Abstract
This research mainly studies the factors influencing the efficiency of energy utilization. Firstly, by calculating and local indicators of spatial association (LISA) of energy efficiency of regions in mainland China, we found that energy efficiency shows obvious spatial autocorrelation and spatial clustering phenomena. Secondly, we established the spatial quantile autoregression (SQAR) model, in which the energy efficiency is the response variable with seven influence factors. The seven factors include industrial structure, resource endowment, level of economic development etc. Based on the provincial panel data (1998–2016) of mainland China (data source: China Statistical Yearbook, Statistical Yearbook of provinces), the findings indicate that level of economic development and industrial structure have a significant role in promoting energy efficient. Resource endowment, government intervention and energy efficiency show a negative correlation. However, the negative effect of government intervention is weakened with the increase of energy efficiency. Lastly, we compare the results of SQAR with that of ordinary spatial autoregression (SAR). The empirical result shows that the SQAR model is superior to SAR model in influencing factors analysis of energy efficiency.
1. Introduction
With the rapid development of the global economy, energy demand and consumption are increasing extensively, which has also brought some problems, such as environmental pollution, global warming, excessive exploitation of resources etc. For sustainable economic development and social progress, it is very important to improve energy efficiency and formulate relevant policies. There are some studies focused on how to put the energy system onto a more sustainable path from a macro perspective. See for example [1,2,3,4,5] and references therein.
The reasonable calculation method of energy utilization efficiency and quantitative analysis of influence factors are necessary and important for policymakers. Tobler, an American geographer in [6] proposed that everything is related to everything else, but near things are more related to each other, which is also known as Tobler’s First Law of Geography. The energy efficiency of one region also can be influenced by neighboring regions. Some studies showed the spatial auto-correlation and clustering phenomenon of energy efficiency. For example, Shen and Liu [7] used the data envelopment analysis (DEA) model to measure the energy efficiency values of 30 provinces in China from 1992 to 2007. The result shows that there are obvious spatial aggregation phenomena in provincial energy efficiency.
Concerning research on influence factors of energy efficiency, there are some literatures, for example [7,8,9,10,11,12,13,14,15] etc. Shen and Liu [7] studied influence factors by using SAR and threshold regression models. Liu and Mao [10] studied the factors influencing energy efficiency by using a spatial lagged model (SLM, also called SAR in literature) and spatial error model (SEM) based on the data of 29 provinces and cities in China from 2000 to 2012. They did not consider the test of homoscedasticity of explanatory variables, which is required before building SLM and SEM. Makridou et al. (2016) [8] analyzed the energy efficiency of five energy-intensive industries in 23 European Union countries by using a two-level cross-classified model. Li and Shi (2014) in [9] proposed an improved super-SBM (slacks-based measure) model to analyze the energy efficiency of Chinese industrial sectors. Jiang et el. [12] analyzed energy efficiency of provinces in China by using the ordinary spatial Dubin error model for panel data. Li and Lin (2018) [13] studied the direct and indirect effects of different types of technological progress on China’s energy efficiency.
To the best of our knowledge, existing references about influence factors of energy efficiency used ordinary regression without considering different quantiles. However, the ordinary regression model characterizes the relationship between the expectation of the explained variable and explanatory variables, which is not robust to outliers. To this end, the quantile regression model is a good way to deal with outliers, which can describe more detail of data. Since Koenker and Bassett [16] proposed the quantile regression method in 1978, the quantile idea has been widely used and developed (see e.g., [17,18]).
The purpose of this work is to analyze the factors influencing the efficiency of energy utilization based on the spatial quantile autogression model, so as to provide some advice on how to improve energy efficiency for decision-makers. As far as we know, the SQAR model has not been employed in existing references related to this topic. Why do we use quantiles? Quantile regression is robust to outliers. By considering different quantiles, we can get different coefficients of factors, which can reveal the relationship between factors and energy efficiency more comprehensively. Based on the work [19], we combine spatial autoregression with quantiles to study factors influencing the efficiency of energy. Firstly we analyze the ([20]), local indicators of spatial association (LISA) of provincial energy efficiencies of China. The data set for empirical analysis comes from China Statistical Yearbook, Statistical Yearbook of provinces and http://data.stats.gov.cn, http://www.tjcn.org (1998–2016). The and LISA of energy efficiency show that energy efficiency possesses obvious spatial autocorrelation and spatial aggregation. Secondly, thanks to the spatial dependence of energy efficiency, we use the spatial quantile autoregressive model of panel data to analyze the influence of seven factors on energy efficiency at different quantile levels. The conclusion shows that the industrial structure, economic development level and technical level have a positive effect on the provincial energy efficiency in China. Resource endowment shows a negative correlation to energy efficiency. According to the empirical analysis based on the real data, the SQAR model is superior to the ordinary spatial autoregressive model in analyzing influence factors of energy efficiency.
The rest of the paper is organized as follows: Section 2 is about the methods and models including the measurement of efficiency of energy utilization, , LISA and SQAR. In Section 3, we apply the models to the provincial data of China during the years of 1998–2016 to analyze the efficiency of energy utilization.
2. Methods and Models
2.1. Spatial Auto-Correlation Test Based on Index
In this subsection, we introduce the measurement of energy efficiency, and LISA which are employed to test the spatial autocorrelation of energy efficiency.
For the measurement of energy efficiency, we use the data envelopment analysis (DEA) by taking the so-called low-carbon GDP [19] as the output variable. For convenience, we briefly describe the method of data envelopment analysis here. Assume there are n regions or called decision making units (DMU) in some references. Each region has m input variables and k output variables. For a year in the j-th region, and represent input and output vectors respectively, whose corresponding weight vectors are denoted by and respectively. The CRS-DEA model [21] of the j-th region can be expressed as follows:
The dual problem of model (1) can be expressed as:
where is a scalar, the efficiency value of the j-th region. It embodies the region’s ability to effectively allocate resources and sustainable development capability. If , it means that the j-th region is located at the production frontier, that is, the j-th region that obtains the maximum output under certain input is effective. is an vector of constants. It serves to form a convex combination of observed inputs and outputs.
The global describes the global spatial autocorrelation of all data, which is defined as follows [20]:
where , n the number of areas (spatial units), the energy efficiency value of the i-th region, the element of the spatial weight matrix, which represents the adjacent relationship between the i-th region and the j-th region. It is defined as follows:
The design of the spatial weight matrix in this paper follows the rook adjacency method. That is, if there is a common boundary between the two regions, they are considered to be adjacent. Using this method, a spatial weight matrix can be constructed.
The range of is . A positive means that there is a positive spatial correlation between the economic behaviors of various regions. The negative indicates that there is a spatial negative correlation between economic behaviors in various regions. If , there is no spatial correlation, and the economic behavior of each region is independent of each other. The closer the absolute value of is to 1, the greater the spatial correlation between regions.
By standardizing statistic , a significance test can be performed. Let
Under the null hypothesis : , that is, the null hypothesis of no spatial autocorrelation, we have:
where ; ; ; , . When the null hypothesis holds, follows a normal distribution.
Global spatial autocorrelation analysis yields only one statistic to summarize the whole study area. One statistic is not enough to describe the details of individual regions. One way is to study the local spatial autocorrelation of local regions. The local indicators of spatial association (LISA) to evaluate the clustering in those individual units by calculating Local for each spatial unit and evaluating the statistical significance for the i-th region:
2.2. Spatial Quantile Autoregressive Model
Based on Su and Yang’s research [22] on the spatial quantile autoregressive model under cross-section data, we extend it to the panel data case. Combining the spatial autoregressive model with quantile regression method, we need to deal with endogenous issues. We use the instrumental variable method proposed by Chernozhukov and Hansen [23,24] to solve the variable endogenous problem, and give the process of parameter estimation of the spatial quantile autoregressive model.
In 1978, Koenker and Bassett [16] proposed the idea of quantile regression and extended the mean regression model to the quantile one.
Let be a probability space, Y a random variable defined in . For any real number y, the distribution function of the random variable Y is defined by . For any , is called the -th quantile of Y. is abbreviated as . can be seen as a function of , called the quantile function of Y. Particularly, is the median of Y.
The multivariate quantile regression model is defined as follows:
where with dependent components. is a non-random explanatory matrix, where the transpose ’′‘ follows the transpose rules of the block matrix. For each , . is the parameter vector to be estimated. is the error term. Assume each error component satisfying the condition
the formulas (9) mean that the conditional -quantile of each error term is 0.
In 1973, Cliff and Ord [25] proposed a spatial autoregressive model. For the cross-sectional data, the spatial autoregressive model is expressed as:
where the subscript i is the cross section unit. is the explained variable of the i-th cross section unit, and is the explanatory vector. is the weight, reflecting the relation between the i-th region and the j-th region. Denote , , , . is the random error vector of independent and identically distributed with zero mean. The model (10) can be written in matrix form as follows:
By applying the first-order moment constraint to Equation (10), then the conditional mean , where . Similarly, applying quantile constraint to Equation (10), the following Equation (12) can be obtained:
Combining formula in (10) and (12), we have the spatial quantile autoregressive model for the cross-sectional data as follows:
We extend model (13) to the spatial quantile autoregressive model for panel data:
where is an m-dimensional column vector.
Note: t can also be continuous time. Here we only consider the discrete case. We assume the time is divided into T periods. For each i and t, ( is the set of all real numbers, is the m-dimensional Euclidean space). , is the coefficient of the spatial lagged factor. is an vector of regression coefficients, is the error term with zero quantile, .
Endogenous variables are important in economic modeling, which are determined by their relationship with other variables within the model and show whether a variable causes a particular effect. The spatial lagged factor in the spatial autoregressive model can be regarded as an endogenous variable. The spatial econometric model combined with quantile regression needs to deal with endogenous issues. Otherwise, it will affect the accuracy of parameter estimation. Therefore, in the next subsection, we will discuss the instrumental variable method to deal with endogenous problems and parameter estimation.
2.3. Instrument Variable Method for Endogenous Problem and Parameter Estimation
Instrumental variables are variables that do not belong to the original model and are related to endogenous variables (Pearl, 2000 [26]). Concerning instrumental variable(IV) method, we refer to the literatures of Chernozhukov and Hansen [23,24], Matthew and Carlos (2009) [27].
Let be a matrix of instrument variables, where . is related to but unrelated to and satisfies
Let , where is the identity matrix and ‘⊗’ represents the Kronecker product.
Take , where , for , which implies the spatial weights are invariable in different periods. Then is strictly exogenous and related to endogenous variables. The IV method will be simpler if are independently and identically distributed. Then (15) is equivalent to find such that zero is a solution to the ordinary quantile regression:
where . is the indicator function. G is a class of measurable functions of . Let , there is . Here we assume G is defined as follows:
where is a column vector and . In order to solve the problem (17), we construct the weighted quantile regressive objective function as follows:
By the results in [23], the principle to solve problem (17) is to find such that the instrument variable coefficient is driven as close to zero as possible. Here we use the two-stage least squares on the objective function (18).
Assumptions:
- (1)
- .
- (2)
- For any t, .
- (3)
- Given a value of , the conditional distribution function has a bounded continuous conditional probability density function . Where , is the element of G.
- (4)
- X is non-random. Its absolute value is uniformly bounded and contains the intercept term.
- (5)
- The instrument variable Z is non-random with full column rank.
Let . The algorithm of solving parameter estimation of the SQAR model are summarized as follows:
Step 1: for a given , to perform a ordinary quantile regression on based on as follows:
Step 2: minimize the value of , and then get the estimator of :
where , , , A is a symmetric positive definite matrix. In fact, in order to find the estimator of , the coefficient of the instrument variable should be driven as close to zero as possible. For simplicity, referring to the study of Chernozhukov and Hansen [23,24], here we take to be an identity matrix.
Step 3: performing weighted quantile regression on based on we can get an estimator of :
3. Empirical Analysis and Results
In this section, we apply the above models to analyze the spatial autocorrelation and influence factors of energy efficiency of China during the years 1998–2016. Here we only consider 30 provinces and cities of China (Tibet, Hongkong, Macao and Taiwan were not studied in this paper since the incomplete data). All data come from China statistical Yearbook and local statistical Yearbooks (http://www.tjcn.org, http://data.stats.gov.cn). In the web page http://data.stats.gov.cn, one can find the navigation links to the annual reports of provinces. We downloaded and checked the data carefully. We assure the accuracy of input data in our models.
3.1. Spatial Autocorrelation Test Based on Global and Local
In [19], Lu and Zhang calculated energy efficiency according to (2) based on the low-carbon GDP output, where , and . Based on the results in [19], here we obtain yearly and LISA during the study period 1998–2016. The spatial weight matrix is designed following the rook adjacency rule. Hainan province’s geographical location in China is special, an island across the sea from the mainland. There will be no neighbors under the rook adjacency method. However, since the reform and opening up, Hainan province has become increasingly close to the outside world. So we consider Hainan province to be adjacent to Guangdong province.
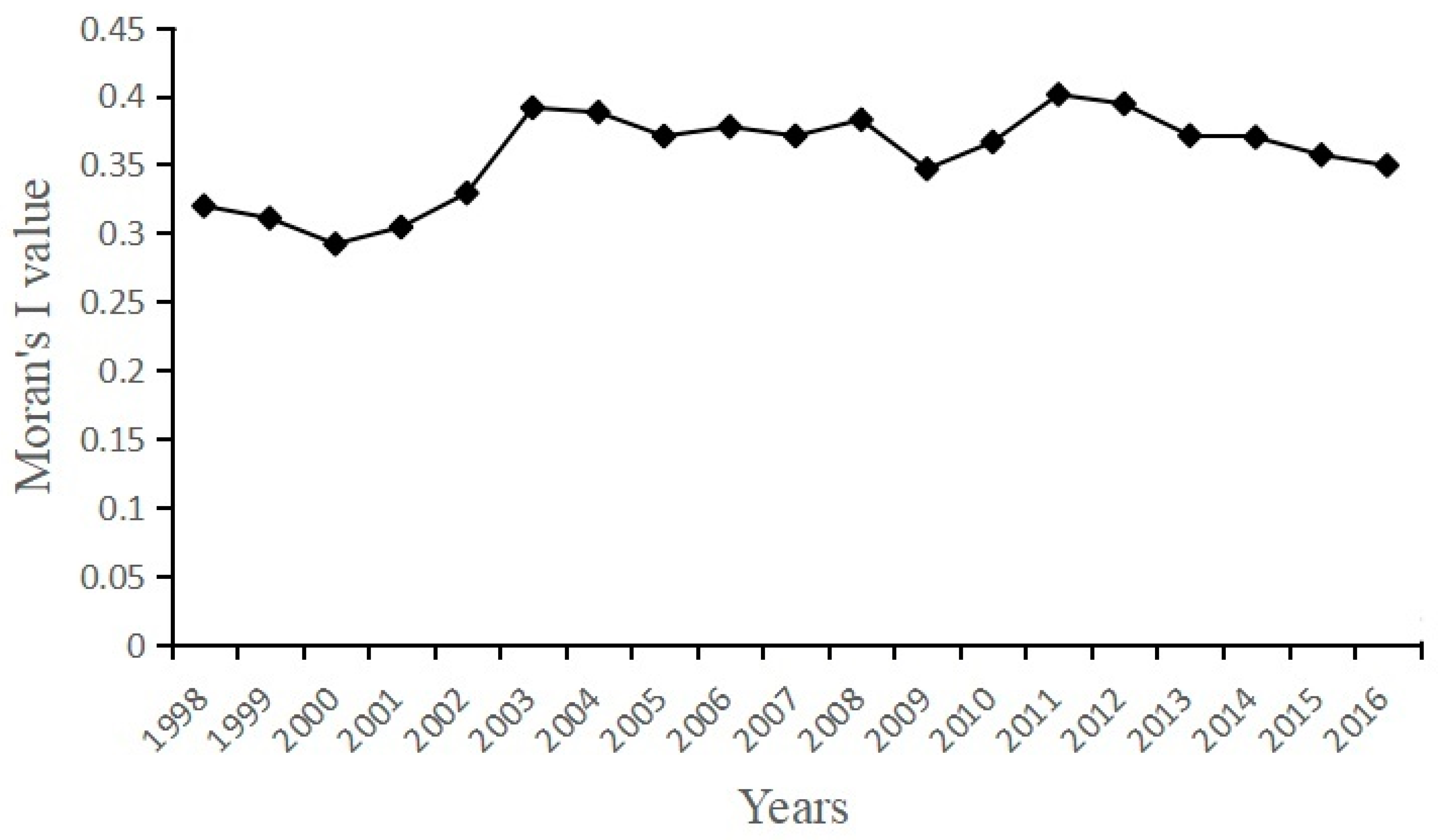
In statistics, there are p-value and Z-value or Z-score. The p-value is the probability that you have falsely rejected the null hypothesis. The Z-value is the measure of standard deviation. Very high or a very low (negative) Z-value, associated with very small p-values, are found in the tails of the normal distribution. It can be seen from Table 1 and Figure 1 that values of of China’s provincial energy efficiency are positive. All are statistically significant at the given significance level . Therefore, it rejects the null hypothesis that there is no spatial autocorrelation in China’s provincial energy efficiency.

Table 1.
value of China of provincial energy efficiency.
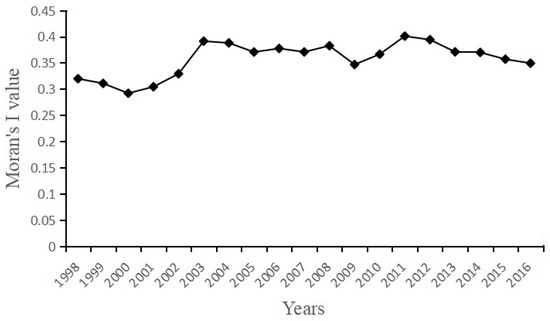
Figure 1.
Trend of .
For each year, we obtained the scatter plots and clustering graphs of LISA. Here we only list the yearly results of 2008 and 2016 for limitation of pages.
It can be seen from Table 1 and Figure 1, the values of are positive and fluctuate around 0.366 from 1998 to 2016, with little change year-on-year, which implies a positive correlation. On the whole, the energy efficiency has a slight upward trend, and the spatial autocorrelation of energy efficiency is gradually increasing although the future trend is unclear.
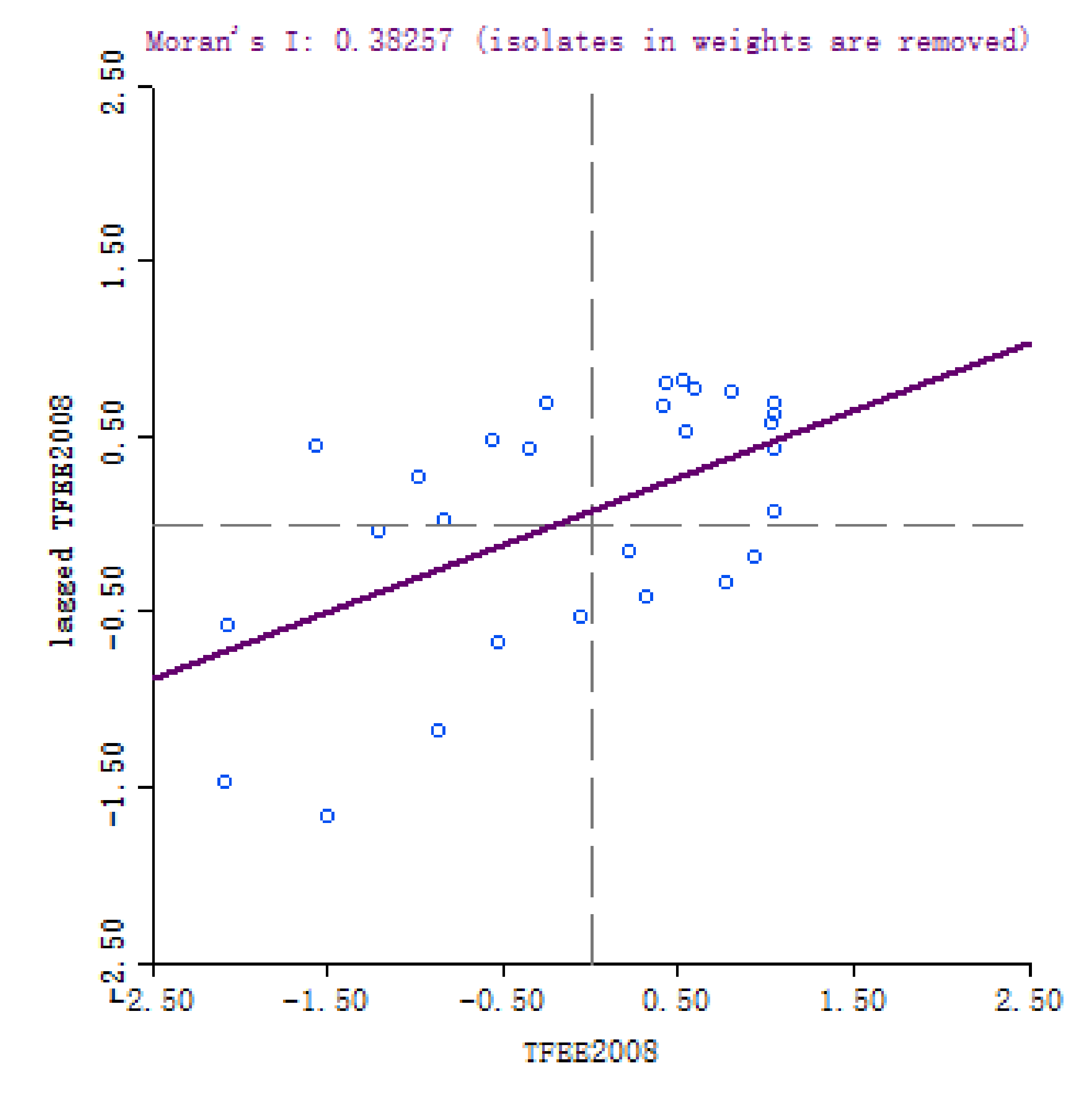
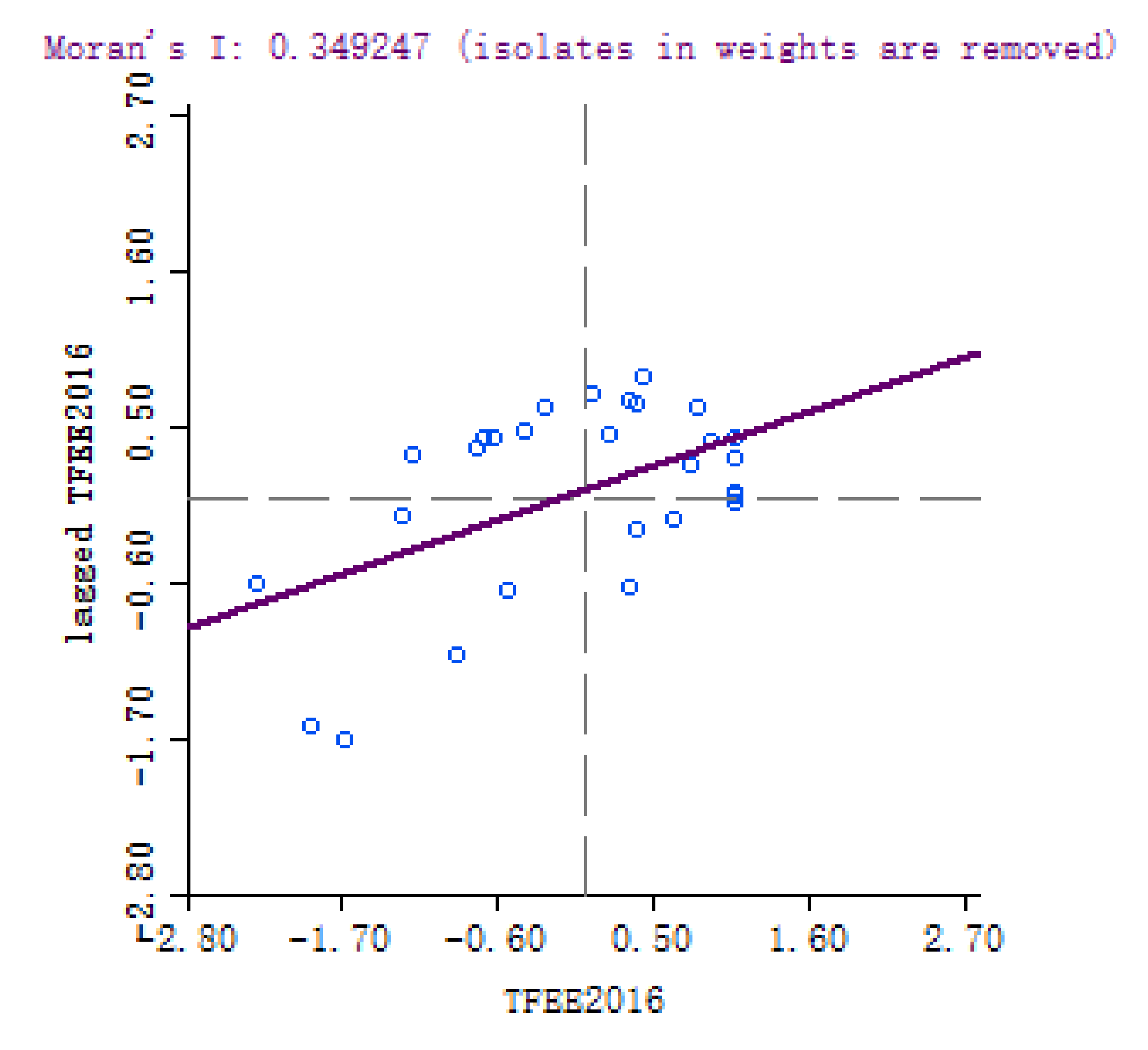
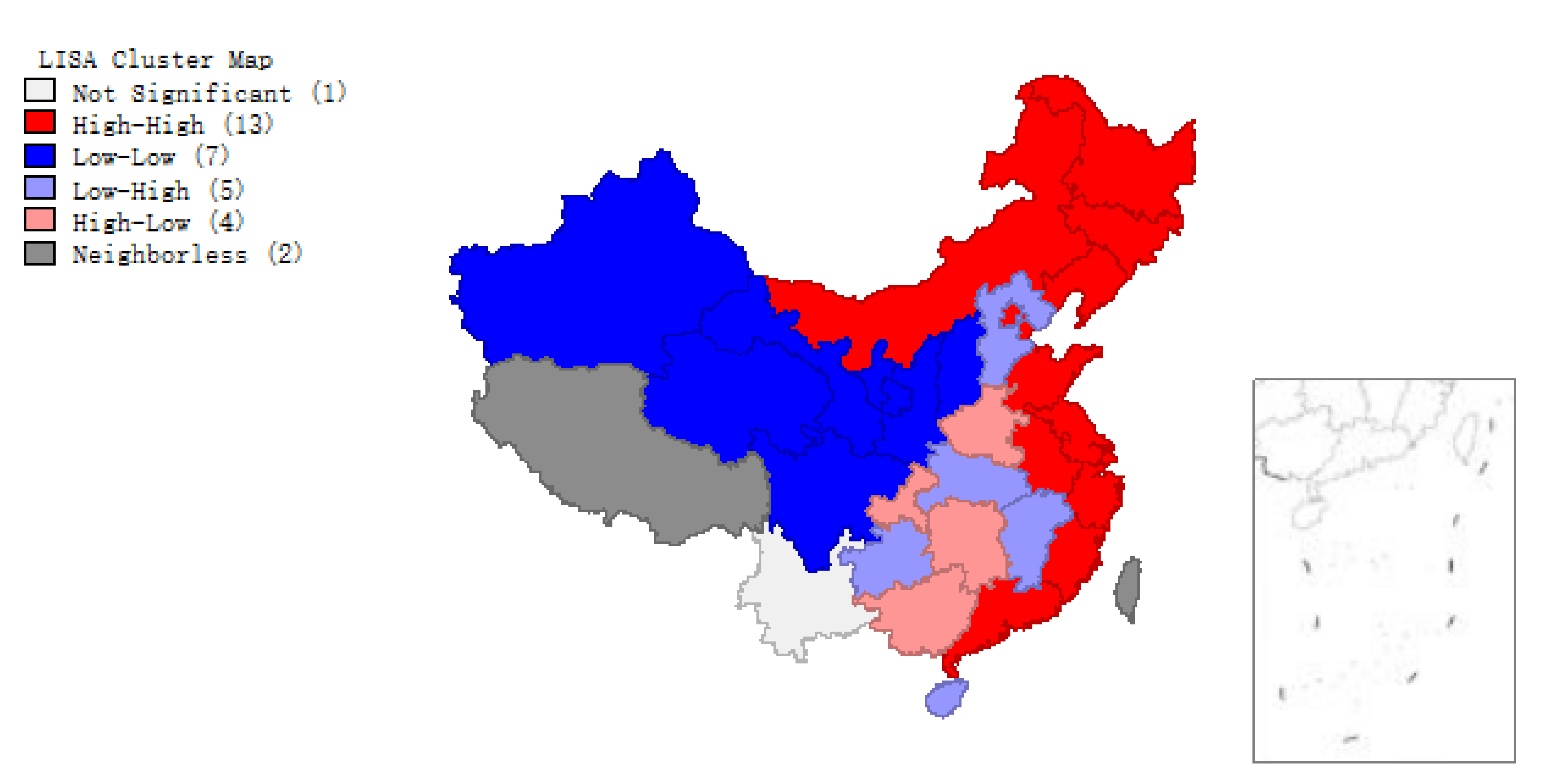
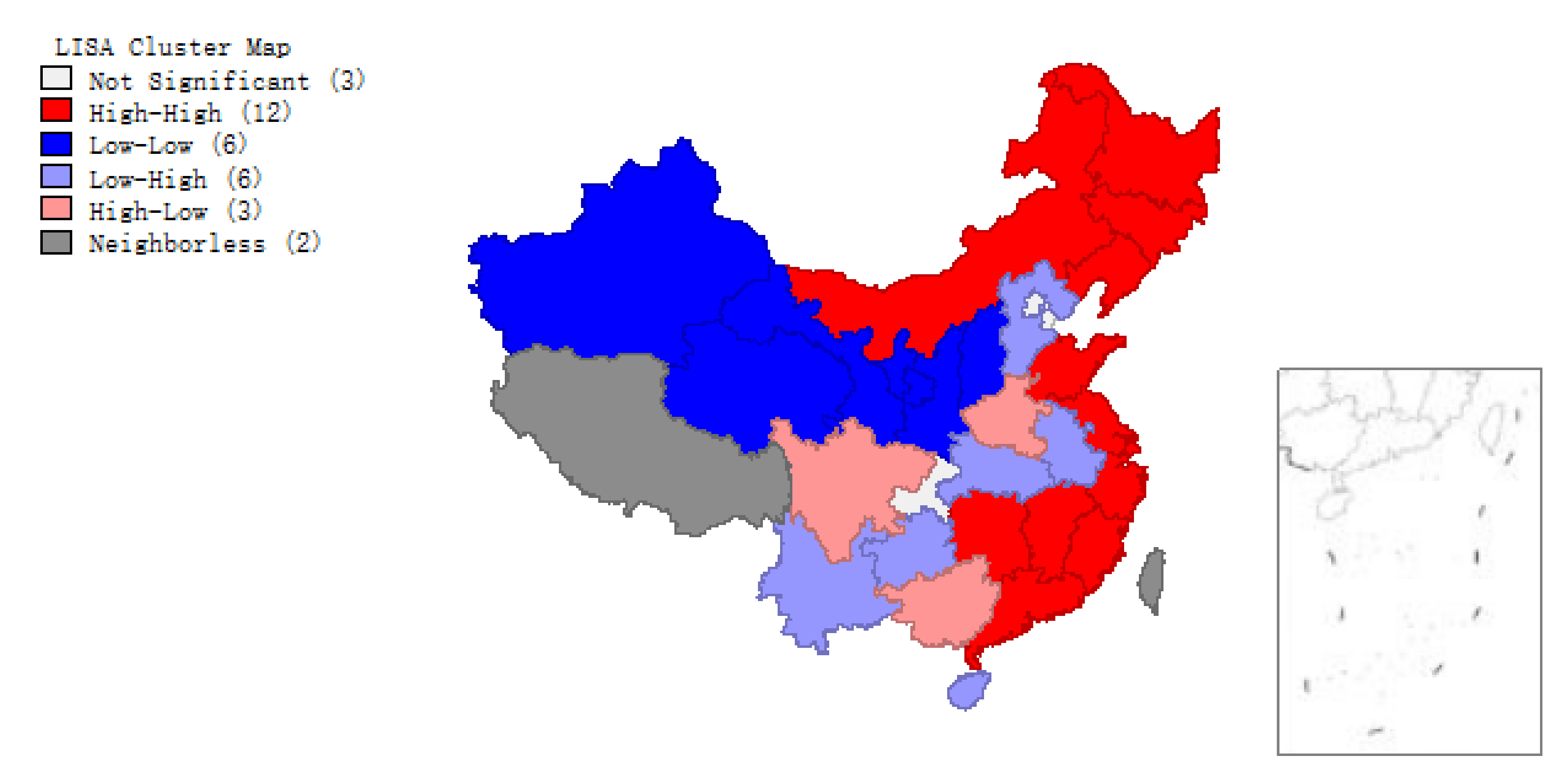
The scatter plots of (Figure 2 and Figure 3) and clustering graphs (Figure 4 and Figure 5) of LISA indicate that the spatial agglomeration of energy efficiency in China’s provinces tends to be stable. We can see that the energy efficiency of Chinese provinces is not randomly distributed. The energy efficiencies of regions with similar properties tend to gather together (High value of energy efficiency is adjacent to the high value of energy efficiency, low value of energy efficiency is adjacent to a low value of energy efficiency). The map is divided into four quadrants: The first quadrant (High-High) represents a space unit with a high energy efficiency value. Its neighboring provinces and cities are also high-efficiency units; The second quadrant (Low–High) represents the region with a low energy efficiency value. The energy efficiency values of its neighboring regions are at high level; the third quadrant (Low–Low) represents a low-energy efficiency space unit, and its neighboring provinces and cities are also low-efficiency units; The fourth quadrant (High–Low) represents a region with high energy efficiency value, but its neighboring region efficiency value is low.
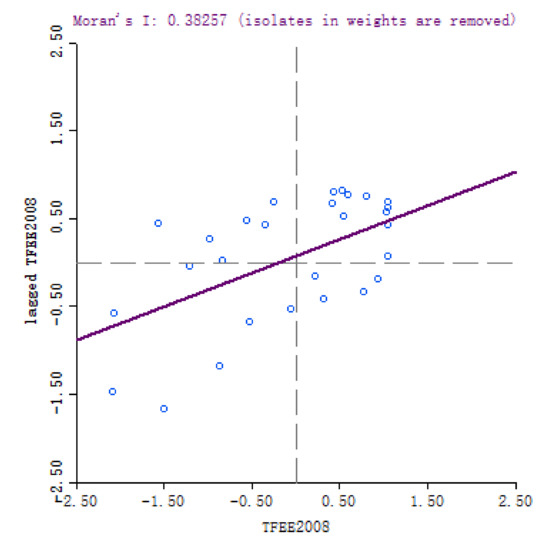
Figure 2.
Scatter plot of of provincial energy efficiency, 2008.
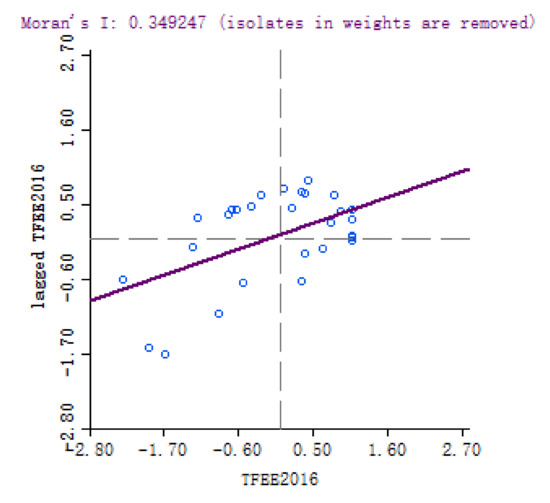
Figure 3.
Scatter plot of of provincial energy efficiency, 2016.
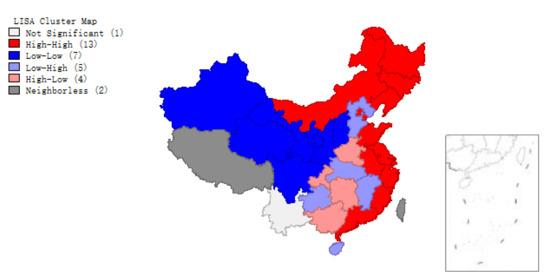
Figure 4.
Local indicators of spatial association (LISA) of provincial energy efficiency, 2008.
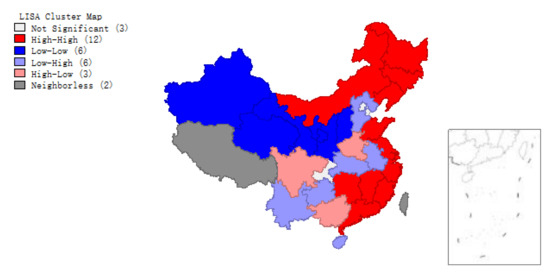
Figure 5.
LISA of provincial energy efficiency, 2016.
Figure 1, Figure 2, Figure 3, Figure 4 and Figure 5 show that regions located in the first quadrant (High-High) are mainly the provinces and cities with higher economic development in the eastern coastal areas, such as Guangdong, Fujian, Zhejiang and Shanghai etc. The economic development of these provinces and cities is rapid. They have a positive influence on each other’s development. Provinces and cities in the third quadrant (Low–Low) are mainly distributed in northwest China such as Qinghai, Ningxia, Xinjiang, Gansu etc., where economic development is relatively backward with lower energy efficiency. The energy efficiency value of surrounding provinces and cities is also relatively low. Most provinces and cities in central China are located in the second quadrant (Low–High). In the fourth quadrant (High–Low) the energy efficiency values of various provinces and cities are interleaved, with little dependence on each other. Briefly, China’s provincial energy efficiency has obvious spatial autocorrelation. The energy efficiency value of a province is largely affected by the energy efficiency values of its neighboring provinces.
3.2. Influence Factors of Energy Efficiency
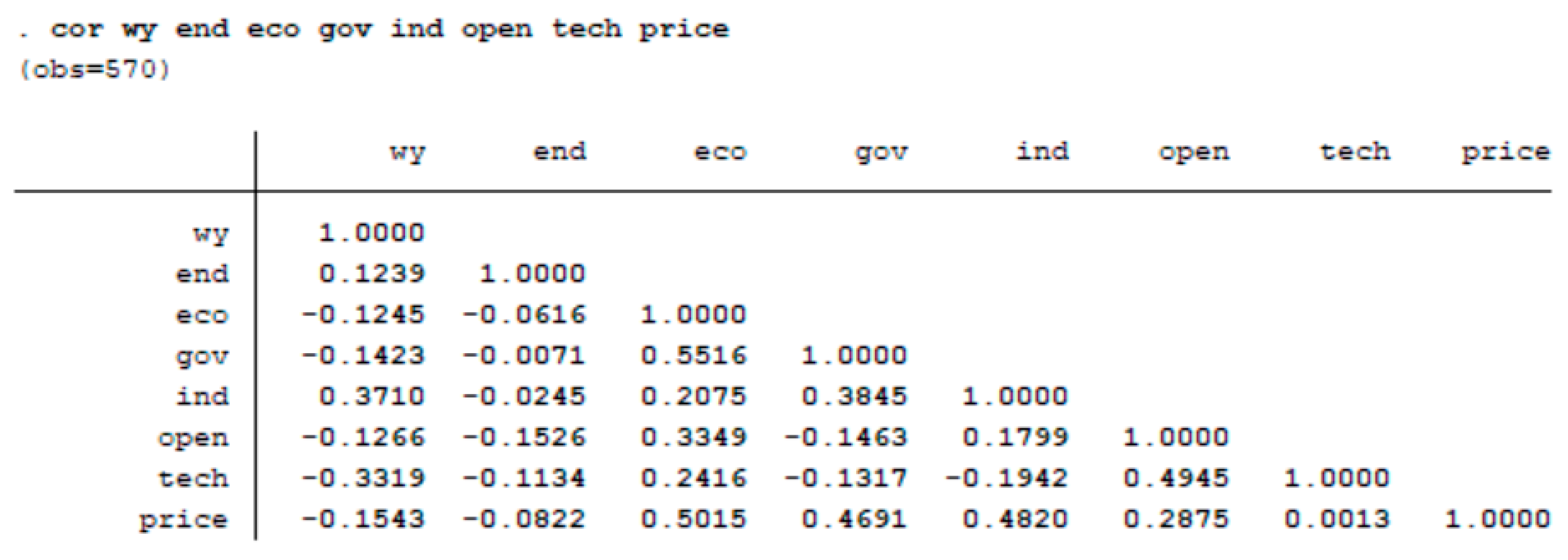
Base on results above, there are obvious spatial autocorrelation and spatial clustering phenomena in China’s provincial energy efficiency. The energy efficiency value of each province and city is affected by the neighboring regions’, which makes it reasonable to describe the data by a spatial autoregressive model. We take resource endowment (End), level of economic development (Eco), degree of government intervention (Gov), industrial structure (Ind), degree of opening to the outside world (Open), technical level (Tech) and energy prices (Price) as the main factors that affect energy efficiency. We use the spatial quantile autoregressive model (14) to analyze the influence of seven factors on energy efficiency values at the quantiles of . Before build models, at first we preprocess the data set. For linear regression analysis, hypothesis testing on the data is necessary. Here we need to consider the multicollinearity of all explanatory variables. We also consider the heteroscedasticity of data. From Figure 6, we found that all explanatory variables have no multicollinaerity. The hypothesis test result in Figure 7 shows that the data are of heteroscedasticity, which implies that ordinary linear regression is invalid while quantile regression is a better tool to deal with the data with heteroscedasticity.
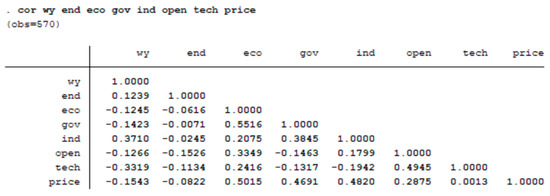
Figure 6.
Multicollinearity test.

Figure 7.
Heteroscedasticity test.
As a comparison, we also give the estimators based on ordinary spatial autoregression (10). The values of total-factor energy efficiency(TFEE) for application analysis come from the study of Lu and Zhang [19]. The variable description and data processing methods are given in Table 2:
Table 2.
Variable description of the spatial quantile autoregression (SQAR) model.
We establish the SQAR model as follows (23):
where the subscripts and denote regions and years respectively. are the parameters to be estimated. is the random error term. is a coefficient of the spatial lagged factor . We treat as an endogenous variable and select that is defined in Section 2.3 as an instrumental variable. The parameters are estimated by using SQAR model at the following quantiles: .
We use the software of Stata 12.0 to estimate parameters of the model SQAR based on the instrumental variables method given in Section 2.3. The formulas (20)–(22) are the algorithm about the parameter estimation of the model (23). For the sake of convenience to repeat the solving process based on our data, we give the operation process as follows:
- Computing the spatial effect , where W is the spatial weight matrix. The spatial weight matrix is designed following the rook adjacency rule. Y is the response variable (TFEE).
- Computing the instrumental variable , where W is the same weight matrix as the above and X is the matrix of explanatory variables.
- Open Stata version 12.0 and input: ivqreg EE eco gov ind tech end price(WY=WX),q()For a given quantile , we then can get the result of SQAR at the quantile.
In this work, we consider quantile . The results are shown in Table 3, Table 4, Table 5, Table 6 and Table 7.
Table 3.
Estimation results of the SQAR model, .
Table 4.
Estimation results of the SQAR model, .
Table 5.
Estimation results of the SQAR model, .
Table 6.
Estimation results of the SQAR model, .
Table 7.
Estimation results of the SQAR model, .
From Table 3, Table 4, Table 5, Table 6 and Table 7, it can be seen that the spatial autoregressive coefficient is significantly negative at and significantly positive for with the significant level 1%. This shows that at lower value of energy efficiency, the neighboring provinces and cities of a region have a negative influence on it, resulting in a low-low clustering case. Regions with higher energy efficiency tend to have a positive influence on the surrounding provinces and cities, which contributes to a high-high clustering distribution pattern. At the same time, this is also consistent with the conclusion of . While in the SAR model (Table 8), the spatial effect coefficient is significantly positive, and much bigger than that at quantile of SQAR model. Obviously, the estimate of spatial effect in SAR is rougher and somewhat unreasonable. The heteroscedasticity of data may explain why this happens.
Table 8.
Estimation results of the ordinary spatial autoregression (SAR) model.
Considering the influence factors, we obtain the following results:
- The coefficient of variable is negative at all quantiles. Except for at the quantile 0.5, the coefficient of variable is statistically significant at other quantiles. It shows that there is a negative correlation between the level of resource endowment and energy efficiency, that is, the situation of energy utilization efficiency in regions with more sufficient resource reserves is worse. The same result also can be obtained in the spatial autoregressive (SAR) model (See Table 8) but the p-value is 0.426, which means the negative influence of resource endowment level on energy efficiency is not statistically significant according to the result of SAR model. This shows that the regression results of the SAR model are not ideal.
- The estimates of the parameter of the variable are positive for all quantiles and the estimate is smaller at the upper quantile. This indicates that the level of economic development obviously promotes the improvement of energy efficiency, and with the increase of energy efficiency, the positive role of promotion is steadily weakening.
- The estimates () of the parameter of variable are significantly negative in SQAR model at all quantiles and in SAR model. The absolute values of estimates are smaller at the upper quantile. For example: ; ; . This shows that the degree of government intervention has a negative correlation with energy efficiency. However, this negative influence gradually weakens as energy efficiency increases.
- The influence of industrial structure on energy efficiency is quite similar to the influence of economic development level on energy efficiency. The influence of industrial structure on energy efficiency is greater.
- When , the degree of opening to the outside world has a positive effect on energy efficiency. while , the degree of opening to the outside has a negative effect on energy efficiency. The results of the SAR model show that there is a positive correlation between the degree of opening to the outside world and energy efficiency. Compared with the SQAR model, the conclusion shown by the SAR model is somewhat limited. It can not describe the full information. This also exposes the disadvantages of ordinary mean regression.
- At lower quantile of energy efficiency , there is a negative correlation between the level of technological development and energy efficiency, and the negative correlation at quantile 0.5 is most significant. At a higher quantile of energy efficiency, the effect of the technical level is positive and statistically significant at the 10% level. However, the SAR model shows that the technical level has a negative influence on energy efficiency. Obviously, the SAR model hides the tail information of the data. So the result of the SAR model can not fully describe the true distribution of data.
- When , the estimates of the parameter of are significantly negative, indicating that at a lower level of energy efficiency, the higher the energy price the lower the energy efficiency value. When , energy prices have a positive effect on energy efficiency.
3.3. Conclusions
Through the empirical analysis to the energy efficiency of Chinese 30 provinces and cities at different quantiles, we draw conclusion as follows.
The level of economic development and industrial structure have a significant role in promoting energy efficiency. There is a negative correlation between resource endowment and energy efficiency. The degree of opening to the outside world has no significant influence on energy efficiency. Only at a high level of energy efficiency can the technical level play a certain role in promoting. At a lower energy efficiency level, energy price has a significant negative influence on energy efficiency. By comparing with an ordinary spatial autoregressive model, this paper shows the advantages of spatial quantile autoregressive modes in the analysis process. SQAR model is more resistant to outliers and can describe the statistical distribution of variables in more detail.
Based on the above analysis, We offer a few suggestions that will help to promote energy efficiency.
- Improve the economic level of each province and optimize the industrial structure. The government at all levels should take measures to allocate resources reasonably. China’s resources are concentrated in the central and western regions. These regions have unique resource conditions but the economic level is generally low. The government’s fiscal expenditure cannot play an active role. Therefore, the government needs to properly adjust the intensity of government intervention and allocate resources to promote the improvement of energy efficiency.
- Provinces and cities with lower energy efficiency should put economic development and optimization of industrial structure in the first place. Regions with higher energy efficiency may continue to accelerate technological development. Under the lower efficiency level, both the technical level and the energy price have a negative influence on energy efficiency. At this time, rushing to raise the technical level and lowering the energy price may not help. So only by solving the most basic problem—economic development—can the development of other aspects be driven. For provinces and cities with higher energy efficiency, they have strong economic strength and a reasonable industrial structure. So it is better to develop and innovate science and technology constantly, making science and technology a powerful driving force for improving energy efficiency.
4. Discussion
The practical world is complex. In order to model the real world by using quantitative methods such as statistics tools, we have to make some assumptions in advance. For example, for ordinary linear regression, normal distribution and homoscedasticity are required. While, if the data does not follow a normal distribution and has heteroscedasticity, quantile regression is a good option. Compared with the existing references related to the analysis of factors influencing energy efficiency, the novelty of our model (23) is that it considers not only the spatial correlation of energy efficiency but also the heteroscedasticity of explanatory variables. Given a quantile and the input data of explanatory variables X in model (23), the output is the conditional quantile of efficiency under given X. It can characterize the distribution of energy efficiency. However, for ordinary regression, the output is the mean of energy efficiency, which is a rougher estimate. For example, given , input the data of Hubei province in 2016, we get the output 0.683 of model (23). That means when the values of explanatory variables change, the quantile at 0.25 of energy efficiency of Hubei is 0.683. Considering the energy of efficiency in the period of 1998–2016 of Hubei province, we get the 0.25 quantile is 0.687. The fitting effect is not bad from this single case. However, it does not mean our model is complete. The result of our model can not perfectly explain the practical world since it is based on some assumptions, although it is expected helpful to improve the energy efficiency for decision-makers for maintaining the sustainability of social development. It still needs to be improved. Here we only considered the spatial lagged effect and ignored the time-lagged effect. In our future work, based on the quantile method, we will consider both spatial lagged effect and time-lagged effect, i.e., consider the dynamic panel data.
Author Contributions
This research was designed and performed by all authors. The data were collected by Q.L., L.G. and X.W. contributed to statistical models and analysis, estimation of parameters. Q.L. contributed to writing—original draft. J.Z. contributed to writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the Natural Science Foundation of Beijing Municipality (No.1192015).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used in this study are available in China Statistical Yearbook, Statistical Yearbook of provinces and http://data.stats.gov.cn, http://www.tjcn.org.
Acknowledgments
The authors are grateful to the editor and referees for valuable comments which led to improvements in this work.
Conflicts of Interest
The authors declare no conflict of interest.
Sample Availability
Samples are available from the authors.
Abbreviations
The following abbreviations are used in this manuscript:
| LISA | Local indicators of spatial association |
| SAR | Ordinary spatial autogression |
| SQAR | Spatial quantile autoregression |
| DEA | Data envelopment analysis |
References
- Ayres, R.U.; Turton, H.; Casten, T. Energy efficiency, sustainability and economic growth. Energy 2007, 32, 634–648. [Google Scholar]
- Mavi, N.K.; Mavi, R.K. Energy and environmental efficiency of OECD countries in the context of the circular economy: Common weight analysis for malmquist productivity. J. Environ. Manag. 2019, 247, 651–661. [Google Scholar]
- Miketa, A. Analysis of energy intensity developments in manufacturing sectors in industrialized and developing countries. Energy Policy 2001, 29, 769–775. [Google Scholar]
- Yu, X.; Moreno-Cruz, J.; Crittenden, J.C. Regional energy rebound effect:The impact of economy-wide and sector level energy efficiency improvement in Georgia, USA. Energy Policy 2015, 87, 250–259. [Google Scholar]
- Zheng, J.; Mi, Z.; Coffman, D.M.; Milcheva, S.; Shan, Y.; Guan, D.; Wang, S. Regional development and carbon emissions in China. Energy Econ. 2019, 81, 25–36. [Google Scholar]
- Tobler, W.R. A computer movie simulating urban growth in the detroit region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar]
- Shen, N.; Liu, F. Spatial spillover, threshold characteristics and the economic growth effect of energy efficiency. China Popul. Resour. Environ. 2012, 5, 155–159. [Google Scholar]
- Makridou, G.; Andriosopoulos, K.; Doumpos, M.; Zopounidis, C. Measuring the efficiency of energy-intensive industries across European countries. Energy Policy 2016, 88, 573–583. [Google Scholar]
- Li, H.; Shi, J.F. Energy efficiency analysis on Chinese industrial sectors: An improved Super-SBM model with undesirable outputs. J. Clean. Prod. 2014, 65, 97–107. [Google Scholar]
- Liu, J.; Mao, J. Analysis of China’s provincial energy efficiency distribution and its influencing factors based on spatial measurement. J. Hunan Univ. Financ. Econ. 2014, 30, 133–140. [Google Scholar]
- Gao, Z.; Wang, Y. Regional division of energy productivity in China and analysis of influencing factors. J. Quant. Tech. Econ. 2006, 9, 46–57. [Google Scholar]
- Jiang, L.; Folmer, H.; Ji, M.; Tang, J. Energy efficiency in the Chinese provinces: A fixed effects stochastic frontier spatial Durbin error panel analysis. Ann. Reg. Sci. 2017, 58, 301–319. [Google Scholar]
- Li, K.; Lin, B. How to promote energy efficiency through technological progress in China? Energy 2018, 143, 812–821. [Google Scholar]
- Qiu, L.; Shen, Y.; Ren, W.; Yan, T. Regional differentiation and influencing factors analysis of energy efficiency in China. J. Nat. Resour. 2008, 23, 920–928. [Google Scholar]
- Zou, Y.; Lu, Y. Analysis of regional characteristics of energy efficiency in China based on spatial autoregressive model. Stat. Res. 2005, 10, 67–71. [Google Scholar]
- Koenker, R.; Bassett, G. Regression quantiles. Econometrica 1978, 46, 33–50. [Google Scholar]
- Koenker, R. Quantile regression for longitudinal data. J. Multivar. Anal. 2004, 91, 74–89. [Google Scholar]
- McMillen, D.P. Quantile Regression for Spatial Data; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Lu, Q.; Zhang, J. Analysis of total-factor energy efficiency in China under low carbon constraint. In Proceedings of the 5th International Conference on Big Data and Information Analytics, Kunming, China, 8–10 July 2019. [Google Scholar]
- Moran, P.A.P. Notes on continuous stochastic phenomena. Biometrika 1950, 37, 17–23. [Google Scholar]
- Charnes, A.; Cooper, W.W.; Rhodes, E. Measuring the efficiency of decision making units. Eur. J. Oper. Res. 1978, 2, 429–444. [Google Scholar]
- Su, L.; Yang, Z. Research Collection School of Economics. Instrumental Variable Quantile Estimation of Spatial Autoregressive Models. Working paper. May 2011, pp. 1–35. Available online: https://ink.library.smu.edu.sg/soe_research/1074 (accessed on 12 January 2021).
- Chernozhukov, V.; Hansen, C. Instrumental quantile regression inference for structural and treatment effect models. J. Econom. 2006, 132, 491–525. [Google Scholar]
- Chernozhukov, V.; Hansen, C. Instrumental variable quantile regression: A robust inference approach. J. Econom. 2008, 142, 379–398. [Google Scholar]
- Paul Elhorst, J. Spatial Econometrics: From Cross-Sectional Data to Spatial Panels; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Pearl, J. Causality: Models, Reasoning, and Inference; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Matthew, H.; Carlos, L. A quantile regression approach for estimating panel data models using instrument variables. Econ. Lett. 2009, 104, 133–135. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).