1. Introduction
The permanent-magnet synchronous motors (SMs) [
1] with many merits are superior to the switched reluctance motors (SRMs) and induction motors (IMs). The permanent-magnet SMs [
2] can offer higher efficiency, higher power density, lower power loss, and higher robustness in comparsion with the SRMs and the IMs at the same volume. The permanent-magnet SMs have mostly adopted the field-oriented control technique owing to their easy implementation. Thereby, output torque can result in lower ripple torque in comparison with the SRMs and IMs at the same output torque. On the other hand, the permanent-magnet SMs controlled by field-oriented control [
1,
2], which can achieve fast four-quadrant operation, are much less sensitive to the parameter variations of the motor. Therefore, they have been widely used in many industrial applications such as robotics [
1], computer numerical control (CNC) tools [
2], and other mechatronics [
3].
The backstepping designs [
4] are befitting for a large type of linearizable nonlinear systems. Each backstepping phase can produce a novel fictitious-control design denoted by previous design phases. When the procedure ends, a feedback design can achieve the primitive design aim by utilizing the last Lyapunov function that made up by adding into the Lyapunov functions regarding all individual design phases [
4]. Moreover, the backstepping control with an adaptive law has been applied in a microgyroscope [
5], automatic train operation [
6], aircraft flight control [
7], power switcher [
8], and synchronous generator [
9]. Further, the backstepping control by using the modified recurrent Rogers–Szego polynomials neural network with decorated gray wolf optimization (DGWO) has been used in the permanent-magnet synchronous linear motor drive system [
10]. The recouped mechanisms in these methods were absent for the estimated uncertainty. Therefore, the main aim of this paper is to improve control performances by using the proposed backstepping control with three adaptive rules using a revised recurring sieved Pollaczek polynomials neural network (RRSPPNN) with reformed grey wolf optimization (RGWO) and recouped controller.
Neural networks (NNs) have better approximation behavior in modeling [
11], identification [
12] and control [
13] of systems. These NNs were the feedforward network structures with static mapping functions. They may not exactly respond the dynamic behavior in real time because of absent feedback loop. The recurrent NNs with feedback loop have been broadly used in the prediction of photovoltaic power output [
14], an accurate electricity spot price prediction scheme [
15], a photovoltaic power forecasting approach [
16], and an adaptive energy management control [
17] as result of higher certification and finer control performance. The primary significant property of the recurrent NN is to recollect feedback message of the foretime effect in the same neuron via its self-link. Moreover, in the general recurrent NNs, the specific self-link feedback of the hidden neuron or output neuron is in charge of recollecting the designated preceding activation of the hidden neuron or output neuron and provender to itself only. Therefore, the outputs of the other neurons have no capacity to infect the designated neuron. However, in a complex nonlinear dynamic system such as the permanent-magnet SM with nonlinear wind stray torque, flux saturation torque, cogging torque, external load torque, and interference of time-varying uncertainties, in general, seriously effect system performances. Hence, if each neuron in the recurring neural networks is considered as a state in the nonlinear dynamic systems, the self-connection feedback type is unable to approximate the dynamic systems efficiently. Due to the recurring neurons, it has certain dynamical merits over static NN and it also has been proverbially applied in photovoltaic power forecasting and electricity spot price prediction. However, these NNs take a longer time to process the online training procedure. Hence, some functional-type NNs, such as the amended recurrent Gegenbauer-functional-expansions NN [
18], reformed recurrent Hermite polynomial NN [
19], and mended recurrent Romanovski polynomials NN [
20], have been broadly applied in the control and identification of nonlinear systems as a result of less calculation complexity. However, the adjustment mechanics of weights were not discussed in these control methods that combined with NNs. It is leads to larger error in control and identification for system. Moreover, the sieved Pollaczek polynomials [
21] belong to the sieved orthogonal polynomials, according to Ismail [
21]. However, the sieved Pollaczek polynomials combined with the NN have never presented in any control of nonlinear systems. Although the feedforward sieved Pollaczek polynomials neural network (SPPNN) can approximate nonlinear function, it may not be an approximated dynamic act of nonlinear uncertainties as a result of lacking a reflect loop. Because of the many benefits compared to the feedforward SPPNN, the revised recurring sieved Pollaczek polynomials neural network (RRSPPNN) control is not introduced yet for controlling the permanent-magnet SM drive system to improve the performances of the nonlinear system and computation complexity. However, the backstepping technique utilizing the RRSPPNN with error recouped agency to decrease uncertainties is thus the main motivation in this topic. Additionally, these learning rates, by utilizing acceleration factors, did not present that the convergent speed of weights is tardy.
A multi-objective grey wolf optimization (GWO) proposed by Emary et al. [
22] was used to attribute the reduction of system. A GWO and conventional NN training method proposed by Mosavi et al. [
23] was used in a sonar dataset category. Khandelwal et al. [
24] proposed to track the programming question of transmitting network by utilizing the modified GWO. Mirjalili et al. [
25] put forward a hunting mechanism of GWO to mimic the social behavior. Even though these algorithms are highly competitive and have been used in certain fields, such as distribution system [
26], melanoma detection [
27], and feature selection in classification [
28], they have poor exploration capability and suffer from local optima stagnation. So, to improve the explorative abilities of GWO, a reformed grey wolf optimization (RGWO) algorithm adopting two exponential-functional adjustable factors is put forward as the novel method in this paper. This newly proposed algorithm makes up two revisions: Firstly, it can explore new regions in the look for space because of diverse locations assigned to the leaders. This can increase the exploration and avoid local perfect stagnation problem. Secondly, an opposition-based learning method has been used in the initial half of iterations to provide diversity among the search agents. To speed up the convergence of weights in the RRSPPNN, the RGWO with two exponential-functional adjustable factors, that is the novel method, is used to adjust the two learning rates of the weights. This novel method can prevent premature convergence and to acquire optimal learning rates with fast convergence.
The better control performance of the permanent-magnet SM drive system cannot be reached by utilizing the linear controller due to the influences of these uncertainties. To heighten robustness, the backstepping approach with three adaptive rules and a swapping function is proposed to control the permanent-magnet SM drive system to trace different periodical references. With the backstepping approach with three adaptive rules and a swapping function, the rotor position of the permanent-magnet SM drive system preserves the merits of fine transient control performance and robustness to uncertainties for the tracedifferent periodical references. Moreover, to improve the large chattering influence under uncertainties, the backstepping control with three adaptive rules by utilizing RRSPPNN with RGWO is proposed to estimate the internal bunched uncertainty and external bunched force uncertainty and the recouped controller to recoup the smallest fabricated error of the appraised rule.
Furthermore, the RGWO algorithm by using two exponential-functional adjustable factors that is applied for regulating two learning rates of the weights in the RRSPPNN is a novel method to speed up the convergence of weights in this paper. Finally, the efficiency of the backstepping control with three adaptive rules using RRSPPNN with RGWO and recouped controller is validated by some test results.
The important issue in this paper is described below.
Section 2 presents the models and conformation of the permanent-magnet SM drive.
Section 3 describes the backstepping control with three adaptive rules using RRSPPNN with RGWO and the recouped controller.
Section 4 is the examination consequences for the permanent-magnet SM utilizing three control methods at five tested events.
Section 5 is the conclusion.
3. Design of the Controller
When the permanent-magnet SM drive system with the electromagnetic torque, the wind stray torque, the flux saturation torque, the cogging torque, the parametric variations, and the external load torque disturbance is enacted, then Equation (7) is typified by
where
and
stand for the rotor position and rotor speed of the SM to be presumed bounded;
and
stand for two parametric uncertainties from
and
to be presumed bounded;
;
;
stand for three real numbers to be presumed bounded;
is the control propulsion of the permanent-magnet SM drive system, i.e., the propulsion current. Equation (9) can be typified by
where
and
stand for two parametric variation that are to be presumed bounded;
and
stand for the internal bunched uncertainty and external bunched force uncertainty to be presumed bounded.
The trace reference locus is the control goal. The design procedure is as below.
The trace error is typified by
Take differential of (13) by
The stabilizing function is typified by:
where
and
stand for two positive constants;
stands for the integral factor.
The fictitious trace error is typified by:
Take the differential of (16) by
where
,
, and
stand for three unknown parameters. The estimated errors are typified by
where
,
, and
are the estimated errors;
,
, and
are the estimated values of
,
and
. The internal bunched uncertainty and external bunched force uncertainty
satisfies the condition
and is to be presumed bounded.
3.1. Design of the Backstepping Control with Three Adaptive Rules and a Swapping Function
So, to design the backstepping control with three adaptive rules and a swapping function, the Lyapunov function can be typified by:
By taking the differential of
and by utilizing Equations (14)–(20) and the integral factor
, Equation (21) can be typified by
In accordance with Equation (22), the control propulsion
in the backstepping control with three adaptive rules and a swapping function can be typified by
where
stands for a positive constant;
stands for upper bound that is a constant, and
stands for a swapping function. By utilizing Equation (23), Equation (22) can be typified by:
For reaching
, three adaptive rules
,
, and
can be typified by
By utilizing Equations (25)–(27), and
, then Equation (24) can be typified by
Equation (28) shows
to be negative semi-definite (i.e.,
), meaning that
and
are bounded. The following term is typified by
The integration of Equation (29) is typified by:
Because
is bounded and
is nonincreasing and presumed bounded, then
. Moreover,
is presumed bounded, hence
is a uniformly continuous function. By utilizing the Barbalat’s lemma [
29,
30], it can be portrayed that
. That is,
and
will converge to zero when
. Furthermore,
and
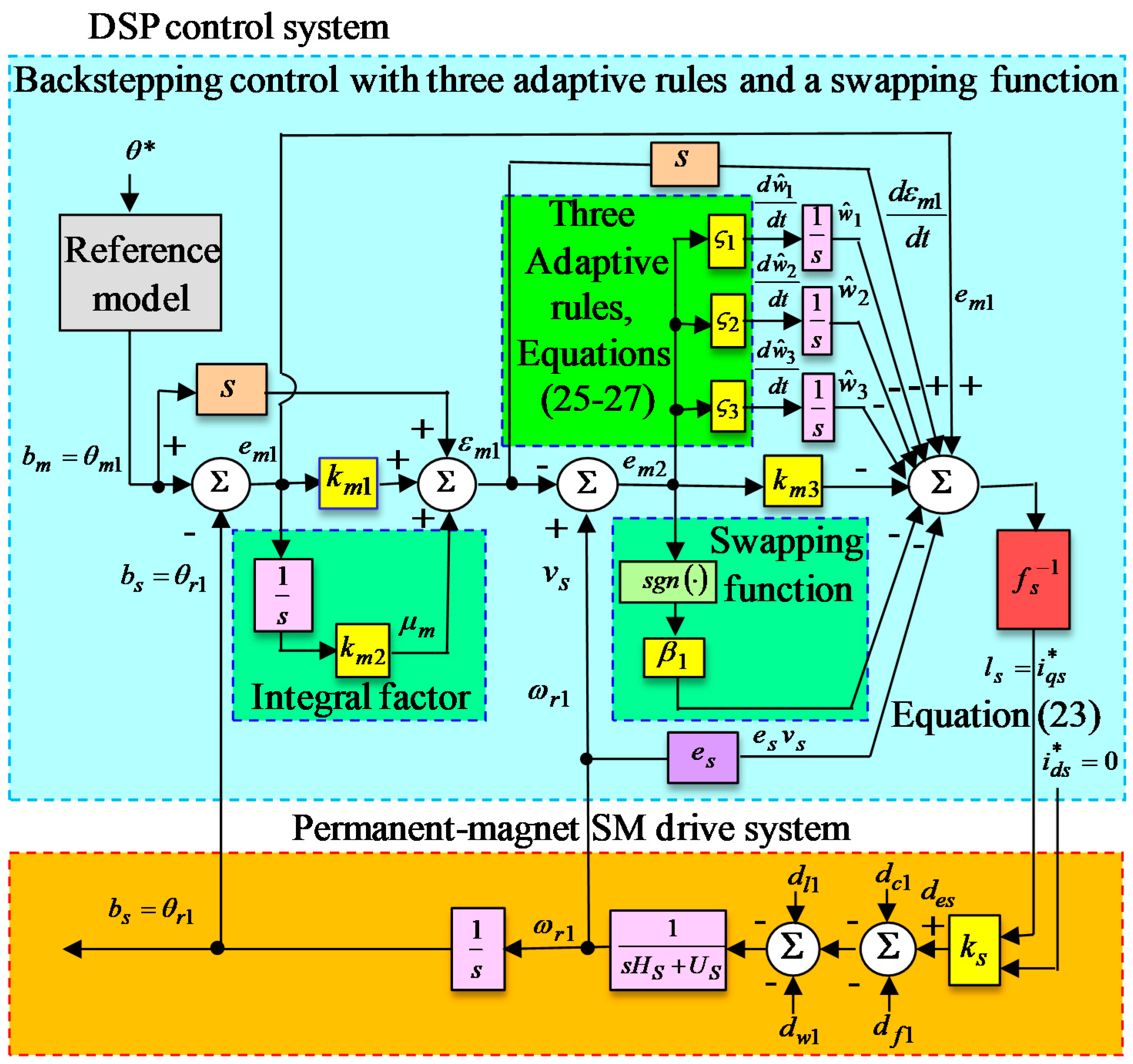
. The stability of the backstepping control with three adaptive rules and a swapping function can be guaranteed, and consequently, the control block diagram is portrayed in
Figure 3.
3.2. Design of the Backstepping Control with Three Adaptive Rules Using RRSPPNN with RGWO and Recouped Controller
Because the internal bunched uncertainty and external bunched force uncertainty is unknown, and its upper bound is troublesome to be decided. The appraised value of the internal bunched uncertainty and external bunched force uncertainty is not easy to be estimated, and consequently, the revised recurring sieved Pollaczek polynomials neural network (RRSPPNN) is proposed to adapt the real value of the internal bunched uncertainty and external bunched force uncertainty .
3.2.1. Constitution of RRSPPNN
The RRSPPNN has a three-layer constitution, with the first layer (input layer), the second layer (hidden layer 1), and the third layer (output layer) portrayed in
Figure 4. The semaphore intentions in each node for each layer are explained in the following expression.
At the first layer, input semaphore and output semaphore are typified by
where
and
stand for the speed discrepancy and speed discrepancy alteration, respectively.
B is the iteration count.
stands for the recurring weight through the third layer and the first layer.
stands for the output of node at the third layer. The symbol
stands for a multiply factor.
At the second layer, input semaphore and output semaphore are typified by
where
stands for the recurring gain at the second layer. Sieved-Pollaczek polynomials function [
21,
31] is adopted as the activation function.
stands for the sieved Pollaczek polynomials in the interval [−1, 1].
,
and
stand for the zero-order, first order and second order sieved Pollaczek polynomials, respectively. The sieved Pollaczek polynomials may be generated by the recurrence relation [
21,
31]
. The symbol
stands for a summation factor.
At the third layer, semaphore and output semaphore are typified by
where
stands for the connecting weight through the second layer and the third layer.
stands for the linear activation function. The output
at the third layer of the RRSPPNN can be typified by:
where
and
stands for the weight vector at the third layer and the input vector at the third layer, respectively. The smallest fabricated error
is typified by
where
stands for an ideal weight vector that reaches the smallest fabricated error. So as to make up the smallest fabricated error
, the recouped controller
with an appraised rule is proposed. It is presumed that the small positive number
stands for greater than absolute value of
, i.e.,
. The Lyapunov function is typified by
where
stands for an adaptive gain.
stands for the appraised error to be presumed bounded. By taking the derivative of
utilizing Equations (14)–(20) and the integral factor
, then Equation (36) is typified by
In accordance with Equation (37), the control propulsion
in the backstepping control with three adaptive rules by using RRSPPNN with RGWO and recouped controller can be typified by
By utilizing Equation (38), then Equation (37) can be typified by
By utilizing Equations (25)–(27) and
, then Equation (39) can be typified by
3.2.2. Recouped Controller with an Adaptive Rule
To reach
, the adaptive rule
, the recouped controller
, and the appraised rule
to reduce uncertainties influences can be typified by:
By substituting Equations (41)–(43) into Equation (40) and by utilizing
, then Equation (40) can be typified by:
Equation (44) portrays
to be negative semi-definite, i.e.,
, meaning that
and
are bounded. By utilizing the Barbalat’s lemma [
29,
30], it can be represented that
at
by way of Equations (29), (30) and (44), i.e.,
and
will converge to zero at
. The stability of the backstepping control with three adaptive rules by using RRSPPNN with RGWO and recouped controller can be ensured and consequently the control block diagram is portrayed in
Figure 5.
3.2.3. Training of the RRSPPNN
By utilizing the Lyapunov stability and the gradient descent skill with the chain rule, a training skillfulness of parameters in the RRSPPNN can be derived. The RGWO with two adjusted factors is applied to look for two better learning rates in the RRSPPNN to acquire faster convergence. The connecting weight parametric presented in Equation (41) can be typified by:
A goal function that explains the online training procedure of the RRSPPNN is typified by
The adaptive learning rule of the connecting weight is typified by:
It is well-known that
by way of Equations (45) and (47). Hence, the adaptive learning rule of recurring weight
is typified by
where
stands for the learning rate. To acquire better convergence, the RGWO is applied to look for two changeable learning rates in the RRSPPNN. Additionally, for improving convergence and looking for two perfect learning rates, the RGWO with two adjusted factors is proposed in this study.
3.2.4. Algorithm of Reformed Grey Wolf Optimization (RGWO)
In the RGWO, the optimization is conducted by
,
, and
. The RGWO algorithm can be typified by:
where
is a vector two learning rates,
are typified by:
where
stand for the three vectors as the three best solutions.
and
can be typified by:
where
and
stand for two random vectors. The updated numbers of two adjusted factors
and
control the tradeoff between exploration and exploitation. Two exponential-functional adjustable factors
and
stand for the updated values at iteration according to the following presentation by:
where
stands for the iteration number;
and
stand for the total numbers of iteration allowed for the optimization. At last,
stands for the best solution in connection with the learning rates
of the two weights in the RRSPPNN. Hence, the better numbers could be optimized by utilizing RGWO with two adjusted factors that yield two changeable learning rates for two weights to look for two perfect values and to speed-up the convergence of two weights.
4. Test Results
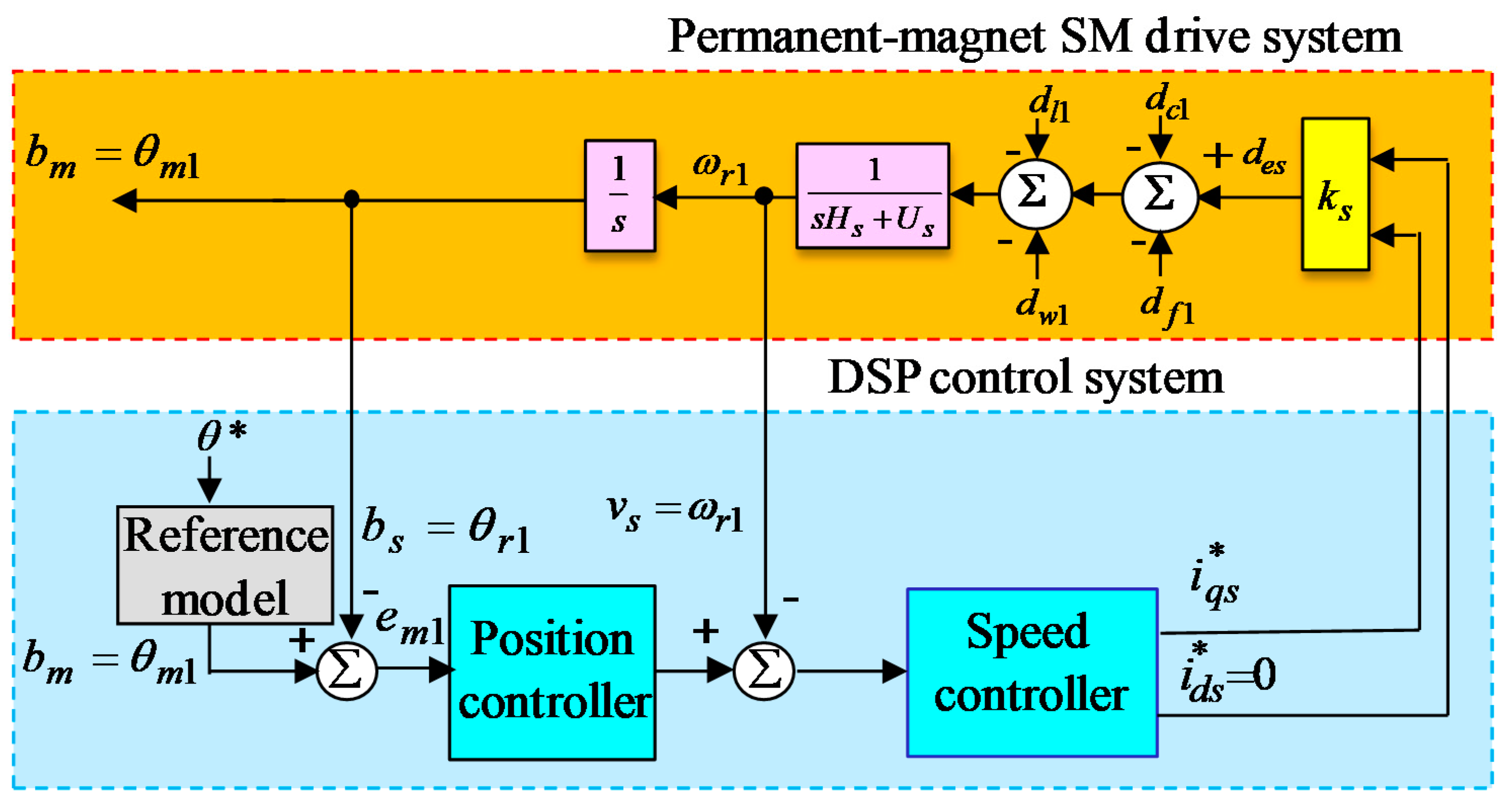
A block diagram of the FOC permanent-magnet SM drive system utilizing the DSP controller is portrayed in
Figure 1. A photo of the examination structure is portrayed in
Figure 6. The sampling time of the control program in the examination is set as 2 ms.
A DSP controller involves 18 channels of input/output (I/O) ports with 6 channels of pulse-width-modulation (PWM) ports, 6 channels of analog-digital (A/D) converters, and 2 channel encoder connective ports. The coordinate transformation in the field-oriented control (FOC) is realized by DSP controller. The used control technologies in the real-time realization by utilizing the DSP controller are composed of the core program and the sub-core interrupt service routine (SCISR) in the DSP controller as portrayed in
Figure 7. In the core program, parameters and I/O initialization are processed. The interrupt time for the SCISR is set. After permitting the interruption, the core program is used to monitor control data. The SCISR with 2 msec sampling time is used for reading the rotor position of the permanent-magnet SM drive system from encoder and three-phase currents by way of A/D converter circuit, calculating reference model and position error, executing lookup table and coordinate transformation, executing the backstepping control with three adaptive rules using RRSPPNN with RGWO and recouped controller, and outputting three-phase current mandates to swap sinusoidal pulse-width-modulation (SPWM) voltage source inverter with three-sets of insulated-gate bipolar transistor (IGBT) power modules by way of the lockout-time and isolated circuits. The SPWM voltage source inverter with three-sets of IGBT power modules is carried out by SPWM control with a switching frequency of 15 kHz. Additionally, the tested bandwidth of the position control loop and the tested bandwidth of the current control loop are about 90 and 900 Hz for the permanent-magnet SM drive system under the nominal event. The proposed controllers are realized by the DSP controller. The coordinate transformation in the FOC is realized by the DSP controller. The control goal is to control the rotor to rotate 6.28 rad cyclically. Then, when the mandate is a sinusoidal reference locus, the reference is set one.
For a comparison of control performance with the four controllers, five events are provided in the experiment. The four controllers are the popular PI controller as the controller FC1, the backstepping control with three adaptive rules and a swapping function as the controller FC2, the modified recurrent Rogers–Szego polynomials neural network with DGWO [
10] as the controller FC3, and the backstepping control with three adaptive rules using RRSPPNN with RGWO and recouped controller as the controller FC4. Five tested events are as follows. Event CQ1 is the nominal event at periodic step command from 0 rad to 6.28 rad. Event CQ2 is the cogging torque, the column friction torque, and the Stribeck effect torque, and the parameters variations event with 4 times the nominal value at periodic step command from 0 rad to 6.28 rad. Event CQ3 is the nominal event due to periodic sinusoidal command from −6.28 rad to 6.28 rad. Event CQ4 is the cogging torque, the column friction torque and the Stribeck effect torque and the parameters variations event with 4 times the nominal value due to periodic sinusoidal command from −6.28 rad to 6.28 rad. Event CQ5 is the adding load torque disturbance
.
Two control gains of the popular PI controller as the controller FC1 are
and
by using the Kronecker method to construct a stability boundary in the
and
plane [
32,
33,
34] on the tuning of the PI controller at Event CQ1 in the position trace so as to reach fine steady-state and transient-state control responses.
Some control gains of the backstepping control with three adaptive rules and a swapping function as the controller FC2 are
,
,
,
,
,
,
according to heuristic knowledge [
4] at Event CQ1 in the position trace so as to reach fine steady-state and transient-state control representation.
Some control gains of the modified recurrent Rogers–Szego polynomials neural network with DGWO [
10] as the controller FC3 are given as
,
,
,
,
,
,
,
according to heuristic knowledge [
4] at Event CQ1 in the position trace so as to reach fine steady-state and transient-state control responses. Moreover, numbers of neurons in the input layer, the hidden layer, and the output layer of the modified recurrent Rogers-Szego polynomials neural network are 2 neurons, 4 neurons and 1 neuron, respectively, so as to demonstrate the effectiveness of the controller adopting small neuron numbers. The method proposed by Lewis et al. [
35] is used to initialize some parameters of the modified recurrent Rogers–Szego polynomials neural network. The adjustment process of these parameters involve a continuous reaction for the duration of the examination.
Some control gains of the backstepping control with three adaptive rules using RRSPPNN with RGWO and recouped controller as the controller FC4 are
,
,
,
,
,
,
,
according to heuristic knowledge [
4] at Event CQ1 in the position trace so as to reach fine steady-state and transient-state control responses. Moreover, the number of neurons in the first layer, the second layer, and the third layer of the RRSPPNN are 2 neurons, 4 neurons, and 1 neuron, respectively, so as to demonstrate the effectiveness of the controller by adopting small neuron numbers. The method proposed by Lewis et al. [
35] is used to initialize some parameters of the RRSPPNN. The adjustment process of these parameters is keeping continusly reaction in the duration of the experiments.
All of the experiments obtained by utilizing the four controllers for controlling the permanent-magnet SM drive system at five events are as follows.
Figure 8a–d are rotor position responses via experiments obtained by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ1.
Figure 9a–d are rotor speed responses by utilizing the controllers FC1, FC2, FC3 and FC4 at Event CQ1.
Figure 10a–d are mandate control propulsion responses by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ1.
Figure 11a–d are rotor position responses by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ2.
Figure 12a–d are rotor speed responses by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ2.
Figure 13a–d are mandate control propulsion responses by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ2.
Figure 14a–d are rotor position responses by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ3.
Figure 15a–d are rotor speed responses by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ3.
Figure 16a–d are mandate control propulsion responses by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ3.
Figure 17a–d are rotor position responses by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ4.
Figure 18a–d are rotor speed responses by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ4.
Figure 19a–d are mandate control propulsion responses by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ4.
Figure 20a–d are measured rotor position responses by utilizing the controller FC1, FC2, FC3, and FC4 at Event CQ5.
Figure 8a and
Figure 14a obtained by utilizing the controller FC1 for controlling the permanent-magnet SM drive system at Event CQ1 and Event CQ3 are displayed as fine trace responses of the rotor positions.
Figure 11a and
Figure 17a obtained by utilizing the controller FC1 for controlling the permanent-magnet SM drive system at Event CQ2 and Event CQ4 are displayed in sluggish trace responses of the rotor position owing to bigger nonlinear disturbance. Because of inappropriate tuning gains or the degenerate nonlinear effect, the linear controller has weak robustness under bigger nonlinear disturbance.
Figure 8b,
Figure 11b,
Figure 14b and
Figure 17b obtained by utilizing the controller FC2 for controlling the permanent-magnet SM drive system at Events CQ1, CQ2, CQ3, and CQ4 are displayed as good trace responses of the rotor positions. However,
Figure 10b,
Figure 13b,
Figure 16b and
Figure 19b are displayed as serious vibration in the control propulsions by utilizing the swapping function with large upper bound at Events CQ1, CQ2, CQ3, and CQ4. It is a well-known fact that the control propulsions with serious vibration will wear the bearing mechanism and might excite unstable system dynamics.
Figure 8c,
Figure 11c,
Figure 14c and
Figure 17c obtained by utilizing the controller FC3 for controlling the permanent-magnet SM drive system at Events CQ1, CQ2, CQ3, and CQ4 are displayed as better trace responses of the rotor positions due to adaptive mechanism action.
Figure 10c,
Figure 13c,
Figure 16c and
Figure 19c displayed a small vibration in the control propulsions at Events CQ1, CQ2, CQ3, and CQ4. Due to the on-line adaptive adjustment of the modified recurrent Rogers–Szego polynomials neural network [
10], the magnitudes of vibration in the control propulsions at Events CQ1, CQ2, CQ3, and CQ4 displayed in
Figure 10c,
Figure 13c,
Figure 16c and
Figure 19c have been slightly improved.
Figure 8d,
Figure 11d,
Figure 14d and
Figure 17d obtained by utilizing the controller FC4 for controlling the permanent-magnet SM drive system at Events CQ1, CQ2, CQ3, and CQ4 are displayed as best trace responses of the rotor positions due to on-line adaptive mechanism action.
Figure 10d,
Figure 13d,
Figure 16d and
Figure 19d are displayed as smaller vibrations in the control propulsions at Events CQ1, CQ2, CQ3 and CQ4 due to on-line adaptive mechanism action of the RRSPPNN. Due to on-line adaptive adjustment of the RRSPPNN under bigger nonlinear disturbance the magnitudes of vibration in the control propulsions at Events CQ1, CQ2, CQ3, and CQ4 displayed in
Figure 10d,
Figure 13d,
Figure 16d and
Figure 19d have been obviously improved.
Figure 20d obtained by utilizing the controller FC4 for controlling the permanent-magnet SM drive system at Event CQ5 under load regulation is better than the controller FC1, FC2, and FC3 displayed in
Figure 20a–c.
5. Discussion and Analysis
Additionally, the control performances displayed in comparsion results by using the controllers FC1, FC2, FC3, and FC4 are listed in
Table 1 in connection with five events with some test results. The 0.21, 0.19, 0.15, and 0.10 are the maximum errors of
(rad) by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ1, respectively. The 0.11, 0.09, 0.07, and 0.05 are the root-mean-square errors of
(rad) by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ1, respectively. The 0.56, 0.36, 0.28, and 0.19 are the maximum errors of
(rad) by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ2, respectively. The 0.27, 0.18, 0.13, and 0.09 are the root-mean-square errors of
(rad) by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ2, respectively. The 0.21, 0.18, 0.14, and 0.10 are the maximum errors of
(rad) by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ3, respectively. The 0.10, 0.09, 0.07, and 0.05 are the root-mean-square errors of errors of
(rad) by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ3, respectively. The 0.52, 0.37, 0.27, and 0.18 are the maximum errors of
(rad) by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ4, respectively. The 0.25, 0.18, 0.13, and 0.09 are the root-mean-square errors of
(rad) by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ4, respectively. The 3.01, 1.57, 1.13, and 0.75 are the maximum errors of
(rad) by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ5, respectively. The 1.50, 0.78, 0.56, and 0.32 are the root-mean-square errors of
(rad) by utilizing the controllers FC1, FC2, FC3, and FC4 at Event CQ5, respectively. The controller FC4 has smaller trace error in comparison with the controllers FC1, FC2, and FC3. The controllers FC4 indeed yields the exellent control performance from
Table 1.
Furthermore, control characteristic performance comparisons in the controllers FC1, FC2, FC3, and FC4 are listed in
Table 2 for test results. In
Table 2, various performances with regard to the control propulsion with vibration, the dynamic response, the ability of load regulation, the convergence speed, the position trace error, and the rejection ability of parameter disturbance in the controllers FC4 are superior to the controllers FC1, FC2, and FC3. Finally, the robust control performance of the controller FC4 demonstrates outstanding performance for controlling the permanent-magnet SM drive system in the trace of the periodic step and sinusoidal commands under the occurrence of parameter disturbance and load regulation due in large part to the on-line adaptive adjustment of the RRSPPNN.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}