Abstract
With the rapid development of machine learning, deep reinforcement learning (DRL) algorithms have recently been widely used for energy management in hybrid electric urban buses (HEUBs). However, the current DRL-based strategies suffer from insufficient constraint capability, slow learning speed, and unstable convergence. In this study, a state-of-the-art continuous control DRL algorithm, softmax deep double deterministic policy gradients (SD3), is used to develop the energy management system of a power-split HEUB. In particular, an action masking (AM) technique that does not alter the SD3′s underlying principles is proposed to prevent the SD3-based strategy from outputting invalid actions that violate the system’s physical constraints. Additionally, the transfer learning (TL) method of the SD3-based strategy is explored to avoid repetitive training of neural networks in different driving cycles. The results demonstrate that the learning performance and learning stability of SD3 are unaffected by AM and that SD3 with AM achieves control performance that is highly comparable to dynamic planning for both the CHTC-B and WVUCITY driving cycles. Aside from that, TL contributes to the rapid development of SD3. TL can speed up SD3’s convergence by at least 67.61% without significantly affecting fuel economy.
1. Introduction
Hybrid electric vehicle (HEV) technology is regarded as a dependable vehicle technology that balances long-endurance mileage and low energy usage. HEVs share the burden of the internal combustion engine (ICE) with batteries and electric motors, allowing the ICE to run more effectively and enhancing fuel economy. Therefore, the hybrid system must balance multiple control objectives, such as fuel economy and charging maintenance, thus making the energy management strategy (EMS) key in determining all aspects of HEVs’ performance.
Research on HEVs has spawned massive EMSs, which can be classified into three groups: rule-based EMSs, optimization-based EMSs, and learning-based EMSs [1]. Rule-based strategies control the operation of the power component in real-time using a well-developed heuristic or fuzzy rules [2,3]. These methods are distinguished by low computing costs and excellent reliability, resulting in widespread use in engineering practice [4]. However, because the formulation of control rules relies too heavily on engineers’ knowledge and necessitates time-consuming experiments for calibration, rule-based EMSs have a lengthy development cycle and low fuel-saving performance and self-adaptability [5]. Consequently, research on optimization-algorithm-based strategies that use optimization algorithms to achieve optimal control of HEVs has been substantially encouraged. Global optimization and real-time optimization are two categories of optimization-based strategies, depending on whether the optimization time domain is global or local [6]. Typical global optimization methods include genetic algorithms [7], particle swarm optimization algorithms [8], and dynamic programming (DP) [9], which can find the optimal global solution of the objective function by offline computation. The DP approach, in particular, has been acknowledged as a standard for investigating the optimal energy optimization for HEVs. However, global optimization techniques rely on prior knowledge of the driving conditions of the future, making it impossible to use them in real-world scenarios [10]. Therefore, real-time optimization method research has received much attention due to its practical viability. For instance, the equivalent consumption minimization strategy (ECMS), which accomplishes torque distribution by finding the least of the sum of the equivalent fuel consumption and the actual fuel consumption at each time step, is a greedy method with proven engineering applications [11]. Unfortunately, the ECMS has a weak immunity to perturbations of the equivalent factor, which leads to its poor adaptability and stability [12]. Despite the emergence of various adaptive ECMSs [13], the sensitivity issue with the equivalency factor has yet to be fully resolved. Another well-liked real-time optimum energy management approach is model predictive control (MPC), which combines optimization algorithms with predictive approaches to achieve rolling optimization control of HEVs [14]. The correctness of the predictive model is crucial to the MPC’s control performance since it determines the system’s torque distribution by solving a predictive model [15]. However, the development of MPC-based EMSs is hampered by the difficulty of balancing accuracy and stability in present prediction methods.
To identify new control approaches that can address the disadvantages mentioned above, learning-based EMSs, particularly those based on deep reinforcement learning (DRL), have recently received much attention [16]. Since the energy management problem for HEVs can be described as the Markov decision process (MDP), the DRL technique can be successfully used for the energy-efficient control of HEVs [17]. The DRL strategy uses neural networks to learn torque distribution, which can improve energy efficiency by interacting with the environment. Therefore, the DRL strategy is a neural network black box with end-to-end state inputs and action outputs, which implies the strategy only needs a small amount of computation to obtain the optimal output [18]. DRL EMSs fall into two categories: discrete control (DC) DRL strategies and continuous control (CC) DRL strategies, depending on the control form [19]. Deep Q-network (DQN)-based, Double DQN-based, and Dueling DQN-based methods are the most emblematic DC DRL approaches [20,21,22]. The core of these methods is to iterate a Q-value function using neural networks that can evaluate state-action pairs according to a temporal-differential (TD) approach so that the actions are selected at each step by [23]. Given that DC DRL methods can only handle actions that are independent of one another due to the way they learn, continuous physical space actions like engine power must be discretized. However, higher discretization accuracy makes it challenging to converge the DC DRL strategy, while lower discretization accuracy causes a significant discretization error [24]. As a result, it is more challenging to employ DC DRL methods to optimize the energy efficiency of HEVs, which encourages the development of CC DRL strategies that can avoid the action discretization issue. The deep deterministic policy gradient (DDPG)-based strategy, the twin delayed DDPG (TD3)-based strategy, and the soft actor-critic (SAC)-based strategy are all representative CC DRL EMSs that learn torque distribution using actor-critic (AC) technology [25,26,27]. Specifically, these strategies use actor neural networks to select output actions within the continuous action space and the critic neural networks to learn value functions that can evaluate the actor. Under the guidance of critics, the actor updates in the direction that can obtain a greater value evaluation through the gradient descent method. With the AC structure, CC DRL strategies are more accurate than DC DRL strategies at determining the optimal action since they can perform any action belonging to a continuous action interval [28]. To demonstrate the effectiveness of CC DRL EMSs, numerous studies have been carried out. Li et al. [29] discovered, for instance, that the DDPG-based strategy performed better than the MPC-based strategy in terms of fuel-saving performance and computational speed without knowledge of future travels. According to Zhou et al. [30], compared to the DQN-based strategy, the double DQN-based strategy, and the dueling DQN-based strategy, the TD3-based technique converges more quickly, is more adaptable, and uses less fuel. Wu et al. [31] indicated that the SAC-based strategy has excellent learning ability. It can reduce the training time by 87.5% and improves fuel economy by up to 23.3% compared to the DQN-based strategy.
Nevertheless, the CC DRL strategies from the current studies still have unsolved issues. The first one is that the critic networks of common CC DRL strategies suffer from large Q-value estimation bias, which can cause poor learning stability and extreme sensitivity to the hyperparameters of the strategies [32]. As a result, it usually takes a great deal of time to assess the effect of various combinations of hyperparameters. Another issue is the lack of security in CC DRL strategies. It is due to the fact that CC DRL strategies would execute aimless exploration over the whole action space to avoid getting trapped in a local optimum, and thus the strategies would output actions that violate the physical constraints of the powertrain system. This means that there may be an unreasonable torque distribution between the engine and the motor/generator, which can cause irreversible damage to the power components. Besides, the initialization of the CC DRL strategies is usually random, so the strategies require long exploration periods to accumulate experience, which leads to a high training cost. Transfer reinforcement learning techniques are expected to solve this problem, i.e., some knowledge from already learned strategies can be transferred to new strategies through transfer learning (TL), which speeds up learning by improving the initial performance of new strategies. However, there is a lack of research on transfer reinforcement learning in the EMS field.
To cope with the above problems, this study adopts a cutting-edge CC DRL algorithm, namely softmax deep double deterministic policy gradients (SD3), to formulate EMS for a power-split hybrid electric urban bus (HEUB). Based on the traditional AC method, SD3 can not only avoid the overestimation and underestimation of the Q-value through the double Q-learning technique, Boltzmann softmax technique, and dual-actor technique, but also can improve the sampling efficiency and learning stability. Therefore, the SD3 algorithm has great potential in the EMS field. The main contributions of this research are as follows:
- The current EMS field lacks research related to the SD3 algorithm, and, to the authors’ knowledge, this is a pioneering research work related to the SD3-based strategy;
- In order to prevent the SD3-based strategy from outputting torque assignments that do not adhere to the physical limits of the powertrain system in stochastic exploration, an action masking method that does not go against the algorithmic concept is proposed. This work can drive DRL-based strategies toward engineering applications and be an inspiration for the improvement of other DRL algorithms;
- The possibility of utilizing TL methods to quicken SD3 learning is investigated. That is, part of the prior knowledge of the already converged strategy is migrated to the new driving cycle for initializing the new strategy, which can avoid the cold start of the new strategy in the new environment.
The paper is organized as follows: In Section 2, the modeling of the studied HEUB and its associated energy management problems are introduced. In Section 3, the system design of the SD3-based strategy, the invalid action masking method, and the transfer learning technique are described. In Section 4, the SD3-based strategy experiments and the strategy’s performance are discussed numerically under several metrics. Conclusions and some suggestions for future work are given in Section 5.
2. Powertrain Modeling and Energy Management Problem
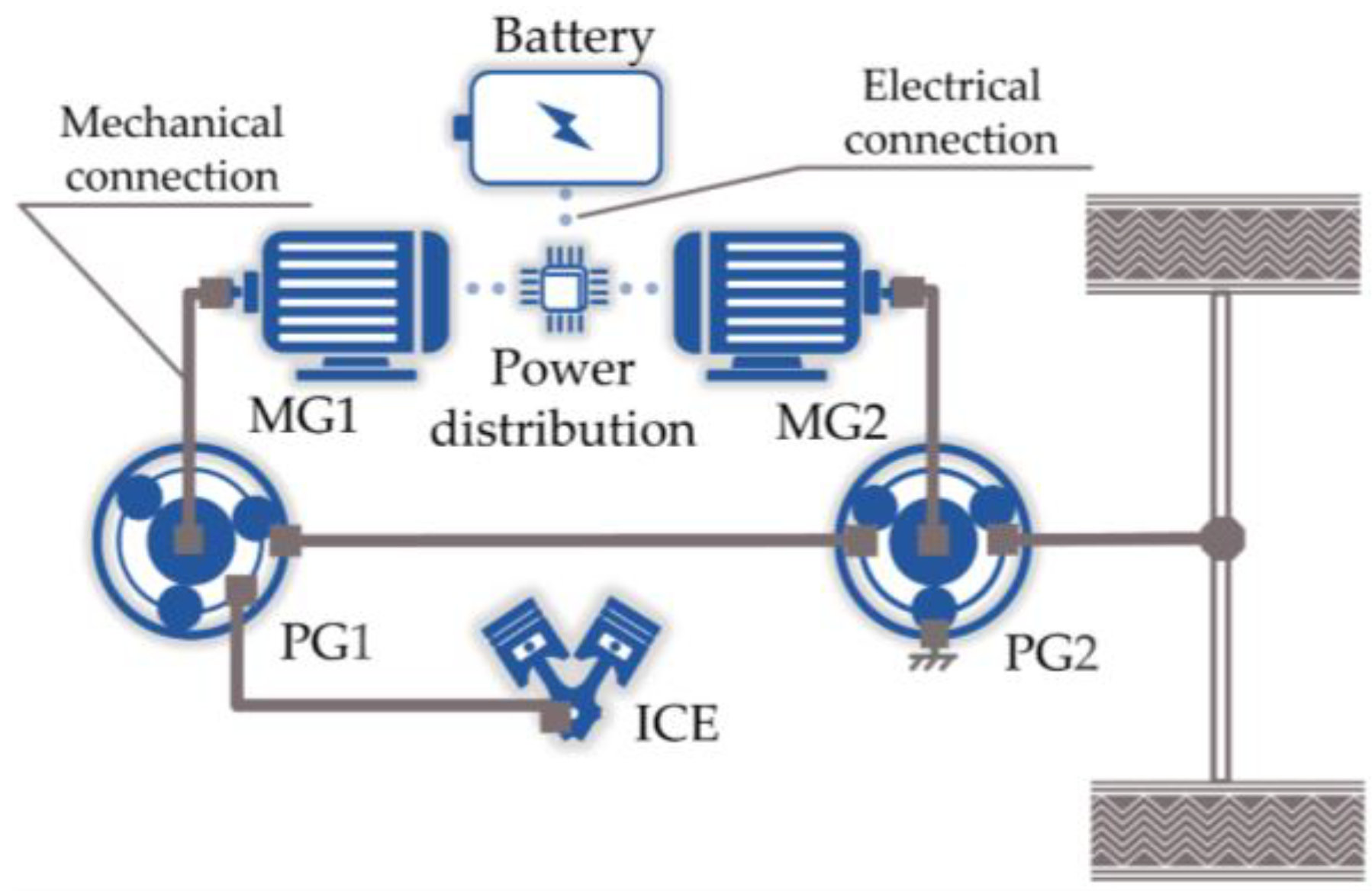
As shown in Figure 1, the powertrain system of the studied HEUB is mainly composed of the ICE, low-power motor MG1, high-power motor MG2, battery pack, and power coupling mechanism with a front planetary row (PG1) and a rear planetary row (PG2). Detailed specifications of the HEUB are provided in Table 1. PG1 acts as a power-split mechanism, with a sun gear (S1) and a planet carrier (C1) connected to MG1 and ICE, respectively. The rear planetary row PG2 acts as the reduction mechanism of MG2, and its sun gear (S2) and gear ring (R2) are connected to MG2 and the chassis frame, respectively. Moreover, the gear ring (R1) of PG1 is connected to the planet carrier (C2) of PG2, and together they serve as the power output of the transmission. This work aims to establish a logical EMS to coordinate the efficient operation of the above components. This section outlines the mathematical formulation of the energy management optimization problem and the modeling of the HEUB’s components.
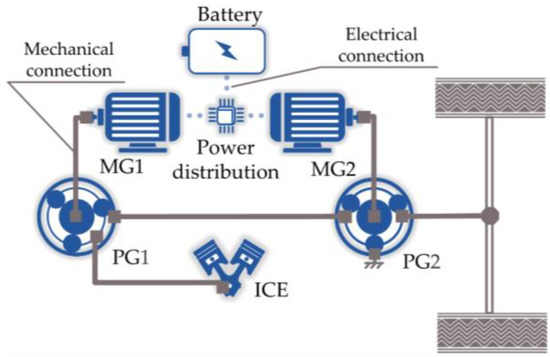
Figure 1.
Powertrain configuration.

Table 1.
Main parameters of HEUB.
2.1. Vehicle Dynamics Model
The studied HEUB in this work is modeled using a backward method, and its longitudinal dynamics can be expressed as follows using the theory of automotive dynamics:
where denotes the driving force demand, denotes the vehicle mass, denotes the gravity acceleration, denotes the rolling resistance coefficient, denotes the angle of road slope, denotes the aerodynamic drag coefficient, denotes the air density, denotes the front area, denotes the vehicle velocity, denotes the rotary mass conversion coefficient, and denotes the acceleration.
The most crucial mechanical transmission part of the investigated HEUB is the power coupling mechanism shown in Figure 1. It can divide the ICE output power into two parts, one of which is converted into electrical energy by the generator and the other of which is transmitted through the mechanical path for driving the vehicle. This advantage enables a complete decoupling of the ICE from the wheels, enabling more effective control of the ICE operating point [33]. According to the dynamics of the planetary wheel system, the constraint relations to be satisfied by the power distribution between the ICE, MG1, and MG2 can be obtained as follows:
where , , and denote the speed of MG1, MG2, and ICE, respectively; , , and denote the torque of MG1, MG2, and ICE, respectively; and denote the characteristic parameters of PG1 and PG2, respectively; and and denote the output speed and output torque of the power coupling mechanism, respectively.
Then, the output torque of the power coupling mechanism and the vehicle driving force should satisfy the following relationship:
where denotes the rolling radius, and denotes the final gear ratio.
2.2. Power Units Model
The power unit model includes the ICE model, MG1 model, MG2 model, and battery model. The ICE and motor are built using a quasi-static-based modeling approach in this research. Namely, their transient responses are ignored in the model, and only experimental data are used to simulate their static variations [34]. Therefore, the fuel consumption rate of the ICE and the efficiency of the motor are both functions concerning speed and torque. According to the efficiency maps [35], once the speed and torque are determined, the fuel consumption rate or efficiency can be calculated using the look-up table method, which has been adopted by most studies.
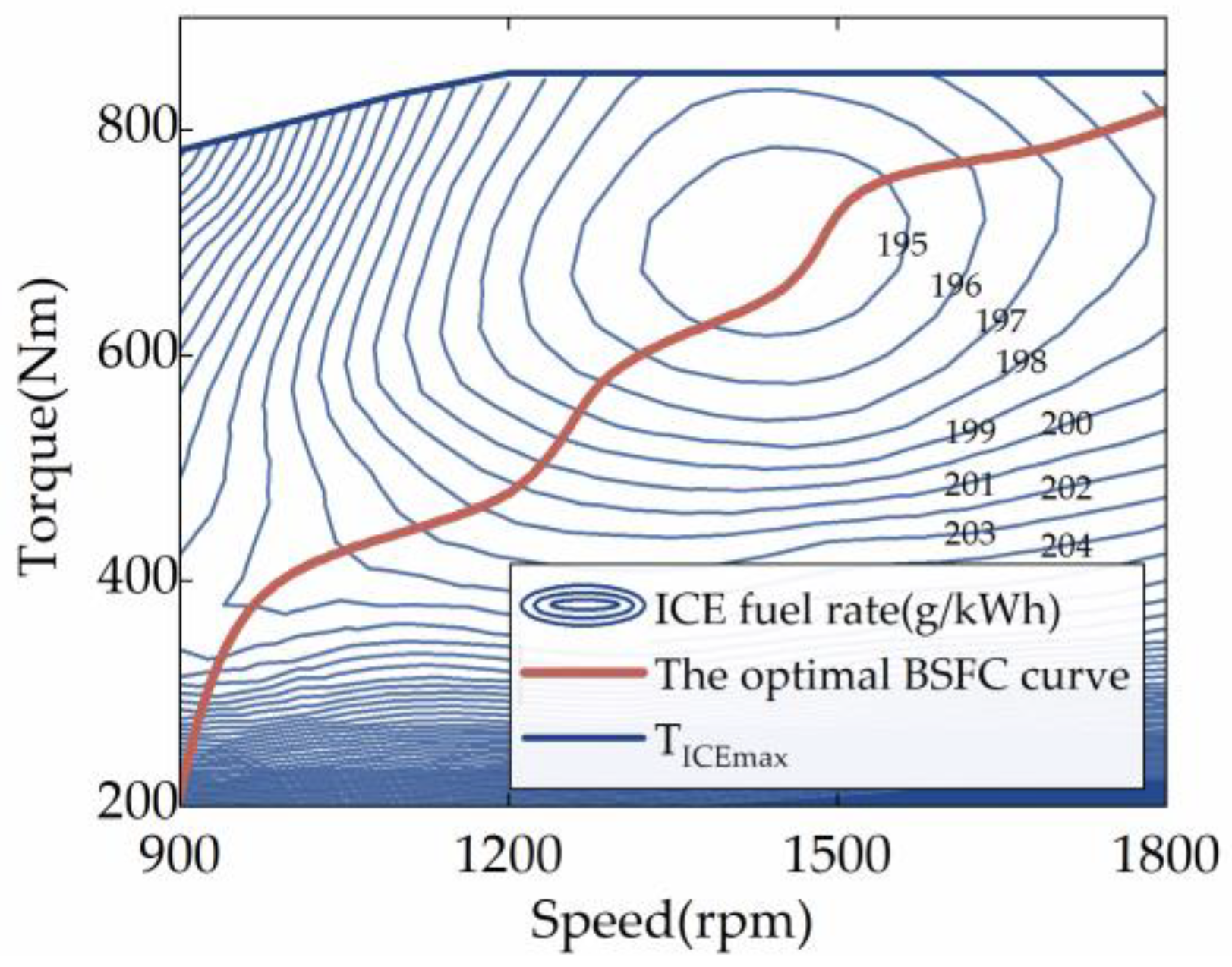
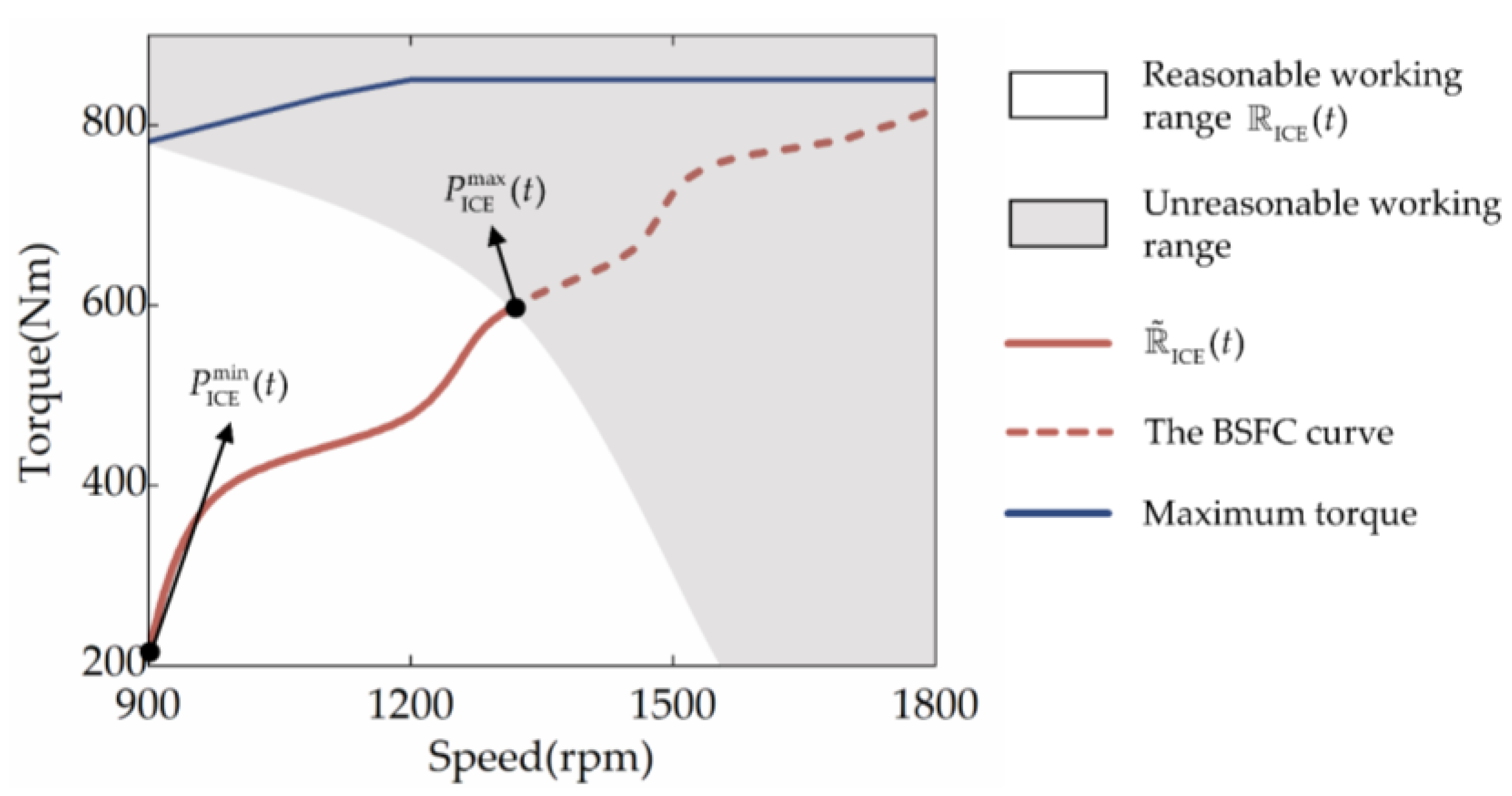
Furthermore, the ICE may be controlled to work in any condition because the investigated HEUB can doubly decouple the ICE speed and torque by employing a planetary gear set. In order to narrow the scope of the EMS’s optimization-seeking, the optimal braking specific fuel consumption (BSFC) curve of the ICE is extracted as a priori information in this work. Lian et al. have demonstrated that this method can significantly shorten the DRL strategy’s learning period without sacrificing fuel efficiency [24]. The optimal operating curve of the object ICE is shown in Figure 2, which consists of the set of operating points with the lowest BSFC at each ICE power, . Additionally, since the electric motor’s efficiency is far higher than the ICE’s, the ICE can be the primary focus of energy management improvement.
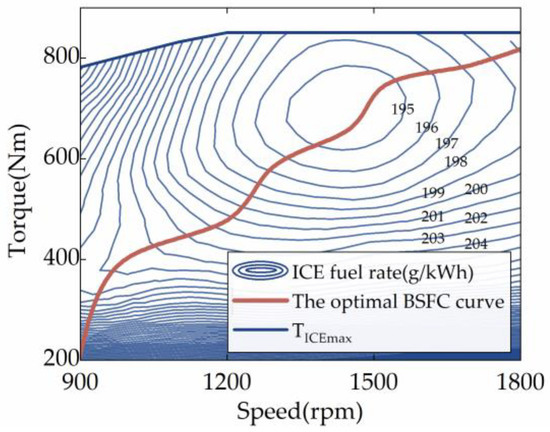
Figure 2.
Optimal BSFC curve of the ICE.
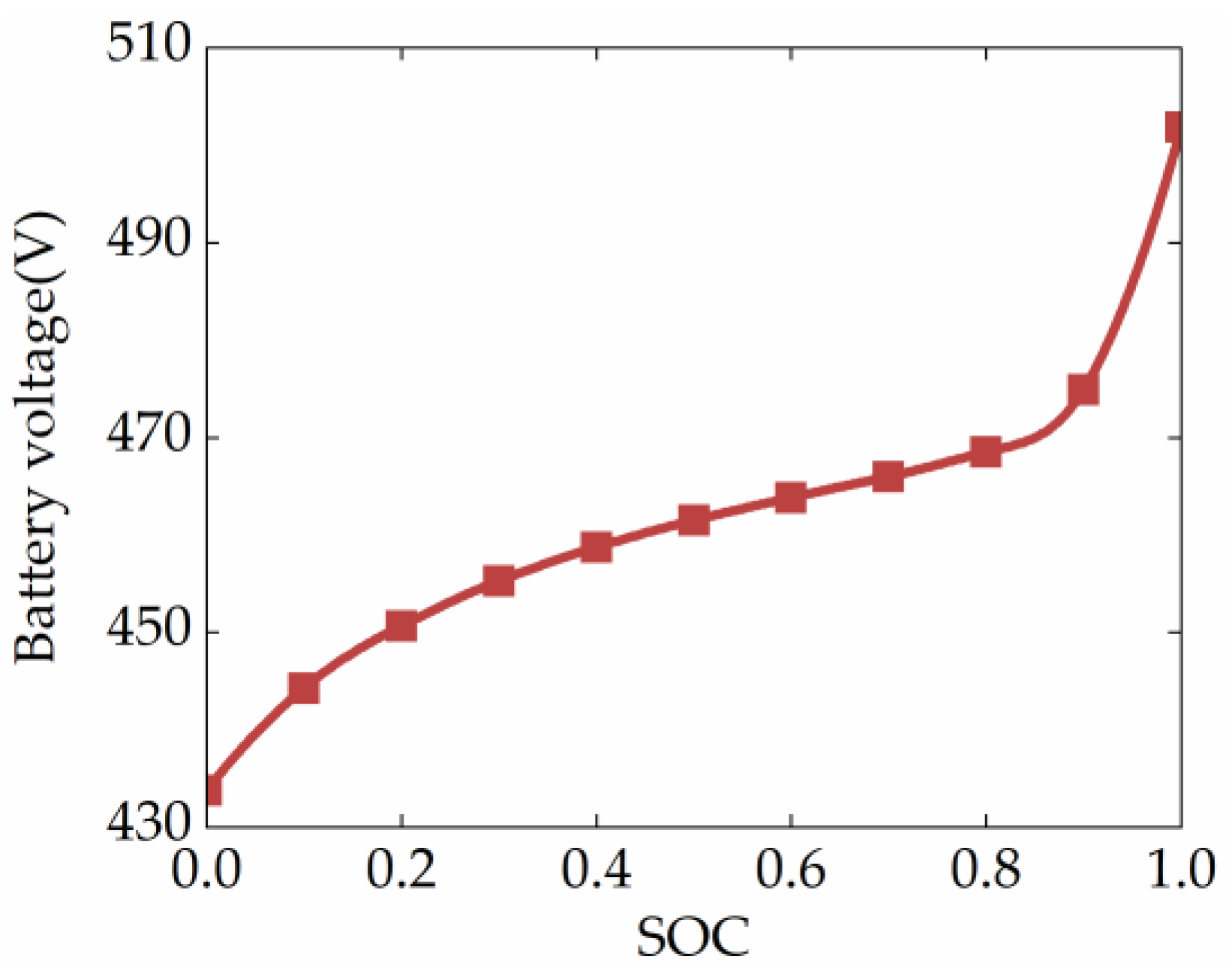
The power battery pack is simulated by a first-order equivalent circuit model, which is practical and effective for energy management problems [36]. The voltage characteristic curve of the battery is shown in Figure 3, which shows that the open-circuit voltage depends on the battery’s state of charge (SOC). In addition, since the open-circuit voltage changes more gently when the SOC is around 0.6, the initial SOC of the HEUB simulation is set to 0.6, and the SOC constraint range is set to [0.5,0.7] in this study. The theoretical battery model is formulated as:
where , , and denote the power of the battery, MG1, and MG2, respectively; denotes the lost power; and , , , , and denote the current, open-circuit voltage, internal resistance, initial SOC, and capacity of the battery, respectively.
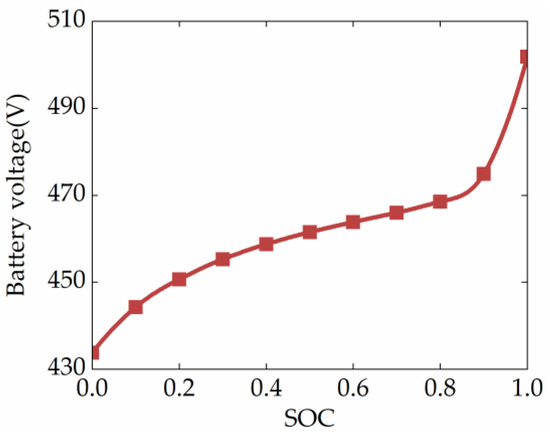
Figure 3.
Characteristic curves of the battery.
2.3. Energy Management Problem
The energy management problem for HEVs is a non-linear optimal control problem with constraints, and its control objectives include minimizing fuel consumption and balancing electric quantity. These two objectives are critical for improving vehicle economy and endurance mileage, as well as maintaining battery life and reliability. Therefore, this study uses a trade-off cost function between fuel economy and electric quantity sustainability to measure the performance of energy management strategies, as established below:
where denotes the instantaneous fuel consumption, denotes the penalty term preset value, and denotes a positive penalty factor.
The energy management problem is subjected to the following physical constraints:
where , , and (, , and ) are the minimum (maximum) torque of MG1, MG2, and ICE, respectively; , , and (, , and ) are the minimum (maximum) rotation speed of MG1, MG2, and ICE, respectively; and and ( and ) are the minimum (maximum) power and current, respectively.
3. Methods and Design of SD3-Based EMS
The DRL problem can be described by an MDP defined as a 5-tuple [37], where S denotes the state space of the environment, A denotes the action space of the agent, T denotes the transfer probability between states, r denotes the reward function, and denotes the discount factor. In the MDP, the DRL algorithm continuously updates the policy function to optimize the action output based on the reward feedback obtained from the interaction with the environment. The policy function is a mapping from states to actions, and its performance can be evaluated by a state-value function or a Q-value function . Therefore, DRL algorithms usually find the optimal policy function that maximizes the cumulative reward by iterating over the optimal value function.
Since the energy management problem of HEVs is a sequential control problem, it can be mathematically described as an MDP. In the energy management MDP, the driving cycle and the powertrain system are part of the environment. The DRL algorithm searches for an optimal strategy that satisfies the energy optimization objective by trying different torque distribution strategies. This section proposes a novel DRL-based strategy, namely the SD3-based strategy, and its algorithm principles and formulation details are presented in detail.
3.1. Preliminary Formulation of SD3-Based EMS
3.1.1. Brief Review of SD3
SD3 is an off-policy CC DRL algorithm that iterates the optimal Q-value function and policy function by the AC method [32]. Specifically, SD3 uses neural networks called actor and critic to approximate the policy function and Q-value function , respectively. The actor network is the interactive end of SD3 for action selection. At the same time, the critic network is used to estimate the Q-value and thus guide the actor network to learn the strategy that maximizes the Q-value by the gradient method. With this clever design, SD3 can handle problems with a continuous action space and avoid discretization errors. On this basis, to improve the critic’s estimation performance and the actor’s sampling efficiency, SD3 draws on the experience of DQN and double Q-learning. It integrates the dual-actor technique, dual-critic technique, and target network technique in the AC method [23,38]. That means the learning framework of SD3 needs to integrate eight neural networks, including two actor networks, two critic networks, two target actor networks, and two target critic networks. Among them, only the actor and critic networks need to be trained with parameters, while the target network is updated by soft copying the weights of the actor and critic networks. It is worth mentioning that the actor and critic networks are trained using an experience replay method. That means that SD3 deposits transfer samples consisting of state , action , immediate reward , next state , and done flag generated from each interaction with the environment into the experience buffer , and then randomly samples mini-batches of samples from the experience buffer to train the network. This practice can improve the utilization of samples and attenuate the correlation between training samples.
As for the critic network, SD3 uses the clipped double Q-learning method integrated with the Boltzmann softmax operator to estimate the Q-value and construct the TD error. Namely, the loss function of the critic network is as follows:
where
where
where denotes the next action; denotes the target actor networks and with weights and , respectively; denotes the noise obeying normal distribution, which is clipped to the interval ; denotes the target critic networks and with weights and , respectively; denotes the probability density function of the normal distribution; denotes the parameters of the softmax operator; denotes the critic networks and with weights and . Note that Equation (9) uses the minimum of the two target critic networks to initially estimate the Q-value. This technique, called clipped double Q-learning, can mitigate the overestimation of values. Equation (8) yields an unbiased estimate of the softmax operator by importance sampling, and the estimated Q-value is further processed. This technique can smooth the optimization landscape to limit the estimation error to a certain range.
As for the two actor networks, their learning objective is to maximize the Q-value, so they are updated according to the output value of the critic network using the deterministic policy gradient method, i.e.,
where denotes the actor networks and with weights and , respectively.
The target networks do not need to be trained, and the parameters are optimized by soft updates, i.e.,
where is the soft update factor. Usually, is set to ensure that the target networks change smoothly so that stable learning targets can be provided for the critic networks. Based on the above description, the pseudo-code of the full SD3 algorithm is provided in Algorithm 1.
| Algorithm 1: SD3 |
| Initialize critic networks , , and actor networks , with random parameters , , , |
| Initialize target networks , , , and |
| Initialize replay buffer |
| forepisode = 1 to E do |
| for t = 1 to T do |
| Observe state s and select action a with exploration noise according to dual-actor: |
| Execute action a, observe reward r, next state s’, and done d |
| Store transition tuple (s, a, r, s’, d) in |
| for i = 1, 2 do |
| Randomly sample a mini-batch of N transitions from |
| Update the critic according to Bellman loss: |
| Update actor by policy gradient: |
| Update target networks: |
| end for |
| end for |
| end for |
3.1.2. Reward, Observation, Action, and Parameters Setting
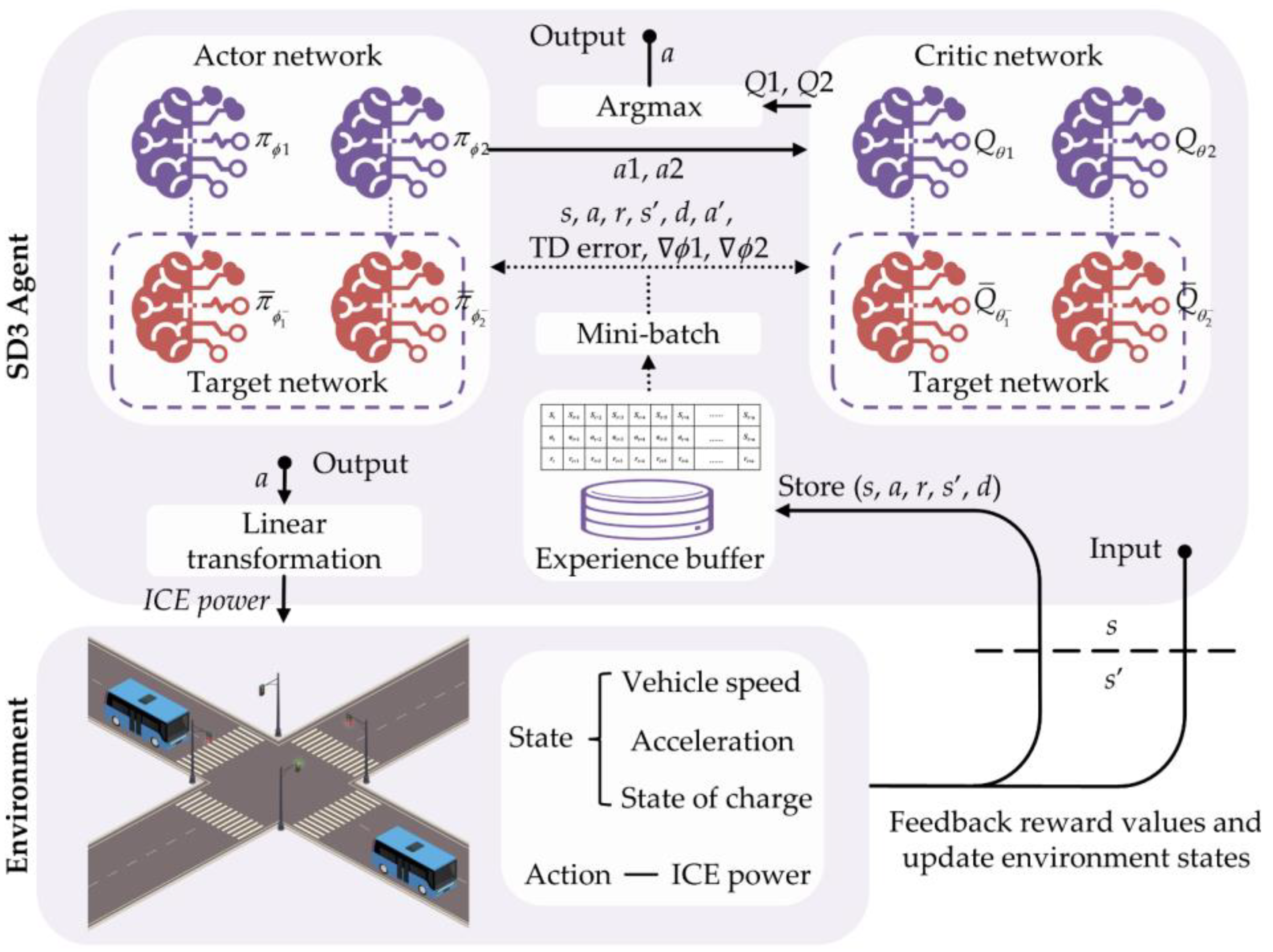
The closed-loop control framework of the SD3-based strategy is shown in Figure 4, and its deployment consists of three main parts: reward design, environment construction (including state design and action design), and parameter setting of the SD3 algorithm.
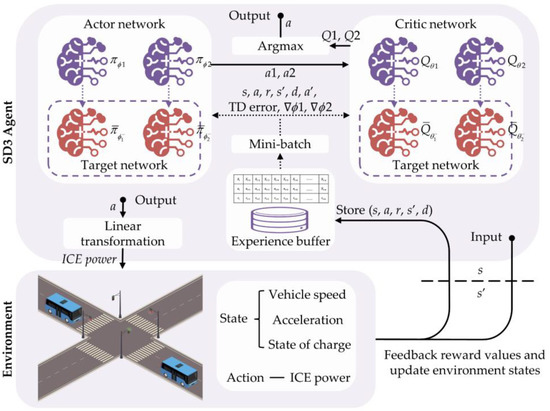
Figure 4.
The framework of the SD3-based EMS.
Reward: In formulating the SD3-based strategy, the SD3 algorithm searches the energy management strategy that minimizes Equation (5) by controlling the HEUB interaction with the environment. Therefore, the multi-objective reward function of the SD3-based strategy should be designed as . The multi-objective reward function’s main challenge is the parameter tuning between and . The purpose of parameter tuning is to minimize fuel use while maintaining SOC. Different weights between them will result in a variety of learning outcomes.
Observation: The SD3-based strategy’s input, the state observation, is used to present fundamental information about the environment. The observation amounts should be comprehensive and independent of one another. Therefore, vehicle speed, acceleration, and SOC are set as state observations in this study, i.e., .
Actions: After observing the state, the SD3-based strategy uses the actor networks to choose a suitable action to decide the system’s torque distribution. According to the optimal BSFC curve discussed in the previous section, the ICE power determines the ICE speed and torque with the best efficiency so that the demand speed and demand torque of the motor can be further determined based on the mechanical characteristics of the system. Thus, the SD3-based strategy can optimize energy control by controlling the power output of the ICE, and the action space is defined as .
Parameter: In this study, all networks of SD3 consist of fully connected layers, including three hidden layers with 512, 256, and 256 nodes, respectively. Among them, the unit layers of the critic networks are activated by the ReLu function. The ReLu function also activates the input and intermediate layers of the actor networks, but the tanh function activates the output layers. Since the tanh function maps the output of the actor networks to (−1,1), the linear transformation of the action space is required. The essential hyperparameters, which were chosen only after several experiments, are also listed in Table 2. Among them, the discount factor , taken as 0.99, means that long-term payoff can be taken into account, thereby increasing the likelihood that SD3 will learn the globally optimal policy [39]. The lower learning rate of the actor networks than that of the critic networks can make the iteration of the Q-function relatively faster, stabilizing the policy update. The larger buffer capacity can accumulate more experience to prevent policy overfitting, and an appropriate mini-batch size is beneficial for the learning stability and efficiency of the algorithm.
Table 2.
Hyperparameters of the SD3.
3.2. Tips for Improving SD3-Based Strategy
3.2.1. Action Masking Technology
In the studied powertrain, MG2′s role is to share the ICE load or charge the battery by brake recovery, so it must have a wide physical operating range to ensure a perfect match with the ICE. Instead, the MG1′s role is to regulate the ICE speed or absorb some of the ICE power to produce electricity. Hence, its physical operating range can be relatively narrow. Given this, the studied HEUB is equipped with a high-power motor MG2 and a low-power motor MG1 for the ICE. Nevertheless, Equation (2) states that when the ICE’s demand speed or torque is too high, the demand speed or torque of the MG1 is also likely to be too high, which would cause the MG1 to violate Equation (5). Namely, the ICE should only operate within a specific range at each time step t to guarantee the reasonable operation of MG1. This indicates that the output action of the SD3 should fall on , the part of the BSFC curve that intersects with . Meanwhile, because the BSFC curve’s speed and torque are positively associated, the higher the power at each point, the higher the speed and torque. Therefore, is continuous, as illustrated in Figure 5, with the upper limit of the maximum feasible power and the lower limit of the minimum feasible power . In conclusion, the output action of SD3 should be limited to and .
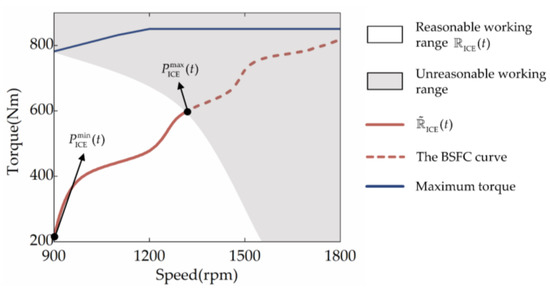
Figure 5.
The reasonable working range of ICE.
Unfortunately, like other DRL-based EMSs, the SD3 would explore the entire action space aimlessly in learning to reduce the risk of falling into a local optimum. That means that SD3 will output actions outside of the . Therefore, it is necessary to design action masking (AM) to filter invalid actions and prevent SD3 from unnecessary exploration in learning. Given that the essence of SD3 is to develop strategies with long-term planning through the state distribution, action distribution, and state transition of the learning environment, AM needs to follow two criteria to prevent the violation of the principles of the SD3 algorithm, thus affecting SD3′s learning performance. The first one is that AM would not change the original action space distribution so that the environment’s potential state transfer probability function will not be destroyed. The second is that samples containing invalid actions will not be collected into the experience replay buffer, so the wrong samples will not participate in the training. Specifically, SD3 implements AM by repeating the following steps at each time step t.
- At each time step t, the is first calculated by the following three steps: (1) The action space is discretized to obtain ; (2) Calculate the and by traversing according to the dynamics of the powertrain system (similar to ECMS); and (3) Obtain ;
- Then, the ICE power output from the actor network in the SD3-based strategy is restricted to by the clip operation, i.e., , since the clip operation does not change the original action space and thus does not have any effect on the policy.
It is essential to point out that the first step is widely used by many mathematical model-based approaches, such as DP, ECMS, and MPC, which all exclude invalid actions by traversing the action space. Also, the AM technique needs to be deployed for both the actor networks and the target actor networks. Otherwise, the learning ability of the algorithm will be seriously affected. Besides, the way to mask invalid actions by the clip operation is only applicable to algorithms like DDPG, TD3, and SD3, which are based on the AC and deterministic policy. For Q-value-based algorithms like DQN, it is possible to ensure that invalid actions are not selected by argmax operations by setting the Q-value of the invalid action to negative infinity. For algorithms such as proximal policy optimization and SAC, which are based on the AC and randomness policy, action masking can be achieved by adjusting the probability of invalid actions being sampled to zero.
3.2.2. Transfer Learning Technology
The DRL algorithm suffers from sample inefficiency, which requires interaction with the environment to acquire many samples to learn the strategy. However, once the environment changes, the previous learning results become invalid and it is necessary to retrain the neural network at a vast cost [40]. Transfer learning is an effective means to solve this problem, and the core idea is to use the experience gained by the model in the old task to improve the learning performance on a related but different task [41].
For HEUBs deployed with the same SD3-based strategy, their rewards, states, actions, powertrain characteristics, and algorithm settings are identical for different urban driving conditions. It implies a correlation between the optimal EMS for different driving conditions. Therefore, after learning in the source driving cycle , some parameters of the actor networks and critic networks can be transferred to the target driving cycle to accelerate the learning. Specifically, the knowledge transfer of the SD3-based strategy from to is divided into three steps:
- The first step is to extract the parameters of the actor networks and critic networks of the SD3-based strategy that have been sufficiently converged in ;
- Then, the extracted parameters are used to initialize the parameters of the corresponding networks of the SD3-based strategy in , and freezing is implemented for the input and intermediate layers of the networks;
- Finally, the output layers of the networks are randomly initialized, and the networks are fine-tuned by a small amount of training.
4. Results and Discussion
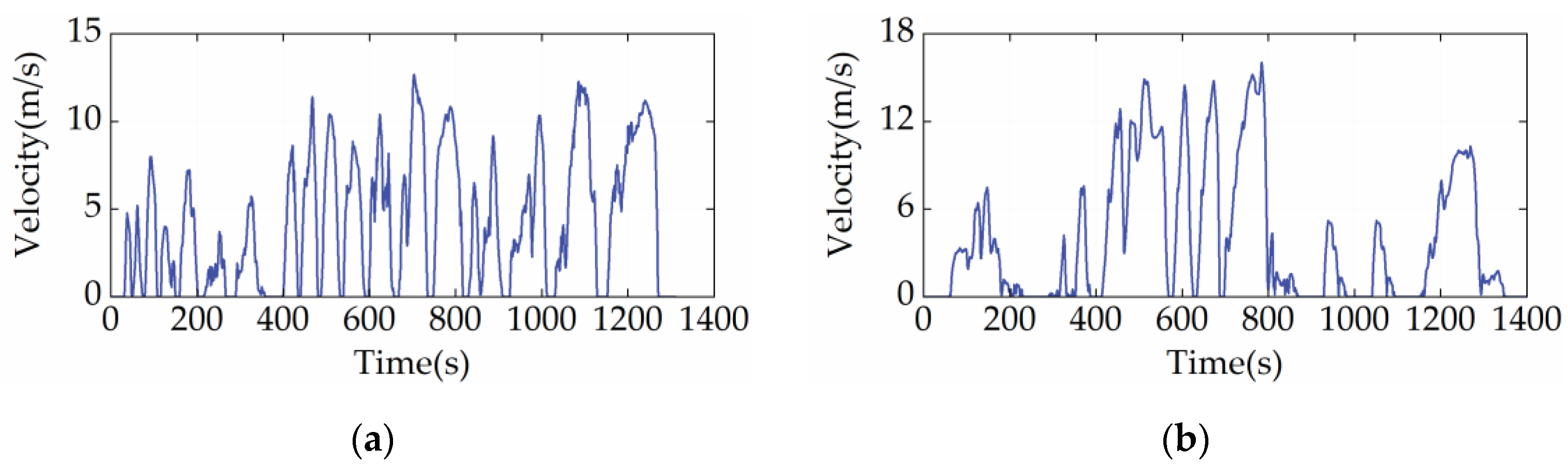
The capability of the proposed EMS in fuel economy optimization and battery charge sustainability maintenance is validated in this section. The driving cycles used in the simulation include the China heavy-duty commercial vehicle cycle-bus (CHTC-B) [see Figure 6a] and the West Virginia University City cycle (WVUCITY) [see Figure 6b]. Moreover, the DP, as an existing benchmarking technique, is involved as the reference strategy [42]. In the formulation of DP, SOC is chosen as the state variable, which is discretized into 200 grids between 0.5 and 0.7. At the same time, the ICE power corresponding to the optimal BSFC curve is designated as the action variable, which is discrete to 160 grids ranging from the minimum to maximum power.
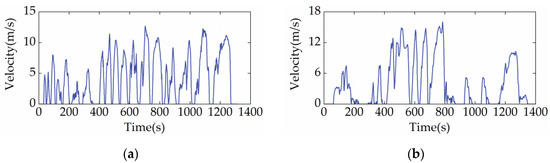
Figure 6.
Driving cycles used for algorithm training and validation. (a) CHTC-B cycle; (b) WVUCITY cycle.
4.1. Performance of SD3-Based Strategy
The performance of the SD3-based strategy in terms of convergence, stability, and control is examined in this section. In this section, the initialization of the parameters of the SD3′s networks is random, meaning that SD3 is not infused with any prior knowledge that contributes to energy optimization before learning. Also, SD3 incorporates AM technology to prevent unreasonable torque distribution in the powertrain system.
4.1.1. Convergence Performance
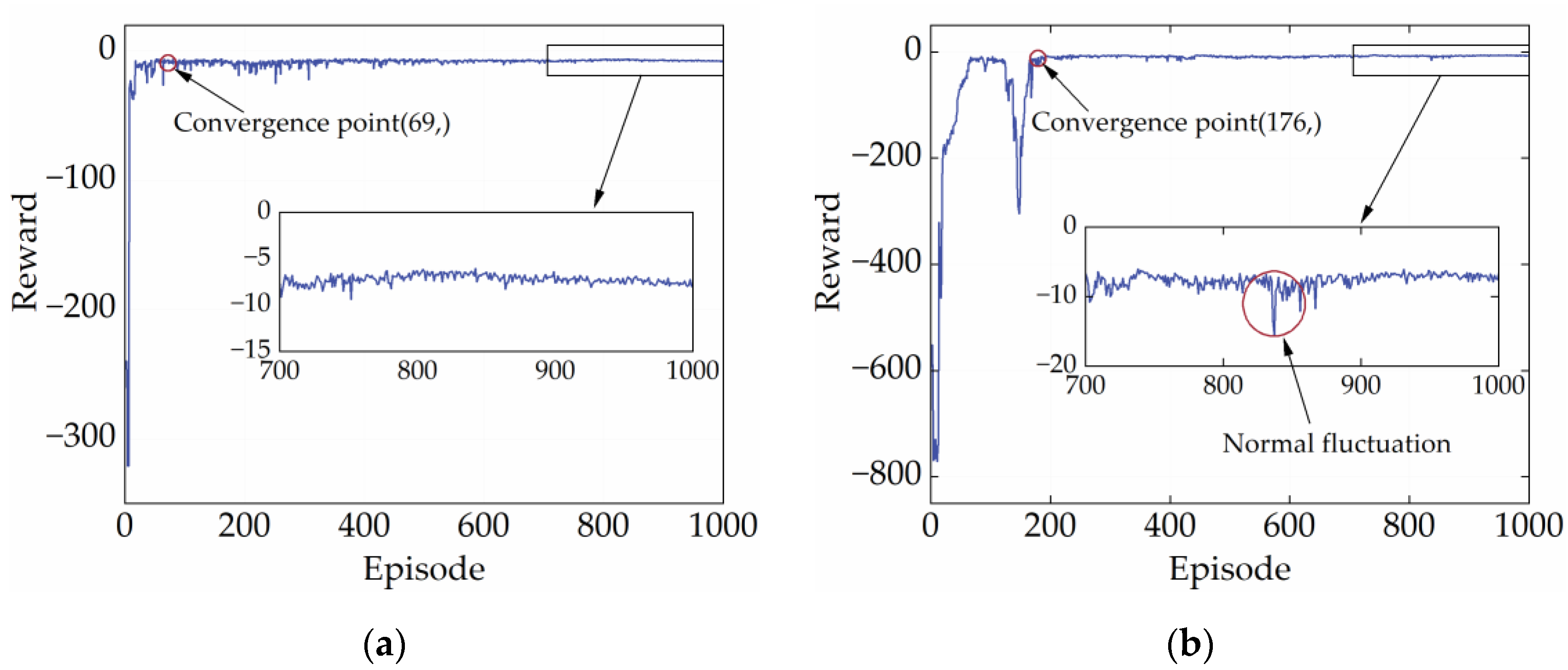
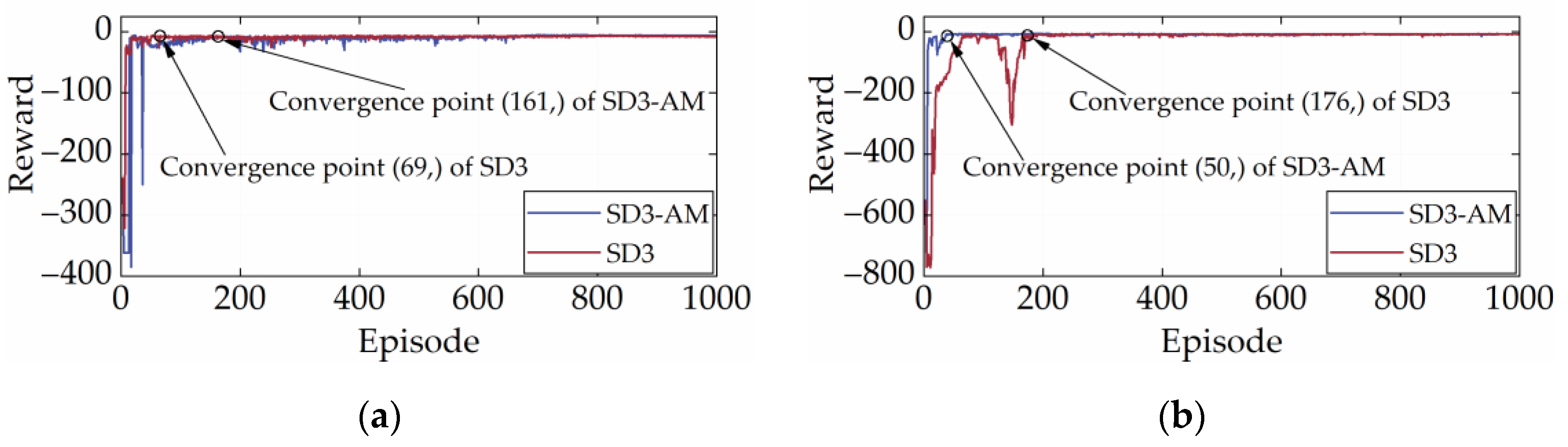
High-quality and stable convergence performance is a reflection of the powerful learning performance of the DRL strategy. Generally, the reward curve is the only metric to assess whether a DRL strategy converges. It shows how the total reward changes in each episode during the training process. In the early stages of training, reward values tend to be low and fluctuate widely. This is because the DRL strategy needs to explore both good and bad experiences. As experience accumulates, the reward value will gradually increase and eventually remain at a high point. Figure 7 illustrates the reward curves of SD3 under the two cycles. According to Figure 7, SD3 completed its early exploration for the CHTC-B and WVUCITY cycles after 69 and 176 episodes, respectively, and the reward value started to fluctuate modestly at the peak. It is important to note that the reward curve finally converges to a straight line, indicating that SD3 has very high convergence stability.
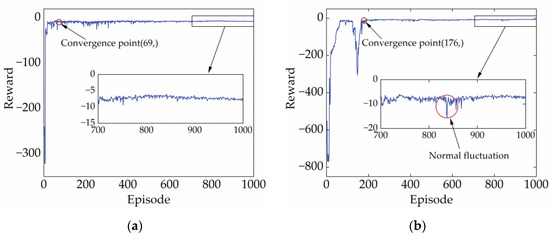
Figure 7.
Reward curves under different driving cycles. (a) CHTC-B; (b) WVUCITY.
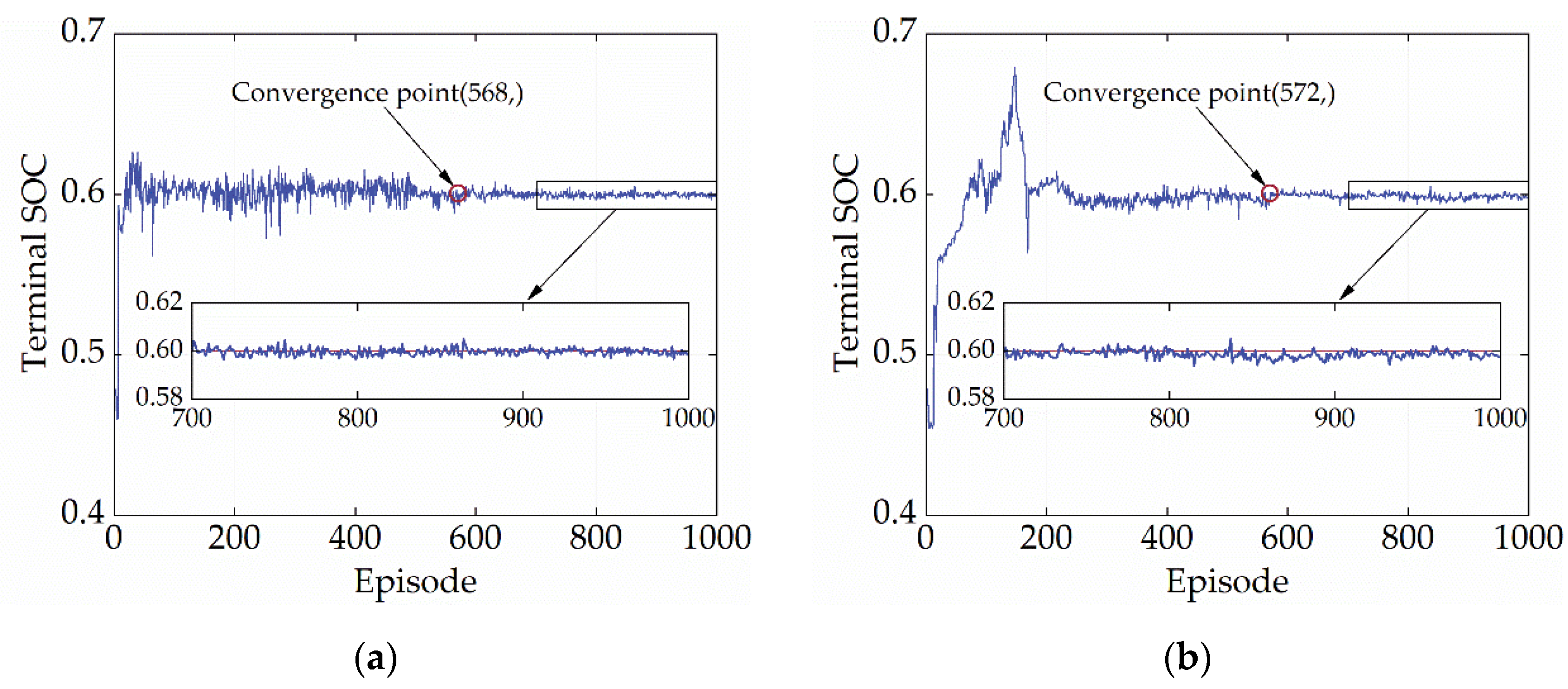
SOC maintenance is a vital control objective for energy management, so the convergence performance of the terminal SOC should also be a criterion to evaluate the convergence capability of the policy. Figure 8 depicts the variation of terminal SOC of SD3 during the learning process. According to Figure 8, the terminal SOC reaches convergence at 568 and 572 episodes under the CHTC-B and WVUCITY cycles, respectively. After, the terminal SOC fluctuates steadily around 0.6, with no value falling below 0.595 and no value exceeding 0.605. (criteria for judging convergence). Table 3 also displays the mean and variance of the terminal SOC for episodes ranging from 600 to 1000. It is evident that the terminal SOC variations after convergence are incredibly minimal, which serves as proof of the high-quality convergence of SD3. Furthermore, the terminal SOC does not converge when the reward curve does, highlighting the significance of employing the terminal SOC as a gauge for the convergence of the strategy.
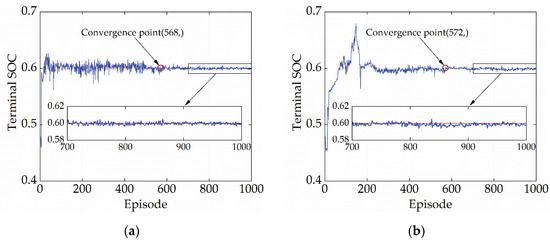
Figure 8.
Terminal SOC curves under different driving cycles. (a) CHTC-B; (b) WVUCITY.
Table 3.
Statistics of the terminal SOC.
4.1.2. Control Performance
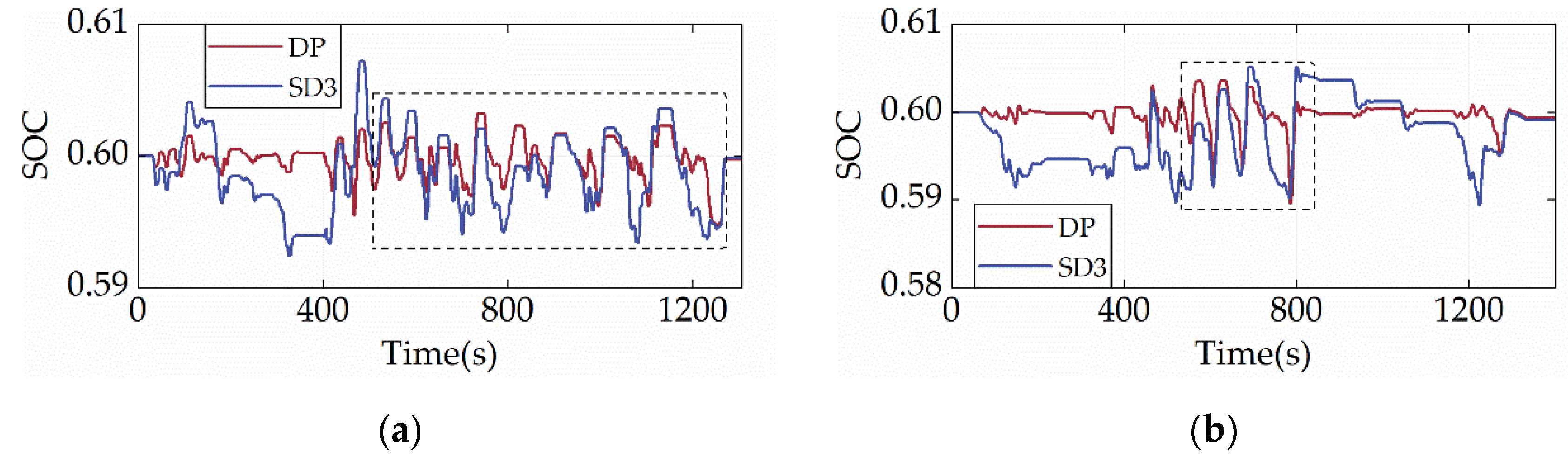
The analysis of terminal SOC convergence discussed above has been able to show that SD3 has a significant capacity for SOC maintenance. To further demonstrate the SOC planning capability of SD3, Figure 9 displays the SOC trajectories of SD3 and DP under two cycles. It is evident that the SD3′s battery does not exhibit overcharging or over-discharging, and the SOC can be tightly controlled to fluctuate only within a narrow range between 0.58 and 0.61. The battery can operate in the shallow cycle, and it is beneficial for improving the charge–discharge efficiency and reliability. Additionally, the SOC change trend of SD3 and DP are strikingly comparable in the boxed area of Figure 9, indicating that their charging and discharging rules are identical.
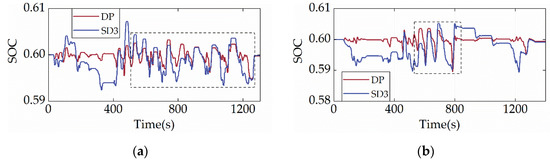
Figure 9.
SOC trajectories under different driving cycles. (a) CHTC-B; (b) WVUCITY.
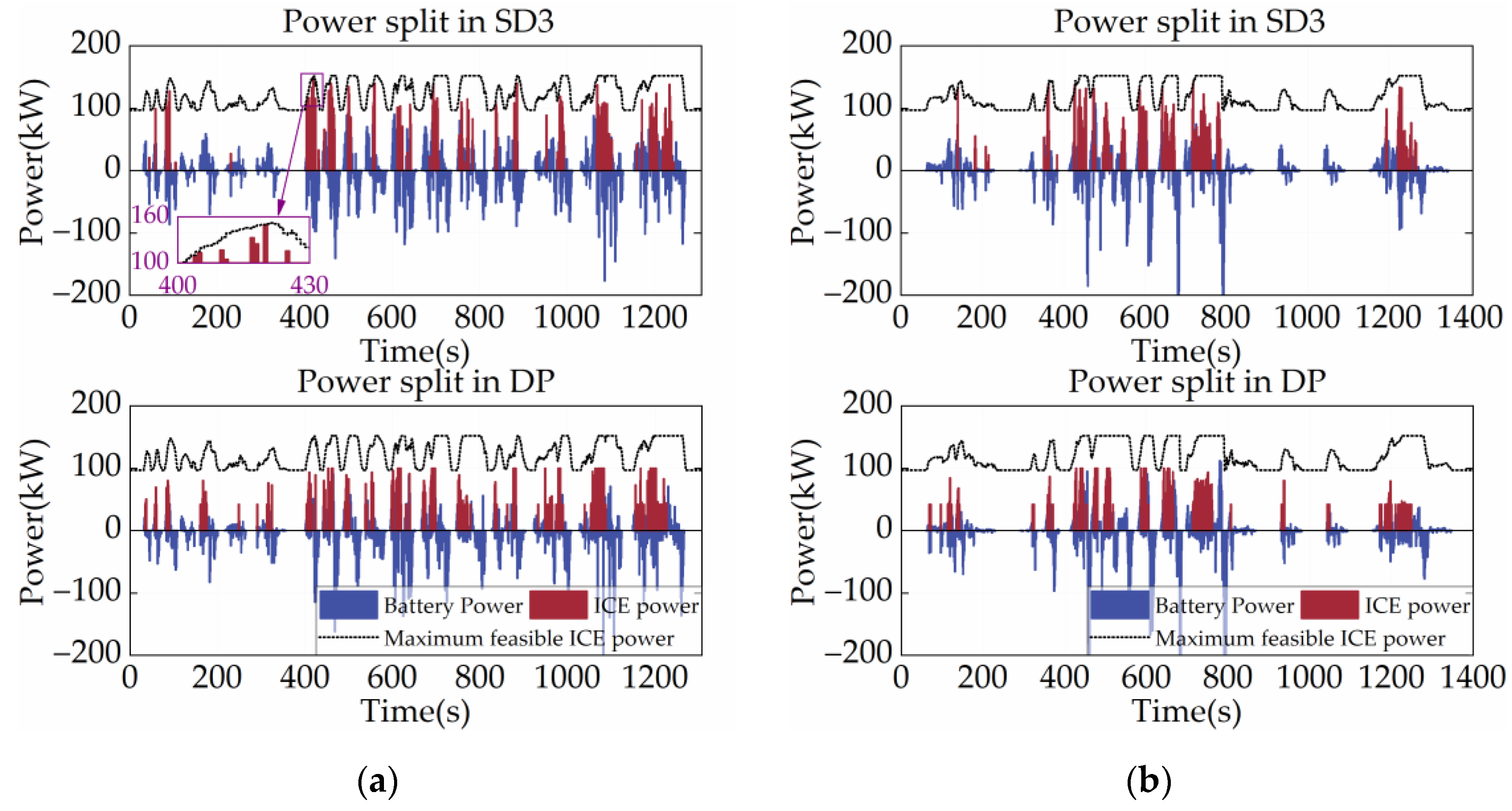
The power allocation of the power system can reflect the basic control logic of the strategy, including the operating mode switching logic and the engine control logic. Figure 10 shows the power split between the ICE and the battery and DP for SD3 under two cycles, with the black dotted lines in the figures representing the ICE’s maximum feasible power at each time step. As shown in Figure 10, the ICE power of SD3 is essentially not too low or too high, indicating that SD3 optimizes the operating point of the ICE by planning the energy allocation. This is because SD3 follows Bellman’s optimality theory and can plan for the entire driving cycle globally. Also, the SD3 tends to utilize more battery power when the vehicle is starting or moving at a low velocity. This control strategy is in line with engineering experience and contributes to the vehicle’s fuel economy. It is also noteworthy that the output power of the ICE never exceeds the maximum limit due to the filtering of the output action by SD3 using the AM technique, which demonstrates the excellent reliability of the proposed AM method.
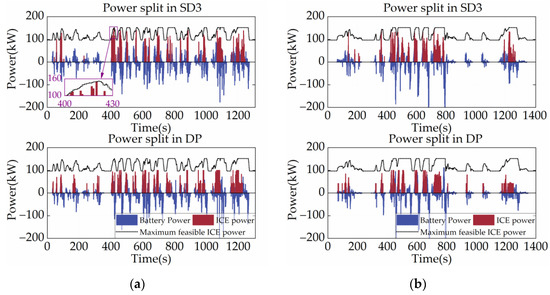
Figure 10.
Power allocation under different driving cycles. (a) CHTC-B; (b) WVUCITY.
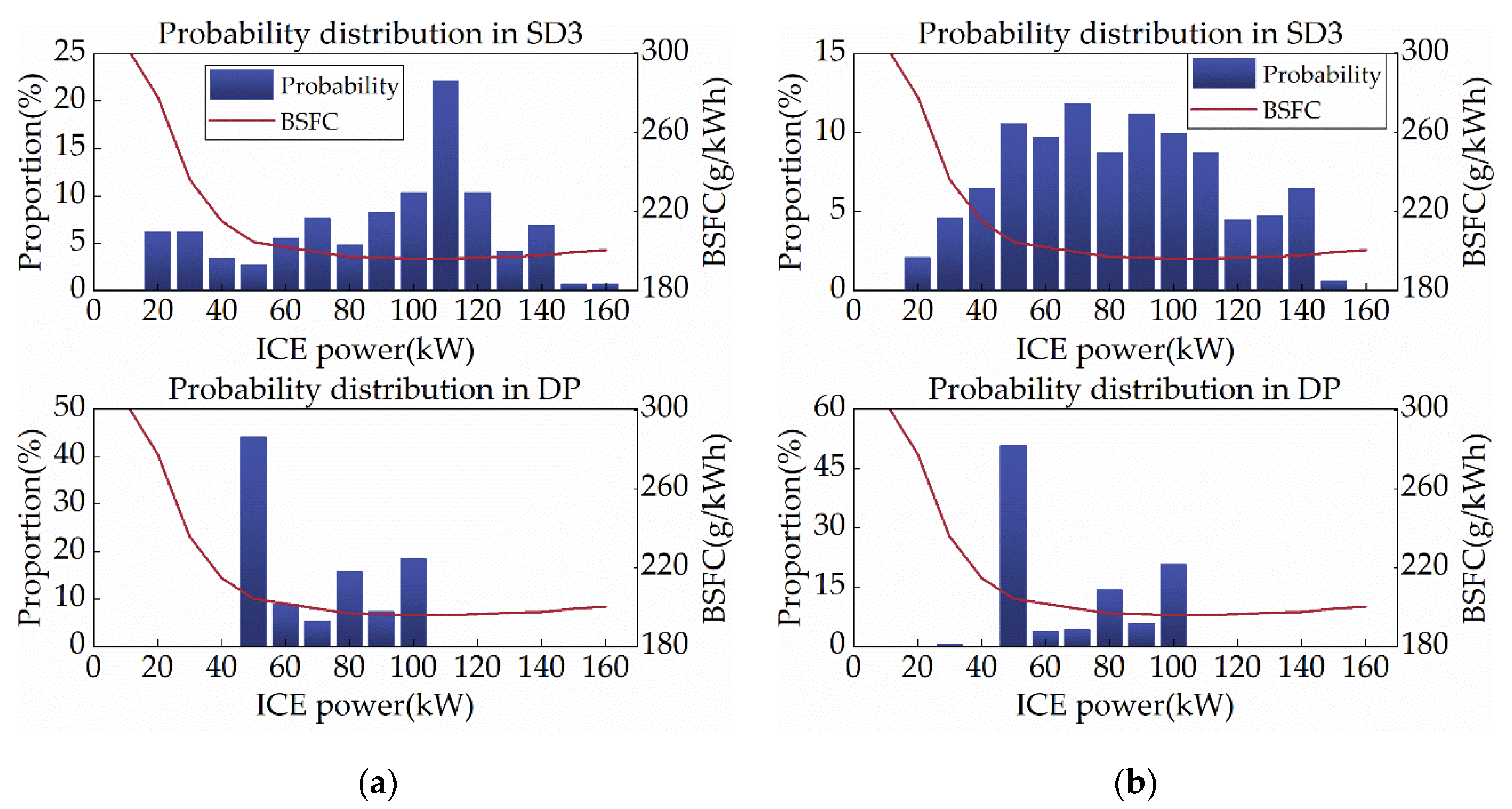
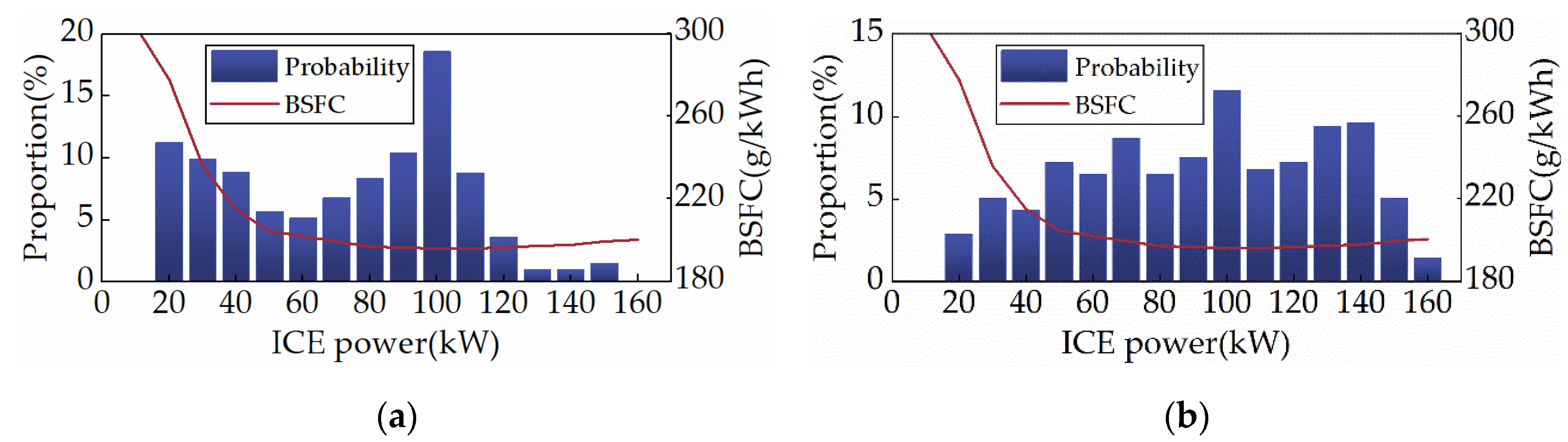
Since ICE is the primary target of this study’s energy optimization, the distribution of ICE operating points can impartially reflect SD3 performance. Corresponding to the optimal BSFC operating curve of the subject ICE, Figure 11 shows the ICE power distribution for SD3 and DP, with the red curve displaying the BSFC for each power. As depicted in Figure 11, the ICE power of SD3 is primarily spread between 100 and 120 kW under the CHTC-B cycle, whereas it is spread between 50 and 110 kW during the WVUCITY cycle. These intervals precisely match the low BSFC region of the object ICE, indicating that SD3 learns to improve the efficiency of ICE as much as possible. Statistics show that under the CHTC-B and WVUCITY cycles, the average BSFC of the ICEs of SD3 and DP are 205.64 g/kWh and 201.12 g/kWh, and 204.81 g/kWh and 201.54 g/kWh, respectively. It is evident that SD3 has very high fuel efficiency. Consequently, SD3 has a powerful ICE control performance, which will eventually be reflected in the vehicle’s fuel consumption.
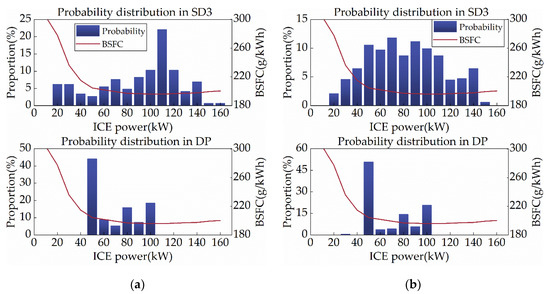
Figure 11.
ICE power distribution under different driving cycles. (a) CHTC-B; (b) WVUCITY.
Table 4 lists the fuel consumption of SD3 and DP under two driving cycles. The final SOC of different strategies is close to the initial value, and the deviation effect on fuel consumption is negligible. It can be seen that the fuel economy of the SD3 is comparable to that of the DP. Under the CHTC-B and WVUCITY cycles, the fuel consumption of SD3 is only 1.06% and 0.65% higher than that of DP, respectively. This indicates that the fuel economy of the proposed strategy is close to the global optimum.
Table 4.
Fuel consumption in simulation of initial SOC = 0.6.
4.2. Impact of Action Masking
The purpose of this section, which is an extension of the preceding section, is to compare the performance of SD3 with AM to SD3 without AM (SD3-AM for short) to examine the effect AM has on learning performance. The random seed for SD3 and SD3-AM is the same to assure the comparison’s fairness. It indicates that the initial weights of their neural networks are identical.
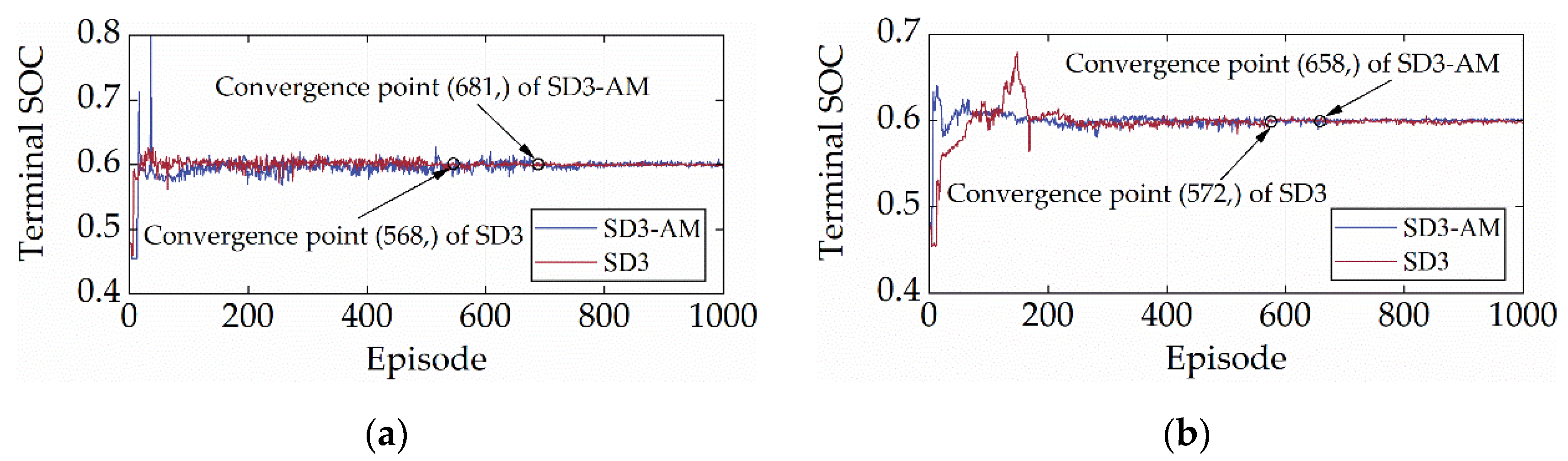
Figure 12 and Figure 13 display the reward and terminal SOC curves of SD3 and SD3-AM under two cycles, respectively. As illustrated in Figure 12 and Figure 13, the terminal SOC and reward values of SD3 and SD3-AM in the first episode are nearly identical, resulting from the identical random seeds used in both. In addition, Figure 12 shows that the reward curves for SD3 and SD3-AM after convergence overlap, which suggests that the maximum rewards they can earn are not much different. It also implies that AM does not impact the learning performance of SD3. Additionally, Figure 13 demonstrates that, under the CHTC-B and WVUCITY cycles, the convergence times of the terminal SOC of SD3 are 16.59% and 13.07% earlier than those of SD3-AM. It suggests that adding AM will considerably accelerate SD3′s learning rate. In conclusion, AM does not reduce SD3′s learning stability or speed. It is attributed to the fact that AM does not destroy the distribution of the environment, and thus does not violate the mathematical principles of SD3.
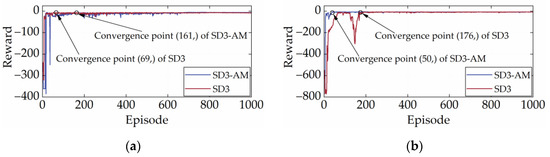
Figure 12.
Reward curve under different driving cycles. (a) CHTC-B; (b) WVUCITY.
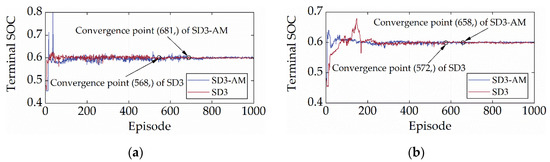
Figure 13.
Terminal SOC curves under different driving cycles. (a) CHTC-B; (b) WVUCITY.
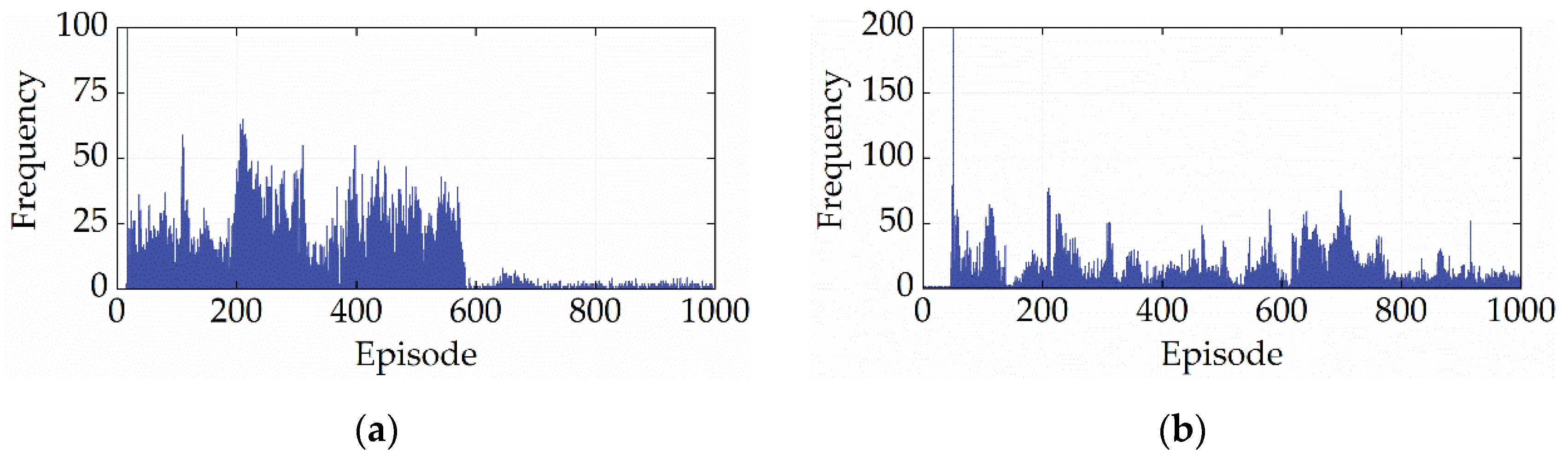
Figure 14 shows the number of invalid actions output by SD3-AM in each round during the learning process. From Figure 14, SD3-AM has difficulty avoiding outputting invalid actions. The first reason is that SD3-AM avoids falling into the local optimum by randomly exploring the entire action space, which puts the SD3 algorithm at risk of selecting invalid actions. The second reason is that SD3-AM will gradually master the highly-efficient control method for ICE during the learning process, i.e., controlling ICE to work in the low-BSFC region. However, the low BSFC corresponds to relatively high power, and the MG1 is easily overloaded when the powertrain system’s demand speed or demand torque is too high.
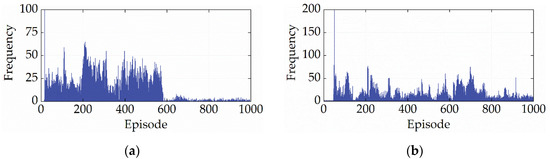
Figure 14.
The number of invalid actions. (a) CHTC-B; (b) WVUCITY.
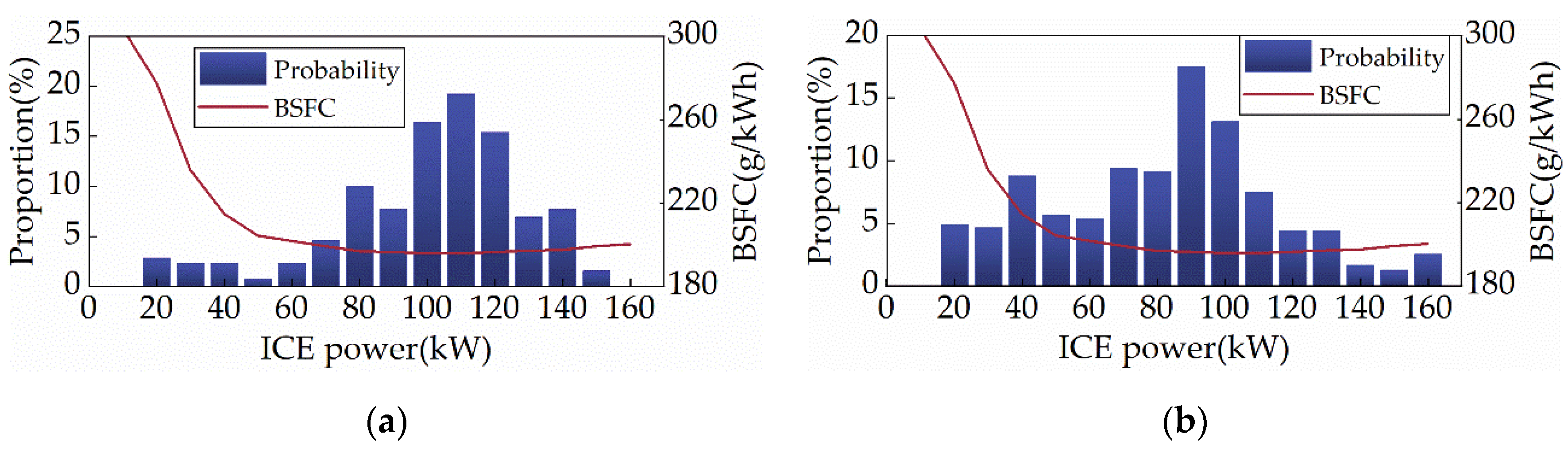
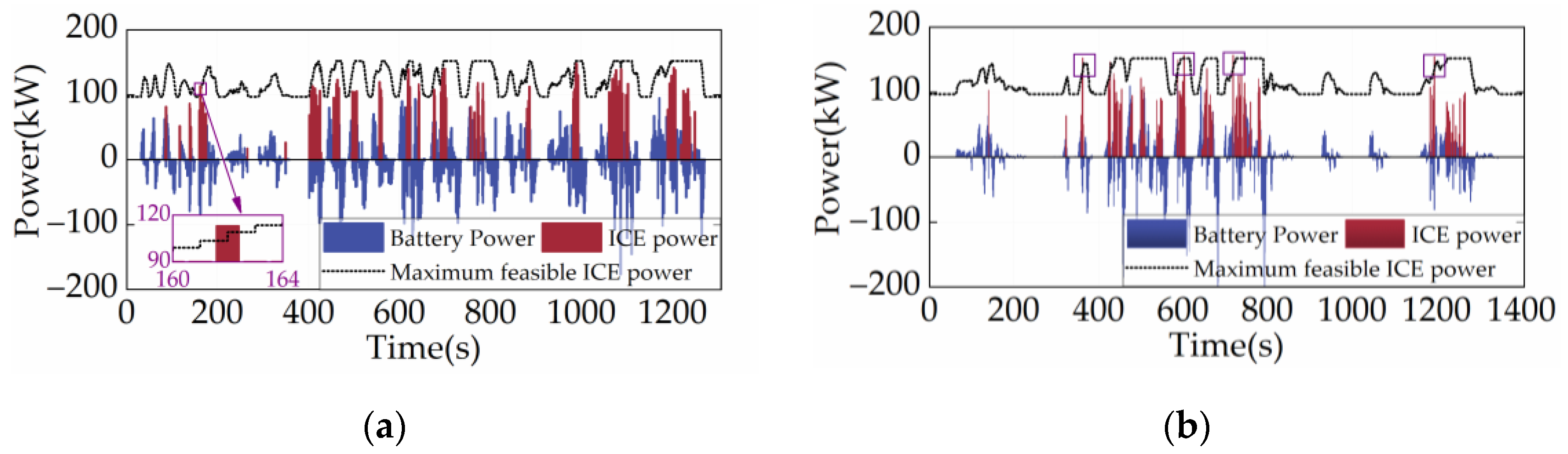
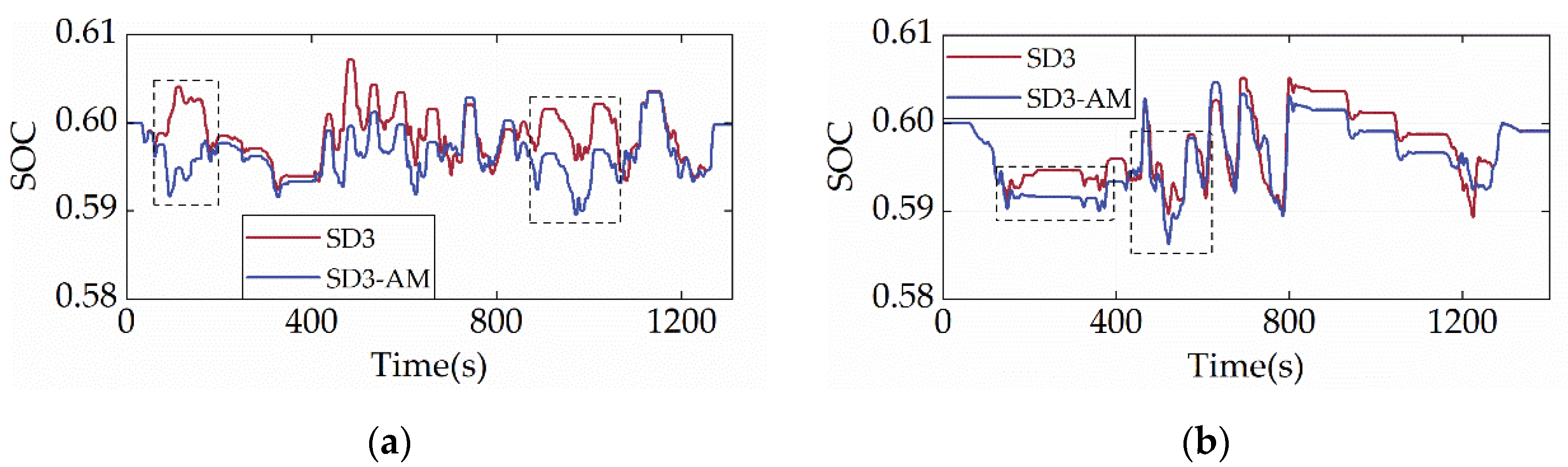
Figure 15, Figure 16 and Figure 17 depict the distribution of ICE power, the powertrain’s power allocation, and the SOC fluctuation of the SD3-AM under two cycles, respectively. Figure 15 shows that the ICE primarily operates in the region with the lowest BSFC, suggesting that the SD3-AM has exceptionally high fuel efficiency. However, Figure 16 reveals that the output power of the ICE exceeds the maximum feasible power several times, which should be categorically forbidden in engineering practice. As a result, shielding the invalid action is essential while aiming for the best fuel efficiency. Figure 17 illustrates that the SOC curves of SD3-AM and SD3 are different. Their differences are mainly in the smaller valley SOC of SD3-AM.
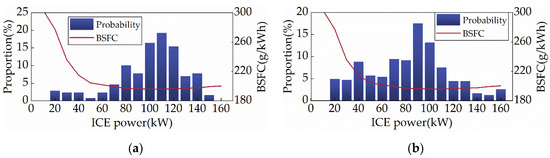
Figure 15.
ICE power distribution under different driving cycles. (a) CHTC-B; (b) WVUCITY.
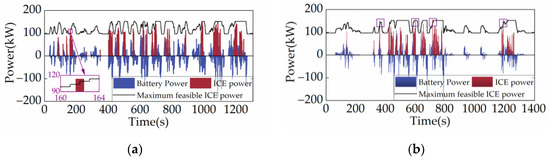
Figure 16.
Power allocation under different driving cycles. (a) CHTC-B; (b) WVUCITY.
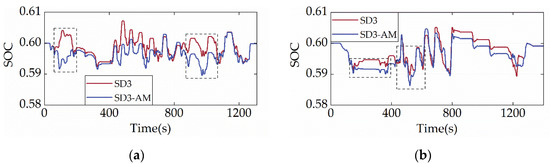
Figure 17.
SOC trajectories under different driving cycles. (a) CHTC-B; (b) WVUCITY.
In order to evaluate SD3-AM more objectively, simulation tests were also conducted in this study for DP without considering powertrain constraints (DP-AM for short). Table 5 lists the fuel consumption of SD3-AM and DP-AM. It is evident that the SD3-AM has excellent fuel efficiency and its fuel consumption differs very little from the DP-AM’s. Comparing Table 4 and Table 5, it is also evident that SD3-AM has a higher economy than SD3 and DP. Since SD3-AM does not consider the physical constraints of the powertrain, it can control the ICE to work more in the low-BSFC region (high power region), achieving lower fuel consumption. Even though AM impacts fuel economy, it ensures that the system’s power distribution is reliable, which is essential for engineering applications. Taken together, AM is a promising technology in DRL energy management.
Table 5.
Fuel consumption in simulation of initial SOC = 0.6.
4.3. Impact of Transfer Learning on SD3-Based Strategy
The primary purpose of this section is to explore the application of TL techniques in the SD3-based strategy (naming SD3 with TL techniques as SD3+TL ). Therefore, in this section, the network parameters of SD3+TL are initialized by the TL technique. That is, the CHTC-B cycle and the WVUCITY cycle are crossed as and . When the WVUCITY cycle is used as , the network initialization reuses the network parameters learned in CHTC-B and vice versa. Moreover, this section also implements the AM technique on SD3 to prevent unreasonable torque distribution in the system.
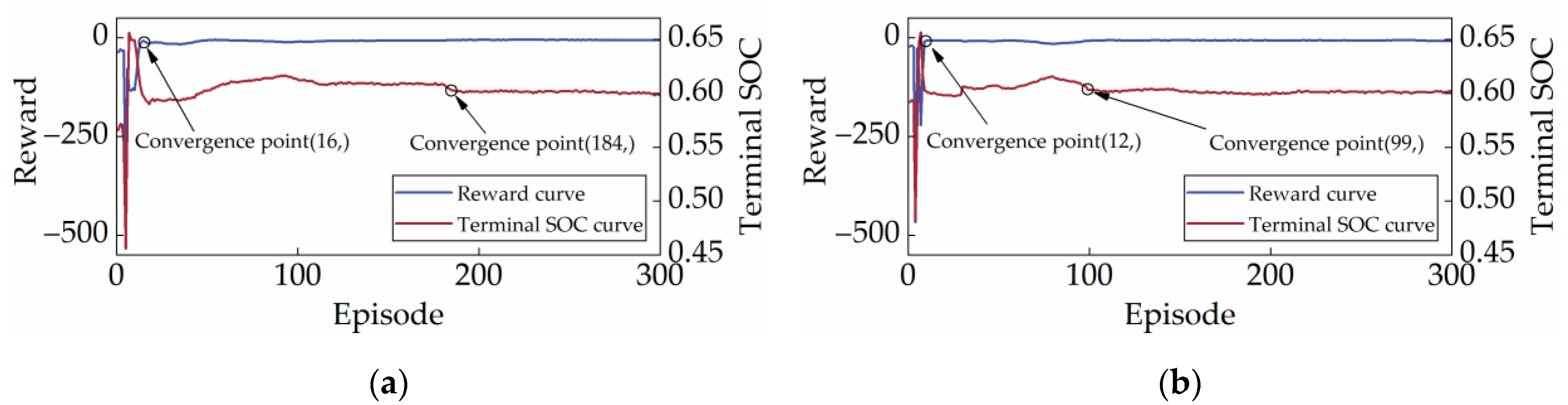
Figure 18 shows the reward and terminal SOC curve of SD3+TL under two cycles. By contrasting Figure 7, Figure 8 and Figure 18, it can be seen that SD3+TL and SD3 start to converge under the CHTC-B cycle after 184 and 568 episodes, respectively, while SD3+TL and SD3 start to converge under the WVUCITY cycle after 99 and 572 episodes, respectively. Obviously, TL can significantly improve the learning efficiency of strategies, with at least a 67.61% reduction in the learning time required for strategies.
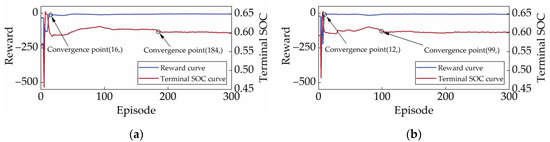
Figure 18.
Reward curves and terminal SOC curves under different driving cycles. (a) CHTC-B; (b) WVUCITY.
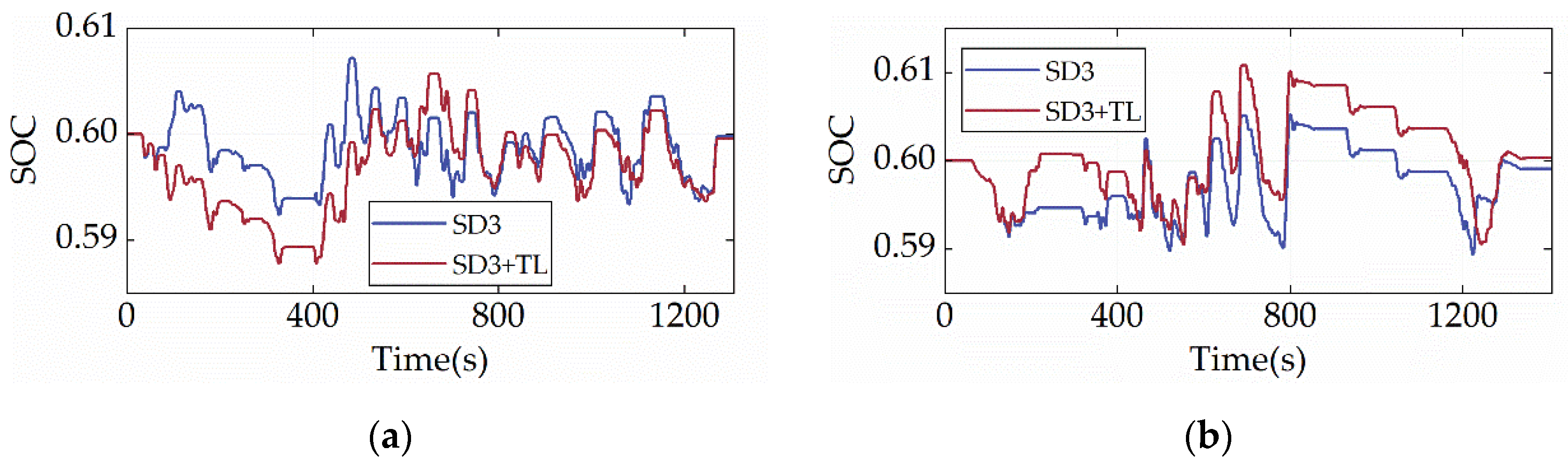
Figure 19 and Figure 20 show the SOC trajectory and ICE power distribution of SD3+TL under the two cycles, respectively. According to the results displayed in Figure 19, despite SD3+TL being injected with prior knowledge and frozen for prior knowledge before training, the overall trends of SOC for SD3+TL and SD3 are similar, with the main differences mainly in the first 400 s of the driving cycle. During this period, SD3+TL displays more charge depletion in the CHTC-B cycle and more charge sustenance in the WVUCITY cycle. Moreover, by comparing Figure 11 and Figure 19, it can be found that the ICE power distribution is similar for SD3 and SD3+TL, with both pieces of ICE mainly operating in the low-BSFC region, demonstrating that TL has no impact on the strategy’s overall learning direction. Table 6 compares the fuel economy of the SD3, DP, and SD3+TL. It can be discovered that SD3+TL is more economical than SD3 under the CHTC-B cycle and that its fuel consumption is only 0.05% greater than that of DP. Under the WVUCITY cycle, the economy of SD3+TL is just marginally worse than that of SD3, and its fuel usage is only 1.43% greater than that of DP. As a result, the TL has almost no impact on fuel economy while improving learning efficiency.
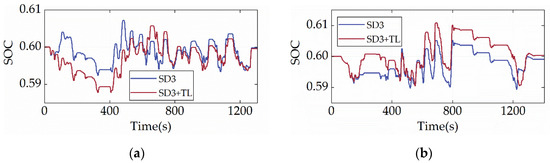
Figure 19.
SOC trajectories under different driving cycles. (a) CHTC-B; (b) WVUCITY.
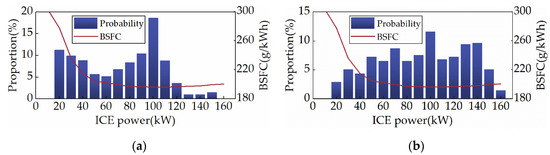
Figure 20.
ICE power distribution under different driving cycles. (a) CHTC-B; (b) WVUCITY.
Table 6.
Fuel consumption in simulation of initial SOC = 0.6.
5. Conclusions
This study develops a novel energy management strategy for HEUB using the state-of-the-art continuous control DRL algorithm, SD3. Additionally, the SD3 algorithm is improved by the proposed action masking method to prevent the torque allocation of the DRL control loop output that does not satisfy the physical constraints of the powertrain system. Meanwhile, the transfer learning technique’s application in developing DRL-based energy management strategies for HEUB is explored, enabling the rapid development of SD3-based strategies. Overall, the proposed strategy is proven to be effective in improving the fuel optimality of the reference HEUB. Furthermore, the following conclusions are obtained:
- The proposed AM technique can effectively filter invalid actions without affecting the learning performance or stability of SD3. Under the CHTC-B and WVUCITY cycles, SD3 with AM has a faster convergence speed than SD3 without AM, and its fuel economy can reach at least 98.94% of that of DP.
- The TL technique can considerably accelerate the learning rate of SD3. Under the CHTC-B and WVUCITY cycles, the learning time of SD3 with TL is at least 67.61% less than that of SD3 without TL. Moreover, TL has almost no impact on the final control performance and economic performance of SD3.
A systematic study of action masking methods for all DRL-based strategies will be carried out in future work. Also, prediction techniques, driving environment identification techniques, and transfer learning techniques will be combined to improve the adaptability of the proposed strategy.
Author Contributions
Conceptualization, K.W. and R.Y.; methodology, K.W.; software, K.W. and Y.Z.; validation, K.W. and Y.Z.; formal analysis, K.W. and R.Y.; investigation, K.W.; resources, W.H., R.Y. and S.Z.; data curation, K.W., R.Y. and Y.Z.; writing—original draft preparation, K.W.; writing—review and editing, R.Y., W.H. and Y.Z.; visualization, K.W., S.Z. and Y.Z.; supervision, R.Y. and W.H.; project administration, W.H.; funding acquisition, W.H., S.Z. and R.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Guangxi Science and Technology Plan (AA22068062), Guangxi Science and Technology Base and Talent Project (2018AD19349), and Guangxi Innovation Driven Development Project (AA18242045-3).
Acknowledgments
Any opinions expressed in this paper are solely those of the authors and do not represent those of the sponsors. The authors would like to thank all the reviewers who participated in the review.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, Y.; Jiao, X. Dual Heuristic Dynamic Programming Based Energy Management Control for Hybrid Electric Vehicles. Energies 2022, 15, 3235. [Google Scholar] [CrossRef]
- Li, X.; Evangelou, S. Torque-leveling threshold-changing rule-based control for parallel hybrid electric vehicles. IEEE Trans. Veh. Technol. 2019, 68, 6509–6523. [Google Scholar] [CrossRef]
- Shi, D.; Liu, S.; Cai, Y.; Wang, S.; Li, H.; Chen, L. Pontryagin’s minimum principle based fuzzy adaptive energy management for hybrid electric vehicle using real-time traffic information. Appl. Energy 2021, 286, 116467. [Google Scholar] [CrossRef]
- Lin, C.; Peng, H.; Grizzle, J.; Kang, J. Power management strategy for a parallel hybrid electric truck. IEEE Trans. Control Syst. Technol. 2003, 11, 839–849. [Google Scholar]
- Liu, T.; Hu, X.; Hu, W.; Zou, Y. A Heuristic Planning Reinforcement Learning-Based Energy Management for Power-Split Plug-in Hybrid Electric Vehicles. IEEE Trans. Ind. Inform. 2019, 15, 6436–6445. [Google Scholar] [CrossRef]
- Tian, X.; He, R.; Sun, X.; Cai, Y.; Xu, Y. An ANFIS-based ECMS for energy optimization of parallel hybrid electric bus. IEEE Trans. Veh. Technol. 2020, 69, 1473–1483. [Google Scholar] [CrossRef]
- Yuan, H.; Zou, W.; Jung, S.; Kim, Y. Optimized rule-based energy management for a polymer electrolyte membrane fuel cell/battery hybrid power system using a genetic algorithm. Int. J. Hydrogen Energy 2022, 47, 7932–7948. [Google Scholar] [CrossRef]
- Zhou, S.; Liu, X.; Hua, Y.; Zhou, X.; Yang, S. Adaptive model parameter identification for lithium-ion batteries based on improved coupling hybrid adaptive particle swarm optimization-simulated annealing method. J. Power Sources 2021, 482, 228951. [Google Scholar] [CrossRef]
- Du, C.; Huang, S.; Jiang, Y.; Wu, D.; Li, Y. Optimization of Energy Management Strategy for Fuel Cell Hybrid Electric Vehicles Based on Dynamic Programming. Energies 2022, 15, 4325. [Google Scholar] [CrossRef]
- Li, L.; Yang, C.; Zhang, Y.; Zhang, L.; Song, J. Correctional DP-based energy management strategy of plug-in hybrid electric bus for city-bus route. IEEE Trans. Veh. Technol. 2014, 64, 2792–2803. [Google Scholar] [CrossRef]
- Paganelli, G.; Guerra, T.; Delprat, S.; Santin, J.; Delhom, M.; Combes, E. Simulation and assessment of power control strategies for a parallel hybrid car. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2000, 214, 705–717. [Google Scholar] [CrossRef]
- Musardo, C.; Rizzoni, G.; Staccia, B. A-ECMS: An adaptive algorithm for hybrid electric vehicle energy management. Eur. J. Control 2005, 11, 509–524. [Google Scholar] [CrossRef]
- Yang, X.; Yang, R.; Tan, S.; Yu, X.; Fang, L. MPGA-based-ECMS for energy optimization of a hybrid electric city bus with dual planetary gear. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2022, 236, 1889–1909. [Google Scholar] [CrossRef]
- Yang, R.; Yang, X.; Huang, W.; Zhang, S. Energy management of the power-split hybrid electric city bus based on the stochastic model predictive control. IEEE Access. 2020, 9, 2055–2071. [Google Scholar] [CrossRef]
- Zhang, H.; Peng, J.; Tan, H.; Dong, H.; Ding, F. A deep reinforcement learning-based energy management framework with lagrangian relaxation for plug-in hybrid electric vehicle. IEEE Trans. Transp. Electrif. 2021, 7, 1146–1160. [Google Scholar] [CrossRef]
- Zhou, Q.; Zhao, D.; Shuai, B.; Li, Y.; Williams, H.; Xu, H. Knowledge implementation and transfer with an adaptive learning network for real-time power management of the plug-in hybrid vehicle. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 5298–5308. [Google Scholar] [CrossRef]
- He, H.; Wang, Y.; Li, J.; Dou, J.; Lian, R.; Li, Y. An improved energy management strategy for hybrid electric vehicles integrating multistates of vehicle-traffic information. IEEE Trans. Transp. Electrif. 2021, 7, 1161–1172. [Google Scholar] [CrossRef]
- Liu, T.; Tan, W.; Tang, X.; Zhang, J.; Xing, Y.; Cao, D. Driving conditions-driven energy management strategies for hybrid electric vehicles: A review. Renew. Sust. Energ. Rev. 2021, 151, 111521. [Google Scholar] [CrossRef]
- Wang, K.; Yang, R.; Huang, W.; Mo, J.; Zhang, S. Deep reinforcement learning-based energy management strategies for energy-efficient driving of hybrid electric buses. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2022. [Google Scholar] [CrossRef]
- Wu, J.; He, H.; Peng, J.; Li, Y.; Li, Z. Continuous reinforcement learning of energy management with deep Q network for a power split hybrid electric bus. Appl. Energy 2018, 222, 799–811. [Google Scholar] [CrossRef]
- Han, X.; He, H.; Wu, J.; Peng, J.; Li, Y. Energy management based on reinforcement learning with double deep Q-learning for a hybrid electric tracked vehicle. Appl. Energy 2019, 254, 113708. [Google Scholar] [CrossRef]
- Qi, X.; Luo, Y.; Wu, G.; Boriboonsomsin, K.; Barth, M. Deep reinforcement learning enabled self-learning control for energy efficient driving. Transp. Res. Part C Emerg. Technol. 2019, 99, 67–81. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.; Veness, J.; Bellemare, M.; Graves, A.; Riedmiller, M.; Fidjeland, A.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Lian, R.; Peng, J.; Wu, Y.; Tan, H.; Zhang, H. Rule-interposing deep reinforcement learning based energy management strategy for power-split hybrid electric vehicle. Energy 2020, 197, 117297. [Google Scholar] [CrossRef]
- Liessner, R.; Schmitt, J.; Dietermann, A.; Baker, B. Hyperparameter optimization for deep reinforcement learning in vehicle energy management. In Proceedings of the 11th International Conference on Agents and Artificial Intelligence, Prague, Czech Republic, 19–21 February 2019; pp. 134–144. [Google Scholar]
- Zhang, S.; Wang, K.; Yang, R.; Huang, W. Research on energy management strategy for hybrid electric bus based on deep reinforcement learning. Chin. Intern. Combust. Engine Eng. 2021, 42, 10–16. [Google Scholar]
- Xiao, B.; Yang, W.; Wu, J.; Walker, P.; Zhang, N. Energy management strategy via maximum entropy reinforcement learning for an extended range logistics vehicle. Energy 2022, 253, 124105. [Google Scholar] [CrossRef]
- Wang, Y.; Tan, H.; Wu, Y.; Peng, J. Hybrid electric vehicle energy management with computer vision and deep reinforcement learning. IEEE Trans. Ind. Inform. 2020, 17, 3857–3868. [Google Scholar] [CrossRef]
- Li, Y.; He, H.; Peng, J.; Wang, H. Deep reinforcement learning-based energy management for a series hybrid electric vehicle enabled by history cumulative trip information. IEEE Trans. Veh. Technol. 2019, 68, 7416–7430. [Google Scholar] [CrossRef]
- Zhou, J.; Xue, S.; Xue, Y.; Liao, Y.; Liu, J.; Zhao, W. A novel energy management strategy of hybrid electric vehicle via an improved TD3 deep reinforcement learning. Energy 2021, 224, 120118. [Google Scholar] [CrossRef]
- Wu, J.; Wei, Z.; Li, W.; Wang, Y.; Li, Y.; Sauer, D. Battery thermal-and health-constrained energy management for hybrid electric bus based on soft actor-critic DRL algorithm. IEEE Trans. Ind. Inform. 2020, 17, 3751–3761. [Google Scholar] [CrossRef]
- Pan, L.; Cai, Q.; Huang, L. Softmax deep double deterministic policy gradients. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 5–12 December 2020; pp. 11767–11777. [Google Scholar]
- He, H.; Huang, R.; Meng, X.; Zhao, X.; Wang, Y.; Li, M. A novel hierarchical predictive energy management strategy for plug-in hybrid electric bus combined with deep deterministic policy gradient. J. Energy Storag. 2022, 52, 104787. [Google Scholar] [CrossRef]
- Li, M.; Yan, M.; He, H.; Peng, J. Data-driven predictive energy management and emission optimization for hybrid electric buses considering speed and passengers prediction. J. CLean. Prod. 2021, 304, 127139. [Google Scholar] [CrossRef]
- De Santis, M.; Agnelli, S.; Patanè, F.; Giannini, O.; Bella, G. Experimental Study for the Assessment of the Measurement Uncertainty Associated with Electric Powertrain Efficiency Using the Back-to-Back Direct Method. Energies 2018, 11, 3536. [Google Scholar] [CrossRef]
- Li, M.; He, H.; Feng, L.; Chen, Y.; Yan, M. Hierarchical predictive energy management of hybrid electric buses based on driver information. J. Clean. Prod. 2020, 269, 122374. [Google Scholar] [CrossRef]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Hasselt, H. Double q-learning. In Proceedings of the Advances in Neural Information Processing Systems 23: 24th Annual Conference on Neural Information Processing Systems 2010, Vancouver, BC, Canada, 6–9 December 2010; pp. 2613–2621. [Google Scholar]
- Xu, D.; Cui, Y.; Ye, J.; Cha, S.; Li, A.; Zheng, C. A soft actor-critic-based energy management strategy for electric vehicles with hybrid energy storage systems. J. Power Sources 2022, 524, 231099. [Google Scholar] [CrossRef]
- Lu, C.; Hu, F.; Cao, D.; Gong, J.; Xing, Y.; Li, Z. Virtual-to-real knowledge transfer for driving behavior recognition: Framework and a case study. IEEE Trans. Veh. Technol. 2019, 68, 6391–6402. [Google Scholar] [CrossRef]
- Lu, C.; Hu, F.; Cao, D.; Gong, J.; Xing, Y.; Li, Z. Transfer learning for driver model adaptation in lane-changing scenarios using manifold alignment. IEEE Trans. Intell. Transp. Syst. 2019, 21, 3281–3293. [Google Scholar] [CrossRef]
- Wang, Y.; Zeng, X.; Song, D.; Yang, N. Optimal rule design methodology for energy management strategy of a power-split hybrid electric bus. Energy 2019, 185, 1086–1099. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).