
Revisiting Adaptive Frequency Hopping Map Prediction in Bluetooth with Machine Learning Classifiers



Abstract
:1. Introduction
- Since [8] evaluates the above classifiers as a module of the whole sniffing system, only per-channel classification results are available. However, since AFH sequence relies on the resulting AFH map, per-channel classification results is not sufficient to evaluate contribution of the classifier in packet sniffing.
- Although SVM is known as powerful on a wide range of problems, there are broad categories of machine learning classifiers. We could understand the AFH map prediction problem more comprehensively by comparing results from multiple machine learning classifiers.
2. Related Work
3. Backgrounds
3.1. An Overview of Bluetooth and AFH
3.2. Machine Learning Classifiers
3.2.1. Logistic Regression
3.2.2. Decision Tree
3.2.3. Random Forest
3.2.4. Support Vector Machine
3.2.5. Multi-Layer Perceptron
4. Experiment
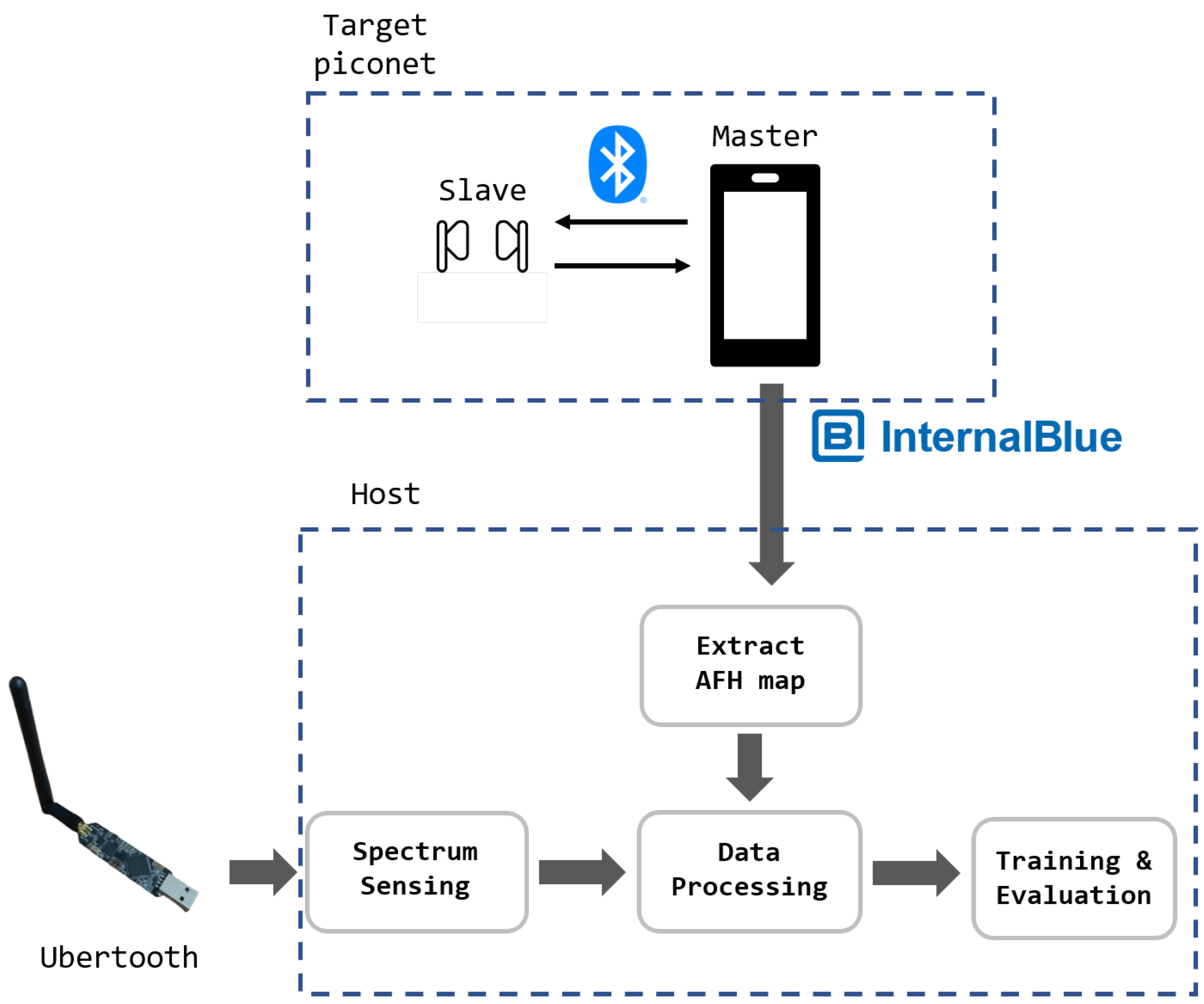
4.1. AFH Map Collection and Prediction Testbed
4.2. Spectrum Sensing
4.3. Data Processing and the Resulting Dataset
4.4. Training and Evaluation
5. Evaluation Results
5.1. Per-Channel Classification
5.2. AFH Map Prediction
5.3. Discussion
5.4. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bluetooth SIG. Bluetooth Market Update 2020; Technical Report; Bluetooth SIG: Washington, DC, USA, 2020. [Google Scholar]
- Jakobsson, M.; Wetzel, S. Security Weaknesses in Bluetooth. In Proceedings of the Cryptographers’ Track at the RSA Conference 2001 (CT-RSA 2001), San Francisco, CA, USA, 8–12 April 2001; pp. 176–191. [Google Scholar]
- Dunning, J. Taming the Blue Beast: A Survey of Bluetooth Based Threats. IEEE Secur. Priv. 2010, 8, 20–27. [Google Scholar] [CrossRef]
- Lonzetta, A.; Cope, P.; Campbell, J.; Mohd, B.; Hayajneh, T. Security Vulnerabilities in Bluetooth Technology as Used in IoT. J. Sens. Actuator Netw. 2018, 7, 28. [Google Scholar] [CrossRef] [Green Version]
- Rohde & Schwartz. Bluetooth Adaptive Frequency Hopping on a R&S CMW; Technical Report 1C108; Rohde & Schwartz: Muenchen, Germany, 2011. [Google Scholar]
- Cominelli, M.; Gringoli, F.; Patras, P.; Lind, M.; Noubir, G. Even Black Cats Cannot Stay Hidden in the Dark: Full-band De-anonymization of Bluetooth Classic Devices. In Proceedings of the 41st IEEE Symposium on Security & Privacy (S&P 2020), San Francisco, CA, USA, 18–20 May 2020; pp. 534–548. [Google Scholar] [CrossRef]
- Spill, D.; Bittau, A. BlueSniff: Eve Meets Alice and Bluetooth. In Proceedings of the 1st USENIX Workshop on Offensive Technologies (WOOT’07), Boston, MA, USA, 6–10 August 2007. [Google Scholar]
- Albazrqaoe, W.; Huang, J.; Xing, G. Practical Bluetooth Traffic Sniffing: Systems and Privacy Implications. In Proceedings of the 14th Annual International Conference on Mobile Systems, Applications, and Services (MobiSys’16), Singapore, 26 May 2016; pp. 333–345. [Google Scholar] [CrossRef]
- Lowe, I.; Buchanan, W.J.; Macfarlane, R.; Lo, O. Wi-Fi Channel Saturation as a Mechanism to Improve Passive Capture of Bluetooth Through Channel Usage Restriction. J. Netw. Technol. 2020, 10, 124–155. [Google Scholar]
- Ossmann, M.; Spill, D. Project Ubertooth: Open Source Wireless Development Platform Suitable for Bluetooth Experimentation. 2011. Available online: http://ubertooth.sourceforge.net/ (accessed on 9 February 2021).
- Lee, J.; Park, C.; Roh, H. Revisiting Bluetooth Adaptive Frequency Hopping Prediction with a Ubertooth. In Proceedings of the 35th International Conference on Information Networking (ICOIN 2021), Jeju Island, Korea, 13–16 January 2021. [Google Scholar]
- Cominelli, M.; Patras, P.; Gringoli, F. One GPU to Snoop Them All: A Full-Band Bluetooth Low Energy Sniffer. In Proceedings of the 2020 Mediterranean Communication and Computer Networking Conference (MedComNet’20), Arona, Italy, 17–19 June 2020; pp. 5–8. [Google Scholar] [CrossRef]
- Ryan, M. Bluetooth: With low energy comes low security. In Proceedings of the 7th USENIX Workshop on Offensive Technologies (WOOT’13), Washington, DC, USA, 13 August 2013. [Google Scholar]
- Huang, J.; Albazrqaoe, W.; Xing, G. BlueID: A practical system for Bluetooth device identification. In Proceedings of the 33rd Annual IEEE International Conference on Computer Communications (INFOCOM’14), Toronto, ON, Canada, 27 April–2 May 2014; pp. 2849–2857. [Google Scholar] [CrossRef]
- Das, A.K.; Pathak, P.H.; Chuah, C.N.; Mohapatra, P. Uncovering privacy leakage in BLE network traffic of wearable fitness trackers. In Proceedings of the 17th International Workshop on Mobile Computing Systems and Applications (HotMobile’16), St. Augustine, FL, USA, 23–24 February 2016; pp. 99–104. [Google Scholar] [CrossRef]
- Chernyshev, M.; Valli, C.; Johnstone, M. Revisiting Urban War Nibbling: Mobile Passive Discovery of Classic Bluetooth Devices Using Ubertooth One. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1625–1636. [Google Scholar] [CrossRef]
- Mantz, D.; Classen, J.; Schulz, M.; Hollick, M. InternalBlue—Bluetooth Binary Patching and Experimentation Framework. In Proceedings of the 17th Annual International Conference on Mobile Systems, Applications, and Services (MobiSys’19), Seoul, Korea, 17–21 June 2019; pp. 79–90. [Google Scholar] [CrossRef] [Green Version]
- Shoemake, M.B. White Paper: Wi-Fi (IEEE 802.11b) and Bluetooth: Coexistence Issues and Solutions for the 2.4 GHz ISM Band; Technical Report; Texas Instruments: Dallas, TX, USA, 2001. [Google Scholar]
- Ophir, L.; Bitran, Y.; Sherman, I. Wi-Fi (IEEE 802.11) and Bluetooth Coexistence: Issues and Solutions. In Proceedings of the 2004 IEEE International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC’04), Barcelona, Spain, 5–8 September 2004; pp. 847–852. [Google Scholar] [CrossRef]
- Song, M.; Shetty, S.; Gopalpet, D. Coexistence of IEEE 802.11b and Bluetooth: An Integrated Performance Analysis. Mob. Netw. Appl. 2007, 12, 450–459. [Google Scholar] [CrossRef]
- Rayanchu, S.; Patro, A.; Banerjee, S. Airshark: Detecting non-WiFi RF devices using commodity WiFi hardware. In Proceedings of the 11th ACM SIGCOMM Internet Measurement Conference (IMC’11), Berlin, Germany, 2–4 November 2011; pp. 137–153. [Google Scholar] [CrossRef]
- Liu, W.; Kulin, M.; Kazaz, T.; Shahid, A.; Moerman, I.; Poorter, E.D. Wireless Technology Recognition Based on RSSI Distribution at Sub-Nyquist Sampling Rate for Constrained Devices. Sensors 2017, 17, 2081. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shao, C.; Roh, H.; Lee, W. BuSAR: Bluetooth Slot Availability Randomization for Better Coexistence with Dense Wi-Fi Networks. IEEE Trans. Mob. Comput. 2019. [Google Scholar] [CrossRef]
- Gomez, C.; Oller, J.; Paradells, J. Overview and Evaluation of Bluetooth Low Energy: An Emerging Low-Power Wireless Technology. Sensors 2012, 12, 11734–11753. [Google Scholar] [CrossRef]
- Sarkar, S.; Liu, J.; Jovanov, E. A Robust Algorithm for Sniffing BLE Long-Lived Connections in Real-Time. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM 2019), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Classification and Regression Trees; Chapman & Hall, CRC Press: Boca Raton, FL, USA, 1984; pp. 1–358. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # of 0 | # of 1 | Total | # of AFH Map | # of 0 | # of 1 | Total | # of AFH Map | ||
|---|---|---|---|---|---|---|---|---|---|
| A | 16,743 | 83,824 | 100,567 | 1273 | Training set | 17,797 | 89,011 | 105,808 | 1352 |
| B | 1054 | 5187 | 6241 | 79 | |||||
| C | 4572 | 16,363 | 20,935 | 265 | Test set | 4572 | 16,363 | 20,935 | 265 |
| Actual Class | ||||
|---|---|---|---|---|
| P | N | Sum | ||
| Predicted class | P | 16,143 | 3840 | 19,983 |
| N | 220 | 732 | 952 | |
| sum | 16,363 | 4572 | 20,935 | |
| Actual Class | ||||
|---|---|---|---|---|
| P | N | Sum | ||
| Predicted class | P | 16,363 | 4572 | 20,935 |
| N | 0 | 0 | 0 | |
| sum | 16,363 | 4572 | 20,935 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Park, C.; Roh, H. Revisiting Adaptive Frequency Hopping Map Prediction in Bluetooth with Machine Learning Classifiers. Energies 2021, 14, 928. https://doi.org/10.3390/en14040928
Lee J, Park C, Roh H. Revisiting Adaptive Frequency Hopping Map Prediction in Bluetooth with Machine Learning Classifiers. Energies. 2021; 14(4):928. https://doi.org/10.3390/en14040928
Chicago/Turabian StyleLee, Janggoon, Chanhee Park, and Heejun Roh. 2021. "Revisiting Adaptive Frequency Hopping Map Prediction in Bluetooth with Machine Learning Classifiers" Energies 14, no. 4: 928. https://doi.org/10.3390/en14040928
APA StyleLee, J., Park, C., & Roh, H. (2021). Revisiting Adaptive Frequency Hopping Map Prediction in Bluetooth with Machine Learning Classifiers. Energies, 14(4), 928. https://doi.org/10.3390/en14040928