1. Introduction—Review of the Problem and the Scope
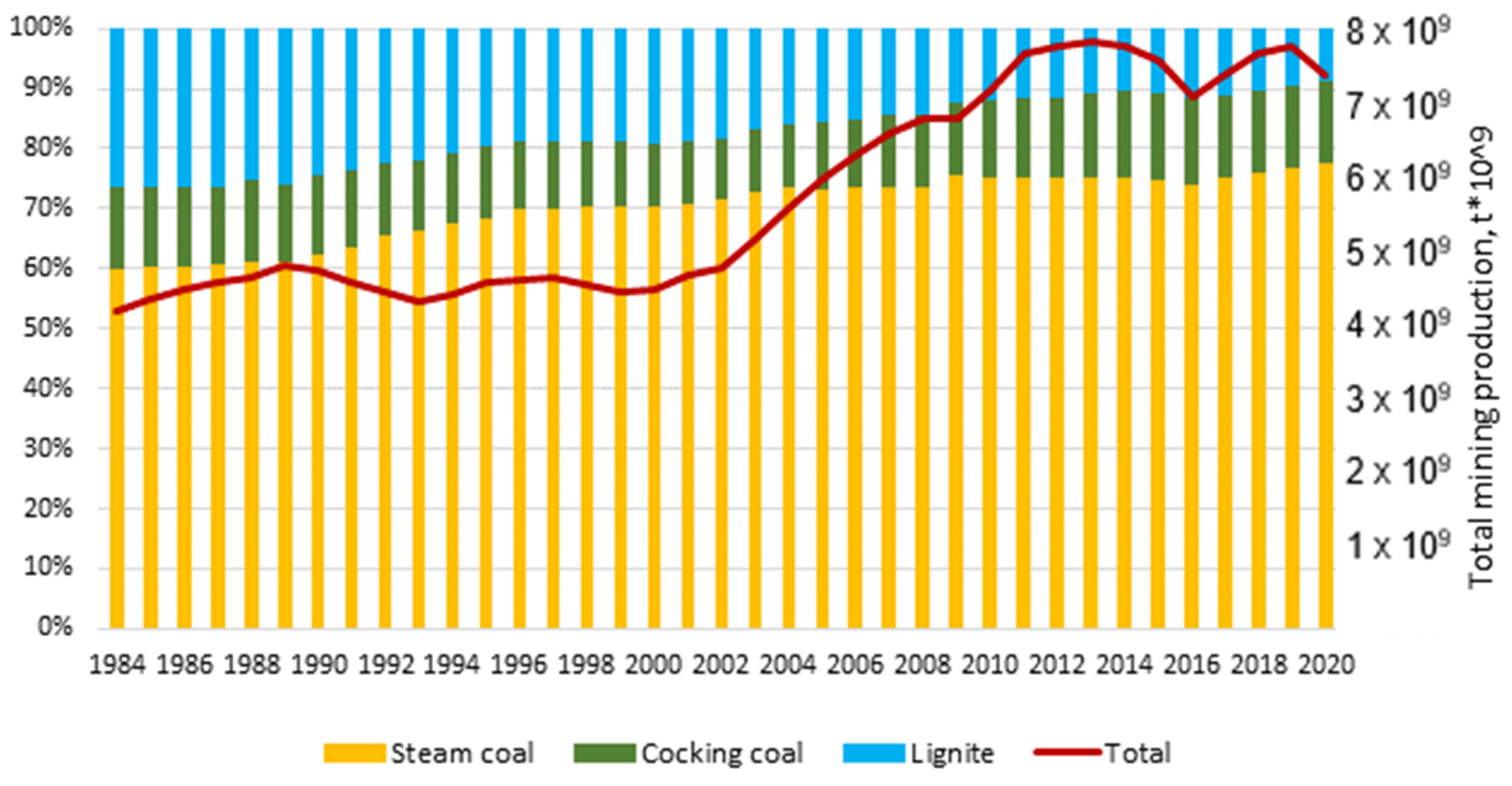
Practical utilization of coal is connected with many industrial branches. Excluding aggregates, coal is the raw material with the highest volume of mining production, reaching globally nearly 7 billion (10
9) tons annually (
Figure 1). It is also a primary energy raw material with strategic meaning, despite global trends aiming at adopting more environmentally friendly methods of energy production.
It should also be pointed out that world coal consumption can be described as a steady but increasing trend, analyzing the time period of the recent four decades. This is also linked with a number of various research projects on coal and a number of scientific publications, as mentioned in the following section.
Figure 1 presents the trend of the world production of coal over the last four decades.
New directions of investigations on coal are being carried out, including the development of new technologies and procedures that help in decreasing the emission of CO
2 and other gas and particulate matter pollutants. In fact, contemporary scientific investigations on coal are strictly related to the entire value chain of coal production, especially with issues of coal acquisition, problems of processing technology and aspects of its industrial utilization. Current trends in coal research also have their reflection in focusing on environmental aspects, including the above-mentioned problems of the emission of gas and dust pollutants, but not limited to the other pending problems, such as logistics and supply limitations [
2,
3,
4]. Social and economic aspects are also present among the pressing problems concerning the topic [
5]. In summary, the following general topics in coal research can be distinguished.
Mining activities, starting from geological investigations, deposit characterization and a variety of geotechnical problems, through to mine operation including a wide range of safety aspects, production effectiveness, process control and operations indirectly connected to the mine production system.
- -
Technology of upgrading coal, including preparatory operations and mechanical processing as well as coal beneficiation processes, together with new technologies aiming at the improvement of the qualitative properties of final products;
- -
Industrial and commercial utilization of coal, with low-emission combustion technologies, improving the energetic and economic effect of coal consumption;
- -
Environmental aspects that appear during the entire life cycle of coal;
- -
Economic issues.
It is worthwhile to note that the above topics are thematically intertwined and often cannot be analyzed separately, especially in more strategic investigations and projects. Therefore, there is always room for creating a new direction of research or more detailed development of the existing topics. Models related to coal research are in fact present in each of the above directions, but they differ significantly depending on their utilization area, methodological bases, mathematical apparatus used and the purpose.
Coal modeling for the purpose of this paper is understood as an approach that uses any kind of simulation, approximation, optimization, prediction and other evaluating procedures and tools correlated to coal in general. From a technical point of view, models very often use mathematical apparatus for the determination and description of a specific phenomenon, process or action, but a variety of descriptive models based on expert opinions and interactions, i.e., Delphi models and the AHP process [
6], also exist. There are various classifications of general models and models dedicated to a specific topic, such as coal, regarding the area, time, technology and point in the coal value chain and many others. The authors’ intention was not to limit the scope to specific types of models but to take into consideration all records connected with coal and modeling approaches.
Coal modeling in the stage of mining activities may concern very general and fundamental issues, such as mine operation, the estimation of mine servicing time, quality of raw material and others [
7,
8,
9]. Geological investigations in underground coal mines show geotechnical models based on numerical analysis, a probabilistic approach and statistical analysis that characterize the stability of the rock mass [
10,
11,
12,
13]. Simulation models that control the flow of gas and particle mattes in underground mines are useful for improving the operation of ventilation systems and for contaminant removal. Developments of these models are possible through the utilization of computational fluid dynamic (CFD) tools, regression techniques and machine learning [
14,
15,
16].
Coal processing technology is a field with many opportunities for the application of both simulation and optimization models. Simulation models based on the discrete elements method (DEM) and the mentioned CFD may bring a detailed description of the feed material behavior during the process in a device, which helps in the design of more effective machines [
17,
18,
19,
20,
21], while the results of coal beneficiation in separation processes can be modeled by means of mathematical programming theory, regression models, neural networks and genetic algorithms [
22,
23,
24].
Industrial utilization of coal mostly concerns investigations into obtaining an optimal amount of energy from the combustion of the raw material, together with the neutralization or at least limitation of the major drawbacks of coal fuel use, such as the emission of toxic gases, ashes and slags and increasing the greenhouse effect. Research on the development of more effective, environmentally and economic friendly technologies also has a reflection in contemporary science concerning the issue [
25,
26,
27,
28,
29,
30,
31]. These investigative projects combine various disciplines, such as chemistry, physics, material sciences and engineering areas. The thermal conversion of mixtures, i.e., coal–water (or coal–other medium), heat transfer, kinetics and other chemical or thermodynamic problems are covered [
32,
33,
34,
35]. Mathematical models are very popular within this topic, but numerical modeling, simulations and predictions are also among the utilized tools and methods [
36,
37,
38].
Environmental aspects of coal modeling and the coal itself were always a significant interest of researchers. The issue has gained even more importance as a result of higher environmental awareness in society, but also due to the ratification of various international agreements aiming at carbon emission reduction, greenhouse effect limitation and a general effort for the improvement of societies’ quality of life. Coal extraction causes a number of hydrological consequences [
39,
40,
41,
42] and is a source of a significant amount of waste materials that interact with the environment, causing increased erosion, acid drainage and concentration of dissolved soils [
43]. Models concerning the reduction of carbon emission in general and through a specific design of the mining process are also applied [
44]. Mathematical modeling and simulations are widely used here, but also statistical and predictive models are also in use [
45,
46,
47,
48].
Economic models on coal concern the supply–demand balance, as well as supporting the decision-making in the rational planning of the development of an industry, more usually at a microeconomic scale [
49,
50]. Such models help in analysis through the development of general scenarios of sector growth, as well as forecasting the coal demands through the estimation of the required energy governance and consumption, considering different scenarios. Simulation and optimization models are developed, utilizing, among others, a theory of mathematical programming and auto-regression [
51,
52,
53,
54]
There are also publications presenting the results of a bibliometric analysis carried out in the field of coal, but they focus either on selective aspects, a limited time period or a narrower area, i.e., domestic industry [
55,
56,
57], and that needs updating and expansion due to the increased number of publications issued in recent years (
Figure 2). Bibliometric analyses are becoming popular methods of measuring impact for scientific publications on the specific topic [
58,
59]. Authors are aware, however, that the bibliometric analysis of investigations on coal appears a huge and challenging task. The multithreading of the topic that appeared during investigations made it impossible to analyze all significant findings in a manner concise enough to include it in a single paper. It also appeared that selected problems were so complex that it was not possible to find relevant conclusions without using more advanced tools than those built into a specific database. The problems concerned especially the analysis of cooperation and the merit content through authors’ and editors’ key words, as well as the cluster analysis. Therefore, minor simplifications to the issue were applied, and the authors decided to analyze publications registered only in one scientific database (the Web of Science database).
In summary, the main aim of analysis presented in the paper sis to address the following questions:
- -
What is the status of international collaboration within the topic?
- -
In what directions can research on coal modeling evolve?
- -
How are the publications clustered?
- -
What areas are dominant in investigations?
Taking into account the above-mentioned issues, as well as the fact that the number of publications concerning coal grows year by year (
Figure 2), it was assumed that the existing research within this area needed expansion and updating. Therefore, the general purpose of this comprehensive bibliometric analysis was to identify research patterns and trends in the scientific literature on coal modeling. The authors have tried to identify these patterns and trends through selected aspects, characterized in the following sections. Bibliometric analysis is a popular method of exploring and analyzing large amounts of scientific data that enables a comprehensive review of the literature in a selected field, identifying knowledge gaps, generating new research ideas and positioning the intended contribution of scientists to the field in question [
60,
61,
62].
There is a general agreement between researchers that research quality cannot be characterized by a single element, especially when more detailed conclusions are expected to be drawn. Single metrics are of course helpful, but a particular indicator or index may fail to capture some significant and different aspects concerning the specific research or investigative program [
63]. A variety of indicators can be used in the assessment of scientific research, and for the purposes of this paper, the following types of metrics were used:
Metrics of productivity, including the number of research works in cooperation, number of publications, number of institutions involved, and others. These characteristics can be also refer to the time period or specific year;
Metrics of impact, showing productivity metrics related to a specific author, institution, publication, country, year or others;
Hybrid metrics, combining various measures, such as the number of publications/citations/cooperations per affiliation/country/author. This group of measures captures both the productivity and impact of a specific item in a single number or figure. They can refer to the same or different research areas [
64,
65]. This group of metrics is also associated with the Hirsch index [
66,
67].
The above metrics can be also generated from different points of view, i.e., for individual (or a group of) journals, editors, institutions, countries, authors, types of documents and many others. A significant number of the obtained indices as a result in such a way may be confusing in the analysis, especially given that some metrics can be correlated between each other. In addition, a bibliometric analysis of key words or research areas can be confusing for the reason that too many searching outcomes can be obtained, sometimes with similar or even doubled meanings. Cluster analysis can be a good solution in such cases, because the results can be partitioned into clusters that contain words, phrases or metrics that are mutually strongly correlated. Clustering can be performed with the use of various methodologies and can be performed using of specific tools and software, such as CiteSpace. The LSI method (Latent Semantic Indexing) groups the outcomes (words or phrases) according to the main keyword, and results in each group are semantically relevant. The terms are also ranked using different algorithms, such as LLR (log-likelihood ratio) and MI (mutual information) [
68].
Detailed characteristics of the methodology and procedures used in the data collection and analyses are characterized in
Section 2.
2. Materials and Methods
The presented analysis was carried out according to the following steps.
Step 1: Study of the problem (selection of the searching phrase, selection of scientific database, selection of searching options for the key word, selection of the time period);
Step 2: Data collection (collection of data from the database, screening of the results, exporting the final list to external file in Excel format, export of the final list into dedicated software);
Step 3: Bibliometric analysis (presentation of selected descriptive statistics, mapping the networks of cooperation, merit content analysis);
Step 4: Discussion of results and remarks.
The selection criteria in step 1 were defined as a combination of two words: “coal” and “modeling”. These two words were combined with the “AND” operator in the searching option in order to narrow down the searching area only to records related to coal and covering the aspects of modeling. The word “modeling”, according to British English spelling, was selected. We used the “all field” option in searching for the term “coal” AND “modeling”, which means the phrase was searched in the title, abstract and keywords. It was also decided that all types of publications would be used. The timespan was preliminarily set as “all years” (default from 1900 ongoing), but it appeared that the first publication registered in the database was published in 1951. The authors also wanted to finish the list with a full year; therefore, the timespan was finally set as 1951–2021.
As mentioned in
Section 1, the Web of Science database was selected, and the core collection option was used. According to the authors’ opinion, both WoS and SCOPUS are equal regarding the quality of presented papers, and most publications that are indexed in SCOPUS are also present in WoS. Preliminary analysis confirmed that only a minor percentage of obtained records was different in each database, and both sources can in fact be used to complete satisfactory searching results. Among the minor advantages of WoS could be the fact that an insignificantly higher percentage of publications registered in it has the granted IF index compared with the SCOPUS database. This factor is very popular for the quantification of top-quality publications. A major drawback of WoS, however, is connected with technical issues of data gathering. There are limitations in the maximum number of records that can be downloaded from the database in a single file; therefore, the export had to be executed in several files, which were then bound together. This caused some problems, especially when the searching data were exported to the external software CiteSpace for use in further analyses. Up to 1000 records could be exported at a time; therefore, the completion of the overall input file consumed a considerable amount of time.
These restrictions were established to protect the the WoS data from excessive and automatic data copying and downloading, and advanced analyses were carried out by utilizing the InCites tool. This professional bibliometric software (CiteSpace 6.1), created by SourceForge (San Diego, CA, USA), was used mainly for in-depth analyses of key words, cooperation and clusters. This tool provides professional evaluations of patterns and trends in scientific literature and is utilized worldwide by academic and non-academic researchers. The software helps to address questions such as the following: what are major research areas connected to data, what are main connections between these areas, which areas are more active and more productive, which are key papers (key institutions, authors, countries) related to the problem/area and others. This tool enables the researcher to detect and track the knowledge on a certain topic and visualize networks of topic words and titles, collaborations and clustering. The specific organization of data makes it possible to follow the changes in the structures of collaboration, which are under constant modification over time. The work of Chen [
69] was one of the initial publications concerning the problem, but many other examples of publications can be found as developed versions of the CiteSpace software were released [
70,
71,
72].
The raw data for analysis were obtained from the Web of Science database. The Web of Science Core Collection database was selected, and the primary searching criterion was set as “COAL & MODELING”. We chose the all-fields option in the searched documents, and the analyzed period included the years 1951–2021. The searching was performed on 24 February 2022.
Table 1 summarizes the preliminary characteristics of the searching procedure.
After the preliminary screening of the searching results, the final list was exported to an external Excel file. Separate files had to be exported manually each time for a selected criterion. The following criteria were used in the preparation of the searching results.
Year,
WoS category,
Type of documents,
Affiliation,
Title (journal),
Publisher,
Research area,
Funding agency,
Country.
3. Results and Analysis
As many as 53,372 records in total were returned after searching the WoS database. The phrase “COAL” itself returned 230,946 records, while the term “MODELING” returned 10,773,552. The obtained records were analyzed according to cooperation, authors’ and editors’ key words as well as clustering. Overall characteristics are provided in
Table 2.
The numbers of years do not match the used timespan (1951–2021), for the reason that no publications were registered in the following years: 1952–53, 1958, 1961–65 and 1967. Some records appeared incomplete, as selected details in some categories were not provided.
Table 3 below summarizes identified cases.
Incomplete records in the category funding agency do not mean that a file is corrupted, but it rather indicates that a publication was not financed through a dedicated project or entity. Therefore, these records were not considered as corrupted. Special attention was paid to the WoS categories. Certain categories were connected with medicine, humanistic sciences and other different areas (i.e., philosophy, religion, psychology, language sciences). In total, 95 WoS categories, containing 597 records, were considered as not connected with the topic and were removed from further analysis. In the case of the research area category, 70 out of 136 were left for analysis, and 420 records were removed from the searching results. Considering the fact that some incomplete records were sometimes in common for more than one category and that there were also the same publications in the removed WoS categories and research areas, 1580 publications were removed from the searching results, constituting nearly 3% of the total.
3.1. Main Outcomes of Cooperation
The analysis of cooperation was provided from the scope of the two countries with the highest number of documents: China and the USA.
Figure 3 shows the number of common publications for China (
Figure 3a) and other countries on the list, while
Figure 3b visualizes the same cooperation but for the USA. Both figures include the 15 top countries that cooperate the most with both countries. Descriptions related to a specific country or region were provided by the authors originally, and different characterizations (i.e., UK and England) result from this fact only and were not modified during analysis.
Chinese institutions cooperated most frequently with entities from the USA. This cooperation was effective in nearly 1600 documents. The second country, China, cooperated most frequently with Australia, reaching 1048 documents. International cooperation between China and the mentioned two countries covered over 50% of the total international cooperation of China. International cooperation from the USA was over 60 times lower, in terms of the number of publications, compared to China. Nearly 50% of cooperation of the USA was with China. It can also be noticed that both China and the USA cooperate roughly with the same countries, and their order, to some extent, reflects the sequence on the list of top publishing countries (
Table 4).
The analysis of cooperation according to the number of citations also shows that China reached almost 120,000 citations in total, as a result of cooperation with the top 15 countries. The USA reached a much lower number of citations, at nearly 20,000, which is approximately six times lower than for China. However, the comparison of these numbers with the total number of documents (
Figure 3) shows that documents that are the result of bilateral cooperation between the USA and other countries resulted in a 10 times higher number of citations per document, on average, compared to China. Cooperation between China and the USA produced 32.5% of citations counted as international from the Chinese point of view. In the case of the USA, the analogical number reaches 40.8%. The United Kingdom, Australia, Canada and Germany are among the countries producing the top number of citations in international collaboration with China and USA. (
Figure 4).
Interested information can be drawn when percentage of cited documents in international collaboration, are analysed (
Figure 5). An average percent of cited documents from international collaboration between China and other countries equals 90.95%, wile for USA it reached 100%. The results show that all publications related to USA cooperation seem to be scientifically significant, as all of them gained at least one citation. But it is worth to mention that only nearly 10% of scientific publications, being the result of Chinese international collaboration, hasn’t gained citations. On the bases of the above, an international cooperation of the two most significant countries is on the high scientific level and bring significant findings that can be applied in further investigations and practical activities.
Another insight into the problem may be achieved through the utilization of the Category Normalized Citation Index (CNCI). Normalization, in general, helps to analyze a single publication in a wider context. As an example, a paper’s citation count does not provide the whole information, i.e., the publication period, type of document or the frequency of citation in a specific research area. The CNCI is calculated by dividing the number of citations by the expected citation rate for documents with the same document type, year of publication and subject area. When a document is assigned to more than one subject area, the harmonic average is used. Results are shown in
Figure 6.
Further statistical characteristics of this index are presented in
Table 5. Results show that the average value of the CNCI for the USA equals 13.65, which is over seven times greater than for China (CNCI_China = 1.91). This shows that in a larger context, the quality of citations for papers from the USA can be considered as more favorable than papers from China. The variability index, defined as the relation of the average to standard deviation (m/σ), is also lower for the USA (2.55), while this value for China equals 4.66. The USA reached the highest values for cooperation with Norway (23.05) and England (21.84), while the lowest values were for Australia (5.44) and India (6.63). Analogous results for China are as follows: South Korea (2.66) and Austria (2.63) have the highest values, Germany (1.41) and Canada (1.47) the lowest.
An analysis of cooperation was also performed from the scope of international publications, especially those with the highest number of citations. The below analysis was carried out on the basis of the 100 top cited papers issued in cooperation with more than one country (
Table 6). The table shows a list of countries that have the highest number of publications as a result of international cooperation, and such publications are on the list of the top 100 most cited papers.
Figure 7 shows a visualization of bilateral cooperation in the form of lines. The width of each line reflects the number of produced citations within a specific cooperation. Numbers of total citations are provided next to each shape, with the number of common publications in brackets. It can be seen that the USA predominates in terms of mutual bilateral cooperation. The country has both the highest number of publications in the top 100 most cited and the highest number of total citations.
In the case of trilateral cooperation (
Figure 8), the USA also plays a leading role. Only three such publications according to the provided country affiliation were on the list of the top 100 most cited, and in each of the groups, scientists from the USA were involved. Similarly, as in the case of
Figure 3, the width of the bordering line of a set denotes the number of citations gained for the group.
3.2. Key Words Analysis
An analysis of key words was carried out separately for authors’ key words and for editorial key words. As many as 968 authors’ key words, with a total number of 37,545 appearances, were distinguished. However, only 62 words appeared more frequently than or equal to 100 times. For editor’s key words, in turn, 352 words or phrases were distinguished with a frequency greater than or equal to 100 times. As many as 2152 words were distinguished in total in both categories, with a total indications count of 185,454. A summary of both types of words is presented in
Table 7, while visualizations are shown in
Figure 9 and
Figure 10.
The analysis of authors’ key words shows that the most frequent phrase was “numerical simulation”, with a 2.66% share. The latter words reached a much lower share and did not exceed 1%. For editor key words, in turn, two words were predominant: “model” with 3.62% and “coal” with 2.16%. The three further key words exceeded a 1% share.
The visualization of both types of key words indicates the combinations and networks in which individual key words were present. The layout also organizes these key words and shows the most frequent links among them. Analyzing
Figure 9 and
Figure 10, it can be noticed that individual words have a tendency to group themselves in natural sets. To investigate this phenomenon in more detail, a clustering analysis was performed.
Clustering analysis was used for the evaluation of author and editor key words as well as research areas. On the basis of authors’ key words, the following main clusters were defined using the LSI labeling method, numbered from #0 to #10:
#0: climate change; CO2 emissions; energy efficiency; greenhouse gases; carbon caps renewable energy; energy policy; energy storage; electricity grid; Nansihu lake basin;
#1: coal gasification; gasification kinetics; drop tube furnace; initial crude; rheological curve|activation energy; Friedmann model; refuse plastic fuel; Arrhenius factor; toc removal;
#2: neural network; genetic algorithm; seismic tomography; evolutionary programming; simulated evolution|artificial neural network; predictive model; nonlinear regression model; heating value; cosine amplitude method;
#3: longwall mining; gob-side entry; backfilling body; self-stabilization structure; roof-controlled backfill ratio|numerical modeling; discrete element method; self-stabilization structure; roof-controlled backfill ratio; cutting test;
#4: coalbed methane; stress sensitivity; reservoir volume; multi-wing fractured well; multiple transportation mechanisms|hydraulic fracturing; gas seepage; stimulating reservoir volumes; triaxial testing; saline aquifer;
#5: numerical simulation; simple gray gas model; gray gases model; weighted sum; filtration rate|coal combustion; emissions reduction; sulfur dioxide; health risk; coal-fired power generation;
#6: CO2 capture; chemical looping combustion; coal power plants; heat exchanger; phase-change material|carbon capture; power plant; rapid temperature swing adsorption; hollow fiber; sensitivity analysis;
#7: vitrinite reflectance; burial history; basin modeling; temperature history; saxony basin|proximate analysis; ultimate analysis; carbon nanotube; fractal analysis; sensitivity analysis;
#8: source apportionment; factor analysis; chemical mass balance model; Lake Michigan; Milwaukee harbor|positive matrix factorization; indoor air quality; health risk assessment; sensitivity analysis; heavy metals;
#9: coal mining; water environment; mine water recycling; bi-level multi-objective programming; fractured coal|sensitivity analysis; chemical reaction kinetics; pollution reduction; percolation theory; potential index
#10: sustainable development; circular economy; coal industry; coal mining; critical factors|coal enterprises; supply chain management; functional framework; procedure accomplishment; c-erp system.
Selected results of the clustering analysis are presented in
Figure 11. Each cluster in the figure is marked with a different color and horizontal axes corresponding to the time period. The size of individual nodes on each axis denotes the concentration of phrases accounted to an individual cluster, while colored arched lines show items between clusters. It can be noticed that clusters from #0 to #5 are characterized with a relatively greater number of inter-cluster records. The highest concentrations of individual arches over horizontal axes are located in the same time periods for all clusters. However, this generally applies to the period 1998–2005, on average. Comparing this time period with
Figure 2, it can be seen that, to some extent, this corresponds to two significant increases in the number of publications: the first following the year 1991 and the second starting from 2006. Such a rapid increase would be effective in a potentially higher number of new topics and investigative aspects that should be formulated or named with new words or phrases. Before this time, all these new descriptions had been sorted out, and some of them were classified as inter-clustering. Together with the development of a more concise description of clusters and their evolution, the numbers of inter-clustering records have been steadily reducing, and in recent years, only an insignificant number of them have been classified as inter-cluster.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}