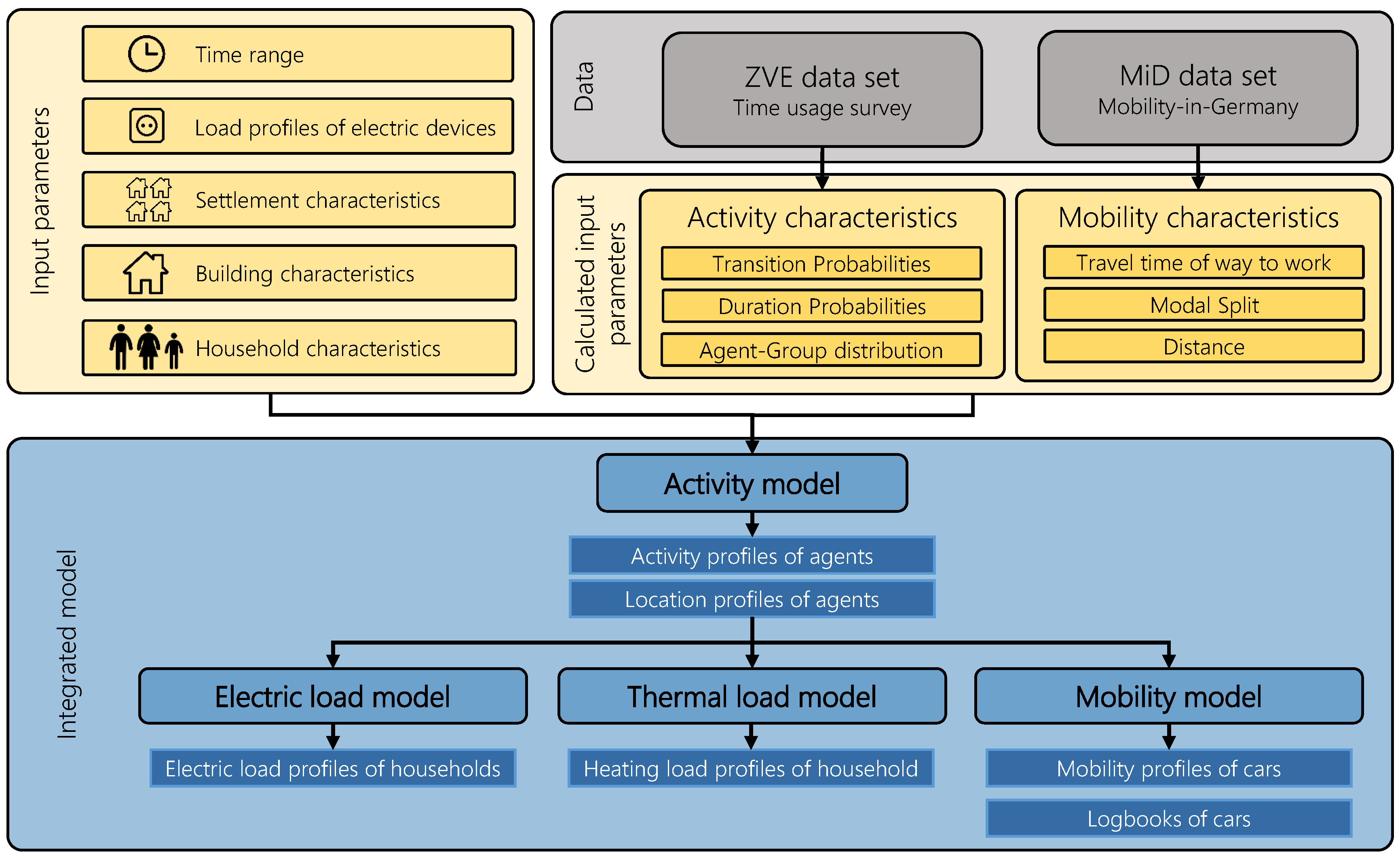
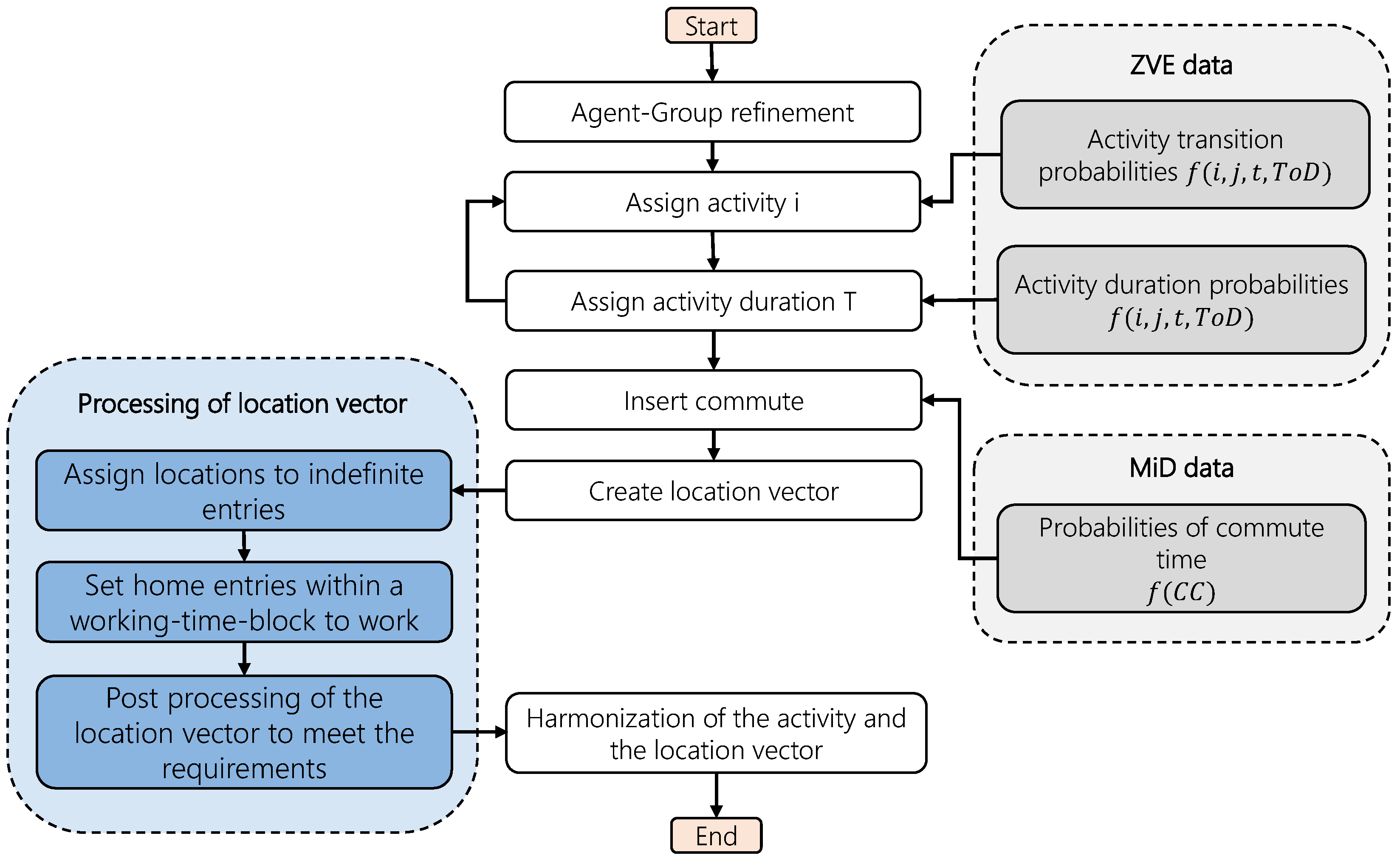
The following chapter gives an overview of the resulting activity, load, and mobility profiles from the described model. Since the focus of this paper is on the generation of the activities, the resulting electrical loads, and the corresponding mobility demand of the modeled agents, a detailed explanation of the thermal model is not shown in this paper. For the other models, the results are shown and compared to literature values and similar models.
The validation of the activity and the electric model is based on one simulation for 300 houses with 940 Households. Therefore, representative distributions for Germany based on [
23] are assumed for the input parameters on household and building levels. The input parameters were already described in
Section 2. A whole year is simulated. Concerning activities and electrical behavior, the city category only affects the duration of the commute. The influence is therefore considered negligible and the city category is assumed to be one, i.e., small cities with less than 20,000 inhabitants. The chosen distribution for the input parameters is given in
Table A1. The input parameters described in
Section 2 are defined based on distributions representative for Germany [
36,
37]. Thus, a representative German settlement is created. These distributions originate from the already mentioned study ZVE [
21] and a population, building, and housing census of the statistical offices of Germany [
38]. The values are included in
Table A1. Exceptions are the distributions of the number of households within a building, the living space, and the specific heating demand. Those depend on the building type. Therefore, a detailed presentation is omitted at this point. The description of the used methodology to reproduce the distribution for these parameters can be found in [
23].
To validate the mobility model, a simulation is carried out for each of the four city categories. In contrast to the first simulation, only 107 buildings with 357 households are simulated. Each simulation uses the same distributions already used in the first simulation and representative for Germany. One vehicle is assigned to each household. Thus, only the variable city category is varied. This allows a clear validation of the sensitivity of the city category.
3.1. Activitiy Model
This subsection describes the results of the activity model. The main result of this model is an activity profile that contains an activity for every agent and time step within the simulated settlement and time range.
To validate the results, the average characteristics of all agents within the simulated settlement are considered.
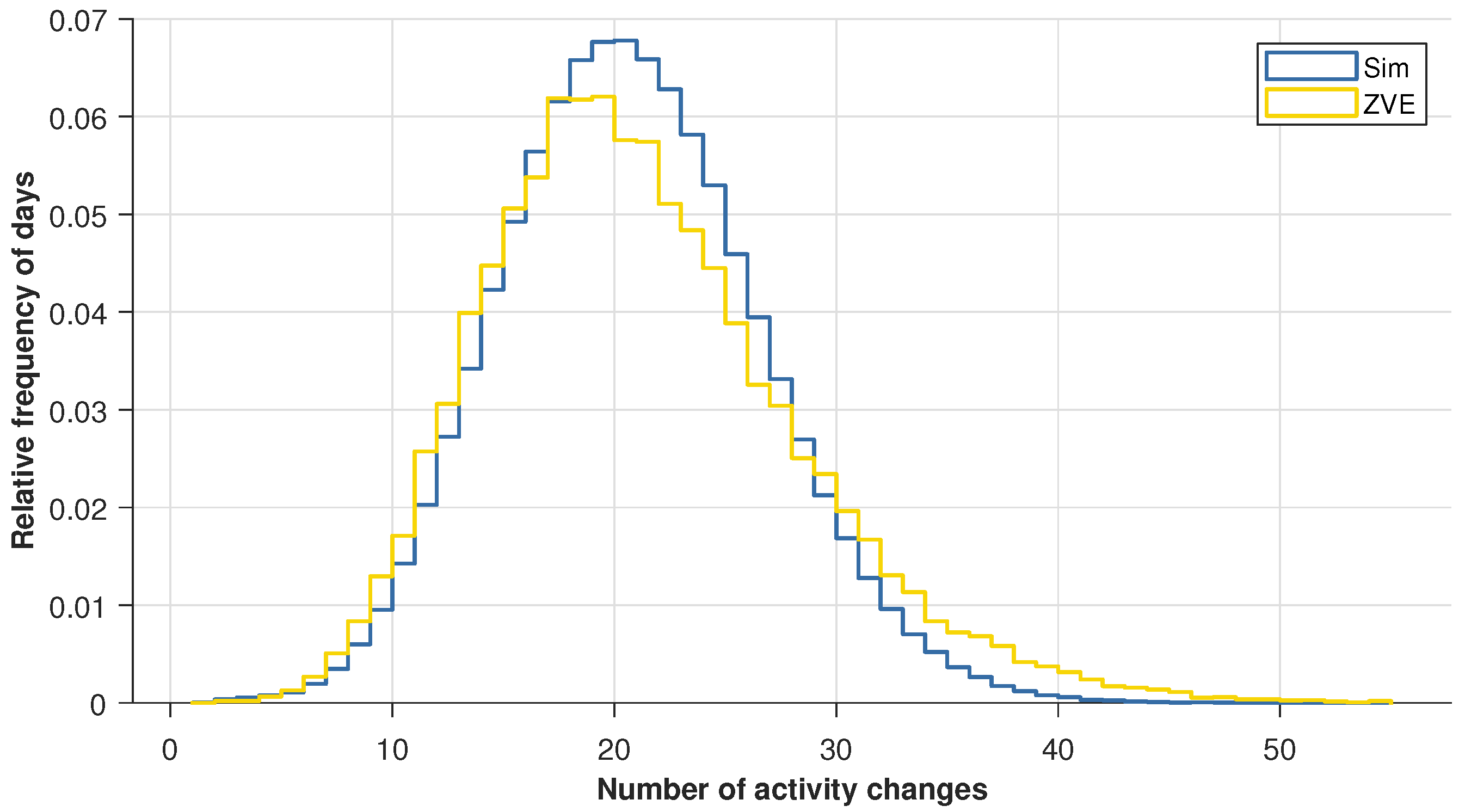
Figure 5 shows the frequency distribution for the number of activity changes. The distribution of the simulated agents is compared with the distribution of individuals from the ZVE data. The similar shape of the curves clarifies that the synthetic activity profiles cover almost the entire spectrum of the ZVE profiles. There are a few days with very few or very many changes. The relative frequency of days in the range of 0 to 18 activity changes is very similar. After that range, the distributions are slightly shifted. The ZVE distribution reaches its maximum at 19 activity changes, while the simulation reaches its maximum at 20 changes. The range with many changes is underrepresented by the simulation. Overall, the synthetic distribution can be described as slightly compressed compared to the ZVE curve. The average activity changes per day are 21 in both cases. The consistency is accepted as sufficient.
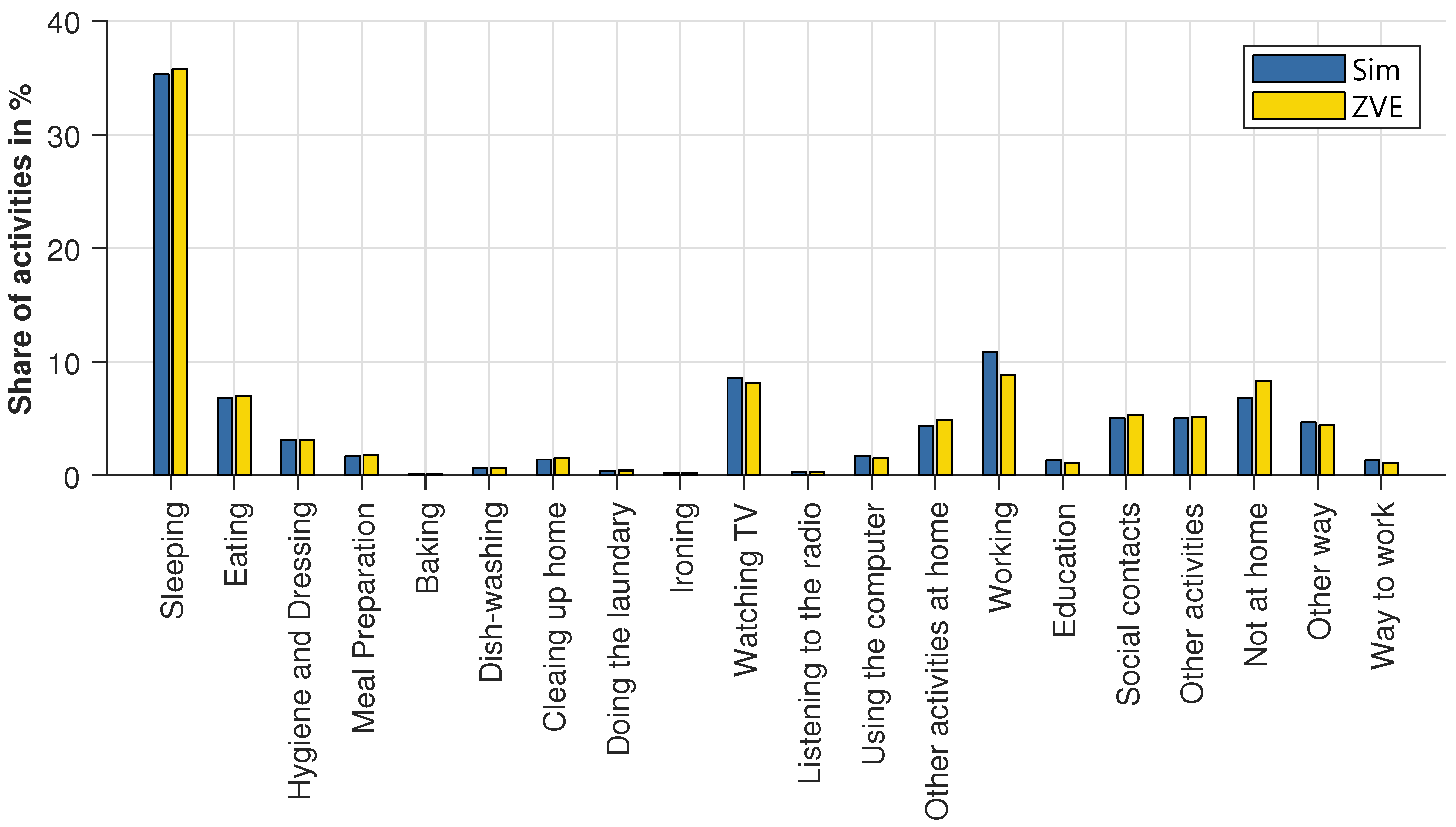
The annual percentage of activities is compared in
Figure 6. Most of the activities fit very well. The absolute deviation for almost all activities is significantly below 1%. However, the activities working and not at home have a higher deviation from the ZVE data. By assuming that activities located at home are prohibited during the working-time-blocks, the activity profiles were subsequently edited. This explains the higher proportion of the activity working (absolute deviation is 2%). However, this percentage is then no longer available for the activities clearly located at home, e.g., sleeping. The insertion of missing journeys and the extension of return journeys are carried out at the expense of the activities not at home. This explains the 1.5% lower share of the activities not at home. The activities related to travel fit very well, although the commute was completely inserted afterwards. Excepting the activities working and not at home, it can be concluded that the activity generator reproduces the activities of the original data over the whole year very well. The significant deviations are caused by the restrictions necessary to generate a plausible mobility profile and are therefore tolerated. The remaining deviations are negligible.
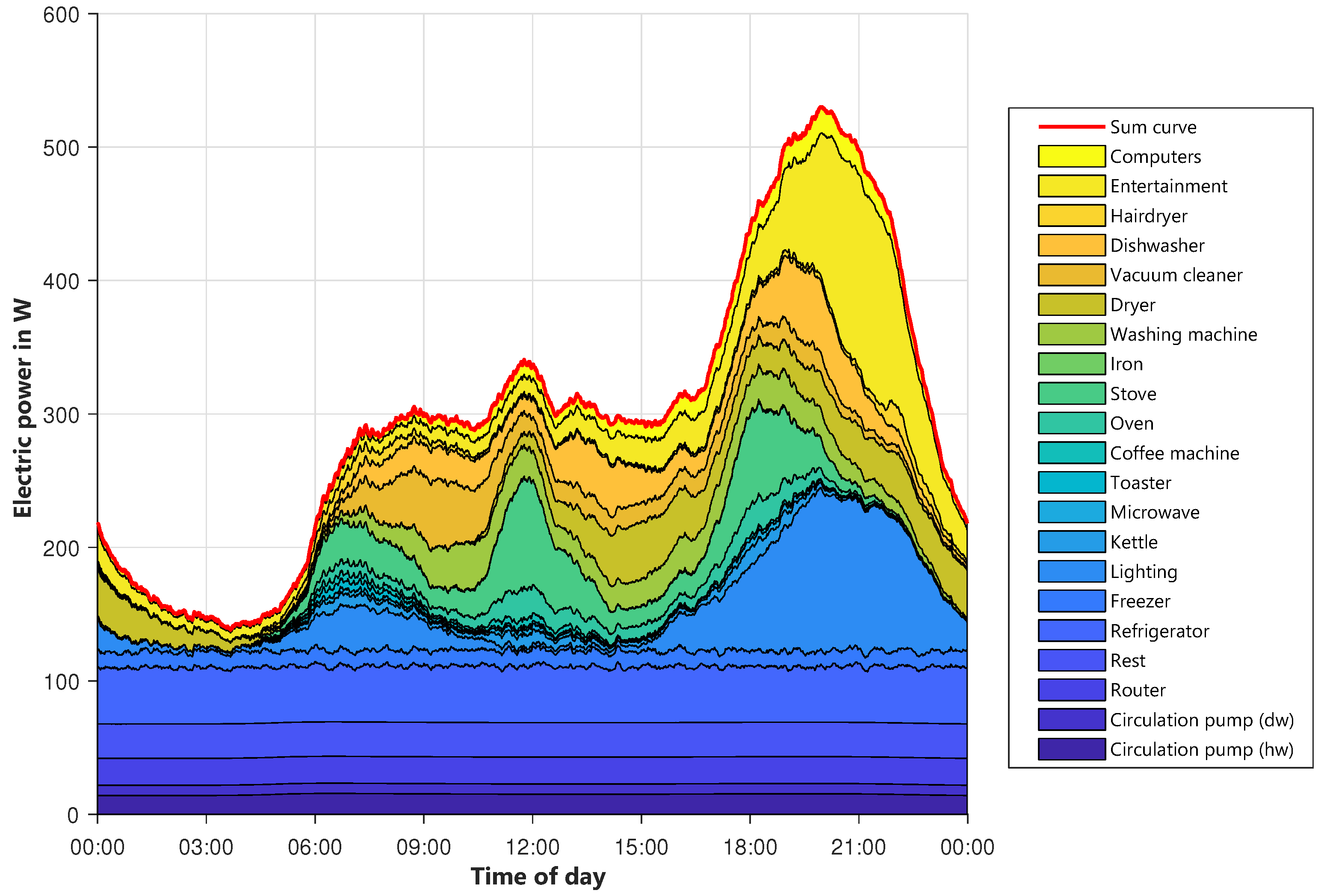
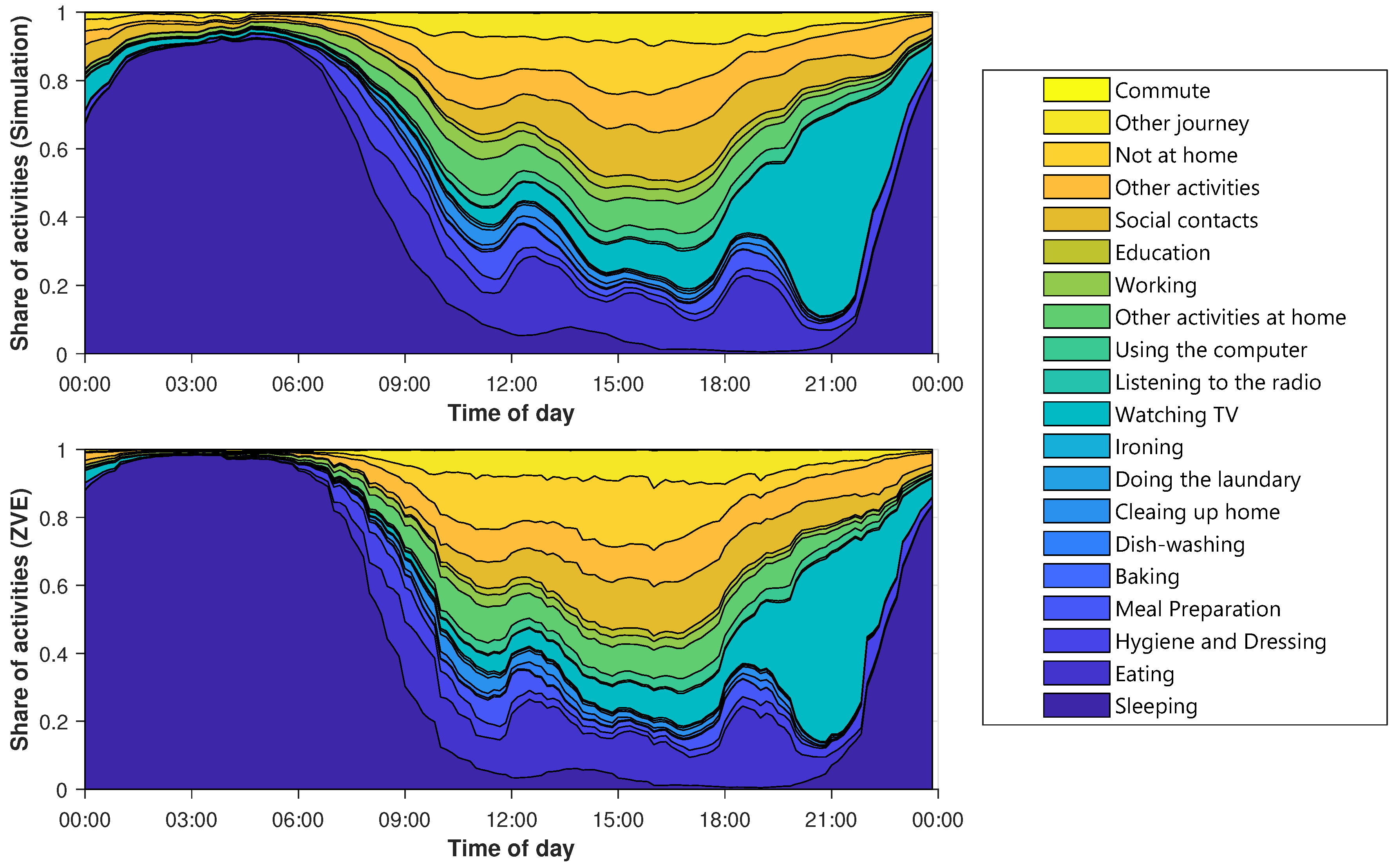
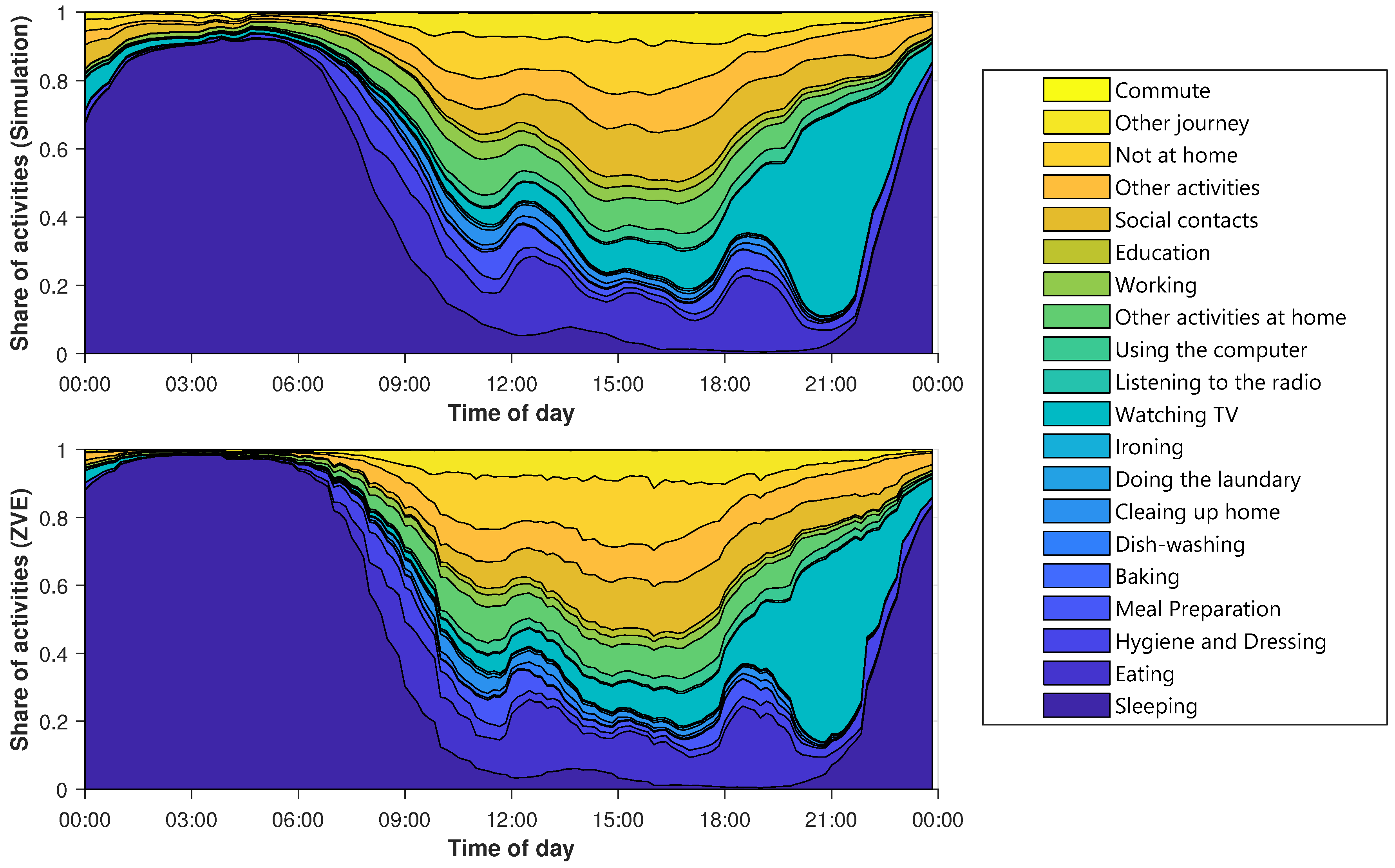
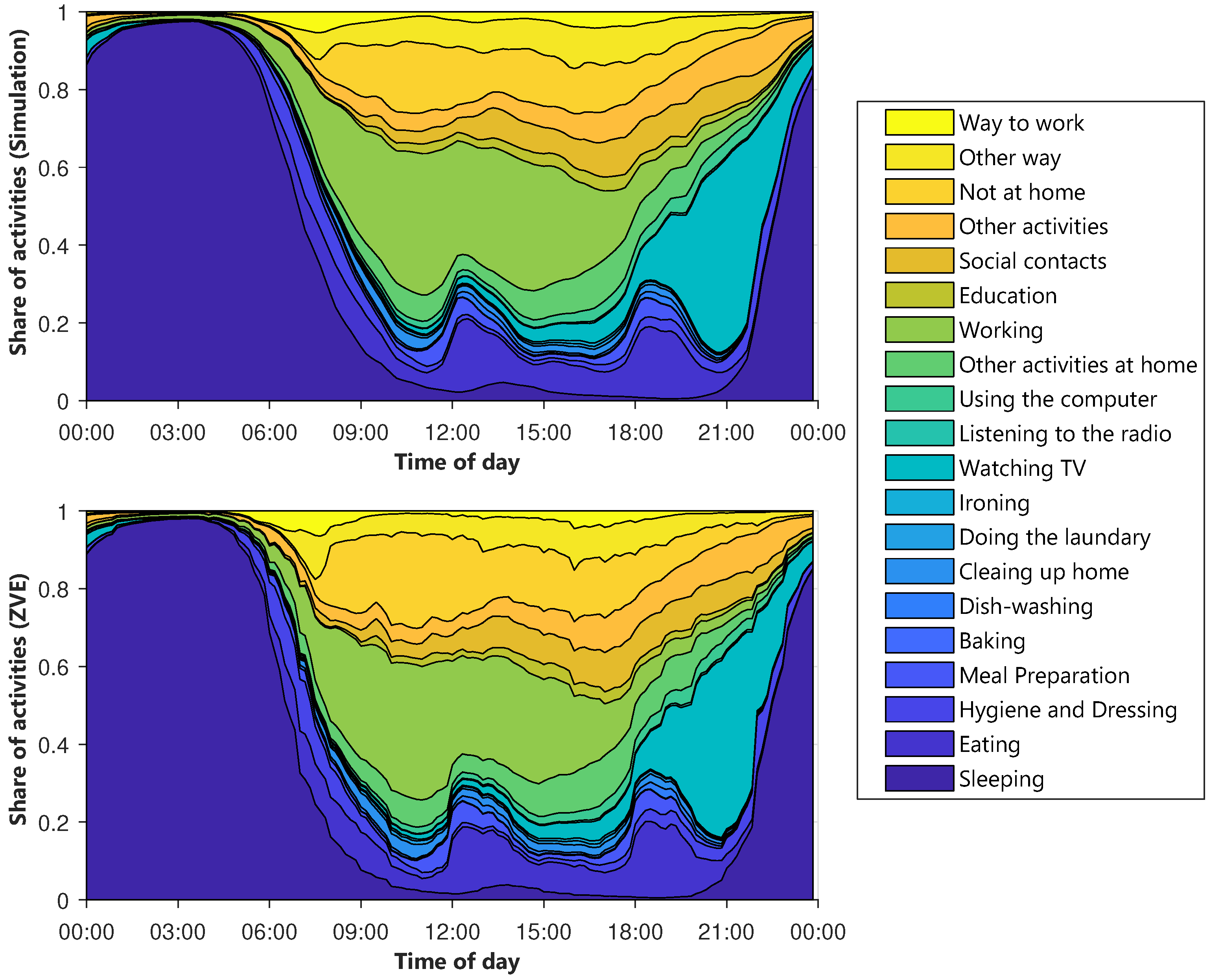
Besides the percentage of activities, it is also particularly important when the activities occur. Later on, this will have a major influence on the shape of the electric load profiles. Therefore, the average layered course of the activities is examined in
Figure 7. The y-axis shows the percentage of agents that perform an activity at a given time. The x-axis contains the time of day. The different types of days are considered separately.
Figure 7 shows the diagram for Sunday.
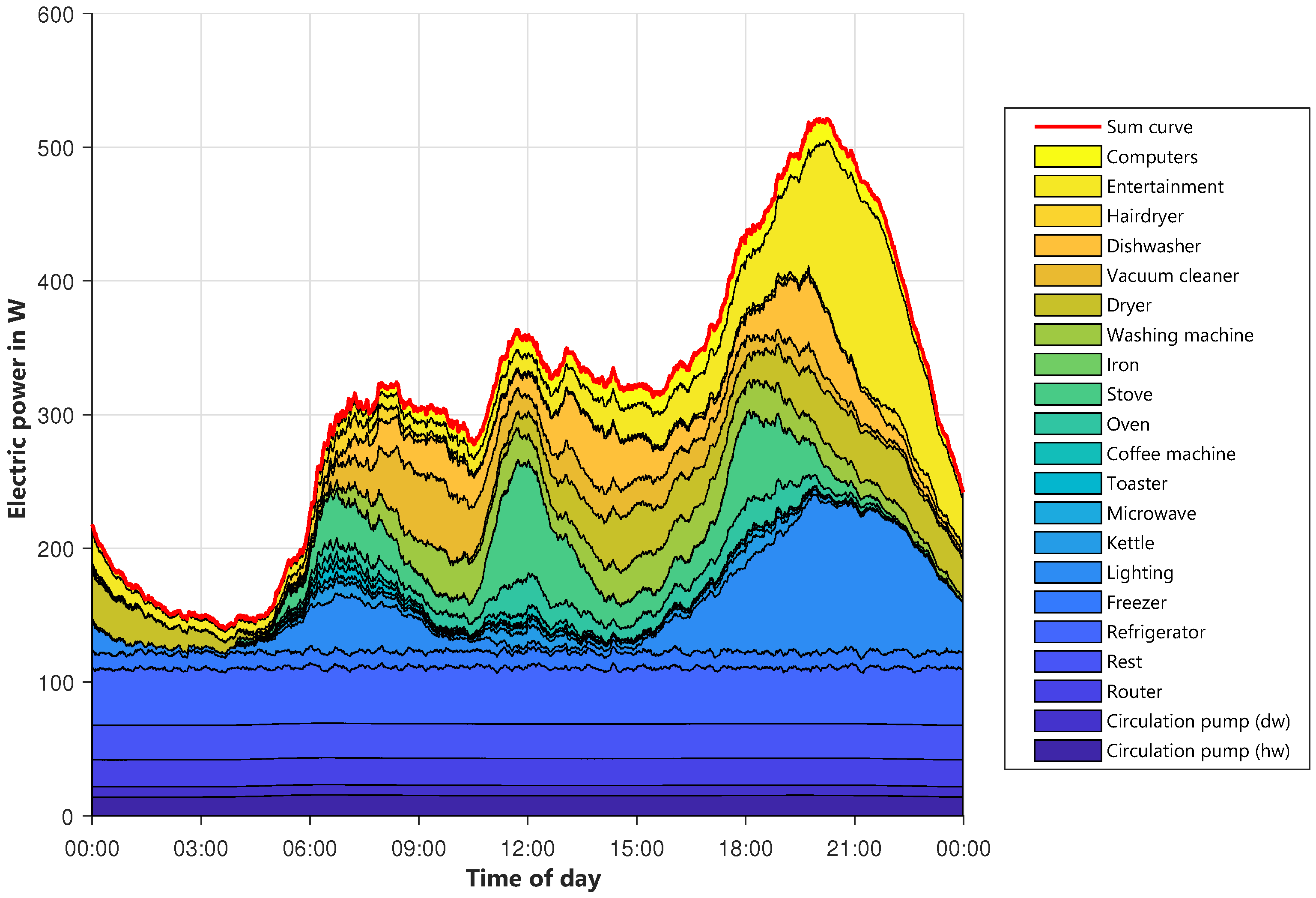
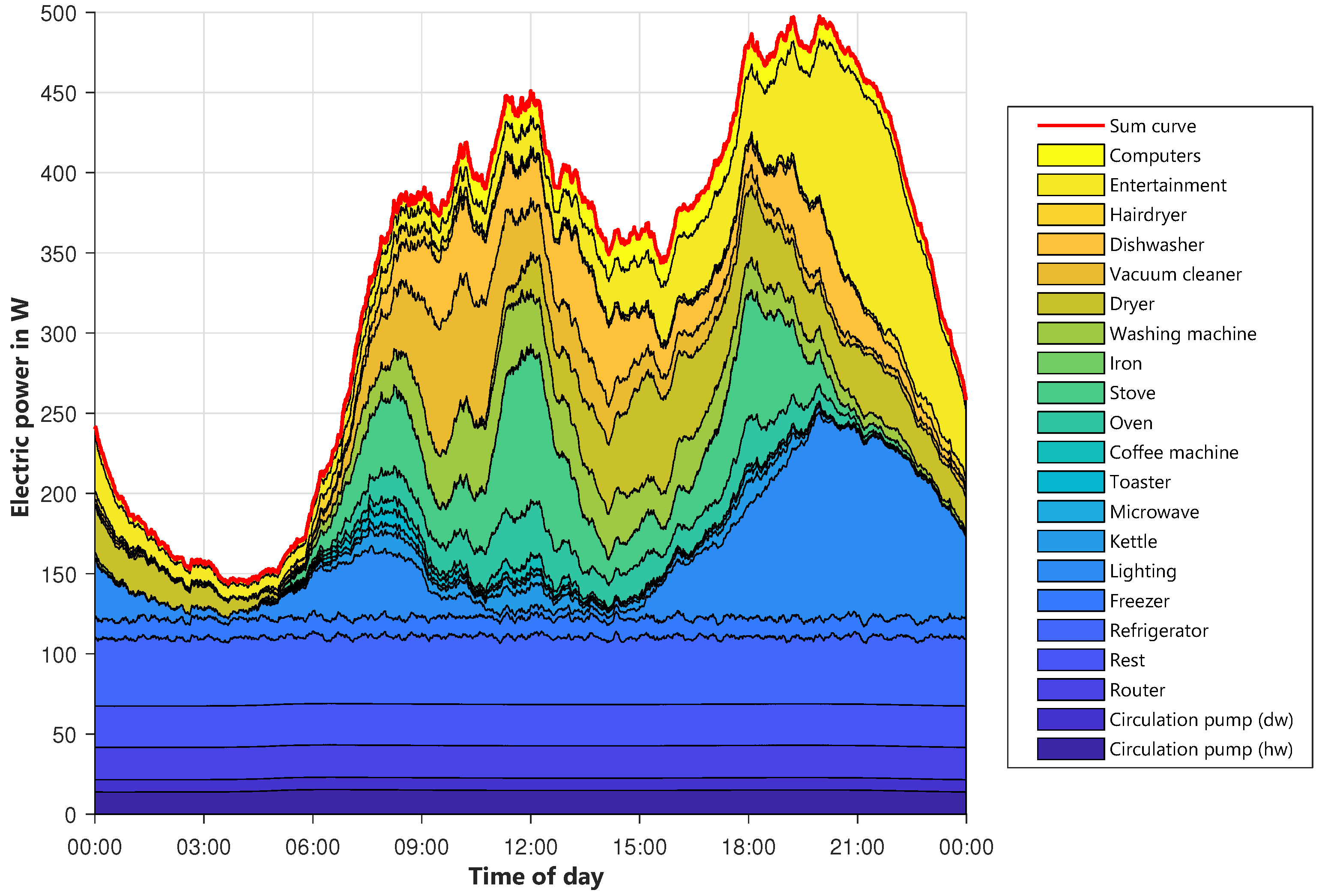
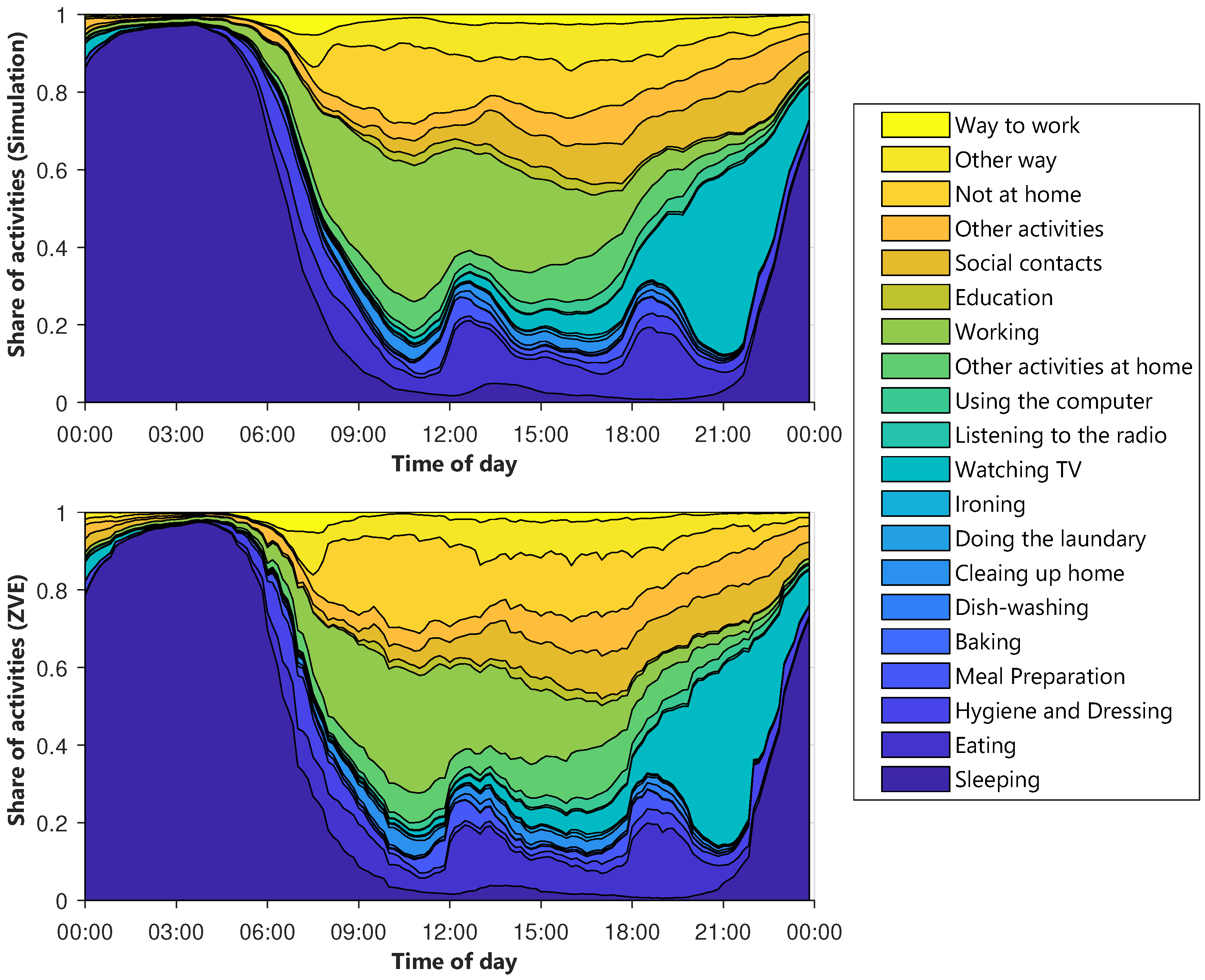
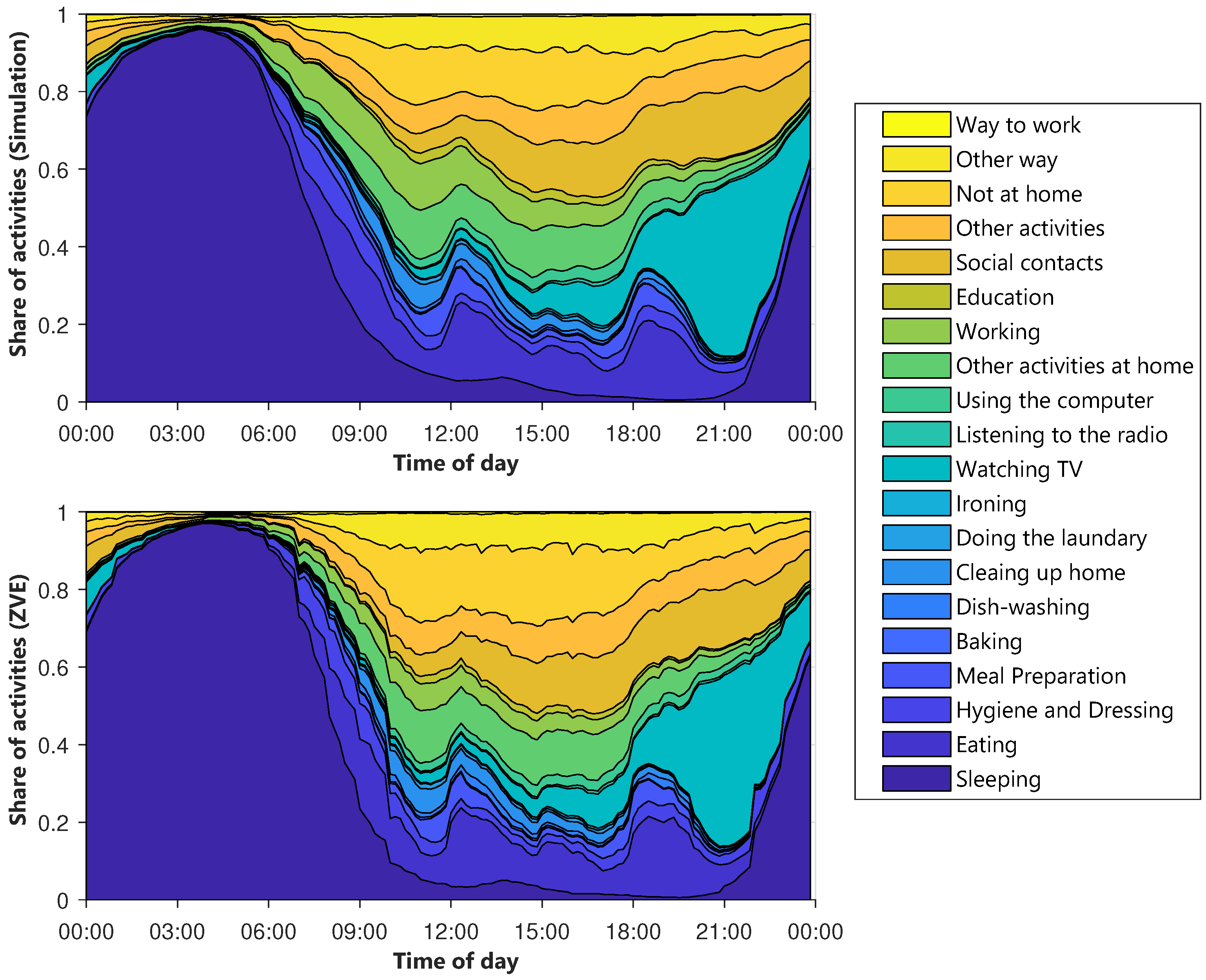
The diagrams of the other types of days are shown in
Figure A1,
Figure A2 and
Figure A3. The top diagram depicts the synthetic activity profiles, while a corresponding diagram for the ZVE-data is plotted below. Immediately noticeable is the smoothing of the synthetic curves. It can be explained by the sample size, because the generated data set contains significantly more day profiles than the ZVE-data set. The comparison confirms the deviations already noted in
Figure 6. Not at home is slightly under-, and working is slightly overestimated. However, the temporal progressions match very well.
3.3. Electric Load Model
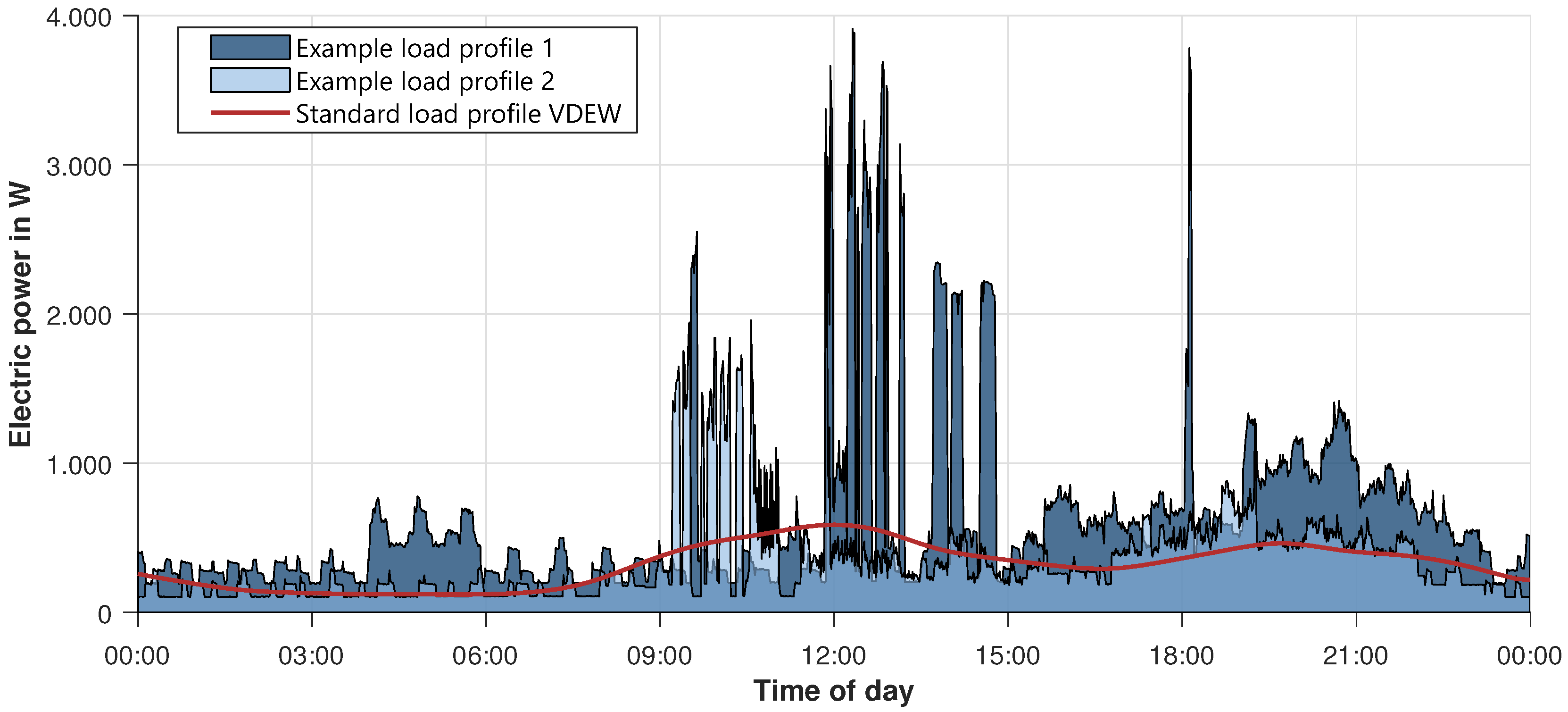
In this section, the results of the electric load model are presented and validated. Different scopes are necessary to fulfill all requirements regarding a realistic load profile for load flow calculations. First, the energy consumption of different households and devices is analyzed. Second, focus is placed upon the shape of an average power profile. Finally, the occurrence of simultaneous power peaks, which are very important for simulations and gradients of the profiles, are discussed. To give an overview of how different a single profile is compared to an SLP, see
Figure 8.
Figure 8 makes it clear that a single profile has much higher peaks, e.g., profile 1 at around 4 a.m., but that there are times where there is almost no energy demand. This is also the reason why the SLP is not suitable for a detailed simulation of less than around 150 households [
6].
After the general overview, one key indicator of the model quality is the energy consumption per household (HH).
Table 7 gives an overview of the annual energy consumption for different households from the literature. The first study [
39] was conducted by the energy agency North Rhine-Westphalia in 2015 and included 522,000 households. In addition to the total consumption, the shares of different devices were also analyzed. Regarding this study, the consumption ranged from 1714 kWh for one person to 5317 kWh for five persons. In other studies, the range was a bit smaller (1500 to 5000 kWh) [
40] but a distinction was made between single and multi-family houses. For this study, more than 226,000 households were analyzed. The last and most recent study [
41] from Destatis only provides data for one- and two-person households, and households with more than two persons. All values are for households without electrical heating since this is not part of the described model. Finally, the resulting energy demand per household type of simulation is also added to the table.
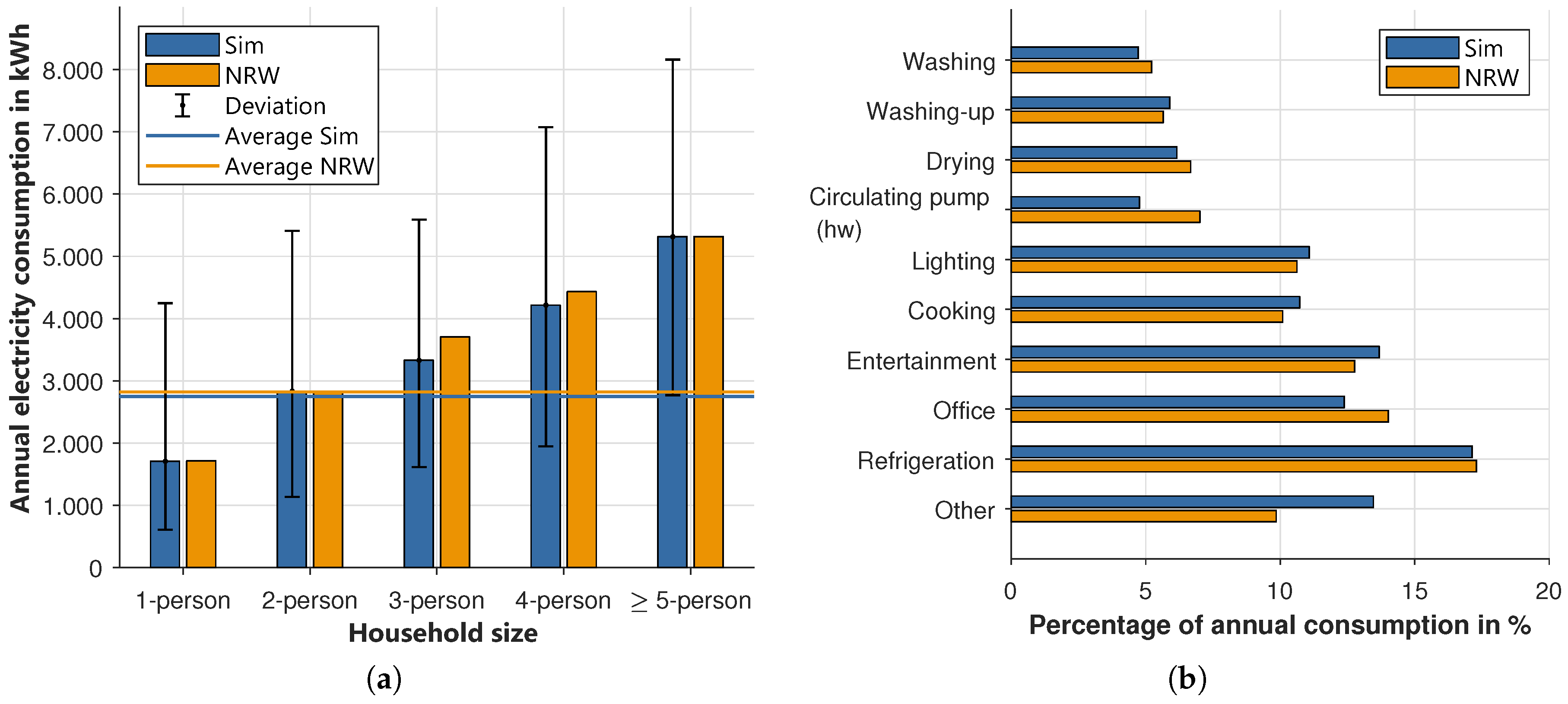
For a better understanding, the results of the simulation and [
39] are visualized in
Figure 9a. On the left side, the different household sizes and the overall average, resulting from the modeled settlement, is shown. Here the overall energy consumption only deviates by 2.5%. In this scenario, households with one, two, or more than four persons have a slightly higher, and the other households a slightly lower energy demand than in [
39]. The black lines also show a large variation between households in the same group. For example, in the simulation demand of a single-person household varies from 608 to 4247 kWh, which shows that the model produces realistic results. On the right side of
Figure 9b, a percentage of annual energy consumption per device group of the simulation and the chosen study is shown. Overall, the figure indicates a good behavior of the model, even though there are some deviations of a maximum of 4% per group. Most obvious is the deviation at “other”, which is higher in the simulation. This group also includes the additional load per agent, which represents devices like mobile phones, tablets, or printers, in the model. This is also an explanation of why the “office” is slightly underrepresented. The circulating pumps in our model are underestimated, but this is part of the thermal model, which is not a focus of this paper. In total, the energy demand per household type as well as the allocation to different device groups is very close to the results of [
39].
Besides the overall energy consumption and the usage of different devices, the resulting profile of the households is fundamental for the usage in a load flow calculation model. To validate the model, two different sources are used. First is the SLP, which is used for billing and procurement, and dates from the year 1999 [
5]. In contrast to that, the University of applied sciences Berlin (HTW) describes 74 representative load profiles with a temporal resolution of one second [
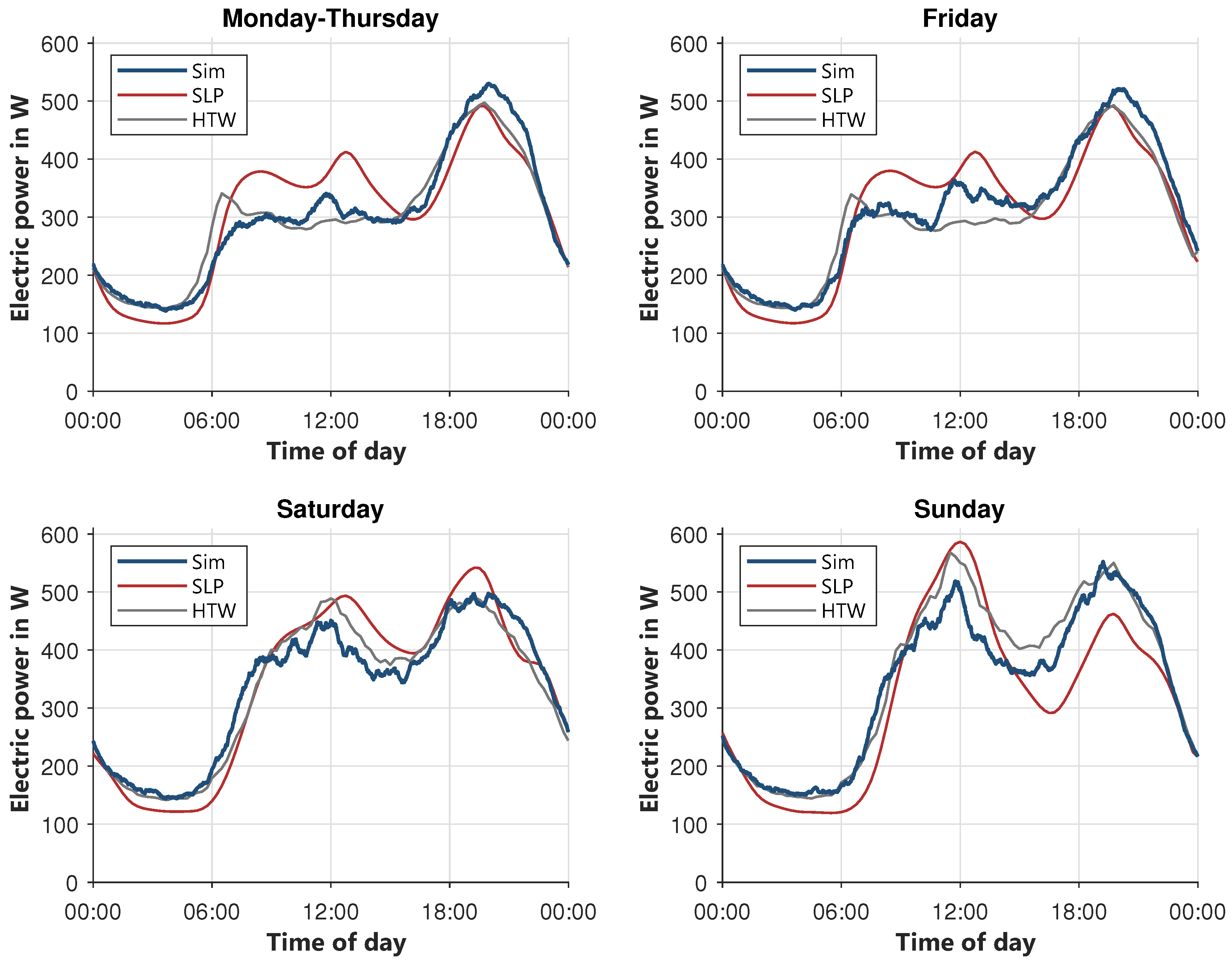
42]. In
Figure 10 the two references and the modeled profile are shown for four types of days (Monday–Thursday, Friday, Saturday and Sunday) since these types of days are different regarding the user behavior. Unfortunately, the SLP does not distinguish between Monday–Thursday and Friday. In general, all profiles have a similar shape, with the lowest load in the early morning hours. Afterwards, at around 6 am, the load starts to increase with a peak at noon, which is higher during the weekend, since there are more people cooking at home. This peak is mostly followed by a dip in the afternoon before the load reaches its peak in the evening at around 7 p.m. For comparison and illustration purposes in the following figures, all load profiles were aggregated to 15 min resolution.
Comparing the two reference profiles shows that there is not a clear “right” profile. The biggest difference occurs on weekdays during noon, where there is a peak in the SLP but none in the HTW profile. The potential reasons for this difference are manifold, starting with the fact that the SLP dates from 1999, whereas the HTW profiles were measured in 2010 and are therefore perhaps closer to contemporary usage patterns. On the other hand, the SLP is still in use in the accounting processes of grid management. For these types of days, the modeled profile largely falls between the reference profiles, and somewhat closer to HTW. Exceptions are the flatter slope in the morning hours, resulting in a lower morning load, and the comparatively higher evening peak. On Fridays, the modeled profile has a slightly higher demand in the afternoon than on the other weekdays. On Saturdays, the modeled profile has a lower peak at noon, but a higher load in the night hours starting from 8 pm. Overall, the simulated profile is quite close to the reference profiles for Saturdays. On the last subfigure, Sunday, the peak at noon is underestimated, in contrast to the other profiles.
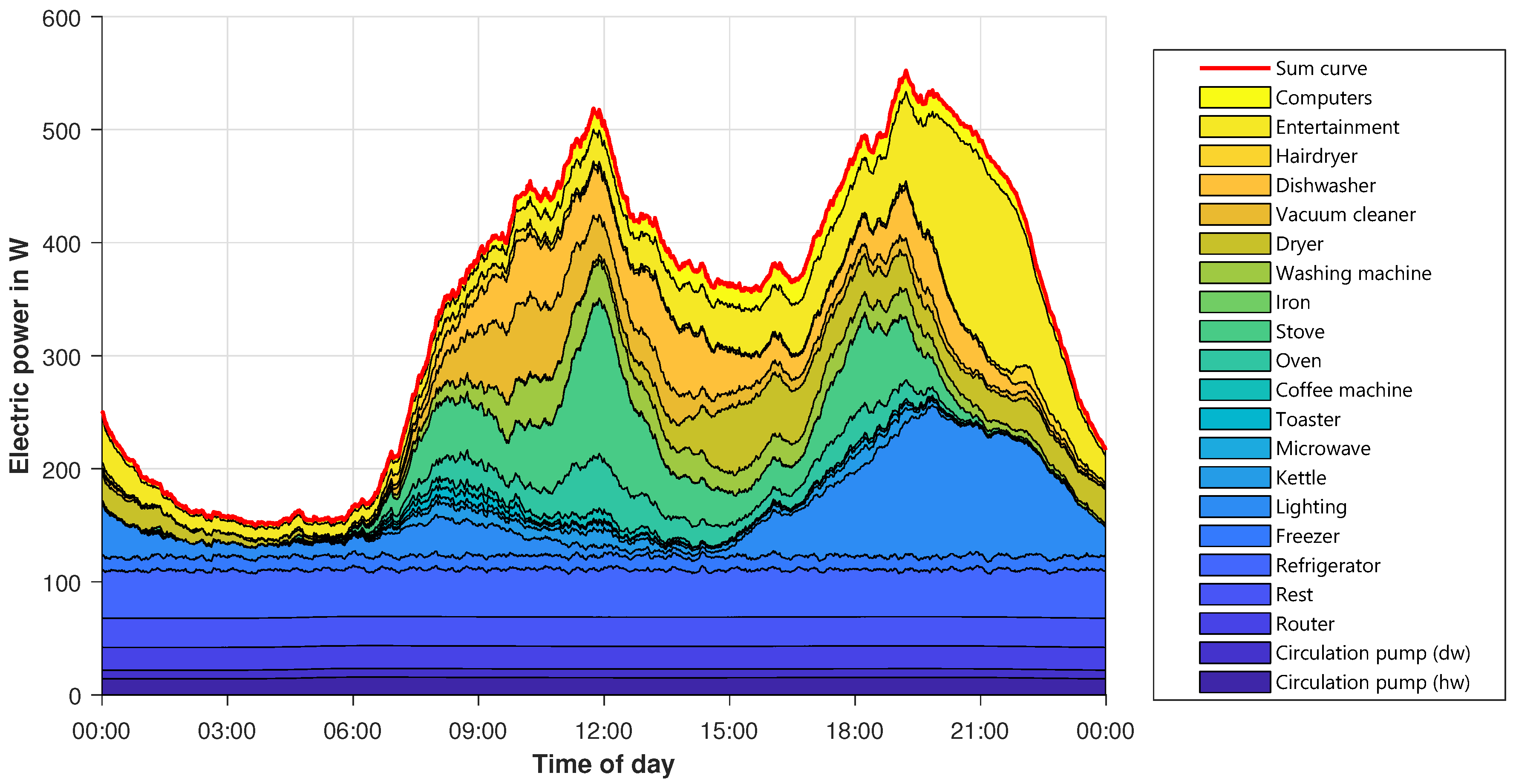
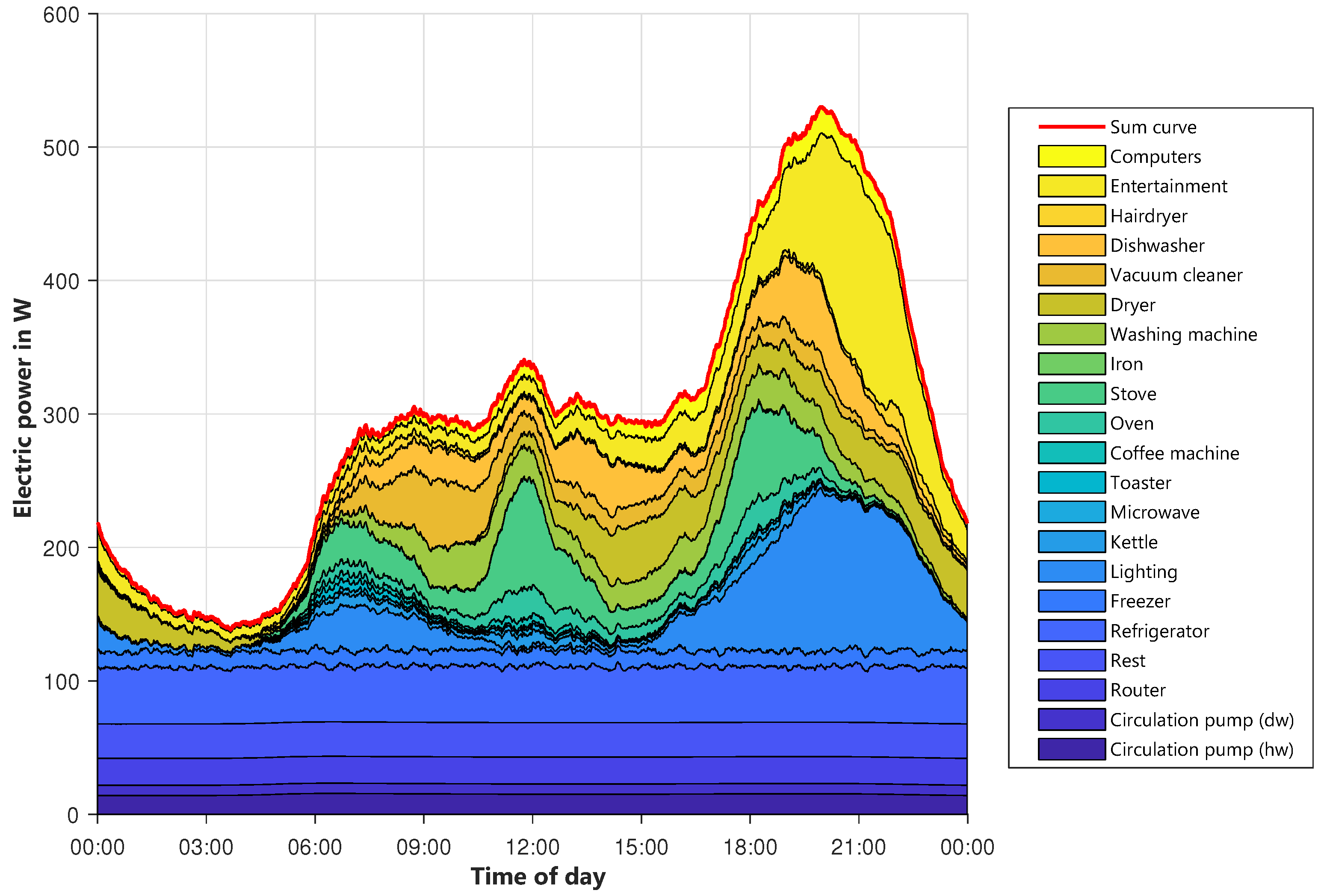
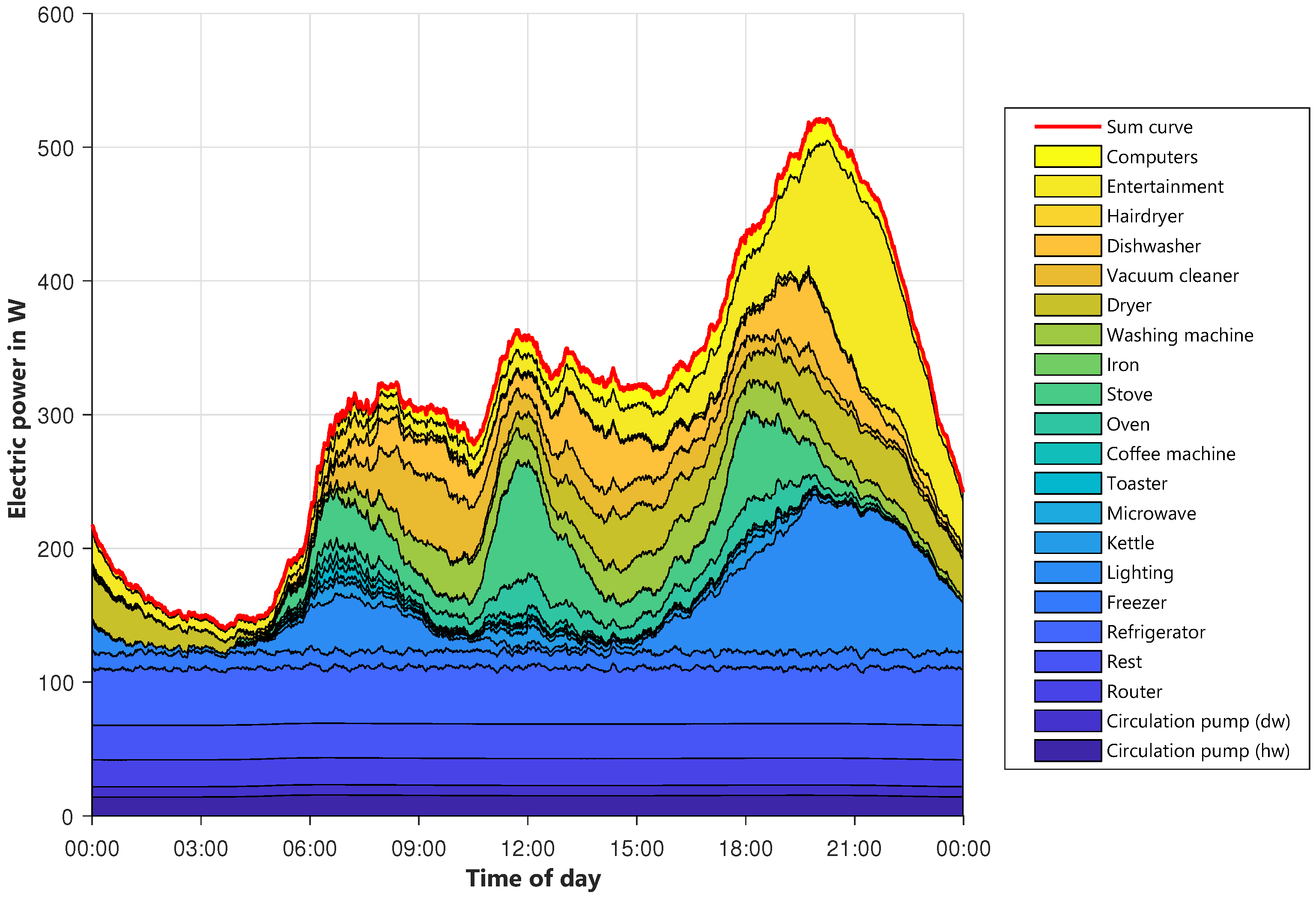
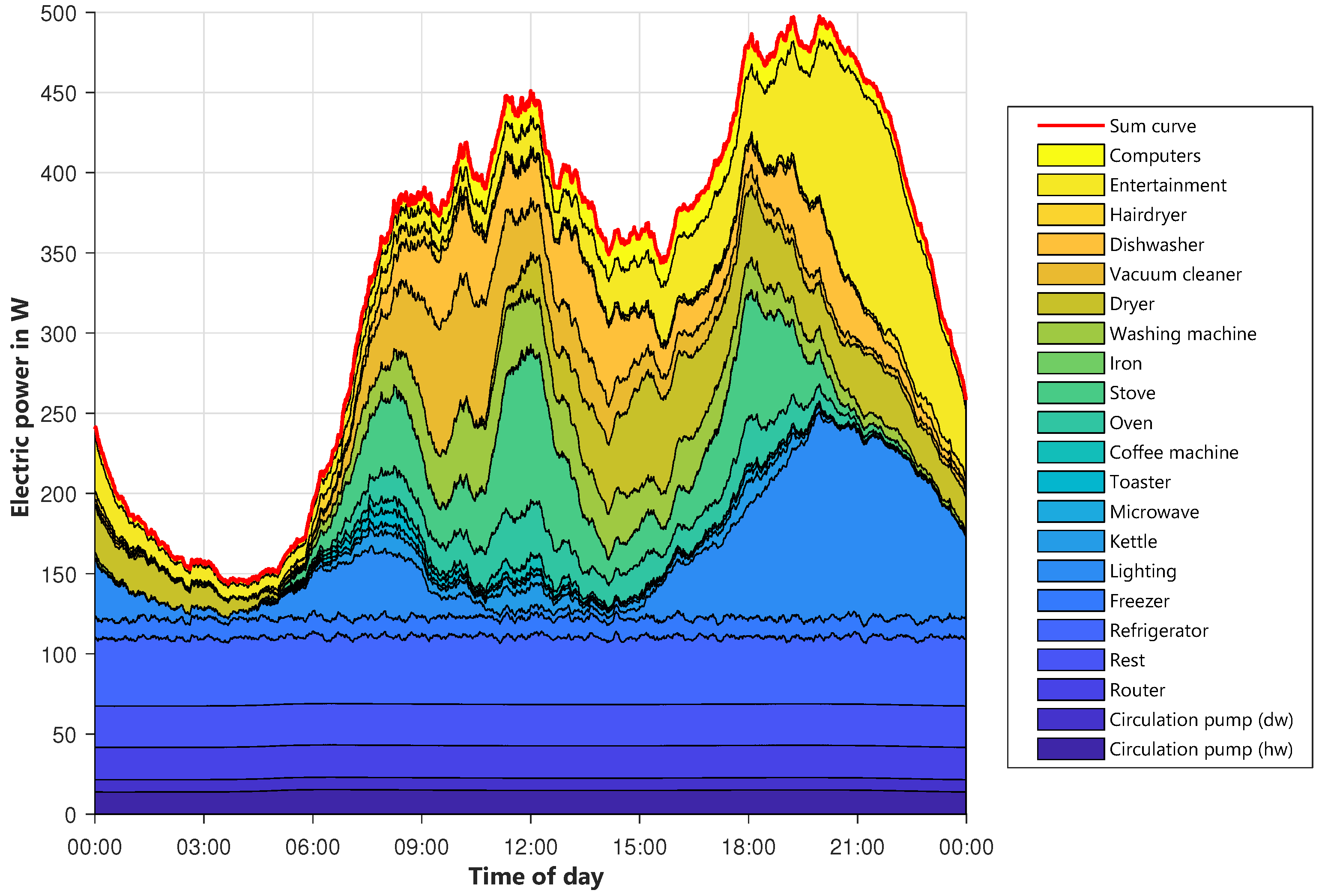
To examine the modeled profile in more detail,
Figure 11 shows the allocation of the power to different device groups. Starting from the bottom, the base loads like circulating pumps, routers, and so on, are displayed. The first bigger load forming the shape of the profile is lighting (light blue), which is mostly on in the morning and evening hours. Cooking equipment also contributes to the evening peak, alongside higher usage of entertainment equipment, like televisions or stereos, and lighting. On the whole, the modeled profile is similar to the reference ones. The shape fits quite well even though there are some smaller deviations. In total, the modeled profiles are closer to the newer HTW profile than to the SLP, which is quite old. Since there is no right or wrong behavior for this shape, and also taking into account that the behavior of people has changed over years since 1999, the result seems to be appropriate for the planned usage.
The last two important indicators which are compared are the occurring simultaneous peak power and the resulting gradients from one minute to the other. The maximal simultaneous power of households describes the maximum concurrent peak load for a number of households. Since not all houses use their maximal power at the same time, this value decreases rapidly with the number of households. If there is only one household connected to the grid, the grid must be able to deal with the maximum power of this household. If there are more houses connected, the maximum occurring power
at a time is lower than the sum of the individual peak powers. To calculate this value,
n profiles were summed up and divided by the number of households, as in Equation (
3). This process was carried out 10,000 times and the maximum of each combination was saved. From these 10,000 results, the 95% quantile was used to calculate a realistic value. [
43] This procedure was performed for the results of the described model and also for the load profiles modeled by [
42]. In literature, an approximation for the simultaneity factor is often used [
43,
44]. Equation (
4) calculates the simultaneity factor, which describes which percentage of the individual maxima are occurring at the same time at a given number of households. To get the resulting power per household, this value must be multiplied with the peak power per household. Within the DIN 18015 [
45] this value is estimated to be 14.5 kW for one house without electric heating or water preparation.
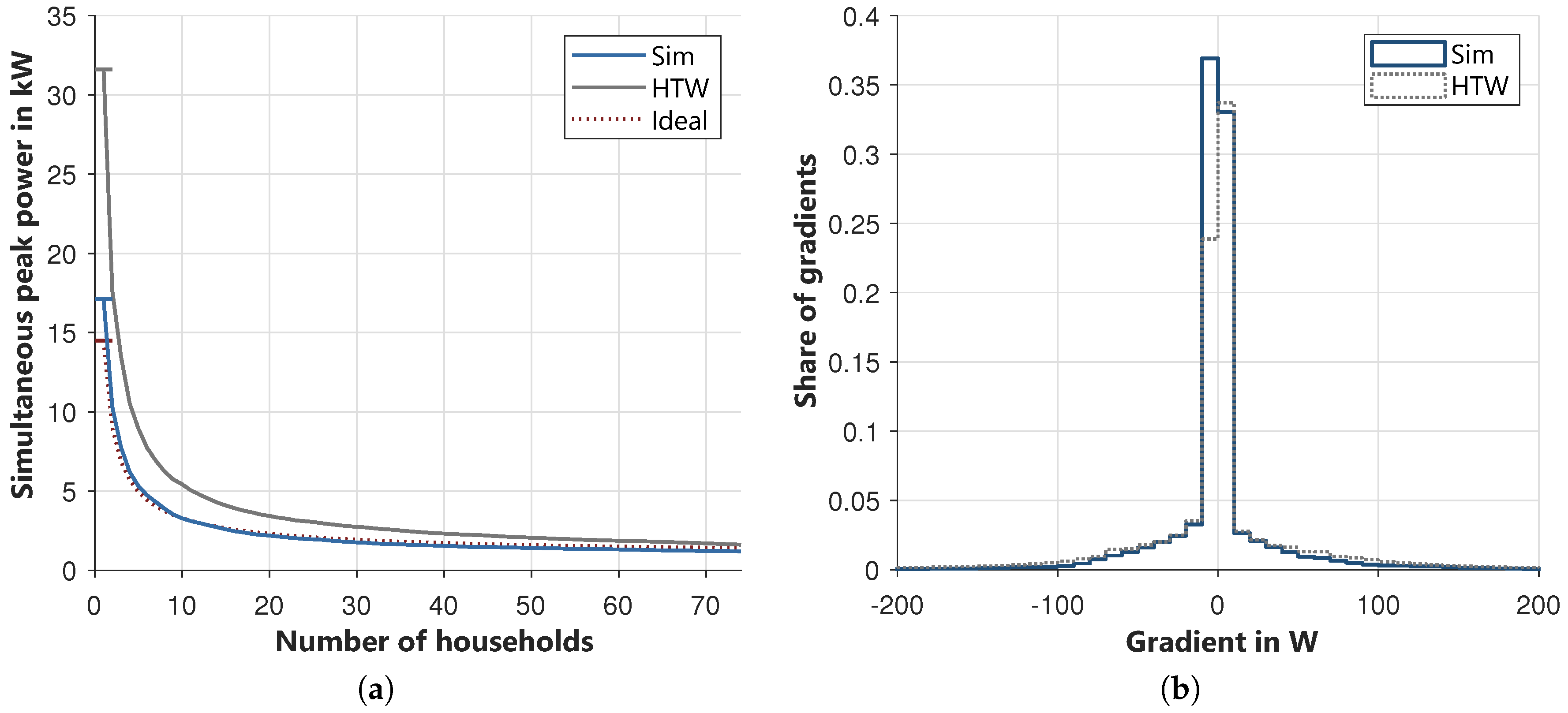
The results of the simultaneous peak power are shown in
Figure 12a. The results of the described model are quite close to the ideal curve calculated by using [
44]. The peak power for one household is 17.1 kW instead of 14.5 kW. In contrast, the results of the data from [
42] have a peak power of 31.6 kW, which is around two times as high. For all these calculations, the one-minutes values were used. The curve of all three lines is similar and is falling rapidly. At ten households, the simultaneous power of the modeled load profiles is only 3.3 kW, which is less than 20% of the overall peak. In total, this figure shows that the resulting peak powers and their simultaneous occurrence are reasonable for performing load flow calculations.
The last important indicator is the occurrence of gradients, which describes the change of power from time step to time step. Low gradients are characteristic of a very constant load profile, which typically occurs at night. High gradients indicate a strongly fluctuating load profile and occur in households mostly through switching power-intensive devices on or off. This value is very important for all control strategies since it is much easier to control a stable system than a system with high gradients. For this value, the data of [
42] is again used as a benchmark. In
Figure 12b the share of the gradients are shown in 10 W steps. Most of the gradients (~70%) are around ± 10 W for both data sets. The described model has more gradients −10–0 W, but slightly fewer higher gradients in the area of ±50–100 W. In total, both curves look very similar and therefore the power changes look reasonable.
To sum up the results of the electrical load model based on the modified Markov activity model, the results are validated with data from literature and other models in the fields of energy consumption per household group and energy consumption per device group. In these fields, the results look reasonable. In the next step, the average profile of many households was investigated and compared to the SLP and HTW data. Unfortunately, there is no right profile to benchmark the results. In general, the generated results are close to or between the benchmark data. Lastly, the most important indicators, the simultaneous peak power and the occurrence of gradients, were analyzed and compared to other data. Both indicators appear accurate with regard to the comparison values. Therefore, the aim of the model, the creation of electrical load profiles for different households based on the activities of the persons living in the houses, is fulfilled.
3.4. Mobility Model
This chapter validates the results of the mobility model. Important mobility parameters of the agents and the vehicles, such as the mobility rate, the kilometrage and the duration of the journey, are compared with the values given in the MiD [
46]. The validation is carried out with a view to the future use of the model. The weightings specified in the MiD are taken into account. For general comparisons, the distribution of vehicles among the city categories based on the MiD data is used and the simulation results are weighted accordingly.
Table 8 contains the distribution for weighting the results of the different city categories based on the vehicle distribution in the MiD. With the help of the weightings, the results were combined to achieve a distribution representative for Germany.
Before considering the characteristics of the vehicles in the next step, important mobility parameters of the agents will be briefly discussed at this point. The overall values of the simulations are compared to those of the MiD [
46] in the upper part of
Table 9. If available, the related value of the mobility panel (MOP) [
47] is attached. MOP is another mobility study representative for Germany. The average values are on a daily basis. The mobility rate generated by the model is, compared to the MiD, about 9% overestimated. That means too many agents are assigned to activities related to travel in the activity model. However, it is very close to the value of the MOP. The daily travel time and the number of journeys per mobile agent lay between the values of the two studies. The comparison shows that although the simulated values differ from the MOP, the studies themselves show noticeably different results. It can be stated that the simulated mobility behavior of the agents lies well between the results of the studies and is therefore assumed as valid.
The next step is to validate the mobility behavior of the vehicles. The generated mobility profiles of the cars are the main output of the mobility model. Therefore, important parameters of the mobility profiles are considered and evaluated at this point. Some important parameters are compared with those of the MiD in the lower part of
Table 9. The mobility rate of simulated cars is significantly higher than in the MiD. The already discussed higher mobility rate of the agents is one reason for that. Consequently, more trips are made by car. Another major reason is the assumption, that every simulated household has only one vehicle. According to the MiD, 53% of households across Germany own one car, 21% own two and 4% own more than 2 cars. This means that the cars in the model are used by more drivers, which leads to a higher mobility rate of cars. These reasons are also responsible for the higher number of drives in the model. The average daily kilometrage of the simulated cars undercuts the MiD values slightly, even though the number of daily drives is lower and the cars are underway around 10 min more per day. As a result, the average distance per drive is underestimated by around 2 km in the simulation.
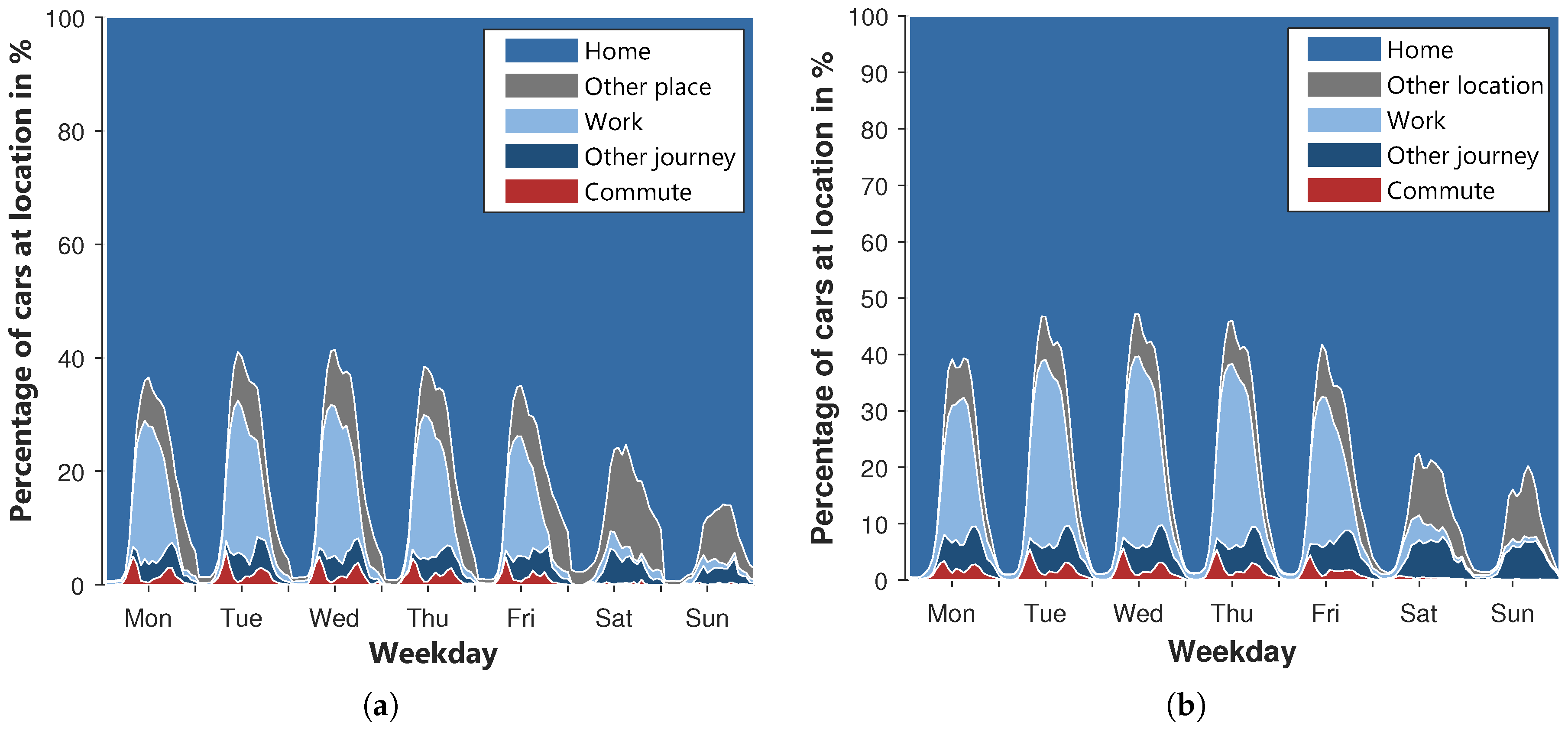
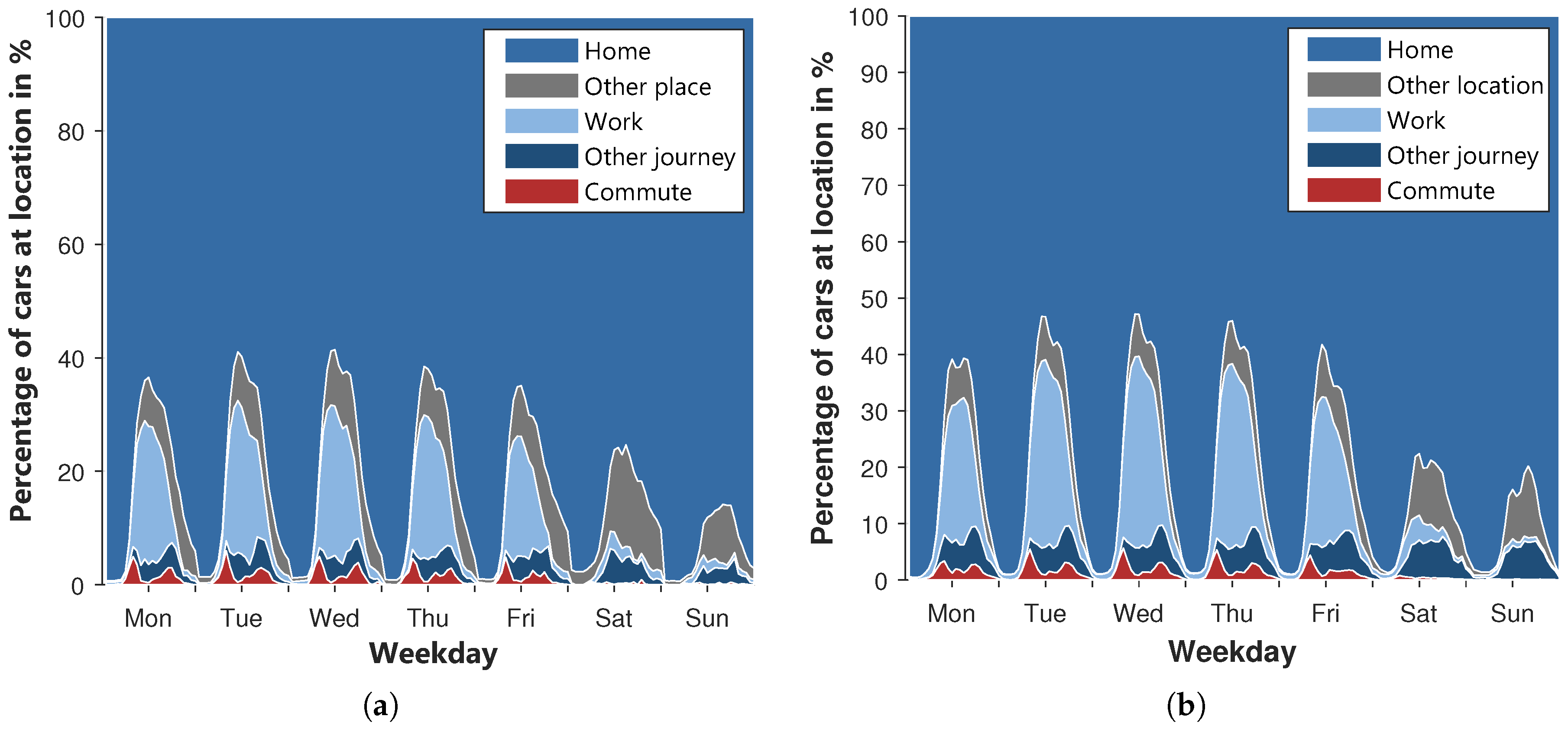
The layered percentage of vehicles at the five defined locations over the week is shown in
Figure 13a for the MiD data and
Figure 13b for the simulated profiles. To outline the reference course of the MiD, the information of the cars for which all routes were recorded within the study are used. As some of the necessary information is not directly contained in the MiD and the study only includes single days, some assumptions had to be made. The destinations are determined by the purpose of the journey. The places between the journeys are determined using the start- and end locations of the journeys. From the beginning of the day until the beginning of the first journey, a vehicle is located at the starting point of the first journey. Using the destination of the last journey, the location at the end of the day is determined similarly. As complete annual profiles are available for the simulated vehicles, no further assumptions are necessary to create diagram
Figure 13b.
In general, a clear similarity between the two diagrams can be identified. In both diagrams, the commute occurs mainly on weekdays. On weekends, less than 1% of the cars commute to work. In both cases, most vehicles are on their way to work around 8 a.m. The peaks are in the range between 4–5%. Deviating from the MiD, the maximum of the commute on Mondays is lower than on other weekdays. At lunchtime, the proportion of commuting vehicles reaches a minimum. The minimum of the MiD is below 1%. The simulated course is in the range between 1 and 2%. The return journeys from the workplace are spread over the rest of the day and peak around 5–6 p.m. in both diagrams. The shape of the other travel on weekdays is similar, too. In the afternoon, both diagrams reach their peaks. However, the peaks of the simulation exceed those of the MiD. Accordingly, the travel time of the simulated cars is slightly overestimated, which is consistent with the findings in
Table 9. Furthermore, the percentage of cars at the workplace is noticeably overestimated by the simulation even though the shape of the curves is very close and reaches its maximum around 12 p.m. Additionally, the cars of the simulation remain at the workplace longer, and more cars stay overnight. The percentage of cars at other places is slightly underestimated within the simulation. However, the differences between other places and at work balance each other out, so that the percentage of vehicles at home is relatively similar. In total, more than 53% of the simulated cars and 58% of the cars of the MiD are at home over the whole week. At the weekend, more vehicles are continuously at home. In general, it can be concluded that the locations of the vehicles over the week differ in places from those of the MiD. However, a good overall consistency is achieved.
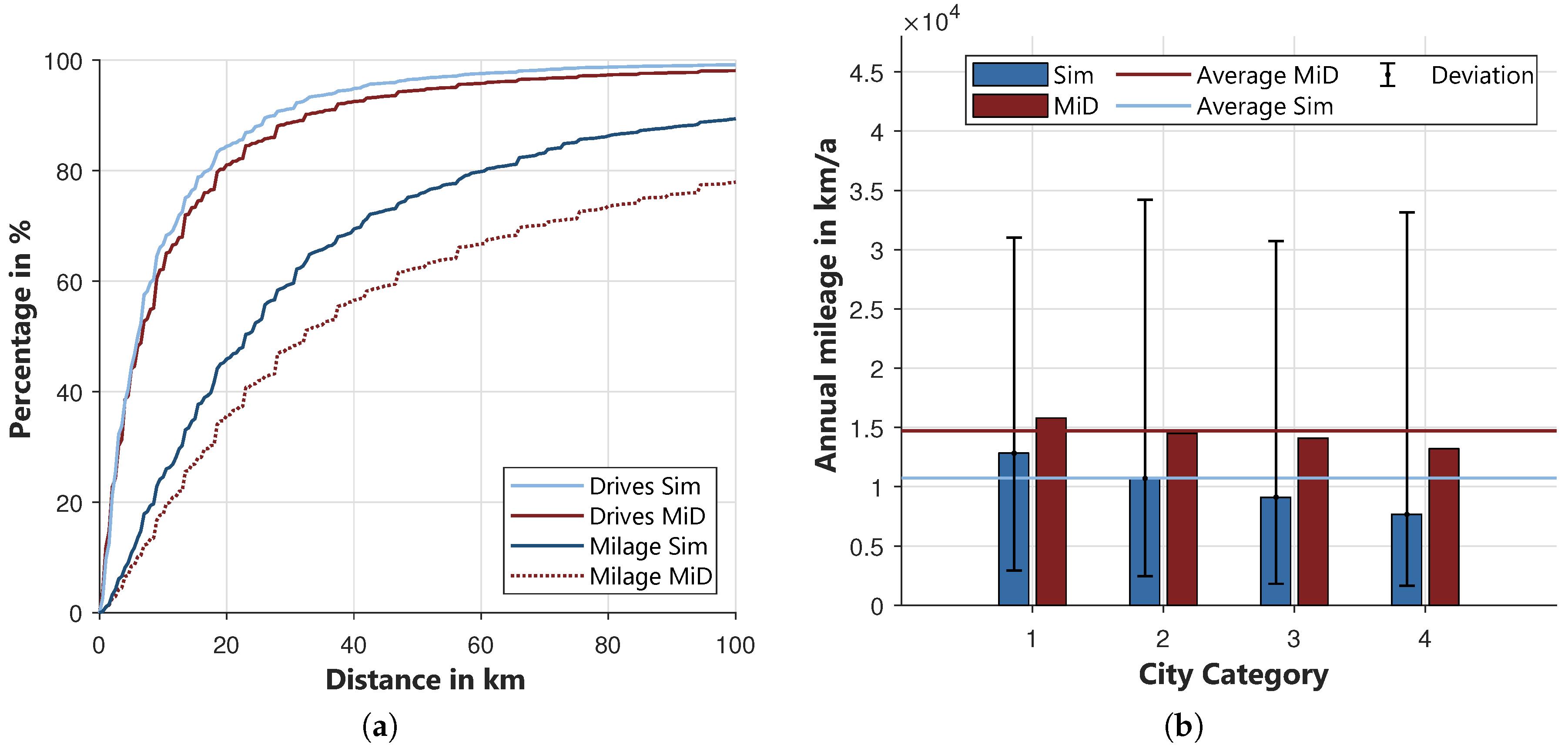
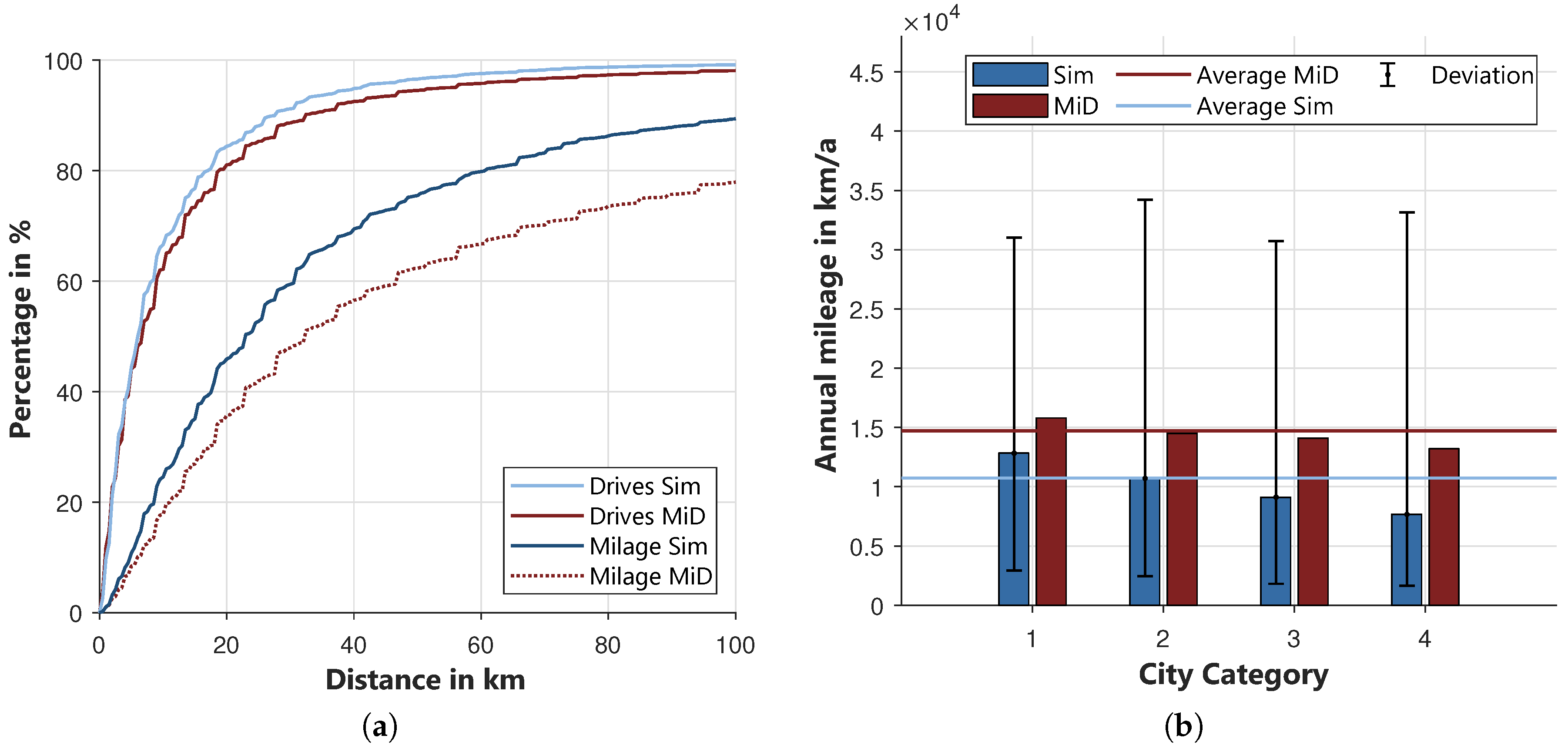
To validate the kilometrage of the cars, the percentage of drives of the total number of drives and of the total kilometrage is calculated as a function of the distance. To illustrate the share of long trips, both shares are cumulative. The resulting curves are compared to those of the MiD data within
Figure 14a. The curves of the percentage of drives are very close. The simulated curve lays slightly over the curve of the MiD. This already suggests that short distances are over-, and very long distances are under-represented, because the simulated curve will reach 100% earlier. The curve of the driving performance confirms this assumption. Almost 90% of the kilometrage is achieved with drives of less than 100 km, whereas in the MiD this value is only 78%. The flattening of the simulated curve starting at 40 km indicates that trips with distances below 40 km are particularly overrepresented. This deviation is partially caused by the underrepresentation of journeys with very long durations in the ZVE. Very long drives can only be generated in the mobility model if the corresponding activities’ durations are generated in the activity model. Furthermore, to achieve a consistent mobility profile, journeys are inserted subsequently. These are assumed to have a constant duration of 10 min. Both reasons cause an overrepresentation of short distances within the model.
Figure 14b compares the average annual kilometrage of the simulated cars with the estimated kilometrage given in the MiD [
46]. The four city categories are considered separately. Besides the annual values, the range in which the simulated driving performance lies is shown. It becomes clear that the model underestimates the total annual kilometrage. In the MiD, the kilometrage representative for Germany is 14,700 km, whereas the simulated kilometrage is only 10,700 km. This means that the total kilometrage is underestimated by around 4000 km. This also becomes clear when comparing the kilometrage of the individual city categories. The deviation for city category 1 is still relatively small. Just like in the MiD, the kilometrage decreases with the city category. In city categories 2 to 4, the difference is significant. The range of deviation of the simulation from the average shows that vehicles with higher kilometrage are also represented in the model. The declarations already mentioned for
Figure 14a can be used at this point again. Due to the higher proportion of drives with short distances and the underrepresentation of individual drives with very long distances, the total annual kilometrage is underestimated. In [
46] it is stated that in metropolitan regions the vehicle is used significantly less than in rural regions. However, the annual kilometrage of both regions is only slightly different. The reason for this is that metropolitan vehicles are used much more frequently for drives over long distances. This behavior cannot be reproduced in the model, as only the commute and the model split depend on the city category. Within the model, the duration of a journey is independent of the city category. The deviations are actually not negligible. However, it must be considered for which purposes the model is to be used, namely to investigate the electrical consumption of households. Therefore, the home charging of electric vehicles will play an important role in the future and this is to be investigated with the model. However, journeys over long distances will play a subordinate role here, as the vehicles will have to access public charging points for this purpose. Hence, the underrepresentation of long drives of the model is tolerated. Trips that are important for home charging of electric vehicles are adequately represented.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}