1. Introduction
With the rapid development of imaging technology, high-resolution remote sensing (RS) imagery is becoming more and more readily available. Therefore, research within the field of RS has flourished, and automatic building segmentation from high-resolution images has received widespread attention [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
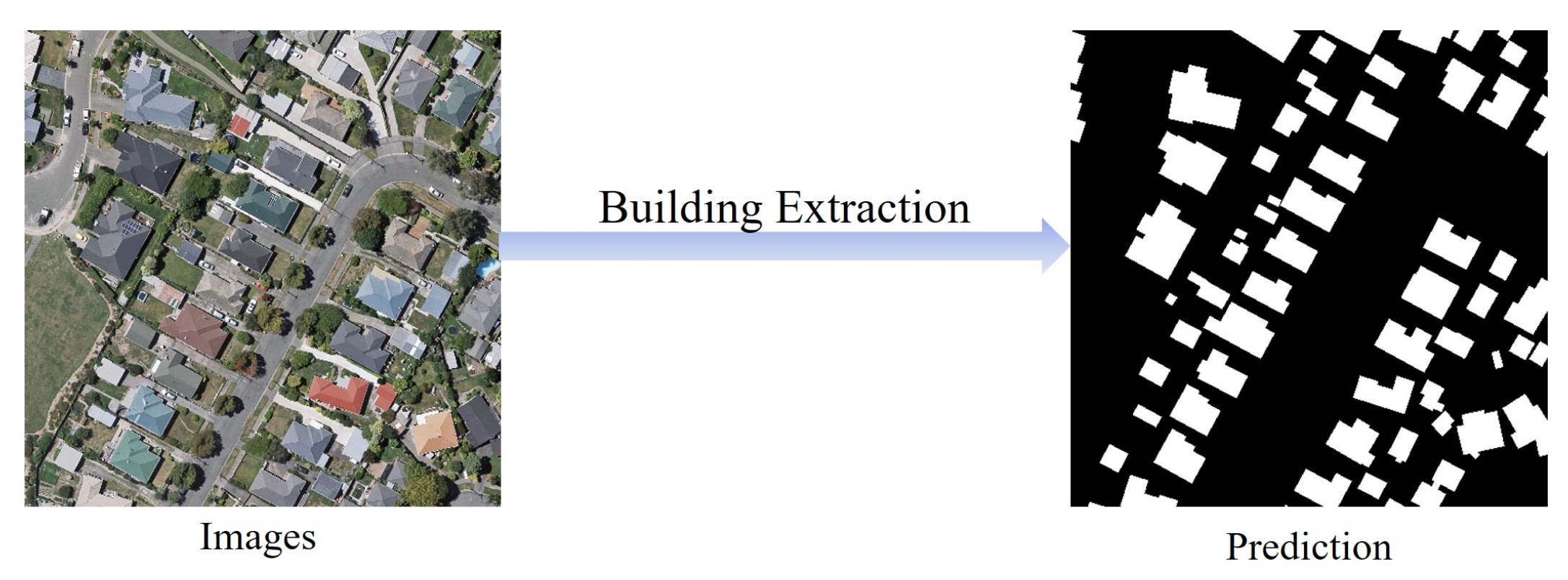
15]. The process of extracting buildings from RS images is shown in
Figure 1, which is essentially a pixel-level classification of RS images to obtain binary images with contents of building or non-building, and this process can be modeled as a semantic segmentation problem [
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29].
Deep learning (DL), with convolutional neural networks (CNN) [
30,
31,
32,
33,
34] as its representative, is an automated artificial intelligence technique that has emerged in recent years, specializing in learning general patterns from large amounts of data as well as exploiting the knowledge learned to solve unknown problems. It has been successfully applied and rapidly developed in areas such as image classification [
35], target detection [
36], boundary detection [
37], semantic segmentation [
16], and instance segmentation [
38] in the field of computer vision. Proving to be a powerful tool for breakthroughs in many fields, DL techniques applied to building extraction in RS have emerged and become the mainstream technical tools. Although there are some reviews on RS image building extraction [
39,
40,
41,
42] or DL-based RS image processing [
43,
44,
45], there is still a lack of a research that summarizes the latest results of RS image building extraction based on DL techniques. In this paper, we extensively review the DL-based building extraction from RS images, excluding the extraction of roads and other man-made features, in which the processing inputs include aerial images, satellite images, and other multi-source data such as light detection and ranging (LiDAR) point cloud data and elevation data.
As a fundamental task in the field of RS, automatic building extraction is of great significance in a wide range of application areas such as urban planning, change detection, map services and disaster management [
46,
47,
48,
49,
50,
51,
52,
53,
54,
55,
56]. It is the basis for accomplishing these applications to have efficient and accurate building information. Building extraction has some unique features and challenges, which mainly include the following:
Building types are in general highly changeable. They differ in interior tones and textures and have a variety of spatial scales. In addition, their shapes and colors may vary from building to building.
Buildings generally stand in close proximity to features of similar materials such as roads, and can easily be confused with other elements. The segmentation quality of boundary contours is particularly important.
The long-distance association relationship between buildings and surrounding objects is an important concern due to a variety of complex factors that may cause foreground occlusions, such as shadows, artificial non-architectural features, and heterogeneity of building surfaces.
RS images have more complex and diverse backgrounds and scenes, and the shapes of buildings are more regular and well-defined than those of natural objects, rendering boundary issues particularly critical.
DL techniques have breathed new momentum into meeting these challenges and have sparked a wave of new promising research. In this paper, we review these research advances, with the following core contributions:
- 1.
A detailed description of existing high-quality public datasets applied to building segmentation problems and commonly used evaluation metrics, which are key elements in judging the effectiveness of building segmentation methods.
- 2.
Structured review of existing DL-based building segmentation methods, including their characteristic structures or contributions.
- 3.
The quantitative experimental results provided in the literature are discussed, including their problems as well as some properties.
- 4.
An outlook based on extensive literature research and summary is given for the possible directions of future work.
As shown in
Figure 2, the remaining parts of the article are organized as follows. The introduction of DL techniques related to the building segmentation problem is presented in
Section 2. In
Section 3, descriptions of the most widely used public building datasets and evaluation metrics for segmentation models are presented. Then, an overview of existing methods is presented in
Section 4. In
Section 5, the proposed methods are briefly discussed based on quantitative results on the datasets, and future research directions are provided. Finally,
Section 6 concludes the paper.
2. DL Techniques
Semantic segmentation, one of the research directions of DL most closely related to building extraction, is not an isolated research area, but a natural step in the process from coarse to refined inference. It is a downstream task of image classification, a fundamental computer vision task, for which image classification models provide feature extractors that extract rich semantic features from different layers. In this section, firstly, we recall the classic deep CNNs and design inspirations used as deep semantic segmentation systems, and point out its enlightening role for subsequent segmentation networks. Then, transfer learning, an important means of training DL models, is introduced. Finally, we introduce the loss functions used to train segmentation networks.
2.1. Deep CNNs
As one of the most fundamental tasks in computer vision, the image classification task assigns labels based on the input image and predefined categories. CNN-based image classification methods have matured in recent years and have become an important part of the downstream task of semantic segmentation. Here, we briefly review some classical CNN architectures for image processing, which include VGG, GooLeNet, and ResNet.
2.1.1. VGG Networks
In 2014, Visual Geometry Group (VGG) [
57] at the University of Oxford proposed a network with more than 10 layers with concise design principles to build deeper neural network models. The structure of the VGG network is shown in
Figure 3, with the main components being a
convolution operation and a
max-pooling operation. The small-sized convolutional layer has a smaller number of parameters and computations than the convolutional layer with large-sized convolutional kernels (e.g.,
or
convolution operations in AlexNet [
35]) to obtain a similar perceptual field. In addition, a remarkable feature is to increase the number of feature maps after using the pooling layer, reducing the phenomenon of useful information loss in feature maps after downsampling.
VGG network is one of the most influential CNN models because of its reinforcing the important idea in DL that CNNs with deeper architectures can facilitate hierarchical feature representation of visual data. It could be a guide to the structural design of subsequent deep CNN models. Meanwhile, VGG with 16 layers (VGG-16) has become one of the common feature extractors for downstream tasks.
2.1.2. GoogLeNet
GoogLeNet based on inception modules was proposed by Google in 2014 [
58], which won the ImageNet competition that year. It has been improved several times in the following years, leading to InceptionV2 [
59], InceptionV3 [
60] and InceptionV4 [
61]. The structure of the inception module is shown in
Figure 4, presenting a net-in-network (NIN) architecture. The same network layer including large-size convolution, small-size convolution and pooling operations can capture feature information separately in a parallel manner. In addition, inception modules control the number of channels with
convolution and enhance the network representation by fusing information from different sensory domains or scales. Due to these modules, the number of parameters and operations is greatly reduced, while the network advances in terms of storage footprint and time consumption. The idea of inception provides a new way of stacking networks for CNN architecture design, rather than just sequential stacking, as well as it can be designed to be much wider. For the same number of parameters, inception-based networks are wider and more expressive, providing a fundamental direction for lightweight design of deep neural networks.
2.1.3. ResNet
Presented in 2015, ResNet [
62] is a landmark research result that pushed neural networks to deeper layers. 152-layer ResNet ranked in the top five at ILSVRC 2015 with an error rate of 3.6% and achieved a new record with respect to classification, detection, and localization in a single network architecture. Through experiments and analysis of several deep CNN models, it was found that deep networks experience network degradation during layer deepening and could not necessarily perform better than shallow networks. In response, a deep residual structure was proposed as shown in
Figure 5, allowing the network to shift to learning of residuals. The residual network learns new information different from what was previously available, relieving the pressure on the deep network to learn feature representations and update parameters. It allows the DL model to move once again in a deeper and better direction.
2.2. Transfer Learning
Training a deep neural network from scratch is often difficult for two reasons. On the one hand, training a deep network from scratch requires enough dataset, and the dataset of the target task is not large enough. On the other hand, it takes a long time for the network to reach convergence. Even if a sufficiently large dataset is obtained and the network can reach convergence in a short time, it is much better to start the training process with weights from previous training results than with randomly initialized weights [
63,
64]. Yosinski et al. [
65] demonstrated that even features learned by migration from less relevant tasks are better than those learned directly from random initialization. It also takes into account that the transferability will decrease as the difference between the source task and the target task increases.
However, the application of transfer learning techniques is not so straightforward. The use of pre-trained networks must satisfy the network architecture constraint of using existing network architectures or network components for transfer learning. Then, the training process itself in transfer learning is very small compared to the training process from scratch, so it can pave the way for fast convergence of downstream tasks. An important practice in transfer learning is to continue the training process from a previously trained network to fine-tune the weight values of the model. It is important to choose the layers for fine-tuning wisely, generally choosing the higher layers in the network, as the underlying layers generally tend to retain more general features.
ImageNet [
66,
67] is a large image classification dataset in the field of computer vision and is often used to train the feature extraction network part of segmentation networks. VGG-16 and ResNet pre-trained by ImageNet are easily available to be used as the encoder part of the segmentation network as well. In addition, a large collection of RS image segmentation data has also been collected and merged into a large dataset and used to pre-train the segmentation network [
68].
2.3. Loss Function
Deep neural network models are trained with the loss-gradient back-propagation algorithm, so that the design of the loss function is also directly related to the efficiency of the network training and the performance of the model on the target task. Then the rest of this section describes several commonly used loss functions in building segmentation networks. To facilitate the expression of the computational process, y and p denote the ground truth label and prediction result, respectively.
Cross entropy loss: Cross entropy loss (CE) is the most commonly used loss function in dense semantic annotation tasks. It can be described as:
Weighted Cross Entropy loss: Weighted cross entropy loss (WCE) is obtained by summing over all pixel losses and can not actively cope with application scenarios such as building extraction where the categories are unbalanced. Therefore, WCEs that consider category imbalance, such as median frequency balancing (MFB) [
69,
70] CEs, have emerged.
where
w is the category balance weight in median form, expressed by the ratio of the median of the pixel frequencies of all the categories to the pixel frequencies of that category.
Dice loss: Dice loss is designed for the intersection over union (IoU), an important evaluation metric in semantic segmentation, and is designed to improve the performance of the model by increasing the value of this evaluation metric.
Focal loss: Focal loss (FL) is improved from CE loss. To address class imbalance, an intuitive idea is to use weighting coefficients to further reduce the loss of the easy classification category. FL can be expressed as:
where
is the weighting factor for the classes and
is a tunable parameter.
4. Building Extraction Methods Based on DL
DL techniques represented by CNNs have been developed for a long time in the direction of building extraction under the field of RS, whose processing of the input and output can be shown in
Figure 9. Various deep neural network architectures for solving building extraction problems have emerged one after another.
Patch-based annotation networks [
81,
82] are the key process of the adoption of DL into the building segmentation problem, with the main advantage of helping researchers to free themselves from complex manual feature design and perform automated building extraction for high- and even ultra-high-resolution RS images. The patch-based approach is essentially an image classification network that assigns a specified label to each patch, where the last layer of the network is usually a fully connected layer. The method cuts the image into a number of sub-images much smaller than the original size, i.e. patches, after which a CNN is applied to process the individual patches and give a single classification for each one, and finally stitch them together to form a complete image. The patch-level annotation method does not require high capacity of the network, and the network is usually uncomplicated in structure and easy to design. Saito et al. [
81] designed a simple neural network containing three convolutional layers and two fully connected layers to accomplish automatic extraction of buildings, in which the feasibility and effectiveness of the method was confirmed by experiments. However, the patch-based classification method has two inherent defects that can not be avoided. On the one hand, the features of neighboring patches are similar and the proportion of overlapping regions is extremely large. Thus, there is a large amount of redundant computation, resulting in wasted resources and low efficiency. On the other hand, there is a lack of long-distance information exchange. As a result, the method can not fully exploit the contextual information in high-resolution RS images, with difficulty in completely and accurately extracting buildings from complex backgrounds.
Fully convolutional network (FCN) [
16] is a landmark pixel-based segmentation method proposed to provide new inspiration for applying CNNs to advance building extraction research. The core idea is to use existing CNNs as encoders to generate hierarchical features and use upsampling means such as deconvolution as decoders to reconstruct images and generate the semantic labels, eliminating the fully connected layer exclusively. A classical encoder-decoder structure is formed, which can theoretically accept images of different sizes as network inputs and output semantically labeled images at pixel level with the same resolution. There exists a common point in current segmentation networks, i.e., feature extraction is performed by the encoder in the process of performing multi-stage downsampling, and the decoder gradually recovers the size and structure of the image in the process of upsampling and generates semantic annotations. Based on this starting point consideration, a popular approach is to use the image classification network with the fully connected layer removed directly as a feature extraction network, i.e., encoder, such as VGG-16, GoogLeNet and ResNet; the decoder part is composed of upsampling modules such as deconvolution, which eventually generates dense pixel-level labels.
However, in spite of a robust approach, there are limitations in the classical FCN model for building extraction from RS images:
- 1.
RS images are usually high-resolution with rich contextual semantic information, while the classical classification network is not sufficient for mining global contextual information.
- 2.
CNNs do well in mining local features, but not in modeling long-distance association information. It is difficult for the plain decoder structure to reconstruct the structured hierarchical detail information, such as building boundaries and contours, which is lost due to the decrease of feature map resolution caused by the encoder downsampling.
- 3.
The RS images are informative, so the processing of building extraction problem should focus on the model operation efficiency while ensuring the segmentation accuracy.
In this section, we first give an overview of the baseline methods such as FCN, SegNet [
17], and U-Net [
18] applied to building extraction. These problems mentioned above are then reviewed along with the current feasible solutions to these problems.
Table 1 shows the main methods involved in the review (in the order in which they appear in this section), containing the architectures involved in the methods, their main contributions, and a hierarchy based on their task objectives: accuracy (ACC) and reusability (Reu) of the model structure. Specifically, Reu indicates whether the advanced network modules proposed in the literature can be reused relatively easily by other partitioned networks or studies. Each objective is divided into three grades, depending on the degree of focus of the corresponding work on that objective. From the perspective of accuracy, aggregating multi-scale contextual information, considering boundary information, iterative refinement and adopting appropriate post-processing strategies are aspects to be considered. Network components with good reusability are usually robust while not producing large changes in the size of the input and output feature maps, such as attention modules. Moreover, they are usually designed with the objective of aggregating certain elements that are useful for accomplishing the target task.
4.1. Baseline Methods
FCN, SegNet, and U-Net all employ an encoder-decoder architecture, but offer different aspects of design mindsets that are reflected in the encoder, upsampling, and skip connection, respectively.
The encoders for FCN and SegNet are usually obtained by removing fully connected layers using classification networks such as VGG-16 and ResNet, and the encoder for U-Net is designed to be symmetric with the decoder, allowing the depth of the network to be increased or decreased depending on the complexity of the task.
The decoder structure of FCN is the simplest and contains only one deconvolution operation, while U-Net and SegNet adopt multiple upsampling to organize the decoder structure.
There is a feature fusion by FCN with feature maps organized by pixel-by-pixel summing, U-Net with feature map stitching, and SegNet with pooling indices generated by pooling operation embedded in the decoder feature map to solve the problem of insufficient recovery information in the upsampling process.
These three types of basic methods have been applied to the building extraction problem since a few years ago [
3,
83,
84,
86,
87,
88,
89], which have recently been used mainly as a baseline to motivate new methods and to compare their effectiveness.
4.2. Contextual Information Mining
The key points of building extraction are mining local information (short-distance contextual information around pixels such as building outline and boundary) and global information (long-distance contextual information between buildings and background and overall association relationship between buildings and buildings with other pixels in the image). Rich local information helps to improve the accuracy of pixel-level annotation, while complete global information is also essential to resolve local blur. It is the concern of all DL-based building extraction methods to balance and fuse these two aspects.
4.2.1. Global Information Mining
An encoder that contains only backbone network such as VGG-16 and ResNet for feature extraction is imperfect. It is specialized in extracting local information at short distances, but not able to adequately extract contextual information at long distances, which is mainly due to the inherent properties of CNNs.
A popular approach to get out of this dilemma is to develop network modules based on self-attention mechanisms. Non-local block (NB) [
112] is a self-attention network module developed to extract global information and efficiently capture global contextual information by computing the similarity relationship between each pair of pixels. At the same time, NB ensures that the input and output shapes are the identical and can be migrated to different networks in a "plug-and-play" manner. The global information is properly fused with the local information extracted by CNN to enhance the building extraction capability of the model. However, the computational effort of NB is closely related to the resolution of the input image with the drawback of high time complexity and high spatial complexity of computation, which reaches
. Asymmetric pyramid non-local block (APNB) [
113] was introduced by Wang et al. [
91] for contextual global information extraction, and it employs four adaptive pooling layers of different scales to reduce the number of pixels involved in the relational computation. Due to these pooling layers, the time and space complexity of APNB is reduced to
, where N is much smaller than
. To better balance the conflict between extracting local and global contextual information and coordinating the relationship between different scales and levels, Zhou et al. [
92] combined atrous spatial pyramid pooling (ASPP) [
114] and NB both structures to propose a pyramidal self-attentive module for convenient embedding in the network, which further enhances the information processing capability of FCNs. Overall, the self-attention mechanism can be cleverly attached to other convolutional networks, but it suffers from an inherent drawback that it can destroy the short-range association and detailed information between buildings to some extent, and should be used in conjunction with other means.
4.2.2. Boundary Contour Refinement
CNNs have spatial transformation invariance, which makes it impossible to accurately locate spatial locations when modeling long distances, so FCNs fail to accurately label the boundary contours of buildings. However, properties such as contours and boundaries are of great significance for buildings.
A feasible way to optimize the segmentation results is to introduce a second-trained conditional random field (CRF) as a post-processing module in the last layer of the segmentation network. The common implementation of CRF is a fully connected network that mines the interrelationships between long-range pixels without distance constraints, a characteristic that is difficult to be taken into account by CNNs. Shrestha et al. [
93] argues that FCN involves upsampling operations that produce rough borders for building segmentation and extraction results. In contrast, among RS image segmentation, two pixels with similar location and color features have a high probability of being assigned the same label, and vice versa is less likely to be segmented. Hence, the fully connected CRF can be used to improve the FCN-8s with VGG-16 as the encoder to exploit the association characteristics between pixels and improve the blurring at the building boundaries. CRFs in the form of fully connected networks are separated from the previous CNN module when used as a post-processing module for segmentation results, and the previous CNN module is usually fixed during training of CRFs without information interaction with the features extracted by the CNN. Li et al. [
71] proposed the feature pairwise conditional random field (FPCRF) based on the graph convolutional network (GCN) [
115,
116,
117,
118,
119], which is a CRF for pairs of potential pixels with local constraints, incorporating the feature maps extracted by the CNN. FPCRF module can be added to the building segmentation network as a plug-and-play component to improve the segmentation performance of the model without significantly increasing the training and inference time. In addition, the training efficiency of FPCRF is significantly higher than that of the fully connected form of CRF. Sharing a similar design idea with CRF, Maggiori et al. [
94] designed a recurrent neural network-based post-processing module for segmentation results by analyzing the mathematical process of partial differential equations for the refinement process when considering the boundary refinement of building segmentation, which enhances the the confidence level of pixel classification and thus optimize the segmentation details.
It is time consuming to find a better CNN network architecture with no guarantee of robustness of the new CNN model. Another way to solve the boundary problem is to design boundary-aware networks in a targeted manner, and boundary labeling can be simply obtained by applying morphological erosion operations through building labeling. The branch network for boundary extraction is used to guide the semantic segmentation network to learn more information about the building boundaries that contribute to image segmentation. Bringing in a branch network focusing on boundary information processing in the segmentation network [
95,
96], the model achieved fine segmentation results by training the network with a joint loss of multiple branches, such as boundary-aware perceptual loss (BP loss).
Shao et al. [
97] provides an idea of segmentation refinement by drawing on the design of residual networks, and the proposed network consists of two parts: a prediction module and a residual refinement module. The prediction part is a conventional segmentation network with encoder-decoder structure, and the residual refinement module is a residual learning module that accepts the coarse segmentation results generated by the prediction module to learn the different information between the coarse segmentation results and the true annotations. The whole network is trained jointly by a multi-branch loss function. The residual refinement module has a deeper hierarchy and large perceptual field with easy portability to other fully convolutional neural networks, thus improving the refinement capability of the basic segmentation network for boundary contour. Shi et al. [
98] analyzed the conflict between the downsampling operation of deep CNN and the accurate segmentation of boundaries, and introduced a gated GCN based on GCN design into the CNN structure, which is able to refine the coarse semantic prediction results to generate clear boundaries and high fine-grained pixel-level classification results.
It is good to take into account the boundary information and some specific structures and train the network with joint loss, but the richness of the boundary samples can also be an important factor that should not be ignored to limit the performance exploration of such methods.
4.2.3. Dilated Convolution
Dilated convolution [
120], also known as atrous convolution, has a convolutional kernel that encompasses a larger region in a mesh without significantly increasing the computational effort. It is able to rapidly increase the perceptual field while maintaining image resolution, alleviating the conflict that deep network features have a theoretical perceptual field much smaller than the actual perceptual field [
121], thus making it easier to model multi-scale contextual information. Hamaguchi et al. [
99] enhanced the extraction of local features with a reasonable stacking of small dilation rate dilation convolutions, effectively reducing the cases of ambiguous results for small-sized building segmentation.This property of that is used to extract multi-scale contextual information, and the most popular design structure is ASPP, as shown in
Figure 10. ASPP mines feature information at different scales in parallel with multiple sets of dilation convolution kernels of different sizes. The proper dilation rate design ensures that each pixel location is involved in the computational side. Feature maps generated by multiple parallel branches are stitched together.
The success of the DeepLab models [
21,
22,
23,
24] can be attributed to the innovation of the ASPP module, which has made a splash in the segmentation of natural images and has also been widely introduced in the study of building extraction [
102,
104]. Kang et al. [
100] proposed a dense ASPP for quantitative analysis of image input size and perceptual field reality, named dense spatial pyramid pooling (DSPP) module, which consists of five parallel convolution or pooling layers. It consists of two dilated convolutions with dilation rates of 3 and 6, two standard convolutional layers with sizes of 1 × 1 and 3 × 3, and one pooling layer, obtaining dense multi-scale contextual information better than ASPP.
Different from the dilation convolution module with parallel structure like ASPP, Liu et al. [
101] designed a self-cascaded multi-scale context aggregation module as shown in
Figure 11. The semantic extraction module at each level is implemented by dilation convolution with different dilation rates, fusing multi-scale semantic information at different resources level by level. The self-cascaded module aims to aggregate global to local contextual information while well preserving hierarchical dependencies, i.e., the underlying containment and relative location relationships between objects and scenes at different scales.
4.2.4. Multi-Scale Prediction
An alternative approach to aggregate contextual information is to use a multi-scale prediction strategy, i.e., to guide the feature information towards the general direction of accurately labeled buildings as it propagates through the decoder step by step. In the process of decoder recovering feature map size to produce labeled images, the parameters of each convolutional block influence the change of feature mapping, so that the process of decoder expanding feature map size is full of many uncertainties. For this reason, a multi-scale prediction can be adopted to guide this process, which can be shown in
Figure 12. Feature maps of different sizes are gradually generated during the upsampling process, where each prediction map aggregates the scale information of the previous level and requires the network to gradually produce better predictions.
Ma et al. [
90] designed a distillation decoder containing an upsampling branch and a multi-scale prediction branch. The upsampling branch contains five deconvolution layers, and the multi-scale branch aggregates the multi-scale feature maps generated by the last four upsamplings without considering the information generated by the first upsampling since it contains only little high-level semantic information. Model ablation experiments show that the aggregation of multi-scale information for prediction is effective and significantly outperforms baseline methods such as FCN, SegNet, and U-Net for building extraction on RS images. Ji et al. [
102] introduced a multi-scale prediction module based on FCN, which generates multiple independent prediction maps simultaneously in the process of aggregating multi-scale information, imposing restrictions on the generation and transmission of each scale information level by level, guiding them in the direction that is conducive to producing better prediction maps. In addition to the restrictions imposed step-by-step inside the network, it is possible to bootstrap externally during the training phase without affecting the inference speed. Li et al. [
103] and Pan et al. [
106] proposed the models by applies the design idea of generative adversarial network (GAN), where a discriminative network is attached to the segmentation network to guide the segmentation network to generate annotated images that are very similar to the real annotations, and make the discriminative network unable to distinguish whether the input annotated images are real annotations or not. This adversarial training approach is shown to be effective and can be transferred to other models to improve model performance.
Multi-branch networks prove to be an important and effective means of extracting multi-scale information, but can limit the speed when inferring. A suitable network post-processing technique is the way to break this limitation.
4.2.5. Feature Fusion
Feature fusion aims to integrate global feature maps from different layers and relatively local feature maps by introducing contextual information in the network architecture in the form of skip connections. A commonly used approach is primarily the pixel-by-pixel position summation of feature maps from FCN and the stitching of feature maps along the channel dimension from U-Net, which are widely used in RS image segmentation networks [
104,
105]. However, it is clear that the capability of the feature maps from different layers to provide information is varied and even in conflict, which may accumulate noisy information irrelevant to the segmentation task.
Bringing in attention mechanism is an important means to improve the way of feature fusion. Pan et al. [
106] chained spatial attention module (SAM) and channel attention module (CAM) in fusing low-level features, enabling segmentation networks to selectively enhance more useful features in specific locations and channels. He et al. [
107] designed a two-stage attention structure for exploring the correlation between different feature channels of intermediate features. The network module contains two parallel channel attention modules of different forms for extracting channel correlation features, which can be easily embedded into segmentation networks such as U-Net to enhance the segmentation capability.
4.3. Lightweight Network Design
Building extraction is usually performed in high-resolution images so that the design of segmentation networks has to take into account the consumption of computational resources such as GPU memory and the inference speed of the prediction phase. However, most existing methods usually require a large number of parameters and floating-point operations to obtain high accuracy, which leads to high computational resource consumption and low inference speed.
In order to achieve a better balance between accuracy and efficiency, a common approach is to apply an existing lightweight network or adopt a more efficient convolutional module to develop a lightweight network as a feature extraction network [
122,
123,
124]. Lin et al. [
108] and Liu et al. [
109] developed new feature extraction backbone networks with deep separable convolutional asymmetric convolution respectively, incorporating decoder networks to achieve segmentation results with accuracy no less than mainstream networks such as U-Net, SegNet, and earlier lightweight networks such as ENet [
125], with significantly lower number of parameters and computational effort.
4.4. Multi-Source Data
Extracting buildings from RGB images is currently the most widely used method. However, DSM elevation data and LiDAR data are widely used as auxiliary data to correct the angle of the building and pinpoint the location of the building to improve the accuracy of building segmentation. In other words, RGB data provides extensive background color information and building shape information, while DSM elevation data and LIDAR data provide accurate relative position information and three-dimensional spatial information. The fusion of RGB images with data from other sources exists in two main stages, the pre-processing stage before input to the network and the post-processing stage of the network.
Data fusion in the previous stage typically involves attaching multi-source data such as DSM as an additional channel to RGB images to form multi-channel data [
110,
111]. However, the approach of direct fusion of data ignores the variability of different data sources. Huang et al. [
2] utilizes independent FCNs to provide segmentation results based on data from different data sources and performs feature fusion at the final layer with confidence votes to obtain the results. Bittner et al. [
85] employs multiple mutually independent encoder networks for feature extraction from multiple sources of data separately, and the segmentation results are derived with a decoder after fusing the features.
5. Discussion and Outlook
In the previous sections we have reviewed the existing methods qualitatively, that is, we have not considered any quantitative results. In this section, we gather the results of the runs of these methods on the three most representative datasets (Massachusetts Building Dataset, Inria building dataset and WHU aerial imagery dataset) in terms of the metrics described in
Section 3 and perform analysis. In addition, we provide an outlook on possible directions for future research.
5.1. Analysis of Quantitative Experimental Results
After an extensive survey of the literature in recent years, it can be found that the experimental results of many methods are conducted on some non-standard datasets, which undoubtedly makes it difficult to engage in comparison of methods from different literature. Therefore, in this section, three widely used publicly available datasets are selected for the summary of quantitative experimental results. The collected experimental results are shown in
Table 2,
Table 3 and
Table 4.
However, the different settings of the experimental hyperparameters (e.g., training time and number of iteration rounds) still make it difficult to compare the newly developed and diverse approaches fairly even if these methods use the same dataset for experiments. Most of the approaches in the literature are compared with well-known baseline methods such as FCN, U-Net, and SegNet to demonstrate the effectiveness of the new methods.
It is worth mentioning that there are some approaches (e.g., ESFNet) whose research goal is to limit the complexity of the model or to pursue the speed of network inference, i.e., to make the model lightweight without significantly reducing its segmentation capability and to make the study of building extraction more relevant to practical application scenarios.
Table 5 shows the amount of FLOPS and the number of parameters for some of the networks involved in this paper. Even though we do not compare the computational complexity measures of all the networks for completeness because the complexity-related measures are not clearly given in the original paper, we can still find the following patterns. Real-time semantic segmentation networks such as ENet, ERFNet and EDANet, as well as the efficient building segmentation network ESFNet, are dedicated to developing lightweight models with much lower number of parameters and FLOPS than other segmentation networks. The remaining networks, except for FCN-8s and Deeplabv3, are almost comparable in terms of computation and number of parameters, and are all controlled within an acceptable range. In addition, some works have reported their training time and inference time, such as GMEDN and ARC-Net. based on their structure and parameter size one can make an estimate of the computing time on GPU, the general model takes about 6 h to train on the Massachusetts building dataset and Inria dataset, and about 0.26 s to infer a patch of 256 × 256 size. But the training time consumption of lightweight model will be greatly reduced. For a larger dataset like WHU, the network may take ten hours or more to train, but random cropping of the input image to a smaller size would shorten that time.
Considering the experimental comparison of methods and their reproducibility, each method should evaluate its results on a standard dataset, including important evaluation metrics such as IoU and F1. An excellent route is to describe their training process comprehensively and disclose their models with corresponding training weights.
Given the performance with respect to the methods, we draw the following points:
- 1.
ResNet and VGG-16 are the most widely used backbone networks for local feature extraction.
- 2.
Dilation convolution is the main underlying module for rapidly increasing the perceptual field and extracting multi-scale information.
- 3.
Skip connection is a necessary way for the intersection of different levels of semantic information.
- 4.
Multi-scale prediction and boundary constraints are powerful tools for improving the information processing capability of the decoder.
When considering the choice of model structure, the following factors can be considered and selected. U-Net can be the first model that can be tried to solve the building extraction problem for a specific region, and usually acceptable results can be achieved. DeeplabV3+ can be an advanced building segmentation network, and some feasible improvements can be developed on it, such as GMEDN, because they are highly scalable. Lightweight real-time segmentation networks based on structures such as channel grouping strategy, deep separable convolution and dilated convolution are an optimal choice when hardware resources are limited within the scene, such as ESFNet.
5.2. Future Research Directions
Based on extensive literature research and summary, it is believed that DL techniques remain the mainstream approach to investigate building extraction and will continue to evolve in the future. However, technical challenges still exist, and the remainder of the section gives some research outlooks.
Multi-source data fusion: RS image segmentation using the combination of RGB images and multi-source data such as LiDAR is an important research direction, but there still exist numerous challenges. There are many multi-source data noises, such as mis-matching of images with LiDAR data, so the robustness of the method is important. Exploring an effective and robust way of multi-source data fusion remains an important research point for the future [
4,
13].
Feature maps fusion: Almost all current FCN segmentation methods use CNN for feature map upsampling and downsampling, which can directly lead to changes in feature map resolution information and thus cause information loss. A feasible approach is to take multiple feature maps from different locations of the network for fusion and complementary information loss [
90,
97,
104,
107], while the specific way of fusing multiple features is an open problem to be studied systematically.
Multi-scale contextual information: Mining of multi-scale contextual information [
104,
105,
107] is a key component of building extraction networks. Although some modules based on dilated convolution attached to feature extraction backbone networks have been developed, further research on more efficient approaches remains necessary.
Boundary optimization: Buildings are usually with a certain regular geometry or a combination of multiple geometries. Therefore, the annotation of boundary contours is extremely important, and improving the quality of boundary segmentation is an obvious research direction to enhance the model segmentation capability. It is a common practice to apply CRF to post-process segmentation results to further improve the accuracy of boundary contour annotation, which is simple in design but has limited room for improvement. A new class of approaches is to exploit a branch network specifically for boundary refinement [
97,
98] as well as a boundary loss function [
95,
96], for which appropriate training strategies are required.
Lightweight network structure: The building extraction study faces a high-resolution RS image application scenario, where the inference speed of the application equipment is limited. Hence, it is of great importance to consider lightweight factors when designing segmentation networks, so that the networks can consume less computational and storage resources while ensuring little performance loss of the segmentation models [
108,
109]. One possible research direction is to separate the training and inference phases of the network. Multi-branch networks are easier to train and get good segmentation capability, while single-branch networks are faster in inference [
128,
129]. Therefore, the network structure can be merged or pruned during inference to improve the application capability in real scenarios.
6. Conclusions
In this paper, we focus on RS-based building extraction using DL semantic segmentation methods. Compared to other surveys on traditional building extraction methods or RS, this review paper is more devoted to the popular topic of DL semantic segmentation, covering the state-of-the-art and latest work. We analyse the building extraction problem and the basics of DL, providing the reader with the basic features of RS related to building distribution and the basic deep learning knowledge to conduct this research. We cover multiple types of popular DL semantic segmentation methods for solving building extraction and their associated elements such as datasets and evaluation methods, illustrating their important organization and characteristics so that researchers can grasp the flow of research and current research progress. We investigate the methods involved from two perspectives: qualitative contributions and quantitative performance comparisons. In addition, we provide some helpful insights into the problems and methodological developments in the field, including the limitations and advantages of existing methods as well as the design and selection of networks. However, the work in this paper also suffers from the following two main limitations: no quantitative comparison of those non-open-source studies because of the difficulty of a fair comparison and less attention to downstream tasks relevant to building extraction, such as building instance segmentation and damage change detection. In conclusion, DL methods to solve the automatic building extraction problem from RS images are very powerful and mainstream means to promote practical application scenarios. Therefore, we strongly encourage researchers to make the implementation code of their proposed models and then their application datasets as open as possible, and look forward to a large number of innovations and research lines in the upcoming years.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}