
Managing Uncertainty in Geological CO2 Storage Using Bayesian Evidential Learning


Abstract
:1. Introduction
2. Methods: Uncertainty Quantification Framework
2.1. Prior Model Definition
2.2. Prior Model Falsification
2.3. Direct Forecasting
2.4. Direct Forecasting-ES-MDA (DF-ES-MDA)
2.5. Direct Forecasting on a Sequential Model Decomposition (DF-SMD)
2.6. Uncertainty Reduction Analysis
3. Materials
3.1. Model Description
3.2. The General Setup
4. Results and Analysis
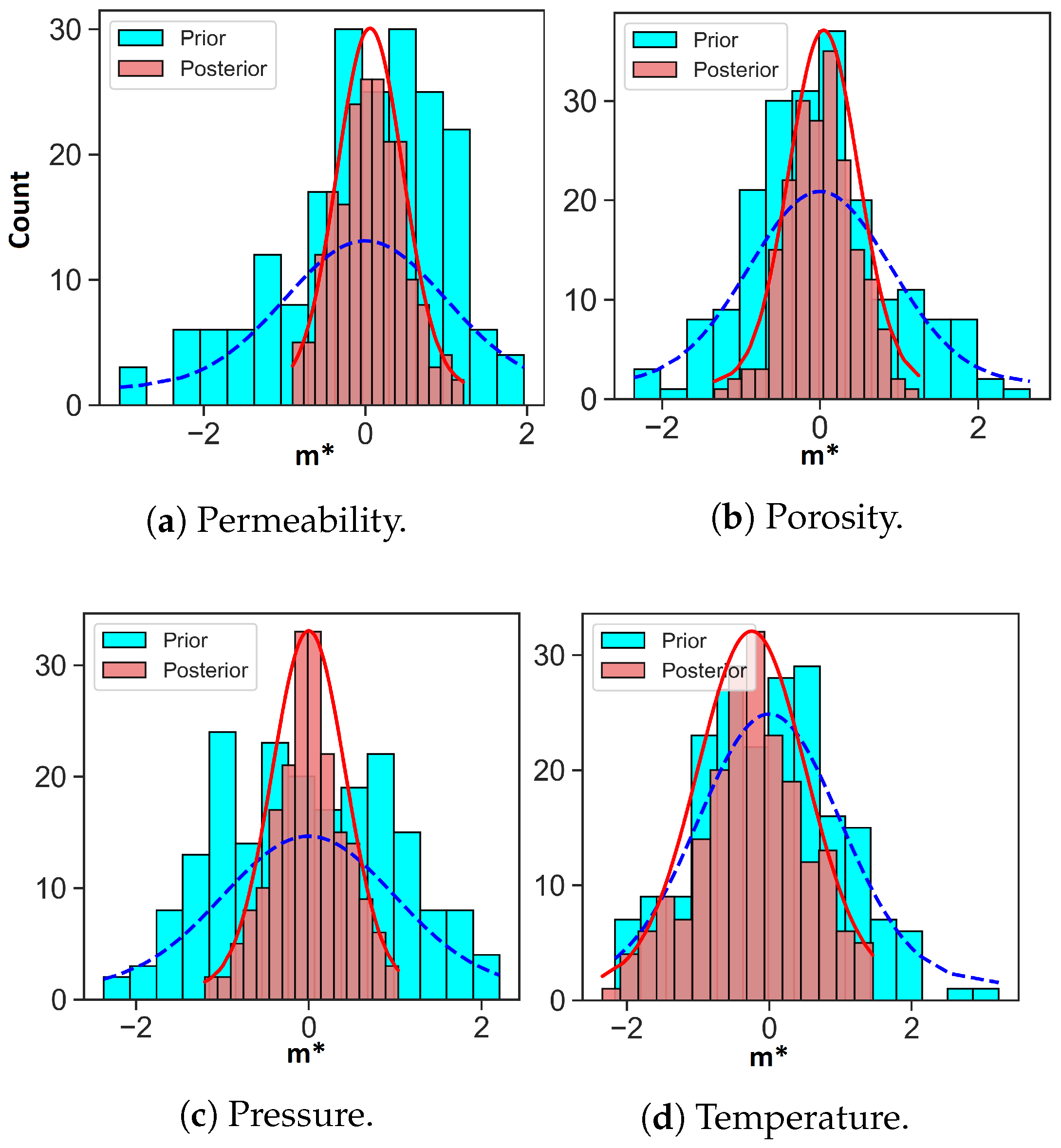
4.1. Scenario 1: Uncertainty Reduction Using Direct Forecasting
4.2. Scenario 2: Uncertainty Reduction Using Direct Forecasting on a Sequential Model Decomposition
5. Discussion and Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Harp, D.R.; Stauffer, P.H.; O’Malley, D.; Jiao, Z.; Egenolf, E.P.; Miller, T.A.; Martinez, D.; Hunter, K.A.; Middleton, R.; Bielicki, J. Development of robust pressure management strategies for geologic CO2 sequestration. Int. J. Greenh. Gas Control 2017, 64, 43–59. [Google Scholar] [CrossRef]
- Jin, L.; Hawthorne, S.; Sorensen, J.; Pekot, L.; Kurz, B.; Smith, S.; Heebink, L.; Hergegen, V.; Bosshart, N.; Torres, J.; et al. Advancing CO2 enhanced oil recovery and storage in unconventional oil play—Experimental studies on Bakken shales. Appl. Energy 2017, 208, 171–183. [Google Scholar] [CrossRef]
- Nilsen, H.M.; Lie, K.A.; Andersen, O. Analysis of CO2 trapping capacities and long-term migration for geological formations in the Norwegian North Sea using MRST-co2lab. Comput. Geosci. 2015, 79, 15–26. [Google Scholar] [CrossRef] [Green Version]
- IPCC. Climate Change 2014: Synthesis Report. Contribution of Working Groups I, II and III to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change; IPCC: Geneva, Switzerland, 2014; p. 151. [Google Scholar]
- Hosa, A.; Esentia, M.; Stewart, J.; Haszeldine, H. Injection of CO2 into saline formations: Benchmarking worldwide projects. Chem. Eng. Res. Des. 2011, 89, 1855–1864. [Google Scholar] [CrossRef]
- Michael, K.; Golab, A.; Shulakova, V.; Ennis-King, J.; Allinson, G.; Sharma, S.; Aiken, T. Geological storage of CO2 in saline aquifers—A review of the experience from existing storage operations. Int. J. Greenh. Gas Control 2017, 4, 659–667. [Google Scholar] [CrossRef]
- Institute for Global Change. Global Status of CCS: 2018; Institute for Global Change: London, UK, 2018. [Google Scholar]
- Jordan, K.; Gary, T.; Jeffrey, P.; Hans, T.; Haroon, K.; Yen-Heng, H.C.; Sergey, P.; Howard, H. Developing a Consistent Database for Regional Geologic CO2 Storage Capacity Worldwide. Energy Procedia 2017, 114, 4697–4709. [Google Scholar]
- Allen, R.; Nilsen, H.; Lie, K.A.; O, M.; Andersen, O. Using simplified methods to explore the impact of parameter uncertainty on CO2 storage estimates with application to the Norwegian Continental Shelf. Int. J. Greenh. Gas Control 2018, 75, 198–213. [Google Scholar] [CrossRef]
- Dai, C.; Li, H.; Zhang, D.; Xue, L. Efficient data-worth analysis for the selection of surveillance operation in a geologic CO2 sequestration system. Greenh. Gases Sci. Technol. 2015, 5, 513–529. [Google Scholar] [CrossRef]
- Oladyshkin, S.; Class, H.; Nowak, W. Bayesian updating via bootstrap filtering combined with data-driven polynomial chaos expansions: Methodology and application to history matching for carbon dioxide storage in geological formations. Comput. Geosci. 2013, 17, 671–687. [Google Scholar] [CrossRef]
- Sun, A.Y.; Nicot, J. Inversion of pressure anomaly data for detecting leakage at geologic carbon sequestration sites. Adv. Water Resour. 2012, 44, 20–29. [Google Scholar] [CrossRef]
- Sun, A.Y.; Zeidouni, M.; Nicot, J.; Lu, Z.; Zhang, D. Assessing leakage detectability at geologic CO2 sequestration sites using the probabilistic collocation method. Adv. Water Resour. 2013, 56, 49–60. [Google Scholar] [CrossRef]
- Chen, B.; Harp, D.R.; Lin, Y.; Keating, E.H.; Pawar, R.J. Geologic CO2 sequestration monitoring design: A machine learning and uncertainty quantification based approach. Appl. Energy 2018, 225, 332–345. [Google Scholar] [CrossRef]
- Chen, B.; Harp, D.R.; Lin, Y.; Lu, Z.; Pawar, R.J. Reducing uncertainty in geologic CO2 sequestration risk assessment by assimilating monitoring data. Int. J. Greenh. Gas Control 2020, 94, 102926. [Google Scholar] [CrossRef]
- González-Nicolás, A.; Baù, D.; Alzraiee, A. Detection of potential leakage pathways from geological carbon storage by fluid pressure data assimilation. Adv. Water Resour. 2015, 86, 366–384. [Google Scholar] [CrossRef] [Green Version]
- Cameron, D.A.; Durlofsky, L.J.; Benson, S.M. Use of above-zone pressure data to locate and quantify leaks during carbon storage operations. Int. J. Greenh. Gas Control 2016, 52, 32–43. [Google Scholar] [CrossRef]
- Oliver, D.S.; Chen, Y. Recent progress on reservoir history matching: A review. Comput. Geosci. 2011, 15, 185–221. [Google Scholar] [CrossRef]
- Scheidt, C.; Li, L.; Caers, J. Quantifying Uncertainty in Subsurface Systems, 1st ed.; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Scheidt, C.; Renard, P.; Caers, J. Prediction-focused subsurface modeling: Investigating the need for accuracy in flow-based inverse modeling. Math. Geosci. 2015, 47, 173–191. [Google Scholar] [CrossRef] [Green Version]
- Satija, A.; Caers, J. Direct forecasting of subsurface flow response from non-linear dynamic data by linear least-squares in canonical functional principal component space. Adv. Water Resour. 2015, 77, 69–81. [Google Scholar] [CrossRef]
- Yin, Z.; Strebelle, S.; Caers, J. Automated Monte Carlo-based Quantification and Updating of Geological Uncertainty with Borehole Data (AutoBEL v1.0). Geosci. Model. Dev. 2019, 13, 651–672. [Google Scholar] [CrossRef] [Green Version]
- Satija, A.; Scheidt, C.; Li, L.; Caers, J. Direct forecasting of reservoir performance using production data without history matching. Comput. Geosci. 2017, 21, 315–333. [Google Scholar] [CrossRef]
- Athens, N.D.; Caers, J. A Monte Carlo-based framework for assessing the value of information and development risk in geothermal exploration. Appl. Energy 2019, 256, 113932. [Google Scholar] [CrossRef]
- Hermans, T.; Lesparre, N.; De Schepper, G.; Robert, T. Bayesian evidential learning: A field validation using push-pull tests. Hydrogeol. J. 2019, 27, 1661–1672. [Google Scholar] [CrossRef] [Green Version]
- Sun, W.; Durlofsky, L.J. Data-space approaches for uncertainty quantification of CO2 plume location in geological carbon storage. Adv. Water Resour. 2019, 123, 234–255. [Google Scholar] [CrossRef]
- Emerick, A.A.; Reynolds, A.C. Ensemble smoother with multiple data assimilation. Comput. Geosci. 2016, 55, 3–15. [Google Scholar] [CrossRef]
- De Maesschalck, R.; Jouan-Rimbaud, D.; Massart, D.L. The Mahalanobis distance. Chemom. Intell. Lab. Syst. 2000, 50, 1–18. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying Density-Based Local Outliers. Assoc. Comput. Mach. 2000, 29, 2. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Schölkopf, B.; Williamson, R.; Smola, A.; Shawe-Taylor, J.; Platt, J. Support Vector Method for Novelty Detection. In Proceedings of the 12th International Conference on Neural Information Processing Systems, NIPS’99, Cambridge, MA, USA, 29 November–4 December 1999; pp. 582–588. [Google Scholar]
- Springer. Principal Component Analysis, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2002. [Google Scholar]
- Hardoon, D.R.; Szedmak, S.; Shawe-Taylor, S. Canonical Correlation Analysis: An Overview with Application to Learning Methods. Neural Comput. 2004, 16, 2639–2664. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tarantola, A. Inverse Problem Theory and Methods for Model Parameter Estimation, 1st ed.; SIAM: New Orleans, LA, USA, 2005. [Google Scholar]
- Emerick, A.A. Analysis of the performance of ensemble-based assimilation of production and seismic data. J. Pet. Sci. Eng. 2016, 139, 219–239. [Google Scholar] [CrossRef]
- Fenwick, D.; Scheidt, C.; Caers, J. Quantifying Asymmetric Parameter Interactions in Sensitivity Analysis: Application to Reservoir Modeling. Math. Geosci. 2014, 46, 493–511. [Google Scholar] [CrossRef]
- Park, J.; Yang, G.; Satija, A.; Scheidt, C.; Caers, J. DGSA: A Matlab toolbox for distance-based generalized sensitivity analysis of geoscientific computer experiments. Comput. Geosci. 2016, 97, 15–29. [Google Scholar] [CrossRef]
- Spear, R.C.; Hornberger, G.M. Eutrophication in peel inlet-II. Identification of critical uncertainties via generalized sensitivity analysis. Water Res. 1980, 14, 43–49. [Google Scholar] [CrossRef]
- Andersen, O.; Nilsen, H.M.; Lie, K.A. RReexamining CO2 Storage Capacity and Utilization of the Utsira Formation. In Proceedings of the ECMOR XIV-14th European Conference on the Mathematics of Oil Recovery, Catania, Italy, 8–11 September 2014; pp. 1–18. [Google Scholar]
- Singh, V.; Cavanagh, A.; Hansen, H.; Nazarian, B.; Iding, M.; Ringrose, P. Reservoir modeling of CO2 plume behavior calibrated against monitoring data from Sleipner, Norway. In Proceedings of the SPE Annual Technical Conference and Exhibition, Florence, Italy, 19–22 September 2010. [Google Scholar]
- Sintef. MRST-co2lab. Available online: https://www.sintef.no/projectweb/mrst/modules/co2lab/ (accessed on 6 February 2021).
- Wang, W.; Huang, Y.; Wang, Y.; Wang, L. Generalized Autoencoder: A Neural Network Framework for Dimensionality Reduction. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 496–503. [Google Scholar]
- Lawrence, N.D. Learning for larger datasets with the Gaussian process latent variable model. In Proceedings of the Eleventh International Workshop on Artificial Intelligence and Statistics, San Juan, Puerto Rico, 21–24 March 2007. [Google Scholar]
- Lawrence, N.D. Probabilistic non-linear principal component analysis with Gaussian process latent variable models. J. Mach. Learn. Res. 2005, 6, 1783–1816. [Google Scholar]
- Lopez-Alvis, J.; Hermans, T.; Nguyen, F. A cross-validation framework to extract data features for reducing structural uncertainty in subsurface heterogeneity. Adv. Water Resour. 2019, 133, 103427. [Google Scholar] [CrossRef]
- Lai, P.; Fyfe, C. A neural implementation of canonical correlation analysis, Neural Networks. J. Mach. Learn. Res. 1999, 12, 1391–1397. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | UR—40 Years | UR—3000 Years |
|---|---|---|
| DF | 26.11 | 51.563 |
| DF-ES-MDA | 29.82 | 66.40 |
| DF-SMD | 28.35 | 56.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tadjer, A.; Bratvold, R.B. Managing Uncertainty in Geological CO2 Storage Using Bayesian Evidential Learning. Energies 2021, 14, 1557. https://doi.org/10.3390/en14061557
Tadjer A, Bratvold RB. Managing Uncertainty in Geological CO2 Storage Using Bayesian Evidential Learning. Energies. 2021; 14(6):1557. https://doi.org/10.3390/en14061557
Chicago/Turabian StyleTadjer, Amine, and Reidar B. Bratvold. 2021. "Managing Uncertainty in Geological CO2 Storage Using Bayesian Evidential Learning" Energies 14, no. 6: 1557. https://doi.org/10.3390/en14061557