
Short-Term Wind Power Prediction Based on LightGBM and Meteorological Reanalysis

Abstract
:1. Introduction
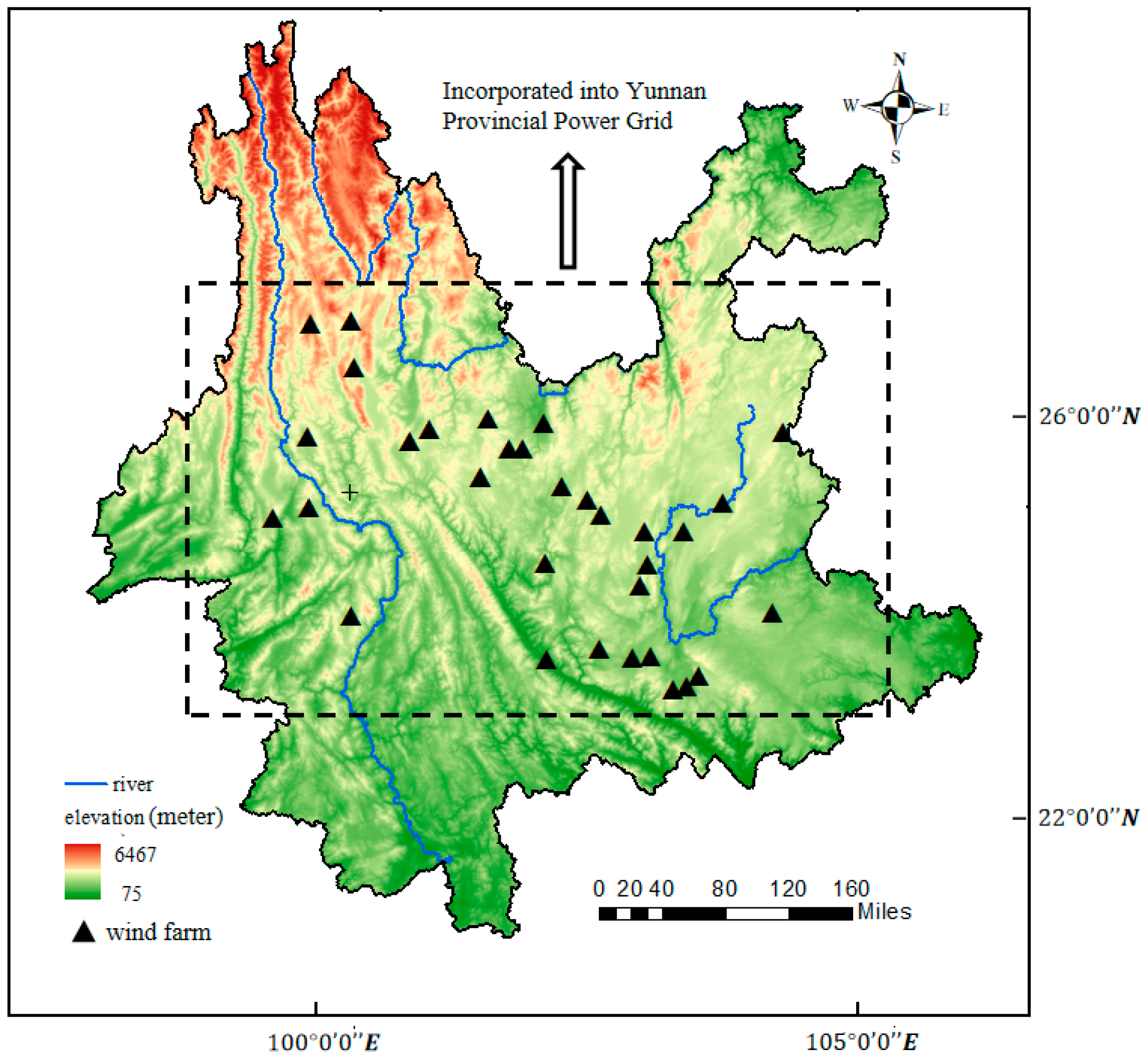
2. Data Acquisition
2.1. Data Introduction
2.2. Meteorological Data
3. Methodology
3.1. Noise Reduction of Wind Power Generation
- Add Gaussian white noise to the signal to be decomposed y(t), where t is the time. Obtain a new signal , where is the number of white noise experiments, is Gaussian white noise that satisfies a standard normal distribution, is the total number of modal components obtained by decomposition and can be obtained by referring to the standard table of white noise.where is the ith intrinsic mode function obtained after EMD, and the new signal is decomposed by EMD to obtain the first-order intrinsic mode function .
- The first intrinsic mode function of CEEMDAN is obtained by the overall average of the generated mode functions.where is the ith intrinsic mode function obtained after CEEMDAN.
- The following is used to calculate the residual after removing the first mode function.
- A new signal is obtained by adding Gaussian white noise with equal positive and negative values to . EMD is carried out with the new signal as the carrier to obtain the first-order mode function , so as to obtain the second intrinsic mode function of CEEMDAN.
- The following is used to calculate the residual after removing the second mode function.
- The above steps are repeated until the obtained residual signal becomes a monotonic function and cannot be decomposed, and the algorithm ends. The number of intrinsic mode functions obtained is , and the original signal is decomposed into:
3.2. Data Preprocessing
3.2.1. Wind Power Output Data Missing or Abnormal
3.2.2. Variable Scale of Meteorological Data
3.2.3. Feature Scaling
3.3. LightGBM Algorithm
3.4. Selection of Input Features
3.4.1. Autocorrelation Analysis of Wind Power
3.4.2. Meteorological Feature Selection via the Maximal Information Coefficient
3.4.3. Model Structure
3.5. Nonparametric Regression Based on the Gaussian Kernel Function
- The prediction error of wind power is the deviation between the predicted output and real output.where represents the deviation of wind power prediction at a certain time, represents the real value of wind power and represents the predicted value of wind power.
- Assuming that the probability distribution curve fitted by is , the symmetrical probability interval shall be adopted in the calculation process. That is, if the predicted wind power is and the probability is , the interval shall be:where stands for the inverse function of , that is, .
3.6. Evaluation Criteria of the Models
3.7. Overview of Framework
- Noise reduction is carried out on the historical output data of wind power to improve the validity of the data, and the autocorrelation analysis of daily average wind power output is carried out.
- Meteorological data are downloaded from ERA5 and preprocessed.
- All data are normalized.
- MIC is used to analyze the correlation between meteorological data and wind power data, and the meteorological data with high correlation are selected as the input.
- The output prediction is made under different input structures.
- The normalized wind power output is restored to the original level.
- Based on the prediction error, the probability distribution function is calculated based on nonparametric regression.
- The prediction interval of wind power output is obtained by combining probability distribution function.
4. Experimental Results and Discussion
4.1. Feature Selection
4.2. Analysis of Prediction Results
4.3. Impact and Comparison of Meteorological Input
4.4. Wind Power Interval Prediction and Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Global Wind Energy Council. Global Wind Report 2022. 2022. Available online: https://gwec.net/global-wind-report-2022/ (accessed on 20 April 2022).
- Available online: https://www.chinabaogao.com/data/202203/578991.html (accessed on 20 April 2022).
- Zhang, Z.; Ye, L.; Qin, H.; Liu, Y.; Wang, C.; Yu, X.; Yin, X.; Li, J. Wind speed prediction method using Shared Weight Long Short-Term Memory Network and Gaussian Process Regression. Appl. Energy 2019, 247, 270–284. [Google Scholar] [CrossRef]
- Tascikaraoglu, A.; Sanandaji, B.M.; Poolla, K.; Varaiya, P. Exploiting sparsity of interconnections in spatio-temporal wind speed forecasting using Wavelet Transform. Appl. Energy 2016, 165, 735–747. [Google Scholar] [CrossRef]
- Vargas, S.A.; Esteves, G.R.T.; Maçaira, P.M.; Bastos, B.Q.; Cyrino Oliveira, F.L.; Souza, R.C. Wind power generation: A review and a research agenda. J. Clean. Prod. 2019, 218, 850–870. [Google Scholar] [CrossRef]
- Feng, C.; Cui, M.; Hodge, B.; Zhang, J. A data-driven multi-model methodology with deep feature selection for short-term wind forecasting. Appl. Energy 2017, 190, 1245–1257. [Google Scholar] [CrossRef]
- Yuan, X.; Tan, Q.; Lei, X.; Yuan, Y.; Wu, X. Wind power prediction using hybrid autoregressive fractionally integrated moving average and least square support vector machine. Energy 2017, 129, 122–137. [Google Scholar] [CrossRef]
- Wang, K.; Qi, X.; Liu, H.; Song, J. Deep belief network based k-means cluster approach for short-term wind power forecasting. Energy 2018, 165, 840–852. [Google Scholar] [CrossRef]
- Gupta, R.A.; Kumar, R.; Bansal, A.K. BBO-based small autonomous hybrid power system optimization incorporating wind speed and solar radiation forecasting. Renew. Sustain. Energy Rev. 2015, 41, 1366–1375. [Google Scholar] [CrossRef]
- Zhang, S.; Chen, Y.; Xiao, J.; Zhang, W.; Feng, R. Hybrid wind speed forecasting model based on multivariate data secondary decomposition approach and deep learning algorithm with attention mechanism. Renew. Energy 2021, 174, 688–704. [Google Scholar] [CrossRef]
- Sanjari, M.J.; Gooi, H.B.; Nair, N.K.C. Power Generation Forecast of Hybrid PV–Wind System. IEEE Trans. Sustain. Energy 2020, 11, 703–712. [Google Scholar] [CrossRef]
- Jahangir, H.; Golkar, M.A.; Alhameli, F.; Mazouz, A.; Ahmadian, A.; Elkamel, A. Short-term wind speed forecasting framework based on stacked denoising auto-encoders with rough ANN. Sustain. Energy Technol. Assess. 2020, 38, 100601. [Google Scholar] [CrossRef]
- Zameer, A.; Arshad, J.; Khan, A.; Raja, M.A.Z. Intelligent and robust prediction of short term wind power using genetic programming based ensemble of neural networks. Energy Convers. Manag. 2017, 134, 361–372. [Google Scholar] [CrossRef]
- Guo, Z.; Chi, D.; Wu, J.; Zhang, W. A new wind speed forecasting strategy based on the chaotic time series modelling technique and the Apriori algorithm. Energy Convers. Manag. 2014, 84, 140–151. [Google Scholar] [CrossRef]
- Cheng, L.; Yu, T. A new generation of AI: A review and perspective on machine learning technologies applied to smart energy and electric power systems. Int. J. Energy Res. 2019, 43, 1928–1973. [Google Scholar] [CrossRef]
- Wang, Y.; Zou, R.; Liu, F.; Zhang, L.; Liu, Q. A review of wind speed and wind power forecasting with deep neural networks. Appl. Energy 2021, 304, 117766. [Google Scholar] [CrossRef]
- Hu, Q.; Zhang, R.; Zhou, Y. Transfer learning for short-term wind speed prediction with deep neural networks. Renew. Energy 2016, 85, 83–95. [Google Scholar] [CrossRef]
- Chang, G.; Lu, H.; Chang, Y.; Lee, Y. An improved neural network-based approach for short-term wind speed and power forecast. Renew. Energy 2017, 105, 301–311. [Google Scholar] [CrossRef]
- Santamaría-Bonfil, G.; Reyes-Ballesteros, A.; Gershenson, C. Wind speed forecasting for wind farms: A method based on support vector regression. Renew. Energy 2016, 85, 790–809. [Google Scholar] [CrossRef]
- Lahouar, A.; Ben Hadj Slama, J. Hour-ahead wind power forecast based on random forests. Renew. Energy 2017, 109, 529–541. [Google Scholar] [CrossRef]
- Zhang, Y.; Han, J.; Pan, G.; Xu, Y.; Wang, F. A multi-stage predicting methodology based on data decomposition and error correction for ultra-short-term wind energy prediction. J. Clean. Prod. 2021, 292, 125981. [Google Scholar] [CrossRef]
- Park, J.; Moon, J.; Jung, S.; Hwang, E. Multistep-Ahead Solar Radiation Forecasting Scheme Based on the Light Gradient Boosting Machine: A Case Study of Jeju Island. Remote Sens. 2020, 12, 2271. [Google Scholar] [CrossRef]
- Ju, Y.; Sun, G.; Chen, Q.; Zhang, M.; Zhu, H.; Rehman, M.U. A Model Combining Convolutional Neural Network and LightGBM Algorithm for Ultra-Short-Term Wind Power Forecasting. IEEE Access 2019, 7, 28309–28318. [Google Scholar] [CrossRef]
- Musbah, H.; Ali, G.; Aly, H.H.; Little, T.A. Energy management using multi-criteria decision making and machine learning classification algorithms for intelligent system. Electr. Power Syst. Res. 2022, 203, 107645. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, N.; Chen, Q.; Kirschen, D.S.; Li, P.; Xia, Q. Data-Driven Probabilistic Net Load Forecasting with High Penetration of Behind-the-Meter, P.V. IEEE Trans. Power Syst. 2018, 33, 3255–3264. [Google Scholar] [CrossRef]
- Danandeh Mehr, A.; Jabarnejad, M.; Nourani, V. Pareto-optimal MPSA-MGGP: A new gene-annealing model for monthly rainfall forecasting. J. Hydrol. 2019, 571, 406–415. [Google Scholar] [CrossRef]
- Olauson, J. ERA5: The new champion of wind power modelling? Renew. Energy 2018, 126, 322–331. [Google Scholar] [CrossRef]
- Yunnan Provincial Energy Bureau of China. Yunnan Energy Briefing. 2021. Available online: http://nyj.yn.gov.cn/nydt/ynnydt/202102/t20210201_1305054.html (accessed on 3 April 2022).
- Qu, Z.; Mao, W.; Zhang, K.; Zhang, W.; Li, Z. Multi-step wind speed forecasting based on a hybrid decomposition technique and an improved back-propagation neural network. Renew. Energy 2019, 133, 919–929. [Google Scholar] [CrossRef]
- Luo, X.; Yuan, X.; Zhu, S.; Xu, Z.; Meng, L.; Peng, J. A hybrid support vector regression framework for streamflow forecast. J. Hydrol. 2019, 568, 184–193. [Google Scholar] [CrossRef]
- Lin, Y.; Yang, M.; Wan, C.; Wang, J.; Song, Y. A Multi-Model Combination Approach for Probabilistic Wind Power Forecasting. IEEE Trans. Sustain. Energy 2019, 10, 226–237. [Google Scholar] [CrossRef]
- Wan, C.; Zhao, C.; Song, Y. Chance Constrained Extreme Learning Machine for Nonparametric Prediction Intervals of Wind Power Generation. IEEE Trans. Power Syst. 2020, 35, 3869–3884. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, Y.; Pan, G.; Zhang, J. Wind Speed Interval Prediction Based on Lorenz Disturbance Distribution. IEEE Trans. Sustain. Energy 2020, 11, 807–816. [Google Scholar] [CrossRef]
- Jiang, Y.; Huang, G.; Yang, Q.; Yan, Z.; Zhang, C. A novel probabilistic wind speed prediction approach using real time refined variational model decomposition and conditional kernel density estimation. Energy Convers. Manag. 2019, 185, 758–773. [Google Scholar] [CrossRef]
- Knoben, W.J.M.; Freer, J.E.; Woods, R.A. Technical note: Inherent benchmark or not? Comparing Nash-Sutcliffe and Kling-Gupta efficiency scores. Hydrol. Earth Syst. Sci. 2019, 23, 4323–4331. [Google Scholar] [CrossRef]
- Tian, Z.; Chen, H. A novel decomposition-ensemble prediction model for ultra-short-term wind speed. Energy Convers. Manag. 2021, 248, 114775. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Variable | Description | Units |
|---|---|---|---|
| 1 | u100 | West wind at 100 m elevation | m · s−1 |
| 2 | v100 | South wind at 100 m elevation | m · s−1 |
| 3 | u10n | West wind of neutral wind at 10 m elevation | m · s−1 |
| 4 | u10 | West wind at 10 m elevation | m · s−1 |
| 5 | v10n | South wind of neutral wind at 10 m elevation | m · s−1 |
| 6 | v10 | South wind at 10 m elevation | m · s−1 |
| 7 | fg10 | 10 m wind gust since previous post-processing (since the parameter was last archived in a particular forecast) | m · s−1 |
| 8 | d2m | 2 m dewpoint temperature | K |
| 9 | t2m | 2 m temperature | K |
| 10 | i10fg | Instantaneous 10 m wind gust | m · s−1 |
| 11 | cdir | Clear-sky direct solar radiation at surface | J · m−2 |
| 12 | e | Evaporation | mm |
| 13 | mx2t | Maximum 2 m temperature since previous post-processing | K |
| 14 | megwss | Mean eastward gravity wave surface stress | N · m−2 |
| 15 | mgwd | Mean gravity wave dissipation | W · m−2 |
| 16 | mngwss | Mean northward gravity wave surface stress | N · m−2 |
| 17 | mn2t | Minimum 2 m temperature since previous post-processing | K |
| 18 | skt | Skin temperature | K |
| 19 | es | Snow evaporation | mm |
| 20 | stl1 | Soil temperature level 1 | K |
| 21 | slhf | Surface latent heat flux | J · m−2 |
| 22 | sp | Surface pressure | Pa |
| 23 | p59 | Mean eastward turbulent surface stress | N · m−2 |
| No | Variable | MIC | Units |
|---|---|---|---|
| 1 | u10 | 0.694 | m · s−1 |
| 2 | u10n | 0.682 | m · s−1 |
| 3 | fg10 | 0.662 | m · s−1 |
| 4 | u100 | 0.645 | m · s−1 |
| 5 | i10fg | 0.640 | m · s−1 |
| 6 | t2m | 0.583 | K |
| 7 | mgwd | 0.577 | W · m−2 |
| 8 | megwss | 0.543 | N · m−2 |
| 9 | sp | 0.523 | Pa |
| 10 | d2m | 0.483 | K |
| 11 | v10 | 0.467 | m · s−1 |
| 12 | v10n | 0.462 | m · s−1 |
| 13 | v100 | 0.435 | m · s−1 |
| 14 | mx2t | 0.405 | K |
| 15 | mngwss | 0.374 | N · m−2 |
| 16 | mn2t | 0.364 | K |
| 17 | skt | 0.352 | K |
| 18 | es | 0.343 | m of water equivalent |
| 19 | stl1 | 0.274 | K |
| 20 | slhf | 0.258 | J · m−2 |
| 21 | p59 | 0.189 | N · m−2 |
| 22 | cdir | 0.154 | J · m−2 |
| 23 | e | 0.102 | m of water equivalent |
| No | Input |
|---|---|
| 1 | , |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 | |
| 16 | |
| 17 | |
| 18 | |
| 19 | |
| 20 | |
| 21 | |
| 22 | |
| 23 |
| No. | Description | Index | Unit | MIC | Type |
|---|---|---|---|---|---|
| 1 | power on day d-1 | W | - | Obs | |
| 2 | power on day d-2 | W | - | Obs | |
| 3 | power on day d-3 | W | - | Obs | |
| 4 | power on day d-4 | W | - | Obs | |
| 5 | 10 m u-component of wind | u10 | m · s−1 | 0.694 | ERA5 |
| 6 | 10 m u-component of neutral wind | u10n | m · s−1 | 0.682 | ERA5 |
| 7 | 10 m wind gust since previous post-processing | fg10 | m · s−1 | 0.662 | ERA5 |
| 8 | 100 m u-component of wind | u100 | m · s−1 | 0.645 | ERA5 |
| 9 | Instantaneous 10 m wind gust | i10fg | m · s−1 | 0.640 | ERA5 |
| 10 | 2 m temperature | t2m | K | 0.583 | ERA5 |
| 11 | Mean gravity wave dissipation | mgwd | W · m−2 | 0.577 | ERA5 |
| 12 | Mean eastward gravity wave surface stress | megwss | N · m−2 | 0.543 | ERA5 |
| 13 | Surface pressure | sp | Pa | 0.523 | ERA5 |
| 14 | 2 m dewpoint temperature | d2m | K | 0.483 | ERA5 |
| 15 | 10 m v-component of wind | v10 | m · s−1 | 0.467 | ERA5 |
| Parameter | Screening Scope | Selected Result |
|---|---|---|
| Learning rate | 0.1, 0.2, …, 0.6 | 0.1 |
| Feature fraction | 0.5, 0.6, …, 1.0 | 0.8 |
| Num leaves | 8, 16, 32, 64, 128 | 16 |
| Max depth | 1, 2, …, 9 | 3 |
| Model | RMSE (MW) | MAE (MW) | CORR | KGE | IA | |
|---|---|---|---|---|---|---|
| train | LightGBM-MIC | 373 | 287 | 0.940 | 0.898 | 0.967 |
| XGBoost-MIC | 386 | 301 | 0.932 | 0.874 | 0.966 | |
| RF-MIC | 472 | 359 | 0.922 | 0.870 | 0.954 | |
| SVR-MIC | 584 | 452 | 0.904 | 0.839 | 0.938 | |
| test | LightGBM-MIC | 551 | 425 | 0.927 | 0.869 | 0.959 |
| XGBoost-MIC | 584 | 437 | 0.917 | 0.853 | 0.952 | |
| RF-MIC | 620 | 471 | 0.908 | 0.840 | 0.947 | |
| SVR-MIC | 678 | 541 | 0.879 | 0.814 | 0.926 |
| Model | Input | RMSE | MAE | CORR | KGE | IA |
|---|---|---|---|---|---|---|
| LightGBM | Four traditional meteorological characteristics | 734 | 536 | 0.863 | 0.806 | 0.907 |
| LightGBM-MIC | Eleven meteorological characteristics | 551 | 425 | 0.927 | 0.869 | 0.959 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, S.; Tian, X.; Liu, B.; Liu, T.; Su, H.; Zhou, B. Short-Term Wind Power Prediction Based on LightGBM and Meteorological Reanalysis. Energies 2022, 15, 6287. https://doi.org/10.3390/en15176287
Liao S, Tian X, Liu B, Liu T, Su H, Zhou B. Short-Term Wind Power Prediction Based on LightGBM and Meteorological Reanalysis. Energies. 2022; 15(17):6287. https://doi.org/10.3390/en15176287
Chicago/Turabian StyleLiao, Shengli, Xudong Tian, Benxi Liu, Tian Liu, Huaying Su, and Binbin Zhou. 2022. "Short-Term Wind Power Prediction Based on LightGBM and Meteorological Reanalysis" Energies 15, no. 17: 6287. https://doi.org/10.3390/en15176287