1. Introduction
Industry 4.0 is generally taken as the alternative of the fourth industrial revolution and is defined as smart networking of machines and industrial operations. The Internet of Things, Big Data, sensors, artificial intelligence (AI) and augmented reality, etc., are the key technologies of Industry 4.0 [
1] and are deployed to develop smart and connected production systems. Energy efficiency is the key element of Industry 4.0, and digital energy transformation goals promise energy savings and process optimization of the power systems. In this regard, the data-driven optimum control strategies and construction of custom-built performance profiles of industrial machinery are the promising paradigm shift for achieving operational excellence and energy efficiency for the energy systems [
2,
3,
4].
Mathematical models are constructed based on the simplified assumptions and the governing laws’ limitations [
5]. Constructing an analytical model for complex and large-scale systems is difficult as it requires deriving the mathematical equations for a large number of systems’ components. Moreover, these modeling techniques cannot effectively mine the complex interactions and nonlinear interdependencies present among a physical system’s large number of control variables. As a result, the mathematical models express only a certain degree of agreement with the system’s actual response and cannot be deployed to develop the complex industrial systems’ accurate performance curves. On top of this, these models’ shortcomings in terms of including valuable operation data for deriving the optimum control strategies have further limited their usage in real-world industrial applications [
5,
6,
7,
8,
9,
10,
11].
On the other hand, the real operational data, having the featured information and operational details of industrial systems, can be used to construct the effective data-driven models and performance curves of industrial equipment by the advanced AI techniques. Unlike mathematical modeling which requires detailed process analyses, a few systems’ representative operation parameters are needed to construct the AI models [
5,
11]. The AI models present excellent predictability and are also deployed as the operation excellence tools for industrial operations [
3,
10]. In this regard, the AI techniques, including artificial neural networks (ANNs) and automated machine learning (AutoML) platforms, are well suited for improving the process operation management, material, energy savings, failure diagnosis, and, ultimately, the efficient industrial practices [
12,
13,
14].
Use of an ANN is a proven data analytic technique widely used for its well established ability and efficacy to formulate data-driven characteristics, operating strategies, and planning [
15]. ANNs utilize large-scale data for their construction with higher computational performances and small memory storage [
15,
16]. ANNs’ remarkable features make them suitable for industrial operations to be effectively stimulated for enhancing the energy-efficient process control of industries. [
2,
3,
7,
15,
17,
18]. Recently, AutoML techniques have been popular in various applications, as they help develop high-quality AI models. Several machine learning-based models are trained from the toolbox, and the model’s performance is compared. The best performing model is retained and deployed for real-life applications.
In recent times, the status of AI applications in various industrial sectors has been reported. It is found that the current scientific focus on deploying AI for modeling and optimization purposes covers manufacturing and petrochemical industries [
19,
20]. The other studies focusing on the inclusion of Industry 4.0 technologies in industrial systems have identified the data enabling aspect of Industry 4.0. The value-creating and Industry 4.0-driven data analytics centered on the performance enhancement and efficiency improvement of complex industrial systems are scarcely reported [
21,
22]. However, potential applications of AI are anticipated for energy and electrical power systems’ optimization, management, and control [
21,
23].
Recently, AI techniques have been deployed to accurately capture the characteristic responses of many components of a supercritical steam power plant and combine cycle power plants, including the flue gas network, water and steam network, and turbine units [
24,
25,
26]. Industry 4.0 data analytics-driven parametric responses on the key performance indicators have been plotted for a 660 MW power plant in other studies. The useful operating regions of critically controlled parameters have been identified. Moreover, the savings in energy spent are achieved without compromising the power plant operation [
2,
3].
Similarly, various studies have attempted to construct the data-driven power curve of power systems. A power curve of offshore wind turbines has been made by utilizing the synthetic data reported in the literature. However, a further improvement in the performance curve is suggested by including many system’ operational parameters [
27]. The other studies have reported a better version of data-driven power curves developed for wind turbines. Power curves are constructed by fueling the large volume of operational data of wind turbines and, after that, using them for monitoring, fault detection, and conditional monitoring purposes [
28,
29]. Likewise, the data-driven performance curves of a hydroelectric power plant are utilized to improve the power facility [
30]. However, the generator’s operation data-based performance curve incorporating sizeable operational data and an appropriate number of operating parameters of the power facility are not reported in the literature.
In this paper, the operation data-driven power curve of the generator installed at a 660 MW supercritical coal power plant is constructed. The modeling tools of AI such as ANN and AutoML are deployed for the task. Active loads of 330 and 660 MW are the two extremes of the power plant’s active load, whereas the power factor is kept from 0.85 to 1.0 (lagging phase) and 0.95 to 1.0 (leading phase). Under these operating states, the generator’s power, which is the vectorial sum of resistive power and reactive power, is changed from 355 to 715 MVA. The operational data containing almost all the power plant’s operating states is retrieved from the power plant’s Supervisory Information System (SIS). Practical ANN and AutoML approaches are employed for a principal objective—i.e., to construct the operation data-based power curve of the generator power with a 95% confidence interval. The construction of a data-driven power curve against the power plant’s operating parameters’ influence is the main novelty reported in this paper. The performance profiles of equipment or systems constructed by AI modeling tools can be potentially valuable for developing the custom-built optimum operational control strategies for the industrial systems. In contrast with analytical solutions, the data-driven control strategies governed by the operational constraints of complex processes can effectively help achieve higher energy efficiency and the industrial systems’ energy economy. Therefore, it would realize Industry 4.0 ideas in industrial applications and contribute to the United Nations Sustainable Development Goals 2030.
The next section describes the applied materials and methods; particularly, it presents an overview of a pulverized coal plant operation and the generator. Moreover, the methodology applied within the carried out research is described. The third section concerns data acquisition and processing as well as visualization. The construction of AI models and validation are presented in
Section 4. This section is divided into two subsections concerning the development of ANN and AutoML models. The results and discussion section presents the selection of the best AI model and construction of the power curve of the generator. Finally, the conclusions are discussed in the last section.
2. Materials and Methods
The applied materials and methods, particularly an overview of a pulverized coal plant operation, the generator as well as the methodology used within the confines of the carried out research, are described in this section.
2.1. Overview of a Pulverized Coal Power Plant Operation and the Generator
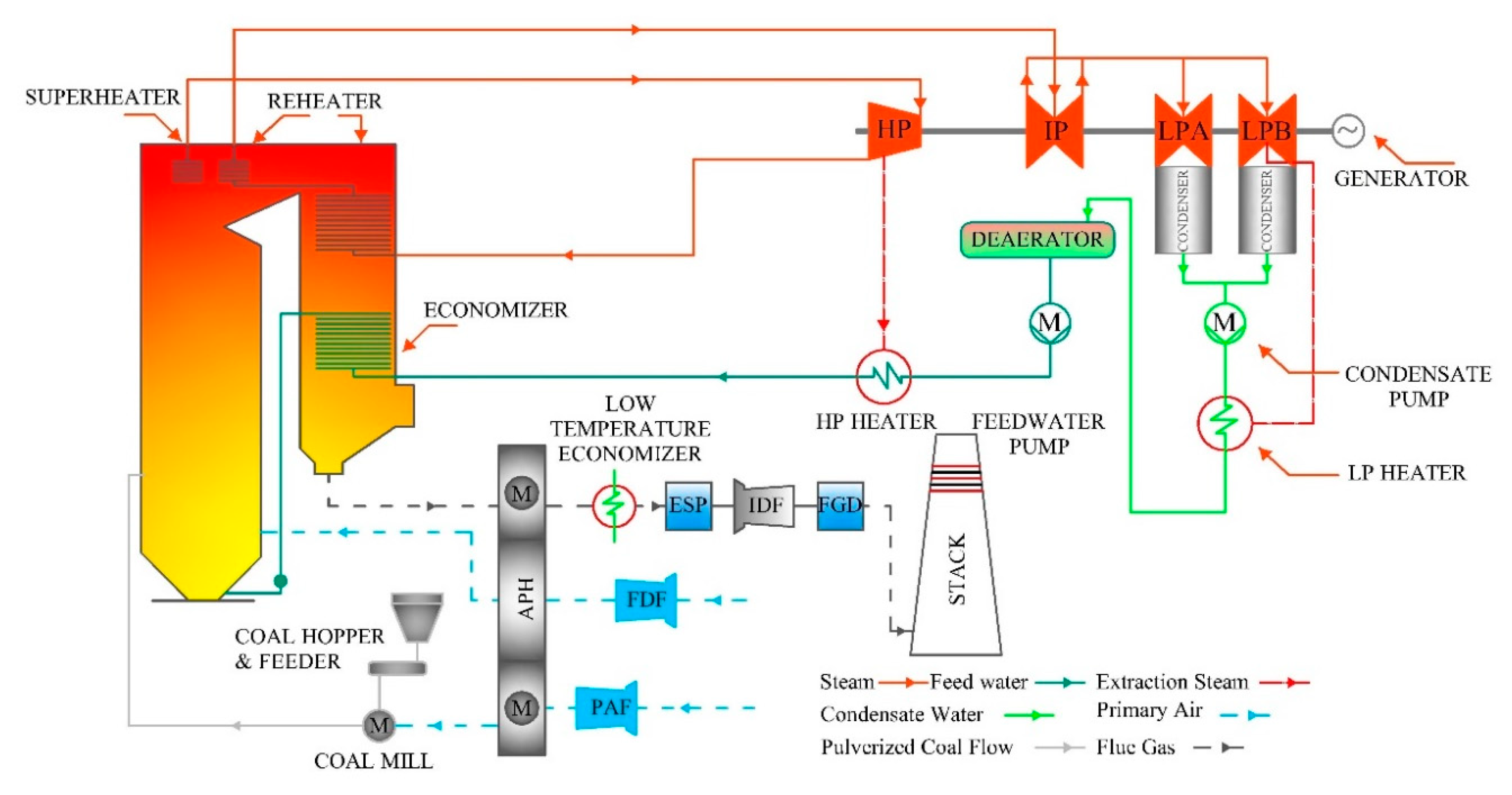
The schematic flow diagram of a pulverized coal-fired power plant is presented in
Figure 1. The power plant’s operation can be explained in two cycles—i.e., air–flue gas cycle and steam and the water cycle.
In the first cycle, primary air from the primary air fan (PAF) is supplied to the air preheater (APH) and is heated by the flue gas exiting the boiler. From the APH, primary air is supplied to the coal mill for transporting the pulverized coal to the boiler furnace. Similarly, secondary air from the forced draft fan (FDF) is heated in APH and supplied to the furnace to assist coal combustion. Moreover, secondary air is supplied in multiple boiler stages to decrease NOx formation in the combustion zone. The flue gas produced from fuel combustion exchanges heat to the heating surfaces. Upon leaving from the boiler’s tail, flue gas transmits the heat to a low-temperature economizer (LT Economizer). Then, flue gas is fed into an electrostatic precipitator (ESP) for the removal of ash carried by it. An induced draft fan (IDF) essentially maintains negative pressure in the boiler. Additionally, IDF directs the flue gas to the flue gas desulfurization (FGD) system, where oxides of Sulphur (SOx) and other harmful gases are removed. Finally, flue gas is discharged to the ambient environment from the stack.
In the second cycle, condensate water from the condenser is pressurized by a condensate pump, and it is passed through a low-pressure heater (LP Heater). Condensate water in the LP heater is heated by steam extraction from the intermediate-pressure (IP) turbine and enters the deaerator to remove dissolved gases present in it. Feedwater is pressurized by the feedwater pump and is passed through the high-pressure heater (HP Heater), economizer and superheater. Upon leaving the superheater, it is converted to superheated steam. The superheated steam expands in high-pressure (HP) steam turbine and after leaving HP turbine, is reheated in a re-heater and fed to the IP turbine. After expanding in the IP turbine, steam is further expanded in low-pressure (LP) turbines LPA and LPB, and enters the condenser where it is condensed to condensate water, and the cycle continues. The steam expansion in the turbine series helps rotate the generator shaft, and, thus, electrical power is produced.
QFSN-660-2 water-hydrogen–hydrogen steam turbine synchronous generator of 660 MW capacity is manufactured by Shanghai Electric Group Co., Ltd., for which the rated voltage is 22 kV. SIEMENS SPPA E3000-SES530 self-shunt static excitation system is integrated with the generator. Rated parameters for excitation voltage and excitation current are 491 V and 4669 A, whereas no-load excitation system parameters are 150 V and 1497 A, respectively. Here in this study, the power produced by the generator was added to the 500 kV national grid of Pakistan.
2.2. Methodology
In this paper, the framework developed for constructing the generator’s data-driven power curve is presented in
Figure 2. In the first step, the essential operating parameters associated with the power generation operation of the power plant are selected. Then, the operational data of the selected parameters is retrieved from the data storage system. In the next step, extensive data processing and visualization techniques are incorporated into prepare the filtered dataset out of the extracted raw operational data. The two steps for data acquisition, data processing, and visualization are comprehensively explained in
Section 3. Later, various AI models are constructed on the filtered data and validated as described in
Section 4. As a result, the best AI model is selected as explained in
Section 5.1 and thus would be deployed for constructing the power curve of the generator, as described in
Section 5.2.
3. Data Acquisition, Data Processing, and Visualization
In this work, twenty-four operating parameters were selected to model the generator power and, consequently, construct the power curve of the generator installed at the power plant. All of the parameters were critically controlled to ensure smooth power production and were decided after discussion with experienced operation managers of the power plant and the literature survey [
2,
5,
11,
31,
32]. The parameters enlist the boiler, turbine, and generator operational parameters and are named as thermo-electric operating parameters in this study. It is essential to mention here that sub-bituminous coal is used at the power plant, and the average values of different coal properties measured on the air-dried basis are listed in
Table 1.
State of the art and reliable sensors were installed for measuring the values of different operation parameters of the power plant. A distributed control system driven through these sensors was employed for the control of the processes and subsystems integrated with the power generation operation of the power plant. The data generated by these sensors were stored in a centralized data storage system of SIS. TPRI SIS software version 3.7.5. was used for the implementation of SIS at the power plant. It provides easy access and retrieval of the historical operation data of the operating parameters of the power plant. Approximately 2560 hourly averaged observations of thermo-electric operating parameters were retrieved from the SIS. Different power generation modes’ operational data of the power plant were taken in the dataset. The data were subjected to removal of outliers and recorded faulty observations of sensors before being fed for model development. Moreover, the operating parameters’ effective operating ranges were established, which would otherwise be inappropriate, and the models constructed on those ranges would be inefficient [
5,
11].
In this study, data were initially visualized in the form of line graphs, scatterplots, and histograms, and the identified faulty observations were eliminated from the dataset. Here, the data cleaning of a few operating parameters is presented in
Figure 3a–c. The fluctuating and faulty observations of LT Eco water outlet temperature (LT.ECO) caused by the sensor’s fault are represented in
Figure 3a. The faulty observations of LT.ECO have an operating range from 3 °C to 2024 °C, which is quite inappropriate and thus were eliminated from the dataset. Similarly, the outliers present in the observations of attemperation water flow rate and the fixed values of ambient temperature measured due to the sensor’s fault are represented in
Figure 3b,c. The faulty observations in the two operating parameters were thus eliminated. The same practice was repeated on the remaining thermo-electric operating parameters, and the data were further filtered to eliminate the inconsistent and inappropriate observations. Resultantly, the dataset was reduced to around 1900 observations after the data processing procedure and was therefore utilized for the model development, as discussed in the next section.
Finally, the list of the thermo-electric operating parameters (1st–24th) and generator power (25th) with their operating ranges is given in
Table 2. The operating ranges of the thermo-electric operating parameters were established after the extensive data processing techniques and are comparable to those reported in literature studies [
3,
33]. Moreover, the histograms of two important operating parameters, i.e., the main steam temperature and excitation current, are shown in
Figure 4a,b, respectively.
The two histograms present the wide distribution of data across the operating parameters, which is essentially required to construct a robust and flexible model representing the complex process of a physical system. Therefore, data processing and visualization are crucial for selecting the appropriate dataset of the operating parameters. They provide a strong foundation for carrying out data-driven modeling and optimization analytics, thereby enabling the developing of effective operational control strategies for real-life industrial systems [
5,
11].
6. Conclusions
The power curves constructed by the mathematical modeling techniques are limited in their applications to complex and large-scale industrial systems. In this work, two data-driven modeling techniques of AIs, i.e., ANN and AutoML, were utilized to construct a generator power curve against the influence of twenty-four thermo-electric operating parameters of a 660 MW supercritical coal power plant.
Comprehensive operational data of the power plant containing all possible operating modes of the generator power was taken from the SIS. Comprehensive data processing and visualization techniques were used to eliminate the faulty observations present in the raw data. Thus, the filtered data were fueled to construct the ANN and AutoML models for the power plant’s generator power. However, in the external validation test, ANN outperformed the AutoML-based SVM model and therefore ANN was selected. Monte Carlo experiments comprising the power plant’s thermo-electric operating parameters and the Gaussian noise were made to be simulated from ANNs and deployed to construct the power curve of the generator with a 95% confidence interval.
The presented Industry 4.0 data analytics can be treated as a complementary approach in the data-driven construction of power curves for industrial systems and machinery and constitute the main novelty of the paper. The characteristic responses reflected in the custom-built performance curves can be used to formulate effective operational control strategies for the large-scale and complex industrial systems. However, it is important to mention here that the quality of the data, operating ranges of control parameters, and the specific operational constraints of real-life industrial systems need to be considered carefully to construct true and effective data-driven performance curves. Thus, the performance curves could be confidently implemented at the component level, system level, and strategic level of the industrial systems and thereby would contribute to energy efficiency, operation excellence, and the Industry 4.0 vision for industries.
The applicability levels of the developed ANN and AutoML models are very high mostly due to their novelty and that they can be generalized to other branches of industry.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}