1. Introduction
The world is witnessing the increasing involvement of sensors in human life due to the technological advancements that have been achieved in recent decades. Various arrangements of sensors are serving humankind in the present scenario. Wireless sensor networks can be visualised as various sensing nodes sensing a specified domain, gathering information normally pertaining to environmental changes (movement of human beings, animals or vehicles; temperature changes, etc.) and forwarding it to a central control station, generally referred to as a sink or base station (BS), for decision-making purposes [
1,
2,
3].
Figure 1 shows a typical hierarchical architecture, where sensing nodes collect the data from the environment and forward it to a leader node in the cluster, referred to as a cluster head (CH), which, after aggregation, further forwards it towards the base station. The analysis of data for decision-making purposes is generally performed at the BS level, but some basic computations can also be performed at the CH level or even at the normal sensing node level depending on the approach used [
1,
4].
Inherent to the wireless networks are a few constraints such as limited battery life, bandwidth, memory, processing capabilities, abrupt sensor breakdown or abrupt behaviour, etc., which all need to be efficiently addressed. These networks may be deployed in friendly environments such as homes and offices or may be air-dropped into hostile environments where sometimes it is not possible to replace the batteries of the sensors or calibrate the sensors [
1,
3]. The sensing nodes of WSNs are generally fixed but they may have limited mobility as well, such as sensors floating on water bodies.
Continuing advancements in micro-electro-mechanical systems (MEMS) technology have made it possible to fabricate smaller, inexpensive, energy-efficient sensors with increased memory and increased computational capability [
1,
5,
6,
7] (e.g., Mica motes from Crossbow, Tmote Sky from Moteiv, the MKII nodes from UCLA and SunSpot from Sun), which have further boosted confidence in the use of WSNs. The integration of sensing capabilities, computation and communication into a single unit has also been much refined. This has tempted researchers to analyse the sensors’ data for the purpose of efficient decision-making.
Various methodologies have been adopted in relation to WSNs; of late, many researchers have been tempted to use machine learning (ML) in the context of WSNs [
8,
9]. It provides generalised solutions through an architecture that can learn and improve its performance. The application of ML has led to great improvements in the performance of WSNs. Thus, advancements in machine learning have and are being applied to solve various WSN issues [
10,
11].
Routing strategies also play a key role in the efficient working of WSNs. These strategies in WSNs, on the basis of the network structure, are broadly classified into flat network routing, location-based routing and hierarchical network routing. In flat network routing, all the sensors are uniformly deployed at the same level and each sensor serves as the other’s peer. This can further be divided into proactive or reactive routing [
12]. On the other hand, in the case of location-based routing, the sensors are clustered based on their location in the deployment, which is determined by the received signal strength [
13,
14].
Amongst the three, hierarchical routing protocols have attracted the attention of many researchers as they ensure better energy efficiency [
15,
16]. Here, the protocols arrange the deployed sensors into groups and each group has a designated cluster head (generally the sensor with the maximum energy). The cluster head coordinates with all the nodes inside the group, generally called a cluster, and with the activities outside the cluster, whether communicating with other CHs or the BS.
One of the most prominent hierarchical routing protocols is Low-Energy Adaptive Clustering Hierarchy (LEACH). It has shown great energy efficiency and is the basis of various other subsequent routing protocols [
17]. It makes use of randomisation for the purpose of evenly distributing the energy load across all the sensing nodes and arranges various sensors into groups, where each group has a special sensor behaving as the leader of the group, coordinating the activities of the group. Here, a few sensors designate themselves as cluster heads based on a certain probability and the number of times they have been the cluster head so far. This leader’s role is rotated so that it does not drain any single sensor’s energy [
15].
Since, the deployed battery-operated sensing nodes are energy-constrained, it is important to utilize the energy wisely to extend the network’s lifetime. Moreover, the nodes deployed in hostile environments are very prone to faults, which may be related to a harsh environment, energy depletion or hardware failure. Although it is quite evident that a non-CH faulty node will degrade the network performance, a faulty CH node can be much more problematic, as it will hamper the whole data aggregation and dissemination process of this cluster and will make normal working nodes useless. This paper discusses the basic concept of the hierarchical clustering protocols and proposes a base-station-controlled Fault-tolerant Energy-efficient Hierarchical Clustering Algorithm (FEHCA), which focuses on:
The issue of energy efficient clustering to enhance the network lifetime;
The optimal cluster counts for the network;
The use of k-means clustering that partitions N-nodes into k-clusters, in which each node is associated with the cluster with the nearest mean;
The election of CHs near the centroids of the respective clusters for effective inter-cluster communication;
Minimization of energy dissipation by deferring the re-election of new CHs after each round;
Attempting to make the cluster heads (CHs) fault-tolerant by appointing a secondary cluster head (sCH) in case the current cluster head goes down between two successive rounds.
In essence, this paper proposes a centralised cluster formation technique controlled by the base station (BS), where the deployed sensors are divided into an optimal number of clusters. Once the number of clusters is decided and cluster formation is done, the algorithm, instead of electing any arbitrary CH, as shown in
Figure 2, elects the CH near the centroid of respective clusters. The algorithm has been developed to be fault-tolerant in the context of the CH and does not require re-cluster formation between two successive rounds if the CH is found to be permanently defective.
The work was carried out by considering both friendly and hostile environments; thus, the placement of the BS was assumed to be within the deployment and far away from the hostile environment, respectively. The performance of the network highly depends on the placement of the base station. Suppose that a BS is placed within the monitored area (user-friendly environments such homes and offices, etc.); it will be in close proximity to the cluster heads, as compared to a base station, which is outside the monitored area (generally in the case of hostile deployments such as harsh terrains, border areas, etc.), where most of the cluster heads generally will be at a distance from the base station.
Most of the implementations discuss either friendly environment deployments or hostile environment deployments, but the proposed algorithm was simulated and validated for both scenarios. We also compared our work with some of the state-of-the-art existing technologies with common parameters by positioning the BS within the monitored area. Furthermore, the paper simulates the proposed algorithm in hostile environments by integrating high energy nodes into the network, with the primary aim of keeping the entire monitored area alive for the majority of the lifetime of the network rather than monitoring only the surrounding region after certain rounds of communication, as shown in
Figure 3, and the results are promising.
The rest of the paper is organized as follows.
Section 2 presents a summary of the related work done in this domain, whereas the proposed system model is explained in
Section 3, which includes the network model and energy model for the proposed system.
Section 4 discusses the proposed algorithm for cluster head selection and fault tolerance. Investigational outcomes are discussed in detail in
Section 5, which also contains the comparative study of our algorithm. Finally, the summary and conclusions are presented in
Section 6.
2. Related Work
Clustering and fault tolerance are the focus of various researchers working on wireless senor networks [
3,
18]. Clustering is generally studied as either centralised or distributed [
18]. Centralised clustering involves clustering that is dictated by the base station and the decisions are communicated in the field to the elected CHs; it is generally used in location-aware sensor networks. On the other hand, distributed clustering can be utilised in the case of location-unaware sensor networks, where the sensors are not aware of their relative positioning in the network.
Various hierarchical routing protocols for WSNs have also been presented in the past [
15,
19,
20,
21,
22]. Heinzelman et al. [
15] presented a two-phase (setup phase and steady phase) cluster-based protocol for WSNs, known as Low Energy Adaptive Clustering Hierarchy (LEACH). Though LEACH was one of the earliest clustering protocols and formed the basis for various forthcoming protocols, it has its own share of shortcomings, which have been addressed by various researchers [
23,
24,
25,
26,
27,
28,
29].
Mechta et al. [
30] have proposed a protocol named LEACH-CKM that makes use of k-means classification for grouping the nodes. The proposed protocol is based on Centralised LEACH, where CHs are appointed centrally with the help of the CH’s and sensing node’s local information. LEACH-CKM addresses the node isolation problem where a remote node is not able to communicate with the base station. It utilises a Minimum Transmission Energy routing algorithm for routing the information from remote nodes.
An energy-efficient, fault-tolerant, distributed clustering and routing scheme for wireless sensor networks has been proposed by Azharuddin et al. [
31]. The proposed scheme is a set of two algorithms jointly named Distributed Fault-tolerant Clustering and Routing (DFCR). It makes use of a distributed run time recovery strategy for the sensor nodes in case of unexpected failure of the cluster heads. The scheme is shown to be capable of handling the sensor nodes that do not have any cluster head to be associated with.
In another work, LEACH’s threshold formula has been modified and presented by Xingguo L et al. [
20], where the residual energy is taken into account while selecting a cluster head, as the traditional LEACH does not pay attention to the residual energy of the nodes while choosing the cluster heads, which might lead to a low energy sensor node being elected as the cluster head, which will exhaust early, leading to wastage of resources utilised for cluster head selection. The protocol uses direct BS and CH communication.
Bhatti et al. [
32] have proposed a clustering technique using fuzzy c-means. The paper presents a cluster-based cooperative spectrum sensing scheme to reduce energy consumption and proposes an algorithm that creates clusters and elects the cluster heads in such a way that focuses on both the issues of energy consumption and efficiency in a positive manner. The proposed scheme ensures maximum probability of detection under an imperfect channel, utilising minimal consumption of energy when compared with the conventional clustering approaches.
Further, the role of energy balancing in extending the network lifespan has been explored by Azharuddin et al. [
33]. The authors propose a Particle Swarm Optimization (PSO)-based routing and clustering algorithm for wireless sensor networks, where the routing algorithm creates a balance between energy efficiency and energy balancing. The clustering algorithm is responsible for the CH and normal sensing node’s energy consumption. The proposed algorithms are also sophisticated enough to handle the failure of cluster heads.
A comparison between Particle Swarm Optimisation and Genetic Algorithm when applied to wireless sensor networks for network optimisation has been presented by Parwekar et al. [
34]. It shows how both the algorithms can optimise cluster formation. Their experimental results found that PSO outperformed GA for clustering purposes.
Saveros et al. [
35] have proposed a low-power handover design algorithm for wireless sensor networks (WSNs). The algorithm is designed to place the majority of the scanning responsibility on the mains-powered access points. The proposed algorithm has been implemented and empirically evaluated. The evaluation results show that the energy consumption can be reduced by several orders of magnitude compared to existing algorithms for WSNs.
Nigam, G.K et al. [
36] have pointed out at some of the drawbacks of the LEACH protocol, such as the unnecessary cluster head election after each round, which results in significant energy depletion, discarding the remaining energy of the sensors, non-uniformity of number of cluster heads, etc. The paper proposes an algorithm, namely ESO-LEACH, for addressing some of these issues. It makes use of metaheuristic particle swarm enhancement for the initial clustering of the nodes, introduces the concept of advanced nodes and also takes the residual energy of the nodes into consideration. An enhanced set of rules and a fitness function are also defined for the purpose of cluster head selection. The algorithm demonstrates enhanced network lifetime as compared to conventional LEACH.
Based on the above observations, it seems that there is a need for a centrally administered fault-tolerant and energy-efficient clustering algorithm. In order to achieve this, we have proposed an improved, centrally administered, fault-tolerant and energy-efficient clustering algorithm that is capable of enhancing the energy load balance and able to achieve encouraging results. Therefore, in the next section, a system model is considered for implementing the proposed algorithm.
4. Proposed Algorithm
In the proposed algorithm, the network lifetime is divided into several rounds. The algorithm works in two phases, the setup phase and the steady-state phase, as shown in
Figure 4. In the setup phase, the base station (BS) gathers the energy and location information of the deployed nodes, based on which it clusters the entire region into an optimal number of clusters (7 optimal clusters in our case), as shown in
Figure 5. The BS, after deciding the optimal cluster ratio (
Cr) in the network, performs the clustering using the k-means clustering algorithm [
39]. Once the clusters are determined, the BS elects the CHs at or near the centroid of the clusters, which is followed by the steady-state phase.
In the steady-state phase, when the cluster formation is accomplished, the non-cluster head sensing nodes sense the region and forward the sensed data to the appropriate CHs. The CHs aggregate the data, look for any redundancy and uncorrelated data and send it to the BS in a single hop. For better energy efficiency, the proposed algorithm elects the CHs near the centroid of the cluster and delays the subsequent setup phases, unlike in LEACH, until the residual energy of the current CH ( >= specified threshold energy (), thus conserving energy, as each setup phase consumes a significant amount of energy in exchanging the control packets required for the cluster formation.
Algorithm 1 describes the proposed scheme, followed by Lemma 1′s analysis of its complexity. The clustering and cluster head selection processes used in the proposed algorithm are discussed in the following section.
4.1. Clustering Phase
The proposed algorithm uses a popular unsupervised vector quantisation k-means algorithm to divide the randomly distributed sensors into clusters and performs iterative computations to optimise the centroids. The algorithm tries to minimise the distance between the sensor nodes within the clusters with the respective centroids. FEHCA implements a centralised approach where the BS performs the task of clustering. The BS elects the sensor node nearest to the centroid with energy greater than or equal to the average cluster energy, i.e., Eres >= Cluster_Eavg. Here, the current CH retains its role until its energy falls below the average energy of the cluster. Moreover, the number of clusters to be formed is not changed unless the ideal number of clusters required changes. In essence, the clustering phase is divided into two phases, namely centralised clustering and cluster head selection.
4.2. Centralised Clustering
In centralised clustering, each ith node is represented by Ni, where i ∈ {1, 2, …, n}, and the base station is represented as N+. Therefore, the overall entities participating are N= {N1, N2, …, Nn, N+}. N+, based on the sensor’s location and residual energy, partitions the network into clusters; for this, the proposed scheme makes use of k-means clustering as shown in Algorithm 2. Once the clustering decision is made, N+ conveys the clustering information to the sensing nodes (Ni). N+ elects the CHs and sends the corresponding CH parameters to Ni. On receiving the values from the BS, each node determines whether it is the CH or a normal participating node in the current round. If any node is not selected as a CH in the current round, then the N+ directly transmits the Ni value corresponding to the CH with which that node needs to associate. The k-means clustering initially performs a random partition of the network into centroid based k-clusters; then, it repeatedly performs the task of minimising the distance between each node and the respective centroid. Ultimately, this process ensures that the sensor nodes within the cluster are in close proximity. This leads to reduced energy dissipation and efficient communication of the CH with the member nodes, as well as supporting efficient monitoring of the cluster.
4.3. Cluster Head Selection
In this process, the BS (N
+) elects the CHs based on the distance from the centroid and the specified energy requirements, and it communicates the N
i value corresponding to the selected CH to the participating nodes in the network. If the received N
i value corresponds to the value of the receiving node, then the recipient recognises itself as the CH and creates and broadcasts to its member nodes for the coordination of the data transmission in the specified schedule. Otherwise, if the N
i value does not correspond to the value of the receiving node, then it recognises itself as a normal member node of the cluster, sends a cluster joining request to the CH whose N
i value it has received from N
+ and subsequently waits for the schedule to be generated by its CH. Once this process is completed, each member node in the cluster transmits the sensed data and the corresponding residual energy to the respective CH as per the received schedule. Between the subsequent transmission schedule, the sensor switches off the radios to conserve the energy. The CH compares its energy with the average energy of the cluster and communicates this information to the BS. If its energy is greater than or equal to the average energy of the cluster, then it remains the CH; otherwise, the BS elects a new CH by considering the residual energy and the distance from the centroid in the next round. New CHs are elected from the sensors within the current clusters only, and new clusters are created only when the ideal number of clusters to be formed is changed (depending on the C
r). The cluster head election in FEHCA is shown in Algorithm 1 which has a worst-case time complexity of O (Cn
2 + Cn CN
2 log CN) and is discussed in Lemma 1.
| Algorithm 1. Cluster head election in FEHCA. |
| Input: |
| alive nodes with co-ordinates |
| : initial energy |
| n: number of alive nodes |
| Cr: Optimal cluster ratio |
| Output: |
| where CH represents cluster heads |
| Procedure: |
| 1: | |
| //Number of clusters in the network |
| 2: | |
| //Calculating cluster(s) centroid, and |
| respective participating members |
| 3: | |
| //For finding the minimum distance node |
| in a cluster |
| 4: | |
| 5: |
//For all nodes in a cluster |
| 6: | |
| 7: | |
| 8: | |
| 9: | |
| 10: | |
| 11: | |
| 12: |
//CH is elected cluster head |
| 13: | |
| 14: | |
| 15: | |
| Algorithm 2. K-Means algorithm. |
Input:
alive nodes with co-ordinates
represents number of clusters in the network
is number of alive nodes
Output: |
| Procedure: |
| 1: |
|
| 2: | |
| 3: | |
| 4: | |
| 5: | |
| 6: | |
| 7: | |
| 8: | |
| 9: | |
| 10: | |
| 11: |
//distance computation |
| 12: |
//reassignment of vectors |
| 13: | |
| 14: | |
| 15: |
//recompilation of centroids |
| 16: | |
| 17: | |
| 18: | |
Generally, the network lifetime is considered till the last cluster head is able to communicate with the base station; once the base station stops receiving the sensed data of the region, the network is assumed to be exhausted. Though this is a valid way of computing the lifetime of a network, it does not give a true picture of the sensed region. This is because, initially, the BS receives sensed values from the entire region being monitored but, as the time elapses, the CHs far away from the BS start dying earlier than the CHs near the BS (in the case of direct non-multi-hop networks) and, as the time elapses, only the CHs near the BS are able to communicate, as depicted in
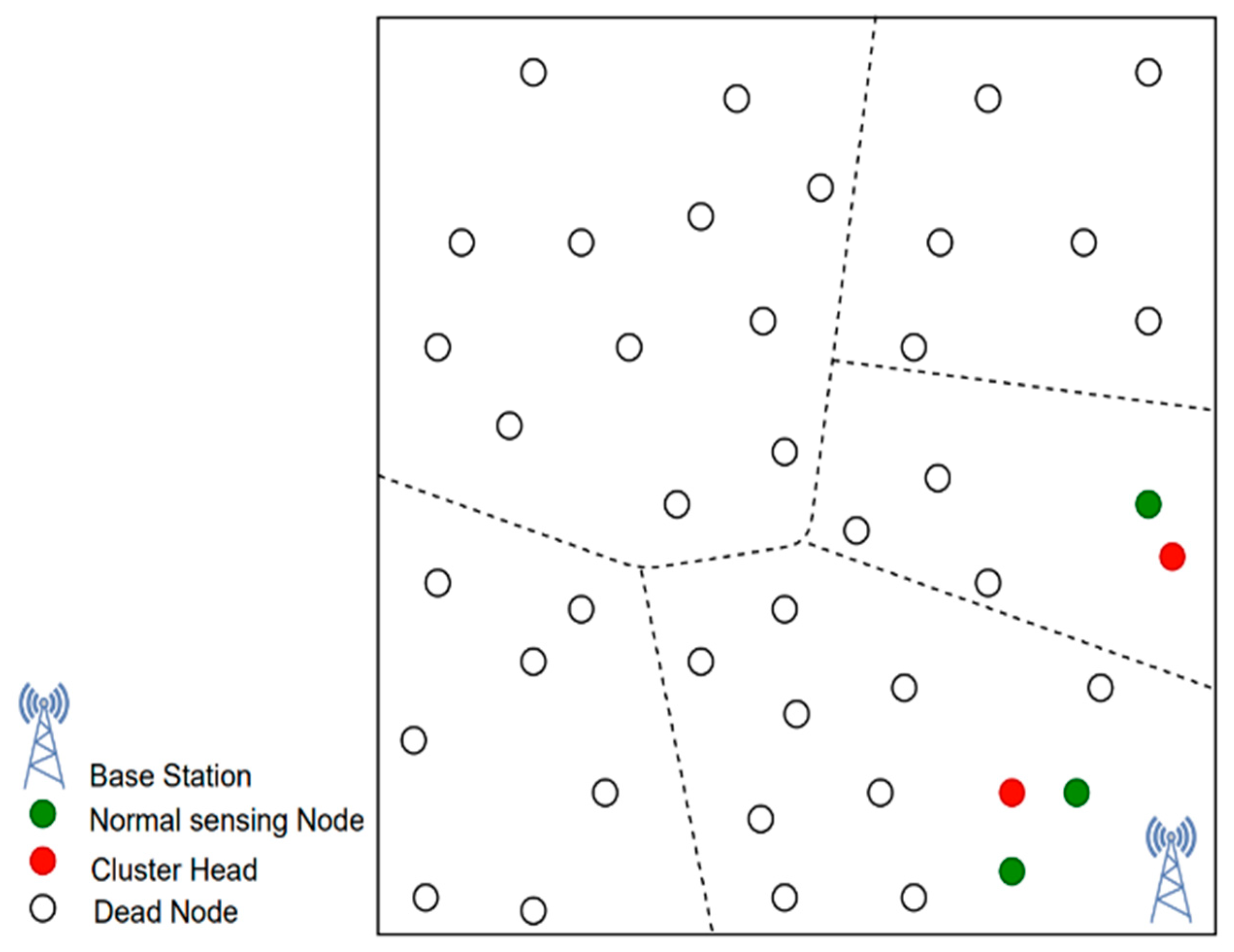
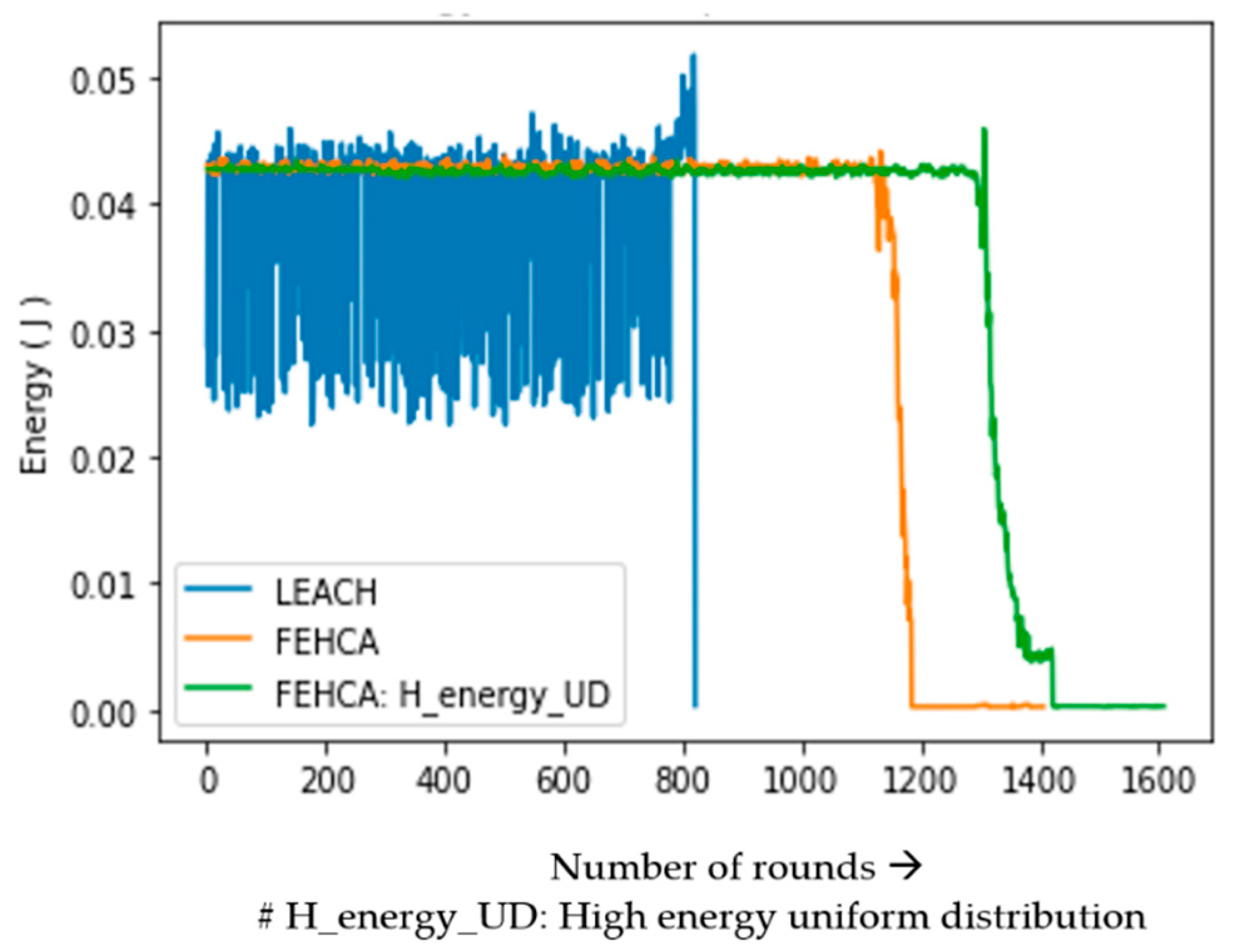
Figure 3, this fact is later validated in the results analysis section. Then, based on the nearby cluster readings, the BS is forced to either made decisions for the entire monitored area (which is not justified) or make decisions for only the areas from which it can communicate and preserving the rest of the area for further monitoring. The same issue occurs when CHs transmit multi-hop data to the BS, with the exception that CHs closer to the BS wear out faster than CHs farther away due to the overhead of transmitting the additional packets from faraway nodes to the BS.
This is taken into account by the proposed algorithm (FEHCA), which focuses on controlling the entire region for almost the entire network lifespan. It demonstrates the inclusion of advanced nodes within the clusters in uniform fashion (in case the BS is within the deployment zone) as well as in increasing fashion when the distance between the cluster and BS increases (in case the BS is far away from the deployment zone). This is crucial in order to monitor a larger area rather than only monitoring clusters in close proximity to the BS for most of the time and making decisions for the entire area based solely on inputs from neighbouring CHs only. With or without the same number of high energy nodes, the CHs far away from the BS die out early and only the CHs and the clusters near the BS remain alive for a longer period of time. We need sensed data from the entire area being monitored for better decision-making, which means that the CHs of the entire area must be alive, and one way to achieve this is to deploy advanced nodes in increasing order as the distance from the BS increases.
If two CHs are at different distances from the BS, then the transmission energy consumption must be different according to Equation (1). Therefore, in order to equate the transmissions of both the CHs to the BS, we require additional energy for the distant CH. The computation of the additional amount of energy is given in Lemma 2.
Lemma 1. The cluster head election in FEHCA has a worst-case time complexity of O (Cn2 + Cn CN2 log CN).
Proof: The major components in the FEHCA algorithm that dominate the complexity from Step 2 and Steps 3 to 15. As in Step 2, we use the k-means algorithm, which has a complexity of O (CN). Steps 3 to 15 mainly consist of two parts. For Part 1 (Steps 5 to 8), the complexity of this part is O (CN). For Part 2 (Steps 10 to 14), in Step 12, we have used a sorting technique, which has a time complexity of O (CN log CN). Thus, the complete Steps 10 to 14 have a time complexity of O (CN2 log CN). Therefore, the time complexity from Steps 3 to 15 is O (Cn2) + O (Cn CN2 log CN). Now, the overall complexity of Algorithm 1 is O (Cn2) + O (Cn CN2 log CN) + O (CN) ≈ O (Cn2+ Cn CN2 log CN). □
Lemma 2. Let the energy requirement for the transmission of k-bits from a cluster head (CH) to the base station (BS) in the case of a multipath be where ‘d’ is the distance between BS and a CH. If the distance between two CHs (CH1 and CH2) from the BS is d1 and d2 such that d2>d1, then, in order to equate the transmissions of CH1 and CH, we need additional energy for CH2, which is given by
where
is the initial energy with CH
1 and CH
2.
Proof. The energy requirement for transmitting k-bits over the distance d as discussed in Equation (1) is given by:
Since
is a strictly increasing function over ‘d’,
for given d
2 > d
1. Now, using Equation (3), we obtain
Reversing the inequality in Equation (4) produces
Further, multiplying
in (5), we obtain
Then, equating Equation (6), we obtain
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}