
Model-Based Identification of Alternative Bidding Zones: Applications of Clustering Algorithms with Topology Constraints †

 ,
,  , ,
, ,  ,
,  ,
,
Abstract
:1. Introduction
- Data pre-processing is extended to show further relevant statistical properties of the features considered.
- The analyses are carried out using also the Power Transfer Distribution Functions (PTDFs) as features, in addition to LMPs.
- An alternative way to aggregate the results obtained from the analysis of the scenarios is presented.
- The spectral clustering is applied to the last step of the formation of the zones, to incorporate the topology constraints.
2. Construction of the Reference Cases and Feature Selection
2.1. Scenario Generation
2.2. Feature Selection
- (1)
- The Locational Marginal Prices (LMPs), which provide the information on the nodal prices. The LMPs are the nodal variables mostly used in the literature for the definition of the bidding zones [11]. The congestion that could appear in the network affects the differences among the LMPs determined for the nodes. The LMPs are calculated by executing the Optimal Power Flow (OPF), taking the Lagrange multipliers associated with the power balance equality constraint, and with the inequality constraints referring to the network security.
- (2)
- The Power Transfer Distribution Factors (PTDFs), which represent the sensitivity of the power flow in a connection due to the variation of the power injected in a node.
3. Application of Clustering Methods to Form the Bidding Zones
3.1. Overview on the Clustering Methods Applied to the Formation of the Bidding Zones and Related Challenges
3.2. General Aspects of the Proposed Procedure and Notation
- (a)
- Variables:
| D | Number of LMP and PTDF initial data for each bus |
| F | Number of input features for clustering (LMP or PTDF). If the input features are LMPs, it corresponds to FLMP. If the input features are PTDFs, it is equal to FPTDF |
| FLMP | Number of LMP input features for clustering |
| FPTDF | Number of PTDF input features for clustering |
| K | Number of centroids |
| N | Number of nodes |
| L | Number of lines |
| S | Number of types of scenarios |
- (b)
- Vectors and matrices:
| A | Node adjacency matrix |
| DLMP | Initial LMP data matrix |
| DPTDF | Initial PTDF data matrix |
| P | Similarity matrix |
| X | Input data matrix for clustering |
| v | Cluster location vector |
| w | Vector containing the weighting factors for the scenarios |
3.3. Input Data Pre-Processing in the Multi-Scenario Clustering
3.4. Multi-Scenario Clustering Methodology
- The bidding zones shall be formed by only interconnected buses.
- Nodes that always belong to the same cluster should be part of the same bidding zone.
- Scenarios with more likelihood of occurrence should have greater impact.
- The number and the likelihood of occurrence of the scenarios are not rigid constraints.
- (1)
- In the first step, a clustering algorithm is executed by considering each scenario individually (the algorithms used in this paper are listed in Table 2).
- (2)
- In the second step, for each pair of nodes, a similarity index is computed on the base of two factors, as shown in Equation (1) for the nodes i and j: (i) the number of times in which the selected nodes belong to the same clusters, and (ii) the likelihood of occurrence of each scenario.where:
- is the similarity index for the nodes i and j;
- is the probability of occurrence of the scenario related to the feature f;
- ;
The indices are collected in the symmetric similarity matrix P, which is a matrix representation of a similarity graph. A value means that the nodes i and j of the similarity graph are not connected.
- (3)
- In the third step, with P as input, the nodes are merged into the desired number of groups running a graph-based clustering algorithm (this paper uses Spectral Clustering [23], with the number of groups as the single input parameter), which allows to handle the topology constraints. Spectral clustering has been applied in to determine areas in the power system on the basis of specific properties (e.g., admittance matrix [24] power flows and line admittances [25], both without referring to the bidding zone formation). In [25], spectral clustering has been used by considering branch-based attributes, taken from the line admittances, as the first stage of the calculations, and has been followed by a second clustering method (with hierarchical clustering). In [26], the spectral clustering has been combined with k-means for determining bottlenecks on the transmission system. In the approach proposed in this paper, the spectral clustering is used as the last step, conversely to what happens in other approaches.
4. Applications and Results
4.1. Italian Network Data
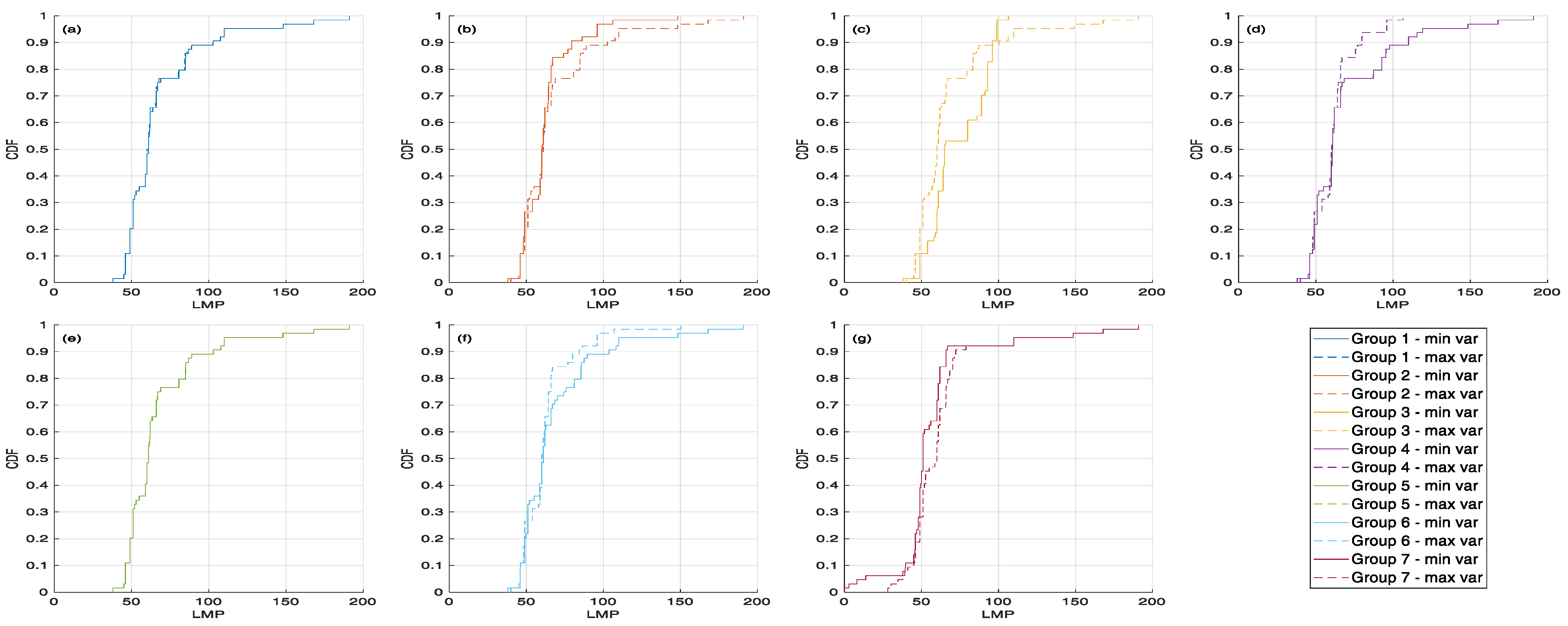
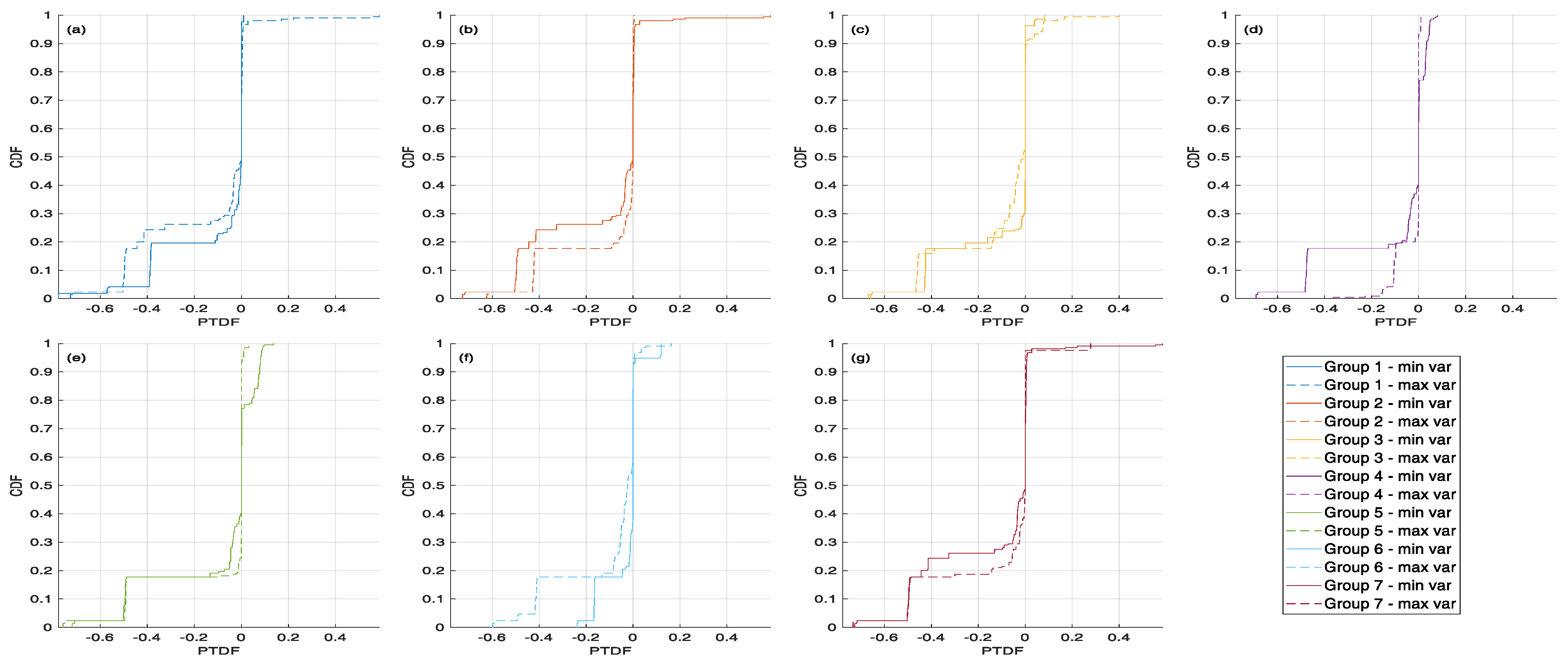
4.2. Input Data and Preliminary Analysis
4.3. Results of the Clustering Procedures
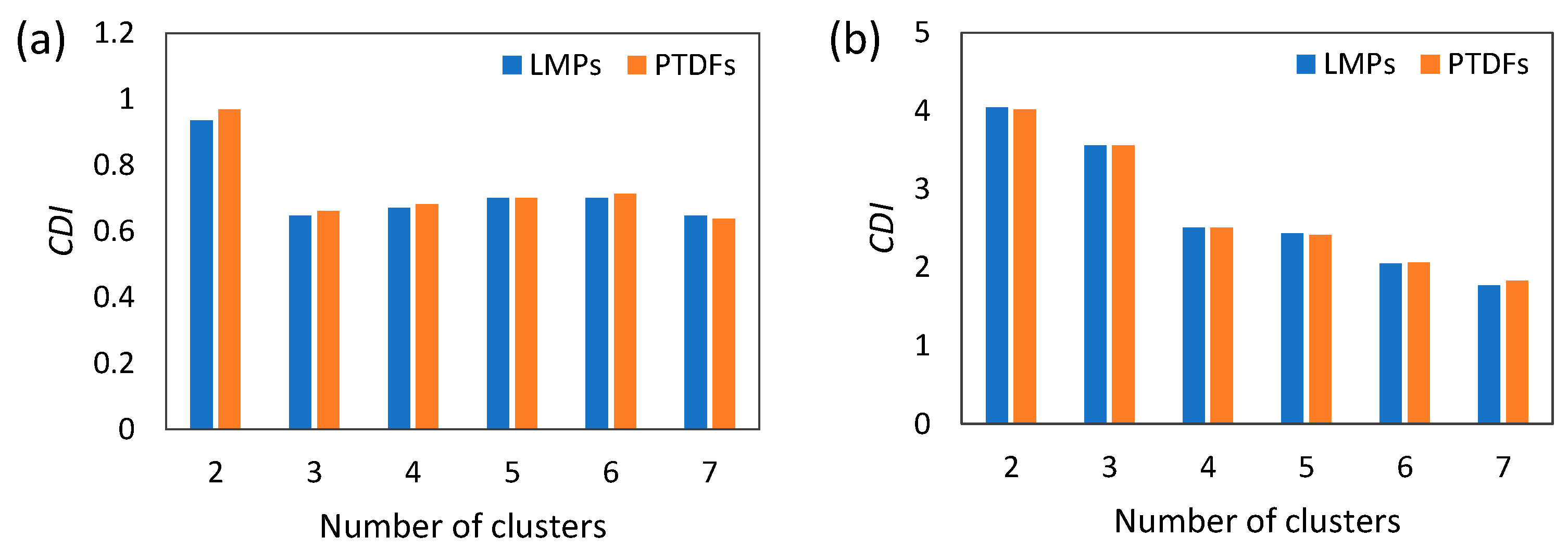
4.4. Assessment of the Clustering Solutions
5. Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
References
- Wolak, F.A. Measuring the Benefits of Greater Spatial Granularity in Short-Term Pricing in Wholesale Electricity Markets. Am. Econ. Rev. 2011, 101, 247–252. [Google Scholar] [CrossRef] [Green Version]
- Joskow, P.L. Challenges for wholesale electricity markets with intermittent renewable generation at scale: The US experience. Oxf. Rev. Econ. Policy 2019, 35, 291–331. [Google Scholar] [CrossRef]
- Pototschnig, A. The Importance of a Sound Bidding-Zone Review for the Efficient Functioning of the Internal Electricity Market; FSR Energy—Florence School of Regulation; European University Institute: Florence, Italy, 2020. [Google Scholar]
- European Commission. Commission Regulation (EU) 2015/1222 of 24 July 2015 Establishing a Guideline on Capacity Allocation and Congestion Management; European Commission: Brussels, Belgium, 2015. [Google Scholar]
- European Commission. Regulation (EU) 2019/943 of the European Parliament and of the Council of 5 June 2019 on the Internal Market for Electricity; European Commission: Brussels, Belgium, 2019. [Google Scholar]
- ARERA. Decision 496/2017/R/EEL “Disposizioni in Merito Alla Revisione Della Suddivisione Della Rete Rilevante in Zone”. ARERA. 2017. Available online: https://www.arera.it/it/docs/17/496-17.htm (accessed on 10 May 2021).
- ARERA. Decision 103/2019/R/EEL “Ulteriori Disposizioni in Merito Alla Suddivisione Della Rete Rilevante in Zone, in Esito al Processo di Revisione Svolto ai Sensi Del Regolamento (UE) 2015/1222 (CACM)”. ARERA. 2019. Available online: https://www.arera.it/it/docs/19/103-19.htm (accessed on 10 May 2021).
- ARERA. Decision 386/2018/R/EEL “Disposizioni in Merito Alla Suddivisione Della Rete Rilevante in Zone, in Esito al Processo di Revisione Svolto ai Sensi Del Regolamento UE 2015/1222 (CACM)”. ARERA. 2018. Available online: https://www.arera.it/it/docs/18/386-18.htm (accessed on 10 May 2021).
- Colella, P.; Mazza, A.; Bompard, E.; Chicco, G.; Russo, A.; Carlini, E.M.; Caprabianca, M.; Quaglia, F.; Luzi, L.; Nuzzo, G. Model-based identification of alternative Bidding Zone Configurations from Clustering Algorithms applied on Locational Marginal Prices. In Proceedings of the 2020 55th International Universities Power Engineering Conference (UPEC), Torino, Italy, 1–9 September 2020. [Google Scholar]
- Wood, A.J.; Wollenberg, B.F. Power Generation, Operation, and Control, 2nd ed.; Wiley-Interscience: New York, NY, USA, 1984. [Google Scholar]
- Chicco, G.; Colella, P.; Griffone, A.; Russo, A.; Zhang, Y.; Carlini, E.M.; Caprabianca, M.; Quaglia, F.; Luzi, L.; Nuzzo, G. Overview of the Clustering Algorithms for the Formation of the Bidding Zones. In Proceedings of the 2019 54th International Universities Power Engineering Conference (UPEC), Bucharest, Romania, 3–6 September 2019; pp. 1–6. [Google Scholar]
- Bovo, C.; Ilea, V.; Carlini, E.M.; Caprabianca, M.; Quaglia, F.; Luzi, L.; Nuzzo, G. Optimal computation of Network indicators for Electricity Market Bidding Zones configuration. In Proceedings of the 2020 55th International Universities Power Engineering Conference (UPEC), Torino, Italy, 1–9 September 2020; pp. 1–6. [Google Scholar]
- First Edition of the Bidding Zone Review—Final Report. 2018. Available online: https://eepublicdownloads.entsoe.eu/clean-documents/news/bz-review/2018-03_First_Edition_of_the_Bidding_Zone_Review.pdf (accessed on 10 May 2021).
- Michi, L.; Quaglia, F.; Bompard, E.; Griffone, A.; Bovo, C.; Carlini, E.M.; Luzi, L.; Chicco, G.; Mazza, A.; Ilea, V.; et al. Optimal Bidding Zone Configuration: Investigation on Model-based Algorithms and their Application to the Italian Power System. In Proceedings of the 2019 AEIT International Annual Conference (AEIT), Florence, Italy, 18–20 September 2019; pp. 1–6. [Google Scholar]
- Griffone, A.; Mazza, A.; Chicco, G. Applications of clustering techniques to the definition of the bidding zones. In Proceedings of the 2019 54th International Universities Power Engineering Conference (UPEC), Bucharest, Romania, 3–6 September 2019; pp. 1–6. [Google Scholar]
- Anderberg, M.R. Cluster Analysis for Applications; New York Academic Press: New York, NY, USA, 1973. [Google Scholar]
- Ward, J.H., Jr. Hierarchical grouping to optimize an objective function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Chicco, G. Overview and performance assessment of the clustering methods for electrical load pattern grouping. Energy 2012, 42, 68–80. [Google Scholar] [CrossRef]
- Wagstaff, K.; Cardie, C.; Rogers, S.; Schroedl, S. Constrained k-means clustering with background knowledge. In Proceedings of the 18th International Conference on Machine Learning, Boca Raton, FL, USA, 16–19 December 2001; Volume 1, pp. 577–584. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Oakland, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Esmaeilian, A.; Kezunovic, M. Prevention of power grid blackouts using intentional islanding scheme. IEEE Trans. Ind. Appl. 2016, 53, 622–629. [Google Scholar] [CrossRef]
- Fouss, F.; Saerens, M.; Shimbo, M. Algorithms and Models for Network Data and Link Analysis; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Hamon, C.; Shayesteh, E.; Amelin, M.; Sӧder, L. Two partitioning methods for multi-area studies in large power systems. Int. Trans. Electr. Energy Syst. 2015, 25, 648–660. [Google Scholar] [CrossRef]
- Sánchez-García, R.J.; Fennelly, M.; Norris, S.; Wright, N.; Niblo, G.; Brodzki, J.; Bialek, J.W. Hierarchical spectral clustering of power grids. IEEE Trans. Power Syst. 2014, 29, 2229–2237. [Google Scholar] [CrossRef] [Green Version]
- Cao, K.-K.; Metzdorf, J.; Birbalta, S. Incorporating power transmission bottlenecks into aggregated energy system models. Sustainability 2018, 10, 1916. [Google Scholar] [CrossRef] [Green Version]
- Chicco, G.; Napoli, R.; Postolache, P.; Scutariu, M.; Toader, C. Customer characterization options for improving the tariff offer. IEEE Trans. Power Syst. 2003, 18, 381–387. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario Type | TSO Weight | Operation or Outage |
|---|---|---|
| S1 | 5% | Planned outage of a 380 kV line on the Adriatic path |
| S2 | 40% | Planned outage of a 380 kV line in the southern part of Italy |
| S3 | 5% | Planned outage of a 380 kV line in the central part of Italy |
| S4 | 20% | Planned outage of a 380 kV line in the northwestern part of Italy |
| S5 | 30% | all network elements are considered fully available |
| Clustering Algorithm | Linkage Criterion | Acronym |
|---|---|---|
| Hierarchical | Average | HC-average |
| Hierarchical | Single | HC-single |
| k-means | KM |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Colella, P.; Mazza, A.; Bompard, E.; Chicco, G.; Russo, A.; Carlini, E.M.; Caprabianca, M.; Quaglia, F.; Luzi, L.; Nuzzo, G. Model-Based Identification of Alternative Bidding Zones: Applications of Clustering Algorithms with Topology Constraints. Energies 2021, 14, 2763. https://doi.org/10.3390/en14102763
Colella P, Mazza A, Bompard E, Chicco G, Russo A, Carlini EM, Caprabianca M, Quaglia F, Luzi L, Nuzzo G. Model-Based Identification of Alternative Bidding Zones: Applications of Clustering Algorithms with Topology Constraints. Energies. 2021; 14(10):2763. https://doi.org/10.3390/en14102763
Chicago/Turabian StyleColella, Pietro, Andrea Mazza, Ettore Bompard, Gianfranco Chicco, Angela Russo, Enrico Maria Carlini, Mauro Caprabianca, Federico Quaglia, Luca Luzi, and Giuseppina Nuzzo. 2021. "Model-Based Identification of Alternative Bidding Zones: Applications of Clustering Algorithms with Topology Constraints" Energies 14, no. 10: 2763. https://doi.org/10.3390/en14102763
APA StyleColella, P., Mazza, A., Bompard, E., Chicco, G., Russo, A., Carlini, E. M., Caprabianca, M., Quaglia, F., Luzi, L., & Nuzzo, G. (2021). Model-Based Identification of Alternative Bidding Zones: Applications of Clustering Algorithms with Topology Constraints. Energies, 14(10), 2763. https://doi.org/10.3390/en14102763