1. Introduction
Well-logging is the process of characterizing the variations in physical properties of formations, such as electromagnetic, acoustic, nuclear radiation, and thermal energy, with depth along a borehole using specialized instrumentation. The interpretation and utilization of well-logging data is particularly important in petroleum engineering [
1,
2]. The conventional methods of well-logging interpretation are empirical and statistical models that establish the relationship between different rock properties and estimate missing log data using correlations [
3].
The application of artificial intelligence (AI) in the field of well-logging is emerging and promising [
4]. In recent years, more and more oilfield researchers are using deep learning techniques to predict different reservoir properties, such as permeability, porosity, and fluid saturation, from available well-logging data to reduce the cost of exploration and development. Researchers have proposed a series of algorithms with shallow-learning mechanisms [
5,
6,
7]. However, these algorithms are only suitable for the application and theoretical analysis of specific-scale data, and their effect is not good for the application of large-sample data analysis or feature extraction from complex feature data. Hinton et al. [
8] pointed out that deep neural networks have a dimensionality reduction effect on high-dimensional data and can characterize the target data well, which can alleviate the difficulties caused by the analysis and recognition of multidimensional massive data to a certain extent, and can become a bright spot of machine learning. Deep learning can represent data feature information at multiple levels; it can automatically abstract high-dimensional data at different levels to accomplish specific tasks [
9].
Well-logging curve reconstruction refers to the data reconstruction of inappropriate parts of existing well-logging curves using correlated data or objective laws obtained from massive data. Because of the advantages of deep learning in feature extraction, previous studies have applied deep learning algorithms to predict the missing well-logging curves by inputting well-logging data and constructing a model with the help of algorithms to achieve the reconstruction of the target curve [
10]. Korjani et al. [
11] proposed a reservoir-modeling method based on deep neural networks for predicting petrophysical characteristics. They used a large amount of geological data from neighboring drilled wells to construct virtual logging data for well sections lacking well-logging curves and core data. Parapuram et al. [
12] proposed a multistage curve generation scheme in which the well-logging curves generated in each stage automatically participate in the next stage to improve the accuracy of the final predicted well-logging curves. Yang et al. [
13] selected four logging parameters—compensation density, acoustic time difference, natural gamma, and mud content—as independent variables of a convolutional neural network (CNN) to reconstruct the variation curves of dependent variables, such as porosity. However, CNNs can only capture the spatial properties of a well-logging curve, and the properties of the rocks usually exhibit a trend with depth. In contrast, recurrent neural networks (RNNs) consider both internal and external inputs from the previous step and, thus, can capture the trend with depth [
14]. Zhang et al. [
15] considered well-logging as a data sequence, and designed a long short-term memory (LSTM) network model to predict the entire well-logging curve or the missing well-logging curve. Pham et al. [
16] integrated bidirectional LSTM (BiLSTM) with a fully connected neural network to generate accurate acoustic logs from neutron porosity logs, gamma ray logs, and density logs. Their proposed method combines the local shapes of well-logging curves with different geological profiles to improve the predictions.
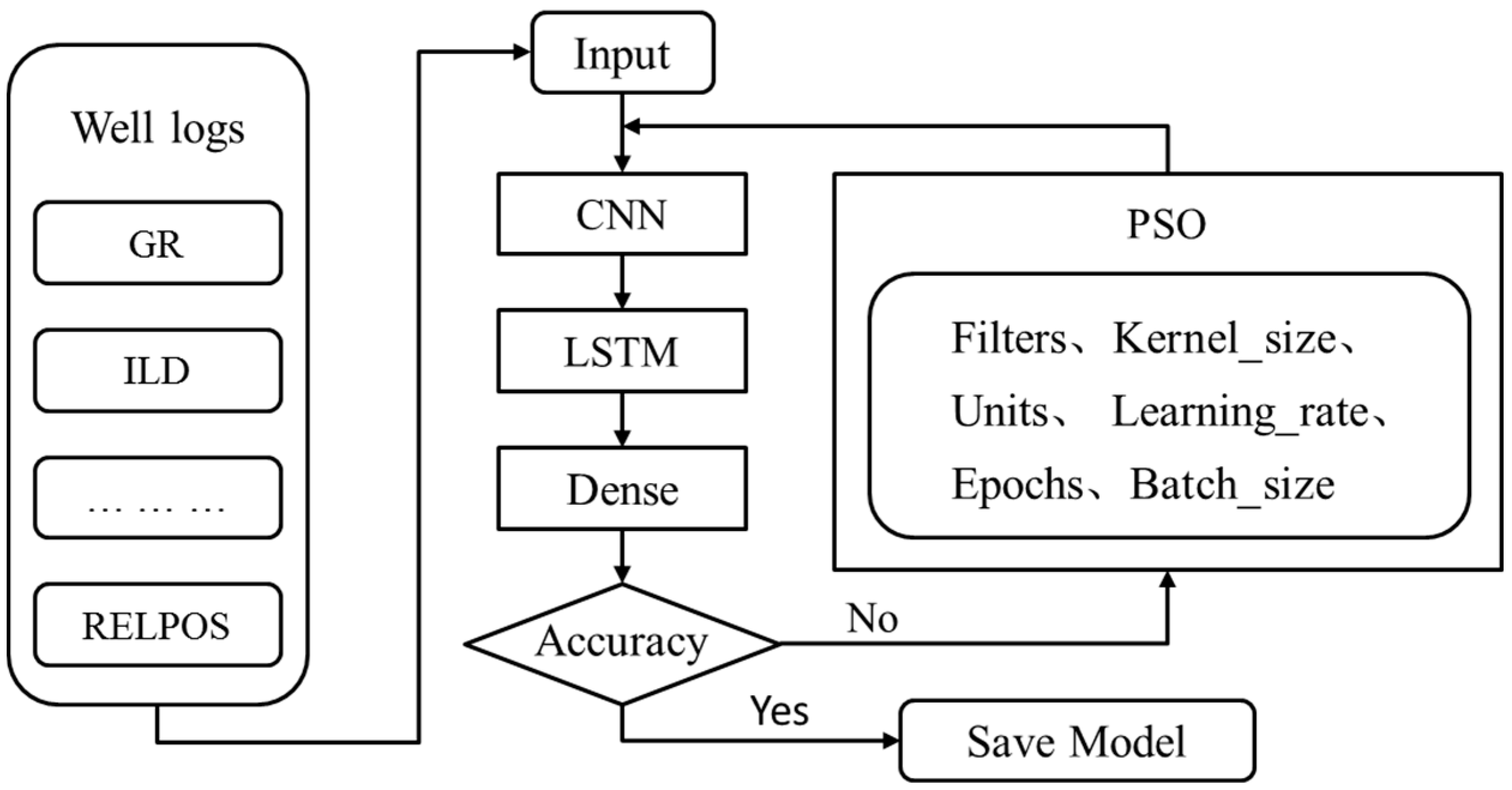
The focus of this study was on the use of machine learning techniques to solve the logging curve complementation and generation problem. Current research using machine learning methods to predict missing well-logging curves can rarely account for both the spatial and temporal characteristics of the logging data. To overcome the shortcomings, we proposed a new neural network architecture that was composed of CNN and LSTM, which respectively extracts the temporal and spatial characteristics of well-logging data to predict the well logs of interest. To further improve the prediction accuracy, the CNN-LSTM model was then optimized by the particle swarm optimization (PSO) algorithm, which is another new contribution of this study.
The main structure of this paper is as follows:
Section 2 introduces the theoretical basis of the basic neural networks CNN, LSTM and PSO used in this study.
Section 3 presents the architecture of the hybrid neural network model (CNN-LSTM-PSO), and describes the evaluation metrics used to evaluate the performance of the CNN-LSTM-PSO model.
Section 4 presents the data source of the well-logging dataset, and performs PE log prediction from other logs of the target well and from logs of adjacent wells with the proposed CNN-LSTM-PSO model. Then, the superiority of the proposed model is evaluated by comparing it with other conventional machine learning methods, such as the SVR, GBDT, CNN-PSO and LSTM-PSO models.
Section 5 summarizes the main problems of using current AI technologies in well-logging applications, and presents our future work. The conclusions are presented in
Section 6.
4. Experiments and Results
The main objective of this section is to evaluate the effectiveness of the CNN-LSTM-PSO model in predicting well-logging curves, as well as to compare the performance and accuracy of the neural network with traditional regression algorithms. All experiments were carried out on the Google Colab platform (1 December 2021,
https://colab.research.google.com) using the Python 3.7 and TensorFlow 2.7 environment to implement the proposed network. Google Colab is a product developed by the Google Research team to write and execute arbitrary Python code through a browser, especially for machine learning and data analysis.
4.1. Experimental Data Set
The experimental data set of this study comprised public data downloaded from GitHub open-source collection of well-logging data (
https://github.com/sunyingjian). In total, eight wells from a gas reservoir in Cornwall, Kansas, were included in the data set. Each well contained seven logging attributes, including natural gamma ray, resistivity, photoelectric effect, neutron density–porosity difference, average of neutron and density logs, nonmarine–marine indicator, and relative position. The data set was divided into training and validation sets using a ratio of 80:20 to evaluate the performance of the CNN-LSTM-PSO model architecture.
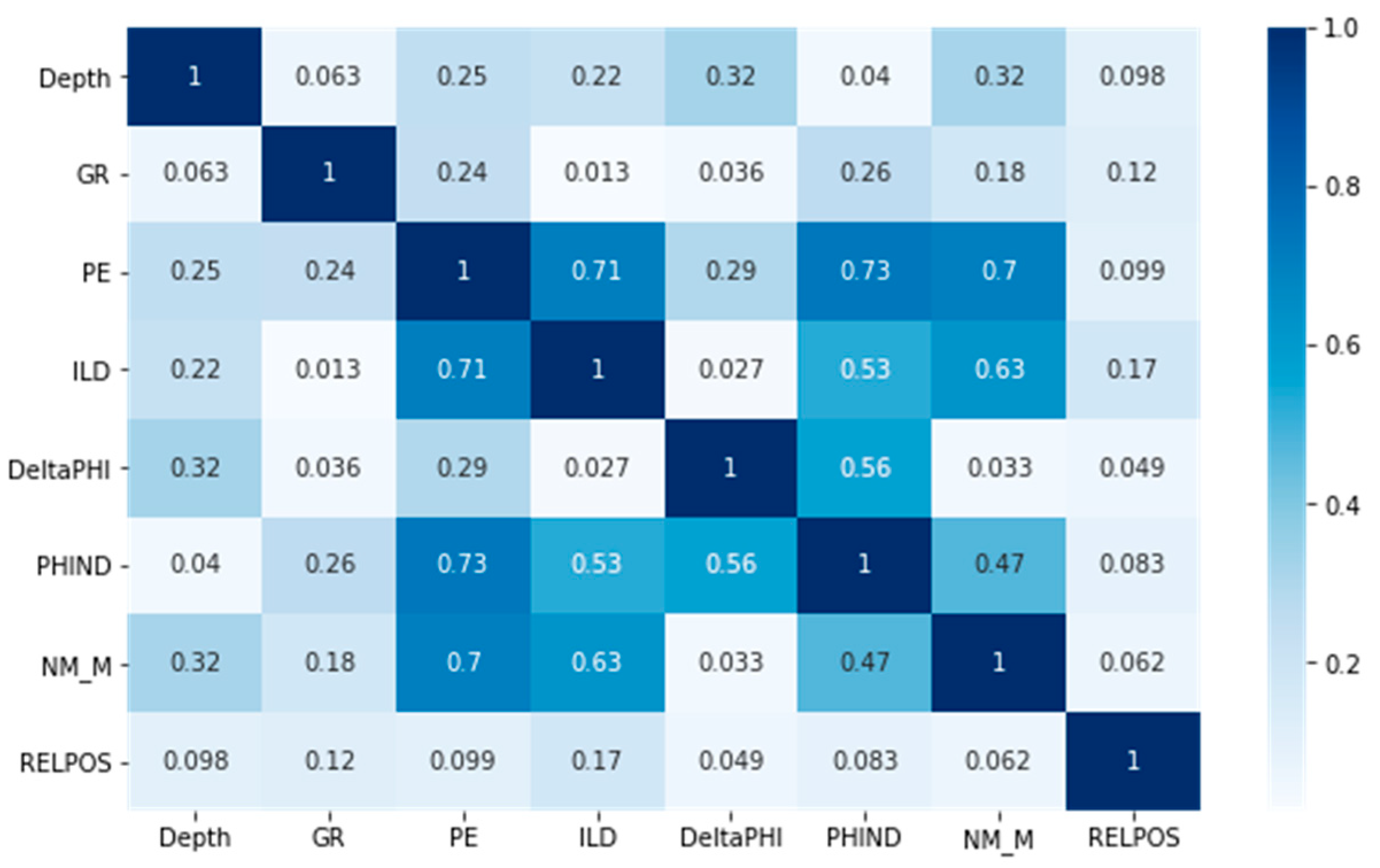
A heat map is often used in practice to display the correlation coefficient matrix of a set of variables [
33]. This also has great applicability in displaying the data distribution of the contingency table. Through heat mapping, we can intuitively feel the difference in value size.
Figure 5 is a heat map of the above seven logging attributes, as well as depth. The right side of
Figure 5 is the color bar, which represents the mapping from value to color. A value from small to large corresponds to the color from light to dark. From the heat map in
Figure 5, we can see that the correlation of the photoelectric effect curve (PE) is the best, with the correlation between photoelectric effect (PE) and average of neutron and density logs (PNHIND) being 0.73, the correlation between photoelectric effect (PE) and resistivity (ILD) being 0.71, and the correlation between photoelectric effect (PE) and nonmarine–marine indicator (NM_M) being 0.7. The photoelectric effect is usually included in modern well logs to provide essential information on formation lithology. However, many legacy wells might not have photoelectric effect logs. Therefore, the photoelectric effect was selected as the target curve in this study, and the remaining six attributes were used as the known characteristic values.
Data preprocessing, including data cleaning and normalization, is important to improving the accuracy of data prediction. Professional engineers perform data cleaning to improve the quality of well-logging data by discarding outliers and noisy information using mean substitution and scatterplot visualization methods [
34]. Normalization usually refers to the scaling of features to (0,1), a special case of normalization adjustment that has the effects of speeding up training and preventing gradient explosion [
35]. In these experiments, to normalize the data, the maximum–minimum scaling adjustment can be simply applied to each feature column, where the new value of the sample can be calculated as follows:
where
is the normalized value of the well-logging curve at the well depth,
is the maximum value, and
is the minimum value. This method is suitable for cases wherein the approximate upper and lower bounds of the data are known, the data have few or no outliers, and the data have an approximately uniform distribution.
After data preprocessing, a data set with a total number of 3232 samples was established in this study. The key characteristics of the well-logging samples are shown in
Table 1. In the study, the data were randomly partitioned into an 80:20 split for training and validation data sets, respectively. The first 80% was used as the training set to train the network model, and the second 20% was used as the test set to verify the prediction accuracy of the proposed model.
A model comparison was performed among a suite of machine learning techniques—SVR, GBDT, CNN, LSTM—and the CNN-LSTM hybrid model to validate the effectiveness of the CNN-LSTM model according to the evaluation metrics of the test set. The various models were optimized by the PSO algorithm for comparison.
4.2. Photoelectric Effect Prediction from Other Logs for the Target Well
The first well, denoted as
Well 1, in the data set was selected as the target well in this section to verify the prediction accuracy of the hybrid network model for single-well analysis.
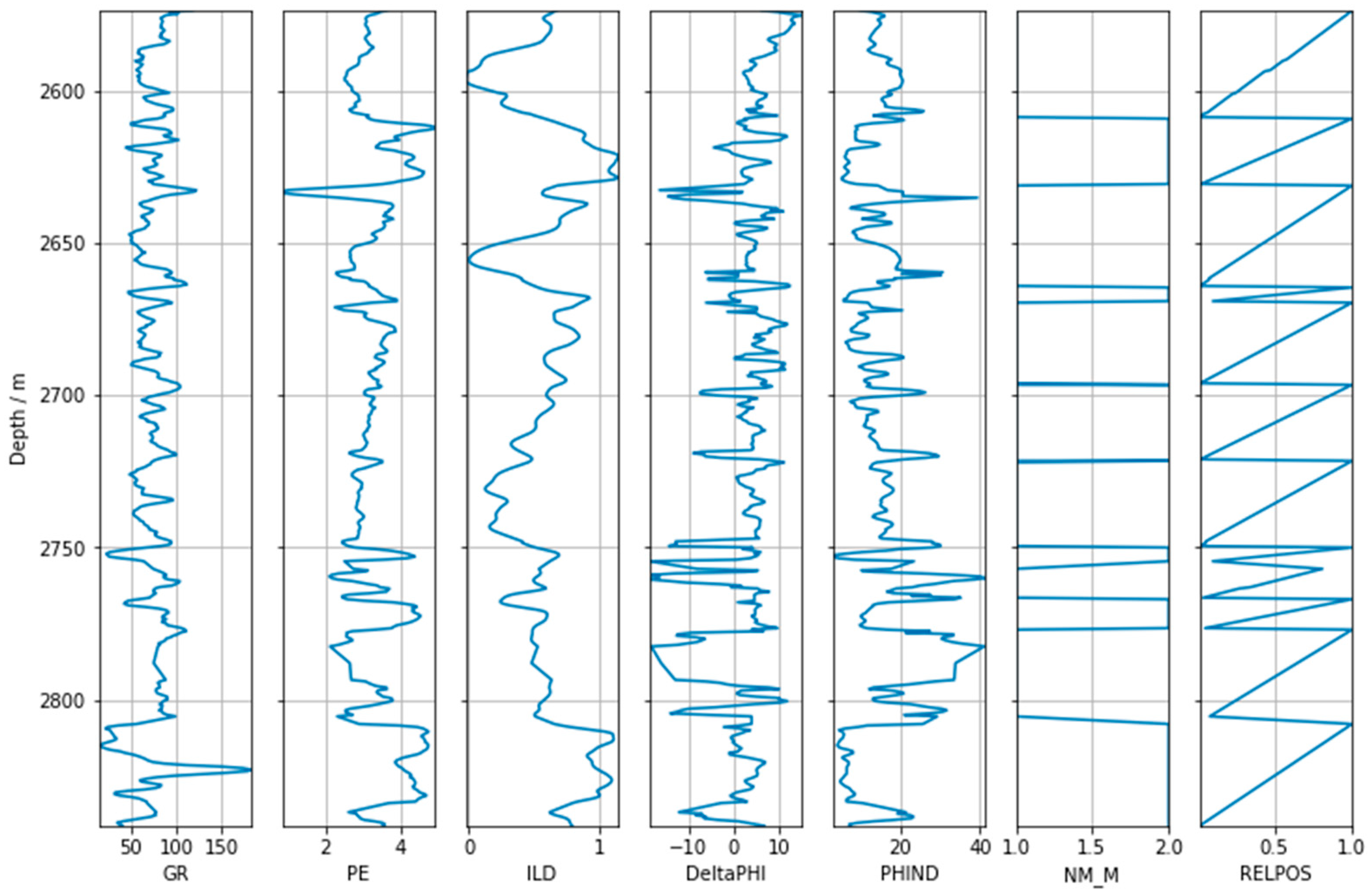
Figure 6 shows the seven well-logging curves of
Well 1. In the experiment,
Well 1 had six eigenvalues for training and prediction logs: gamma ray (GR), resistivity (ILD), neutron density–porosity difference (DeltaPHI), average of neutron and density logs (PHIND), nonmarine–marine indicator (NM_M), and relative position (RELPOS), and the data set was divided into training and validation sets with a ratio of 80:20. The hybrid CNN-LSTM network model was optimized using the PSO algorithm for predicting the photoelectric effect curve in the validation set. The depth of
Well 1 was from 2573.5 to 2841.5 m; therefore, there were 501 sets of data in the well section with a total length of 268 m. The photoelectric effect curves in the last 100 sets of data were manually removed as the prediction targets.
4.2.1. Performance Evaluation of CNN-LSTM-PSO Model
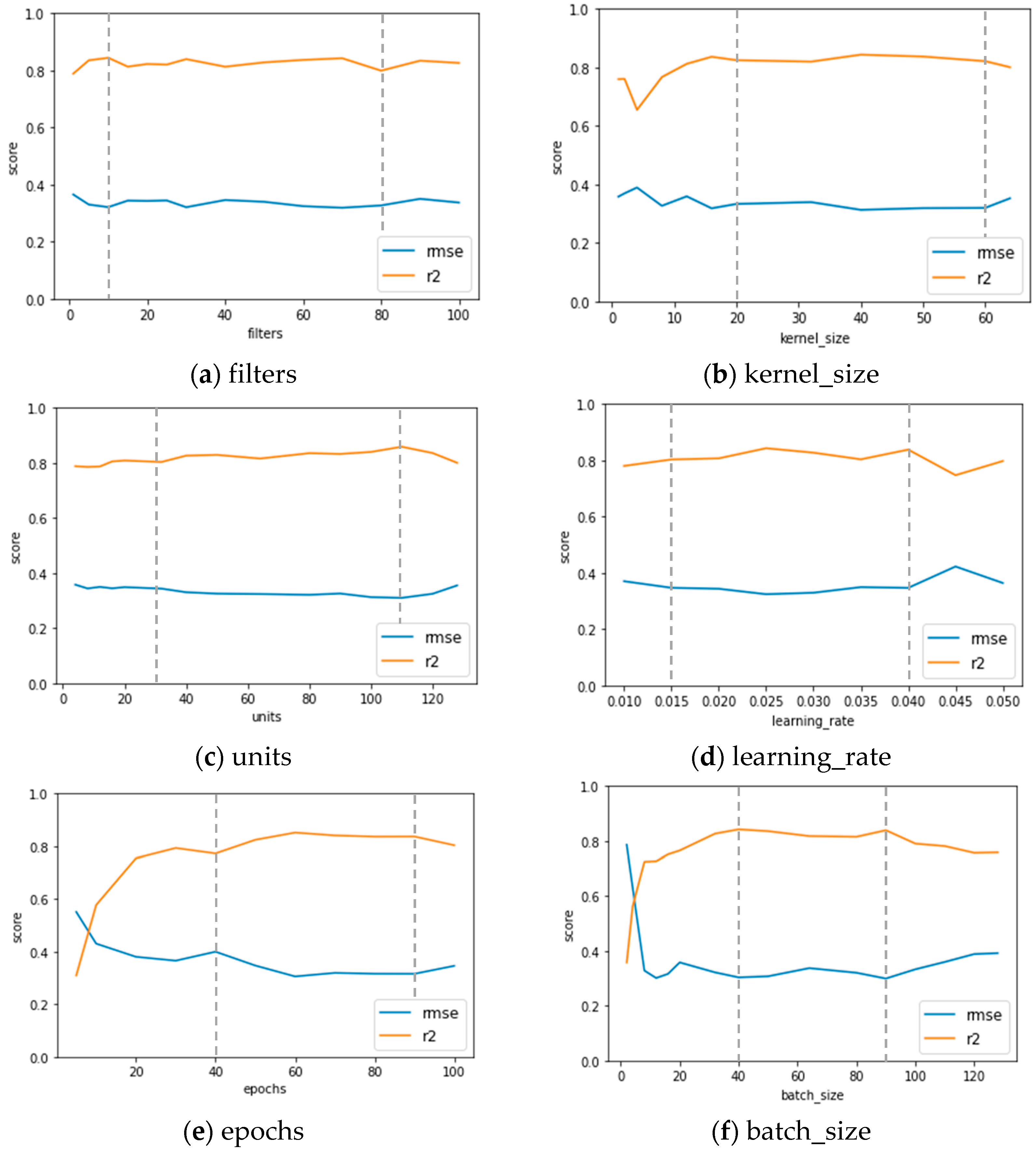
There are seven main hyperparameters in the CNN-LSTM hybrid network model, including filters (the number of CNN filters), kernel_size (the size of the CNN convolutional kernel), units (the number of LSTM hidden neurons), learning_rate (the learning rate of the neural network), epochs (the number of samples trained), batch_size (the size of each batch of data), and number of iterations (the number of times the training data are trained using the network model), which need to be calibrated and determined during PSO iterations. The first step is to analyze the impact of each hyperparameter on the prediction accuracy, and then the analysis result is used to determine the reasonable range of hyperparameters for performing the PSO.
The initial values and ranges of the seven hyperparameters are listed in
Table 2.
Figure 7 shows the curves of the estimated RMSE and
R2 values of each hyperparameter with single-factor analysis by changing one parameter at a time. These curves indicate the effects of each hyperparameter on the prediction accuracy of the logging data. Epochs and batch_size had the greatest effect on the accuracy, as both the RMSE and
R2 curves of these two hyperparameters changed with significant variation during PSO iterations. Based on the results shown in
Figure 7, reasonable ranges for each hyperparameter for performing further PSO were determined, and are given in
Table 2. Furthermore, the CNN-LSTM model with the lowest RMSE and highest
R2 among all the CNN-LSTM models in the single-factor analysis was recorded and saved as a reference model before PSO for further comparison. The lowest RMSE was 0.252, and the highest
R2 was 0.885 among all the models.
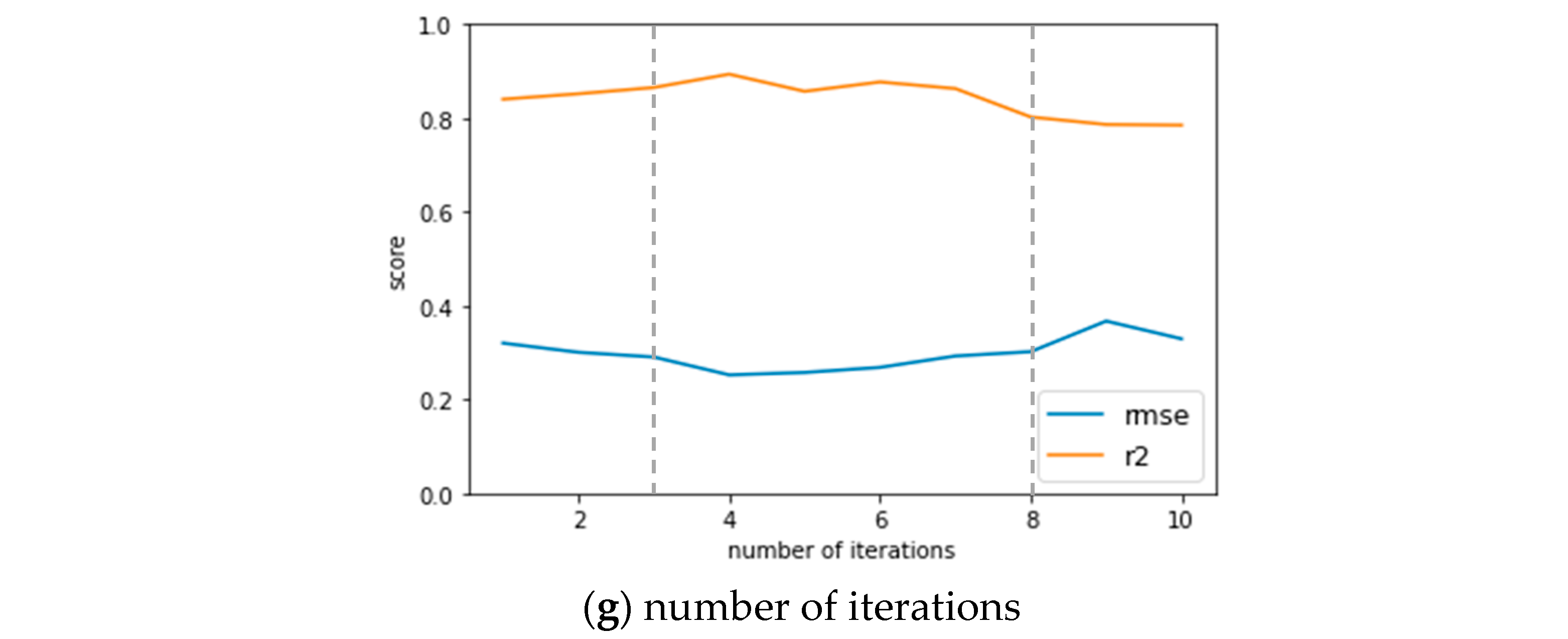
The seven hyperparameters of the CNN-LSTM hybrid network model were selected as the tuning parameters of PSO, and the range of each hyperparameter was finalized according to the results of single-factor analysis. The PSO had a total of 50 iterations with 15 particles each.
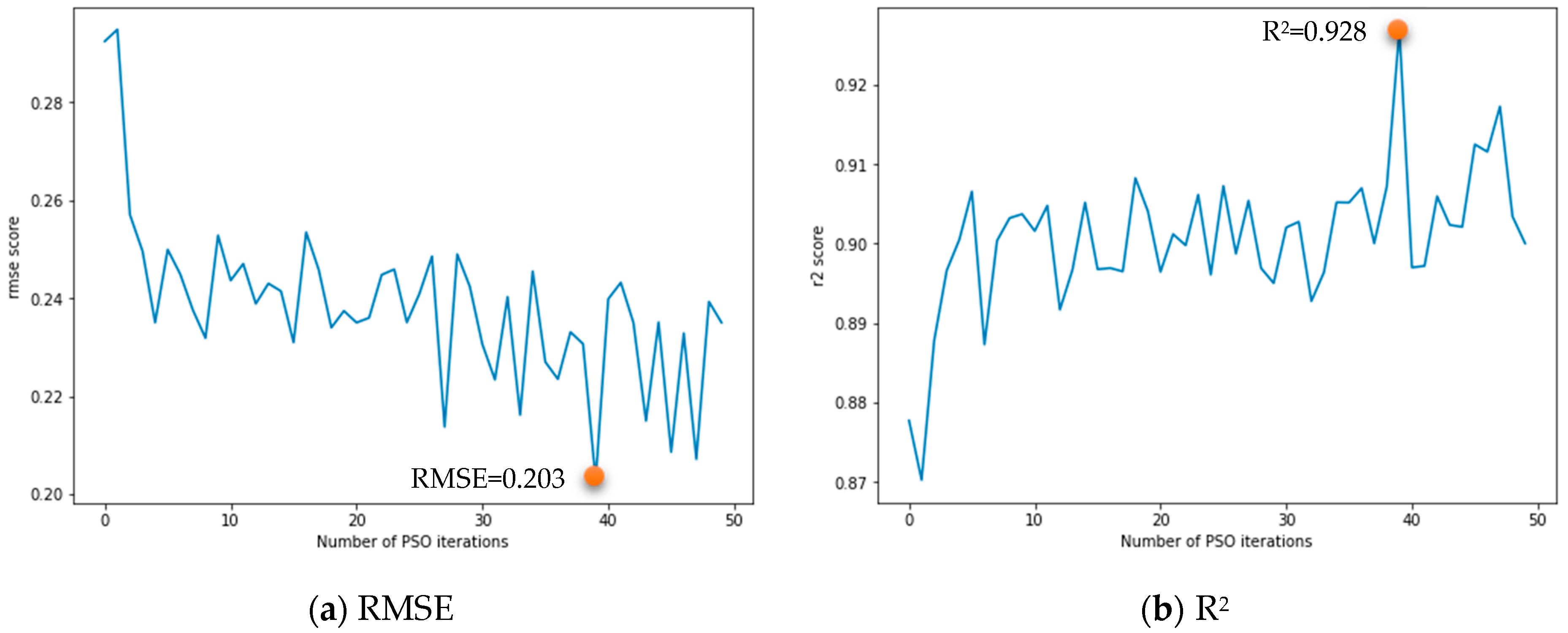
Figure 8 shows the distribution of the optimal RMSE and
R2 for each PSO iteration. As the number of iterations increased, the optimal RMSE showed a decreasing trend and the optimal
R2 showed an increasing trend, indicating that the training effect of the proposed model was getting better and tended towards the global optimum value. The hyperparameters of the optimal CNN-LSTM model with the best evaluation metrics after PSO were then obtained and are listed in
Table 2. The RMSE of the optimal CNN-LSTM model was 0.203, which is 19% lower than that before the performance of PSO (RMSE = 0.252), and the
R2 was 0.928, which is 4.9% higher than that before the performance of PSO (
R2 = 0.885). This means that the optimal CNN-LSTM hybrid network model constructed with the seven hyperparameters determined by the PSO algorithm can greatly improve the accuracy of the CNN-LSTM model.
The model with the best prediction was saved through several iterations of the CNN-LSTM-PSO model, and the saved model was used to make predictions for the single-well test data.
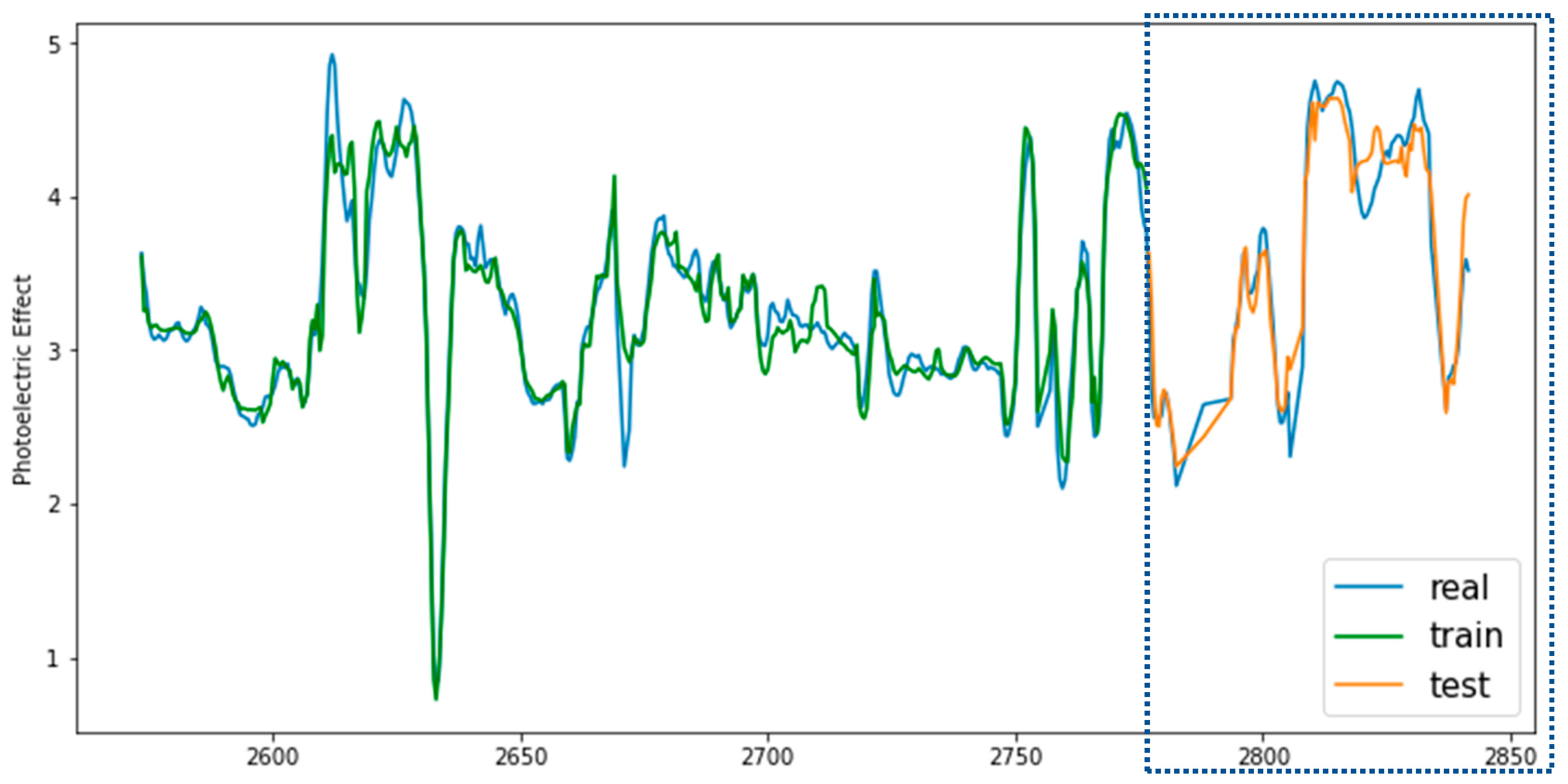
Figure 9 shows the photoelectric effect curve-matching result for
Well 1, where the true value is shown in blue, the predicted photoelectric effect curve of the training data set is shown in green, and the predicted photoelectric effect curve of the test data set is shown in orange. The result shows that the predicted photoelectric effect curves, on both the training and test sets, agreed well with the field logging data.
4.2.2. Model Competition
The CNN-LSTM-PSO model was then compared with traditional machine learning models and deep learning-based AI models for single-well logging prediction analysis. There are many classical machine learning models available for logging curve prediction [
36], such as SVR, GBDT, and artificial neural network (ANN). Among these methods, ANN has become a popular method for logging curve prediction, and SVR and GBDT are very effective methods for logging curve prediction as well. These classical algorithms were used in the experiments to generate logging curves, and the PSO algorithm was used to optimize the model hyperparameters for comparison.
Taking the prediction of the photoelectric effect curve as an example, each model was experimented with several times in independent environments to save the optimal model for prediction. First, we looked at the prediction results of the CNN, LSTM, and CNN-LSTM hybrid neural network models, and compared the prediction results of the models by optimizing the hyperparameters of each of the three neural network models with the PSO algorithm.
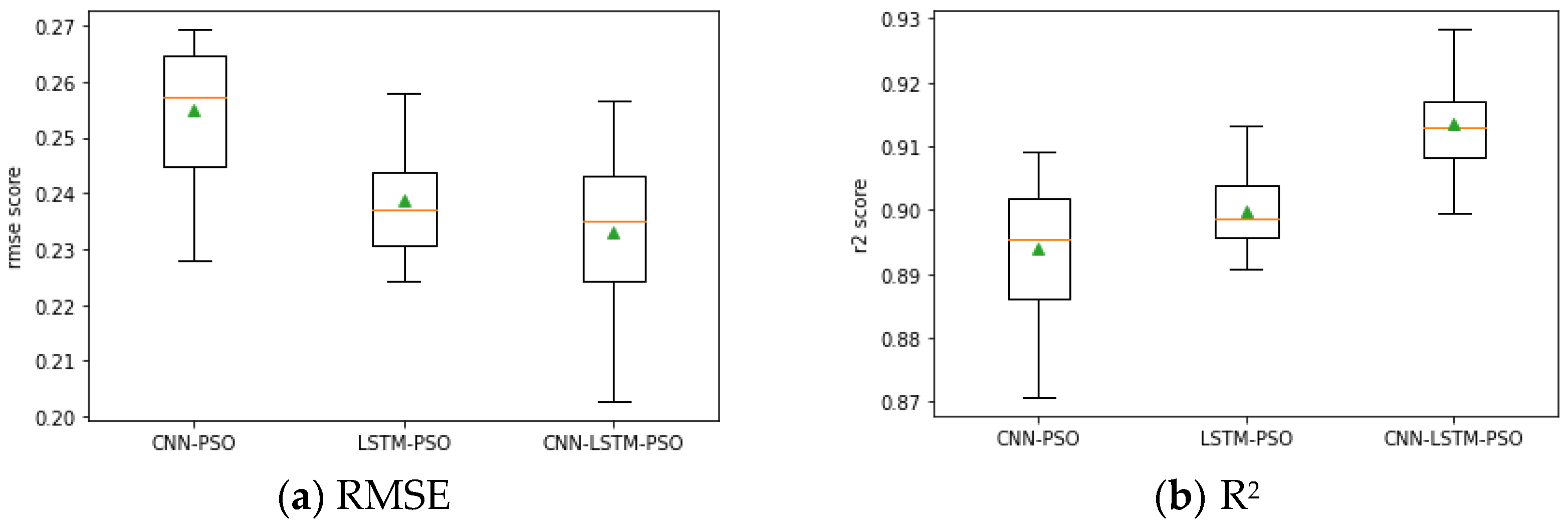
Figure 10 shows a comparison of the best results of the three different neural network models after 10 iterations of the PSO algorithm, with the best value of the lower whisker for RMSE and the best value of the upper whisker for
R2. The orange line represents the median value, and the green triangle is the mean value.
Figure 10a shows the CNN model as having the worst accuracy, because it has the highest mean RMSE and median RMSE among the three models. The LSTM model and the CNN-LSTM hybrid model are shown to have closer median and mean values.
Figure 10b shows the median and mean
R2 values of the CNN model to be slightly lower than those of the LSTM model. The median and mean
R2 values of the CNN-LSTM hybrid model are better than those of the CNN and LSTM models. Therefore, the hybrid CNN-LSTM neural network model is superior to the CNN and LSTM neural network models alone in terms of prediction accuracy.
Looking at the traditional machine learning models, we chose SVR and GBDT in the scikit-learn library and used the default parameters for both.
Table 3 shows the scores of the two evaluation metrics, RMSE and
R2, of the photoelectric effect predictions evaluated by the SVR, GBDT, CNN-PSO (optimized CNN network using PSO), LSTM-PSO (optimized LSTM network using PSO), and CNN-LSTM-PSO (hybrid CNN-LSTM network using PSO) models. Among the classical machine learning algorithms, the GBDT model had an RMSE of 0.321 and an
R2 of 0.783, which values are better than the SVR model. The CNN-PSO model and the LSTM-PSO model had RMSE values of 0.228 and 0.225 and
R2 values of 0.909 and 0.913, which outperform the traditional machine learning methods. The RMSE of the CNN-LSTM-PSO model proposed in this study was 0.203, and its
R2 was 0.928—showing the best performance among all the models. The reason may be that the hybrid structures of the CNN, LSTM, and PSO algorithms can fully extract the spatial and temporal features of the well-logging data.
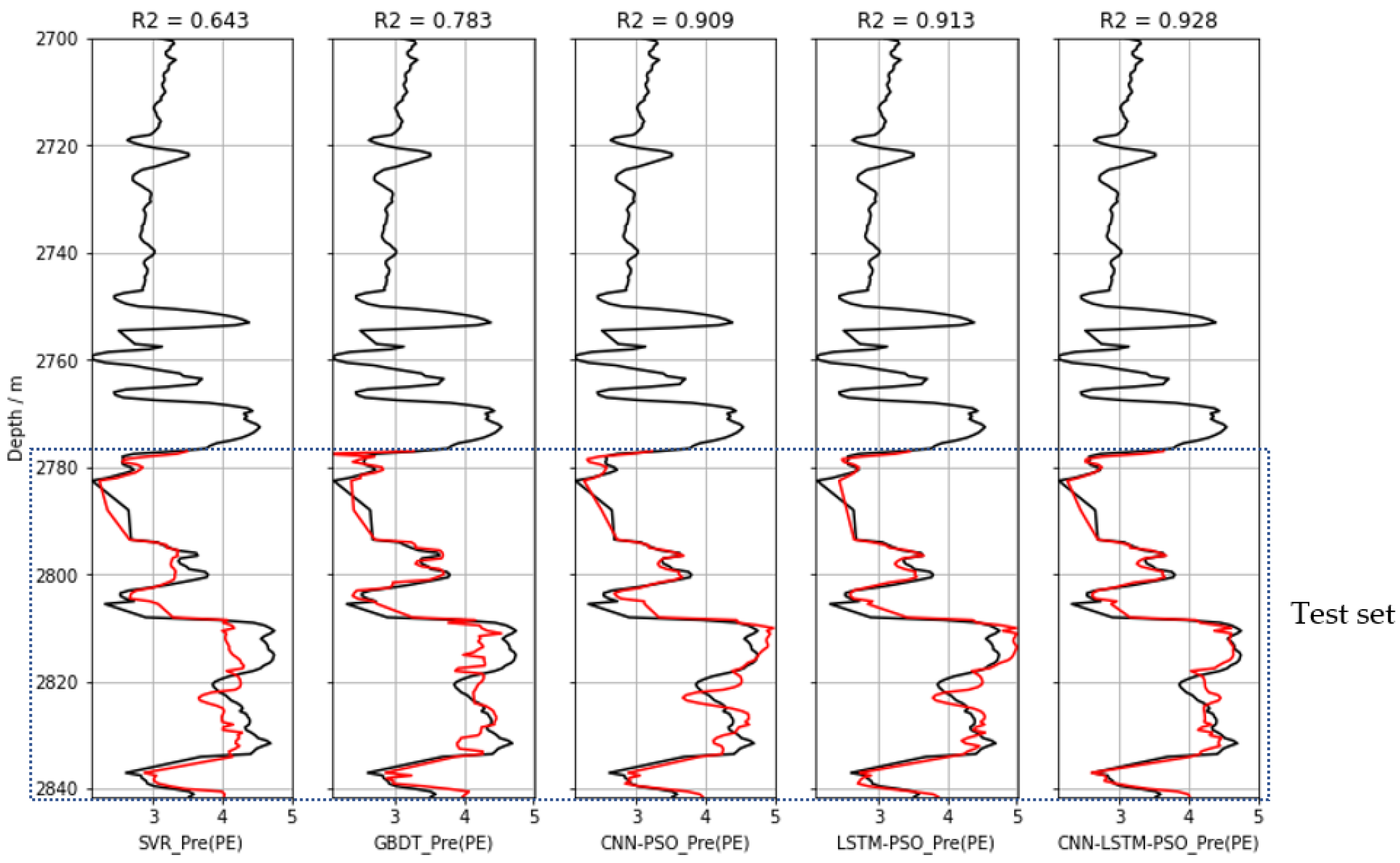
Figure 11 shows the photoelectric effect curves predicted by the SVR, GBDT, CNN-PSO, LSTM-PSO, and CNN-LSTM-PSO models from other logs of
Well 1 test data, where black is the actual measured photoelectric effect curve in the oilfield and red is the prediction result on the 20% test set. Overall, there was a good overlay between the measured photoelectric effect and the predicted photoelectric effect for all five models. The
R2 values of all models ranged from 0.643 to 0.928, indicating that deep learning can accurately predict the trend of the target photoelectric effect curve. However, combining CNN, LSTM, and PSO algorithms was chosen as the best model, as the logging prediction accuracy is significantly improved in this arrangement, and it is more suitable for predicting the photoelectric effect curve. Therefore, the CNN-LSTM-PSO model was proven to be useful for predicting logging curve sequences from other well logs of the target well itself.
4.3. Photoelectric Effect Prediction from Adjacent Well Logs
This section uses the data of multiple adjacent wells to predict the entire missing curve of the target well. Well 1 was selected as the verification set from the eight wells, so all photoelectric effect curve data of Well 1 were deleted from the data set. In other words, only the logging data of the remaining seven wells, as well as the remaining logging data (expect photoelectric effect data) of Well 1, were used as the training set. In the experiments, a total of six logging feature values was used to train and predict photoelectric effect curves, and the PSO algorithm was used to improve the prediction accuracy of the model. There were 3232 total sets of data derived from all eight wells. Among them, 501 sets of photoelectric effect data of Well 1 were manually removed and treated as the prediction target, and the rest of the data sets from Well 1 and the remaining seven wells were used as the training set.
4.3.1. Performance Evaluation of CNN-LSTM-PSO Model
Table 4 gives the initial ranges of the seven hyperparameters (filter, kernel size, units, learning rate, epoch, batch size, and number of iterations) of the CNN-LSTM hybrid network model as the tuning parameters of the PSO.
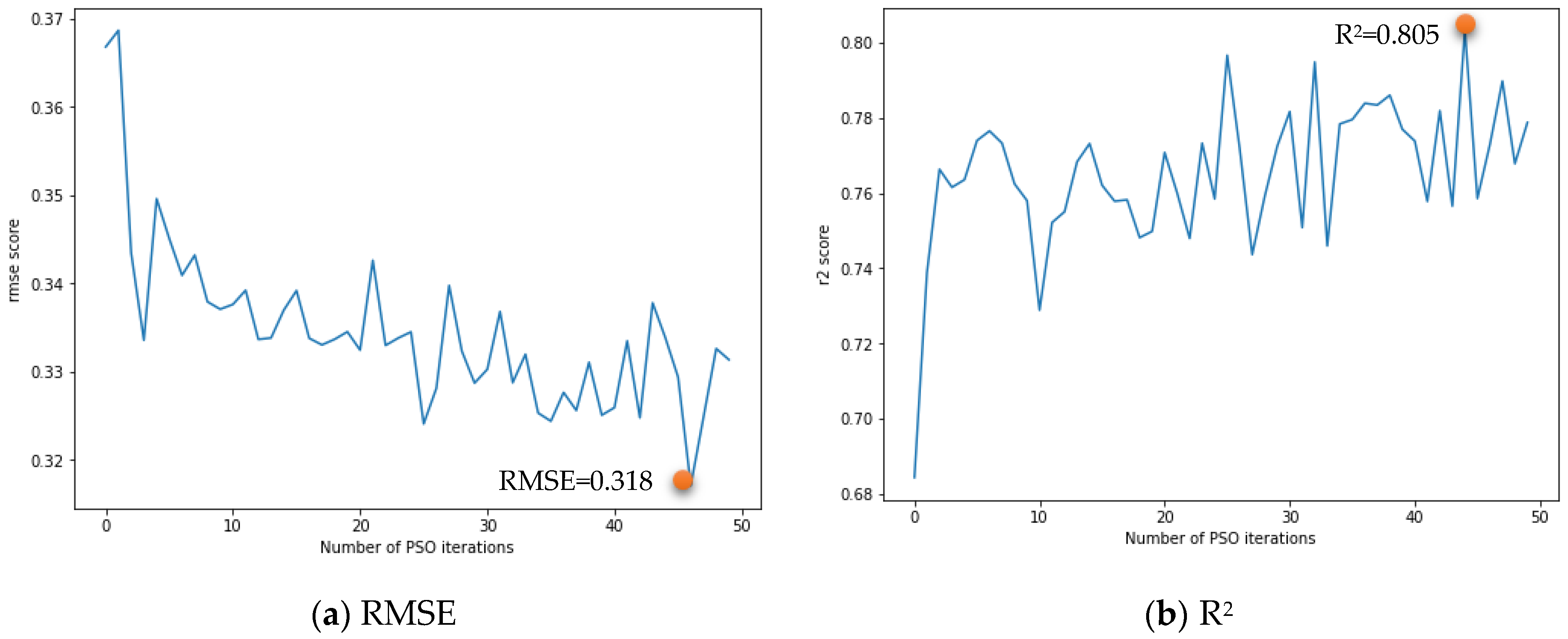
Figure 12 shows the distribution of the optimal values of RMSE and
R2 for 50 iterations of PSO, with the optimal values of RMSE and
R2 converging towards the global optimal values as the numbers of iterations increased. Based on both the RMSE and
R2 values of all PSO iterations, the seven hyperparameters that established the optimal CNN-LSTM model with the lowest RMSE and highest
R2 after PSO were determined and are shown in
Table 4. The RMSE of the optimal CNN-LSTM model was 0.318, which is 13.1% lower than that before PSO (RMSE = 0.366), and the
R2 of the optimal CNN-LSTM model was 0.805, which is 10.3% higher than that before PSO (
R2 = 0.73). The result indicates that the CNN-LSTM-PSO hybrid network model used to predict photoelectric effect logs from multiple adjacent wells can also greatly improve the prediction accuracy of missing logging segments.
The prediction performance of the CNN-LSTM model optimized by the PSO algorithm was then verified by predicting the photoelectric effect curve of
Well 1 on test data sets.
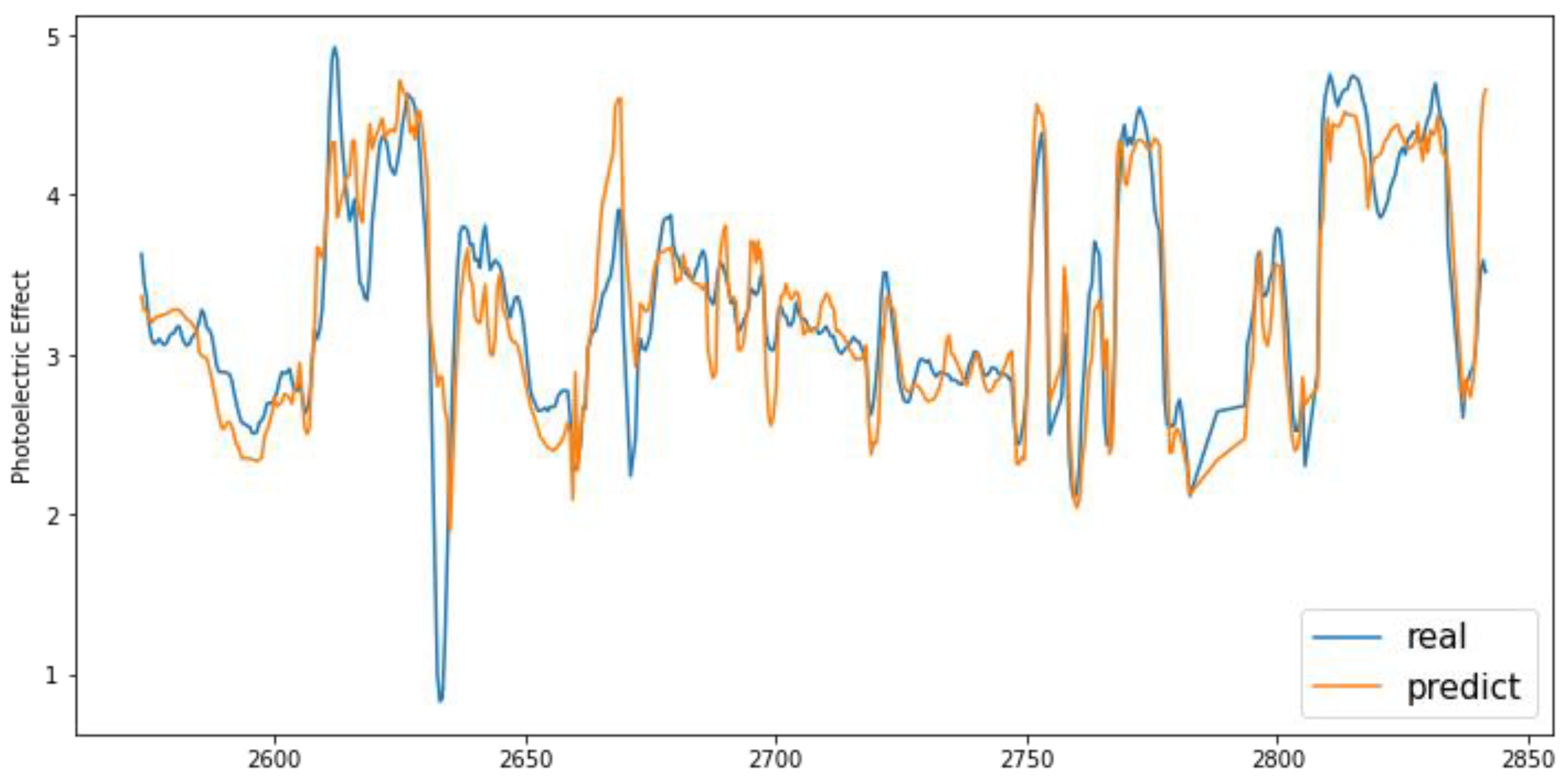
Figure 13 shows both the actual measured photoelectric effect curve of
Well 1 and the photoelectric effect curve of
Well 1 predicted by the CNN-LSTM-PSO model with logs from adjacent wells. The blue curve is the test photoelectric effect data of
Well 1, and the orange curve is the photoelectric effect curves of
Well 1 estimated by the CNN-LSTM-PSO model with adjacent well information. It is obvious that the photoelectric effect curve predicted by the CNN-LSTM-PSO hybrid network model agrees well with the measured photoelectric effect curve from the test data.
4.3.2. Model Competition
The prediction results of the CNN-LSTM model were compared with those of conventional machine learning models, including SVR, GBDT, CNN, and LSTM. Different models were used in the experiments to generate photoelectric effect curves; SVR and GBDT models used default parameters, and the PSO algorithm was used to optimize the hyperparameters of the CNN, LSTM, and CNN-LSTM models. As an example, for photoelectric effect curve prediction for multiple adjacent wells, each model was run several times in independent environments, and the best prediction model was saved for comparison.
The hyperparameters of the CNN, LSTM, and CNN-LSTM models were optimized by the PSO algorithm, and then the performances of the three models in predicting the whole photoelectric effect curve of
Well 1 were examined and compared.
Figure 14 shows a comparison of the local optimum scores in the last 10 iterations of the three different neural network models optimized by the PSO algorithm. Analysis of the RMSE and
R2 values showed the best and average scores of the CNN-LSTM hybrid neural network model to be better than those of the individual CNN and LSTM neural network models.
The traditional machine learning models SVR and GBDT, with the default parameters in the scikit-learn library, were also investigated and compared with the proposed model. To select the best model, the RMSE and
R2 values of the validation data set of the completed models were compared, and the one with the lowest RMSE and highest
R2 was selected.
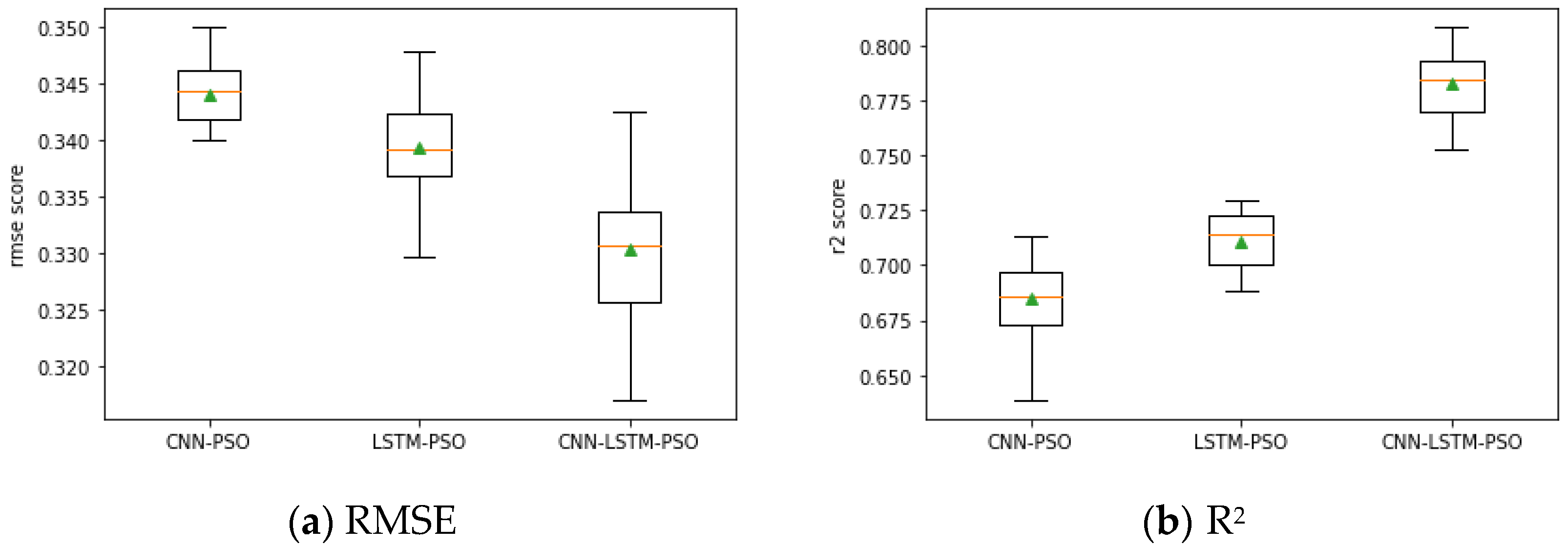
Table 5 shows the scores of the two evaluation metrics used for the photoelectric effect logs predicting by the SVR, GBDT, CNN-PSO, LSTM-PSO, and CNN-LSTM-PSO models with adjacent well information. Among the traditional machine learning algorithms, the GBDT model had an RMSE of 0.359 and an
R2 of 0.703, which are significantly better than the SVR model. The CNN-PSO model and the LSTM-PSO model had RMSE values of 0.340 and 0.331, and
R2 values of 0.718 and 0.732, which thus outperform the traditional machine learning methods. The RMSE of the CNN-LSTM-PSO model was 0.318, and its
R2 was 0.805. The CNN-LSTM-PSO model was obviously the most accurate among all five models.
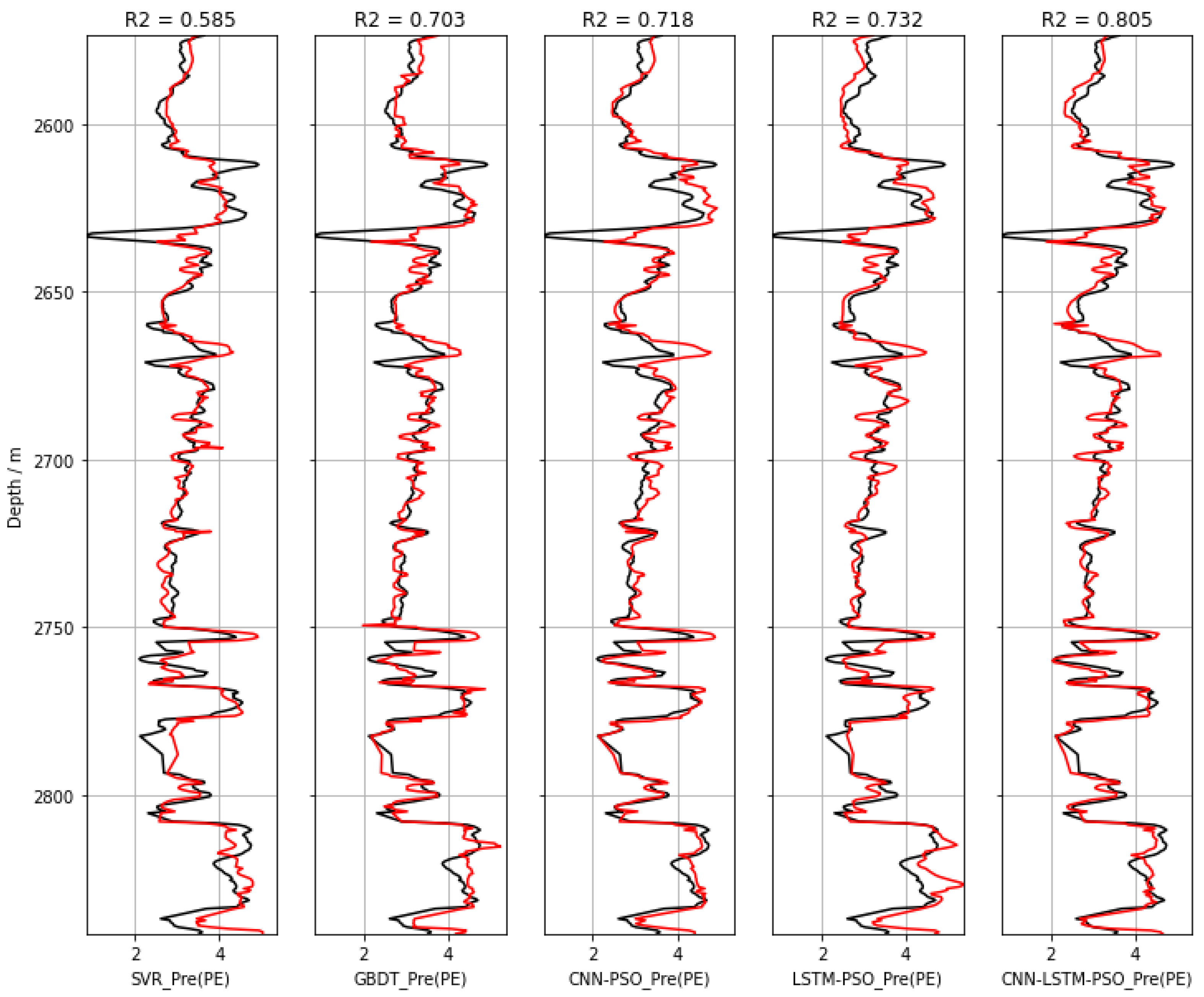
Figure 15 shows the photoelectric effect curves of
Well 1 predicted from multiple adjacent wells by the SVR, GBDT, CNN-PSO, LSTM-PSO, and CNN-LSTM-PSO models. In the figure, black is the actual measured photoelectric effect curve of
Well 1 in the oilfield, and red is the prediction result of
Well 1. Compared with the actual measured photoelectric effect data, the prediction results of each model had a high degree of fit, indicating that deep learning can accurately predict the trend of the target photoelectric effect curve (
Well 1) using the adjacent well information. Combining the CNN, LSTM, and PSO algorithms improves the accuracy of logging prediction, and is more suitable for predicting the target logging curve (
Table 5). Therefore, the CNN-LSTM-PSO model also works well in predicting well-logging curve sequences from multiple adjacent wells, but the accuracy is not good enough for comparing with those derived from the other logging data of the target well itself, probably because the correlation between well-logging data from different adjacent wells is not as good as the correlation with the logging data from the well itself. The
R2 value of 0.805 in the test data suggests that there is space to improve the architecture. More experiments with the network might yield better results. The study proved that for a newly drilled well, the trained CNN-LSTM-PSO model can also generate a logging curve with the well-logging data of neighboring wells surrounding the new well, but the accuracy needs to be further improved by accounting for geological complexity.
5. Discussion and Future Work
It should be noted that there are still three main problems with AI in well-logging curve prediction applications: (1) the limited number of samples does not accurately and comprehensively reflect the actual geological conditions; (2) the discussion focuses on the AI level, often ignoring the preprocessing of well-logging data, such as missing value processing, outlier correction, and standardization; and (3) there is poor robustness, which does not permit learning methods such as deep reinforcement and adaptive neural network tuning. It does not allow the machine to gradually improve its analysis and adaptation capabilities in the process of building the database. Researchers should take into account the economic applicability and scalability as much as possible while designing the implementation method.
A limitation of the proposed hybrid model was that the accuracy of the logs predicted using the logging data of adjacent wells was not high enough. In the future, we will investigate the inability of the prediction model to efficiently generate missing well-logging curves for any region of interest by considering geological complexity. In order to better conduct this work, it is necessary to deeply integrate neural networks with specific application scenarios [
37]. It is not simple to apply machine learning algorithms directly to the logging curve problem, but a more organic and in-depth combination needs to be considered. On the one hand, domain knowledge can be introduced into the machine-learning model by adding physical constraints, for example. On the other hand, it is also possible to improve machine learning models by borrowing features from algorithms used in engineering. Because there are many problems that are not prominent in the computer domain but that need to be faced in engineering practice (e.g., the problem of small samples due to training data not being easily available), there exist instead some algorithms in the engineering domain that specifically deal with such problems that are not available in machine learning. By applying such algorithms to machine learning, there is potential to improve machine-learning models and make them easier to apply to practical engineering domains.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}