Noise Reduction Power Stealing Detection Model Based on Self-Balanced Data Set

Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Theft Detection Model
3. Processing of Imbalanced Data Sets
3.1. Stealing Data Set Balance Processing
3.2. Design of CW Generation Counterattack Network for Stealing Data
4. Feature Extraction
4.1. Feature Extraction of Electricity Data
4.2. Electricity Data SCDAE Design
5. Theft Detection Based on LightGBM Classification
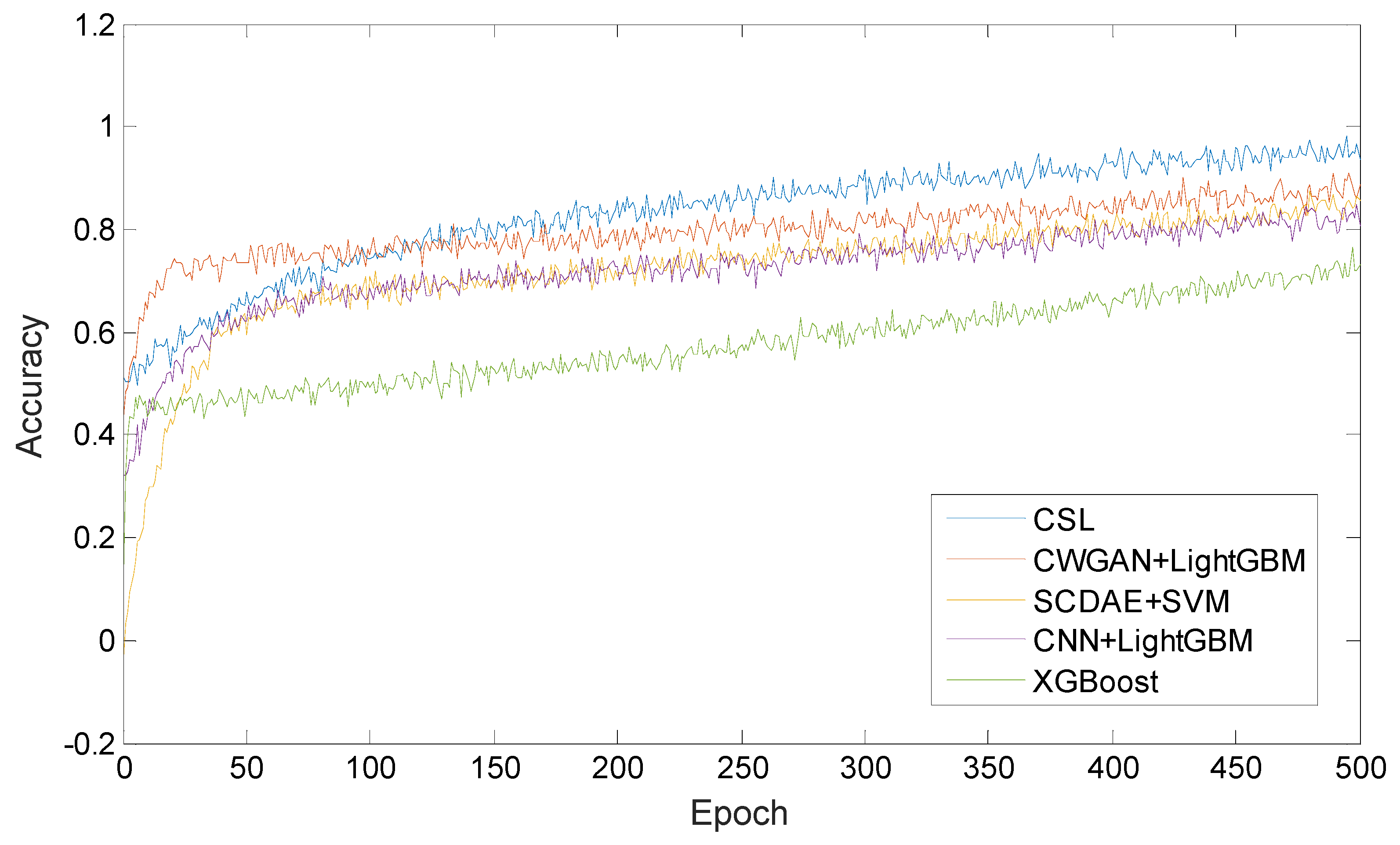
6. Experimental Results and Analysis
6.1. Evaluation Index
6.2. Data Set Balance Verification
- Step 1: Count the number of stolen users and the number of normal users in the original data set , and set the undersampling rate α (0 < α <1). Randomly undersampling normal users and mixing them with the original data set stealing users constitutes a new data set for training of the CWGAN network;
- Step 2: Train the CWGAN network;
- Step 3: Use the trained CWGAN network to generate new stealing data to form a new stealing sample set . Finally, it is merged with the original data set to generate the final balanced power consumption data set. The Algorithm 1 pseudo code is as follows:
| Algorithm 1 CWGAN algorithm for generating steal data |
| Input: unbalanced data set D0, sampling rate is , number of iterations epoch1, epoch2 / * Construct training data set * / Step 1: Calculate n1 and n2 according to D0 Step 2: Undersampling of negative samples constitutes D, the number is / * construct training data set * / Step 3: Train CWGAN model based on data set D
/ * Generate positive samples based on generative adversarial network * / Step 4: The random noise with a vector capacity of extracted from U (0,1) is amplified into data {{}, {}, {} … {}}. As an input to generate the network G, n positive sample sets can be generated. Step 5: Mix the generated positive sample set with the original data set to obtain a balanced data set Step 6: Output data set Output: balanced data set |
6.3. SCDAE Feature Extraction Verification
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| G | Generative model |
| D | Discriminant model |
| Overall objective function | |
| Distribution function of G (x) | |
| Sample true distribution | |
| E | Expectation function |
| Optimal discriminant model | |
| Optimal generative model | |
| Original data set | |
| Original power consumption data | |
| Loss function | |
| W (, ) | Wasserstein distance |
| C | Minimum radius |
| Noise | |
| Probability distribution of | |
| Generator function | |
| Multiple hidden layers | |
| Hidden layer | |
| Activation function of the code | |
| Undersampling operator | |
| Decoder activation function | |
| Daily electricity consumption vector | |
| Encoder Neural network weights | |
| Encoder Neural network biases | |
| k | Histogram width |
| n | Dimension of the data set |
| σ | Probability constant |
| A,B | Feature data sets |
| Vector with dimension s in space X s | |
| O | Feature data set |
| Negative gradients of the loss function |
References
- Jokar, P.; Arianpoo, N.; Leung, V.C.M. Electricity theft detection in AMI using customers’ consumption patterns. IEEE Trans. Smart Grid 2017, 7, 217–227. [Google Scholar] [CrossRef]
- Zheng, K.; Chen, Q.; Wang, Y.; Kang, C.; Xia, Q. A Novel Combined Data-Driven Approach for Electricity Theft Detection. IEEE Trans. Ind. Inform. 2019, 15, 1809–1819. [Google Scholar] [CrossRef]
- Messinis, G.M.; Rigas, A.E.; Hatziargyriou, N.D. A Hybrid Method for Non-Technical Loss Detection in Smart Distribution Grids. IEEE Trans. Smart Grid 2019, 10, 7080–7091. [Google Scholar] [CrossRef]
- Jindal, A.; Dua, A.; Kaur, K.; Singh, M.; Kumar, N.; Mishra, S. Decision tree and SVM-based data analytics for theft detection in smart grid. IEEE Trans. Ind. Inform. 2017, 12, 1005–1017. [Google Scholar] [CrossRef]
- Shuan, L.; Han, Y.; Yao, X.; Ying, C.S.; Wang, J.; Zhao, Q. Electricity Theft Detection in Power Grids with Deep Learning and Random Forests. J. Electr. Comput. Eng. 2019, 1–12. [Google Scholar] [CrossRef]
- Lu, F.; Ding, X.; Yin, X.; Chen, H.; Wang, Y. Support Vector Machine Stealing Identification Method Based on Sample Optimization Selection. Comput. Meas. Control 2018, 26, 223–226. [Google Scholar]
- Zheng, Z.; Yang, Y.; Niu, X. Wide and Deep Convolutional Neural Networks for Electricity-Theft Detection to Secure Smart Grids. IEEE Trans. Ind. Inform. 2018, 14, 1707–1715. [Google Scholar] [CrossRef]
- Punmiya, R.; Choe, S. Energy Theft Detection Using Gradient Boosting Theft Detector With Feature Engineering-Based Preprocessing. IEEE Trans. Smart Grid 2019, 10, 2326–2329. [Google Scholar] [CrossRef]
- Buzau, M.; Tejedor-Aguilera, J.; Cruz-Romero, P.; Gómez-Expósito, A. Hybrid Deep Neural Networks for Detection of Non-Technical Losses in Electricity Smart Meters. IEEE Trans. Power Syst. 2020, 35, 1254–1263. [Google Scholar] [CrossRef]
- Buzau, M.M.; Tejedor-Aguilera, J.; Cruz-Romero, P.; Gómez-Expósito, A. Detection of Non-Technical Losses Using Smart Meter Data and Supervised Learning. IEEE Trans. Smart Grid 2019, 10, 2661–2670. [Google Scholar] [CrossRef]
- Chatterjee, S.; Archana, V.; Suresh, K.; Saha, R.; Gupta, R.; Doshi, F. Detection of non-technical losses using advanced metering infrastructure and deep recurrent neural networks. In Proceedings of the 2017 IEEE International Conference on Environment and Electrical Engineering and 2017 IEEE Industrial and Commercial Power Systems Europe (EEEIC/I&CPS Europe), Milan, Italy, 13 July 2017. [Google Scholar]
- Ramos, C.C.O.; Souza, A.N.; Papa, J.P.; Falcao, A.X. Fast Non-Technical Losses Identification Through Optimum-Path Forest. In Proceedings of the 2009 15th International Conference on Intelligent System Applications to Power Systems, Curitiba, Brazil, 11 December 2009. [Google Scholar]
- Ford, V.; Siraj, A.; Eberle, W. Smart grid energy fraud detection using artificial neural networks. In Proceedings of the 2014 IEEE Symposium on Computational Intelligence Applications in Smart Grid (CIASG), Orlando, FL, USA, 19 January 2014. [Google Scholar]
- Pan, T.; Zhao, J.; Wu, W.; Yang, J. Learning imbalanced datasets based on SMOTE and Gaussian distribution. Inf. Sci. 2020, 512, 1214–1233. [Google Scholar] [CrossRef]
- Wang, Y. Identification of credit card fraud under imbalanced data. Commun. World 2018, 25, 219–220. [Google Scholar]
- Depuru, S.S.S.R.; Wang, L.; Devabhaktuni, V.; Nelapati, P. A hybrid neural network model and encoding technique for enhanced classification of energy consumption data. In Proceedings of the 2011 IEEE Power and Energy Society General Meeting, San Diego, CA, USA, 24–29 July 2011. [Google Scholar]
- Glauner, P.O. Large-scale detection of non-technical losses in imbalanced data sets. In Proceedings of the Seventh IEEE Conference on Innovative Smart Grid Technologies (ISGT 2016), Minneapolis, MN, USA, 6–9 September 2016. [Google Scholar]
- Georgios, D.; Fernando, B. Effective data generation for imbalanced learning using conditional generative adversarial networks. Expert Syst. Appl. 2018, 91, 464–471. [Google Scholar]
- Fiore, U.; Santis, A.D.; Perla, F. Using Generative Adversarial Networks for Improving Classification Effectiveness in Credit Card Fraud Detection. Inf. Sci. 2017, 479, 448–455. [Google Scholar] [CrossRef]
- Ben Said, A.; Mohamed, A.; Elfouly, T. Deep learning approach for EEG compression in mHealth system. In Proceedings of the 2017 13th International Wireless Communications and Mobile Computing Conference (IWCMC), Valencia, Spain, 27–30 June 2017. [Google Scholar]
- Wei, L.; Sundararajan, A.; Sarwat, A.I.; Biswas, S.; Ibrahim, E. A distributed intelligent framework for electricity theft detection using benford’s law and stackelberg game. In Proceedings of the 2017 Resilience Week (RWS), Wilmington, DE, USA, 18–22 September 2017. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 3149–3157. [Google Scholar]
- Wang, C.; Li, P.; Yu, H. Analysis and application of new forms of smart distribution network and its flexibility characteristics. Autom. Electr. Power Syst. 2018, 42, 13–21. [Google Scholar]
- Zhao, H.; Shi, H.; Wu, J.; Chen, X. Research on Imbalanced Learning Based on Conditional Generative Adversarial Network. Control Decis. 1–10.
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.-A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Buckman, J.; Roy, A.; Raffel, C.; Goodfellow, I. Thermometer encoding: One hot way to resist adversarial examples. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 23 February 2018. [Google Scholar]
- Available online: https://github.com/henryRDlab/ElectricityTheftDetection (accessed on 22 September 2018).
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. Comput. Sci. 2014, 2, 2672–2680. [Google Scholar]
- Zhao, W.; Meng, Q.; Zeng, M.; Qi, P.-F. Stacked Sparse Auto-Encoders (SSAE) Based Electronic Nose for Chinese Liquors Classification. Sensors 2017, 17, 2855. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, T.; Guo, Q.; Sun, H. Power theft detection based on stacked decorrelation autoencoder and support vector machine. Autom. Electr. Power Syst. 2019, 43, 119–127. [Google Scholar]
- Zou, H.; Zhou, Y.; Yang, J.; Jiang, H.; Xie, L.; Spanos, C.J. DeepSense: Device-free Human Activity Recognition via Autoencoder Long-term Recurrent Convolutional Network. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018. [Google Scholar]
- Ju, Y.; Sun, G.; Chen, Q.; Zhang, M.; Zhu, H.; Rehman, M.U. A Model Combining Convolutional Neural Network and LightGBM Algorithm for Ultra-Short-Term Wind Power Forecasting. IEEE Access 2019, 7, 28309–28318. [Google Scholar] [CrossRef]









© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Li, Z.; Li, Y. Noise Reduction Power Stealing Detection Model Based on Self-Balanced Data Set. Energies 2020, 13, 1763. https://doi.org/10.3390/en13071763
Liu H, Li Z, Li Y. Noise Reduction Power Stealing Detection Model Based on Self-Balanced Data Set. Energies. 2020; 13(7):1763. https://doi.org/10.3390/en13071763
Chicago/Turabian StyleLiu, Haiqing, Zhiqiao Li, and Yuancheng Li. 2020. "Noise Reduction Power Stealing Detection Model Based on Self-Balanced Data Set" Energies 13, no. 7: 1763. https://doi.org/10.3390/en13071763