
Twin-Delayed Deep Deterministic Policy Gradient for Low-Frequency Oscillation Damping Control


Abstract
:1. Introduction
2. Background
2.1. The Principles of RL Algorithms
2.2. DDPG Algorithm
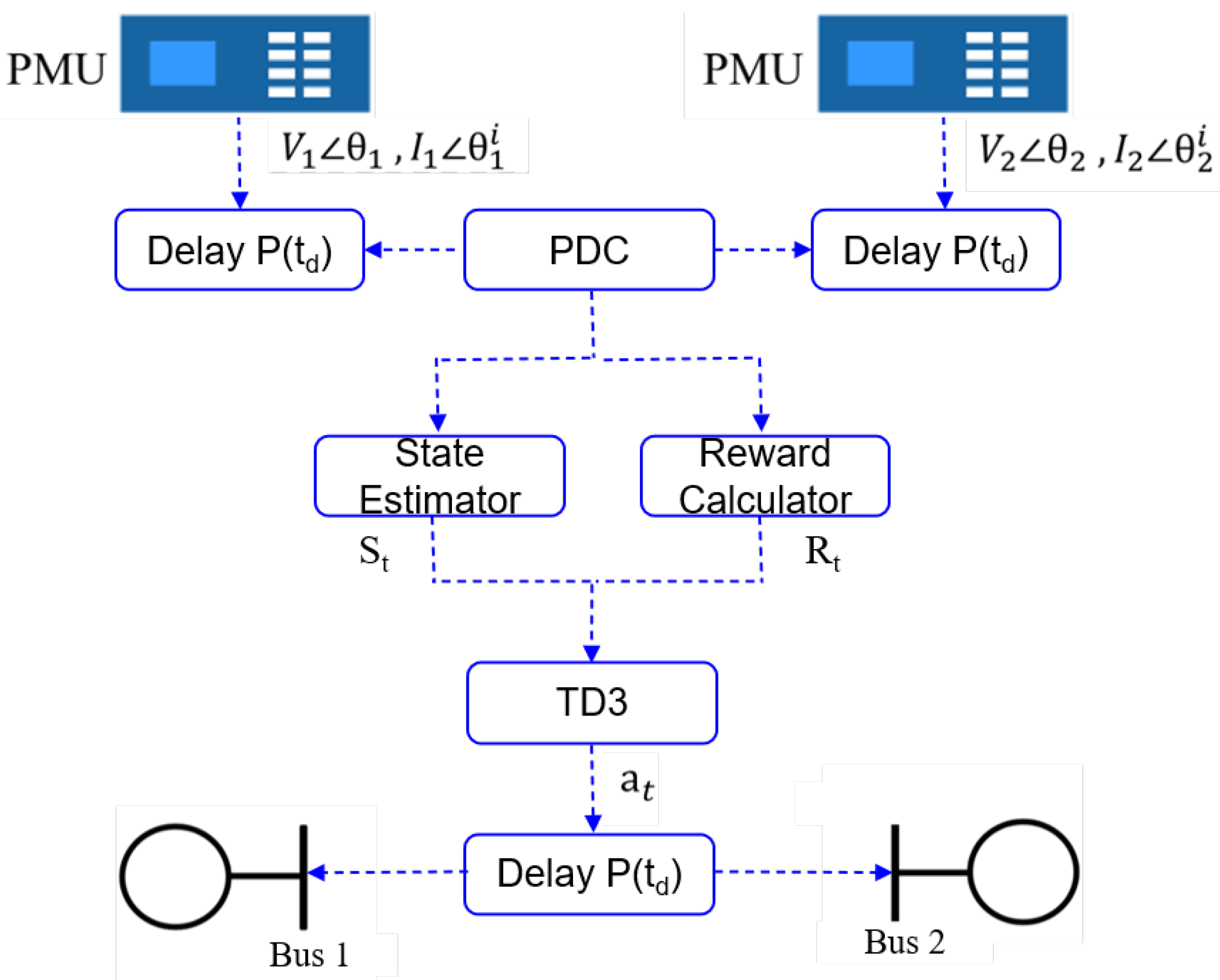
3. Reinforcement Learning Based Controller
3.1. State of the Controller
3.2. Action of the Controller
3.3. Reward Design for Enhanced Control Results
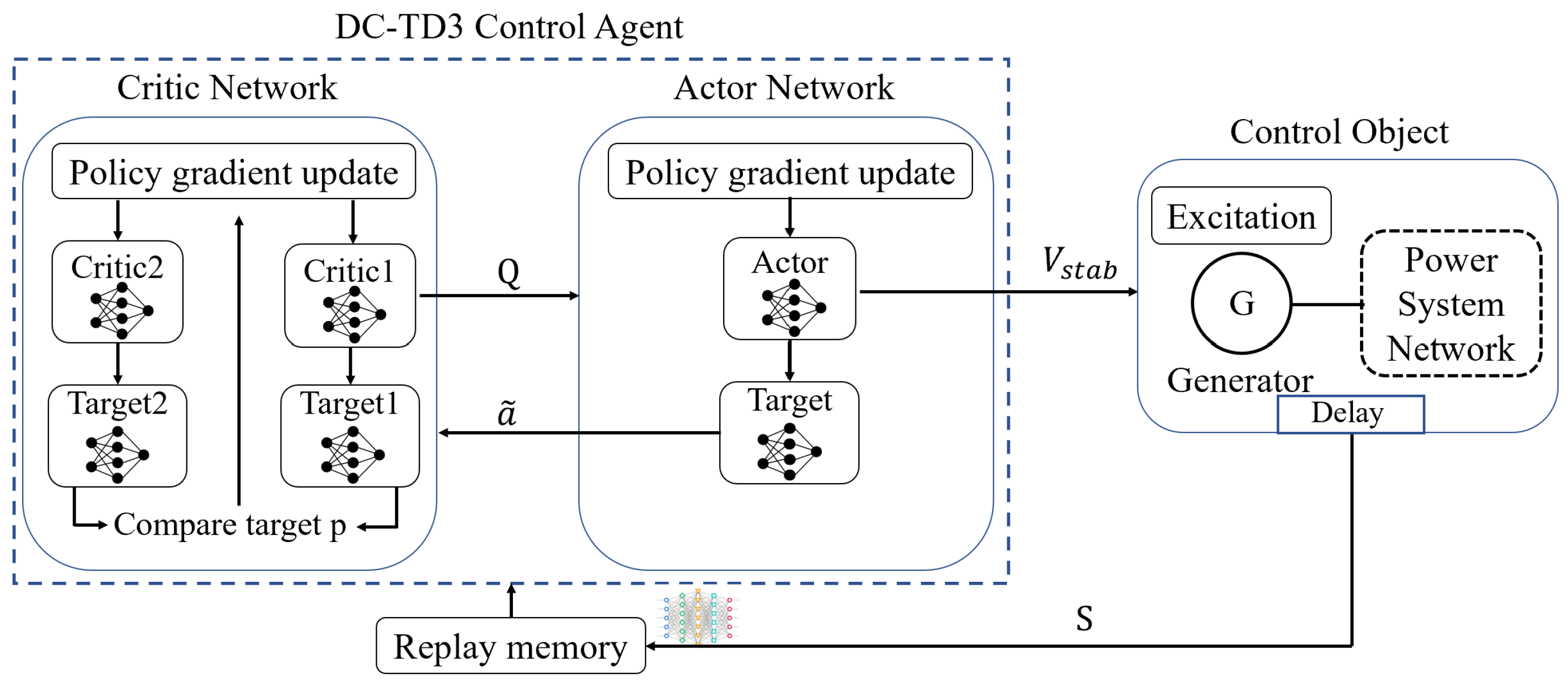
3.4. Twin-Delayed Deep Deterministic Policy Gradient Method
3.5. Avoid the Overestimation Bias
4. Numerical Validation
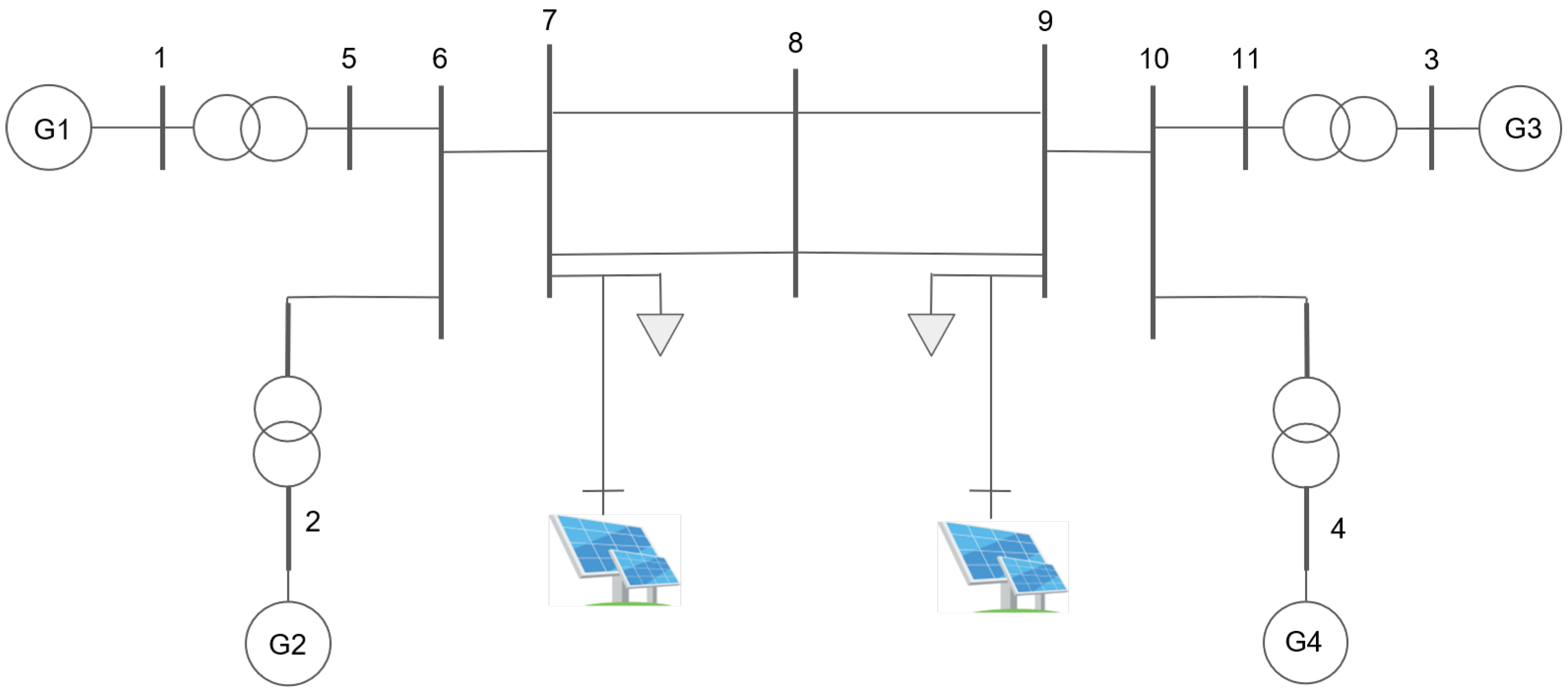
4.1. Benchmark System
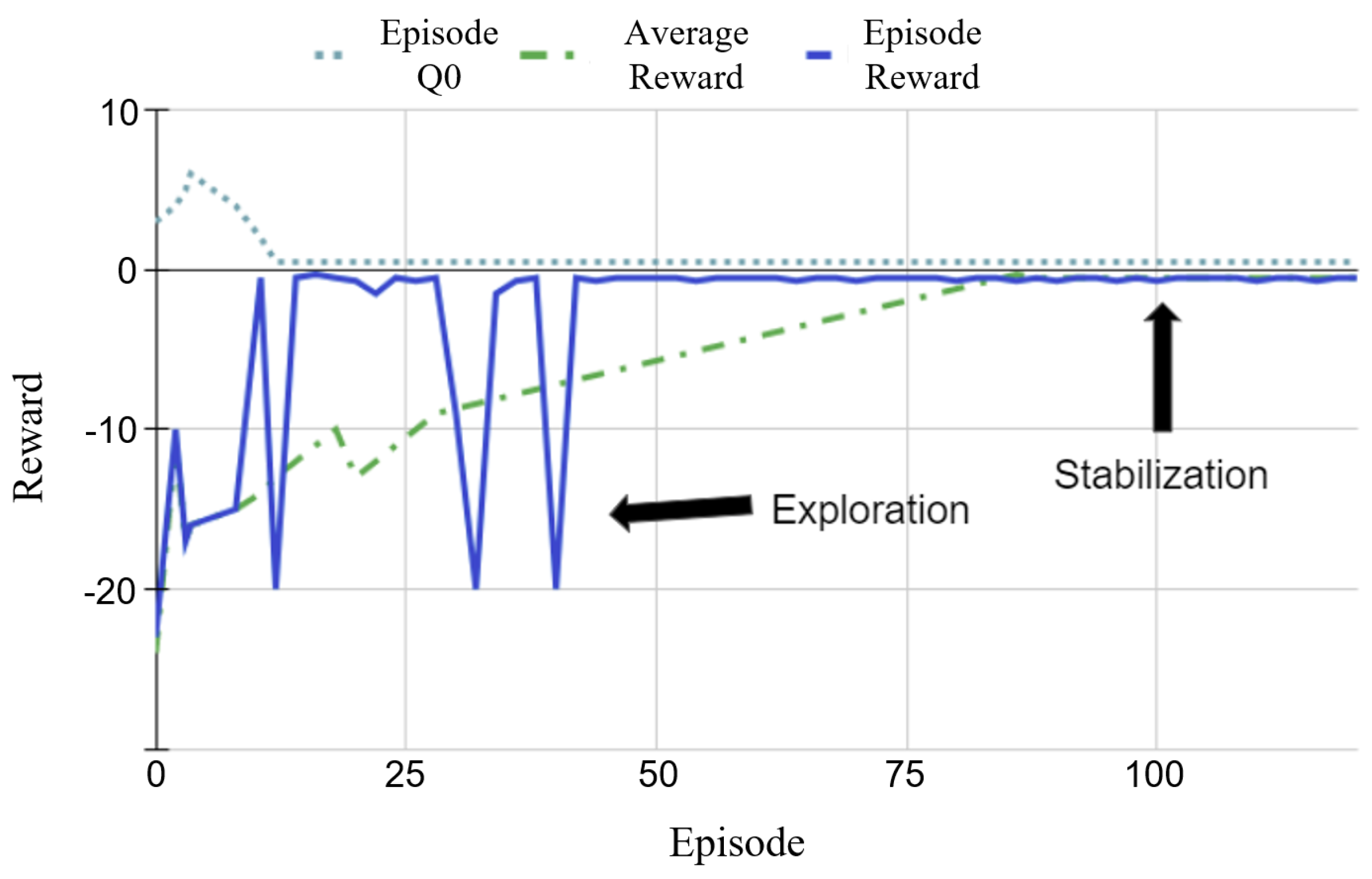
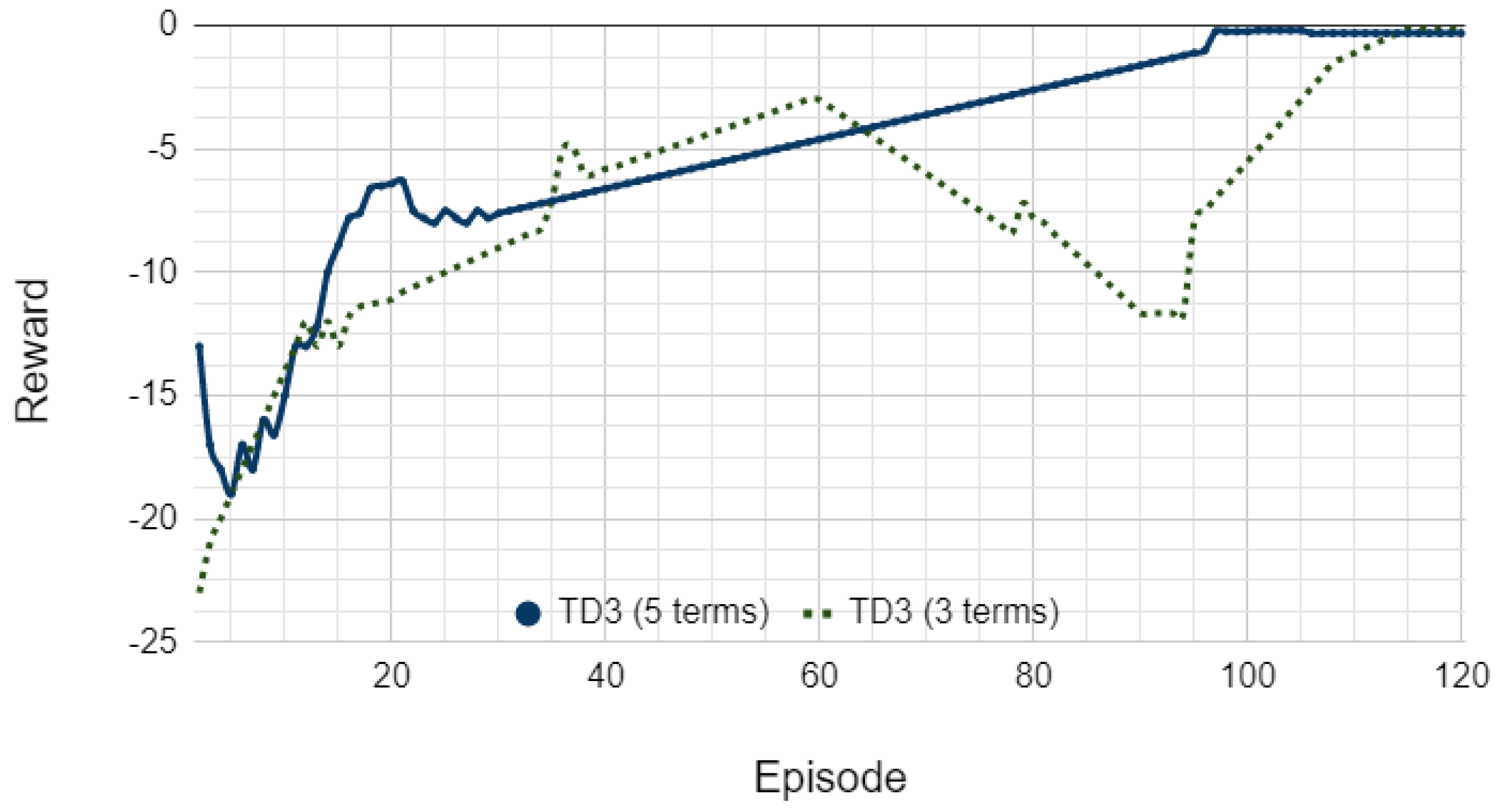
4.2. Twin-Delayed Deep Deterministic Policy Gradient Control Agent: Fast Learning Curve
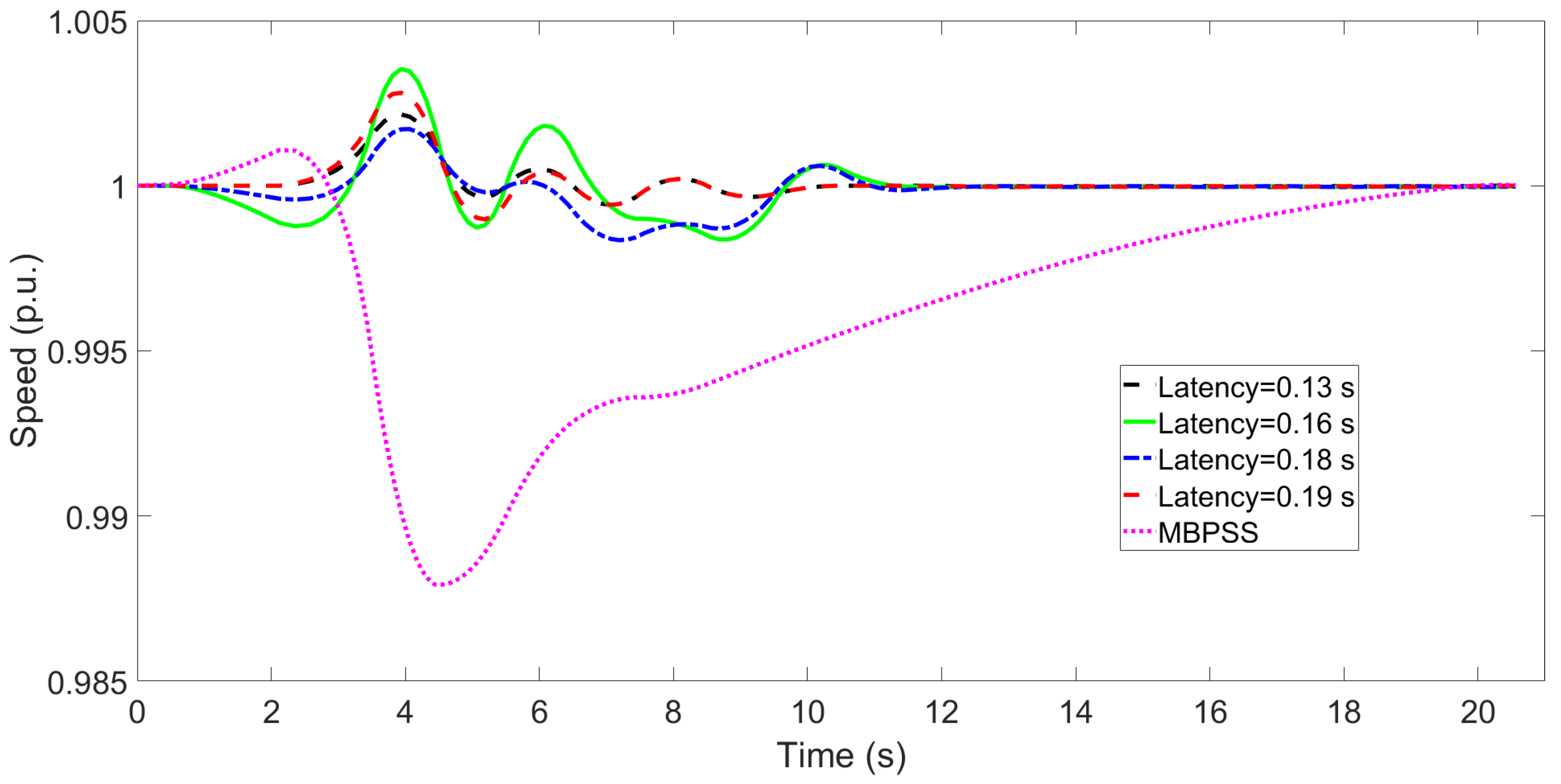
4.3. Control Agent: Robust to Communication Latency
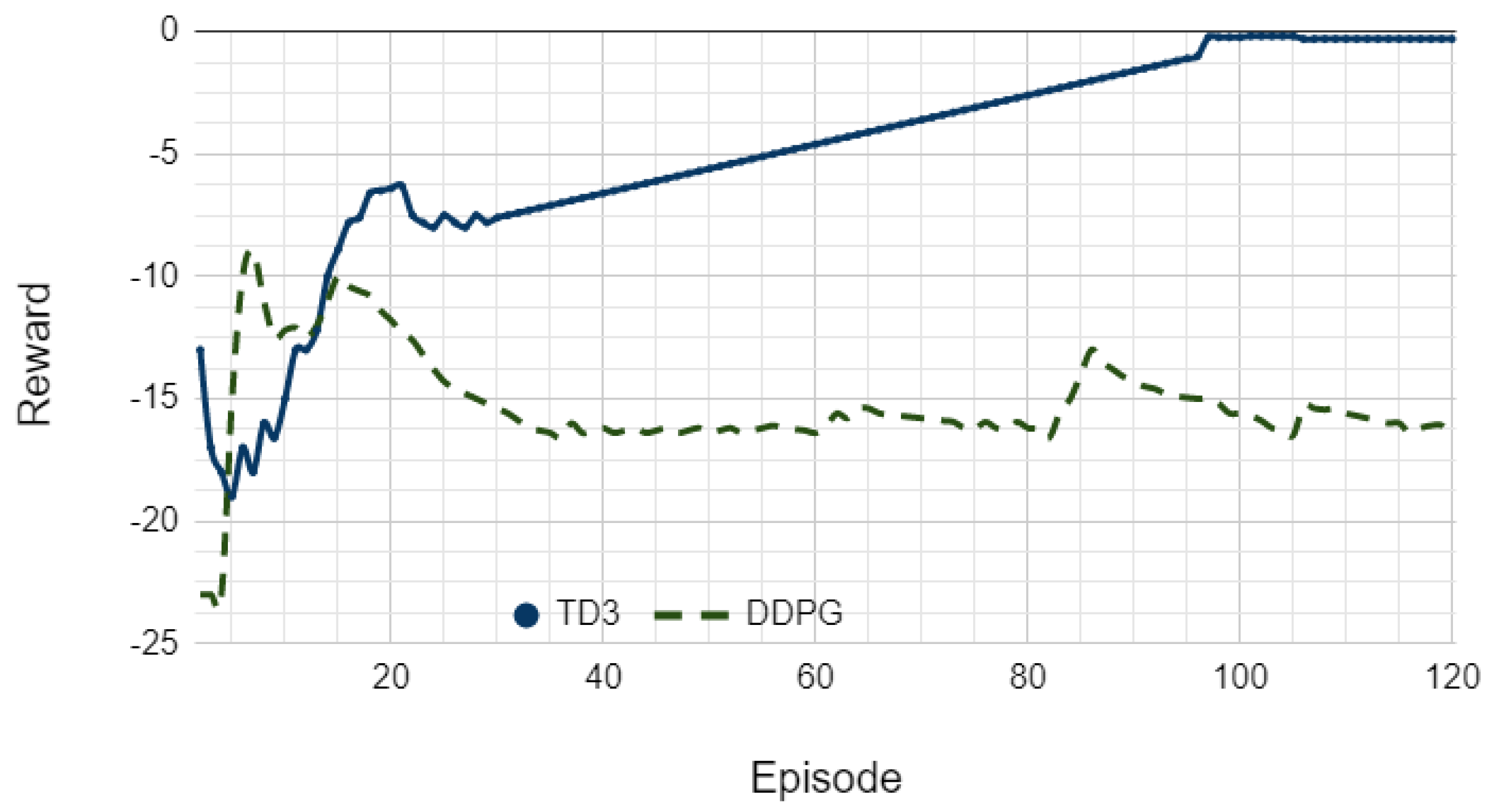
4.4. Performance Comparison with DDPG
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. The Parameters of Four Testing Scenarios

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean (ms) | Variance | |
|---|---|---|
| S1 | 130 | |
| S2 | 160 | |
| S3 | 180 | |
| S4 | 190 |
References
- Yohanandhan, R.V.; Srinivasan, L. Decentralized Wide-Area Neural Network Predictive Damping Controller for a Large-scale Power System. In Proceedings of the IEEE International Conference on Power Electronics, Drives and Energy Systems, Chennai, India, 18–21 December 2018; pp. 1–6. [Google Scholar]
- Andersson, G.; Donalek, P.; Farmer, R.; Hatziargyriou, N.; Kamwa, I.; Kundur, P.; Martins, N.; Paserba, J.; Pourbeik, P.; Sanchez-Gasca, J.; et al. Causes of the 2003 major grid blackouts in North America and Europe, and recommended means to improve system dynamic performance. IEEE Trans. Power Syst. 2005, 20, 1922–1928. [Google Scholar] [CrossRef]
- Azad, S.P.; Iravani, R.; Tate, J.E. Damping inter-area oscillations based on a model predictive control HVDC supplementary controller. IEEE Trans. Power Syst. 2013, 28, 3174–3183. [Google Scholar] [CrossRef]
- Klein, M.; Rogers, G.J.; Kundur, P. A fundamental study of inter-area oscillations in power systems. IEEE Trans. Power Syst. 1991, 6, 914–921. [Google Scholar] [CrossRef]
- Zenelis, I.; Wang, X. Wide-Area Damping Control for Interarea Oscillations in Power Grids Based on PMU Measurements. IEEE Control Syst. Lett. 2018, 2, 719–724. [Google Scholar] [CrossRef]
- Aboul-Ela, M.E.; Sallam, A.A.; McCalley, J.D.; Fouad, A.A. Damping controller design for power system oscillations using global signals. IEEE Trans. Power Syst. 1996, 11, 767–773. [Google Scholar] [CrossRef]
- Zhang, S.; Vittal, V. Design of wide-area power system damping controllers resilient to communication failures. IEEE Trans. Power Syst. 2013, 28, 4292–4300. [Google Scholar] [CrossRef]
- Kamwa, I.; Grondin, R.; Hebert, Y. Wide-area measurement based stabilizing control of large power systems—A decentralized/hierarchical approach. IEEE Trans. Power Syst. 2001, 16, 136–153. [Google Scholar] [CrossRef]
- Ma, J.; Wang, T.; Wang, Z.; Thorp, J.S. Adaptive Damping Control of Inter-Area Oscillations Based on Federated Kalman Filter Using Wide Area Signals. IEEE Trans. Power Syst. 2013, 28, 1627–1635. [Google Scholar] [CrossRef]
- Erlich, I.; Hashmani, A.; Shewarega, F. Selective damping of inter area oscillations using phasor measurement unit signals. In Proceedings of the IEEE Trondheim PowerTech, Trondheim, Norway, 19–23 June 2011; pp. 1–6. [Google Scholar]
- Hashmy, Y.; Yu, Z.; Shi, D.; Weng, Y. Wide-area measurement system-based low frequency oscillation damping control through reinforcement learning. IEEE Trans. Smart Grid 2020, 11, 5072–5083. [Google Scholar] [CrossRef]
- Vu, T.L.; Turitsyn, K. Lyapunov Functions Family Approach to Transient Stability Assessment. IEEE Trans. Power Syst. 2016, 31, 1269–1277. [Google Scholar] [CrossRef] [Green Version]
- Roy, S.; Patel, A.; Kar, I.N. Analysis and Design of a Wide-Area Damping Controller for Inter-Area Oscillation with Artificially Induced Time Delay. IEEE Trans. Smart Grid 2019, 10, 3654–3663. [Google Scholar] [CrossRef]
- Bento, M.E.C. Fixed Low-Order Wide-Area Damping Controller Considering Time Delays and Power System Operation Uncertainties. IEEE Trans. Power Syst. 2020, 35, 3918–3926. [Google Scholar] [CrossRef]
- Lu, C.; Zhang, X.; Wang, X.; Han, Y. Mathematical Expectation Modeling of Wide-Area Controlled Power Systems with Stochastic Time Delay. IEEE Trans. Smart Grid 2015, 6, 1511–1519. [Google Scholar] [CrossRef]
- Mokhtari, M.; Aminifar, F.; Nazarpour, D.; Golshannavaz, S. Wide-area power oscillation damping with a fuzzy controller compensating the continuous communication delays. IEEE Trans. Power Syst. 2013, 28, 1997–2005. [Google Scholar] [CrossRef]
- Surinkaew, T.; Ngamroo, I. Inter-Area Oscillation Damping Control Design Considering Impact of Variable Latencies. IEEE Trans. Power Syst. 2019, 34, 481–493. [Google Scholar] [CrossRef]
- Yu, S.S.; Chau, T.K.; Fernando, T.; Iu, H.H.C. An Enhanced Adaptive Phasor Power Oscillation Damping Approach with Latency Compensation for Modern Power Systems. IEEE Trans. Power Syst. 2018, 33, 4285–4296. [Google Scholar] [CrossRef]
- Roberson, D.; O’Brien, J.F. Variable Loop Gain Using Excessive Regeneration Detection for a Delayed Wide-Area Control System. IEEE Trans. Smart Grid 2018, 9, 6623–6632. [Google Scholar] [CrossRef]
- Yao, W.; Jiang, L.; Wen, J.; Wu, Q.H.; Cheng, S. Wide-Area Damping Controller of FACTS Devices for Inter-Area Oscillations Considering Communication Time Delays. IEEE Trans. Power Syst. 2014, 29, 318–329. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Chen, Y. A Wide-Area Dynamic Damping Controller Based on Robust H∞ Control for Wide-Area Power Systems with Random Delay and Packet Dropout. IEEE Trans. Power Syst. 2018, 33, 4026–4037. [Google Scholar] [CrossRef]
- Liu, H.; Zhu, L.; Pan, Z.; Bai, F.; Liu, Y.; Liu, Y.; Patel, M.; Farantatos, E.; Bhatt, N. ARMAX-Based Transfer Function Model Identification Using Wide-Area Measurement for Adaptive and Coordinated Damping Control. IEEE Trans. Smart Grid 2017, 8, 1105–1115. [Google Scholar] [CrossRef]
- Vahidnia, A.; Ledwich, G.; Palmer, E.W. Transient Stability Improvement through Wide-Area Controlled SVCs. IEEE Trans. Power Syst. 2016, 31, 3082–3089. [Google Scholar] [CrossRef]
- Bian, X.Y.; Geng, Y.; Lo, K.L.; Fu, Y.; Zhou, Q.B. Coordination of PSSs and SVC Damping Controller to Improve Probabilistic Small-Signal Stability of Power System with Wind Farm Integration. IEEE Trans. Power Syst. 2016, 31, 2371–2382. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Shi, Z.; Huang, Y.; Qiu, C.; Yang, S. SVC damping controller design based on novel modified fruit fly optimisation algorithm. IET Renew. Power Gener. 2018, 12, 90–97. [Google Scholar] [CrossRef]
- Lala, J.A.O.; Gallardo, C.F. Adaptive Tuning of Power System Stabilizer Using a Damping Control Strategy Considering Stochastic Time Delay. IEEE Access 2020, 8, 124254–124264. [Google Scholar] [CrossRef]
- Shi, X.; Cao, Y.; Shahidehpour, M.; Li, Y.; Wu, X.; Li, Z. Data-Driven Wide-Area Model-Free Adaptive Damping Control with Communication Delays for Wind Farm. IEEE Trans. Smart Grid 2020, 11, 5062–5071. [Google Scholar] [CrossRef]
- Jhang, S.; Lee, H.; Kim, C.; Song, C.; Yu, W. ANN Control for Damping Low-frequency Oscillation using Deep learning. In Proceedings of the IEEE Australasian Universities Power Engineering Conference, Auckland, New Zealand, 27–30 November 2018; pp. 1–4. [Google Scholar]
- Duan, J.; Xu, H.; Liu, W. Q-Learning-Based Damping Control of Wide-Area Power Systems Under Cyber Uncertainties. IEEE Trans. Smart Grid 2018, 9, 6408–6418. [Google Scholar] [CrossRef]
- Araghi, S.; Khosravi, A.; Johnstone, M.; Creighton, D.C. A novel modular Q-learning architecture to improve performance under incomplete learning in a grid soccer game. Eng. Appl. Artif. Intell. 2013, 26, 2164–2171. [Google Scholar] [CrossRef]
- Das, P.; Behera, D.H.; Panigrahi, B. Intelligent-based multi-robot path planning inspired by improved classical Q-learning and improved particle swarm optimization with perturbed velocity. Eng. Sci. Technol. Int. J. 2016, 19, 651–669. [Google Scholar] [CrossRef] [Green Version]
- Shinohara, S.; Takano, T.; Takase, H.; Kawanaka, H.; Tsuruoka, S. Search Algorithm with Learning Ability for Mario AI—Combination A* Algorithm and Q-Learning. In Proceedings of the Australasian Conference on Information Systems International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing, Kyoto, Japan, 8–10 August 2012; pp. 341–344. [Google Scholar]
- Cui, Q.; Hashmy, S.M.Y.; Weng, Y.; Dyer, M. Reinforcement Learning Based Recloser Control for Distribution Cables with Degraded Insulation Level. IEEE Trans. Power Deliv. 2020, 36, 1118–1127. [Google Scholar] [CrossRef]
- Szepesvari, C.; Sutton, R.S.; Modayil, J.; Bhatnagar, S. Universal Option Models. In Proceedings of the 28th Annual Conference Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 990–998. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.M.O.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.; Veness, J.; Bellemare, M.; Graves, A.; Riedmiller, M.; Fidjeland, A.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529. [Google Scholar] [CrossRef] [PubMed]
- Simon, L.; Swarup, K.S.; Ravishankar, J. Wide area oscillation damping controller for DFIG using WAMS with delay compensation. IET Renew. Power Gener. 2019, 13, 128–137. [Google Scholar] [CrossRef]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1587–1596. [Google Scholar]
- Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Kamwa, I.; Trudel, G.; Gerin-Lajoie, L. Robust design and coordination of multiple damping controllers using nonlinear constrained optimization. IEEE Trans. Power Syst. 2000, 15, 1084–1092. [Google Scholar] [CrossRef]
- Younis, M.R.; Iravani, R. Wide-area damping control for inter-area oscillations: A comprehensive review. In Proceedings of the IEEE Electrical Power & Energy Conference, Halifax, NS, Canada, 21–23 August 2013; pp. 1–6. [Google Scholar]
- Kamwa, I.; Grondin, R.; Trudel, G. IEEE PSS2B versus PSS4B: The limits of performance of modern power system stabilizers. IEEE Trans. Power Syst. 2005, 20, 903–915. [Google Scholar] [CrossRef]

| Name | Value |
|---|---|
| Generator | 20 kV/900 MVA |
| Synchronous machine inertia | 6.5 s, 6.175 s |
| Thermal plant exciter gain | 200 |
| Solar capacity (PV1, PV2) | 100 MW |
| Surge impedance loading | 140 MW |
| Area 2 power generation | 700 MW |
| Parameter Type | Value |
|---|---|
| Number of input states | 12 |
| Number of output actions | 4 |
| Discount factor | |
| Sample time (sec) | |
| Replay memory | 500,000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, Q.; Kim, G.; Weng, Y. Twin-Delayed Deep Deterministic Policy Gradient for Low-Frequency Oscillation Damping Control. Energies 2021, 14, 6695. https://doi.org/10.3390/en14206695
Cui Q, Kim G, Weng Y. Twin-Delayed Deep Deterministic Policy Gradient for Low-Frequency Oscillation Damping Control. Energies. 2021; 14(20):6695. https://doi.org/10.3390/en14206695
Chicago/Turabian StyleCui, Qiushi, Gyoungjae Kim, and Yang Weng. 2021. "Twin-Delayed Deep Deterministic Policy Gradient for Low-Frequency Oscillation Damping Control" Energies 14, no. 20: 6695. https://doi.org/10.3390/en14206695