
Dynamic Blackout Probability Monitoring System for Cruise Ship Power Plants

 ,
,  ,
, 
Abstract
1. Introduction
2. Materials and Methods
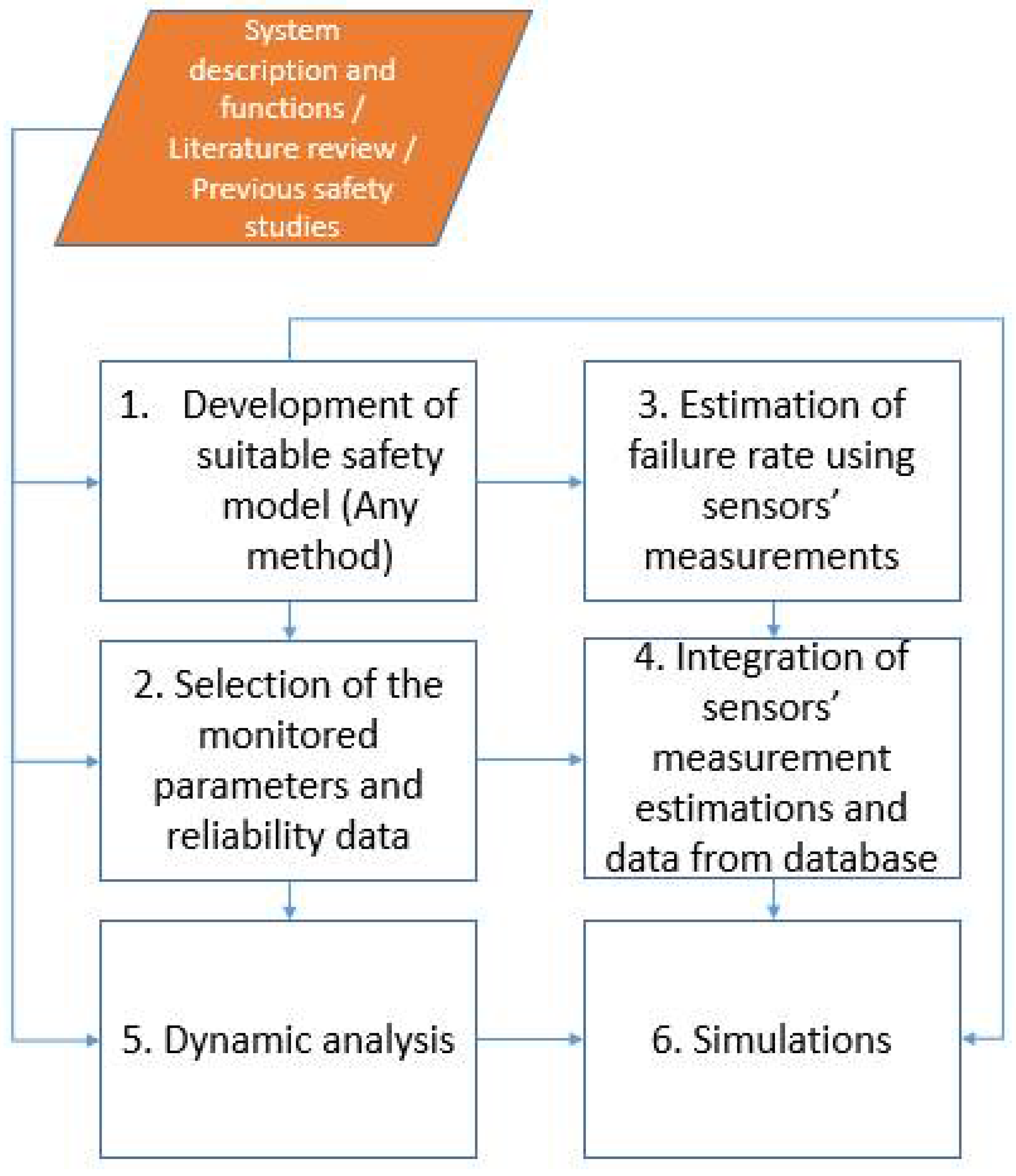
2.1. Methodology Overview
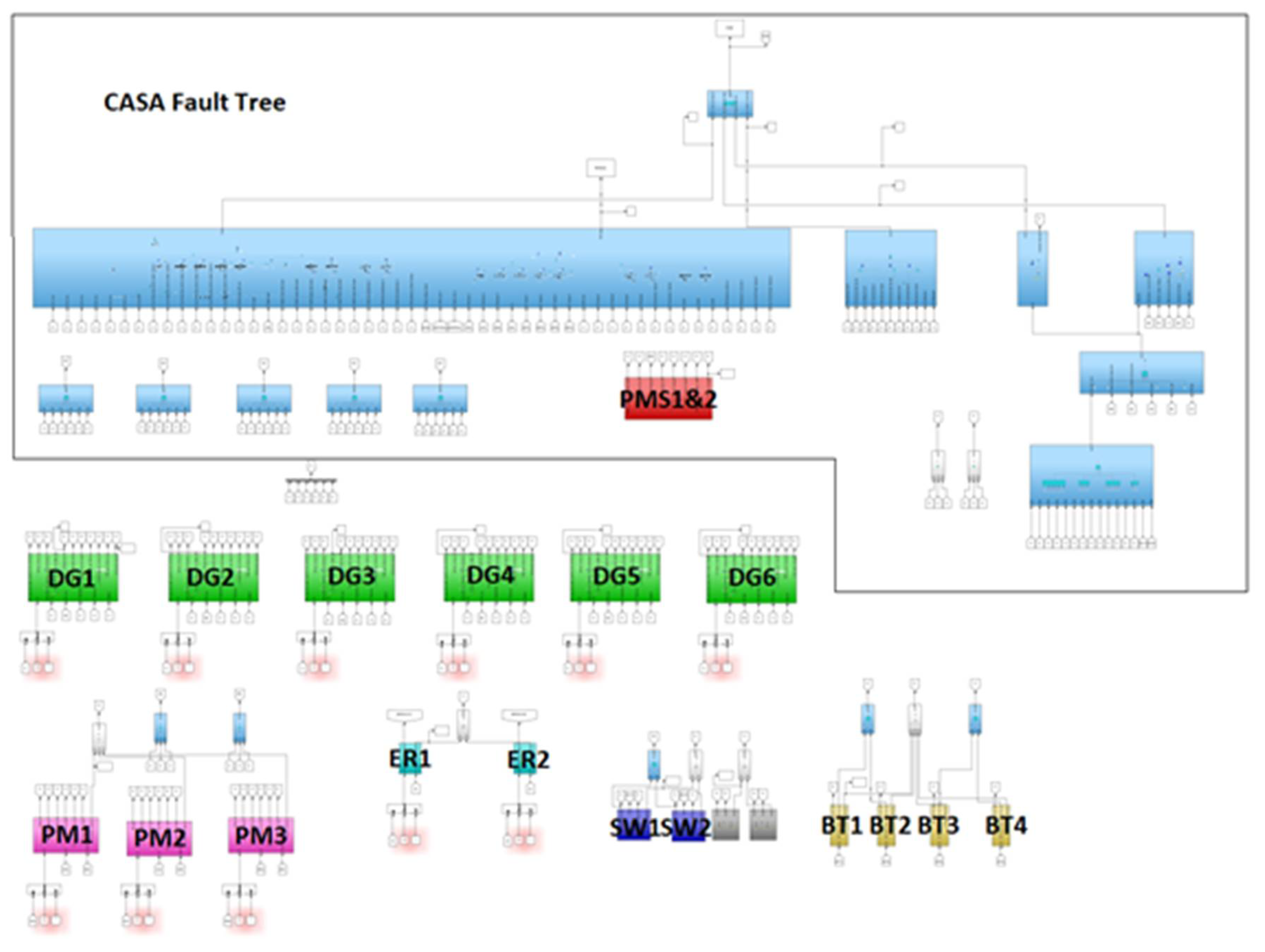
2.2. Step 1—Development of Safety Model
2.3. Step 2—Selection of the Monitored Parameters and Reliability Data
- Measured parameters that sufficiently and effectively depict/represent the actual system health based on the pertinent literature.
- Measured parameters that represent the system configuration and power demand, e.g., operating DG set(s).
- Measured parameters monitored by the existing ship alarm and monitoring system.
- Measured parameters from the ship plant critical components, as identified from previous safety analyses or accident investigation data.
2.4. Step 3—Estimation of Failure Rates Using Sensors Measurements
2.5. Step 4—Integration of Sensor Measurements Estimation and Database Data
2.6. Step 5—Dynamic Analysis
2.7. Step 6—Simulation in Virtual Environment
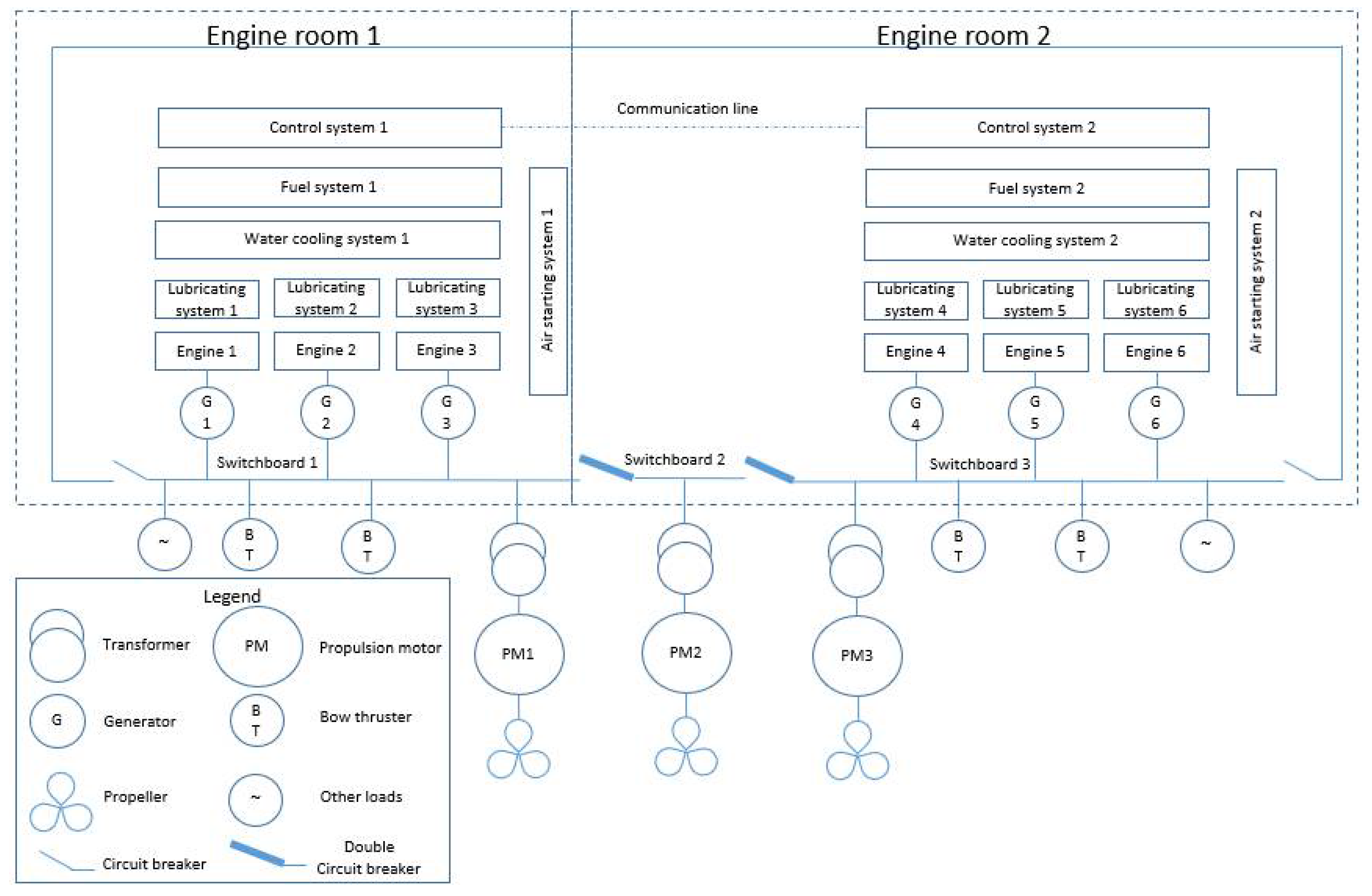
3. Investigated System Description
Case Studies Description
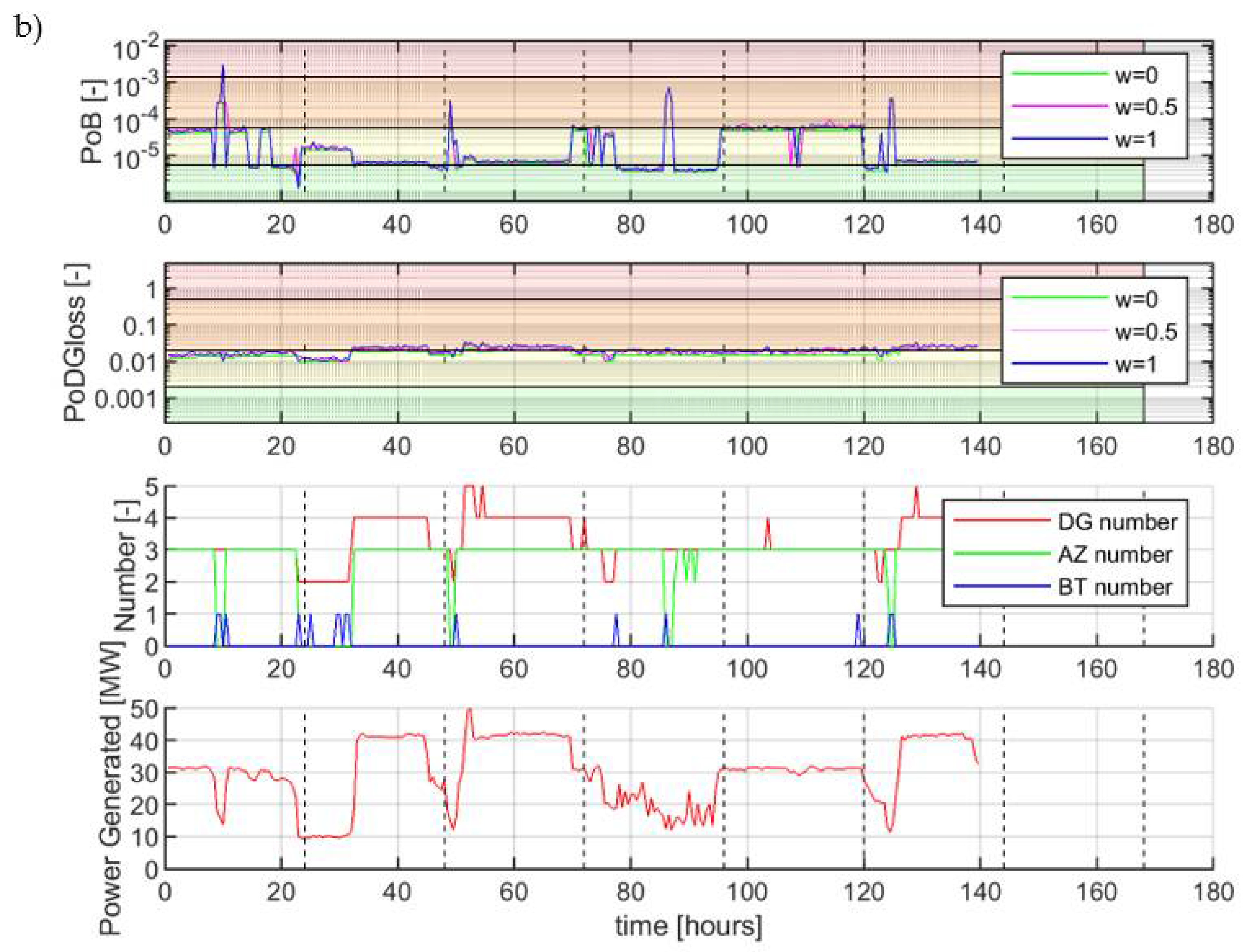
4. Results
4.1. Step 1—The Developed Safety Model
4.2. Step 2—Selection of the Monitored Parameters
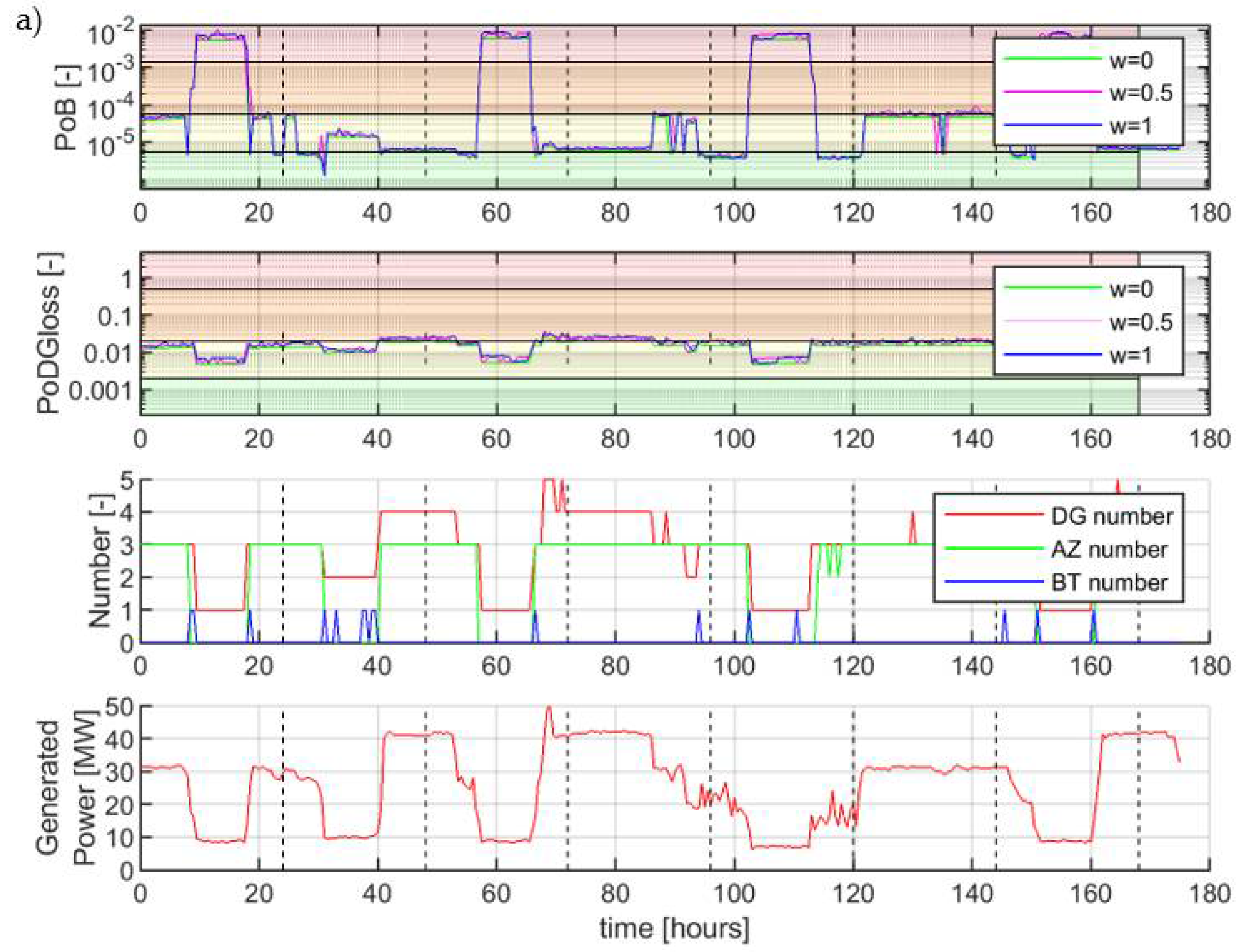
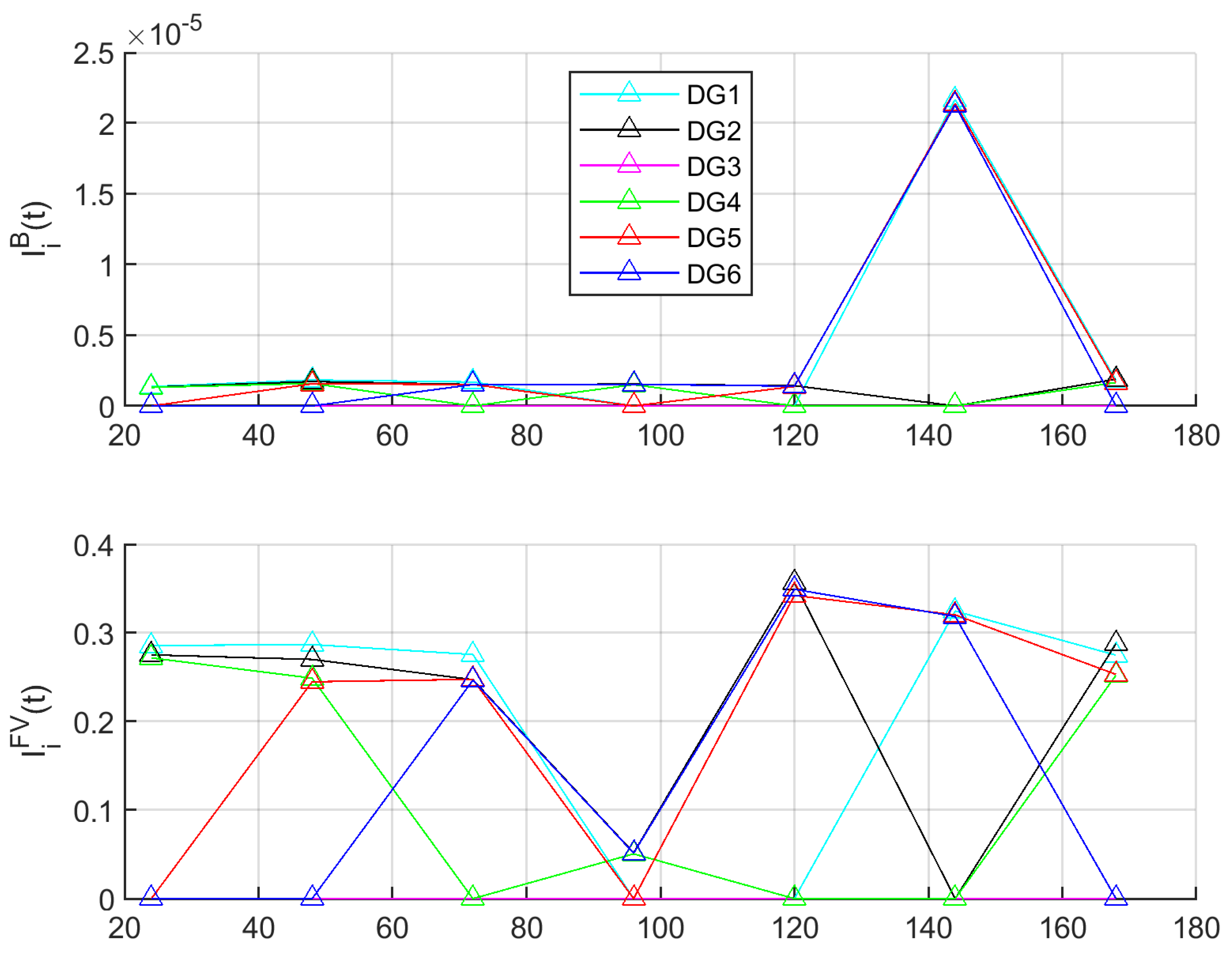
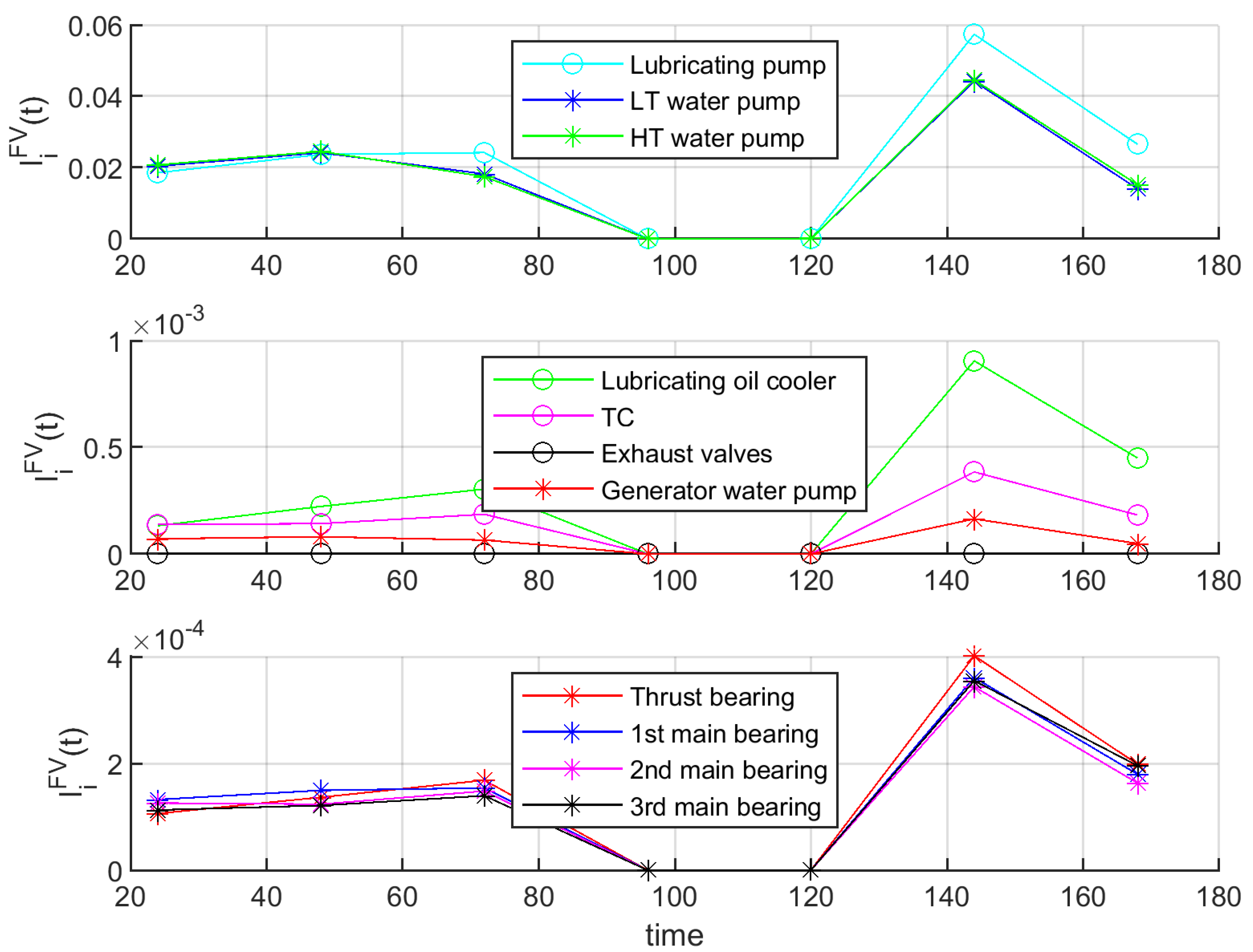
4.3. Steps 3−6—Simulation Results
4.4. Discussion
5. Conclusions
- Specific operational parameters as DG load and number of connected DG sets need be used as input into the safety monitoring system, as these influence the system’s probability of failure.
- An operation with a single DG set increases the PoB to the red warning level.
- The PoB during start of DG sets also reaches the red level.
- Failures in operating components can increase the PoB also above the desired threshold, however their criticality is varying in time dependent on the system other parameters.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations/Nomenclature List
| Greek symbols | |
| Symbol | Explanation |
| Weibull shape factor [-] | |
| Aggregated failure rate for component estimated using sensor measurements and reliability data | |
| Blackout failure rate [h−1] | |
| Failure rate for component [h−1] | |
| Failure rate for component estimated using sensor measurements [h−1] | |
| Repair rate for component [h−1] | |
| English symbols | |
| Symbol | Explanation |
| Feature [variable units] | |
| Normal feature value [variable units] | |
| Feature degradation slope [variable units/h] | |
| Health index for component i | |
| Birnbaum’s importance measure [-] | |
| An averaged over time metric [-] | |
| Fussell-Vesely importance measure [-] | |
| An averaged over time metric [-] | |
| Maximum Continuous Rating power [kW] | |
| Number of simulations [-] | |
| Number of criticality assessments implemented [-] | |
| Operational parameters [depending on parameter] | |
| Operational time [h] | |
| Aggregated probability [-] | |
| Probability of failure for operating component [-] | |
| Probability of failure of safety system [-] | |
| Probability of specific system states [-] | |
| The probability of failure on demand [-] | |
| Probability of top event in specific system configuration [-] | |
| Probability of top event [-] | |
| Reference probability of top event [-] | |
| Number of identical components | |
| Time [h] | |
| Time of last maintenance [h] | |
| Inspection or maintenance interval [h] | |
| Weight depicting which information is selected. w = 1, sensors are used to estimate failure rate, w = 0 failure rate from database is used. | |
| Subscripts | |
| Symbol | Explanation |
| Importance measure estimation number in dynamic simulation | |
| Component | |
| j | Basic event in Fault Tree |
| Failure rate estimated based on measurements | |
| Abbreviation | Explanation |
| BDMP | Boolean logic Driven Markovian Process |
| BT | Bow Thruster |
| CASA | Combinatorial Approach to Safety Analysis |
| DEP | Diesel-electric Propulsion |
| DG | Diesel Generator |
| ER | Engine Room |
| HT | High Temperature |
| LT | Low Temperature |
| MI | Maintenance Interval |
| PM | Propulsion Motors |
| PMS | Power Management System |
| PoB | Probability of Blackout |
| PoDGloss | The probability of sudden loss of a DG set |
| TC | Turbocharger |
References
- Asariotis, R.; Benamara, H.; Finkenbrink, H.; Hoffmann, J.; Lavelle, J.; Misovicova, M.; Valentine, V.; Youssef, F. Review of Maritime Transport, 2011; United Nations: Geneva, Switzerland, 2011; ISBN 9211128412. [Google Scholar]
- Cruise Lines International Association. 2017 Cruise Industry Outlook. 2016. Available online: https://cruising.org/-/media/research-updates/research/featured/2017-clia-state-of-the-industry.pdf (accessed on 1 December 2017).
- Nilsen, O.V.; Johansen, C.B.; Knight, M.; Hoffman, P.; Skjong, R. FSA for Cruise Ships—Task 4.1.1—Hazid Identification; SAFEDOR-4.1.1 2005-12-31 DNV rev. 1; Det Norske Veritas, 2005; Available online: http://www.safedor.org/resources/SAFEDOR-D-04.01.01-2005-10-31-DNV-HAZID-Cruise-vessels.pdf (accessed on 1 June 2018).
- MAIB. Report on the Investigation of the Catastrophic Failure of a Capacitor in the Aft Harmonic Filter Room on Board RMS Queen Mary 2 While Approaching Barcelona 23 September 2010; MAIB: Southampton, UK, 2011. [Google Scholar]
- Ullah, Z.; Waldrop, T.; Chavez, N. Helicopters Sent to Rescue 1300 Passengers from Cruise Ship Off Norway. Available online: https://edition.cnn.com/2019/03/23/europe/norway-cruise-ship-evacuation/index.html (accessed on 30 September 2019).
- DNV. Guidance for Safe Return to Port Projects; DNV GL: Hovik, Norway, 2016. [Google Scholar]
- Bolbot, V.; Theotokatos, G.; Bujorianu, L.M.; Boulougouris, E.; Vassalos, D. Vulnerabilities and safety assurance methods in Cyber-Physical Systems: A comprehensive review. Reliab. Eng. Syst. Saf. 2019, 182, 179–193. [Google Scholar] [CrossRef]
- DNV. 2025 Technology Outlook; DNV: Hovik, Norway, 2015. [Google Scholar]
- Stefani, A. An Introduction to Ship Automation and Control Systems; Institute of Marine Engineering, Science & Technology: London, UK, 2013. [Google Scholar]
- Malone, T.; Kirkpatrick, M.; Mallory, K.; Eike, D.; Johnson, J.; Walker, R. Human Factors Evaluation of Control Room Design and Operator Performance at Three Mile Island-2; Essex Corp: Alexandria, VA, USA; Washington, DC, USA, 1980. [Google Scholar]
- Accident Investigation Boar Norway. Interim Report on the Investigation into the Loss of Propulsion and Near Grounding of Viking Sky; Accident Investigation Board Norway: Lillestrøm, Norway, 2019. [Google Scholar]
- Papadopoulos, Y.; McDermid, J. Automated safety monitoring: A review and classification of methods. Int. J. COMADEM 2001, 4, 14–32. [Google Scholar]
- Xing, J.; Zeng, Z.; Zio, E. A framework for dynamic risk assessment with condition monitoring data and inspection data. Reliab. Eng. Syst. Saf. 2019, 191, 106552. [Google Scholar] [CrossRef]
- Hu, J.; Zhang, L.; Ma, L.; Liang, W. An integrated method for safety pre-warning of complex system. Saf. Sci. 2010, 48, 580–597. [Google Scholar] [CrossRef]
- Hu, J.; Zhang, L.; Ma, L.; Liang, W. An integrated safety prognosis model for complex system based on dynamic Bayesian network and ant colony algorithm. Expert Syst. Appl. 2011, 38, 1431–1446. [Google Scholar] [CrossRef]
- Aizpurua, J.I.; Catterson, V.M.; Papadopoulos, Y.; Chiacchio, F.; Manno, G. Improved Dynamic Dependability Assessment Through Integration with Prognostics. IEEE Trans. Reliab. 2017, 66, 893–913. [Google Scholar] [CrossRef]
- Aizpurua, J.; Catterson, V.; Papadopoulos, Y.; Chiacchio, F.; D’Urso, D. Supporting group maintenance through prognostics-enhanced dynamic dependability prediction. Reliab. Eng. Syst. Saf. 2017, 168, 171–188. [Google Scholar] [CrossRef]
- Gomes, J.P.P.; Rodrigues, L.R.; Galvão, R.K.H.; Yoneyama, T. System level RUL estimation for multiple-component systems. In Proceedings of the 2013 Annual Conference of the Prognostics and Health Management Society, New Orleans, LA, USA, 14–17 October 2013; pp. 74–82. [Google Scholar]
- Pattison, D.; Segovia Garcia, M.; Xie, W.; Quail, F.; Revie, M.; Whitfield, R.; Irvine, I. Intelligent integrated maintenance for wind power generation. Wind Energy 2016, 19, 547–562. [Google Scholar] [CrossRef]
- Abaei, M.M.; Hekkenberg, R.; BahooToroody, A. A multinomial process tree for reliability assessment of machinery in autonomous ships. Reliab. Eng. Syst. Saf. 2021, 210, 107484. [Google Scholar] [CrossRef]
- Eriksen, S.; Utne, I.B.; Lützen, M. An RCM approach for assessing reliability challenges and maintenance needs of unmanned cargo ships. Reliab. Eng. Syst. Saf. 2021, 210, 107550. [Google Scholar] [CrossRef]
- ISO. Risk management—Risk assessment techniques. In ISO 31010; International Organization for Standardization: Geneva, Switzerland, 2009; p. 92. [Google Scholar]
- Bouissou, M.; Bon, J.-L. A new formalism that combines advantages of fault-trees and Markov models: Boolean logic driven Markov processes. Reliab. Eng. Syst. Saf. 2003, 82, 149–163. [Google Scholar] [CrossRef]
- Kabir, S.; Papadopoulos, Y.; Walker, M.; Parker, D.; Aizpurua, J.I.; Lampe, J.; Rüde, E. A Model-Based Extension to HiP-HOPS for Dynamic Fault Propagation Studies. In Model-Based Safety and Assessment; Springer: Cham, Switzerland, 2017; pp. 163–178. [Google Scholar]
- Bozzano, M.; Cimatti, A.; Katoen, J.-P.; Nguyen, V.Y.; Noll, T.; Roveri, M. The COMPASS approach: Correctness, modelling and performability of aerospace systems. In Proceedings of the International Conference on Computer Safety, Reliability, and Security, Hamburg, Germany, 15–18 September 2009; pp. 173–186. [Google Scholar]
- Dionysiou, K.; Bolbot, V.; Theotokatos, G. A functional model-based approach for ship systems safety and reliability analysis: Application to a cruise ship lubricating oil system. Proc. Inst. Mech. Eng. Part M J. Eng. Marit. Environ. 2021. [Google Scholar] [CrossRef]
- Milioulis, K.; Bolbot, V.; Theotokatos, G. Model-based safety analysis and design enhancement of a marine LNG fuel feeding system. J. Mar. Sci. Eng. 2021, 9, 69. [Google Scholar] [CrossRef]
- Niculita, O.; Nwora, O.; Skaf, Z. Towards Design of Prognostics and Health Management Solutions for Maritime Assets. Procedia CIRP 2017, 59, 122–132. [Google Scholar] [CrossRef]
- Bolbot, V.; Theotokatos, G.; Boulougouris, E.; Psarros, G.; Hamann, R. A novel method for safety analysis of Cyber-Physical Systems—Application to a ship exhaust gas scrubber system. Safety 2020, 6, 26. [Google Scholar] [CrossRef]
- Bolbot, V.; Theotokatos, G.; Boulougouris, E.; Psarros, G.; Hamann, R. A Combinatorial Safety Analysis of Cruise Ship Diesel–Electric Propulsion Plant Blackout. Safety 2021, 7, 38. [Google Scholar] [CrossRef]
- Bolbot, V.; Theotokatos, G.; Vassalos, D. Using system-theoretic process analysis and event tree analysis for creation of a fault tree of blackout in the Diesel-Electric Propulsion system of a cruise ship. In Proceedings of the International Marine Design Conference XIII, Helsinki, Finland, 10–14 June 2018; pp. 691–699. [Google Scholar]
- OREDA. Offshore Reliability Data Handbook, 6th ed.; OREDA Participants: Hovik, Norway, 2015. [Google Scholar]
- Knutsen, K.; Manno, G.; Vartdal, B. Beyond Condition Monitoring in the Maritime Industry; DNV GL Strategic Research & Inovation Position Paper; DNV GL: Hovik, Norway, 12 September 2014. [Google Scholar]
- Jürgensen, J.H.; Godin, A.S.; Hilber, P. Health index as condition estimator for power system equipment: A critical discussion and case study. CIRED-Open Access Proc. J. 2017, 2017, 202–205. [Google Scholar] [CrossRef][Green Version]
- Bohatyrewicz, P.; Płowucha, J.; Subocz, J. Condition Assessment of Power Transformers Based on Health Index Value. Appl. Sci. 2019, 9, 4877. [Google Scholar] [CrossRef]
- Aizpurua, J.I.; Stewart, B.G.; McArthur, S.D.; Jajware, N.; Kearns, M. Towards a hybrid power cable health index for medium voltage power cable condition monitoring. In Proceedings of the 37th IEEE Electrical Insulation Conference, Calgary, AB, Canada, 16–19 June 2019. [Google Scholar]
- Goebel, K.; Daigle, M.; Saxena, A.; Sankararaman, S.; Roychoudhury, I.; Celaya, J.R. Prognostics the Science of Prediction; Create Space Independent Publishing Platform: Charleston, SC, USA, 2017; p. 396. [Google Scholar]
- Hafver, A.; Pedersen, F.B.; Jakopanec, I.; Oliveira, L.; Domingues, J.; Eldevik, S.; Lindberg, D.V. Dynamic RISK Management for Enhanced Safety; DNV GL AS: Høvik, Norway, 2017. [Google Scholar]
- Mutunga, J.M.; Kimotho, J.K.; Muchiri, P. Health-Index Based Prognostics for a Turbofan Engine using Ensemble of Machine Learning Algorithms. J. Sustain. Res. Eng. 2019, 5, 50–61. [Google Scholar]
- EMSA. Risk Acceptance Criteria and Risk Based Damage Stability. Final Report, Part 1: Risk Acceptance Criteria. 2015. Available online: http://emsa.europa.eu/about/308-management/2419-study-1-emsa-3-risk-acceptance-criteria-and-risk-based-damage-stability-part-1-part-2.html (accessed on 1 June 2020).
- Schüller, J.; Brinkman, J.; Van Gestel, P.J.; Van Otterloo, R. Methods for Determining and Processing Probabilities: Red Book; Committee for the Prevention of Disasters: Arnhem, The Netherlands, 1997. [Google Scholar]
- Ådnanes, A.K. Maritime Electrical Installations and Diesel Electric Propulsion; ABB: Oslo, Norway, 2003; p. 86. [Google Scholar]
- Kongsberg. Power Management System. Available online: https://www.km.kongsberg.com/ks/web/nokbg0397.nsf/AllWeb/B759133464F70B12C1256DEB0039EBCD/$file/AD-00447B_PMS_datasheet.pdf?OpenElement (accessed on 1 June 2017).
- Radan, D. Integrated Control of Marine Electrical Power Systems. Ph.D. Thesis, Norwegian University of Science and Technology, Trondheim, Norway, 2008. [Google Scholar]
- MAN. Diesel-Electric Propulsion Plants; MAN, 2012. [Google Scholar]
- Krogseth, I.B. Dynamic Fault-Detection in Shipboard Electric Load Sharing; Norwegian University of Science and Technology: Trondheim, Norway, 2013. [Google Scholar]
- Meyle. Arc Detection System. Available online: http://www.meyle.com.cn/pdf/arc-detection-systems.pdf (accessed on 1 September 2017).
- Sfakianakis, K.; Vassalos, D. Design for safety and energy efficiency of the electrical onboard energy systems. In Proceedings of the 2015 IEEE Electric Ship Technologies Symposium, Washington, DC, USA, 21–24 June 2015; pp. 150–155. [Google Scholar]
- AUTOSHIP. Autonomous Shipping Initiative for European Waters. Available online: https://www.autoship-project.eu/ (accessed on 1 January 2020).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Warning Levels | Range |
|---|---|
| Red | [ × 5, × 50] |
| Orange | [ × 0.2, × 5] |
| Yellow | [ × 0.02, × 0.5] |
| Green | [ × 0.002, × 0.05] |
| System Components | Original Fault Tree Probability [30] | Modified Fault Tree Probability Estimation (Used for Simulation) | |
|---|---|---|---|
| Operating components | Software, hardware, communication and sensors failures following exponential distribution for failure rate [41] | t | |
| Other components with preventative maintenance following Weibull distribution for failure rate | |||
| Parts with preventive maintenance where a single component failure out of identical will lead to event occurence (based on [41]) | Replaced with OR gates connecting components failures. Each component failure rate is modelled by | ||
| Parts with preventive maintenance where all the identical components must fail for event occurrence (based on [41]) | Replaced with AND gates connecting components failures. Each component state is modelled as a Markov process, whereas each component failure rate is estimated by | ||
| Safety systems | Tested standby equipment failure on demand (except for software failures) [41] | ||
| For safety system/functions with continuous monitoring failure on demand [41] | Modelled as Markov process | ||
| Safety functions with periodical testing failure on demand [41] | |||
| For software failures in safety functions [41] | |||
| Unavailability due to periodical maintenance of standby equipment where components are standby (based on [41]) | Replaced with AND gate connecting components failures. Each component failure rate is estimated by Equation (8) and each component state is modelled as a Markov process. |
| Case Study No. | Analysis Conducted | |
|---|---|---|
| 1 | 0 | Estimation of PoB every 0.5 h for 168 h (7 days, 1 week) with horizon prediction ( of 24 h |
| 2 | 0.5 | Estimation of PoB every 0.5 h for 168 h (7 days, 1 week) with horizon prediction () of 24 h and importance analysis every 24 h |
| 3 | 1 | Estimation of PoB every 0.5 h for 168 h (7 days, 1 week) with horizon prediction ( of 24 h |
| a/a | Component | Normal/Alarm Value | MI * (hours) | |
|---|---|---|---|---|
| 1 | Engine Thrust bearings | Temperature | 80/100 °C | 18,000 |
| 2 | Engine Main bearings | Temperature | 80/100 °C | 18,000 |
| 3 | DG engine high temperature cooling water pump | Pressure at engine inlet | 4/2 bar | 10,000 |
| 4 | DG set engine low temperature cooling water pump | Pressure at engine inlet | 3.6/2 bar | 10,000 |
| 5 | Engine low temperature cooling water pump | Pressure | 3.6/2 bar | 10,000 |
| 6 | Cylinders Exhaust gas | Temperature at exhaust gas port | 450/490 °C | 6000 |
| 7 | Turbocharger (TC) | Temperature at turbine inlet | 450/490 °C | 12,000 |
| 8 | Engine lubricating oil cooler | Temperature at engine inlet | 70/80 °C | 10,000 |
| 9 | Lubricating oil pump | Pressure at engine inlet | 4/3 bar | 5000 |
| Component or Software Function Failure | Type of Failure | |
|---|---|---|
| Power Management System failure to reduce load of propulsion motors | 0.0047 | Software |
| Arc protection software failure | 1.21 × 10−9 | Software |
| Arc in switchboards N1 and N2 | 0.0072 | Physical |
| DG 1 water cooler failure | 0.0004 | Physical |
| DG 1 Engine lubricating oil cooler | 0.0004 | Physical |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bolbot, V.; Theotokatos, G.; Hamann, R.; Psarros, G.; Boulougouris, E. Dynamic Blackout Probability Monitoring System for Cruise Ship Power Plants. Energies 2021, 14, 6598. https://doi.org/10.3390/en14206598
Bolbot V, Theotokatos G, Hamann R, Psarros G, Boulougouris E. Dynamic Blackout Probability Monitoring System for Cruise Ship Power Plants. Energies. 2021; 14(20):6598. https://doi.org/10.3390/en14206598
Chicago/Turabian StyleBolbot, Victor, Gerasimos Theotokatos, Rainer Hamann, George Psarros, and Evangelos Boulougouris. 2021. "Dynamic Blackout Probability Monitoring System for Cruise Ship Power Plants" Energies 14, no. 20: 6598. https://doi.org/10.3390/en14206598
APA StyleBolbot, V., Theotokatos, G., Hamann, R., Psarros, G., & Boulougouris, E. (2021). Dynamic Blackout Probability Monitoring System for Cruise Ship Power Plants. Energies, 14(20), 6598. https://doi.org/10.3390/en14206598