1. Introduction
With the large amount of air pollution caused by the traditional energy consumption represented by coal, oil and firewood, human society has been paying more and more attention to natural gas as a relatively clean energy [
1]. Except for the direct consumption as fuel, natural gas has shown attracting potential in electricity generation for both economic and environmental concerns [
2]. Under the background of worldwide economic slowdown due to the COVID-19 epidemic in 2020, natural gas consumption has increased in the proportion of primary energy consumption under the condition of a significant decline in all kinds of energy consumption, and it maintained rapid growth in China and other countries. As a non-renewable resource, the rapid growth of natural gas consumption has brought new challenges to ensure the long-term security of energy supply. In recent years, with the rapid development of exploration and recovery technology of unconventional oil and gas reservoirs, unconventional resources represented by shale gas, which have huge potential reserves but have not been effectively developed, have become the investment hotspot and research focus [
3]. The successful cases of the commercial development of shale gas in China and North America have inspired the in-depth exploration of efficient development technology of shale gas, but the questions in economic benefits and risks in environmental impact also require a more complete and thorough understanding of the flow and transport mechanism in shale gas reservoirs [
4].
The fluid flow and transport in shale gas reservoirs usually demonstrates multiphase and multicomponent properties, while multiple numerical schemes and multiscale domains may be incorporated [
5]. A reliable description of the compositional distribution of each phase with thermodynamic consistency and accuracy is a necessary basis for further analysis of the flow and transportation behaviors in all the computational domains, especially when multi-scale expansion is involved [
6]. In the recovery of shale gas, the understanding of the phase transmission law is helpful to control the phase compositions during the discovery and development process, so as to benefit the engineering operations. Due to the small pore size and even the common distribution of nano-pores in shale gas reservoirs, the influence of capillarity caused by the strong rock surface wettability preference cannot be ignored [
7]. Furthermore, the effect of capillarity can be reflected in the phase distribution and transmission phenomenon, and the thermodynamic mechanism implied under such an effect should be investigated [
8]. Therefore, an accurate modeling of the phase distribution and changing rules in the subsurface unconventional reservoirs with capillary effect is of significant importance with respect to both the theoretical studies and engineering applications. Moreover, thermodynamic studies on phase behaviors can further suggest the formulation of governing equations for modeling multicomponent multiphase flow and transport to ensure the thermodynamic consistency and mass conservation properties [
9].
Flash calculation is a mathematical tool for predicting the phase distribution of a given fluid mixture at equilibrium, also known as phase equilibrium calculations. Thanks to the critical importance of the calculated properties as the result of flash calculation, including pressure, volume, compositional phase distribution, total phase numbers, and many others, this calculation is often considered to be the key and fundamental step in the complete simulation of multicomponent multiphase fluid flows. Especially, the total number of phases existing in the mixture at equilibrium is directly relevant with the formulation of fluid dynamics, as the conventional governing equation for single phase flow may be enough if the mixture is in the single-phase region at equilibrium [
10]. Meanwhile, information regarding supercritical fluid could be indicated from the flash calculation results [
11], and that information can help explain many interesting fluid phenomena. There are two flash calculation methods commonly used in engineering computations: NPT type flash calculation [
12] (flash at constant mole, pressure and temperature) and NVT type flash calculation [
13] (flash at constant mole, volume and temperature). In recent years, the emerging VE type [
14] (flash at constant volume and internal energy) has emerged and attracted increasing attention. NPT flash calculation has a long development history and is widely used in the petroleum industry thanks to its easy understanding and implementation, but NVT flash is more suitable for phase equilibrium calculations in unconventional reservoirs as capillary pressure is a challenge to conventional NPT flash schemes [
15]. In addition, the manual selection of the best root in solving the cubic equation, if a realistic equation of state is involved, is not preferred, and such computational efficiency is not acceptable, especially for field-scale reservoir simulations with a large number of components considered. The recent emerging VE type flash calculation is more convenient for changing temperature systems, but it is rarely used in industry as the current implementation is not convenient for engineering computations.
In shale gas reservoirs, due to the space limitation in nano-pores and the difference of pore size distribution from the micro-scale to the nano-scale, the phase equilibrium of reservoir fluid often varies greatly [
16]. In fact, before the large-scale commercial development of shale gas reservoirs, researchers have been studying the fluid flow in porous media with nano-pores, focusing on the application of this flow phenomenon in chemical separation design, pollution control or fuel cells [
17]. Based on that, in order to improve the exploration and development performance of shale gas reservoirs, extensive interest has been attracted to the phase equilibrium calculations of fluid flow in nano-pores, focusing on the special mechanisms behind phase transmission and phase separation processes. The effect of capillarity has found to be significant in modifying the fluid dynamics and thermodynamics in the confined geometry, so as to change the entire thermodynamic properties and physical laws within the system [
18]. Thus, it is of critical importance to design a thermodynamically consistent flash calculation scheme considering capillary pressure to accurately predict phase behaviors for the reliable simulation of fluid flow and transport in shale gas reservoirs.
Both the conventional NPT and NVT flash calculation schemes are implemented by iterative calculations, which is too time-consuming to be adapted in large-scale reservoir simulators, especially when a large number of components are involved. The equation of state (EOS) is the fundamental governing equation in the generation of phase equilibrium calculation schemes, while a number of EOSs have been proposed that continuously approach realistic thermodynamic rules. Starting from the van der Waals EOS proposed in [
19], cubic-type EOSs have been preferred in the petroleum industry thanks to the reasonable volume and pressure correction in a large range or temperature and pressure conditions. The current popularity on Peng–Robinson equation of state [
20] (P-R EOS) and Soave–Redlich–Kwong equation of state [
20] (SRK EOS) mainly depends on the good adaptability to hydrocarbon mixtures, but the strong nonlinearity brought by the cubic-type EOSs is always a challenge in fast and accurate phase equilibrium calculations. Especially, the manual selection of the best root for the cubic equation is not efficient and even more time-consuming in conventional iterative algorithms. Hundreds of components may be involved in current compositional reservoir studies [
21], which is urgently requiring a reliable but efficient phase equilibrium calculation method to lay the thermodynamic foundation for the multicomponent multiphase flow and transport simulations.
Starting from 1986 [
22], the reduction method has been focused on accelerating flash calculations, in which the number of nonlinear equations and unknowns is reduced by using the low rank attribute of the binary interaction coefficient (BIC) matrix. Further developments were proposed to extend the application scope by introducing a non-hydrocarbon component in actual reservoir fluid [
23] and to redefine the phase equilibrium problem using chemical potential conversion according to the reduction variables [
24]. The performance of the tangent plane distance (TPD) function in the reduced space was tested in [
25] as an index checking the phase stability, and the spectrum theory of linear algebra was adapted in the algorithm. The decomposing BIC matrix was developed in [
26], which could be degenerated to the original reduction model in [
22] if all BIC coefficients are zero. A simplified expression of the Jacobian matrix was formulated in [
27], by which the efficiency and robustness were improved significantly. A new decomposition method was proposed in [
28] to minimize the approximation error of energy parameters instead of the traditional spectrum analysis method. Although the above simplified flash calculation method significantly improves the calculation efficiency compared with the classical algorithm, the accuracy of phase equilibrium prediction in multicomponent reservoir fluid is always unsatisfactory, and recent studies have found that the acceleration effect of the simplified algorithm in multicomponent problems is not obvious [
29]. In addition, the performance of the simplified algorithm in phase stability detection is not always accurate and reliable. The boundary of the single-phase region is often incorrectly described, and the solution beyond the physical meaning will be given in the prediction of physical quantities such as saturation. Thus, an accelerated but still accurate phase equilibrium prediction method is still in development, especially for multi-component systems.
In recent years, the rapid improvement on the computing equipment has prompted the petroleum industry to put forward higher accuracy and larger scale requirements for reservoir simulation. The super large-scale reservoir simulator containing tens of millions or even hundreds of millions of grid points has brought new challenges to the robustness and efficiency of oil and gas reservoir fluid phase equilibrium algorithms. The conventional accelerated flash calculation algorithms cannot handle this task in the context of accelerating performance and accuracy reservations. Researchers have turned their attention to the booming artificial intelligence and machine learning technology. Alexnet’s breakthrough in 2012 [
30] announced the beginning of the era of deep learning. This technology has completely changed various fields of industry and academia, including computer vision [
31], natural language translation and processing [
32], electronic entertainment [
33], etc. Compared with traditional machine learning methods, deep learning algorithms have made significant progress in prediction accuracy and physical consistency because they contain multiple hidden nonlinear layers, which can represent the complex correlations among the input features. Generally, the task environment in flash calculation is quasi-static, so the trained model can capture the distribution of specific time points, which makes the deep learning model a promising choice in the actual phase equilibrium calculation. However, although the appropriateness and necessity of developing deep-learning-based methods in this field have been widely recognized, limited attempts have been made to develop deep learning methods for accelerating flash calculation. A fully connected deep neural network was proposed in [
34]. Using the trained model instead of the conventional equation of state, the underneath thermodynamic laws among the input characteristics were formulated, and the calculation efficiency was significantly improved with an acceptable prediction accuracy. In order to overcome the problem that a limited number of expensive experimental data were used as the training ground truth, an NVT flash calculation was first carried out in [
35], and the results provided enough data for training and testing. These advances moved closer to the real reservoir complex fluid, but all these existing depth learning methods assume that the mixture has a fixed given number of components, which makes this model often useless in a wide range of engineering practice. A self-adaptive deep learning algorithm was proposed in [
36] to develop a general scheme suitable in wide engineering scenarios for different reservoir fluids consisting of various components. However, the effect of capillarity was not taken into consideration, which limited the adaption in unconventional studies. Capillarity was considered in [
37], but an implicit constraint was implied in that scheme as the pore size was assumed to be constant. In recent years, a number of publications have been reported to handle various phase equilibrium problems [
38,
39,
40], and the concept of deep learning and artificial neural network has also been sorted [
41]. The application of neural networks accelerating flash calculation has been extended to the other concepts of flashes, entropy volume (SV) and an enthalpy volume (HV) flash [
42], which significantly extended the application of the model. The deep-learning-trained flash model has been successfully incorporated in compositional reservoir simulators in [
43,
44,
45,
46], which is more directly relevant with the practical demands of oil industry.
In this paper, a thermodynamically consistent deep learning algorithm will be developed considering the effect of capillarity in general cases. Thermodynamic foundations will be formulated in
Section 2. Deep learning techniques as well as the neural network configurations are described in
Section 3. Scheme verification and prediction results of phase stability test and phase splitting calculation will be illustrated and analyzed in
Section 4. Concluding remarks are organized in
Section 5, together with suggestions on the future research directions.
2. Thermodynamic Foundations
The NVT flash system minimizes the Helmholtz free energy of the system, which can be formulated as:
where the capital
denotes the Helmholtz free energy, and the lowercase
denotes the volume-averaged energy density. The superscripts
and
denote the gas and liquid phase, respectively, and
denotes the volume. The molar density vector
for
components can be calculated as
, while a constraint on the volume and mole numbers can be formulated as:
where the capital
denotes the mole numbers. Using chain rule, the partial derivative of
over time can be formulated as (using the gas phase as the primary phase and the gas phase mole and volume as the primary variables):
The two partial derivatives
and
can be formulated as:
The following ODE can be formulated:
which could further derive the time marching scheme of Helmholtz free energy as:
The above formulation meets exactly the second law of thermodynamics if the coefficient
and
are positive definite. The Onsager coefficient matrix generated in [
36] is a good choice to ensure the stiffness, which could be written as:
where
denotes the diffusion coefficient of component
and
denotes the parameters for gas and liquid phase, respectively.
The effect of capillary can be taken into account by constructing the entropy production equation as:
where
can be formulated as:
The capillary pressure
can be calculated using the classical Young–Laplace equation as
where
denotes the interfacial tension. The Weinaug–Katz correlation [
38] calculates the interfacial tension as
. Considering capillarity, the generalized discretized time marching scheme could be reformulated as:
where
denotes the Onsager coefficients.
3. Deep Learning Technique
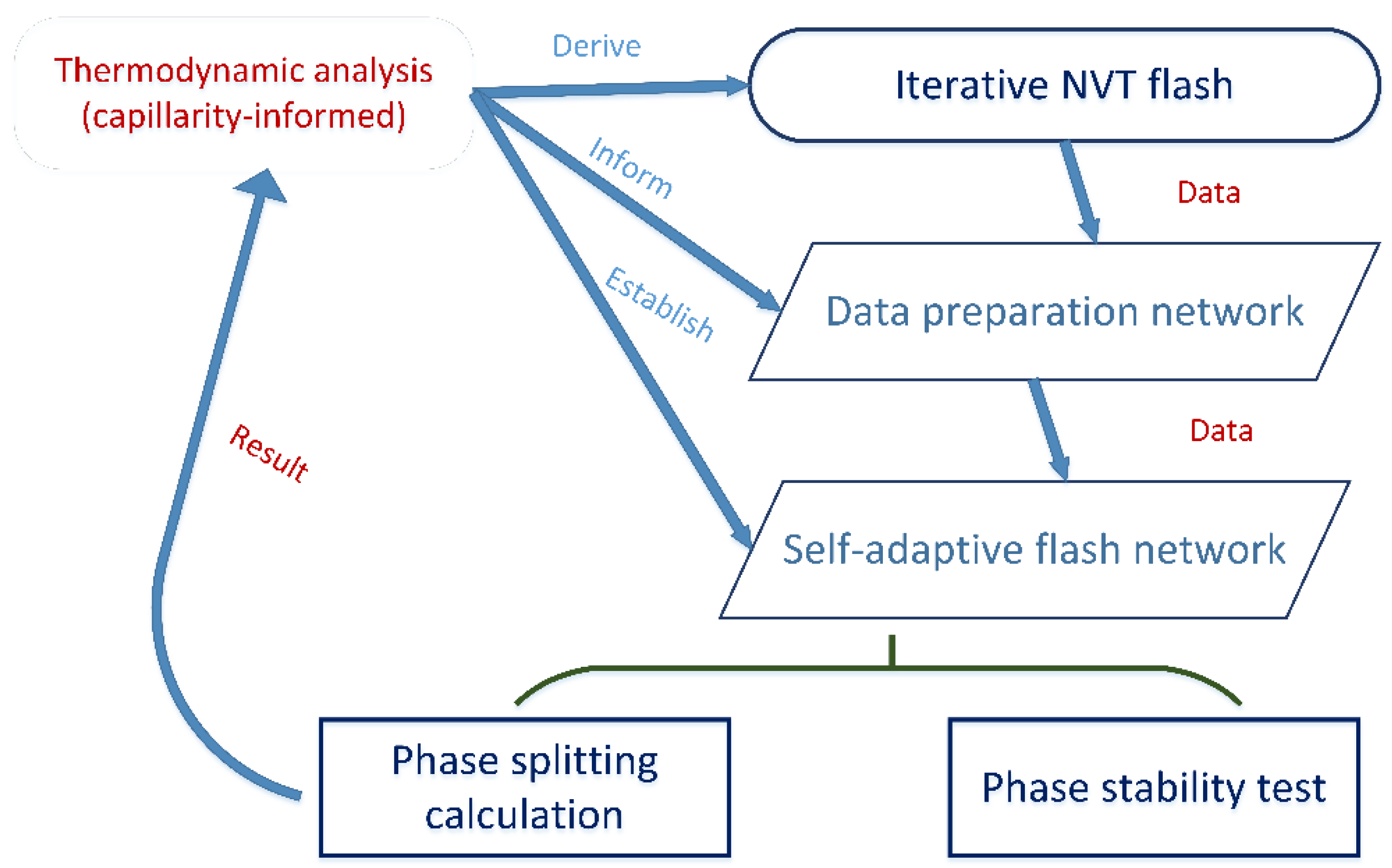
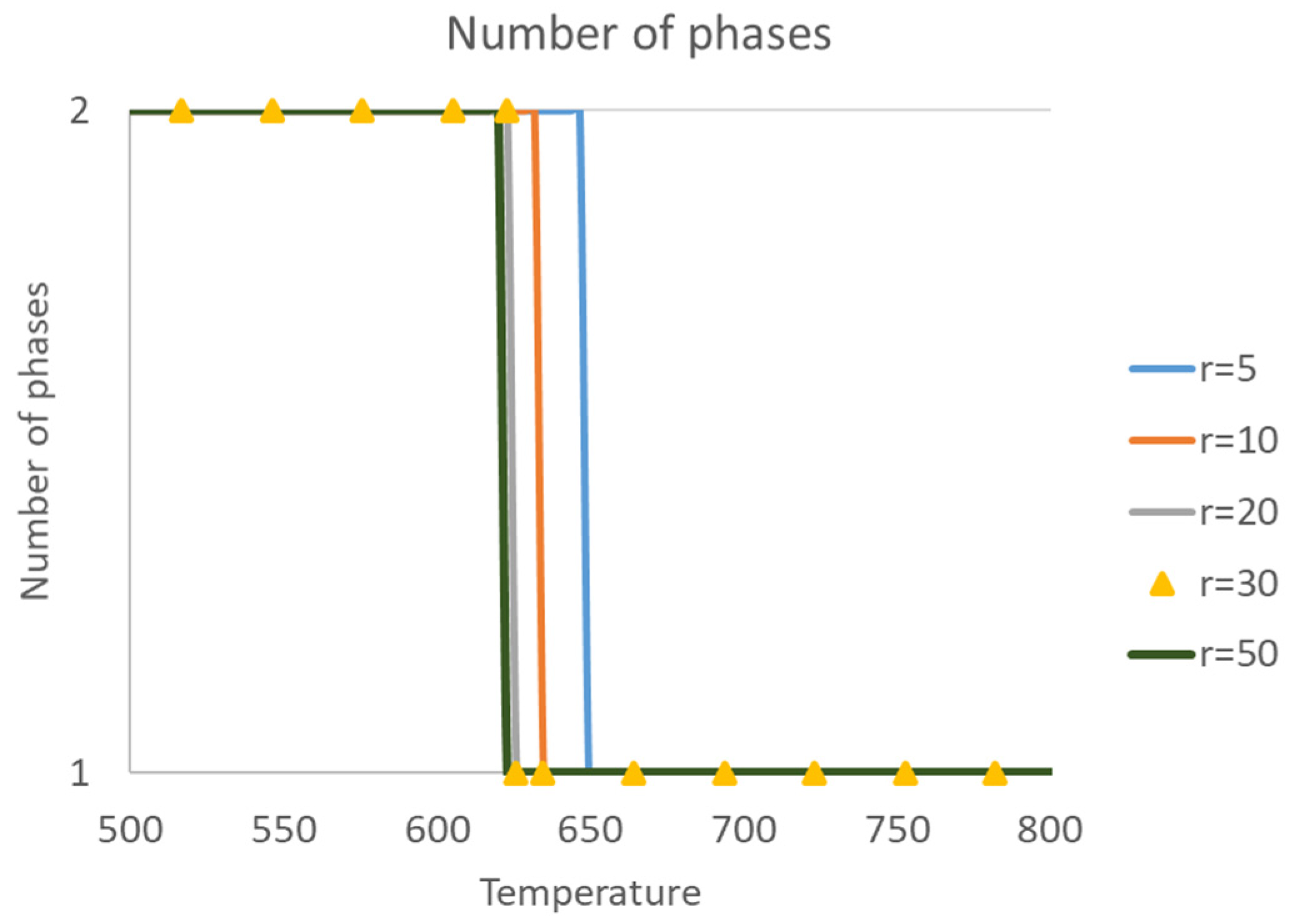
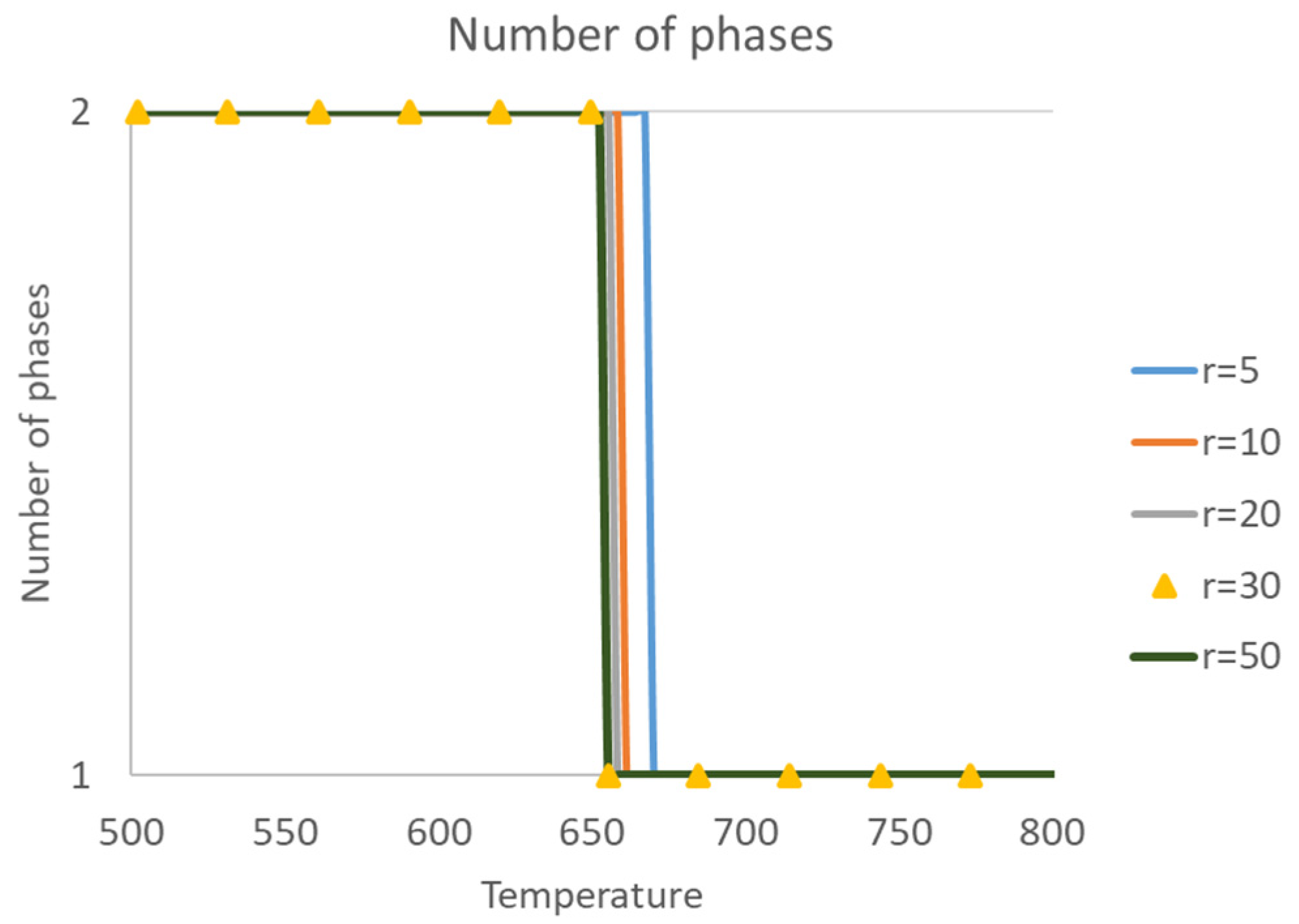
In order to overcome the limitations of the current phase equilibrium calculation methods and the accelerated approach using the deep learning technique, a thermodynamically consistent phase equilibrium calculation scheme is proposed in this paper, as shown in
Figure 1. This work starts from the realistic equation of state and a thermodynamically consistent NVT type flash calculation method is generated as discussed in
Section 2. Using iterative calculations, sufficient data can be prepared for the further training and testing purposed in the deep learning algorithm, and the network structure is also designed based on thermodynamic analysis to determine the input and output features. A two-network structure is established for the adaptive flash calculation, with one network for data padding and the other one for phase equilibrium prediction. Both phase stability test and phase splitting calculations are involved in the output of the flash network, which informs both the number of phases at equilibrium and the compositional mole fraction. The predictions can be further analyzed using the thermodynamic scheme. As illustrated in the figure, data are transferred through both the iterative flash calculation scheme and the accelerated deep learning scheme, and thermodynamic analysis plays a role in the whole process. Such a coherent and complete phase equilibrium calculation scheme is believed to be capable of providing fast, accurate and robust thermodynamic foundations for further multi-component multi-phase fluid flow simulation [
39]. It should also be noticed that the thermodynamic correlations among the input features are now described by the inner connections of the hidden layers and nodes, as well as the usage of activation functions, to replace the conventional thermodynamic models represented by EOSs. If the trained model as a liner combination of the nodes and activation functions is verified to meet well with the ground truth data, i.e., iterative flash calculation data in a wide range of environmental conditions, it is reasonable to state that the thermodynamic rules in the phase equilibrium calculations are well-informed in the proposed deep neural network.
For oil and gas reservoirs, hydrocarbons are considered to be the main components existing in the investigated fluid mixtures. Peng–Robinosn EOS [
40] is proven to be a good one describing the thermodynamic properties of hydrocarbons, which could be formulated in a polynomial form as:
where the parameters
and
can be calculated as:
The pressure correction coefficient
and volume correction coefficient
can be calculated by:
where the attraction parameter is modeled by:
We define the acentric factor as a conceptual number to be a measure of the non-sphericity (centricity) of molecules. As it increases, the vapor curve is “pulled” down, resulting in higher boiling points. The coefficient in Equation (17) can be calcualted by for . If holds, then the coefficient should be determiend based on .
Based on the previous thermodynamic analysis, the critical temperature
, critical pressure
and acentric factor
are chosen to be the key features identifying each component
, while the mole fraction
is also needed as an initial condition. For an NVT type flash calculation, environmental temperature
and overall molar concentration
are slected to be the environmental conditions, and the pore size
should also be included to involve the effect of capillarity in general reservoir geometries. Thus, the dimension of the input data is
for the input fluid mixture with
components. The data prepartion network will read the number of components
of the target fluid and automatically construct the output layer with a dimension of
, while
can be different from
. If
, all information in the training data will be retained, and data padding will be carried out by defining the
ghost components with all the key thermodynamic characteristics set as zero. The result data output by this network have a dimension of
. If
, the data set output by this network remains the same as the input training data, but the test data set of the target fluid is filled with
ghost components with zero key thermodynamic characteristics. In this way, it can be ensured that the input and output data dimensions of the second neural network, that is, the self-adaptive flash network plotted in
Figure 1, are the same, thereby realizing the wide applicability of phase equilibrium calculations for practical reservoir fluids including unconventional reservoirs, with variable compositions and capillary pressures.
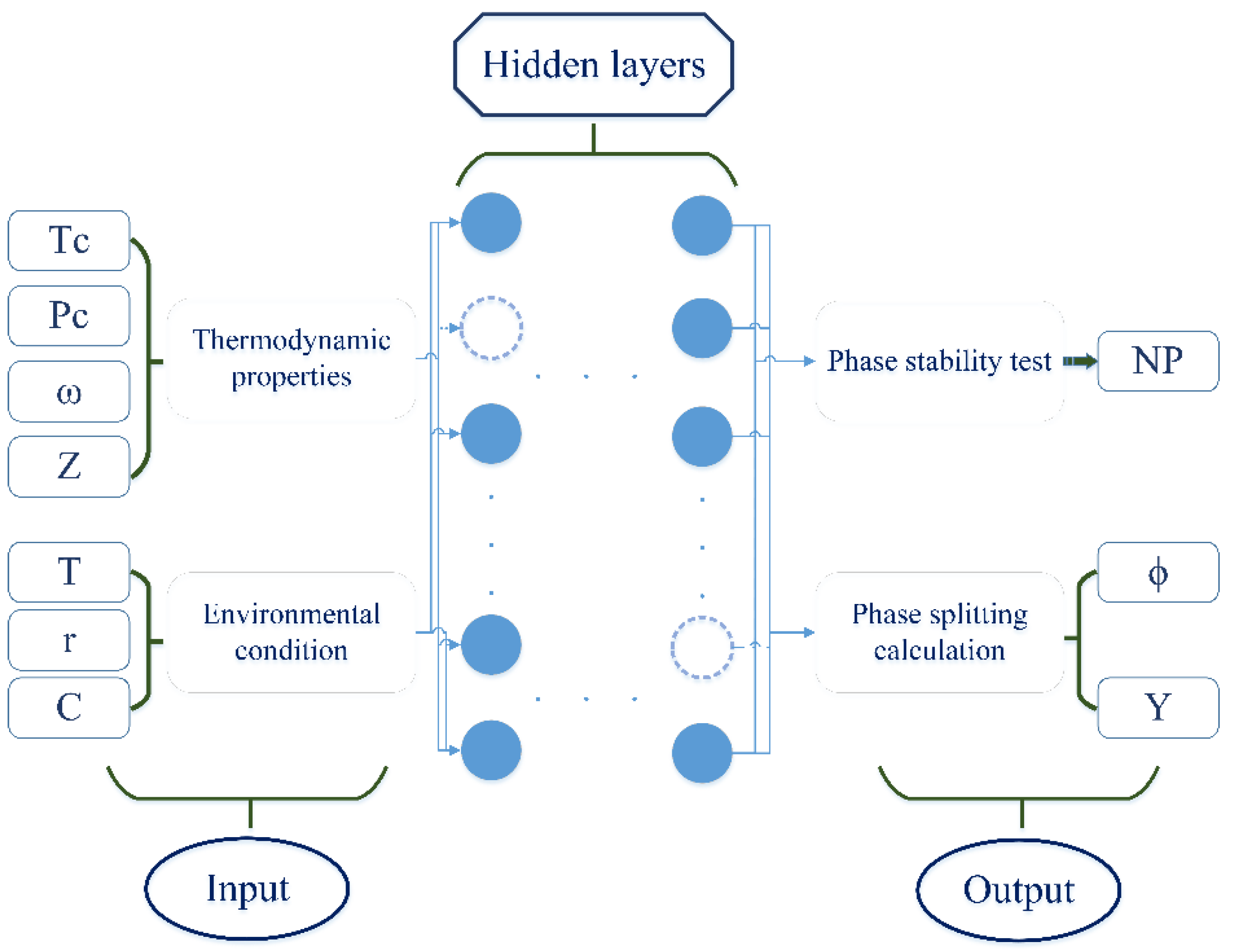
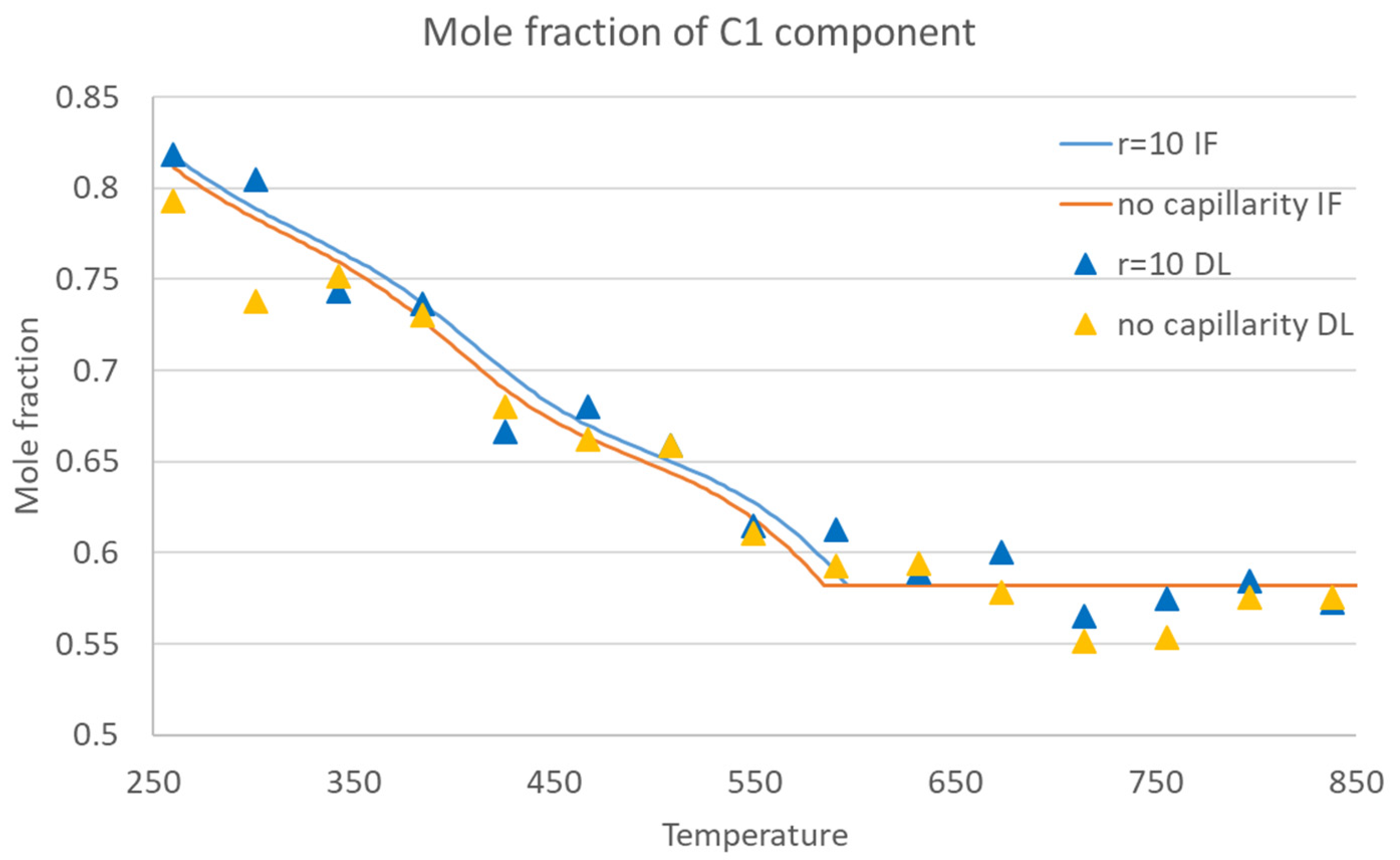
The structure of the flash neural network is illustrated in
Figure 2. The output layer will obtain the result of the phase stability test, that is, the total number of phases in the fluid at the equilibrium state, represented by
, and the result of the phase splitting calculation, that is, the molar composition of the gas phase (
) and the gas–liquid ratio (
) at the equilibrium state. A number of hidden layers are placed between the input and output layer [
41]. Each hidden layer contains several nodes, and the model trained on each layer can be expressed as:
where
denotes the weight parameters in the
th hidden layer,
denotes the input data in that layer and
denotes the output data.
represents the activation function used in that layer, and
is the bias. For a fully connected deep neural network, the output data from the previous layer are usually directly used as the input data of the next layer. Taking a neural network consisting of three hidden layers as an example, the overall prediction model is:
where
denotes the final output predictions,
denotes the input data in the first layer,
,
and
denote the weight parameter in the 1st, 2nd and 3rd layer, respectively, and
,
and
denote the activation functions used in the layers.
The self-adaptive neural network architecture proposed in this paper will allow the data to be padded to unify the training data set and the target test data set, which brings the following corrections to the above training model: assuming
, the
ghost components are defined with zero key thermodynamic properties and padded into the input data, which could be formulated as:
where the subscript
denotes the ghost components.
Overfitting is a common challenge in deep learning research, which means that the perfect performance of the trained model has been achieved for training data, but only poor performance can be obtained when verifying the predictions for the testing data. Usually, this problem occurs if too many parameters are included in a deep learning model (also known as an over-parameterized model). For multi-component phase equilibrium problems, the calculation model generally includes a super-large-scale weight matrix, especially when the realistic oil and gas reservoir fluid, containing a large number of components, is taken into account. An additional constraint is usually applied to reduce the degree of freedom of the model to prevent overfitting from damaging the performance of the deep learning algorithm. An important feature of overfitting is that the norm of the coefficient parameter is very large, which may help us point out a solution to add this additional constraint. The loss function could be corrected by adding a L2 norm of weight matrix, which may help avoid the extra-large weight matrix in the final trained model.
The super-large-scale weight matrix needed by the phase equilibrium prediction model of realistic multi-component oil and gas reservoir fluids requires a good initial guess to improve the convergence speed during training, thereby improving the performance and reliability of the developed deep learning algorithms. If the weight parameters are overestimated in the initialization, a rapid increase in variance may be observed during the training process, which may further cause the gradient to explode or disappear. In this case, the training will never converge. On the contrary, if the weight parameters are underestimated during initialization, the variance may quickly drop to a very small value, which will lead to the loss of model complexity and even damage the performance of the final evaluation. The commonly used initialization method is to initialize the weight parameters with a certain variance following the Gaussian distribution to ensure that the input and output variances of each layer will remain unchanged. This is the commonly used Xavier initialization technique [
44], which is also used in this paper to initialize the weight matrix predicting the phase equilibrium.
In order to accurately describe the complex thermodynamic laws in the phase equilibrium investigations, it is difficult for the model trained by the deep neural network to fully avoid the overfitting problem caused by the high complexity, which affects the final prediction effect. Dropout is a common method that eliminates the corresponding connections by discarding certain nodes in the network, thereby significantly reducing the degree of freedom of the model. As shown in
Figure 2, the dotted circle in the hidden layer represents the node eliminated by the dropout technique. After evaluating all nodes and connections with certain probability, the training of the model will be performed on the simplified network after dropout. It should be pointed out that in order to maintain the robustness of training and conservation of the physical laws, before the start of the next training cycle, it is necessary to use the initialized coefficients to insert the discarded nodes back into the model for re-evaluation and dropout operations.
Due to the complexity of the multi-component phase equilibrium prediction model and the huge amount of training data required, the training of the deep learning model is very time-consuming. In addition, together with the gradient descent process, the variable matrix
and
of each layer may change, which in turn causes the linear and nonlinear calculation result distribution of each layer to change frequently. The next layer in the network has to constantly adapt to this distribution change, which will make the learning rate of the entire network too slow. In addition, when using saturated activation functions, such as sigmoid, tanh, etc., it is easy to cause the model training to fall into the gradient saturation zone. At this time, the gradient will become very small or even close to 0, and the update speed of the parameters will slow down, which further slows down the convergence rate of the network training. This is the common internal covariate shift problem (Internal Covariate Shift, ICS) in machine learning. A usual solution is whitening, that is, making the input feature distribution to have the same mean and variance, thereby reducing the impact of the ICS problem. However, the computational cost of the whitening technique is too high, especially when every layer in each round of training needs to perform this operation, which slows down the training efficiency. In addition, because the whitening process changes the distribution of each layer of the network, it changes the expressive ability of the raw data in the network configurations. It is often questioned that certain information underlying the physical rules among the input features may be lost after whitening process, so that the trained model cannot be trusted for the accurate and robust predictions with physical meanings. Therefore, a more advanced batch normalization method (Batch Normalization, BN [
45]) is used in this paper to calculate the mean and variance for each batch of data samples, and then standardizes the distribution of each input feature values with a mean value of 0 and a variance of 1. Linear transformations are also added to recover the information underneath the input data.
The strong nonlinear correlations among the input features (characterized by the nonlinear evolution equations based on the equation of state in conventional iterative flash calculation) is characterized by the activation functions in the deep learning model. As a key factor in expressing network nonlinearity and problem-solving ability, the activation function has developed rapidly in recent years. Different activation functions have different expressions and thus are preferred in different engineering scenarios. In previous publications, careful tuning has been carried out on the selection of the best activation function for phase equilibrium prediction, and generally “softsign” function performs the best. In addition, the “softmax” function, formulated as:
should also be included in the last layer. By calculating the ratio of the index of the mole fraction of each component in each phase to the sum of the index of the mole fraction of all components in that phase, it can be ensured that the final output of the deep neural network meets the restriction condition that the sum of mole fractions in each phase is 1, so as to preserve the consistency and physical meanings of thermodynamics.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}