
Hierarchical Clustering-Based Framework for Interconnected Power System Contingency Analysis



Abstract
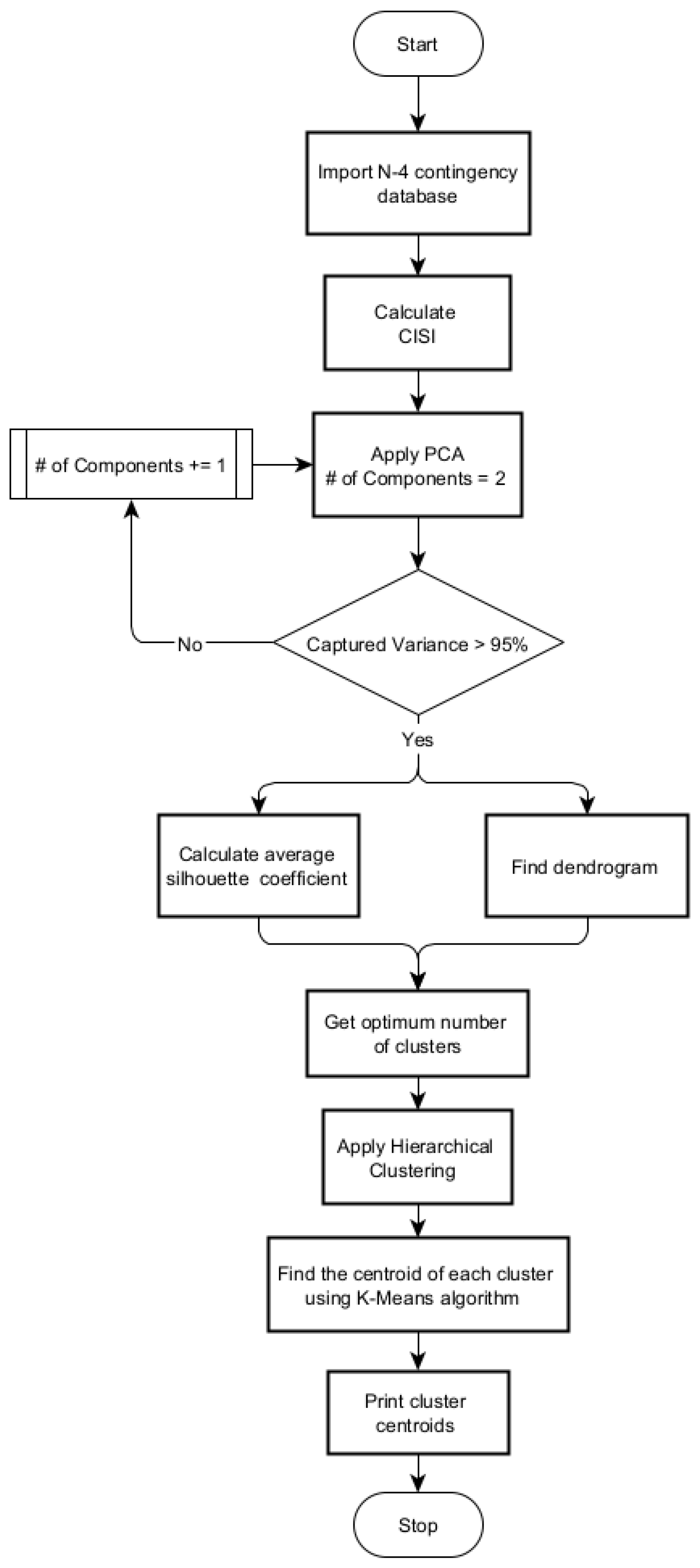
:1. Introduction
2. Insecurity Indices
3. Principal Component Analysis
| Algorithm 1: PCA |
|
4. Hierarchical Clustering
- Single linkage: Uses the slight dissimilarity between observations of the two clusters.
- Complete linkage: Uses the considerable dissimilarity between observations of the two clusters.
- Ward method: Aims to minimize the variance between merged clusters.
- Average method: Uses the average dissimilarity between observations of two merged clusters.
5. Results Discussions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Panda, S.B.; Mohanty, S. Assessment of Power System Security for Different Bus Systems through FVSI/RFVSI and Fuzzy Logic Approaches. IETE Tech. Rev. 2022, 1–16. [Google Scholar] [CrossRef]
- Hassan, R.U.; Yan, J.; Liu, Y. Security risk assessment of wind integrated power system using Parzen window density estimation. Electr. Eng. 2022, 104, 1–12. [Google Scholar] [CrossRef]
- Wood, A.J.; Wollenberg, B.F.; Sheblé, G.B. Power Generation, Operation, and Control; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2013. [Google Scholar]
- Wood, A.J.; Wollenberg, B.F. Power System Generation, Operation and Control; John Wiley: New York, NY, USA, 1984. [Google Scholar]
- Martin, K.; Benmouyal, G.; Adamiak, M.; Begovic, M.; Burnett, R.; Carr, K.; Cobb, A.; Kusters, J.; Horowitz, S.; Jensen, G.; et al. IEEE standard for synchrophasors for power systems. IEEE Trans. Power Deliv. 1998, 13, 73–77. [Google Scholar] [CrossRef]
- Phadke, A. Phasor Measurement Units (PMU s). In Wiley Encyclopedia of Electrical and Electronics Engineering; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2001; pp. 1–3. [Google Scholar]
- Martin, K.E. Synchrophasor Standards Development-IEEE C37. 118 & IEC 61850. In Proceedings of the 2011 44th Hawaii International Conference on System Sciences, Kauai, HI, USA, 4–7 January 2011; pp. 1–8. [Google Scholar]
- Ali, I.; Aftab, M.A.; Hussain, S.M.S. Performance comparison of IEC 61850-90-5 and IEEE C37. 118.2 based wide area PMU communication networks. J. Mod. Power Syst. Clean Energy 2016, 4, 487–495. [Google Scholar] [CrossRef] [Green Version]
- Puhan, S.S.; Sharma, R.; Lenka, S.R. Optimal PMU Placement Using Fuzzy Logic and WAMS Based PMU Measurement for Faulted Zone Identification. In Proceedings of the 2021 1st Odisha International Conference on Electrical Power Engineering, Communication and Computing Technology (ODICON), Bhubaneswar, India, 8–9 January 2021; pp. 1–6. [Google Scholar]
- Amarendra, A.; Srinivas, L.R.; Rao, R.S. Contingency Analysis in Power System- Using UPFC and DVR Devices with RDOA. Technol. Econ. Smart Grids Sustain. Energy 2022, 7, 17. [Google Scholar] [CrossRef]
- Sabhahit, J.N.; Solanke, S.S.; Jadoun, V.K.; Malik, H.; Márquez, F.P.G.; Pinar-Pérez, J.M. Contingency Analysis of a Grid Connected EV’s for Primary Frequency Control of an Industrial Microgrid Using Efficient Control Scheme. Energies 2022, 15, 3102. [Google Scholar] [CrossRef]
- Veda, S.S. WAMS-Based Intelligent Load Shedding Scheme for Preventing Cascading Blackouts. Ph.D. Thesis, Virginia Polytechnic Institute and State University, Blacksburg, VA, USA, 2012; p. 3585949. [Google Scholar]
- Gazafroudi, A.S.; Neumann, F.; Brown, T. Topology-based approximations for N−1 contingency constraints in power transmission networks. Int. J. Electr. Power Energy Syst. 2022, 137, 107702. [Google Scholar] [CrossRef]
- Anwer, A.; Almosawi, A.H. A Dynamic Optimal Power Flow of a Power System Based on Genetic Algorithm. Eng. Technol. J. 2022, 40, 290–300. [Google Scholar] [CrossRef]
- Niebur, D.; Germond, A. Power system static security assessment using the Kohonen neural network classifier. IEEE Trans. Power Syst. 1992, 7, 865–872. [Google Scholar] [CrossRef]
- Kim, H.; Singh, C. Steady State and Dynamic Security Assessment in Composite Power Systems. In Proceedings of the 2003 International Symposium on Circuits and Systems, ISCAS’03, Bangkok, Thailand, 25–28 May 2003; Volume 3. [Google Scholar] [CrossRef]
- Pandit, M.; Srivastava, L.; Sharma, J. Fast voltage contingency selection using fuzzy parallel self-organizing hierarchical neural network. IEEE Trans. Power Syst. 2003, 18, 657–664. [Google Scholar] [CrossRef]
- Pandit, M.; Srivastava, L.; Sharma, J. Cascade fuzzy neural network based voltage contingency screening and ranking. Electr. Power Syst. Res. 2003, 67, 143–152. [Google Scholar] [CrossRef]
- Agreira, C.I.F.; Ferreira, C.M.M.; Pinto, J.A.D.; Barbosa, F.P.M. The Performance Indices to Contingencies Screening. In Proceedings of the 2006 International Conference on Probabilistic Methods Applied to Power Systems, Stockholm, Sweden, 11–15 June 2006; pp. 1–8. [Google Scholar]
- Li, L.; Zhu, Z.-H. On-line Static Security Assessment of Power System Based on a New Half-Against-Half Multi-Class Support Vector Machine. In Proceedings of the 2011 3rd International Workshop on Intelligent Systems and Applications, Wuhan, China, 28–29 May 2011; pp. 1–5. [Google Scholar]
- Hassan, S.; Rastgoufard, P. Detection of power system operation violations via fuzzy set theory. Electr. Power Syst. Res. 1996, 38, 83–90. [Google Scholar] [CrossRef]
- Matos, M.; Hatziargriou, N.; Lopes, J.A.P. Multicontingency steady state security evaluation using fuzzy clustering techniques. IEEE Trans. Power Syst. 2000, 15, 177–183. [Google Scholar] [CrossRef]
- Kalyani, S.; Swarup, K.S. Supervised fuzzy C-means clustering technique for security assessment and classification in power systems. Int. J. Eng. Sci. Technol. 2010, 2, 175–185. [Google Scholar] [CrossRef]
- Kalyani, S.; Swarup, K. Particle swarm optimization based K-means clustering approach for security assessment in power systems. Expert Syst. Appl. 2011, 38, 10839–10846. [Google Scholar] [CrossRef]
- Javan, D.S.; Mashhadi, H.R.; Rouhani, M. A fast static security assessment method based on radial basis function neural networks using enhanced clustering. Int. J. Electr. Power Energy Syst. 2013, 44, 988–996. [Google Scholar] [CrossRef]
- Talaat, H. Predictive out-of-step relaying using fuzzy rule-based classification. Electr. Power Syst. Res. 1999, 48, 143–149. [Google Scholar] [CrossRef]
- Hua, H.; Qin, Y.; Hao, C.; Cao, J. Stochastic optimal control for energy Internet: A bottom-up energy management approach. IEEE Trans. Ind. Inform. 2018, 15, 1788–1797. [Google Scholar] [CrossRef]
- Salehi, N.; Martínez-García, H.; Velasco-Quesada, G. Networked Microgrid Energy Management Based on Supervised and Unsupervised Learning Clustering. Energies 2022, 15, 4915. [Google Scholar] [CrossRef]
- Hua, H.; Qin, Z.; Dong, N.; Qin, Y.; Ye, M.; Wang, Z.; Chen, X.; Cao, J. Data-driven dynamical control for bottom-up energy Internet system. IEEE Trans. Sustain. Energy 2021, 13, 315–327. [Google Scholar] [CrossRef]
- Ibrahim, H.A.; Hemade, B.A.; Talaat, H.E.A. Generated Power-Based Composite Security Index for Evaluation of Cascading Outages. In Proceedings of the 2017 Nineteenth International Middle East Power Systems Conference (MEPCON), Cairo, Egypt, 19–21 December 2017; pp. 735–740. [Google Scholar]
- Ejebe, G.C.; Wollenberg, B.F. Automatic contingency selection. IEEE Trans. Power Appar. Syst. 1979, PAS-98, 97–109. [Google Scholar] [CrossRef]
- Halilčević, S.S.; Gubina, F.; Gubina, A.F. The uniform fuzzy index of power system security. Eur. Trans. Electr. Power 2010, 20, 785–799. [Google Scholar] [CrossRef]
- Baghaee, H.; Abedi, M. Calculation of weighting factors of static security indices used in contingency ranking of power systems based on fuzzy logic and analytical hierarchy process. Int. J. Electr. Power Energy Syst. 2011, 33, 855–860. [Google Scholar] [CrossRef]
- Krishnakumar, B.; Soundarajan, S.K.; Gnanadass, R. Fuzzy Based Contingency Assessment Using Performance Indices with Masking Effect. In Proceedings of the 2012 IEEE Students’ Conference on Electrical, Electronics and Computer Science, Bhopal, India, 1–2 March 2012; pp. 1–5. [Google Scholar]
- Dhandhia, A.; Pandya, V. Contingency ranking in static security assessment using teaching learning based optimization enhanced support vector regression. Mater. Today Proc. 2022, 62, 7174–7178. [Google Scholar] [CrossRef]
- Talaat, H.E.A.; Ibrahim, H.A.; Hemade, B.A. Synchrophasor Measurements-Based on-Line Power System Steady-State Security Indices—Part I: Methodology. In Proceedings of the 2016 Eighteenth International Middle East Power Systems Conference (MEPCON), Cairo, Egypt, 27–29 December 2016; pp. 699–704. [Google Scholar]
- Hemade, B.A.; Ibrahim, H.A.; Talaat, H.E.A. Steady-state Security Assessment Based on K-Means Clustering Algorithm and Phasor Measurement Units. Recent Adv. Electr. Electron. Eng. 2020, 13, 559–570. [Google Scholar] [CrossRef]
- Zhang, J.; Yan, Y.; Lades, M. Face Recognition: Eigenface, Elastic Matching, and Neural Nets. Proc. IEEE 1997, 85, 1423–1435. [Google Scholar] [CrossRef]
- Thompson, M. Digital Image Processing by Rafael C. Gonzalez and Paul Wintz. Leonardo 1981, 14, 256–257. [Google Scholar] [CrossRef]
- Lakhina, A.; Crovella, M.; Diot, C. Diagnosing network-wide traffic anomalies. ACM SIGCOMM Comput. Commun. Rev. 2004, 34, 219–230. [Google Scholar] [CrossRef] [Green Version]
- Paffenroth, R.; Kay, K.; Servi, L. Robust pca for anomaly detection in cyber networks. arXiv 2018, arXiv:1801.01571. [Google Scholar]
- Mohammadi, H.; Dehghani, M. PMU based voltage security assessment of power systems exploiting principal component analysis and decision trees. International J. Electr. Power Energy Syst. 2015, 64, 655–663. [Google Scholar] [CrossRef]
- Javan, D.S.; Mashhadi, H.R.; Toussi, S.A.; Rouhani, M. On-line Voltage and Power Flow Contingencies Ranking Using Enhanced Radial Basis Function Neural Network and Kernel Principal Component Analysis. Electr. Power Compon. Syst. 2012, 40, 534–555. [Google Scholar] [CrossRef]
- Park, S.; Park, Y.B. Photovoltaic Power Data Analysis Using Hierarchical Clustering. In Proceedings of the 2018 International Conference on Information Networking (ICOIN), Chiang Mai, Thailand, 10–12 January 2018; pp. 727–731. [Google Scholar] [CrossRef]
- Jasinski, M.; Sikorski, T.; Leonowicz, Z.; Kaczorowska, D.; Suresh, V.; Szymanda, J.; Jasinska, E. Different Working Conditions Identification of a PV Power Plant Using Hierarchical Clustering. In Proceedings of the 2020 12th International Conference on Electronics, Computers and Artificial Intelligence (ECAI), Bucharest, Romania, 25–27 June 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Yeung, K.Y.; Ruzzo, W.L. Details of the adjusted rand index and clustering algorithms, supplement to the paper an empirical study on principal component analysis for clustering gene expression data. Bioinformatics 2001, 17, 763–774. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Linkage Criteria | Silhouette Average |
|---|---|
| Ward | 0.75 |
| Complete | 0.61 |
| Average | 0.73 |
| Single | 0.21 |
| Cluster | ||||
|---|---|---|---|---|
| 0 | 0.0 | 0.07 | 0.24 | 0.03 |
| 1 | 0.05 | 0.83 | 0.02 | 0.1 |
| 2 | 0.03 | 0.09 | 0.51 | 1.0 |
| 3 | 0.99 | 1.01 | 1.01 | 0.99 |
| 4 | 0.03 | 0.41 | 0.05 | 0.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hemad, B.A.; Ibrahim, N.M.A.; Fayad, S.A.; Talaat, H.E.A. Hierarchical Clustering-Based Framework for Interconnected Power System Contingency Analysis. Energies 2022, 15, 5631. https://doi.org/10.3390/en15155631
Hemad BA, Ibrahim NMA, Fayad SA, Talaat HEA. Hierarchical Clustering-Based Framework for Interconnected Power System Contingency Analysis. Energies. 2022; 15(15):5631. https://doi.org/10.3390/en15155631
Chicago/Turabian StyleHemad, Bassam A., Nader M. A. Ibrahim, Shereen A. Fayad, and Hossam E. A. Talaat. 2022. "Hierarchical Clustering-Based Framework for Interconnected Power System Contingency Analysis" Energies 15, no. 15: 5631. https://doi.org/10.3390/en15155631
APA StyleHemad, B. A., Ibrahim, N. M. A., Fayad, S. A., & Talaat, H. E. A. (2022). Hierarchical Clustering-Based Framework for Interconnected Power System Contingency Analysis. Energies, 15(15), 5631. https://doi.org/10.3390/en15155631