
A Surrogate Weather Generator for Estimating Natural Gas Design Day Conditions

Abstract
:1. Introduction
2. Background
2.1. Generating Extreme Weather
2.2. Design Day Conditions
2.3. Methods for Determining Design Day Conditions
3. Surrogate Weather Resampler Method
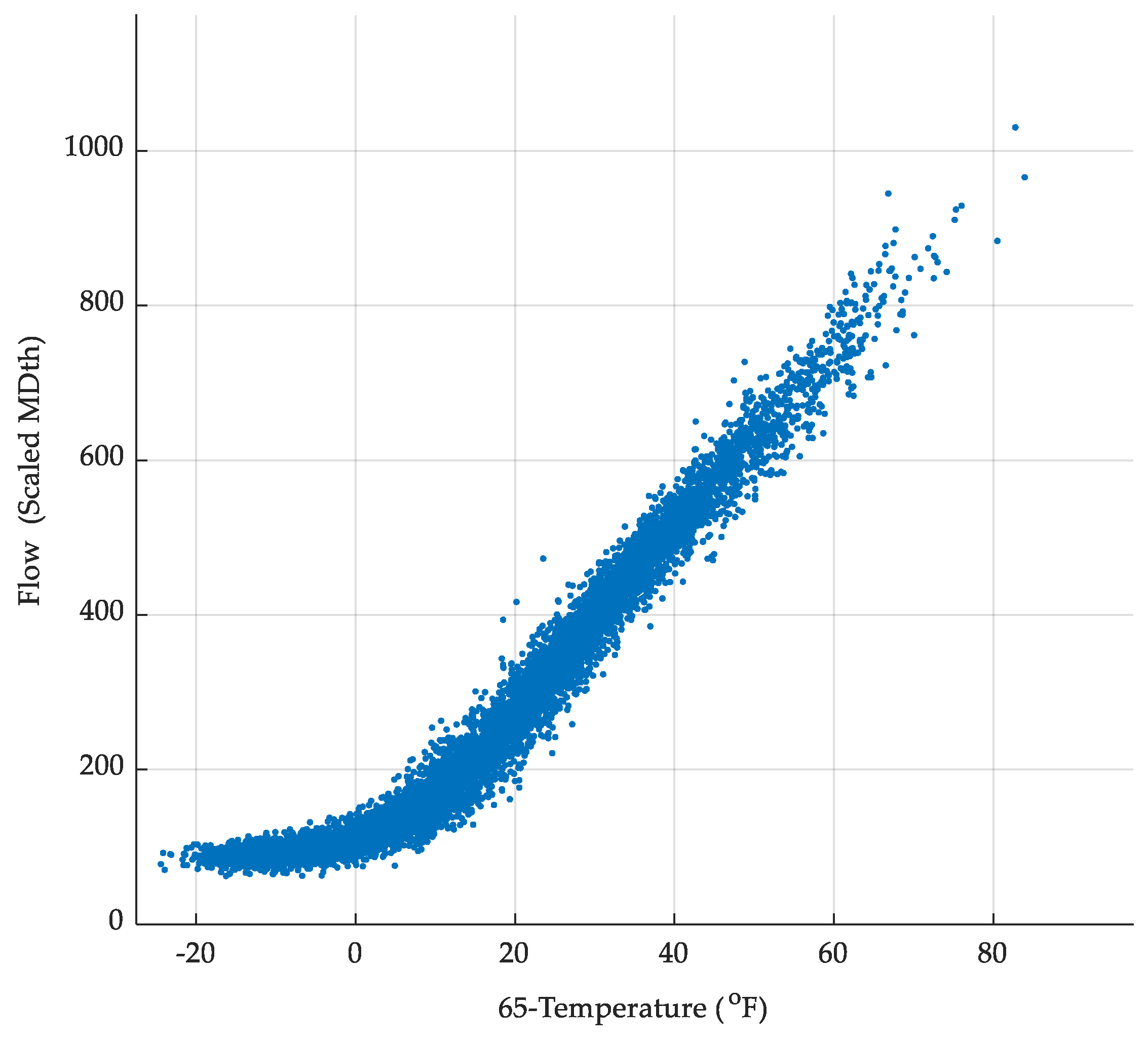
3.1. Modeling Temperature
3.2. Resampling the Scaled Deviation from Normal Temperature
4. Experiments—Comparison of SWR, Naïve Benchmark, and WeaGETS
4.1. Dataset
4.2. Data Preprocessing
4.3. In-Sample Experiment
4.4. Out-of-Sample Experiment
5. Results
5.1. In-Sample Results
5.1.1. Comparing Distributions of Cold Temperatures
5.1.2. Frequency of Exceedance Test
5.2. Out of Sample Results
5.2.1. Out of Sample KS-Test
5.2.2. Out of Sample Frequency of Exceedance Test
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, J.; Brissette, F.P.; Leconte, R. WeaGETS—A Matlab-Based Daily Scale Weather Generator for Generating Precipitation and Temperature. Procedia Environ. Sci. 2012, 13, 2222–2235. [Google Scholar] [CrossRef] [Green Version]
- American Gas Association. Glossary-D. Available online: https://www.aga.org/natural-gas/glossary/d/ (accessed on 11 August 2021).
- Lee, A. Extreme Cold in the Midwest Led to High Power Demand and Record Natural Gas Demand. Available online: https://www.eia.gov/todayinenergy/detail.php?id=38472 (accessed on 11 August 2021).
- Regulators Knew of Freeze Risk to Texas’ Natural Gas System. It Still Crippled Power Generation. Available online: https://www.houstonchronicle.com/business/energy/article/freeze-risk-texas-natural-gas-supply-system-power-16020457.php (accessed on 21 September 2021).
- Navigant Consulting. Analysis of Peak Gasday Design Criteria; Navigant Consulting: Toronto, ON, Canada, 2011. [Google Scholar]
- Oracle Crystal Ball. Available online: https://www.oracle.com/middleware/technologies/crystalball.html (accessed on 21 September 2021).
- Semenov, M.A. Simulation of Extreme Weather Events by a Stochastic Weather Generator. Clim. Res. 2008, 35, 203–212. [Google Scholar] [CrossRef] [Green Version]
- Tebaldi, C.; Hayhoe, K.; Arblaster, J.M.; Meehl, G.A. Going to the Extremes: An Intercomparison of Model-Simulated Historical and Future Changes in Extreme Events. Clim. Chang. 2006, 79, 185–211. [Google Scholar] [CrossRef]
- Oliver, R.; Duffy, A.; Enright, B.; O’Connor, R. Forecasting Peak-Day Consumption for Year-Ahead Management of Natural Gas Networks. Util. Policy 2017, 44, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Sarak, H.; Satman, A. The Degree-Day Method to Estimate the Residential Heating Natural Gas Consumption in Turkey: A Case Study. Energy 2003, 28, 929–939. [Google Scholar] [CrossRef]
- Aras, H.; Aras, N. Forecasting Residential Natural Gas Demand. Energy Sources 2004, 26, 463–472. [Google Scholar] [CrossRef]
- Vitullo, S.R.; Brown, R.H.; Corliss, G.F.; Marx, B.M. Mathematical Models for Natural Gas Forecasting. Can. Appl. Math. Quat. 2009, 17, 807–827. [Google Scholar]
- Ishola, B. Improving Gas Demand Forecast during Extreme Cold Events. Master’s. Thesis, Marquette University, Milwaukee, WI, USA, 2016. [Google Scholar]
- Columbia Gas of Pennsylvania. 2015 Summary Report; Columbia Gas of Pennsylvania: Canonsburg, PA, USA, 2015. [Google Scholar]
- Intermountain Gas Company. Integrated Resource Plan 2019–2023; Intermountain Gas Company: Boise, ID, USA, 2019. [Google Scholar]
- Cascade Natural Gas Corporation. 2016 Integrated Resource Plan; Cascade Natural Gas Corporation: Kennewick, WA, USA, 2017. [Google Scholar]
- Vermont Gas Systems. Integrated Resource Plan 2017; Vermont Gas Systems: South Burlington, VT, USA, 2017. [Google Scholar]
- Avista. 2018 Natural Gas Integrated Resource Plan; Avista: Spokane, WA, USA, 2018. [Google Scholar]
- American Gas Association. Winter Heating Season Energy Analysis; American Gas Association: Wasington, DC, USA, 2014. [Google Scholar]
- de Haan, L.; Ferreira, A.F. Extreme Value Theory: An Introduction; Springer: New York, NY, USA, 2006. [Google Scholar]
- Gross, J.; Heckert, A.; Lechner, J.; Simiu, E. Novel Extreme Value Estimation Procedures: Application to Extreme Wind Data. In Extreme Value Theory and Applications; Galambos, J., Lechner, J., Simiu, E., Eds.; Springer: Boston, MA, USA, 1994; pp. 139–158. [Google Scholar] [CrossRef]
- Smith, A.; Lott, N.; Vose, R. The Integrated Surface Database: Recent Developments and Partnerships. Bull. Am. Meteorol. Soc. 2011, 92, 704–708. [Google Scholar] [CrossRef]
- Breinl, K.; Turkington, T.; Stowasser, M. Simulating Daily Precipitation and Temperature: A Weather Generation Framework for Assessing Hydrometeorological Hazards. Meteorol. Appl. 2015, 22, 334–347. [Google Scholar] [CrossRef]
- Richardson, C.W. Stochastic Simulation of Daily Precipitation, Temperature, and Solar Radiation. Water Resour. Res. 1981, 17, 182–190. [Google Scholar] [CrossRef]
- Underwood, F.M. Describing Seasonal Variability in the Distribution of Daily Effective Temperatures for 1985–2009 Compared to 1904–1984 for De Bilt, Holland. Meteorol. Appl. 2013, 20, 394–404. [Google Scholar] [CrossRef]
- Mcmenamin, J.S. Defining Normal Weather for Energy and Peak Normalization. San Diego, CA, USA, 2008. Available online: www.itron.com/PublishedContent/DefiningNormalWeatherforEnergyandPeakNormalization.pdf (accessed on 21 September 2021).
- Qian, B.; Gameda, S.; Hayhoe, H.; De Jong, R.; Bootsma, A. Comparison of LARS-WG and AAFC-WG Stochastic Weather Generators for Diverse Canadian Climates. Clim. Res. 2004, 26, 175–191. [Google Scholar] [CrossRef] [Green Version]
- Tayebiyan, A.; Mohammad, T.A.; Ghazali, A.H.; Malek, M.A.; Mashohor, S. Potential Impacts of Climate Change on Precipitation and Temperature at Jor Dam Lake. Pertanika J. Sci. Technol. 2016, 24, 213–224. [Google Scholar]
- Semenov, M.A.; Welham, S. Comments on the Use of Statistical Tests in the Comparison of Stochastic Weather Generators by Qian et al. Clim. Res. 2004, 28, 83–84. [Google Scholar] [CrossRef] [Green Version]
- Xu, Q.; Liang, Y.-Z.; Du, Y.-P. Monte Carlo Cross-Validation for Selecting a Model and Estimating the Prediction Error in Multivariate Calibration. J. Chemom. 2004, 18, 112–120. [Google Scholar] [CrossRef]
- Xie, J.; Hong, T. Temperature Scenario Generation for Probabilistic Load Forecasting. IEEE Trans. Smart Grid 2018, 9, 1680–1687. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Survey | N < 16 | 16 <= N < 26 | 26 <= N < 36 | N >= 36 |
|---|---|---|---|---|
| Oliver [9] | 0 | 2 | 0 | 3 |
| Navigant [5] | 3 | 3 | 2 | 1 |
| AGA [19] | 5 | 10 | 27 | 0 |
| IRPs [14,15,16,17,18] | 1 | 0 | 2 | 2 |
| Total | 9 | 15 | 31 | 6 |
| Station Location | Callsign | Station Location | Callsign |
|---|---|---|---|
| Ottawa, ON | CYOW | Kansas City, MO | KMCI |
| Regina, SK | CYQR | Memphis, TN | KMEM |
| Vancouver, BC | CYVR | Miami, FL | KMIA |
| Winnipeg, MB | CYWG | Minneapolis, MN | KMSP |
| Calgary, AB | CYYC | New Orleans, LA | KMSY |
| Amarillo, TX | KAMA | New York, NY | KNYC |
| Aspen, CO | KASE | Pittsburg, PA | KPIT |
| Bakersfield, CA | KBFL | Pueblo, CO | KPUB |
| Nashville, TN | KBNA | Raleigh/Durham, NC | KRDU |
| Boston, MA | KBOS | San Antonio, TX | KSAT |
| Brownsville, TX | KBRO | Louisville, KY | KSDF |
| Corpus Christi, TX | KCRP | Seattle, WA | KSEA |
| Dallas-Fort Worth, TX | KDFW | Salt Lake City, UT | KSLC |
| Evansville, IN | KEVV | Tulsa, OK | KTUL |
| Fort Smith, AR | KFSM | King Salmon, AK | PAKN |
| Hays, KS | KHYS | Honolulu, HI | PHNL |
| Jackson, MS | KJAN |
| Station | Expected | SWR | WeaGETS | Station | Expected | SWR | WeaGETS |
|---|---|---|---|---|---|---|---|
| CYOW | 2.3 | 3 | 0 | KMCI | 2.3 | 2 | 0 |
| CYQR | 2.3 | 0 | 0 | KMEM | 2.3 | 2 | 0 |
| CYVR | 2.3 | 2 | 6 | KMIA | 2.3 | 2 | 1 |
| CYWG | 2.3 | 1 | 0 | KMSP | 2.3 | 0 | 0 |
| CYYC | 2.3 | 0 | 0 | KMSY | 2.3 | 5 | 0 |
| KAMA | 2.3 | 1 | 0 | KNYC | 2.3 | 2 | 0 |
| KASE | 2.3 | 2 | 3 | KPIT | 2.3 | 3 | 0 |
| KBFL | 2.3 | 2 | 0 | KPUB | 2.3 | 0 | 0 |
| KBNA | 2.3 | 1 | 1 | KRDU | 2.3 | 3 | 0 |
| KBOS | 2.3 | 1 | 0 | KSAT | 2.3 | 3 | 0 |
| KBRO | 2.3 | 2 | 0 | KSDF | 2.3 | 2 | 1 |
| KCRP | 2.3 | 2 | 0 | KSEA | 2.3 | 0 | 12 |
| KDFW | 2.3 | 1 | 0 | KSLC | 2.3 | 1 | 3 |
| KEVV | 2.3 | 1 | 0 | KTUL | 2.3 | 1 | 0 |
| KFSM | 2.3 | 3 | 0 | PAKN | 2.3 | 3 | 0 |
| KHYS | 2.3 | 1 | 0 | PHNL | 2.3 | 2 | 0 |
| KJAN | 2.3 | 4 | 0 | Sum | 74.9 | 58 | 27 |
| Station | Naïve | SWR | WeaGETS | Station | Naïve | SWR | WeaGETS |
|---|---|---|---|---|---|---|---|
| CYOW | 40 | 37 | 0 | KMCI | 42 | 40 | 0 |
| CYQR | 40 | 44 | 0 | KMEM | 38 | 40 | 0 |
| CYVR | 40 | 45 | 0 | KMIA | 43 | 44 | 0 |
| CYWG | 42 | 45 | 0 | KMSP | 32 | 39 | 0 |
| CYYC | 39 | 40 | 0 | KMSY | 40 | 39 | 0 |
| KAMA | 39 | 42 | 0 | KNYC | 40 | 39 | 0 |
| KASE | 42 | 43 | 0 | KPIT | 41 | 43 | 0 |
| KBFL | 42 | 44 | 0 | KPUB | 41 | 46 | 0 |
| KBNA | 40 | 42 | 0 | KRDU | 40 | 42 | 0 |
| KBOS | 44 | 48 | 0 | KSAT | 39 | 39 | 0 |
| KBRO | 38 | 46 | 0 | KSDF | 40 | 40 | 0 |
| KCRP | 37 | 42 | 0 | KSEA | 41 | 42 | 0 |
| KDFW | 43 | 44 | 0 | KSLC | 41 | 44 | 0 |
| KEVV | 37 | 40 | 0 | KTUL | 35 | 42 | 0 |
| KFSM | 36 | 38 | 0 | PAKN | 37 | 44 | 0 |
| KHYS | 36 | 46 | 0 | PHNL | 39 | 41 | 0 |
| KJAN | 36 | 42 | 0 | Sum | 1300 | 1392 | 0 |
| Station | Naïve | SWR | WeaGETS | Station | Naïve | SWR | WeaGETS |
|---|---|---|---|---|---|---|---|
| CYOW | 1.02 | 1.08 | 0.00 | KMCI | 1.50 | 1.20 | 0.00 |
| CYQR | 0.04 | 0.10 | 0.00 | KMEM | 0.92 | 1.64 | 0.00 |
| CYVR | 3.38 | 1.56 | 3.40 | KMIA | 0.80 | 1.22 | 0.50 |
| CYWG | 0.78 | 0.52 | 0.00 | KMSP | 0.32 | 0.08 | 0.00 |
| CYYC | 0.36 | 0.00 | 0.00 | KMSY | 1.40 | 2.46 | 0.10 |
| KAMA | 0.84 | 1.00 | 0.00 | KNYC | 1.00 | 0.94 | 0.00 |
| KASE | 1.46 | 1.32 | 1.44 | KPIT | 1.42 | 1.86 | 0.00 |
| KBFL | 1.46 | 1.04 | 0.00 | KPUB | 1.02 | 0.40 | 0.58 |
| KBNA | 1.42 | 1.90 | 0.54 | KRDU | 0.56 | 1.48 | 0.00 |
| KBOS | 1.10 | 1.02 | 0.00 | KSAT | 0.90 | 1.44 | 0.18 |
| KBRO | 1.46 | 1.80 | 0.18 | KSDF | 1.22 | 1.20 | 0.30 |
| KCRP | 0.92 | 1.52 | 0.08 | KSEA | 1.62 | 0.52 | 4.64 |
| KDFW | 1.78 | 1.80 | 0.00 | KSLC | 1.98 | 1.48 | 1.48 |
| KEVV | 0.92 | 1.00 | 0.14 | KTUL | 0.64 | 0.66 | 0.00 |
| KFSM | 1.02 | 1.86 | 0.00 | PAKN | 1.22 | 1.28 | 0.00 |
| KHYS | 1.40 | 0.78 | 0.00 | PHNL | 1.90 | 1.74 | 0.06 |
| KJAN | 1.64 | 2.36 | 0.00 | Sum | 39.42 | 40.26 | 13.62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaftan, D.; Corliss, G.F.; Povinelli, R.J.; Brown, R.H. A Surrogate Weather Generator for Estimating Natural Gas Design Day Conditions. Energies 2021, 14, 7118. https://doi.org/10.3390/en14217118
Kaftan D, Corliss GF, Povinelli RJ, Brown RH. A Surrogate Weather Generator for Estimating Natural Gas Design Day Conditions. Energies. 2021; 14(21):7118. https://doi.org/10.3390/en14217118
Chicago/Turabian StyleKaftan, David, George F. Corliss, Richard J. Povinelli, and Ronald H. Brown. 2021. "A Surrogate Weather Generator for Estimating Natural Gas Design Day Conditions" Energies 14, no. 21: 7118. https://doi.org/10.3390/en14217118