1. Introduction
The increase of renewable energy production has raised a lot of concerns about the capability of distribution networks to host distributed generation. The shift towards bi-directional power flows in distribution networks set new demands for planning algorithms that are able to cope with new requirements of network operation strategies. Due to the complexity of planning tasks, the significance of a good quality starting point for an optimisation process cannot be overestimated.
Power system planning is a complex optimisation task. The nonlinear nature of power flow equations can be relaxed or substituted with convex equivalents [
1]. The binary nature of network connections, however, has still no workaround. Topology optimisation, as any other combinatorial optimisation, is inherently computationally demanding in finding the global optimum for a large system. Numerous attempts to solve the network topology problem have been addressed in works employing mathematical and heuristic programming. A second-order cone programming formulation for distribution network reconfiguration was utilized in [
2,
3]. A similar formulation was employed in [
4] to include active network expansion planning under different scenarios. A multi-objective seeker-optimisation heuristic algorithm was proposed in [
5] for optimal design of distribution network. A scenario-based expansion planning with genetic algorithm optimization was presented in [
6]. The authors of [
7] propose a hybrid Tabu search and particle swarm optimization to address medium-voltage network expansion planning. Heuristics provide a trade-off between accuracy and computation time. Despite the advantages, heuristics cannot guarantee to reach the global solution. Due to that reason, mathematical programming tools are still preferred by a large number of researchers.
The importance of warm-starting an optimisation algorithm with an initial solution has been emphasised in several works. The authors in [
3] have stated that convergence time can be greatly accelerated if a good starting solution is provided. Likewise, Ref. [
2] has stated that an initial solution for a mixed-integer problem can save time for a later stage of branch-and-cut of the search tree that would help optimization to reach the optimum in a smaller number of iterations. Authors of [
8] highlighted a promising field for initial topology generation. A warm up strategy is utilized in [
9] to prune inactive edges of a network topology and reduce the search tree. Most solvers have built-in heuristics to guess a feasible starting point, but the actual routine of generating an initial solution is beyond the user’s control.
Somewhat naturally, network planning often involves an expansion of existing networks. An expansion by reconfiguration of network connections was presented in [
10]. Similarly, an expansion planning for multistage problem with simplified objective function was shown in [
11]. An optimal utilization of connection boxes within an existing network was presented in [
12]. Possible new connections are added to predefined corridors, while keeping the rest of the network untouched. This way, the number of options is limited, thus cutting computation time and giving predictable solutions. A topology optimisation method based on a branch-and-bound algorithm was developed in [
8]. Even though the method was not dedicated specifically for initial network generation, the authors highlighted its potential warm-starting enhanced algorithms. The method was showcased on a realistic network from Brazil; however, it was scaled down to several hundreds of nodes. The initial network problem was addressed in [
13]. It is based on node topological information and is easy to implement as no demanding computation is involved. Still, it considers reconfiguration of existing networks with given tie switches at fixed locations. The scalability of the presented method is great. Nevertheless, the given possible tie switch locations lessen the work for the algorithm.
An algorithm in [
14] modifies the minimum spanning tree (MST) to reduce the optimality gap and take the objective closer to the optimal solution. In the cornerstone of the algorithm lies the assumption that by relaxing the radiality constraint, thus adding extra node connections, a better objective value can be achieved. The method provides an efficient solution and is scaled up to hundreds of nodes. The method covers reconfiguration of an existing network, but as with all the works mentioned above, it does not demonstrate a case with greenfield planning.
Greenfield planning implies no predefined connection options in a planning task, which leaves an enormous number of possible connection combinations. To narrow down the feasible region in greenfield planning, meshing techniques can be employed. Most widely used is the Delaunay triangulation, which sets predefined connection paths in a mesh-like structure. A network is optimized by a combination of steepest descent and simulated annealing in [
15]. The available connections were predefined and constituted a mesh-like structure to initialize the optimization process. A network optimization by bacterial foraging algorithm was initialized by a triangular mesh of a network in [
16]. In [
17], the candidate nodes and lines are prioritized and the topology is found by dynamic programming, with the following relocation of some predefined nodes to improve the objective value. In a densely populated city environment, a street grid was adopted as a starting ground for a network in [
18]. However, many prefer to use the advantage of warm-start capabilities of other methods. The vast majority of warm-start initial networks are based on the MST. Genetic based algorithms use a chromosome coding, such as the Prüfer sequence, which represents a spanning tree, and the population is a set of feasible spanning trees [
19]. Additionally, the MST was employed in [
20,
21] to create a set of feasible network topologies as initial populations for genetic algorithms. A multistage expansion planning algorithm demonstrated in [
22] utilized an MST to construct a radial network for the medium-voltage stage of the distributed network optimization. A spatial optimization algorithm in [
23] utilizes MST as an initialization topology for further search of the Steiner point. The Prim’s or Kruskal’s algorithms are commonly employed for MST generation, and just a few attempts to improve it hints that most of the researchers are satisfied with it.
The general idea of initial network generation remains in the shade of the MST dominance. Nevertheless, a few authors have proposed alternatives. An initial network generator was presented in [
24]. Load nodes are divided into sectors around each feeding substation. Feeders are formed that connect each node within each sector with a minimum cost algorithm that utilises an approximate power flow based on the not-yet-connected remaining demand of the sector. The number of sectors are then progressively increased to find the minimum of the total cost that complies with the technical constraints.
The authors of [
25] proposed an optimisation algorithm, in the base of which lies a clustering of load nodes. The nodes are spatially clustered into groups with similar power demand. The topology within each cluster is then found based on reliability requirements, and the feasibility of the topology is validated. The method is easily scalable up to large number of nodes, but, in essence, it divides the network into a number of small networks and still relies on the MST.
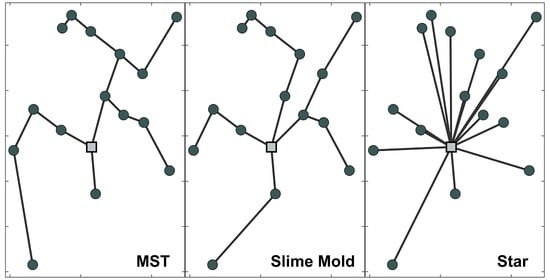
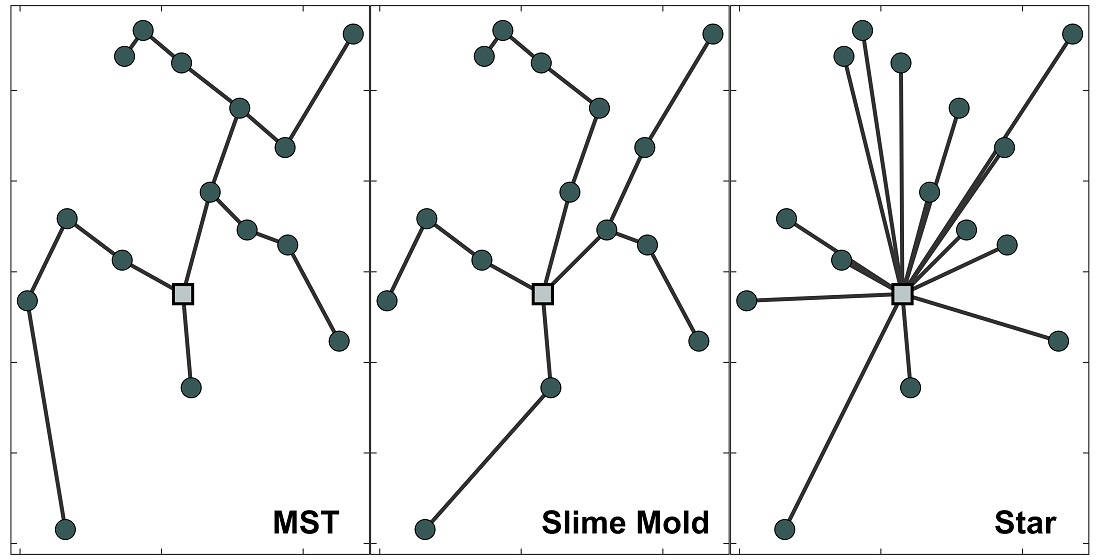
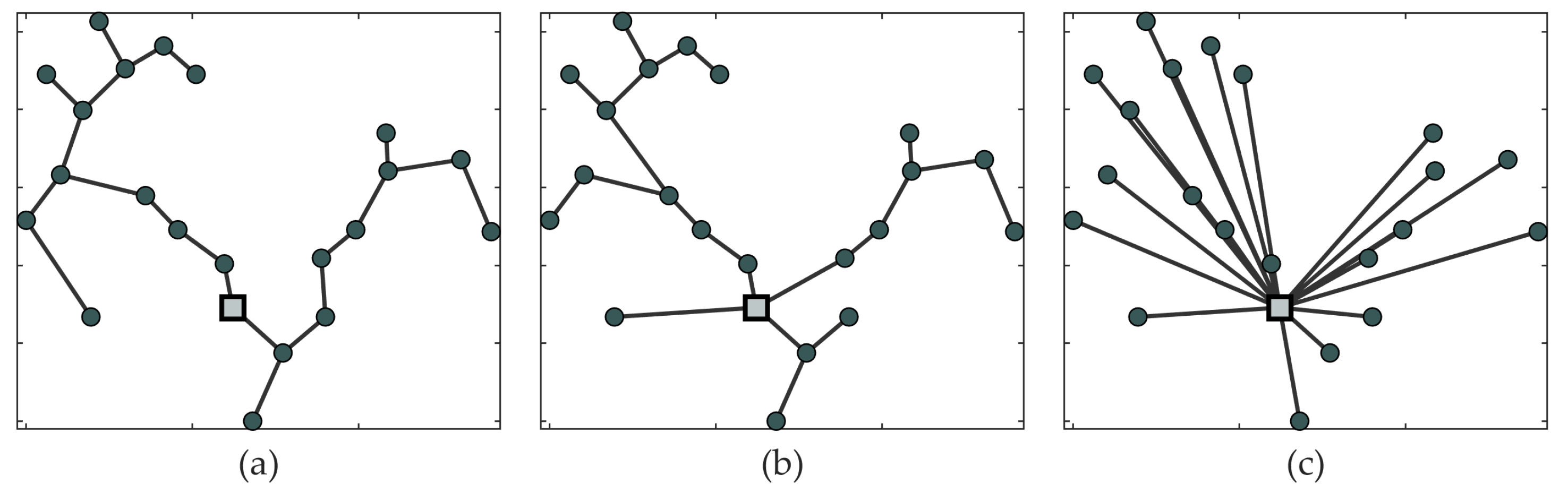
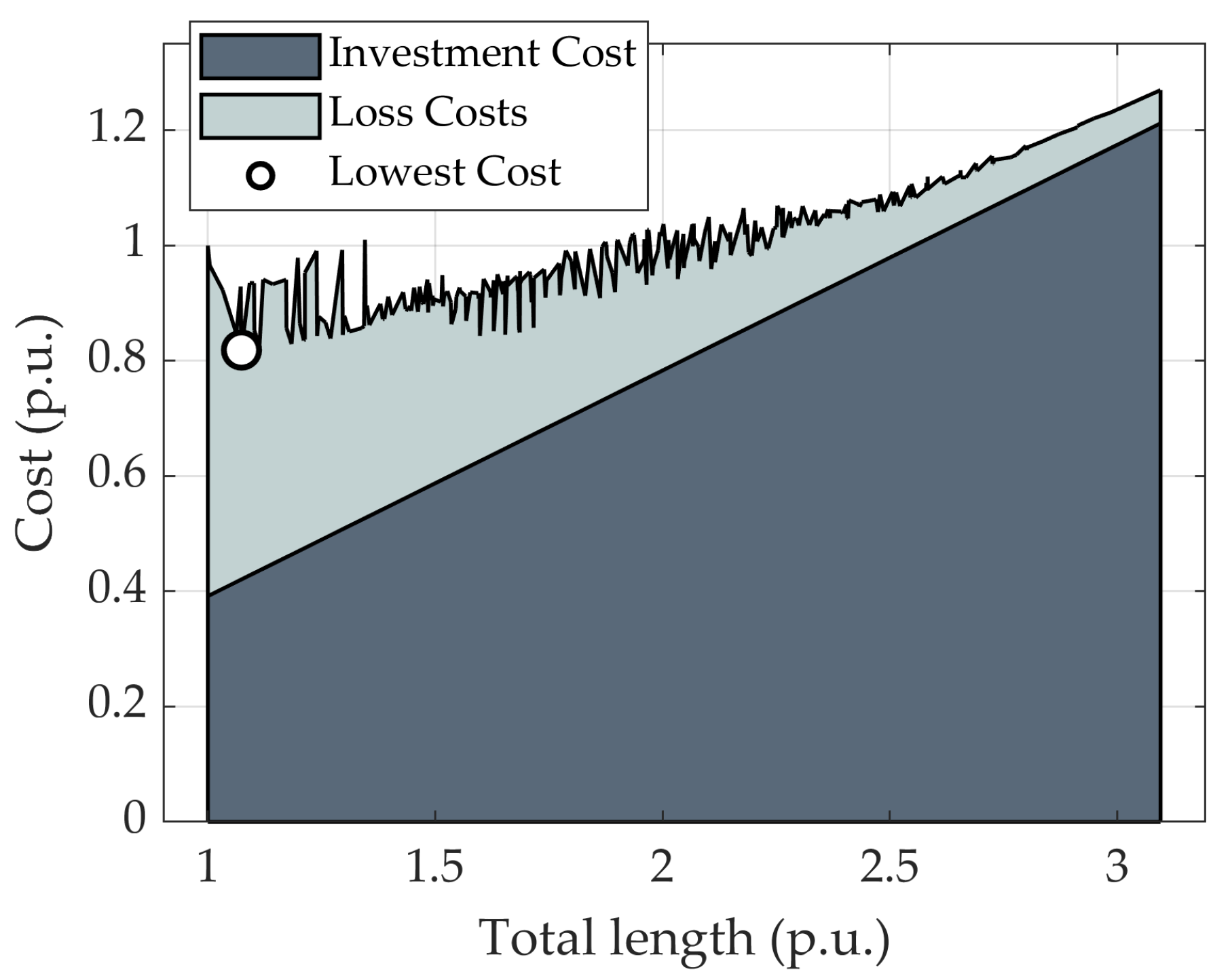
The MST is easy to understand and implement, but it minimises only the length of a network. The other crucial components of the total cost, such as loss costs and others, are neglected. On the contrary, the method proposed in [
26] prefers to start from the other extreme, a star-like topology. Load nodes are connected to the feeding point via straight lines. The investment costs are sacrificed in order to gain the smallest loss costs but guarantees technical compliance in an initial network that is far from optimal. However, in real life cases, the optimal topology lies somewhere in between. The proposed method finds a balance between the MST and the star-like topology.
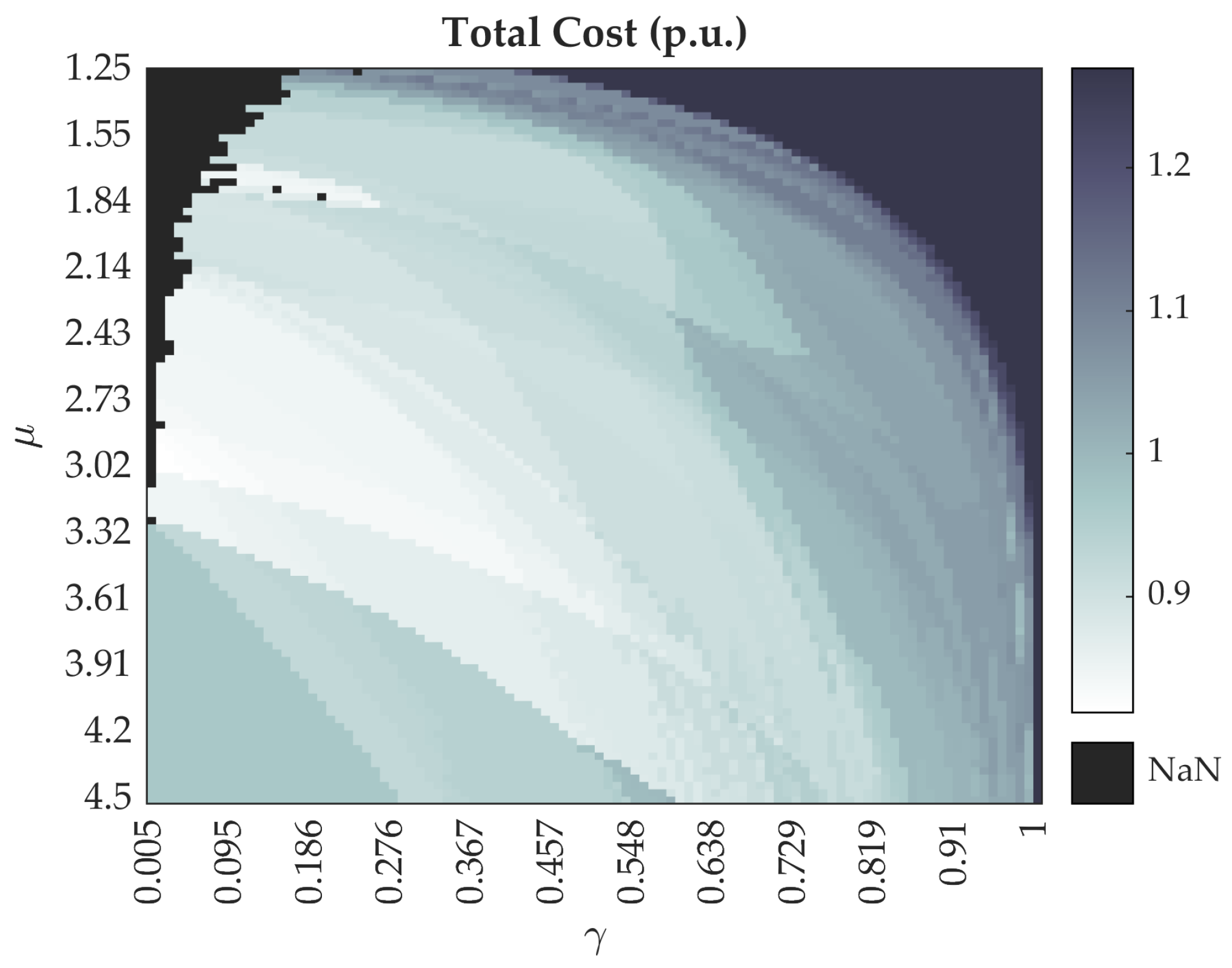
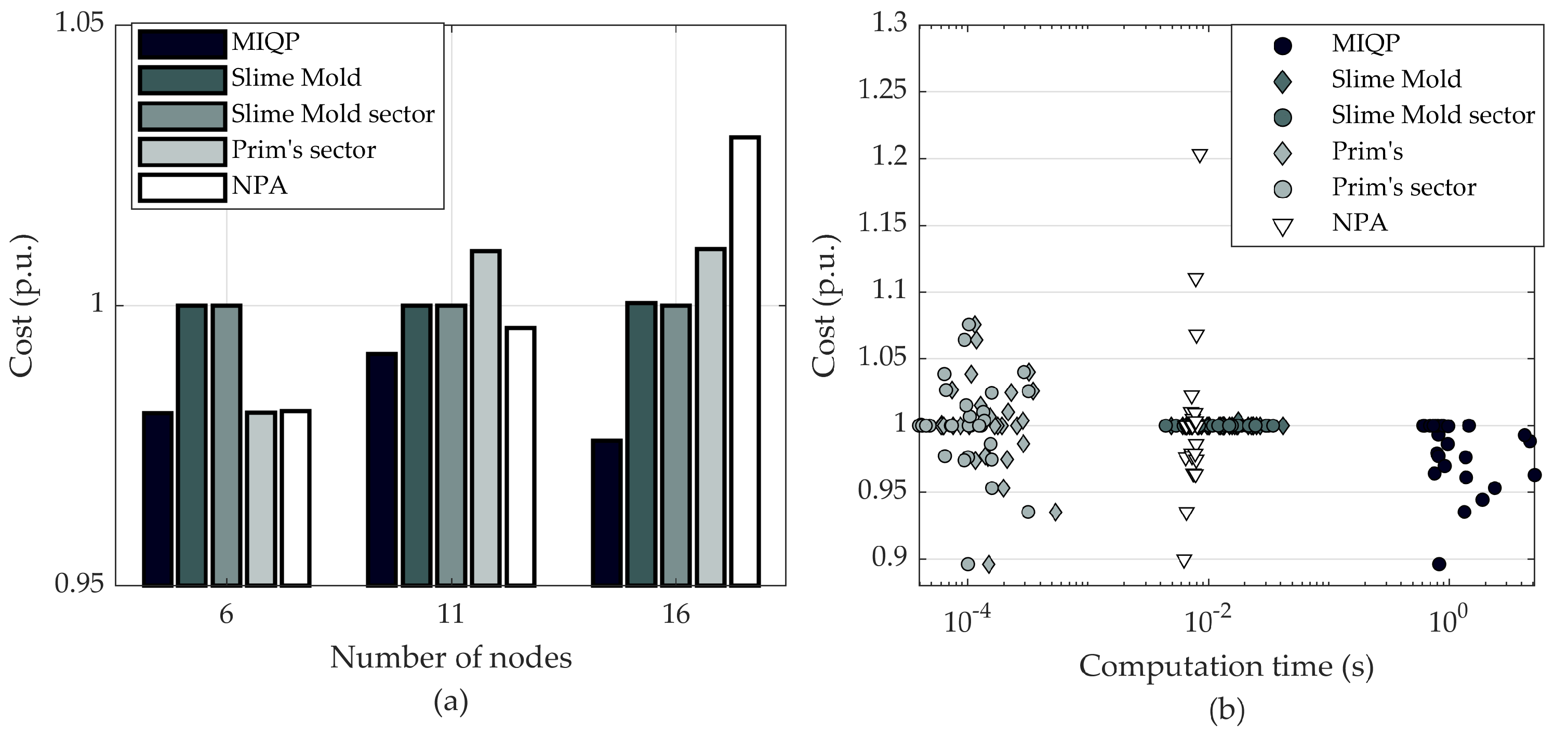
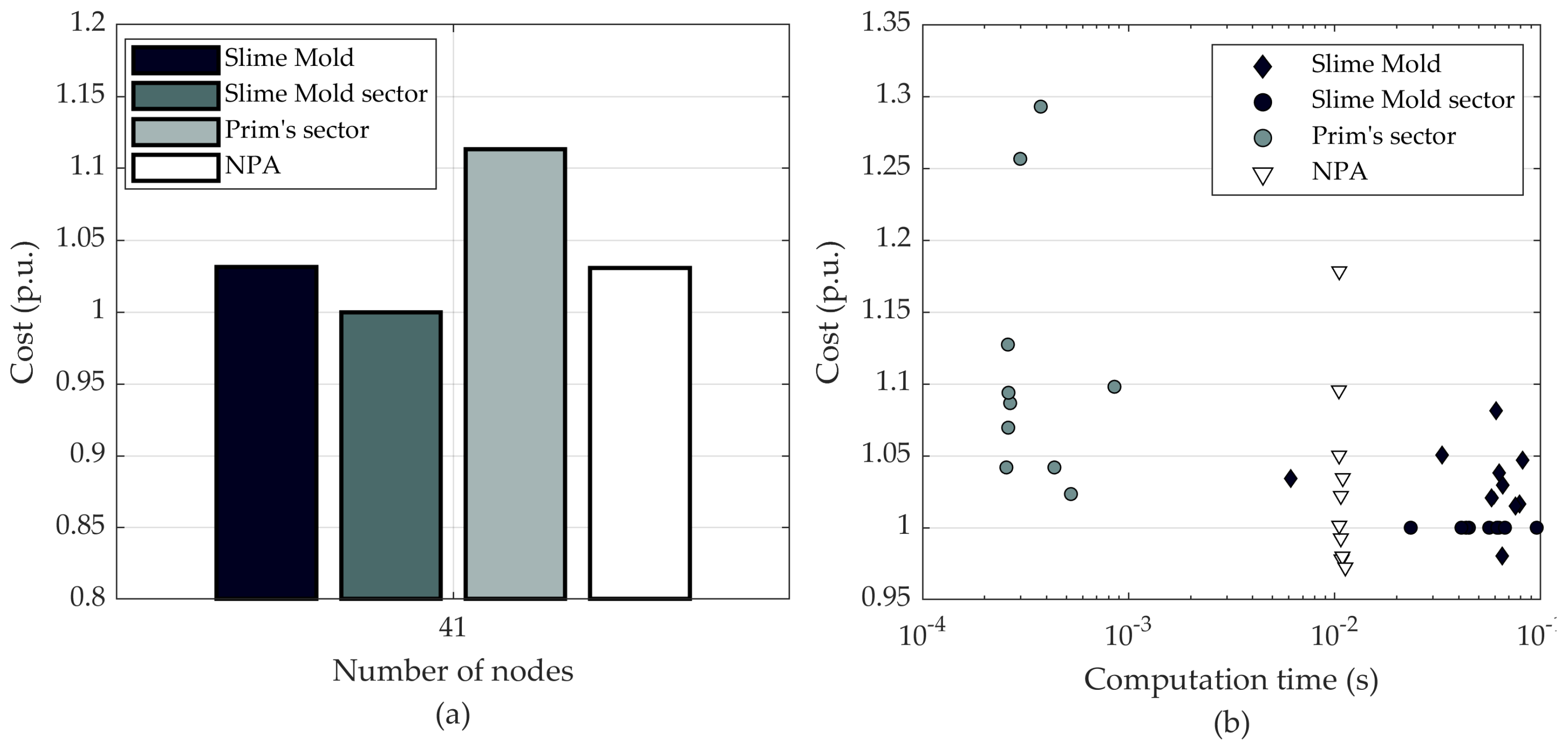
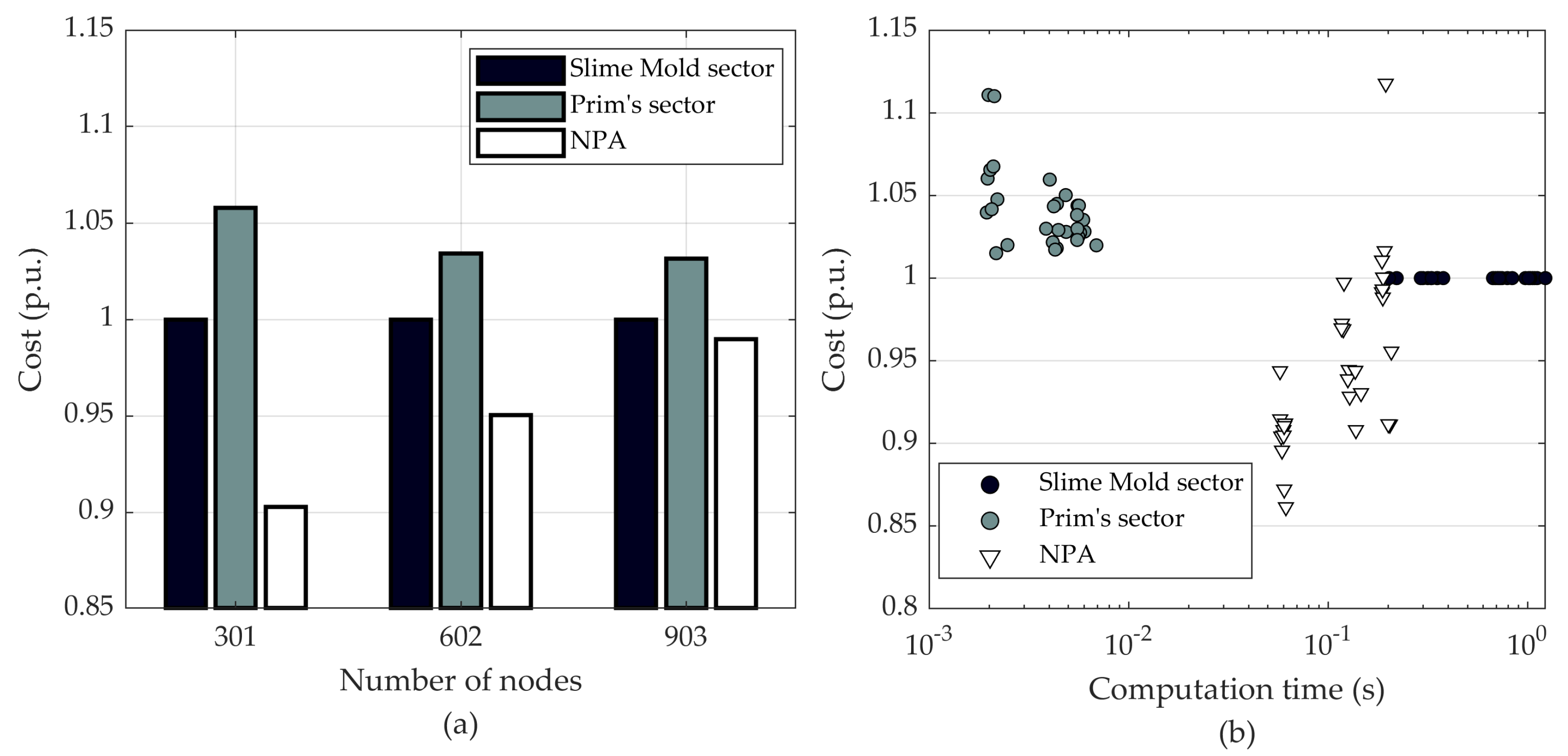
The main contribution of this paper is to present a new algorithm for an initial network generation for the greenfield design of a large-scale distribution network. The proposed algorithm addresses the disadvantage of MST, a widely used initial network type, and demonstrates the advantage of MST relaxation. Compared to the MST, the proposed algorithm can step back from the greedy approach of the MST and sacrifice shortest connections, in order to gain more from reduced loss costs. The algorithm is based on a slime mold organism, and its behaviour on a plane with spread out food sources. The slime mold algorithm can optimise networks with a large number of nodes with multiple sources and multiple sinks under a single simulation. It fills the gap in the algorithms that do not require fixed connections and can manage an enormous number of connection combinations in reasonable computation time. Such characteristics are beneficial for an initial network solution that is closer to the optimal as compared to other commonly used algorithms. The slime mold, which to the best knowledge of the authors, has not been used for this purpose, paves the way for new nature inspired heuristic algorithms that have been useful for topological problem-solving before.
The rest of the paper is organised as follows: the electric distribution network planning problem formulation is described in
Section 2. Mathematical formulation of the slime mold and its parameter exploration are introduced in
Section 3.
Section 4 provides alternative algorithms for comparison simulations. The simulation results of realistic and synthetic networks are presented in
Section 5, followed by a discussion in
Section 6.
Section 7 concludes the paper.
2. Problem Formulation
A distribution network can be defined as a set of nodes linked via connections. The set of nodes consist of load and substation nodes. The number of nodes is denoted by
n and the number of substation nodes by
. Each node has parameters such as
x- and
y coordinates, and estimated maximum load
. The connections between the nodes are denoted in an adjacency matrix
. For the presented problems, none of the fixed connections are defined; each node
i can be connected to any other node
j. The radiality condition of considered networks are granted by limiting the number of connections to
. With the exception of small rural cases, networks are built in a meshed structure. However, they are operated in a radial topology and the unused links are utilized as back-ups. The cost function of an initial network consists of investment and loss costs:
The investment cost (
2) includes the annuity factor
, connection length
, cable cost
and binary directed adjacency matrix
. The loss costs formulated in Equation (
3) include annuity as well as the lifetime factor
, cost of energy losses
, loss utilisation time
, cable resistance
and current flow
. For more detailed description of
and
, please refer to
Appendix A. The rest of the simulation parameters have generalized realistic values based on authors’ experience in network planning in Finland, and are listed in
Table 1.
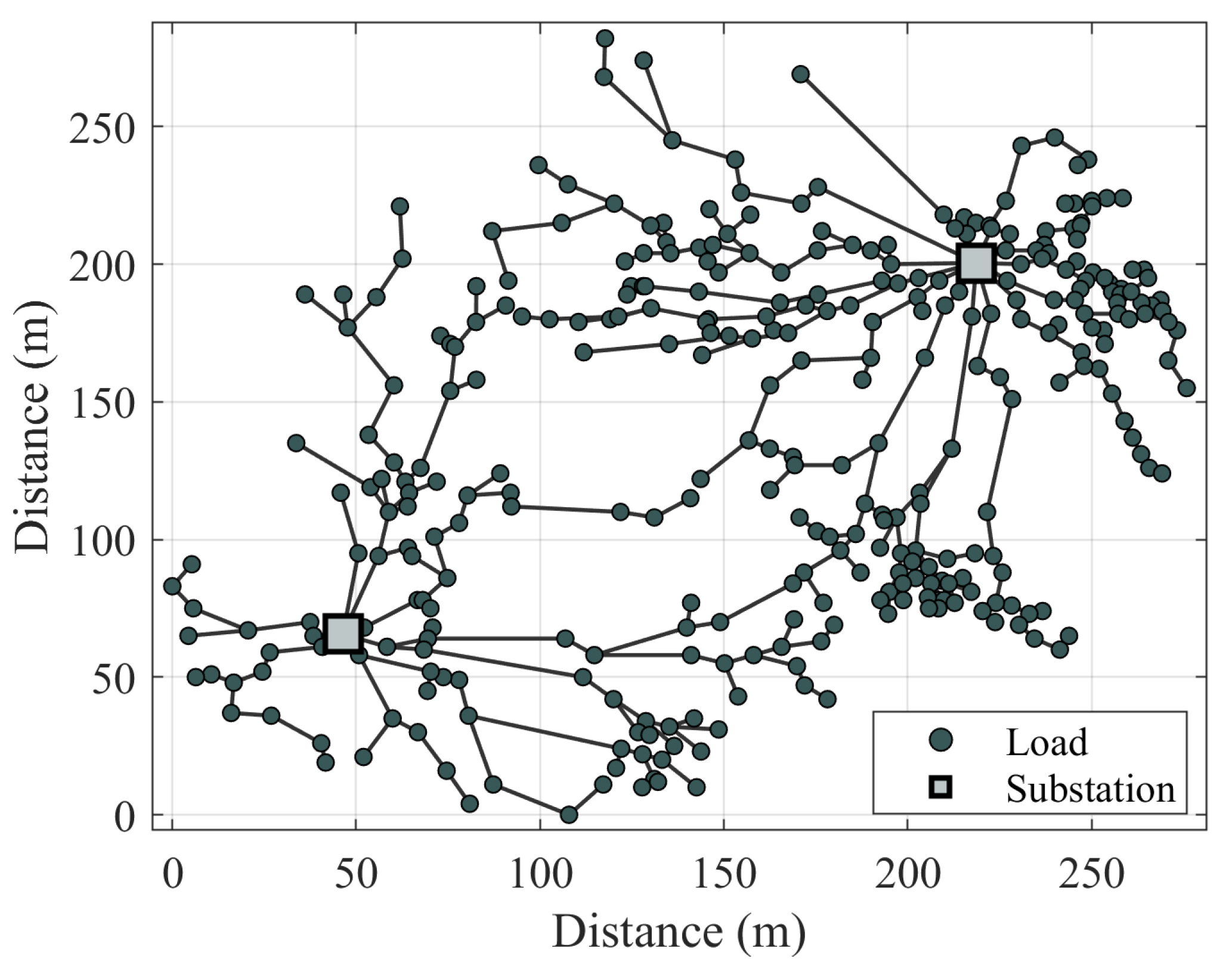
The simulations are carried out on two sets of networks: realistic networks and synthetic networks. The realistic networks are based on distribution networks in Finland. Due to confidentiality reasons, nodal data are falsified. The synthetic networks are randomly generated sets of nodes. The scale of network area, number of nodes and estimated average loads are based on typical Finnish networks, developed in [
27]. Load nodes are placed on a plane in a random manner. The location of substation nodes is determined by the k-means clustering algorithm. Load nodes are clustered into a number of clusters that is equal to the number of substations, where the centroids represent substation locations.
Table 2 includes the parameters of synthetic networks.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







