Predicting the Surveillance Data in a Low-Permeability Carbonate Reservoir with the Machine-Learning Tree Boosting Method and the Time-Segmented Feature Extraction



Abstract
:1. Introduction
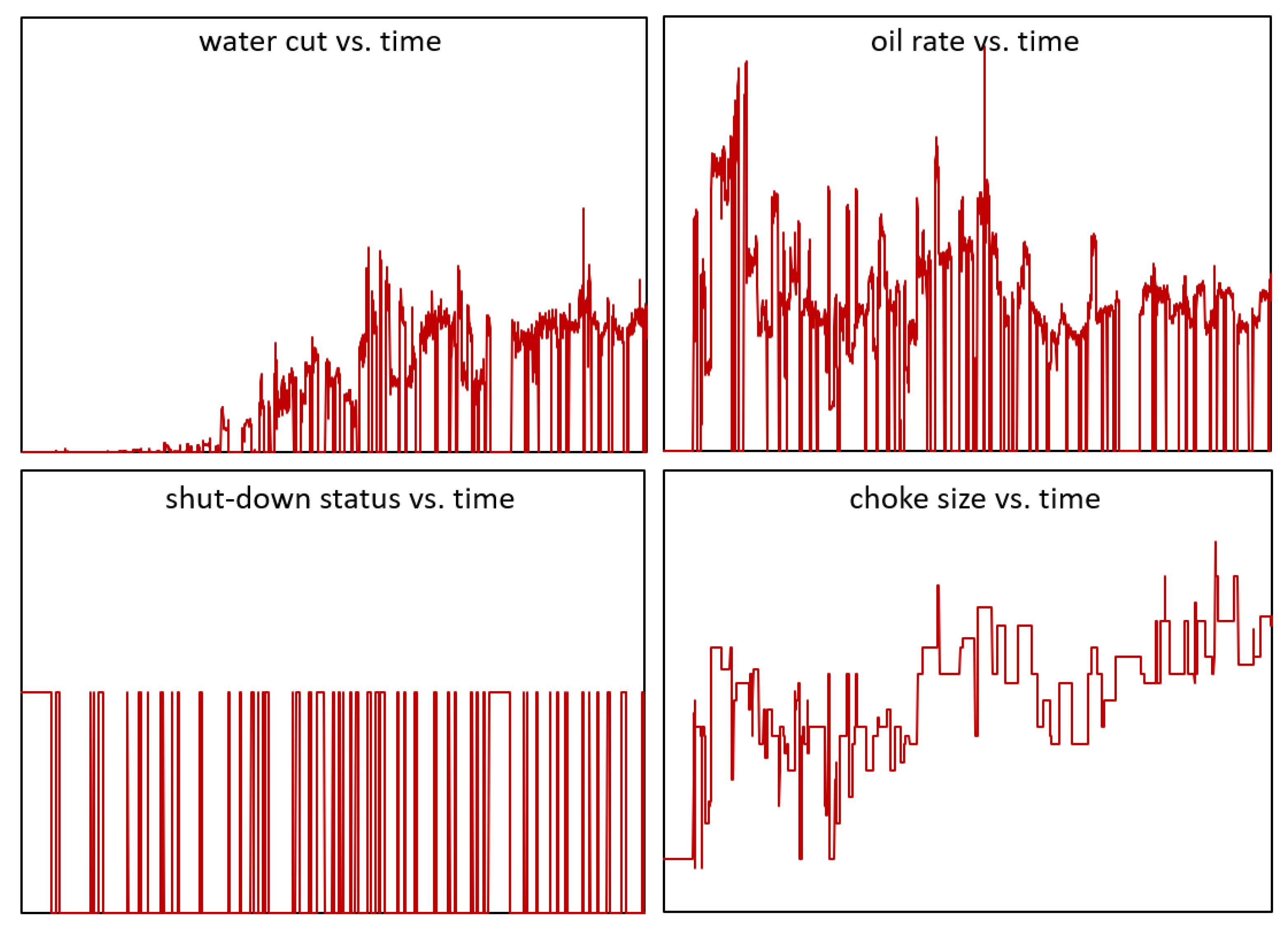
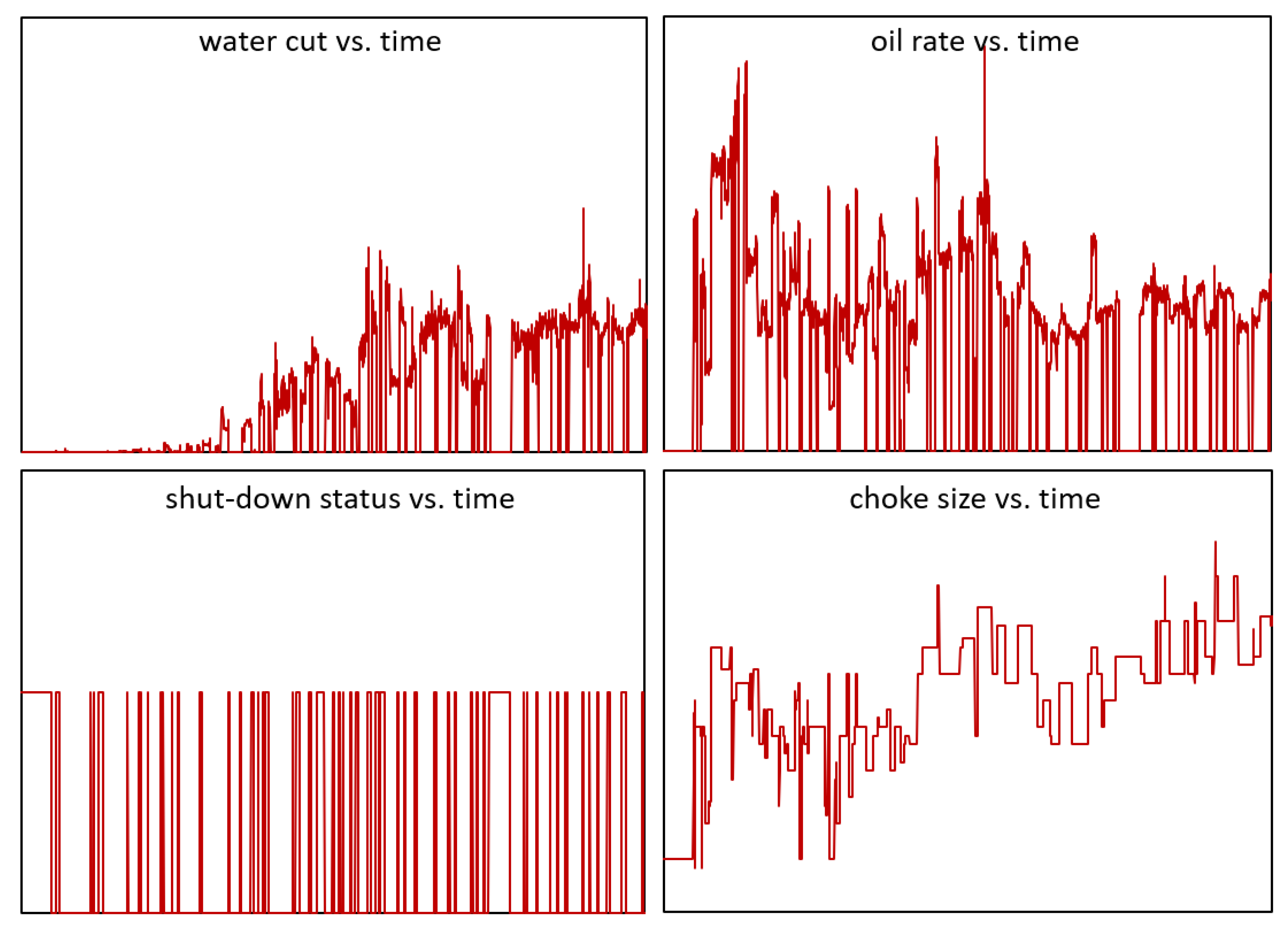
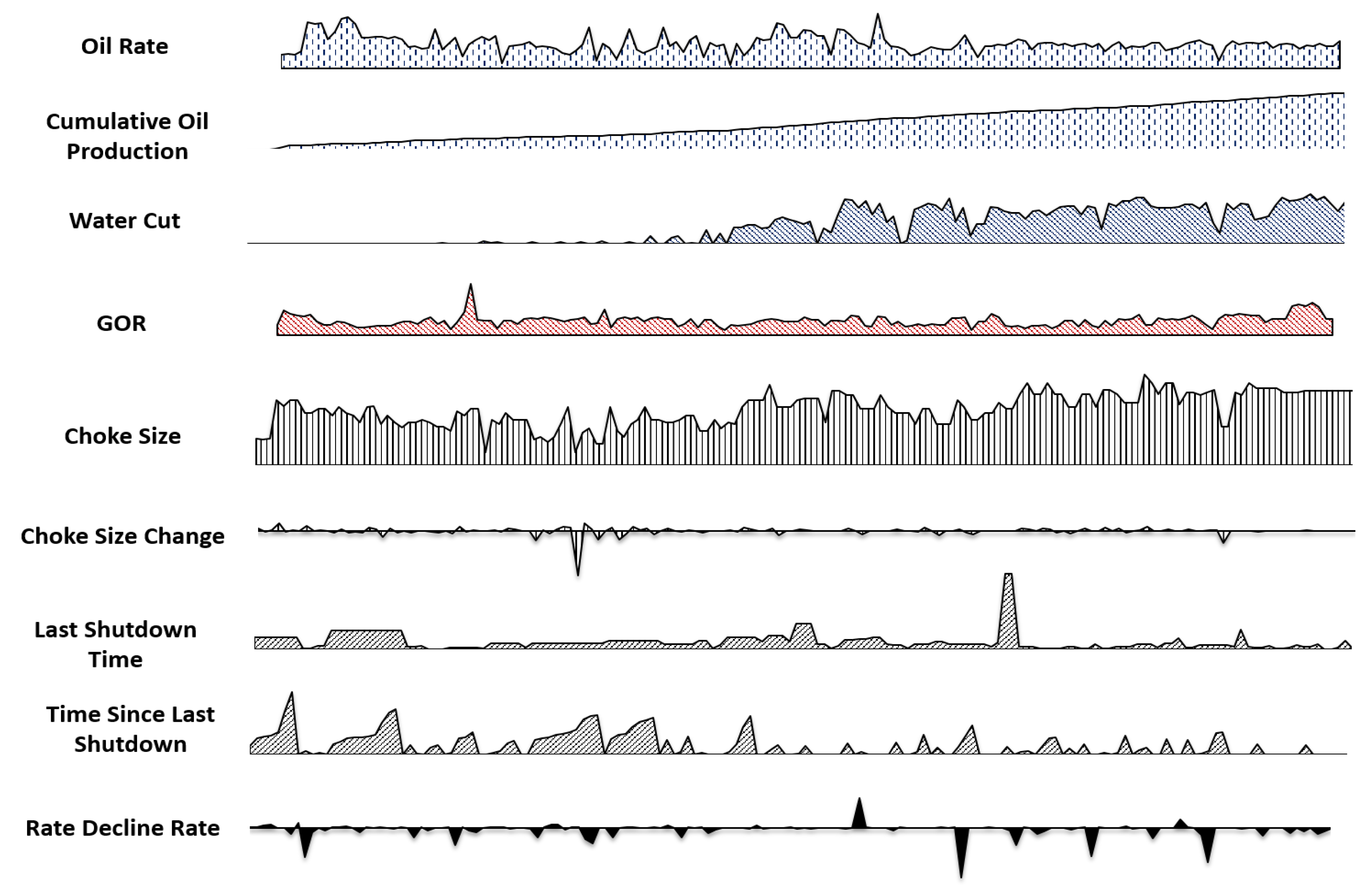
- Most reservoir surveillance data are in a multivariate time-series form with different strengths of internal correlation. Figure 1 illustrates the water cut, oil rate, shutdown status, and choke size with time for one well. If we consider predicting the decline rate of production wells, it is not just a simple function of the historical production rate. It is a function of the water cut, GOR, the change of choke size, previous shut-in period, well locations, early-or-late stages of the development, etc. It is challenging to capture and leverage the dynamic dependencies among multiple variables. To fully understand this problem, production data from many wells would have to be analyzed under varying conditions and analyzed using multivariate methods to reveal the patterns and relationships. Previous methods only keep one or limited subsets of attributes for training. For example, the traditional method of decline curve analysis (DCA) only utilizes the historical production rate data to predict the future production rate [27,28]. Engineers also integrated the surveillance data (including but not limited to bottom hole pressure measurements, pressure transient studies, production logging, pulsed neutron capture logging and flow rate measurements) by the mapping and objective method-based analysis [29]. While this makes the training easier, discarding data attributes leads to information loss and reduces the prediction accuracy and generality.
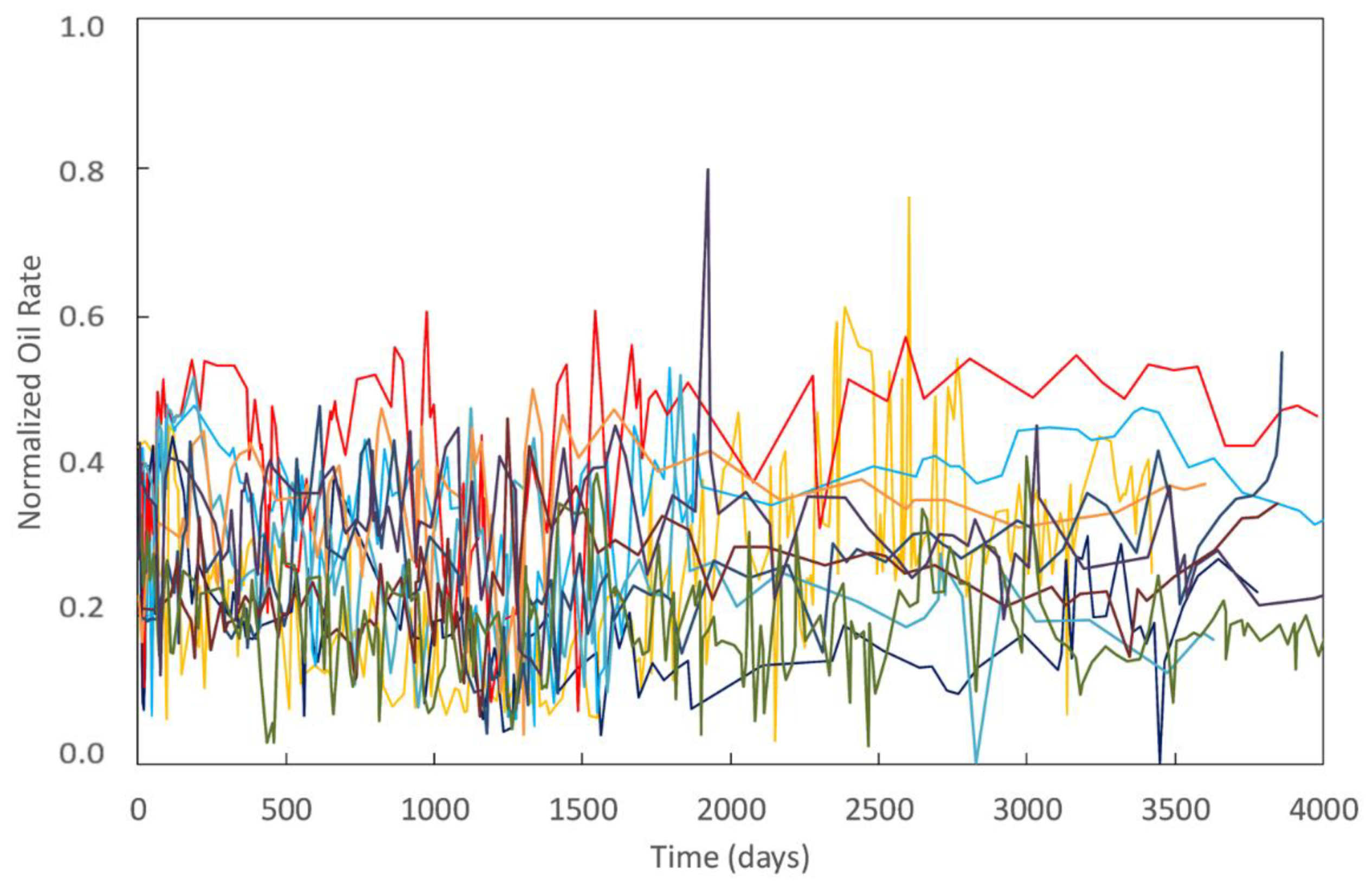
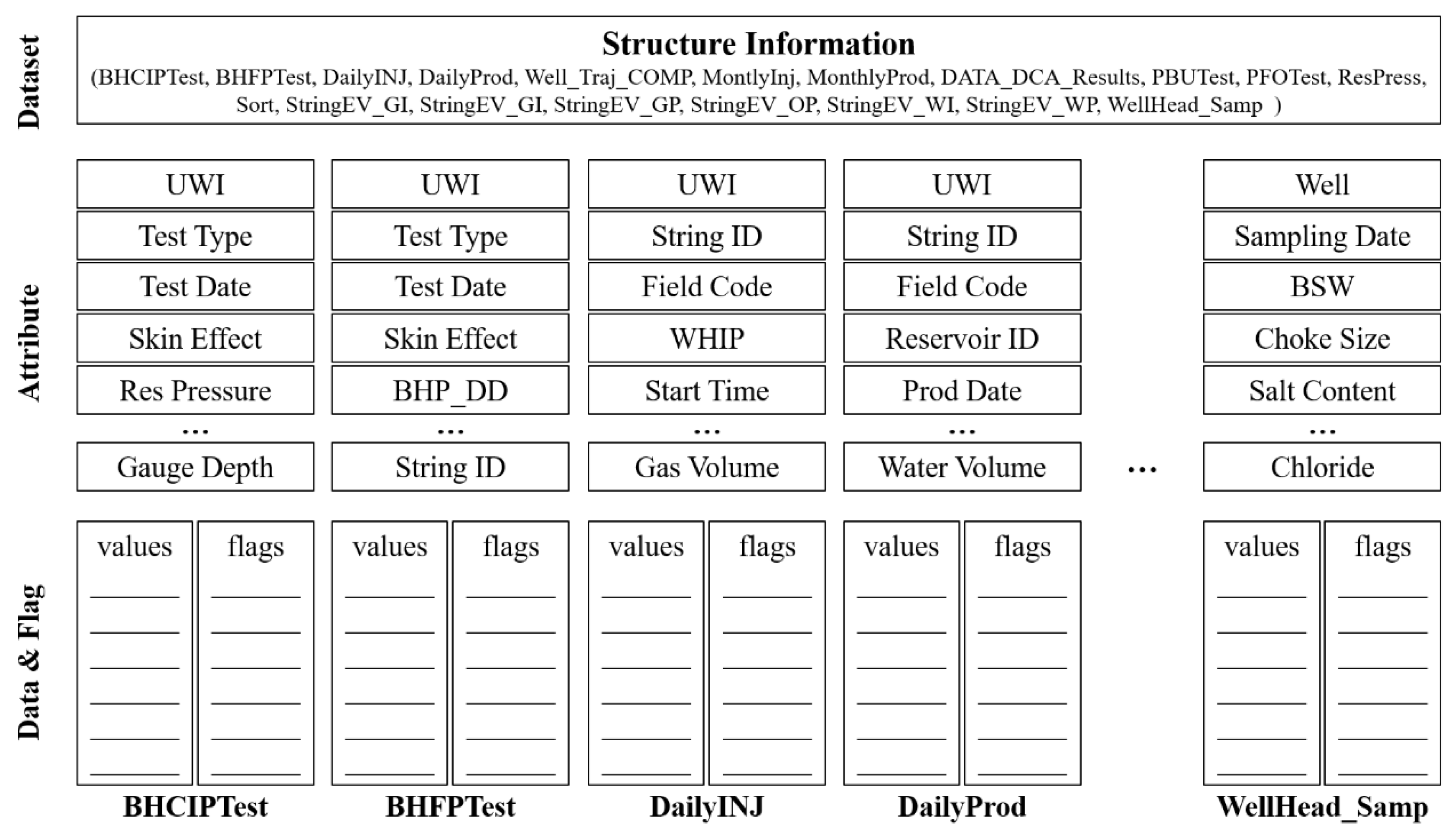
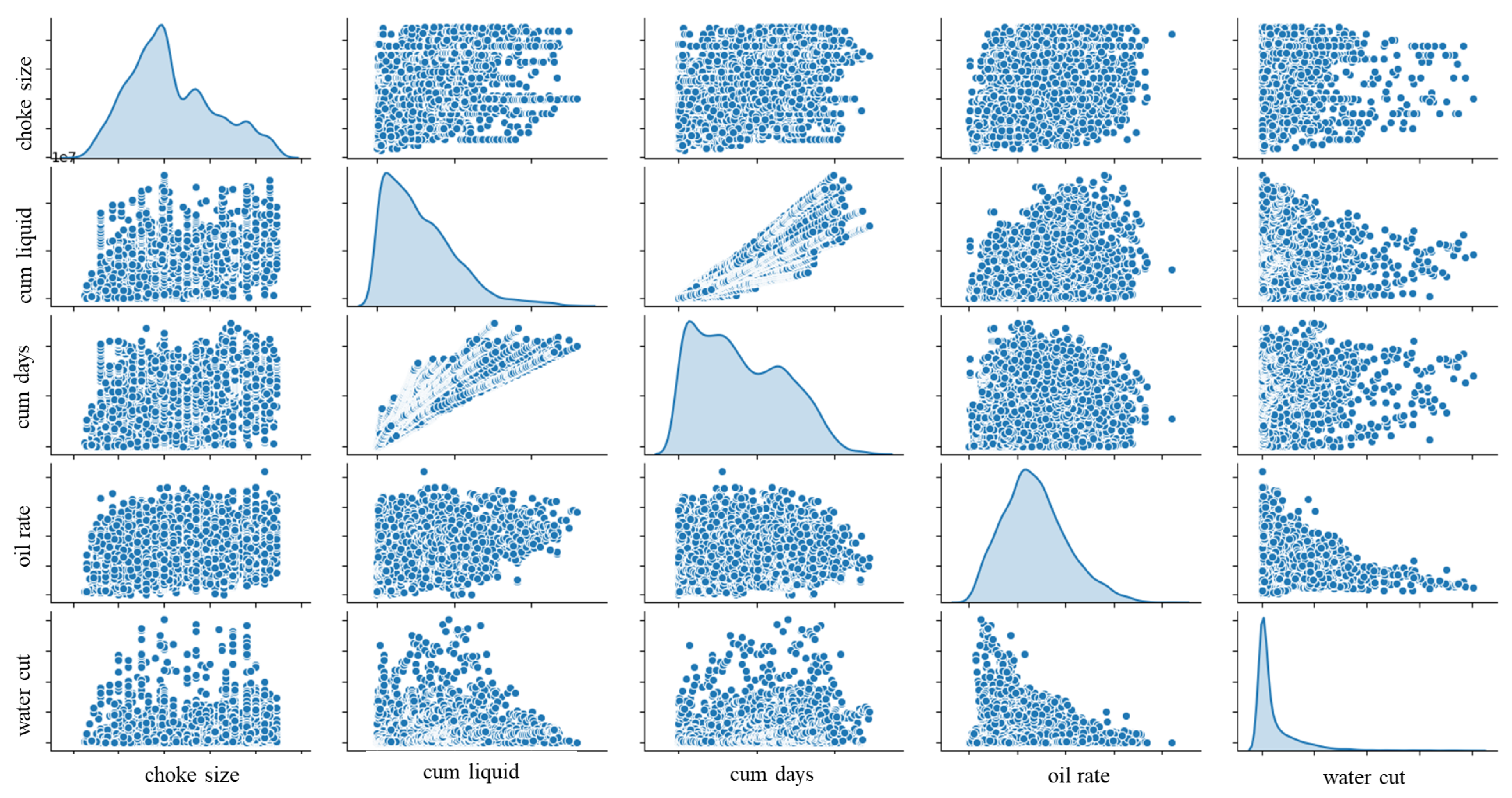
- The reservoir surveillance data contains data obtained for multiple wells (Figure 2) and from multiple sources, such as the daily injection and production monitoring, bottomhole closed-in pressure (BHCIP) test, pressure build up (PBU) test, wellhead fluid sampling, etc., as well as data of several attributes, such as the test date, WHIP, choke size, salt content, etc. (Figure 3). These attributes together provide a wealth of information for the prediction. However, it is nontrivial to use all attributes in a unified model because of variations regarding their data type. For example, the daily monitoring data such as the production rate, choke size, and water cut are in the time-series real number form. The well shut-in conditions are in the time-series Boolean form. The field code and well nameare time-independent character strings.


- Selecting a suitable machine learning algorithm for the production data forecast can also be a difficult task. It is tedious to try all available models. Many factors need to be considered in this model selection, such as explainability, the number of features and examples, the nonlinearity of the data, training speed, prediction speed, cross-validation function, etc. Each model also contains many parameters to be tuned for the best prediction performance. Industry applications typically prefer a machine learning algorithm that is capable of explanation.
2. The Low-Permeability Carbonate Reservoir
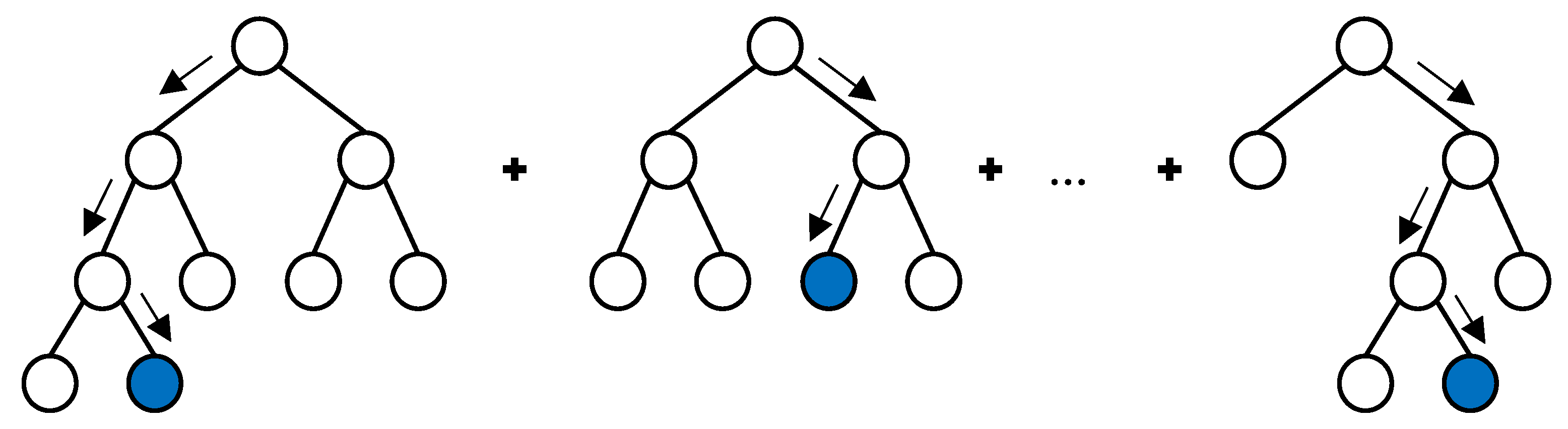
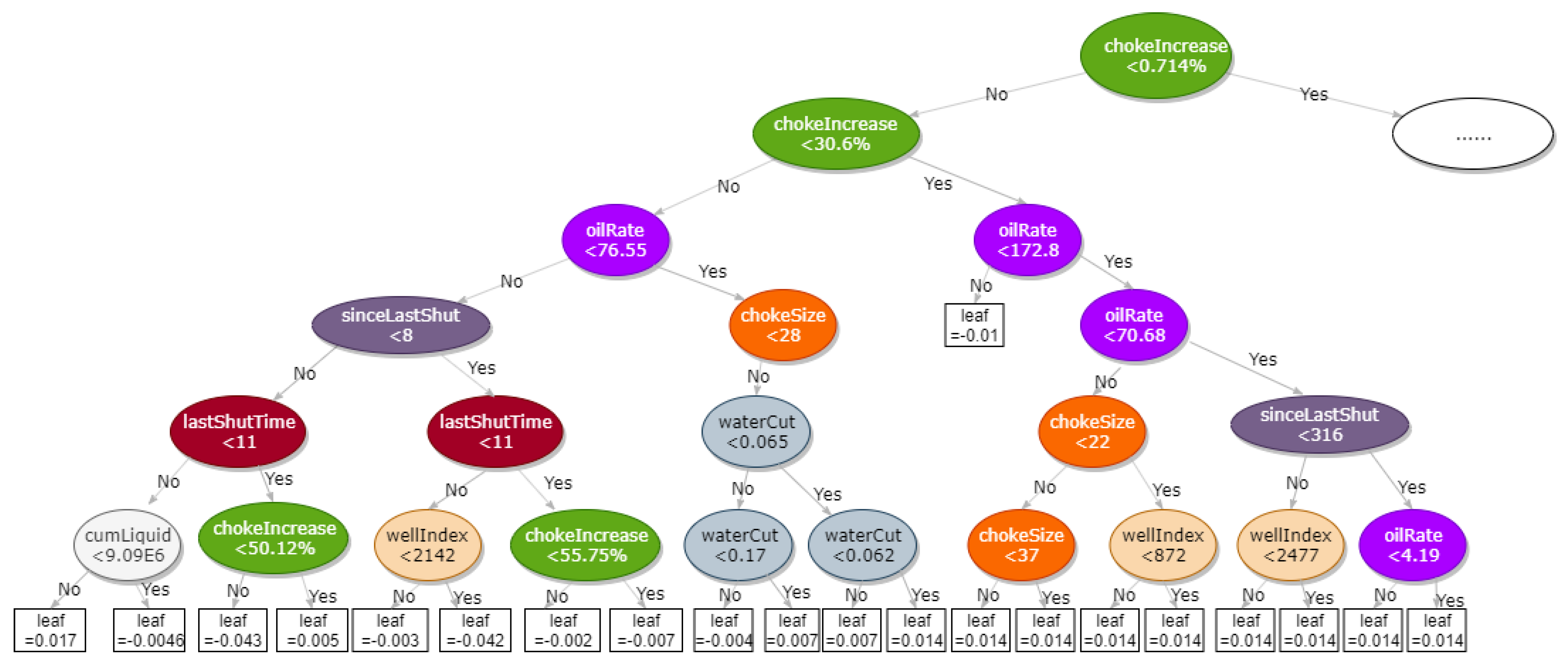
3. Gradient Boosted Classification and Regression Trees
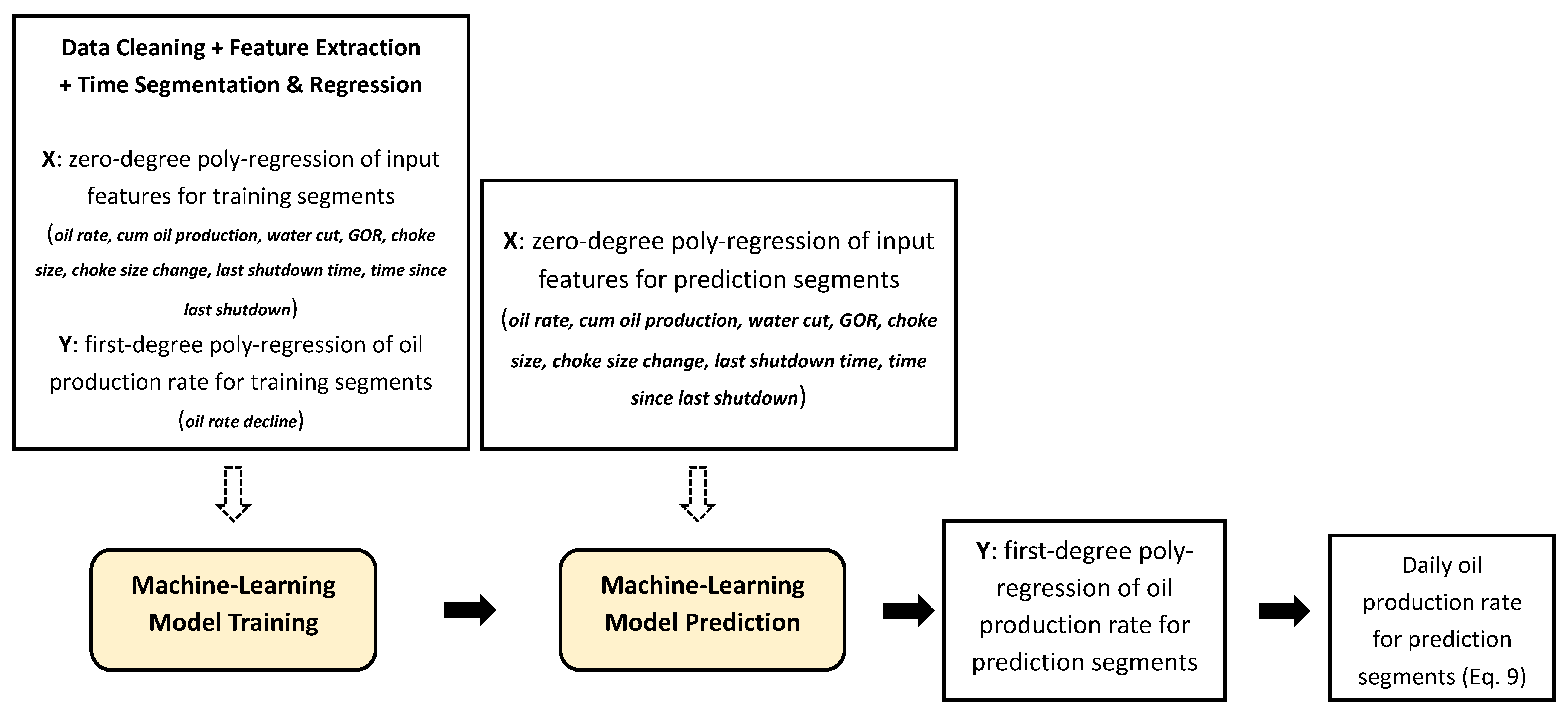
4. Long-Term and Short-Term Feature Extraction
- Cumulative oil production: considering similarities among all producers regarding their local geological conditions as well as reservoir development scheme (e.g., well spacing, horizontal well length) in this oil field, their drainage amount of reserves, and total ultimate oil production are close (Section 2). The cumulative oil production at specific observation dates, therefore, can reflect percentages of recovered oil, and thus can reflect the development stage;
- Water cut and GOR: water cut is correlated to the development stage in this oil field, as can be observed in Figure 1 and Figure 5. In the early stage of reservoir development, the initial water saturation is close to the connate water saturation (Swc), water conning from the bottom water has not occurred, and the displacement front of water alternating gas (WAG) from injectors have not reached to producers. Water cut data in this stage is close to zero. Then this value begins to increase from the mid-stage because the bottom water and injected water reached to producer areas. GOR has a similar correlation trend as the water cut. In mid- or late-stages, free gas evolves from the dissolved gas with the pressure decreasing. Injected gas will also arrive nearby producers.
- Oil rate: oil production rate decline can be a function of current production rate according to the traditional decline curve analysis method (e.g., the hyperbolic exponent approach);
- Choke size and choke size change: adjusting the choke size is the direct operation approach to control production rate, and thus it has an influence on oil rate and oil rate decline. Our surveillance analysis experiences indicate that oil rate tends to increase more sensitively to the increase of choke size, and decrease less sensitively to the decrease of choke size in the early stage;
- Last shutdown time and time since last shut down: shutting down the producer for a while will help the pressure restoration and thus affects the production behavior;
- Rate decline: rate decline is the prediction target in this analysis.
5. Applications
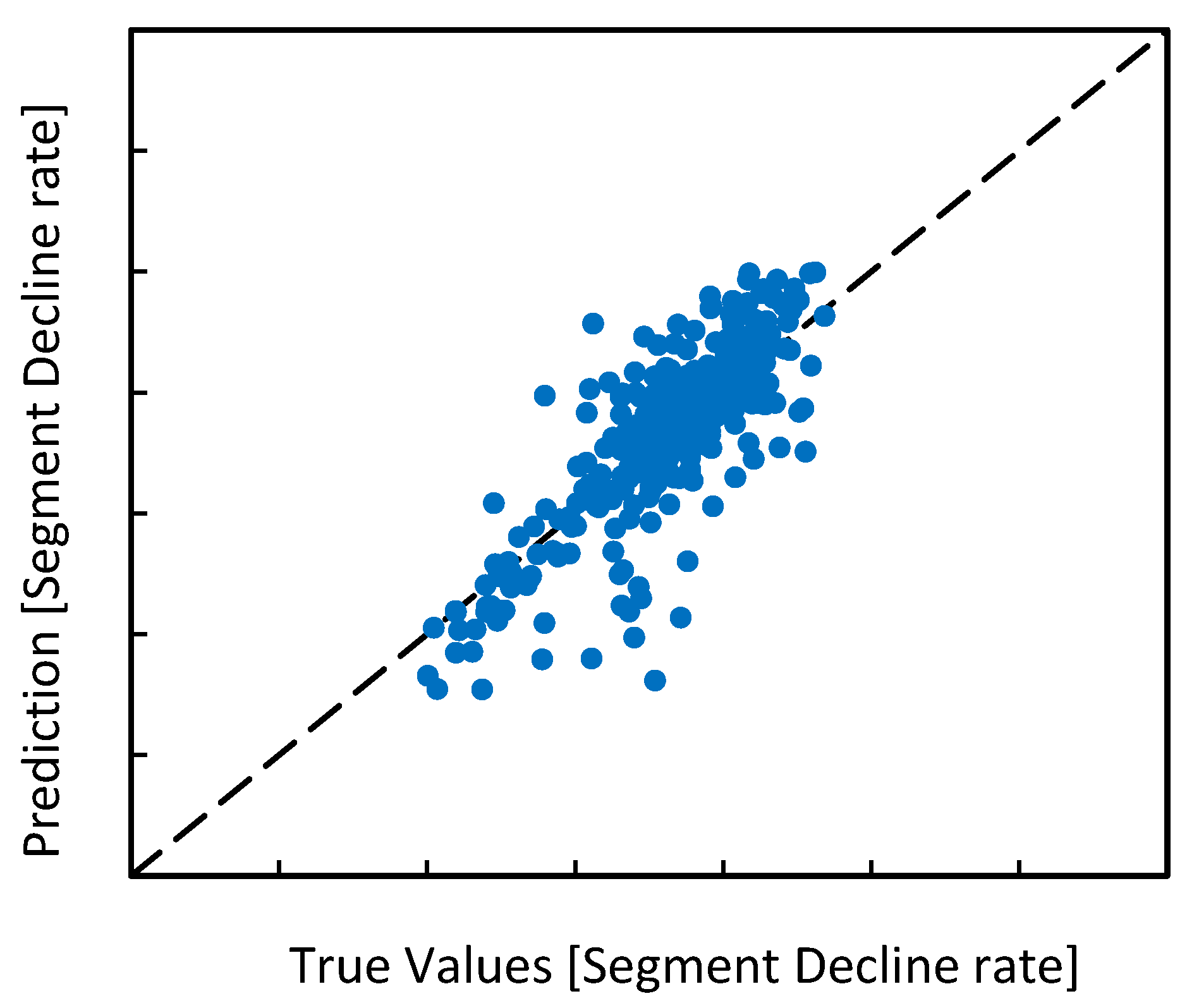
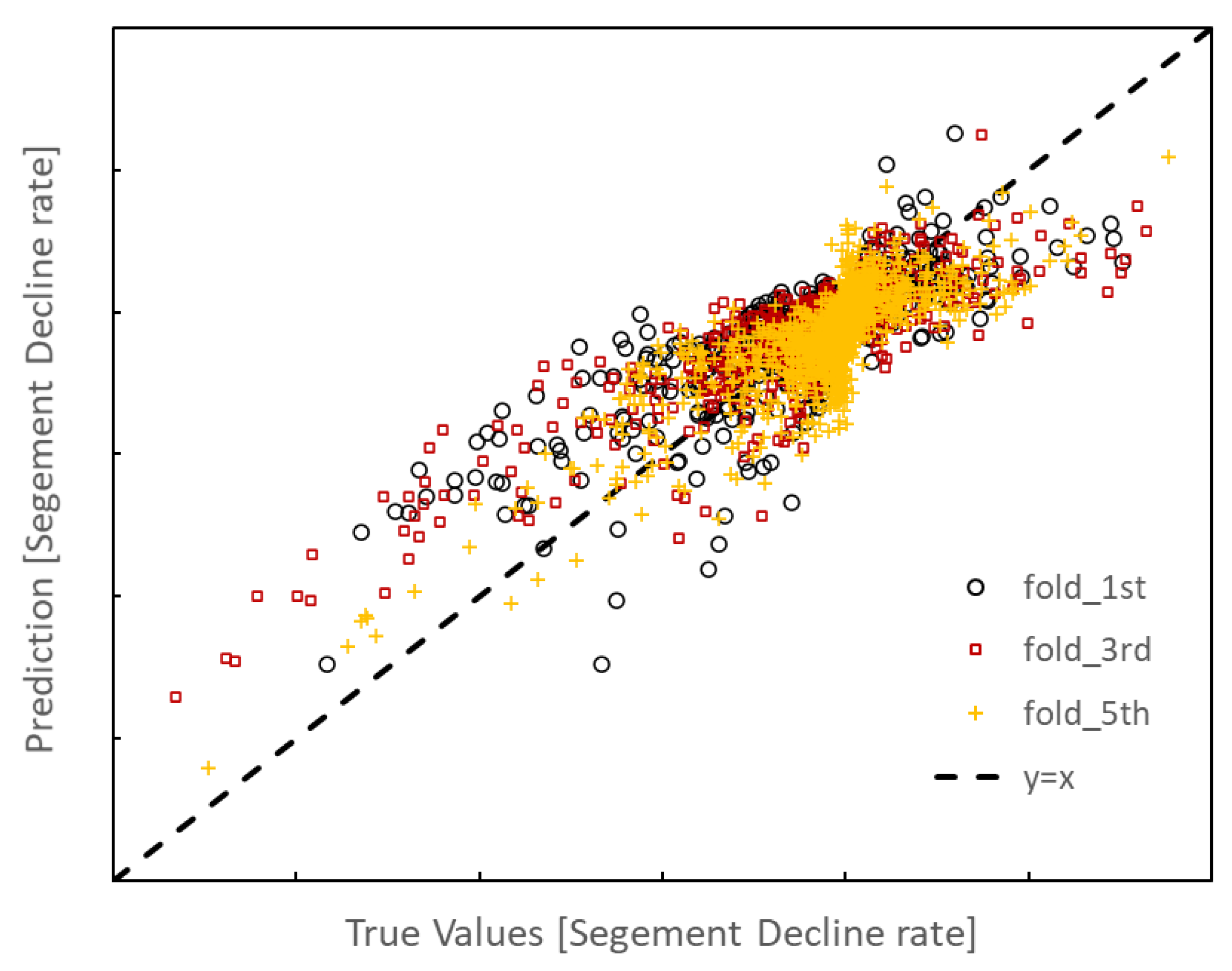
5.1. Randomly 90/10 Split and K-Fold Cross-Validations of the 91 Producer Data Assemblage
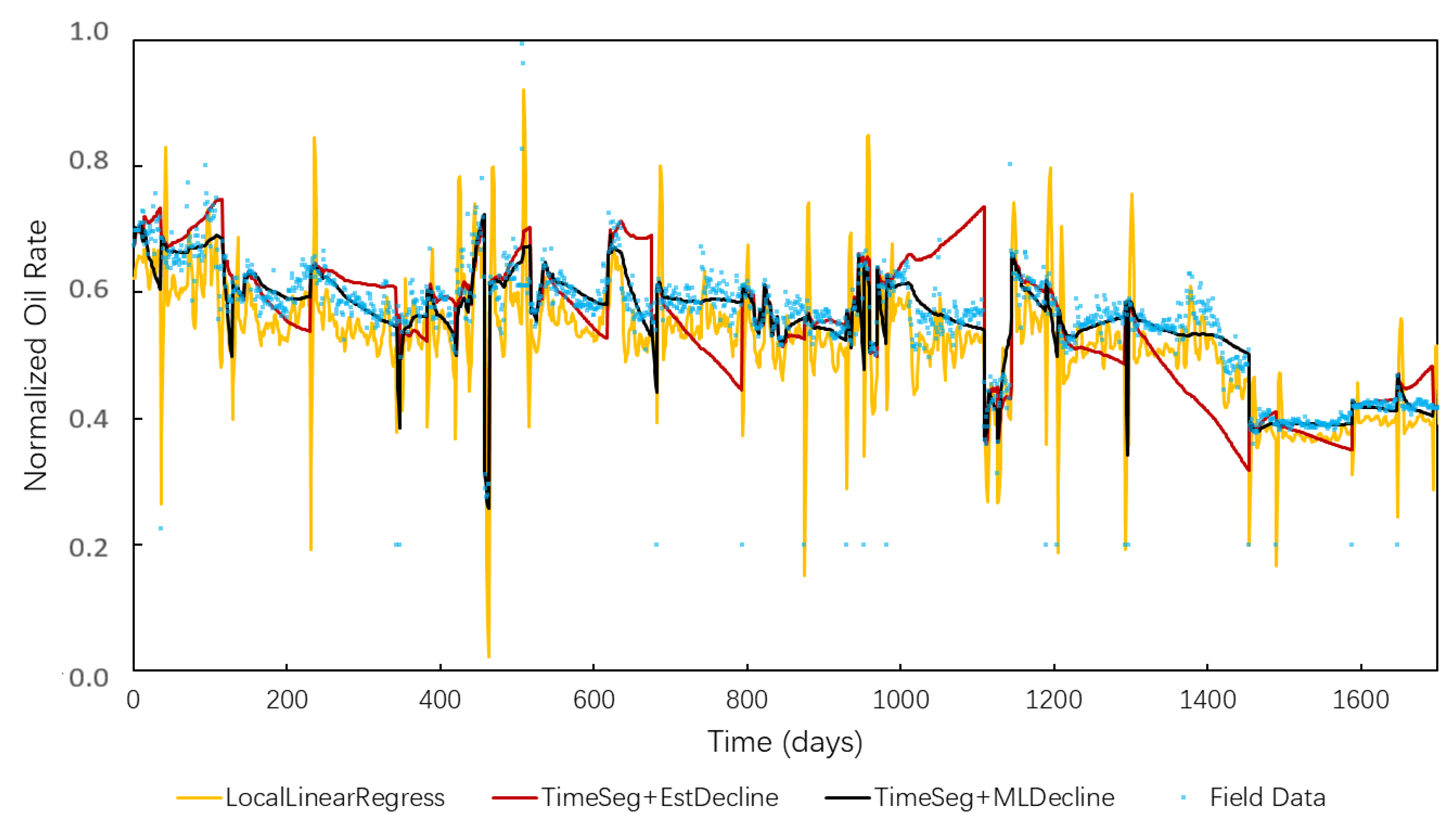
5.2. 90 Producers Data for Training and the Other 1 Producer Data for Testing
6. Summary and Discussions
- We present a machine-learning tree boosting method and the time-segmented feature extraction technique for the predictive analysis of the reservoir surveillance data. This approach aims to quantitatively uncover the complicated hidden patterns between the target prediction parameter and other monitored data of a high variety through state-of-the-art automatic classification and multiple linear regression algorithms. Compared with traditional methods, the approach proposed in this article can handle surveillance data in multivariate time-series form with different strengths of internal correlation. It also provides capabilities for data obtained in multiple wells, measured from multiple sources, as well as of multiple attributes. Manually constructing such a model—considering features of this complexity—would be challenging.
- The developed approach is applied to a field case with 91 producers and 20 years of development history. Two tests are conducted. In the first test, the preprocessed data set of all 91 producers is randomly divided into the training set and the evaluation set. The prediction performance is checked through the cross-plot between the true value and predicted value of the oil decline rate. An RMSE of 2.1903 can be achieved by the proposed method. In the second test, data of 90 producers are used in training, and the left one is for evaluations. We show 96.36% of the predicted data is within 20% error of realistic recording data, which brings 18.54% improvement of accuracy and reliability compared with other approaches.
- Long-term features reflecting the development stages (e.g., the cumulative oil production, water cut, and GOR), and short-term fluctuations by two operation activities (well shut-down and choke size adjustment) can be considered in this model. According to our test, the influential features in sequence are the choke size change, oil production rate, current choke size, the well shut-down status, water cut, well location, and cumulative liquid production.
- Our application results indicate that this approach is quite promising in capturing the complicated patterns between the target variable and several other explanatory variables of the surveillance data, and thus in predicting the daily oil production rate. Continuing work based on this machine learning framework could potentially help in better managing the fields and reducing the maintenance cost, e.g., identifying in advance some possible failure of equipment and to intervene before an event occurs
- Features of local geology conditions and the reservoir development scheme are not included in the model training in this research, because of the homogeneous geological conditions and uniform development pattern in this oil field. Notice only eight features are chosen as the input to train the model for this real field case; some outlier predictions are within expectation. One machine learning model including geological and production features is recommended to be more practical in general. Some smart-model based approaches may also be valuable to extract training features. In addition, more sensitivity analysis of the input parameters can be done based on the proposed ML model. The model is expected to be more reliable and accurate if more valuable features are included.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Terrado, R.M.; Yudono, S.; Thakur, G.C. Waterflood Surveillance and Monitoring: Putting Principles into Practice. In Proceedings of the SPE Annual Technical Conference and Exhibition, San Antonio, TX, USA, 24–27 September 2006; Society of Petroleum Engineers: Dallas, TX, USA, 2006. [Google Scholar]
- Shalev-Shwartz, S.; Ben-David, S. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision And Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Alkinani, H.H.; Al-Hameedi, A.T.T.; Dunn-Norman, S.; Flori, R.E.; Alsaba, M.T.; Amer, A.S. Applications of Artificial Neural Networks in the Petroleum Industry: A Review. In Proceedings of the SPE Middle East Oil and Gas Show and Conference, Manama, Bahrain, 18–21 March 2019; Society of Petroleum Engineers: Dallas, TX, USA, 2019. [Google Scholar]
- Xu, C.; Misra, S.; Srinivasan, P.; Ma, S. When Petrophysics Meets Big Data: What can Machine Do? In Proceedings of the SPE Middle East Oil and Gas Show and Conference, Manama, Bahrain, 18–21 March 2019; Society of Petroleum Engineers: Dallas, TX, USA, 2019. [Google Scholar]
- Poulton, M.M. Neural networks as an intelligence amplification tool: A review of applications. Geophysics 2002, 67, 979–993. [Google Scholar] [CrossRef]
- Alizadeh, B.; Najjari, S.; Kadkhodaie-Ilkhchi, A. Artificial neural network modeling and cluster analysis for organic facies and burial history estimation using well log data: A case study of the South Pars Gas Field, Persian Gulf, Iran. Comput. Geosci. 2012, 45, 261–269. [Google Scholar] [CrossRef]
- Ross, C. Improving resolution and clarity with neural networks. In SEG Technical Program Expanded Abstracts; Society of Exploration Geophysicists: Houston, TX, USA, 2017; pp. 3072–3076. [Google Scholar]
- Arabloo, M.; Bahadori, A.; Ghiasi, M.M.; Lee, M.; Abbas, A.; Zendehboudi, S. A novel modeling approach to optimize oxygen–steam ratios in coal gasification process. Fuel 2015, 153, 1–5. [Google Scholar] [CrossRef]
- Sidaoui, Z.; Abdulraheem, A.; Abbad, M. Prediction of Optimum Injection Rate for Carbonate Acidizing Using Machine Learning. In Proceedings of the SPE Kingdom of Saudi Arabia Annual Technical Symposium and Exhibition, Dammam, Saudi Arabia, 23–26 April 2018; Society of Petroleum Engineers: Dallas, TX, USA, 2018. [Google Scholar]
- Kamari, A.; Bahadori, A.; Mohammadi, A.H.; Zendehboudi, S. Evaluating the unloading gradient pressure in continuous gas-lift systems during petroleum production operations. Petrol. Sci. Technol. 2014, 32, 2961–2968. [Google Scholar] [CrossRef]
- Chamkalani, A.; Zendehboudi, S.; Bahadori, A.; Kharrat, R.; Chamkalani, R.; James, L.; Chatzis, I. Integration of LSSVM technique with PSO to determine asphaltene deposition. J. Petrol. Sci. Eng. 2014, 124, 243–253. [Google Scholar] [CrossRef]
- Rashidi, M.; Asadi, A. An Artificial Intelligence Approach in Estimation of Formation Pore Pressure by Critical Drilling Data. In Proceedings of the 52nd US Rock Mechanics/Geomechanics Symposium, Seattle, WA, USA, 17–20 June 2018; American Rock Mechanics Association: Houston, NV, USA, 2018. [Google Scholar]
- Dzurman, P.J.; Leung, J.Y.W.; Zanon, S.D.J.; Amirian, E. Data-Driven Modeling Approach for Recovery Performance Prediction in SAGD Operations. In Proceedings of the SPE Heavy Oil Conference-Canada, Calgary, AB, Canada, 11–13 June 2013; Society of Petroleum Engineers: Dallas, TX, USA, 2013. [Google Scholar]
- Chang, H.; Zhang, D. Identification of physical processes via combined data-driven and data-assimilation methods. J. Comput. Phys. 2019, 393, 337–350. [Google Scholar] [CrossRef] [Green Version]
- Zendehboudi, S.; Rezaei, N.; Lohi, A. Applications of hybrid models in chemical, petroleum, and energy systems: A systematic review. Appl. Energy 2018, 228, 2539–2566. [Google Scholar] [CrossRef]
- Wang, C.; Ran, Q.; Wu, Y.S. Robust implementations of the 3D-EDFM algorithm for reservoir simulation with complicated hydraulic fractures. J. Petrol. Sci. Eng. 2019, 181, 106229. [Google Scholar] [CrossRef]
- Wang, C.; Winterfeld, P.; Johnston, B.; Wu, Y.S. An embedded 3D fracture modeling approach for simulating fracture-dominated fluid flow and heat transfer in geothermal reservoirs. Geothermics 2020, 86, 101831. [Google Scholar] [CrossRef]
- Wang, C.; Huang, Z.; Wu, Y.S. Coupled numerical approach combining X-FEM and the embedded discrete fracture method for the fluid-driven fracture propagation process in porous media. Int. J. Rock Mech. Min. Sci. 2020. [Google Scholar] [CrossRef]
- Wu, Y.S.; Li, J.; Ding, D.; Wang, C.; Di, Y. A generalized framework model for the simulation of gas production in unconventional gas reservoirs. SPE J. 2014, 19, 845–857. [Google Scholar] [CrossRef]
- Chang, O.; Pan, Y.; Dastan, A.; Teague, D.; Descant, F. Application of Machine Learning in Transient Surveillance in a Deep-Water Oil Fieldc. In Proceedings of the SPE Western Regional Meeting, San Jose, CA, USA, 23–26 June 2019; Society of Petroleum Engineers: Dallas, TX, USA, 2019. [Google Scholar]
- Pan, Y.; Bi, R.; Zhou, P.; Deng, L.; Lee, J. An Effective Physics-Based Deep Learning Model for Enhancing Production Surveillance and Analysis in Unconventional Reservoirs. In Proceedings of the Unconventional Resources Technology Conference, Denver, CO, USA, 22–24 July 2019; pp. 2579–2601. [Google Scholar]
- Al-Fattah, S.M.; Startzman, R.A. Neural network approach predicts US natural gas production. SPE Product. Facil. 2003, 18, 84–91. [Google Scholar] [CrossRef]
- Fetkovich, M.J. Decline Curve Analysis Using Type Curves. In Proceedings of the Fall Meeting of the Society of Petroleum Engineers of AIME, Las Vegas, NV, USA, 30 September–3 October 1973; Society of Petroleum Engineers: Dallas, TX, USA, 1973. [Google Scholar]
- Agarwal, R.G.; Gardner, D.C.; Kleinsteiber, S.W.; Fussell, D.D. Analyzing Well Production Data Using Combined Type Curve and Decline Curve Analysis Concepts. In Proceedings of the SPE Annual Technical Conference and Exhibition, New Orleans, LA, USA, 27–30 September 2014; Society of Petroleum Engineers: Dallas, TX, USA, 2014. [Google Scholar]
- Sinha, S.P.; Al-Qattan, R. A Novel Approach to Reservoir Surveillance Planning. In Proceedings of the Abu Dhabi International Conference and Exhibition, Abu Dhabi, EAU, 10–13 October 2004; Society of Petroleum Engineers: Dallas, TX, USA, 2004. [Google Scholar]
- Saadawi, H.N. Commissioning of Northeast Bab (NEB) Development Project. In Proceedings of the Abu Dhabi International Petroleum Exhibition and Conference, Abu Dhabi, EAU, 5–8 November 2006; Society of Petroleum Engineers: Dallas, TX, USA, 2006. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Domingos, P. A few useful things to know about machine learning. Commun. ACM 2012, 55, 78–87. [Google Scholar] [CrossRef] [Green Version]
- Keogh, E.; Chu, S.; Hart, D.; Pazzani, M. Segmenting time series: A survey and novel approach. In Data Mining In Time Series Databases; World Scientific Publishing: Singapore, Singapore, 2004; pp. 1–21. [Google Scholar]
- Bergstra, J.; Komer, B.; Eliasmith, C.; Yamins, D.; Cox, D.D. Hyperopt: A python library for model selection and hyperparameter optimization. Comput. Sci. Discov. 2015, 8, 014008. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| learning_rate | 0.00283 |
| n_estimators | 16800 |
| max_depth | 7 |
| min_child_weight | 0.8715 |
| gamma | 0 |
| subsample | 0.6712 |
| colsample_bytree | 0.7 |
| objective | reg:linear |
| nthread | −1 |
| scale_pos_weight | 1 |
| seed | 27 |
| reg_alpha | 0.00006 |
| Test | 90/10 Split | k-Fold (Group Number = 5) | ||||
|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | ||
| RMSE | 2.1903 | 2.3033 | 2.7689 | 2.5161 | 2.5112 | 2.3124 |
| Test | Split Ratio | |||
|---|---|---|---|---|
| 90/10 | 80/20 | 70/30 | 60/40 | |
| RMSE | 2.1903 | 2.3791 | 2.5113 | 2.53971 |
| Method | Within 5% of Production Rate | Within 10% of Production Rate | Within 20% of Production Rate |
|---|---|---|---|
| LocalLinearRegress | 10.00% | 33.91% | 85.27% |
| TimeSeg + EstDecline | 37.61% | 57.65% | 77.82% |
| TimeSeg + MLDecline | 58.08% | 84.35% | 96.36% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Zhao, L.; Wu, S.; Song, X. Predicting the Surveillance Data in a Low-Permeability Carbonate Reservoir with the Machine-Learning Tree Boosting Method and the Time-Segmented Feature Extraction. Energies 2020, 13, 6307. https://doi.org/10.3390/en13236307
Wang C, Zhao L, Wu S, Song X. Predicting the Surveillance Data in a Low-Permeability Carbonate Reservoir with the Machine-Learning Tree Boosting Method and the Time-Segmented Feature Extraction. Energies. 2020; 13(23):6307. https://doi.org/10.3390/en13236307
Chicago/Turabian StyleWang, Cong, Lisha Zhao, Shuhong Wu, and Xinmin Song. 2020. "Predicting the Surveillance Data in a Low-Permeability Carbonate Reservoir with the Machine-Learning Tree Boosting Method and the Time-Segmented Feature Extraction" Energies 13, no. 23: 6307. https://doi.org/10.3390/en13236307
APA StyleWang, C., Zhao, L., Wu, S., & Song, X. (2020). Predicting the Surveillance Data in a Low-Permeability Carbonate Reservoir with the Machine-Learning Tree Boosting Method and the Time-Segmented Feature Extraction. Energies, 13(23), 6307. https://doi.org/10.3390/en13236307