluation Indices of Copula Function
After estimating the marginal distribution function of DWP and load, respectively, this paper estimates the parameters based on maximum likelihood estimation (MLE), and the evaluation indices can subsequently be calculated.
The parameter estimation results of Gaussian copula and t copula are the same as Pearson coefficient, which can reflect variables’ linear correlation
where
and
are the expected values of the vectors
ui and
vi, respectively, and
is the Pearson coefficient of the vector
ui and
vi.
The evaluation indices also include Kendall coefficient, Spearman coefficient and Euclidean index [
24].
(1) Kendall coefficient
ρk can reflect the nonlinear correlation of the change trend of the vectors
ui and
vi
where
r is the number of the vectors
ui and
vi, whose two attribute values have the same size relationship.
(2) Spearman coefficient
ρz can reflect the correlation of the rank of the variables
where
di is the rank differences between two vectors
ui and
vi.
(3) Euclidean index can reflect the distance between the model and the empirical copula model [
25].
where
Cm(
ui,
vi) is the empirical copula function of DWP and load, and
Cx(
ui,
vi) is the basic copula functions, where the smaller the Euclidean distance is, the more accurate the model is.
Copula functions used in this paper include Gaussian copula, t copula, Frank copula, Gumbel copula and Clayton copula. To carry out the model evaluation of copula functions, the evaluation indices should be calculated and compared with the empirical copula, as shown in (6) [
25].
where
Fm(
xi) and
Gm(
yi) are the empirical distribution functions of DWP and load, respectively,
represents explanatory function, and
u and
v follow 0-1 distribution satisfying
,
.
2.2.3. Variable-Structure Copula
According to the stochastic characteristic of DWP and load, their joint distribution can exhibit varied correlation features at different periods; under these conditions, a unique copula function cannot sufficiently describe the change. The variable-structure copula provides the most suitable copula model for the description of correlation at different stages according to the varied structural features of DWP and load, and is able to capture the changes of related structures between them more flexibly [
26].
In general, the variable-structure copula can be divided into three types [
27,
28]:
- (1)
Only the marginal distribution of a single variable has a variable structure;
- (2)
The copula function part with a definite marginal distribution possesses a variable structure;
- (3)
Both the marginal distribution of a single variable and the copula function possess variable structures.
In this work, both the marginal distribution of a single variable and the joint copula function are modeled with variable structures. Based on different time division strategies, the main steps of constructing the variable-structure copula model are as follows:
- (1)
Divide the time series of DWP and load into multiple time segments;
- (2)
Apply non-parametric estimation to determine the marginal distribution of each variable at each time segment;
- (3)
Construct the copula model at each time segment;
- (4)
Perform parameter estimation, evaluate the candidate models and select the optimal copula for each time segment;
- (5)
Compare the results based on different time division methods based on (6), and choose the most appropriate division strategy.
For each phased copula function, a binary frequency histogram between variables can be used intuitively as a first estimate of the joint density function selection of DWP and load. By means of the MLE method, the parameters of each basic copula model can be calculated [
29]. Based on the evaluation indices of candidate copulas and empirical copula, the two-stage filtration method [
30] is used to choose the optimal copula model.
After the modeling of the variable-structure copula, typical scenarios can be generated for further DWP planning.
2.3. Typical Scenario Generation
Based on the continuous variable-structure copula function, it is necessary to discretize it to obtain discrete DWP and load data pairs, so as to provide typical scenarios for the capacity planning of a distributed wind farm.
This paper uses K-means clustering to classify typical scenarios. The specific steps are as follows:
- (1)
Discretize each phased copula function to generate two-dimensional discrete data pairs.
- (2)
Set the number of typical scenarios and select the initial condensation point.
- (3)
Calculate the distance from the discrete points to each condensation point, selecting the minimum distance, and divide them into each class.
- (4)
Update the location of the condensate points for each class, and re-calculate step (3) to obtain a new clustering result until the set number of cycles is reached.
- (5)
Choose the best clustering result and find the corresponding original quantile by inverting the probability distribution function.
The joint typical scenarios of DWP and load can reflect the volatility of them with different conditions, and provide a feasible reference for the rational capacity planning of DWP.
4. Case Study
A case study is applied to the modified IEEE 33-bus test system in
Figure 3. The distributed wind farm and ESS are integrated at bus 6, the system-based capacity is 100 MVA, and Matlab
TM is used for analysis.
In this study, with the assumption that the distributed wind farm has the same/similar wind source as that of the centralized wind farm, the centralized wind power data are used, and the wind power data are proportionally converted into DWP. Both wind power and local load data below 110 kV level are practical operation data from an economically developed area in Xuzhou, a city in eastern China. According to the distribution of the load at each bus in the test system, the practical load data in Xuzhou are allocated in the modified IEEE33-bus system. The time series include the 5-min data pairs of DWP and load from 1 January 2016 to 31 December 2018.
4.1. Data Preprocessing
The centralized wind power data is first proportionally converted into distributed wind power. Based on the historical wind power output and load data, the orders of ARMA model for both time series are shown in
Table 1, where
p,
q is the order of the autoregressive, moving average process respectively, and AIC is the value determined by Akaike Information Criterion. Based on the ARMA model, the DWP and load are predicted at the planning stage.
In this work, the Support vector machine (SVM) prediction method is used to evaluate the accuracy of the ARMA model, this paper employs root mean squared error (RMSE), mean absolute percentage error (MAPE), R2 and mean absolute error (MAE) as indices to evaluate ARMA and SVM.
The smaller the RMSE, MAPE and MAE are, the more accurate the model is. The larger the R2 is, the more credible the model is.
The evaluation indices are calculated for DWP prediction by using ARMA and SVM model. The comparison is listed in
Table 2.
The performance of load prediction by ARMA and SVM are further compared based on the four evaluation indices in
Table 3.
Based on the calculation of evaluation indices, it can be concluded that:
- (1)
From
Table 2, the RMSE, MAPE and MAE of ARMA for DWP prediction are smaller than those of the SVM model, the R
2 value of ARMA for DWP prediction is larger than SVM. All the evaluation indices are in agreement that ARMA performs better than the SVM model.
- (2)
From
Table 3, the RMSE, MAPE and MAE of ARMA for load prediction are smaller than those of the SVM model, the R
2 value of ARMA for load prediction is larger than that of SVM. All the evaluation indices agree that ARMA shows better prediction performance than SVM model and it is feasible and satisfactory for load prediction.
- (3)
The model evaluation indicates that prediction results of ARMA model is feasible for the next step of capacity planning for DWP.
4.2. Marginal Probability Density Function of Load and DWP
Based on the non-parametric estimation, the marginal probability density function of DWP and load can be obtained. The empirical distribution function is used as the standard for the actual distribution function and is used to determine the accuracy of the non-parametric estimation method.
Figure 4 and
Figure 5 show the comparison of marginal cumulative distribution by kernel distribution estimation with the corresponding empirical distribution function for DWP and load, respectively.
As shown in the figures, by comparing the gaps of the function graphically, the results of the non-parametric estimation are basically coincident with the empirical distribution, indicating a feasible estimation accuracy.
4.3. Parameter Estimation and Model Selection
With the time division strategy by month, the following is a detailed description of the phased copula selection based on DWP and load data in January, 2018 as an example. Based on the practical data of January, 2018, the binary frequency histogram of DWP and load is illustrated in
Figure 6.
From
Figure 6, the symmetric correlation of DWP and load is identified, and the joint distribution of the two variables are further examined by 5 copula functions.
Figure 7,
Figure 8,
Figure 9,
Figure 10 and
Figure 11 report the probability density and distribution function of each copula model of DWP and load in January, 2018 in a graphic view, and parameter estimation based on the MLE method for the copula models is shown in
Table 4.
Archimedean type copula has good properties including Clayton copula, Frank copula and Gumbel copula. Clayton copula excels at describing the asymmetric correlation and lower-tail characteristics of variables as shown in
Figure 7.
From
Figure 8, it can be found that the asymmetric correlation and upper-tail characteristics of variables are well depicted by the Gumbel copula.
The Frank copula can capture variables’ negative and symmetric correlation. It can be found from
Figure 9 that it can also indicate the progressive independence of both tails.
The ellipse type copula includes the Gaussian copula and t copula. From
Figure 10, the asymmetric and progressive independence of tails are illustrated by Gaussian copula.
From t copula in
Figure 11, the asymmetric tail characteristic of DWP and load is depicted.
Figure 12 draws the empirical copula distribution function.
Different copulas show different characteristics of correlation and results based on different parameter estimation. To select a proper phased copula, the Kendall, Spearman and Euclidean distance indices of each copula are calculated and compared with those of the empirical copula in
Table 4.
Based on the calculation of evaluation indices in
Table 4, the two-stage filtering method [
30] is carried out. When the type of copula model is inferior to other models under the evaluation criteria, it is marked by “×”; when this type of copula model is superior to other models, it is marked by “√”; when this type of copula model is closest among them apart from the optimal model, it is marked by “○”. From
Table 4, the Frank copula is determined to e the best fitting model by Kendall and Spearman correlation coefficients, and the Euclidean distance between the model and the empirical copula model is also the smallest. Since it receives the most “√”, Frank copula function is selected as best fitting the correlation between DWP and load in January.
Similarly, by dividing the year into four quarters, the parameter estimation of each phased copula is obtained and the evaluation indices in each quarter of year are calculated in
Table 5.
In the comparison between the two time division strategies, the average value of the Euclidean distance between the best copula model and the empirical copula model in each month is 1.8864, whereas it is 3.7254 with quarter division. Therefore, the correlation between the DWP and load can be better fitted using the month division strategy.
4.4. Typical Scenario Generation
According to the variable-structure copula divided by month, the typical operation scenario of DWP and load is obtained by discretizing the continuous variable-structure copula function.
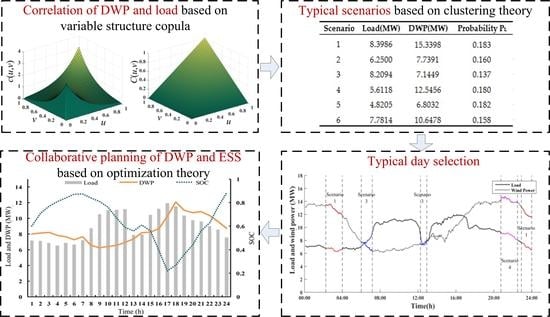
First, we discretize the phased copula model and generate a sample data of 96,000 × 2 dimensions. Next, set the number of typical scenarios to 6 and select the initial condensation point. Finally, use the K-means method to cluster the remaining discrete points and find the corresponding original quantiles.
According to the steps in
Section 2.3,
Table 6 shows the generation results of typical scenarios.
It can be concluded from the results that each typical scenario has a similar incidence, which illustrates the rationality of dividing the initial points into six typical scenarios.
4.5. Capacity Planning of DWP
According to (7)–(9), the optimal solution of the objective function under the constraints of each scenario is obtained.
Table 7 shows the results of capacity planning of DWP and the optimal value of the objective function without energy storage planning in each scenario.
If capacity planning of DWP is conducted based on the minimum load from scenario 5 in
Table 6, the planning result will be 4.95 MW, which is conservative. This will obviously cause a large amount of wind abandonment. The selection with the maximum capacity planning of DWP from scenario 1 will also lead to loss of economic profit. Taking into account the wind power consumption of the typical scenarios above and economic operation, the final planning capacity is the weighted sum with each scenario probability, that is:
where
k is the number of scenarios,
PDWG(
i) is the planning capacity of DWP under scenario
i, and
PL(
i) is the probability of scenario
i. The final capacity planning of DWP is 7.06 MW.
4.6. Collaborative Capacity Planning of DWP and ESS
To maximize the consumption of wind power, it is necessary to employ the ESS so as to increase the planning capacity of DWP.
Based on the generation of typical scenarios, a typical schedule day is selected, and the collaborative capacity planning of DWP and ESS is examined based on the 24-h daily curve. In
Figure 13, based on the
fluctuation range of DWP and load in each typical scenario, several typical scenarios in
Table 6 are included and marked in the typical daily curve.
Before optimization, the initial value of SOC is 0.6, and the initial state of ESS is discharge.
Table 8 shows some specific parameters.
Based on the conditions above, fmincon optimization function in MatlabTM is employed to solve the proposed nonlinear constrained optimization problem.
Under the premise of allowing some wind abandonment, the optimal power output of DWP and the state of SOC in the typical day are obtained and shown in
Figure 14. The corresponding charging and discharging power of ESS in the typical day is reported in
Figure 15.
Based on the optimal DWP planning and the states of ESS in the typical day, the final energy storage capacity planning is 4.63 MW, and the final DWP capacity planning is 12.07 MW. It can be concluded from this study that:
- (1)
The optimal planning of DWP and the SOC of ESS change with the fluctuation of load in the typical day. When load is smaller than actual wind power output, ESS charges and stores the extra wind power. When load is larger than actual wind power output, ESS discharges and supplies power to the load.
- (2)
The SOC of the ESS fluctuates within [0.1, 0.9], which meets the requirement of energy storage operation.
- (3)
Compared with the case without ESS, the DWP planning value increases from 7.06 MW to 12.07 MW, with the study results indicating that with the participation of energy storage, it is conducive to increasing the consumption of DWP.
Moreover, the active power loss of the distribution network, the annual cost of the system is further compared with that before the installation of ESS in
Table 9.
ESS can release power at peak load and it can absorb excess power when DWP output is higher than load. From
Table 9, ESS can reduce the rate of wind abandonment, and the network loss cost is reduced with the collaborative planning of ESS, and the average annual cost is reduced with the benefited from time-of-day tariff in the distribution network.
The fluctuation of bus voltage is further studied and compared in the typical day. The voltage magnitude at some buses is lower than 0.95 in the case of without ESS installation, as shown in
Figure 16, and the bus voltages all lie in the range of [0.95, 1.05] based on the collaborative planning of ESS as reported
Figure 17.
Based on the comparison of
Figure 16 and
Figure 17, with the installation of the ESS, the voltage level is increased effectively at heavy load conditions. At the same time, the range of voltage fluctuation is reduced.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}