
Evaluation of Supervised Learning Models in Predicting Greenhouse Energy Demand and Production for Intelligent and Sustainable Operations


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Sets
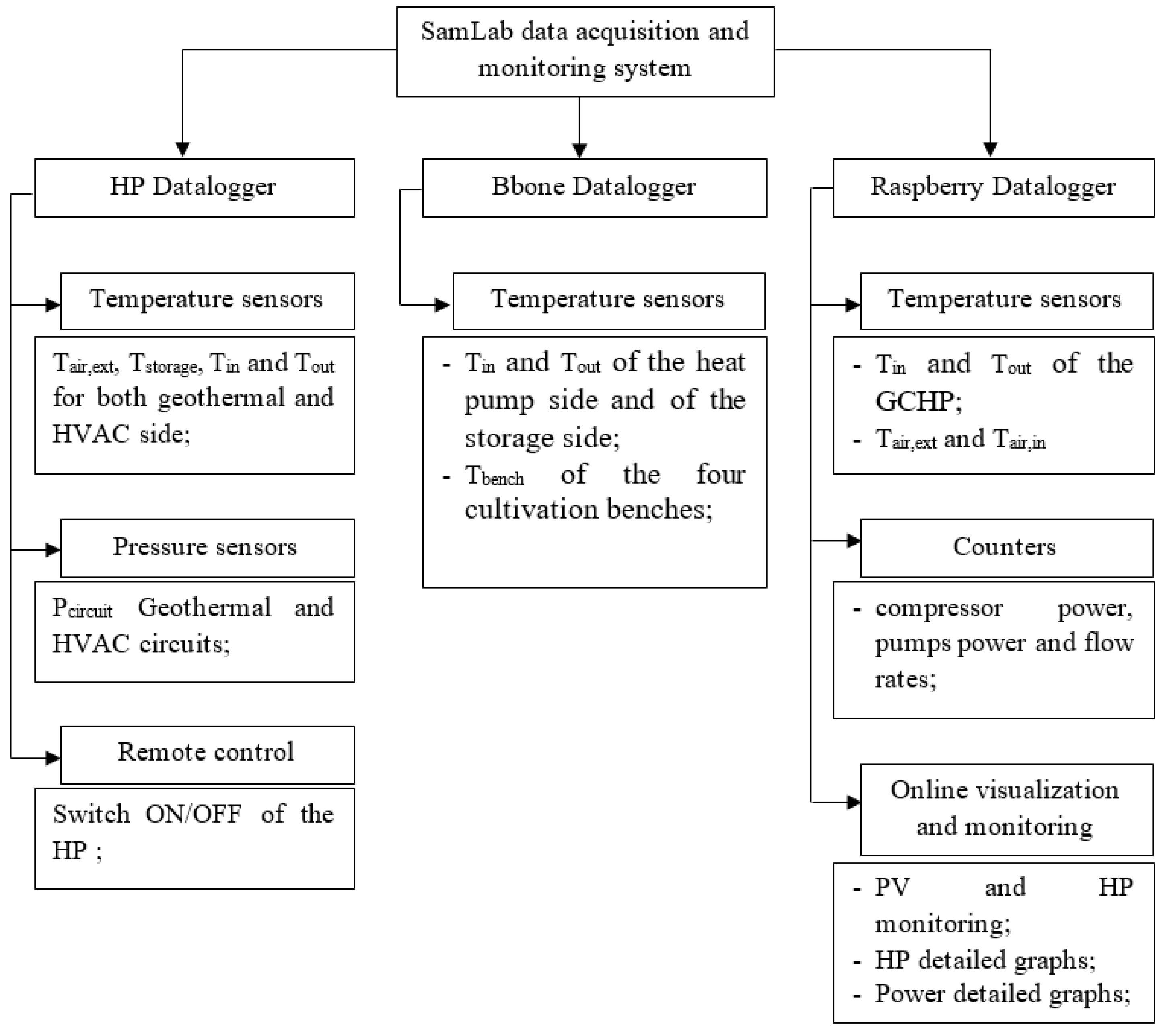
2.2. Data Acquisition
2.3. Description of the Models
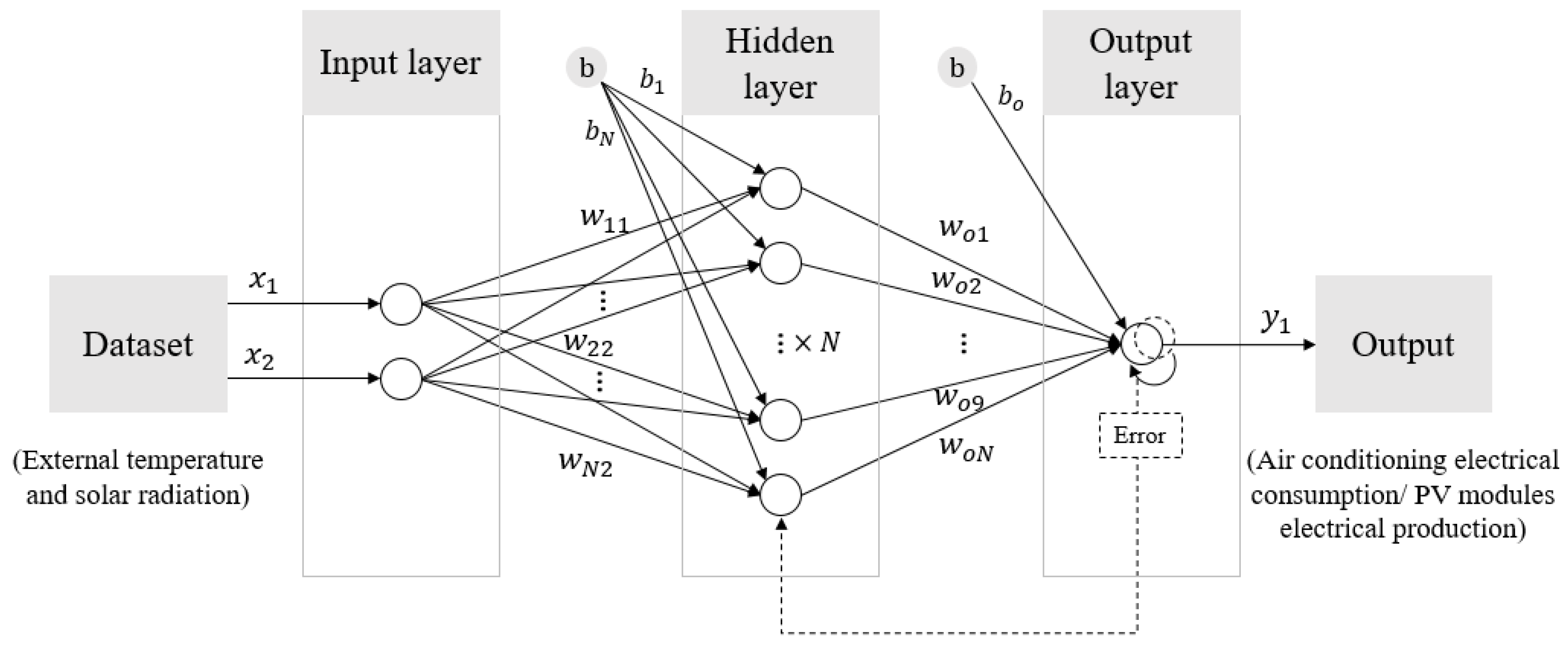
2.3.1. Artificial Neural Networks, ANNs
2.3.2. Gaussian Process Regression, GPR
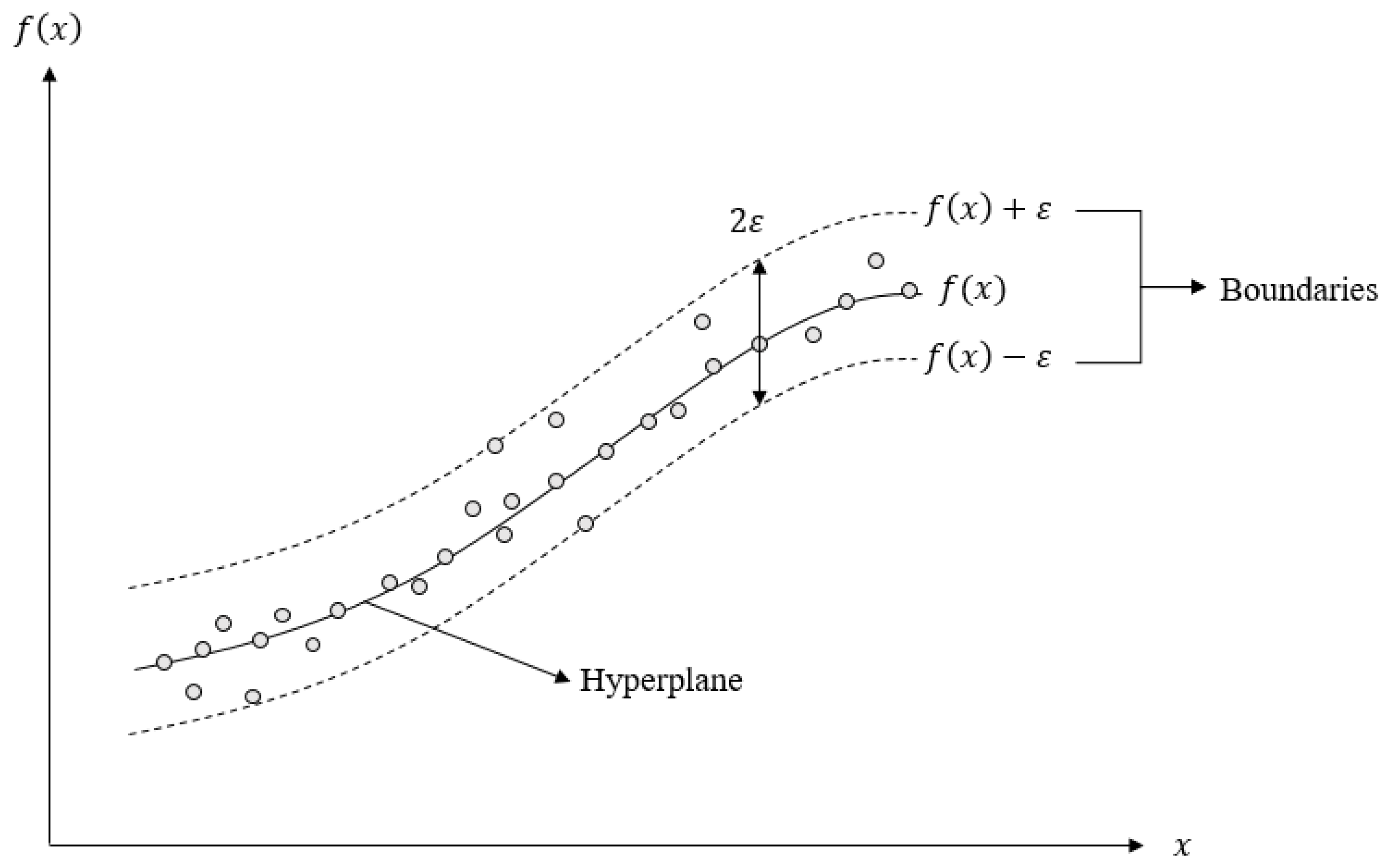
2.3.3. Support Vector Machine SVM
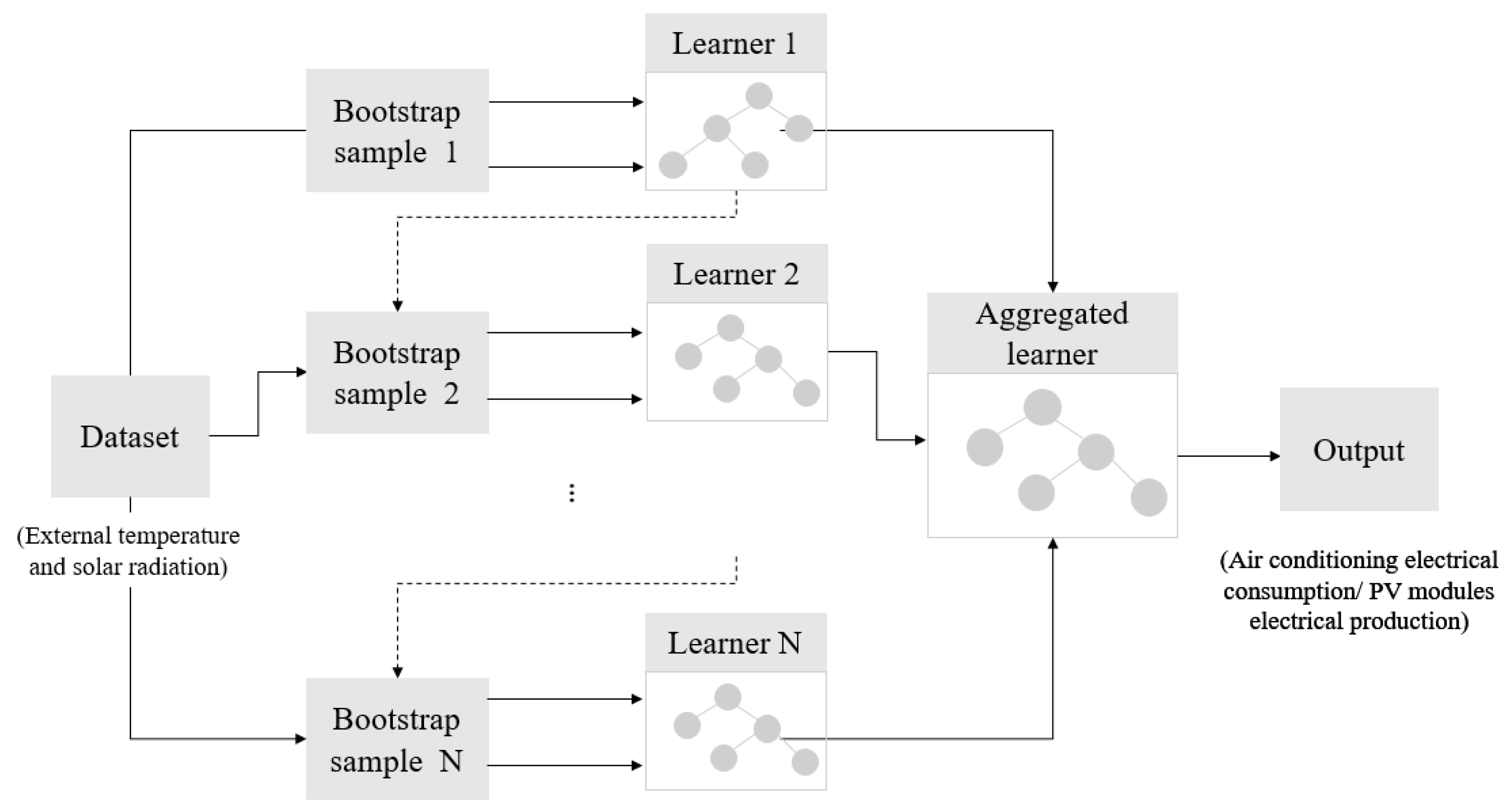
2.3.4. Boosting
2.4. Performance Analysis
3. Results and Discussions
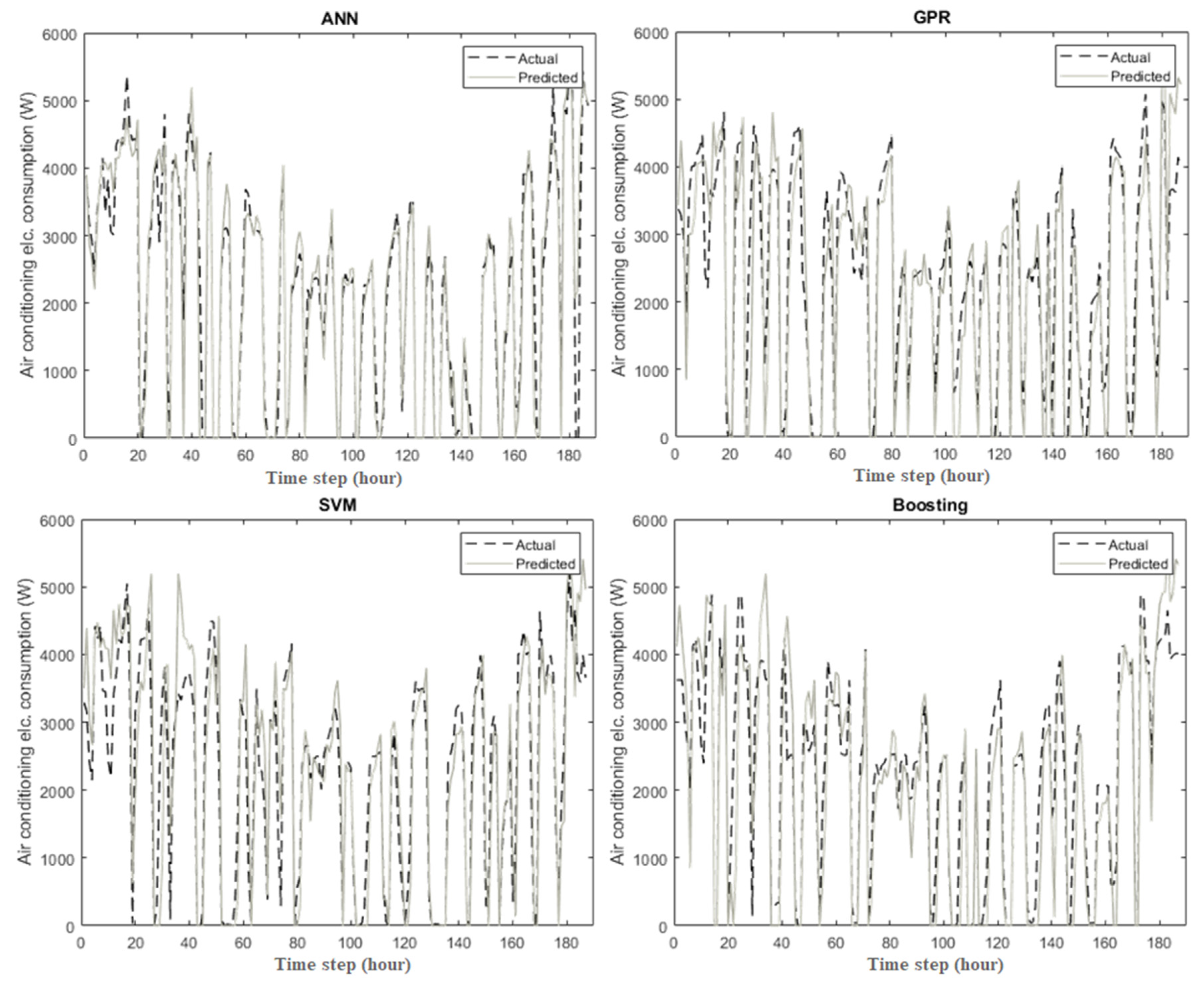
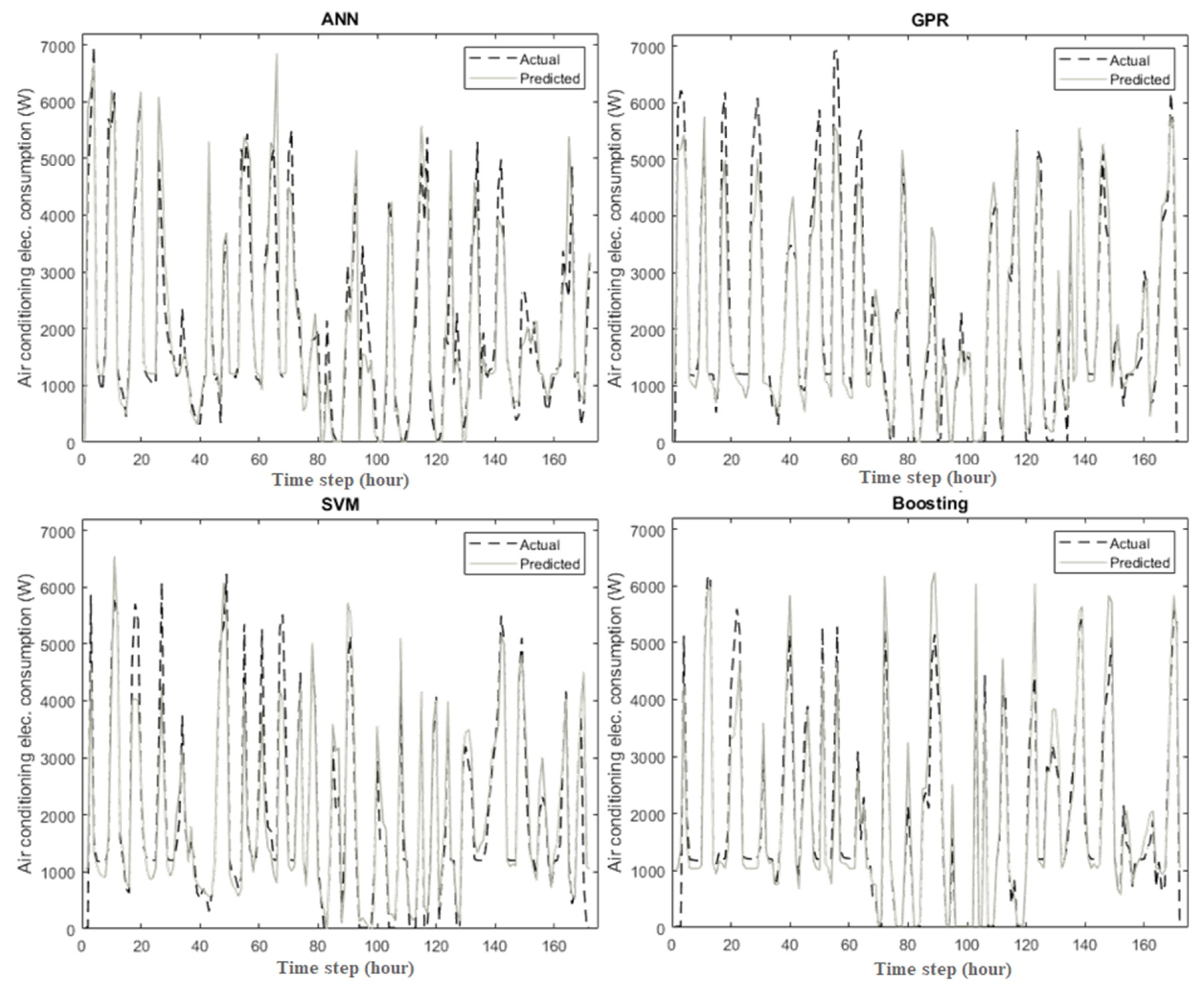
3.1. Prediction of the Air Conditioning Electrical Consumption
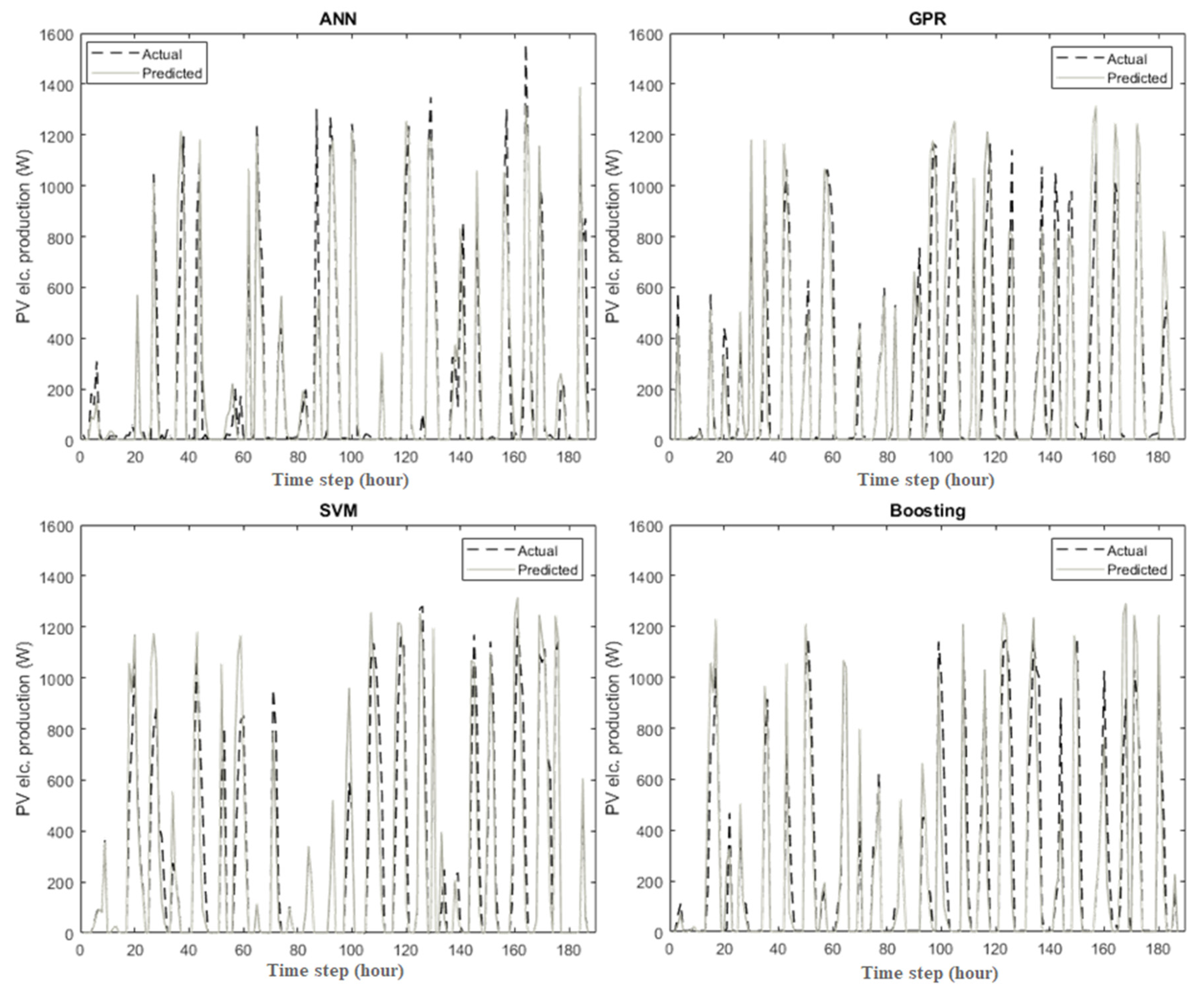
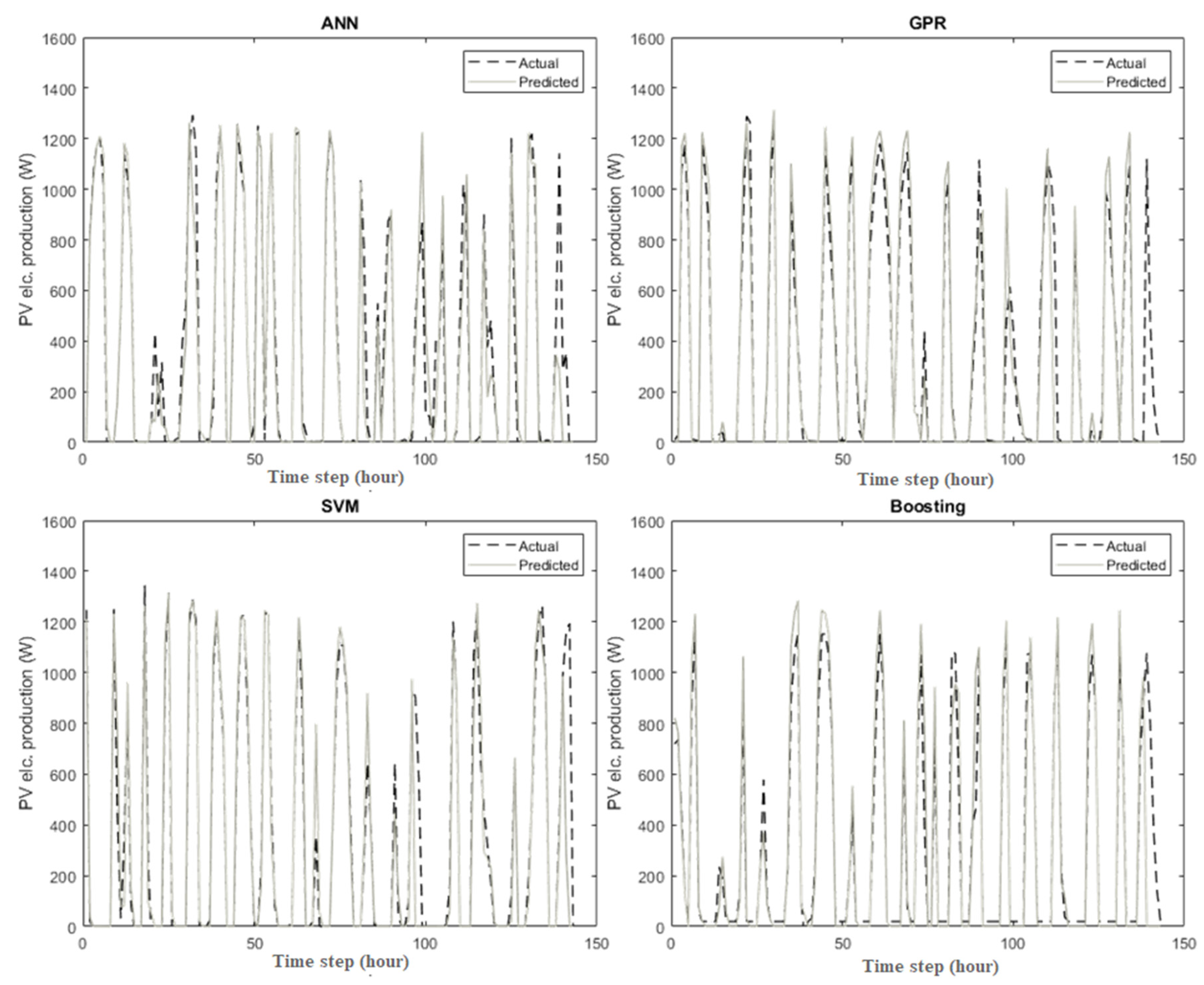
3.2. Prediction of PV Module Electrical Production
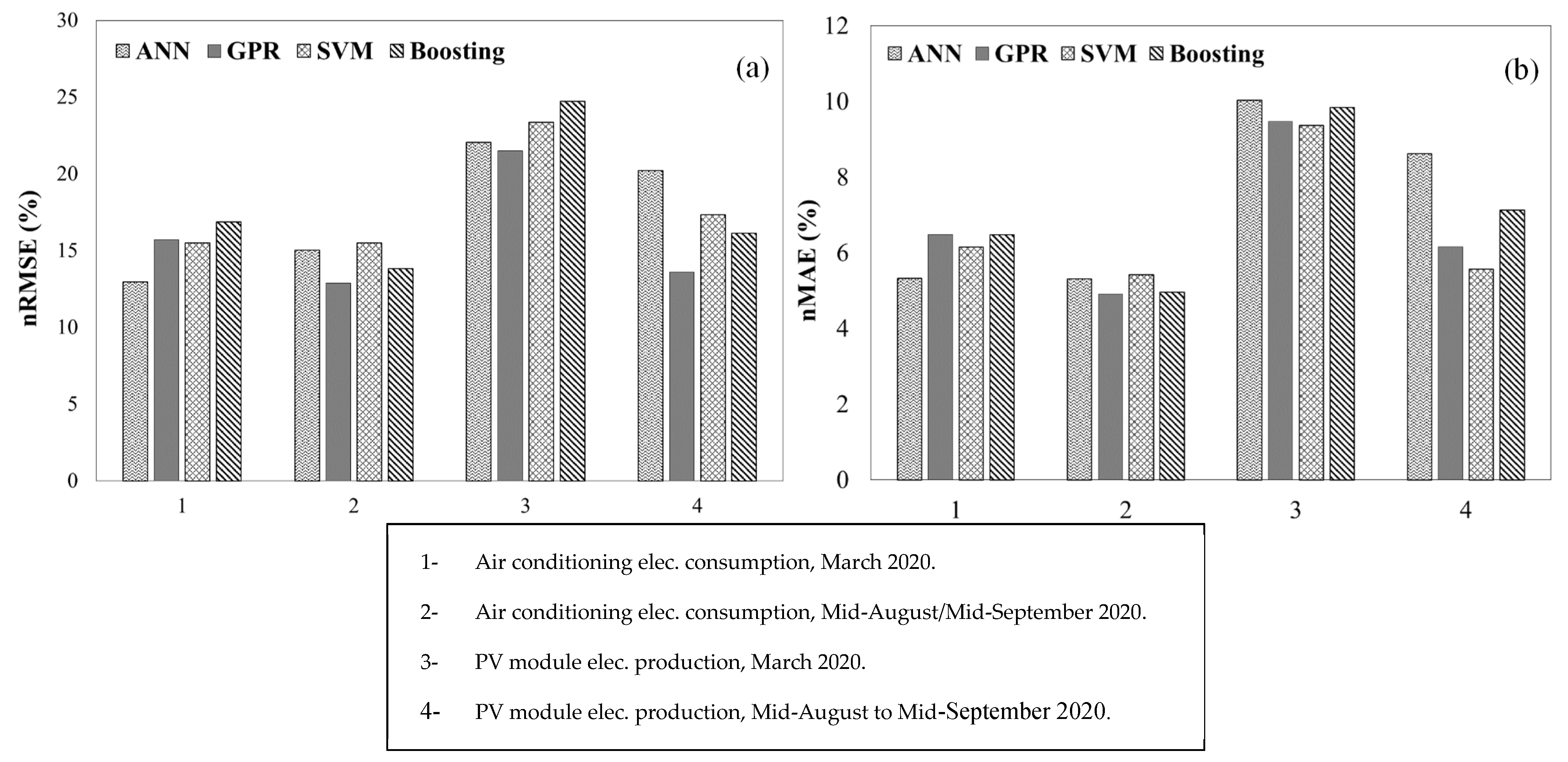
3.3. Comparison and Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| ANN | Artificial Neural Network |
| Bias | |
| Residuals | |
| GPR | Gaussian Process Regression |
| HVAC | Heating, Ventilation and Air Conditioning |
| Kernel function | |
| Measured | |
| ML | Machine learning |
| Normalized mean absolute error | |
| Normalized root mean square error | |
| Predicted | |
| Coefficient of correlation | |
| SamLab | Smart Agro-Manufacturing laboratory |
| SVM | Support Vector Machine |
| Weight | |
| Inputs | |
| Outputs | |
| Greek letters | |
| Deficiency of the model | |
| Covariance noise |
References
- Savvas, D.; Gianquinto, G.P.; Tüzel, Y.; Gruda, N. Good Agricultural Practices for Greenhouse Vegetable Crops. Principles for Mediterranean Climate Areas. FAO Plant Production and Protection Paper 217; Food and Agriculture Organization: Rome, Italy, 2013; ISBN 9789251076491. [Google Scholar]
- Talaviya, T.; Shah, D.; Patel, N.; Yagnik, H.; Shah, M. Implementation of Artificial Intelligence in Agriculture for Optimisation of Irrigation and Application of Pesticides and Herbicides. Artif. Intell. Agric. 2020, 4, 58–73. [Google Scholar] [CrossRef]
- Jha, K.; Doshi, A.; Patel, P.; Shah, M. A Comprehensive Review on Automation in Agriculture Using Artificial Intelligence. Artif. Intell. Agric. 2019, 2, 1–12. [Google Scholar] [CrossRef]
- Patrício, D.I.; Rieder, R. Computer Vision and Artificial Intelligence in Precision Agriculture for Grain Crops: A Systematic Review. Comput. Electron. Agric. 2018, 153, 69–81. [Google Scholar] [CrossRef] [Green Version]
- Pantazi, X.E.; Moshou, D.; Bochtis, D. Artificial intelligence in agriculture. In Intelligent Data Mining and Fusion Systems in Agriculture; Elsevier: Amsterdam, The Netherlands, 2020; pp. 17–101. [Google Scholar]
- Pahlavan, R.; Omid, M.; Akram, A. Energy Input-Output Analysis and Application of Artificial Neural Networks for Predicting Greenhouse Basil Production. Energy 2012, 37, 171–176. [Google Scholar] [CrossRef]
- He, F.; Ma, C. Modeling Greenhouse Air Humidity by Means of Artificial Neural Network and Principal Component Analysis. Comput. Electron. Agric. 2010, 71, S19–S23. [Google Scholar] [CrossRef]
- Uchida Frausto, H.; Pieters, J.G. Modelling Greenhouse Temperature Using System Identification by Means of Neural Networks. Neurocomputing 2004, 56, 423–428. [Google Scholar] [CrossRef] [Green Version]
- Taki, M.; Abdanan Mehdizadeh, S.; Rohani, A.; Rahnama, M.; Rahmati-Joneidabad, M. Applied Machine Learning in Greenhouse Simulation; New Application and Analysis. Inf. Process. Agric. 2018, 5, 253–268. [Google Scholar] [CrossRef]
- Yu, H.; Chen, Y.; Hassan, S.G.; Li, D. Prediction of the Temperature in a Chinese Solar Greenhouse Based on LSSVM Optimized by Improved PSO. Comput. Electron. Agric. 2016, 122, 94–102. [Google Scholar] [CrossRef]
- Zou, W.; Yao, F.; Zhang, B.; He, C.; Guan, Z. Verification and Predicting Temperature and Humidity in a Solar Greenhouse Based on Convex Bidirectional Extreme Learning Machine Algorithm. Neurocomputing 2017, 249, 72–85. [Google Scholar] [CrossRef]
- Samlab. Available online: http://samlab.dibris.unige.it/ (accessed on 12 December 2019).
- Ouazzani Chahidi, L.; Fossa, M.; Priarone, A.; Mechaqrane, A. Energy Saving Strategies in Sustainable Greenhouse Cultivation in the Mediterranean Climate—A Case Study. Appl. Energy 2021, 282, 116156. [Google Scholar] [CrossRef]
- Ambiente in Liguria: Meteo. Available online: http://www.cartografiarl.regione.liguria.it/SiraQualMeteo/script/PubAccessoDatiMeteo.asp (accessed on 30 April 2021).
- Theodoridis, S. Chapter 18—Neural Networks and Deep Learning. In Machine Learning; Theodoridis, S., Ed.; Academic Press: Oxford, UK, 2015; pp. 875–936. ISBN 978-0-12-801522-3. [Google Scholar]
- Williams, C.K.I. Prediction with Gaussian Processes: From Linear Regression to Linear Prediction and Beyond. In Learning in Graphical Models; Jordan, M.I., Ed.; NATO ASI Series; Springer: Dordrecht, The Netherlands, 1998; pp. 599–621. ISBN 978-94-011-5014-9. [Google Scholar]
- Rasmussen, C.E. Gaussian Processes in Machine Learning. In Advanced Lectures on Machine Learning: ML Summer Schools 2003, Canberra, Australia, February 2–14, 2003, Tübingen, Germany, August 4–16, 2003, Revised Lectures; Bousquet, O., von Luxburg, U., Rätsch, G., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, German, 2004; pp. 63–71. ISBN 978-3-540-28650-9. [Google Scholar]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.; Vapnik, V. Support Vector Regression Machines. Adv. Neural Inf. Process. Syst. 1997, 9, 155–161. [Google Scholar]
- Awad, M.; Khanna, R. (Eds.) Support Vector Regression. In Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers; Apress: Berkeley, CA, USA, 2015; pp. 67–80. ISBN 978-1-4302-5990-9. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a New Boosting Algorithm. In Machine Learning: Proceedings of the Thirteenth International Conference, Bari, Italy, 3–6 July, 1996; Citeseer: University Park, PA, USA, 1996; Volume 96, pp. 148–156. [Google Scholar]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Sobri, S.; Koohi-Kamali, S.; Rahim, N.A. Solar Photovoltaic Generation Forecasting Methods: A Review. Energy Convers. Manag. 2018, 156, 459–497. [Google Scholar] [CrossRef]
- Bounoua, Z.; Ouazzani Chahidi, L.; Mechaqrane, A. Estimation of Daily Global Solar Radiation Using Empirical and Machine-Learning Methods: A Case Study of Five Moroccan Locations. Sustain. Mater. Technol. 2021, 28, e00261. [Google Scholar] [CrossRef]
- Li, M.-F.; Tang, X.-P.; Wu, W.; Liu, H.-B. General Models for Estimating Daily Global Solar Radiation for Different Solar Radiation Zones in Mainland China. Energy Convers. Manag. 2013, 70, 139–148. [Google Scholar] [CrossRef]
- Despotovic, M.; Nedic, V.; Despotovic, D.; Cvetanovic, S. Evaluation of Empirical Models for Predicting Monthly Mean Horizontal Diffuse Solar Radiation. Renew. Sustain. Energy Rev. 2016, 56, 246–260. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Output | Period | Model | Training | Validation | |||||
|---|---|---|---|---|---|---|---|---|---|
| (%) | (%) | ||||||||
| Air conditioning electrical consumption | March 2020 | ANN | 2-10-1 | 97.8712 | 18.8831 | 10.8624 | 92.4610 | 12.9642 | 5.321 |
| GPR | 91.2684 | 24.4969 | 15.0304 | 91.5676 | 15.7289 | 6.4811 | |||
| SVM | 91.0673 | 24.0926 | 13.8872 | 90.7590 | 15.4800 | 6.1483 | |||
| Boosting | 36 learners | 91.6594 | 22.6429 | 13.6338 | 91.1679 | 16.8750 | 6.4712 | ||
| Mid-August/Mid-September 2020 | ANN | 2-10-1 | 97.6209 | 24.9683 | 13.6470 | 95.0121 | 15.0257 | 5.3083 | |
| GPR | 96.3606 | 19.6298 | 10.5916 | 96.2057 | 12.8562 | 4.9058 | |||
| SVM | 95.5177 | 22.3990 | 13.0860 | 94.0457 | 15.4998 | 5.4185 | |||
| Boosting | 10 learners | 97.7934 | 15.3439 | 8.6856 | 95.9600 | 13.8336 | 4.9534 | ||
| Output | Period | Model | Training | Validation | |||||
|---|---|---|---|---|---|---|---|---|---|
| (%) | (%) | ||||||||
| PV module electrical production | March 2020 | ANN | 2-10-1 | 97.3864 | 33.1328 | 20.9550 | 96.3285 | 22.0497 | 10.0231 |
| GPR | 92.6129 | 42.7174 | 21.9205 | 92.3836 | 21.4978 | 9.4679 | |||
| SVM | 92.7159 | 42.7893 | 20.7340 | 91.2903 | 23.3442 | 9.3637 | |||
| Boosting | 39 learners | 94.1176 | 35.9266 | 19.7293 | 91.8845 | 24.7175 | 9.8309 | ||
| Mid-August/Mid-September 2020 | ANN | 2-10-1 | 97.6136 | 30.0094 | 16.1551 | 96.1150 | 20.2251 | 8.6132 | |
| GPR | 95.0153 | 24.9565 | 13.9918 | 94.2151 | 13.6115 | 6.1538 | |||
| SVM | 95.3025 | 23.6884 | 12.2957 | 93.5519 | 17.3420 | 5.5604 | |||
| Boosting | 36 learners | 95.6063 | 21.5596 | 13.7941 | 94.1332 | 16.1418 | 7.1238 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ouazzani Chahidi, L.; Fossa, M.; Priarone, A.; Mechaqrane, A. Evaluation of Supervised Learning Models in Predicting Greenhouse Energy Demand and Production for Intelligent and Sustainable Operations. Energies 2021, 14, 6297. https://doi.org/10.3390/en14196297
Ouazzani Chahidi L, Fossa M, Priarone A, Mechaqrane A. Evaluation of Supervised Learning Models in Predicting Greenhouse Energy Demand and Production for Intelligent and Sustainable Operations. Energies. 2021; 14(19):6297. https://doi.org/10.3390/en14196297
Chicago/Turabian StyleOuazzani Chahidi, Laila, Marco Fossa, Antonella Priarone, and Abdellah Mechaqrane. 2021. "Evaluation of Supervised Learning Models in Predicting Greenhouse Energy Demand and Production for Intelligent and Sustainable Operations" Energies 14, no. 19: 6297. https://doi.org/10.3390/en14196297