1. Introduction
Wind turbines are usually operated in remote and harsh areas with extreme weather conditions, which might cause their faults. The gearbox faults will affect the overall performance of the equipment and even cause human injuries and economic loss [
1]. Therefore, fault detection and rapid fault identification of wind turbine gearbox components are of great importance to reduce the operation and maintenance costs of wind turbines and improve the production of wind farms [
2,
3]. Over the years, extensive research has been carried out contributing to the fault diagnosis of wind turbines.
At present, monitoring and fault diagnosis methods are mainly used in wind turbine gearboxes and other major components, such as wavelet-based approaches, statistical analysis, machine learning, as well as some other hybrid and modern techniques [
4,
5,
6,
7,
8]. However, the need for transformation leads to extended detection time and the selection of mother wavelet remains a challenge for fault feature extraction of wind turbines gearboxes. Moreover, the statistical analysis needs to establish an accurate mathematical model and it requires in-depth professional knowledge. Machine learning has been widely used in many industrial diagnosis fields. More and more attention has been paid to the fault diagnosis methods based on machine learning [
9,
10]. In machine learning, the boost algorithm combines weakly predictive models into a strongly predictive model, which is adjusted by increasing the weight of the error samples to improve the accuracy of the algorithm [
11,
12,
13,
14]. However, the boost algorithm needs to use the lower limit of the accuracy of the weak classifier in advance and has limited application in industrial fault diagnosis. To address this concern, Y. Freund and RE Schapire proposed an AdaBoost algorithm which using the strong classifier to improve the classification accuracy and reduce the generalization error, however, most of the boost algorithms are sensitive to outliers and has a negative effect on the weak classifier [
15]. A further study conducted by Friedman combined Gradient Boosting (GB) with Decision Tree (DT), proposing a GBDT algorithm, which has effectively solved the problem of feature transformation complexity, however, it suffers to process big data for fault diagnosis [
16]; Tianqi Chen proposed an XGBoost algorithm, using parallel processing and adding a tree model complexity to the regular term, which was found can effectively solve the overfitting problems [
17]. However, since the traditional boost algorithm is sensitive to outliers and that will significantly affect the learning results of the base classifier especially in the abnormal data sample. Since the traditional boost methods might fail to handle big data in actual wind farms, this has a negative influence on the computational efficiency, real-time fault detection and the accuracy of the learned model.
However, existing studies often suffer problems solving in high computational cost and poor performance in real-time fault detection. Microsoft Research Asia has proposed the LightGBM algorithm which is a new GBDT algorithm with Gradient-based One-Side Sampling (GOSS) and the Exclusive Feature Bundling (EFB) to deal with big data and large number of features respectively [
18]. The algorithm generates a decision tree by leaf node segmentation method, then finds feature a segmentation point based on a Histogram algorithm, which supports parallel learning and can efficiently process big data which also solves problems such as low computational efficiency and poor real-time performance [
19]. There remain several challenges in fault detection with LightGBM algorithms, such as critical parameters in the LightGBM algorithm model need to be tuned to obtain the ideal fault detection performance, hard to guarantee the balance between the local optimization and the global optimization in the traditional optimization algorithm, and even cause premature convergence.
Expected to address the preceding challenges, a novel method using improved LightGBM is proposed in this research for the fault detection of wind turbine gearboxes. Within our method, the improved LightGBM has a lower false alarm rate and lower missing detection rate compared with the GBDT, XGBoost, LightGBM [
20,
21,
22]. An improved LightGBM which combines Bayesian hyper-parameter optimization and the LightGBM algorithm is proposed to diagnose faults and to provide a novel method for monitoring and fault diagnosis of wind turbine gearboxes [
23]. The maximum information coefficient is also used to select parameters in Supervisory Control and Data Acquisition (SCADA) data for wind turbine gearboxes. A case study with a three-year SCADA dataset collected from a wind farm sited in Southern China is conducted to validate the proposed approaches.
2. An Improved LightGBM Algorithm
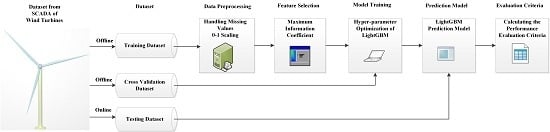
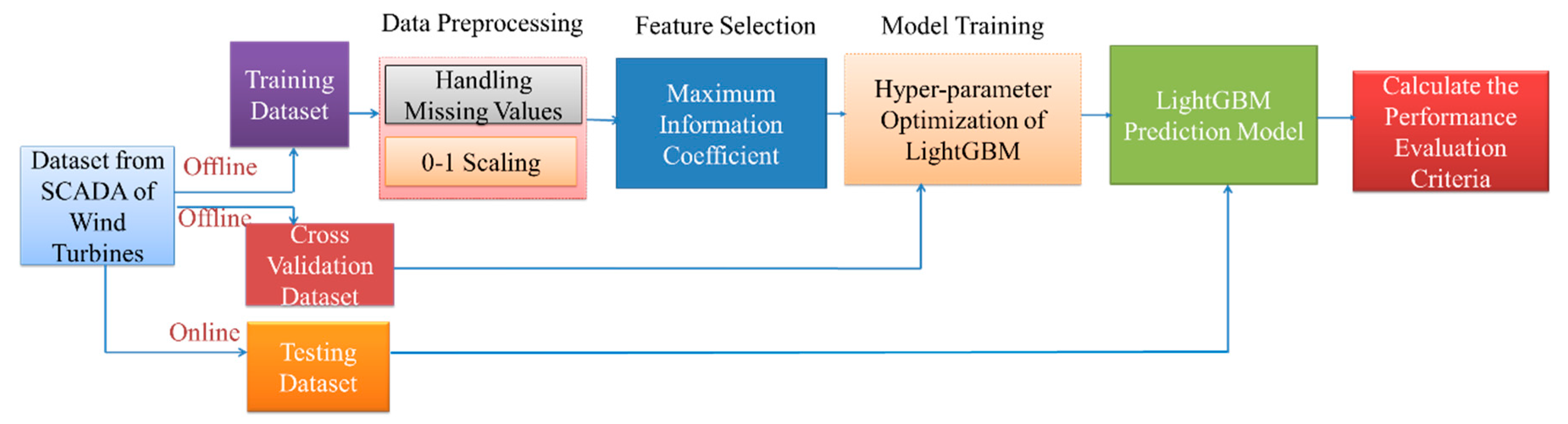
In this section, an improved LightGBM approach is proposed for the fault detection of wind turbine gearboxes. The method can be implemented with four steps: data preprocessing, feature selection, model training, and LightGBM online fault detection. Firstly, the dataset is collected from SCADA and data preprocessing is conducted. 0–1 scaling is used for data preprocessing. In machine learning, D{
X,
Y} is the training dataset, where
X = {
x1,
x1, …,
xm} is the m-dimension feature space, while
Y [0, 1] represents the target variables [
24]. Feature scaling is a method that consists of rescaling the range of features to scale the range in [0, 1] or [−1, 1], the 0–1 scaling of
x can be computed as follows:
where
denotes the normalized value,
x is the initial value,
is the minimum value of
x,
is the maximum value of
x. Missing values also have effects on model estimation performance, while handling missing values often includes deletion methods, and imputation methods [
25]. LightGBM was selected to deal with the possibility of missing values here as it has an amount of knowledge that cannot be overlooked.
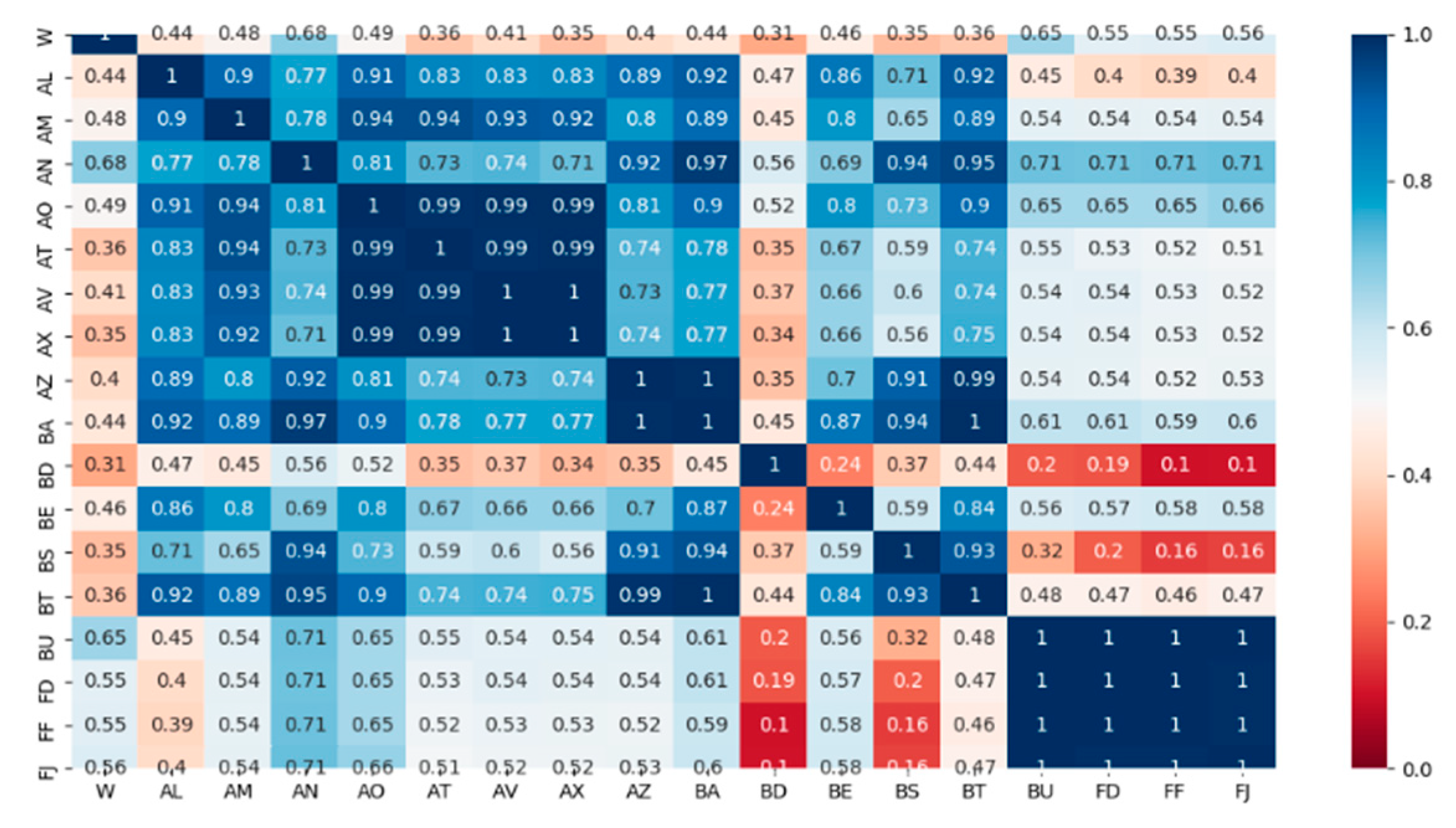
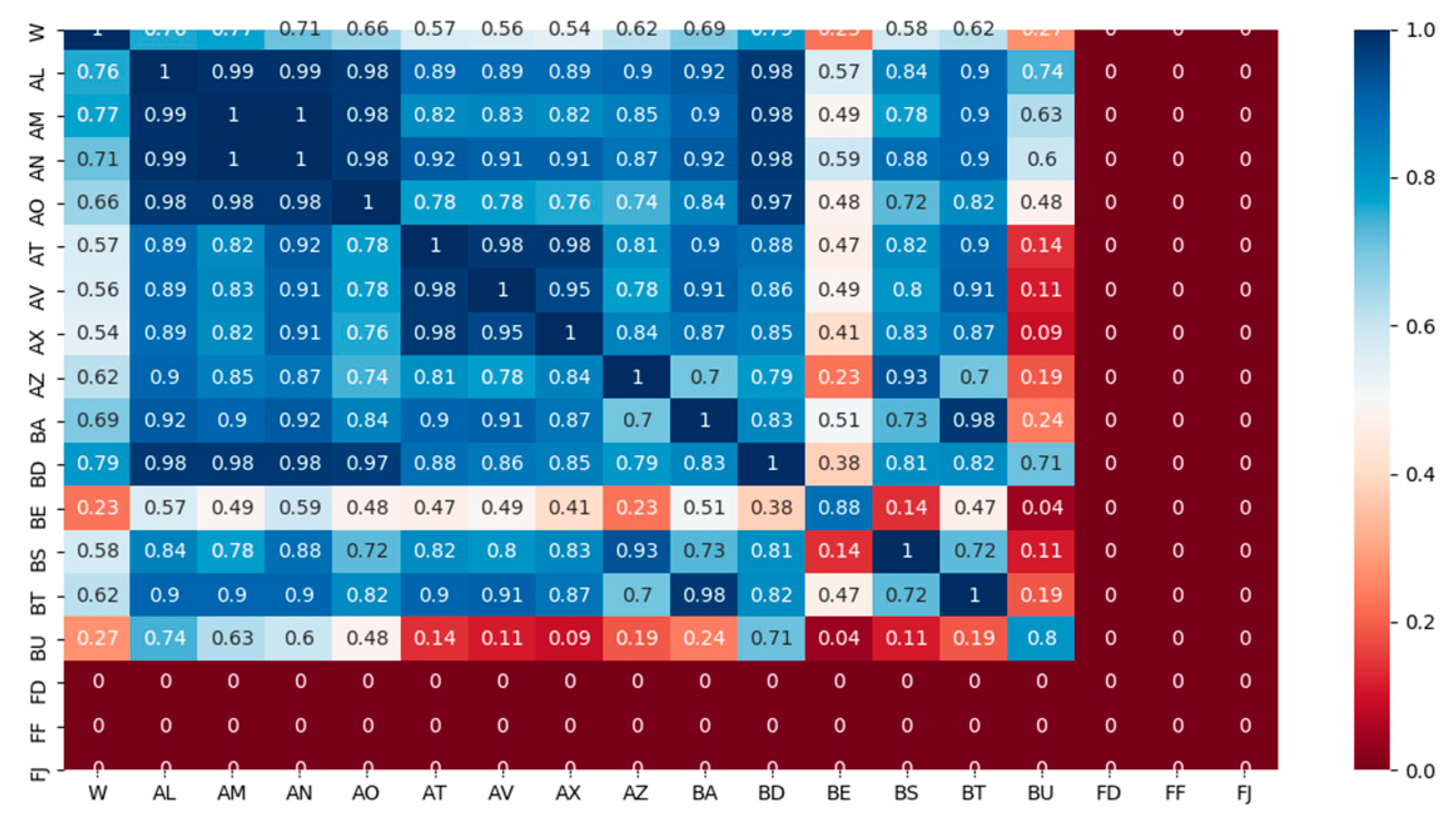
The second stage is for feature selection. By making feature selection, the reasonable parameters of wind turbine gearboxes were selected and the model performance has been improved. In this part, maximum information coefficients are proposed to measure of how much information between two wind turbine features share. By inputting the original feature set, the maximum information coefficient method was used for parameter selection and outputting the optimal feature subset.
The third stage is developed for Bayesian hyper-parameter optimization, as LightGBM is a powerful gradient boosting algorithm which has numerous hyper-parameters. Therefore, here Bayesian hyper-parameter optimization is proposed to tuning the hyper-parameters into LightGBM. By dividing the processed data into two subsets—training dataset and testing dataset—and using the training dataset to construct the improved LightGBM fault detection model. Then the training datasets and the test datasets are inputted, by setting the LightGBM parameter search field and using Bayesian hyperparameter optimization on LightGBM and then output the LightGBM optimal hyperparameters and obtained the final model.
The final step comes to LightGBM online fault detection. By inputting the optimal LightGBM hyperparameters to obtain the final model, followed by applying the final model on testing datasets, and embedding the missing detection rate, finally the false alarm rate can be used to calculate the performance evaluation criteria. The fault sample and the fault-free sample are distinguished according to the improved LightGBM method.
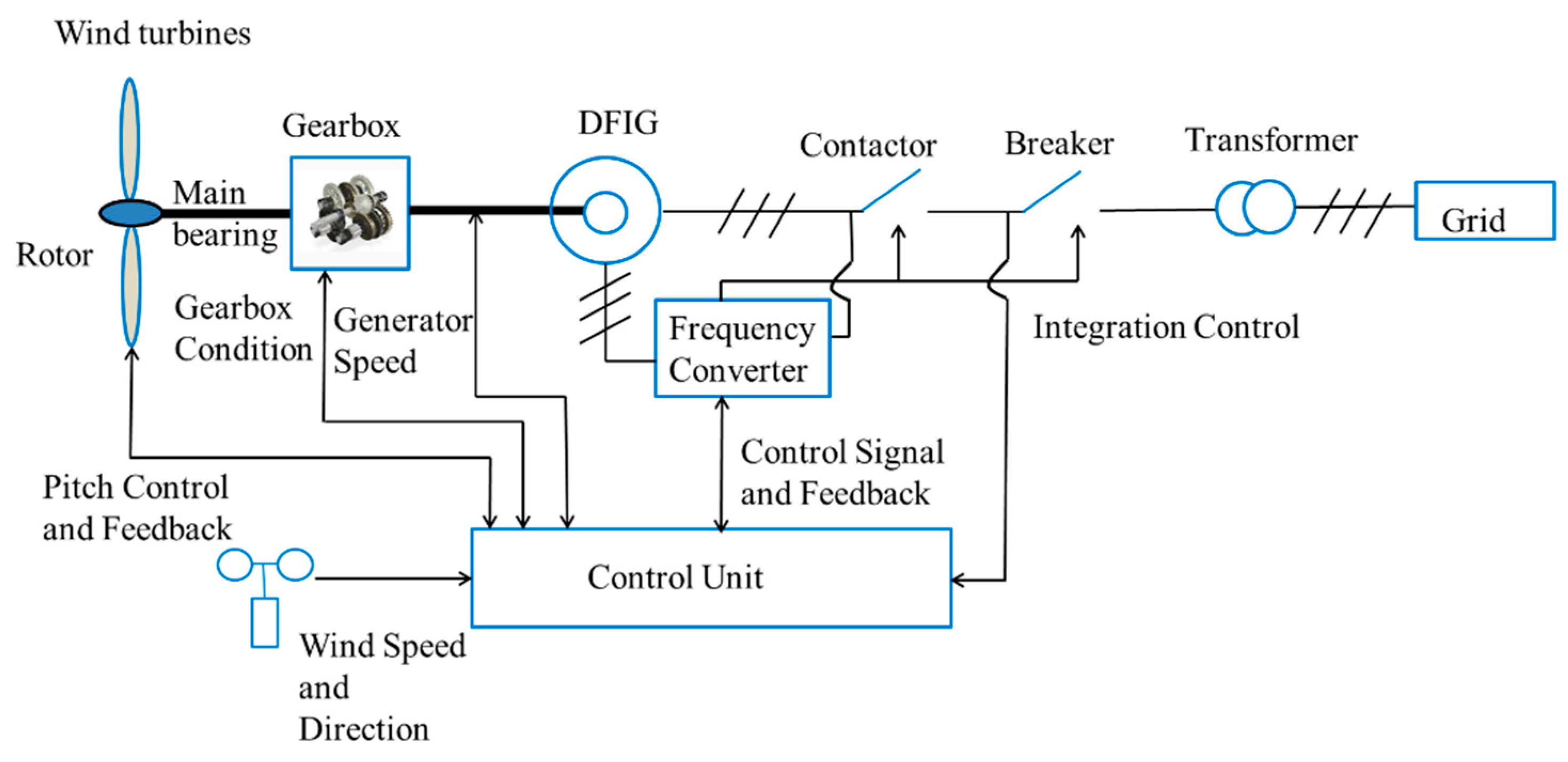
This paper proposed a performance evaluation criterion for the improved LightGBM model to support fault detection. By embedding the confusion matrix as a performance indicator, an improved LightGBM fault detection approach is developed. Subsequently, the improved LightGBM method was used to detect faults of wind turbines. The framework of this study can be shown as
Figure 1.
2.1. Maximum Information Coefficient
The theory of maximum information coefficients is used to measure the strength of the numerical correlation between the two features [
26]. Given
X is a discrete variable, the information entropy [
27] of
X can then be expressed as
Conditional entropy refers to the conditional probability distribution of
X occurring when random variable
Y occurs.
Substituting information for Equation (2) minus Equation (3)
For the random variable
X, the maximum information coefficient of
Y is
where |
X|·|
Y| represents the number of grids. Parameter
B represents the 0.6th power of the total amount of data.
The maximum information coefficient ranges from 0 to 1, and the closer the value is to 1, the stronger the correlation between the two variables, and vice versa.
2.2. LightGBM
Light Gradient Boosting Machine (LightGBM) is a Gradient Boosting Decision Tree (GBDT) framework based on the decision tree algorithm proposed using gradient-based one-side sampling (GOSS) and exclusive feature bundling (EFB). The continuous features can be discretized by the GBDT algorithm, but it only uses the first-order derivative information when optimizing the loss function, the decision tree in GBDT can only be a regression tree which is because each tree of the algorithm learns the conclusions and residuals of all previous trees. Moreover, GBDT is challenged in accuracy and efficiency with the growth of data volume. The XGBoost algorithm introduces the second derivative to Taylor’s expansion of the loss function and the L2 regularization of the parameters to evaluate the complexity of the model, and can automatically use the CPU for multi- threaded parallel computation, after that, the efficiency and accuracy of diagnosis can be improved. However, the leaf growth mode grows with the greedy training method of layer-by-layer. Then LightGBM adopted the histogram-based decision tree algorithm. The leaf growth strategy with depth limitation and multi-thread optimization in LightGBM contributes to solve the excessive XGBoost memory consumption, which can process big data with have higher efficiency, lower false alarm rate and lower missing detection rate.
Given the supervised learning data set
X =
, LightGBM was developed to minimize the following regularized objective.
In this algorithm, logistic loss function is used to measure the difference between the prediction
and the target
.
Regression tree was then used in LightGBM:
The regression tree can be represented by another form, namely
wq(x),
, where
J is the number of leaf nodes,
q is the decision rule of the tree,
w is the sample weight, and the objective function can be expressed as:
The traditional GBDT uses the steepest descent method, which only considers the gradient of the loss function. In LightGBM, Newton’s method is used to quickly approximate the objective function. After further simplification and deriving of Equation (9), the objective function can be expressed as Equation (10):
where
,
represents a first-order loss function and a second-order loss function, respectively.
Using
Ij to represent the sample set of leaf
j, Equation (11) can be transformed as follows:
Given the structure of the tree q(x), the optimal weight of each leaf node and the limit of
can be obtained through quadratic programming:
The gain calculation formula then is:
LightGBM uses the maximum tree depth to trim trees and avoid overfitting, using multi-threaded optimization to increase efficiency and save time.
2.3. Bayesian Hyper-Parameter Optimization
The main parameters which affect the performance of the LightGBM model are the number of leaves, the learning rate, etc., instead of being obtained through training, these parameters need to be manually adjusted. These parameters were defined as hyper-parameters [
28]. Traditional methods of hyper-parameter optimization include grid searching, random searching, and so on. Although grid searching supports parallel computing, it is memory consuming [
29]. The purpose of the random searching is to obtain the optimal solution of the approximation of the function by random sampling in the searched range, which is easier to jump out of the global optima and cannot guarantee an optimal solution.
The Bayesian optimization is based on the past evaluation results of the objective function, using these results to form a probability model, and mapping the hyper-parameters to the objective function’s scoring probability to find the optimal parameter
θ, which can be expressed as P(
Y|
X) [
30]. As to the selection of probability model, it can be divided into Gaussian process, random forest regression, and Tree-structured Parzen Estimator (TPE). The TPE method was found can achieve better performance. The Bayesian Tree-structured Parzen estimation method is used to optimize the parameters of LightGBM.
Suppose
,
…
represents hyperparameters in machine learning algorithm
A (such as LightGBM),
data set is used for training, and
data set is used for verification (i.e., hyperparameter optimization), and the two are independently distributed.
L (
A,
,
,
is used to represent the verification loss of algorithm
A. K-fold cross-validation is generally used to address the optimization requirement:
The interval range for parameters are needed to set in LightGBM algorithm. In the process of parameter optimization, the model is continuously trained, and the classification result obtained by each parameter combination is evaluated by the evaluation function. Finally, the optimal parameter combination is obtained. The combination is substituted into the LightGBM algorithm, and the classification performance is improved.
Implementation of the proposed LightGBM hyper-parameters optimization can be detailed as follows [
31]:
| Algorithm 1: LightGBM via hyper-parameters optimization model |
| Input: LightGBM hyper-parameters , LightGBM Model M, P to record the settings and the corresponding loss |
| 1: Initialize M0; P={} |
| 2: For n = 1, 2,…do |
| 3: find the local optimal hyper-parameter by minimizing the current model : |
| 4: Calculate the loss under the settings of loss function L: = L() |
| 5: Store and the corresponding loss in P |
| 6: Fit a new model |
| End for |
| Output: optimal hyper-parameters of LightGBM with minimum loss in P |
| Algorithm 2: Off-line implementation of improved LightGBM fault detection method |
| Input: LightGBM Model , wind turbines gearboxes SCADA dataset D = ,… |
| 1: Collecting normal wind turbines gearboxes operating dataset D |
| 2: Handing missing data and apply data normalization for D by Equation (5), to have dividing dataset as and |
| 3: Establish LightGBM model based on , from Algorithm 1 |
| 3: Establish LightGBM model based on , from Algorithm 1 |
| 4: Make a fault decision according to Equation (1) |
| 5: Calculate the performance according to Equations (15) and (16) |
| Output: False Alarm Rate and Missing Detection Rate |
| Algorithm 3: Online implementation of improved LightGBM fault detection method |
| Input: LightGBM Model , online data |
| 1: Obtain from Algorithm 2 |
| 2: Establish LightGBM model based on and optimal hyper-parameters of LightGBM from Algorithm 1 |
| 3: Make a fault decision according to Equation (1) |
| 4: If the data is in fault, calculate the error between the model prediction and the online test data |
| 5: Calculate the performance according to Equations (15) and (16) |
| Output: False Alarm Rate and Missing Detection Rate |
Algorithm 1, 2, 3 indicates the process of LightGBM via hyper-parameters optimization model, Off-line implementation of improved LightGBM fault detection method, online implementation of improved LightGBM fault detection method, respectively. LightGBM is a powerful machine learning method that has numerous hyper-parameters. In this paper, TPE is proposed to tune the hyper-parameters in LightGBM.
4. Results and Discussion
In this section, case studies were conducted with a three-year SCADA dataset collected from a wind farm sited in Southern China. The effectiveness of the proposed improved LightGBM framework fault detection was then validated. To further demonstrate the superiority of the proposed framework, comparative studies were implemented between three mainstream fault diagnosis methods, namely GBDT, XGBoost, LightGBM.
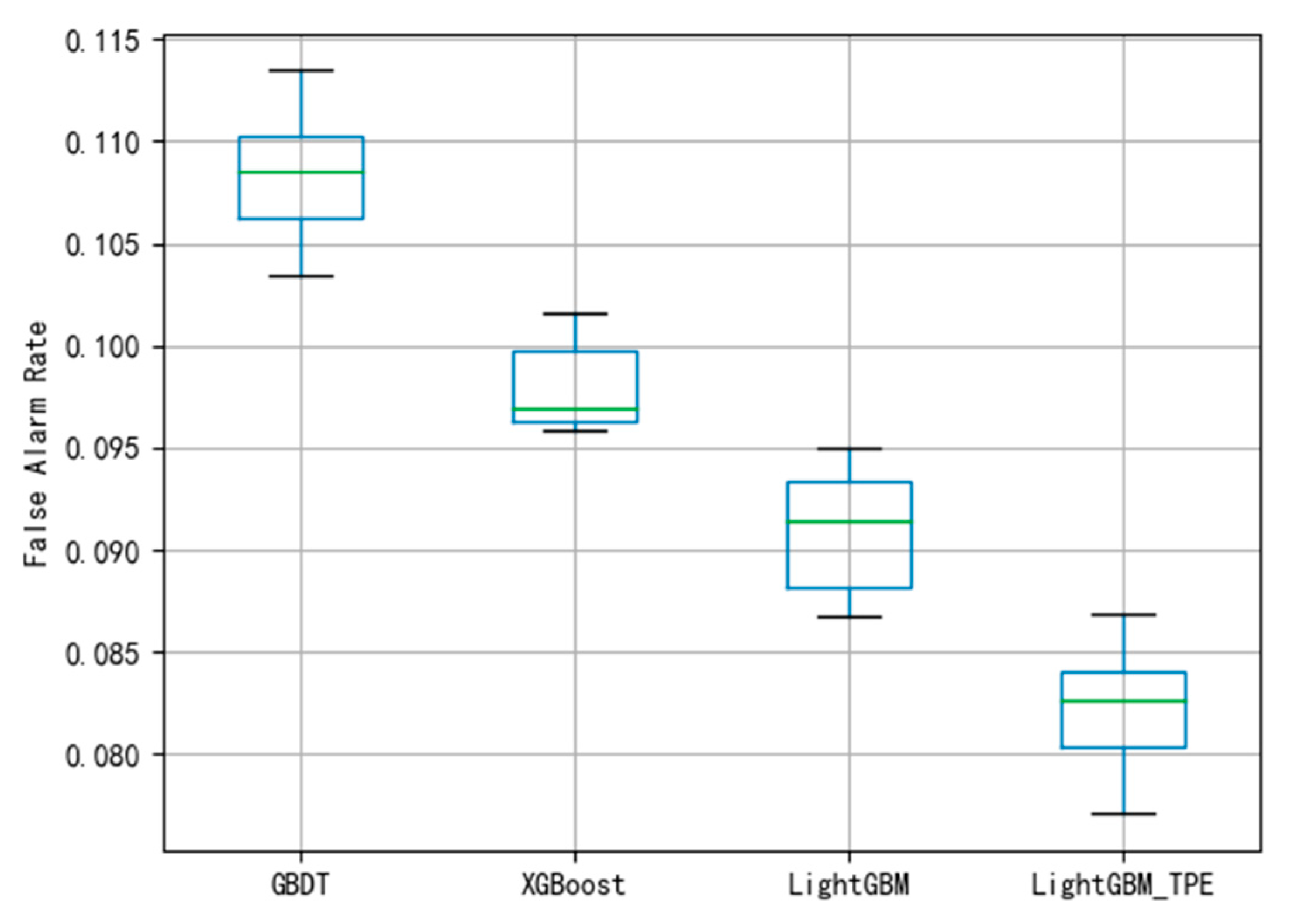
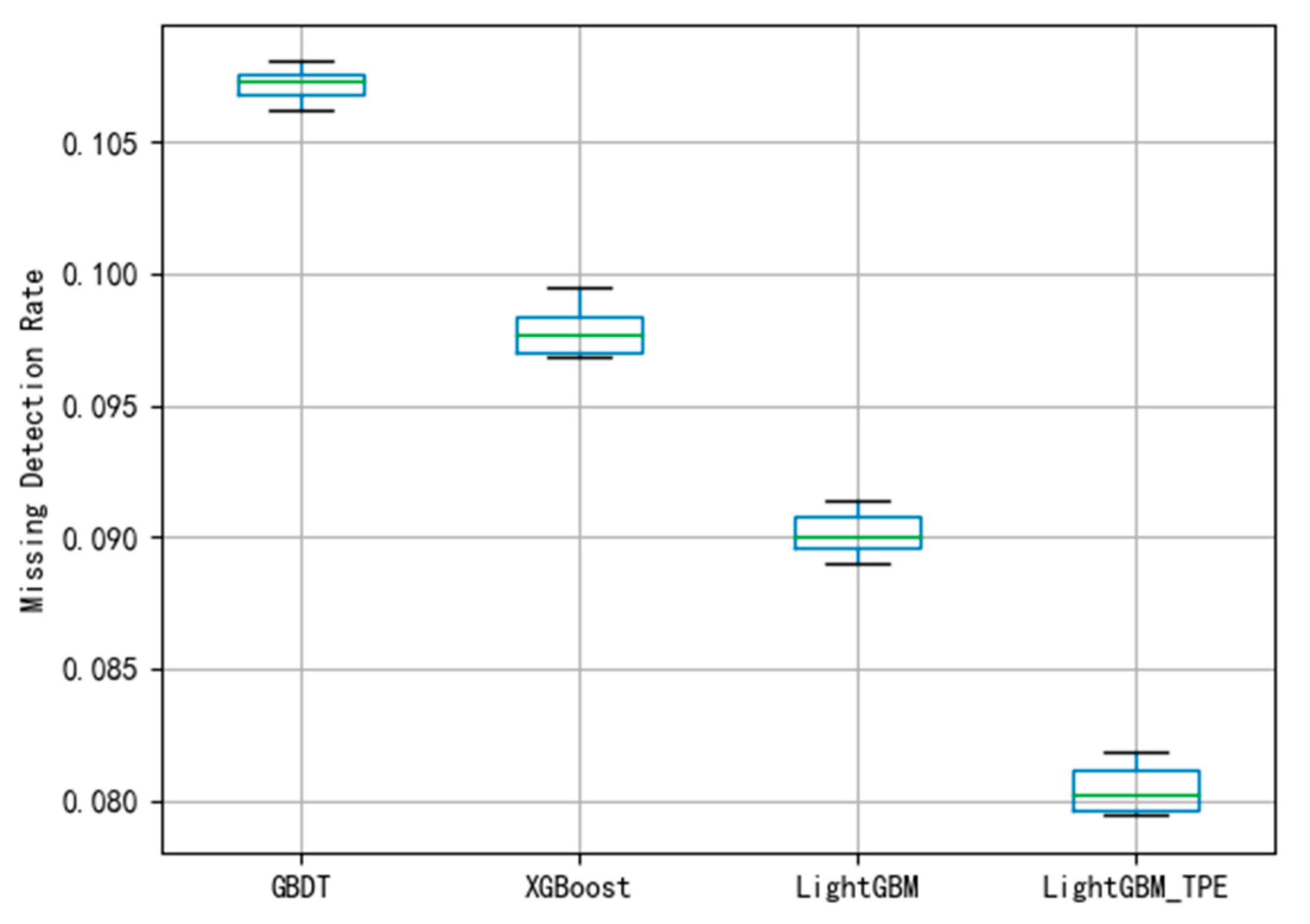
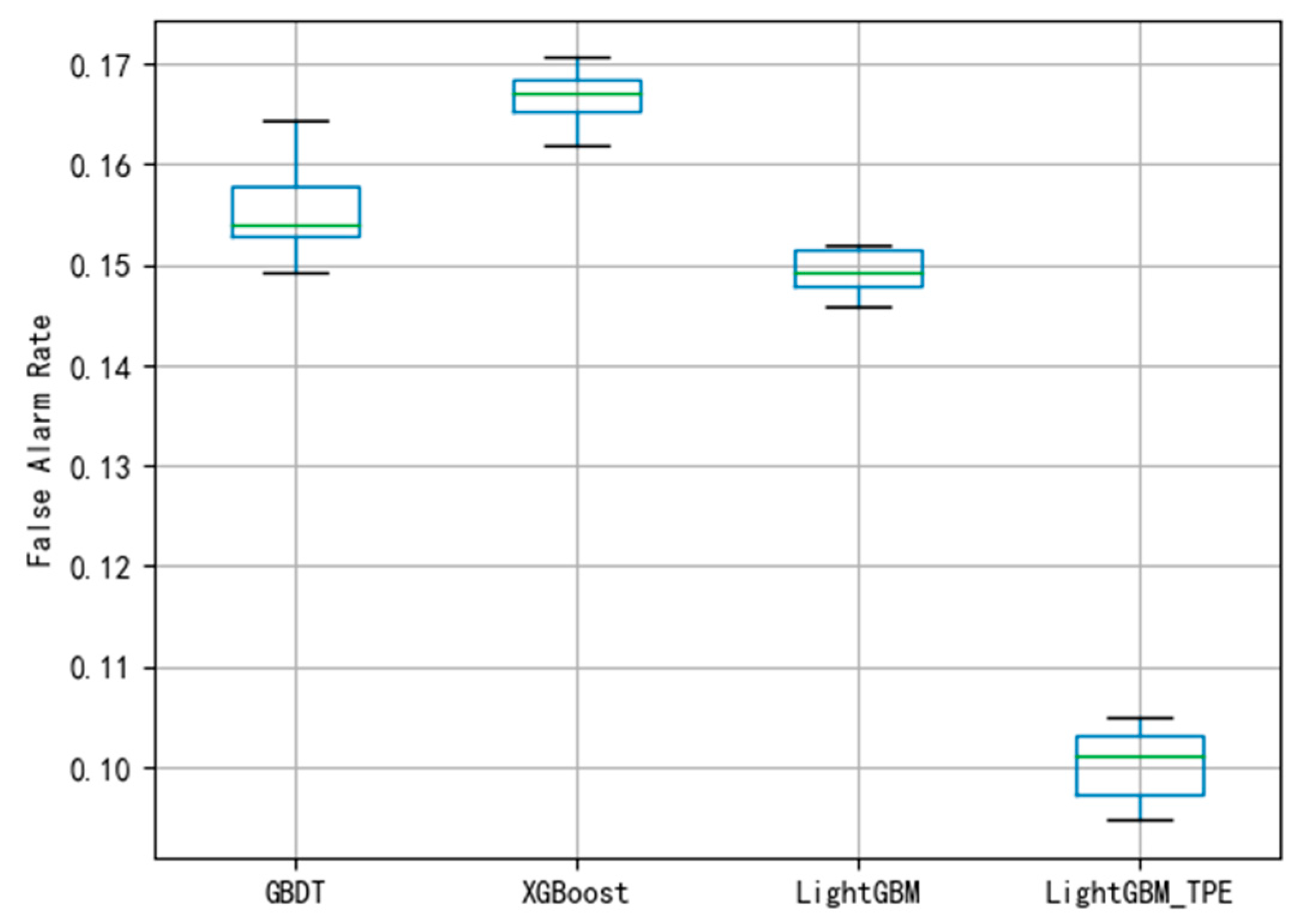
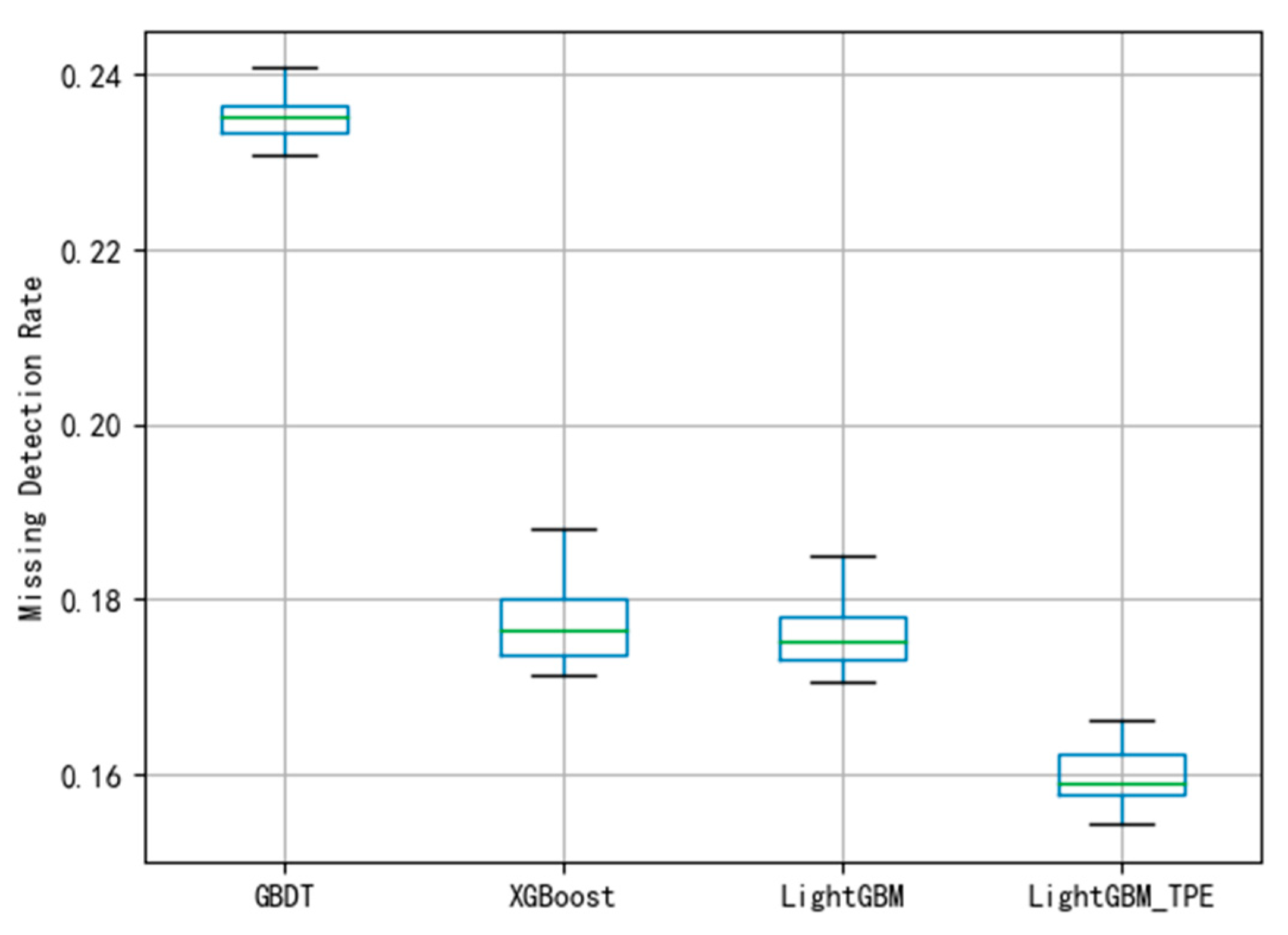
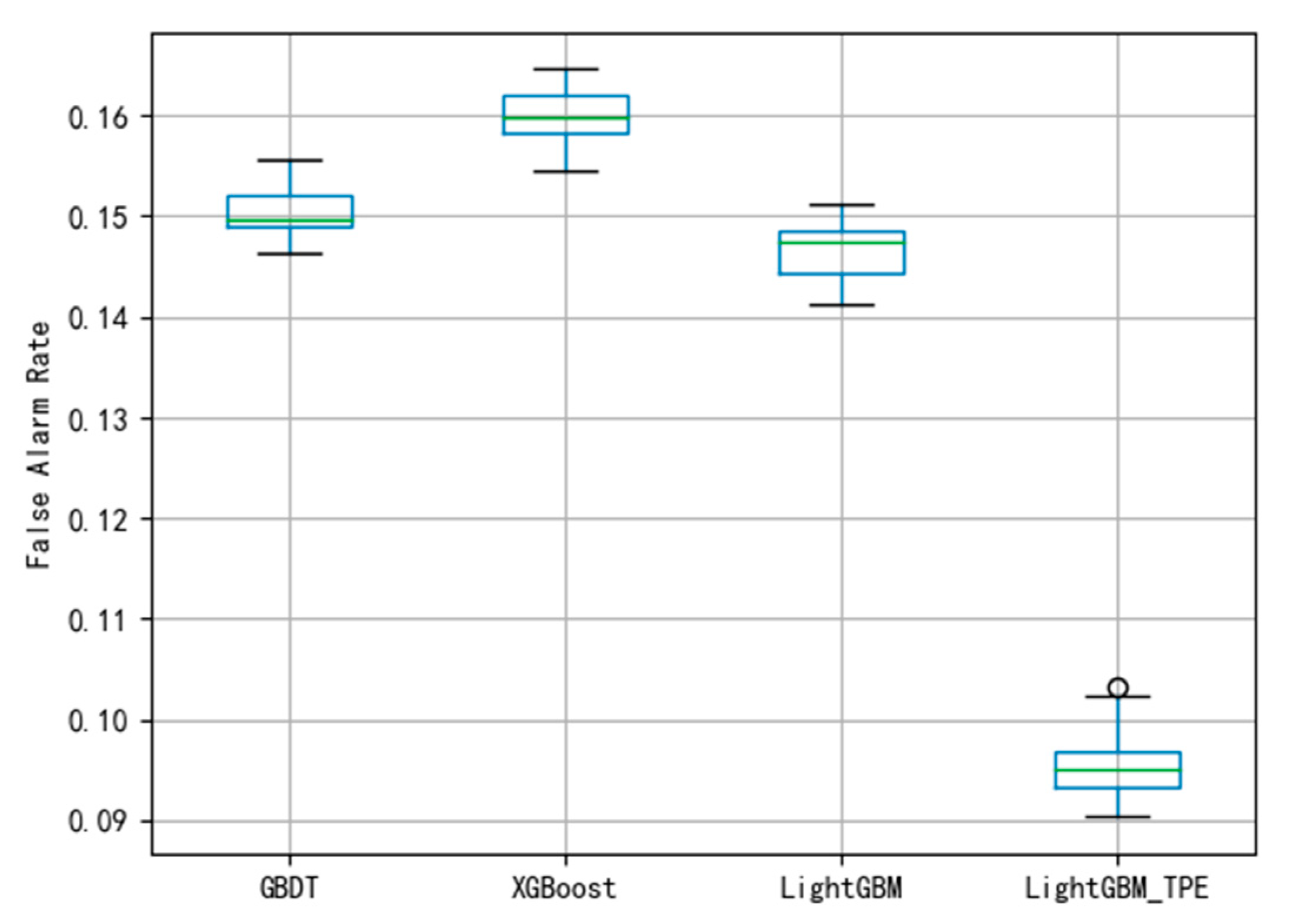
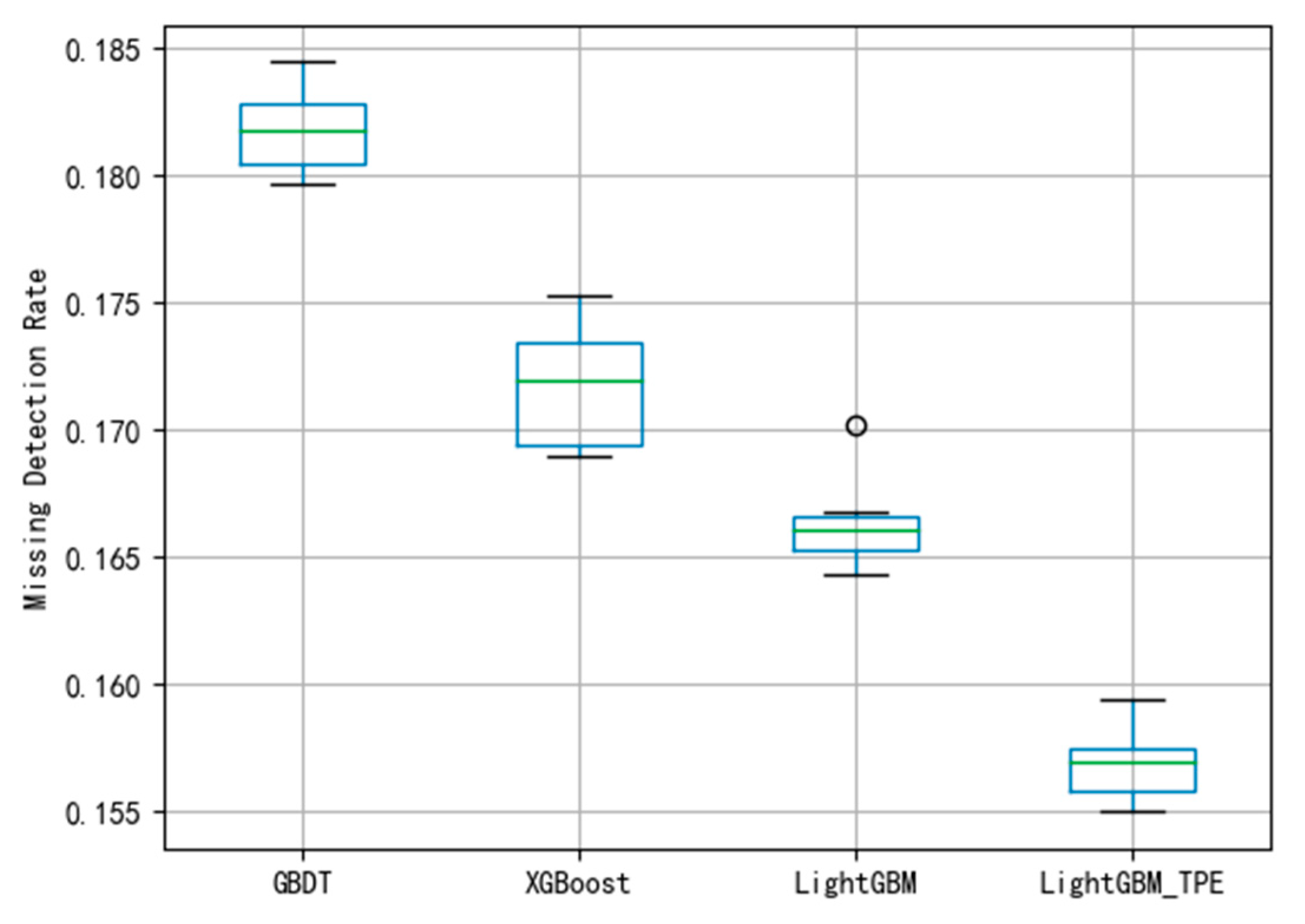
By using different evaluation criteria in the three different datasets, the FAR and MDR under different algorithms are depicted shown in
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10 and
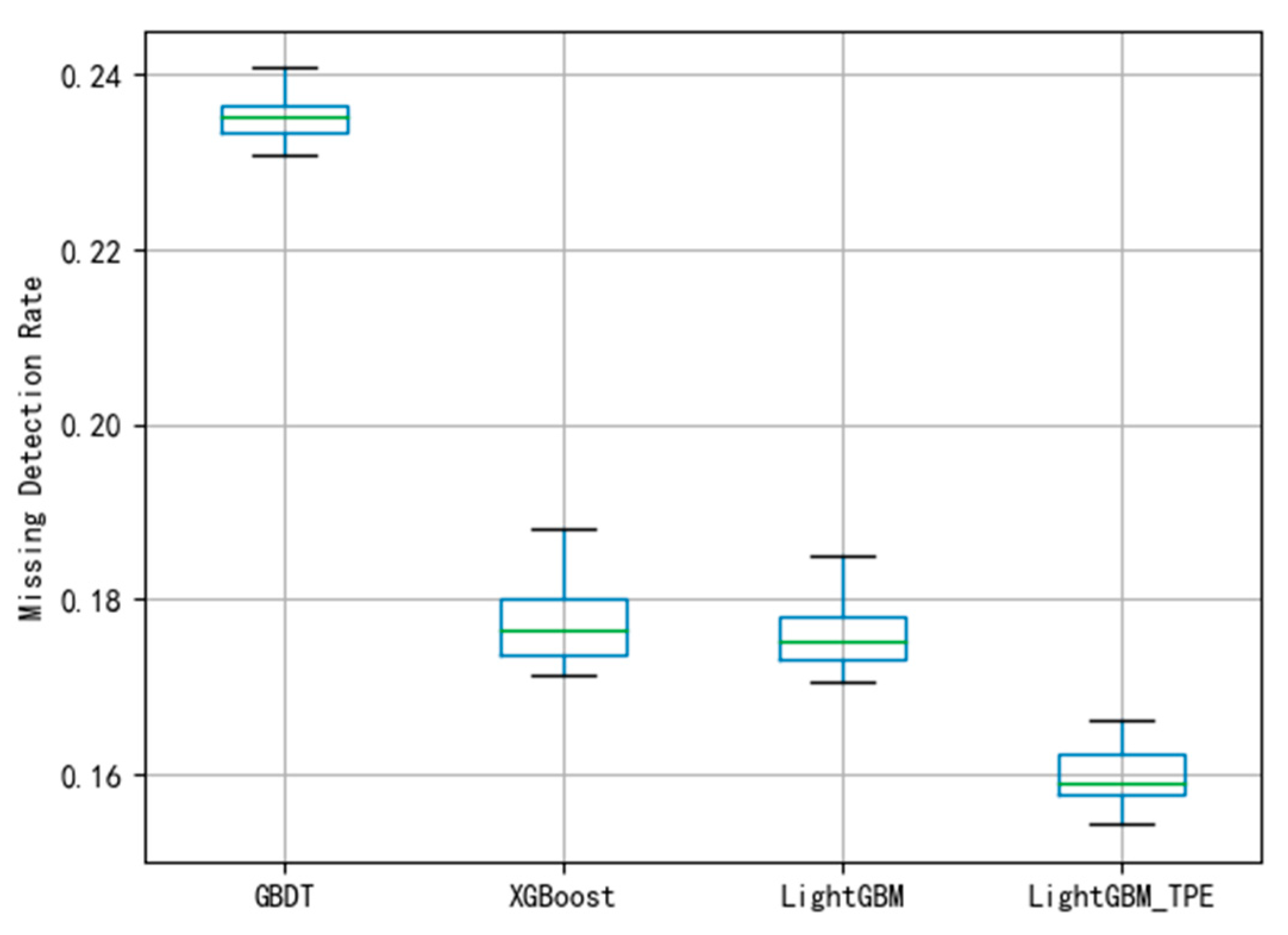
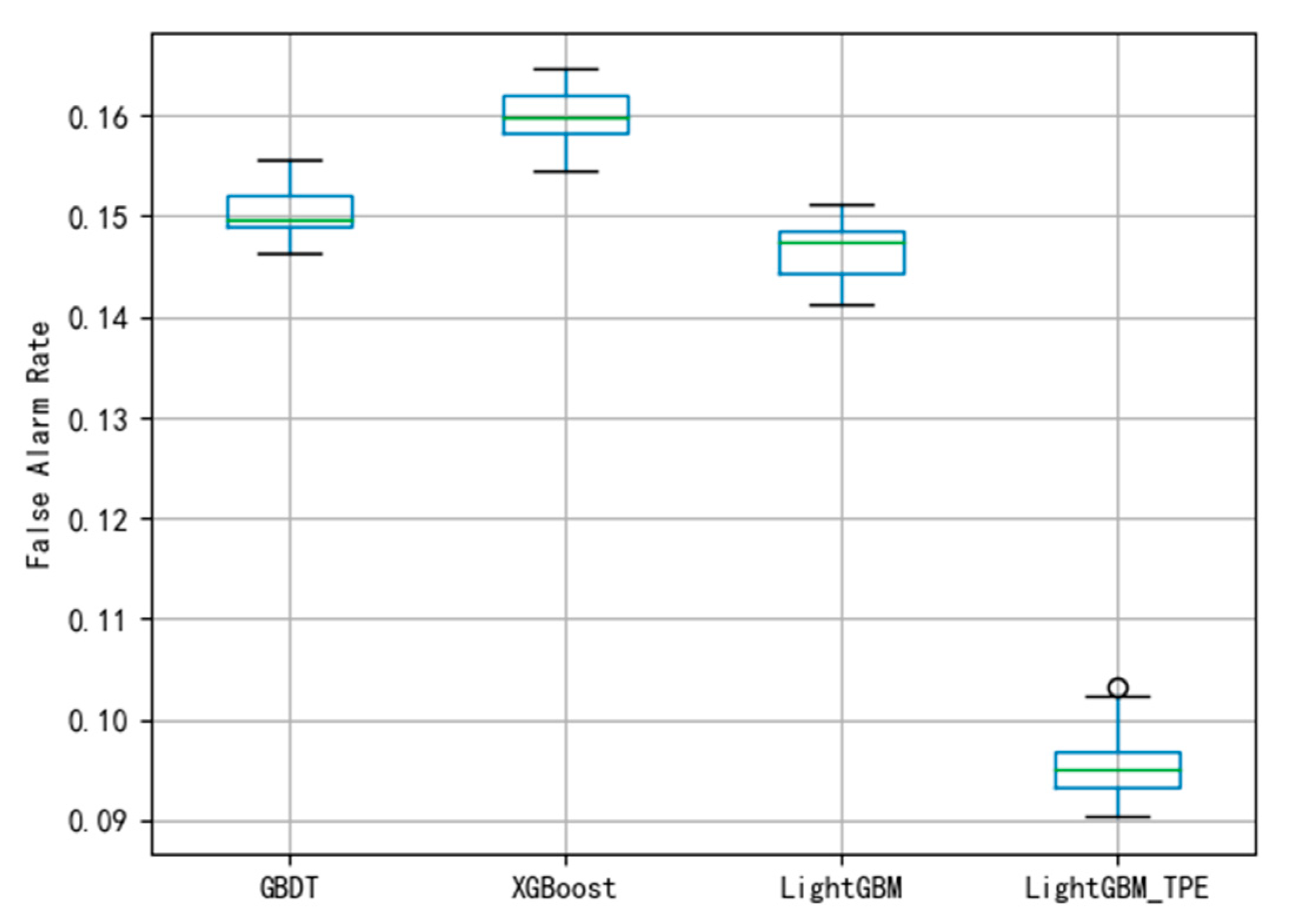
Figure 11. To avoid over-fitting in the model, this paper employed the 10-fold cross-validation method to evaluate the model. The smaller the FAR and MDR the better the performance.
Gradient boosting decision tree (GBDT) is a powerful boosting framework, which is widely used in machine learning models and has been successful applied in fault diagnosis [
33]. Thus, GBDT was applied to predict the faults and classify the type of faults of wind turbines gearboxes. In this paper, as shown in
Figure 6,
Figure 7,
Figure 8,
Figure 9 and
Figure 10, all the fault detection results by using GBDT have a relatively higher FAR and MDR than other boost algorithms. From
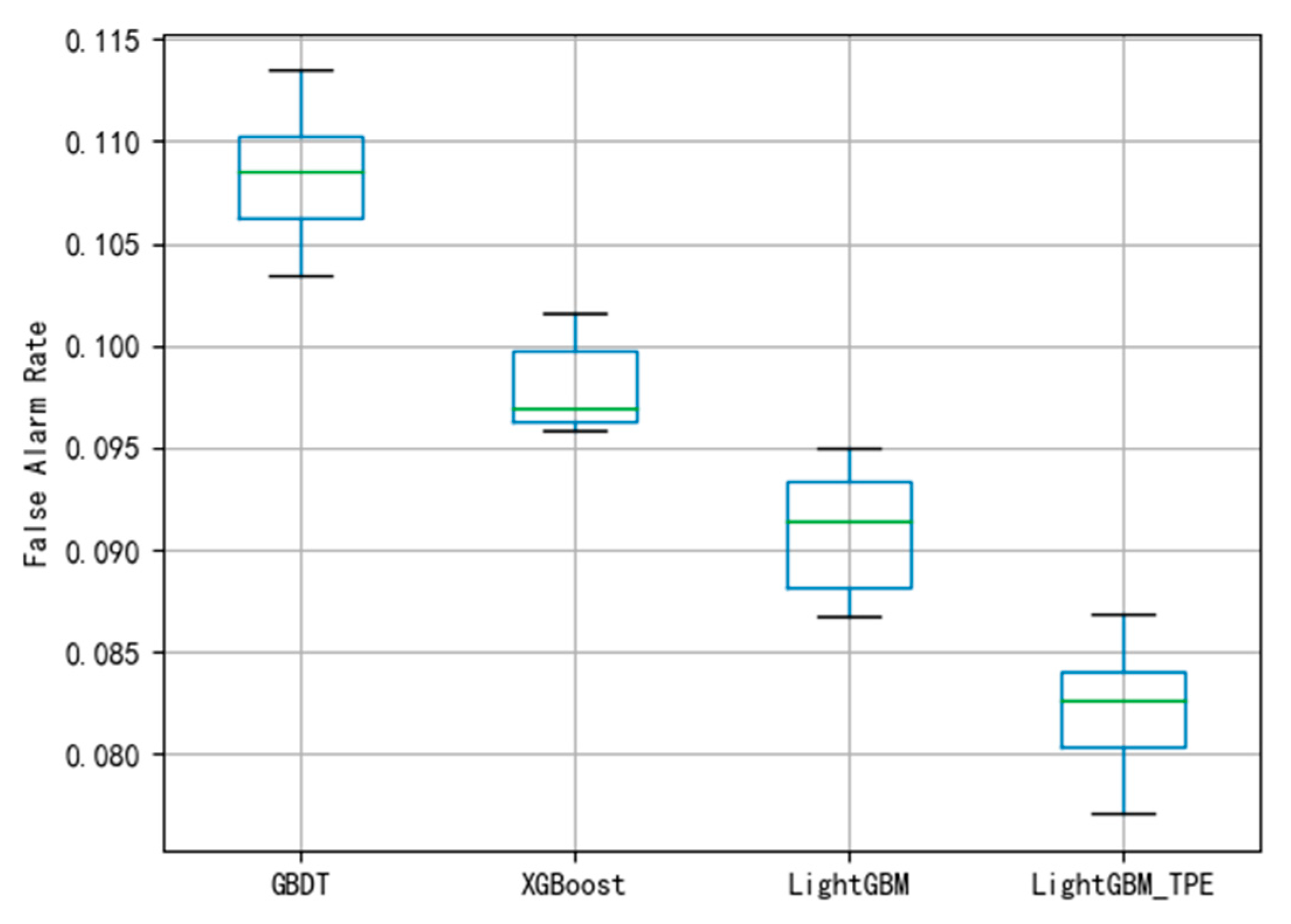
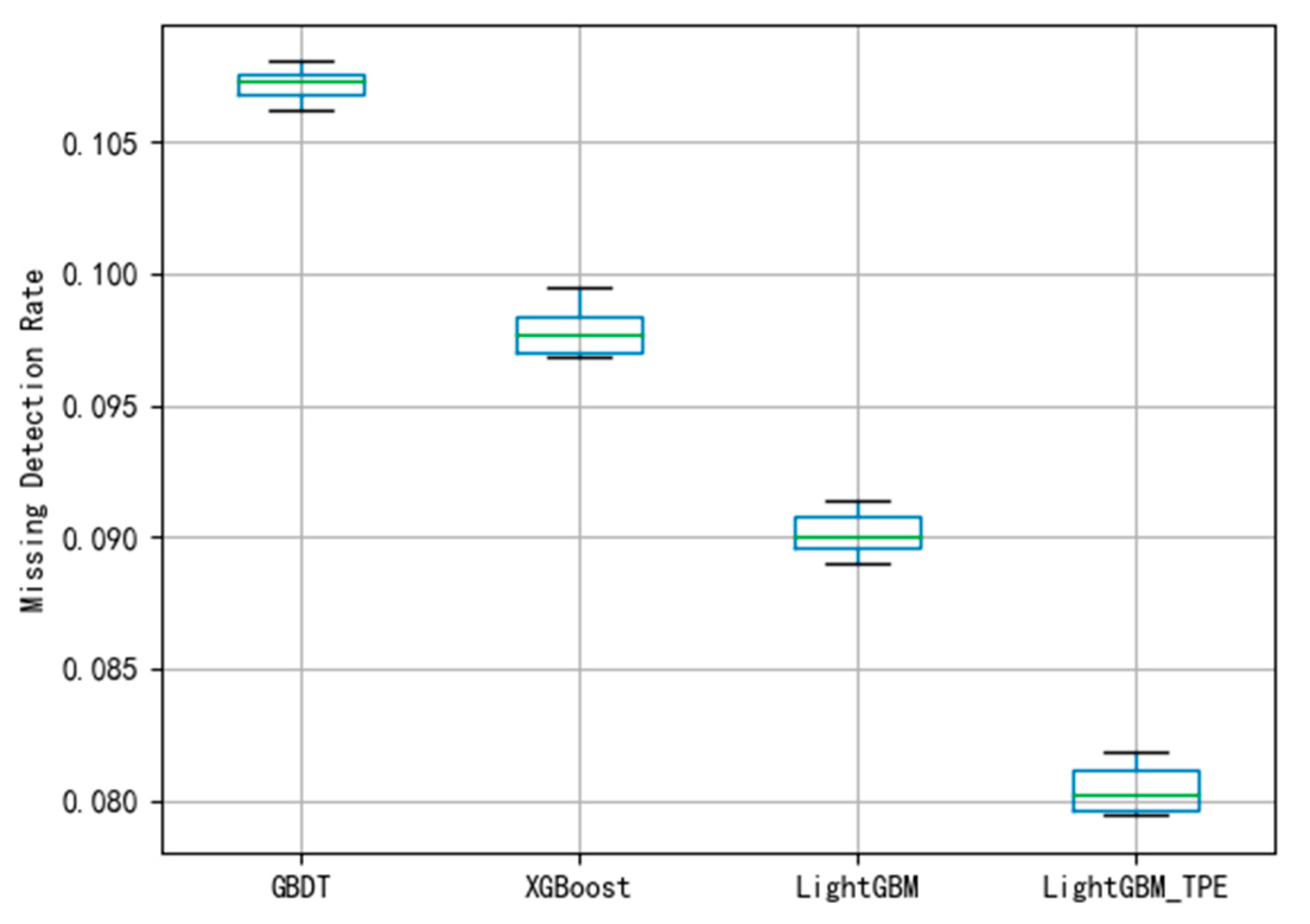
Figure 6, the average of FAR using GBDT is 0.107. The boxplot shows that the classification of the GBDT method is better. Compared with the MDR using the GBDT method in
Figure 6 and
Figure 7, the figure shows that the model has not been fitted.
XGBoost, as a strong classification model in machine learning, has been widely applied in fault diagnosis [
34]. Moreover, it has been reported that this approach can successfully detect faults in industrial fields [
35]. Therefore, XGBoost was also applied to detect faults for comparison. The results in
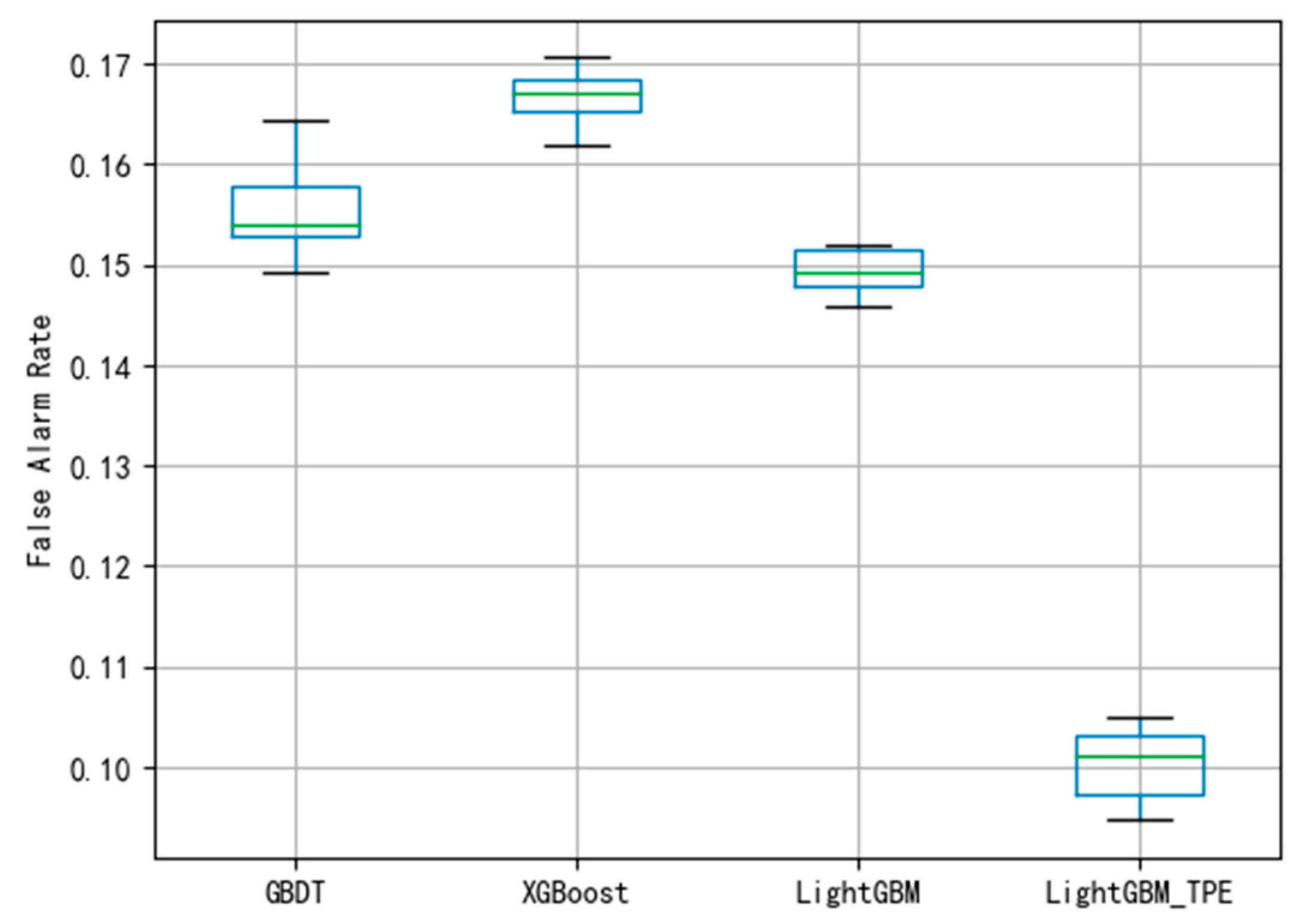
Figure 8 and
Figure 9 indicate that the performance of the fault diagnosis is slightly worse than that of the LightGBM. The average of FAR and MDR using XGBoost was 0.165 and 0.178, respectively. The general performance of XGBoost is better than GBDT, this may be because XGBoost uses a second-order Taylor expansion to approximate the optimal solution of the objective function.
LightGBM is of two novel techniques: gradient-based one-side sampling (GOSS) and exclusive feature bundling (EFB) which can deal with a large number of data instances and large numbers of features in wind turbines, respectively [
36]. In this research, the GOSS is adopted to split the optimal node using variance gain and EFB. The GOSS has no impact on the training accuracy and will outperform random sampling. The results using the LightGBM method are illustrated in
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10 and
Figure 11. The average of FAR and MDR in
Figure 10 and
Figure 11 indicates that it has better performance than existing methods.
To reduce the FAR and MDR, the Maximum Information Coefficient (MIC) is proposed for feature selection and Tree-structured Parzen Estimator (TPE) for hyper-parameter optimization to using the improved LightGBM methods to detect the wind turbine gearbox faults including the gearbox total failure, gearbox oil temperature overrun, and gearbox oil pressure failure. Experimental results indicate that the proposed method can also achieve good performance for real-time fault detecting.
Figure 8 and
Figure 9 show that the average FAR and the average MDR of LightGBM via the TPE method are 0.10 and 0.16, respectively, which are lower than the FAR of GBDT and XGBoost and lower than the MDR of GBDT and XGBoost. Similarly, as shown in
Figure 10 and
Figure 11, it can be known that LightGBM via the TPE method has stronger generalization capability than GBDT and XGBoost. It can be known from the experiments that the hyper-parameter optimization of LightGBM successfully solves the fault detection problems and improves the model performance, and the TPE method is superior to the grid search method. Consequently, the improved LightGBM method in wind turbines gearboxes fault detection is effective and advanced.
The preceding comprehensive comparison studies demonstrate that the improved LightGBM has superior performance over GBDT, XGBoost, and LightGBM for wind turbine gearbox fault diagnosis. Experimental results demonstrated that the proposed improved LightGBM fault diagnosis significantly outperformed the traditional boosting algorithm in terms of feature learning, model training, and classification performance.
5. Conclusions
Over the years, machine learning methods for fault diagnosis were well studied by experts and scholars. The effort was devoted to formulating boost-based fault diagnosis methodology and developing corresponding fault diagnosis systems. However, challenges are still existing. This paper provided a novel method for fault detection. The main contributions including:
A feature selection approach based on MIC is constructed to select state parameters, remove irrelevant, redundant, or useless variables, and it can improve fault detection performance.
By using the TPE hyper-parameter optimization and a novel LightGBM algorithm, an intelligent fault detection method is finally developed in this research. The improved LightGBM classification performance evaluation criteria are better than other algorithms, with high-efficiency parallelization, fast speed, high model accuracy, and low occupancy rate. In addition, the accuracy of fault detection is up to 98.67%, thus the presented approach for wind turbine gearboxes is feasible in practical engineering not only in wind turbines fault detection but also in large-scale industrial fault detection.
Experimental results show that the method is not only suitable for fault diagnosis of wind turbine gearboxes but can also applied in industrial system fault diagnosis with multiple feature vectors and low diagnostic accuracy. Based on the improved LightGBM wind turbines gearboxes fault detection presented in this paper, suggestions for future studies might include:
In the case of few imbalanced data distributions in fault diagnosis field, further investigation can be implemented on the imbalanced dataset based on boost algorithm methods to mitigate the influence on skewed data distribution between faulty samples and fault-free samples.
In addition, real-time fault prediction is of great importance in industrial applications.
Combined applications of the improved LightGBM algorithm with other techniques might offer the potential to overcome the drawbacks of each method.
To improve fault diagnosis performance, hybrid fault diagnosis approaches might be a desired solution which worth to be investigated in upcoming studies.

 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}