1. Introduction
Visual Object Tracking (VOT) is one of the categories in computer vision and plays an important role in various tasks. VOT is widely used in video analysis application programs such as factory automation monitoring, autonomous driving, intruder monitoring, and drone tasks [
1,
2,
3,
4]. In particular, more recently, VOT analyzes a relationship between similar pixels in different frames. The information of the tracking target is initialized using the information of ground truth of the first frame in the image sequence. The output result of the tracking algorithm provides a boundary box that displays the size and location of the target for a specific frame in the image sequence [
5,
6,
7].
However, it has a constraint of using only limited information obtained in the first frame. This constraint causes a tracker to drift in the image sequence and tracking failure to increase if prior information about robust representation that can represent an object well is not sufficient [
8,
9]. Despite there being studies conducted on performance improvements of VOT algorithms, many difficulties still need to be overcome. In the tracking process, situations of failing to robustly respond to changes in features of the target object occur due to various factors, namely shape, illumination variation, and scene distortion that are applied to a video sequence. This results in object tracking failure as a discrepancy between the current target and the original template takes effect [
10,
11].
A number of various approaches have been proposed to solve these problems in object tracking. A tracker extracts the distinctive robust feature, which is the main key feature, from the target to the extent that the target attributes can be expressed. Using this feature, an appearance is modeled to find the target from the image frame area and remove the external noise elements. To capture a change in the target shape during the tracking process, ultimately an effective feature for object tracking should be designed. Generally, attributes that change in the object’s appearance model over time should be reflected or unique features that can represent the object should be extracted.
As methods based on features, there are the correlation filter-based approach and the deep neural network approach. A tracking algorithm based on a correlation filter generates a filter through appearance modeling using the extracted object’s features. Filter weight is updated to run training from image samples of the object region that are continuously inputted while tracking progress. This training is performed in the Fourier domain using a fast Fourier transform (FFT) [
12,
13]. The correlation filter-based method has the advantage of fast operation speed by being computationally efficient. However, its drawback is that image information is represented inaccurately as its information is disturbed, which is caused by a boundary effect [
14].
Recent study methods have focused on deep features based on deep learning, shifting from existing hand-crafted methods. A deep feature extraction method offers many advantages of being more apt to encode multi-layer information through multiple layers and being more invariant to changes in target shapes than a hand-crafted feature extraction method. Thus, it is regarded as the key element to overcome the limitation of traditional tracking algorithms. To robustly track an object using deep features, a correlation filter approach is used [
15,
16]. However, a correlation filter method has to continuously update an appearance model in the tracking process, because even if robust features are added, the original template model gets corrupted by the surrounding background. A deep network provides a generalization capability that captures various features by various training datasets and many parameters in a network. However, a drawback of this is that it cannot adaptively respond to appearance changes, deformation, occlusion, etc.
In this paper, unique features of the target object are extracted using a convolutional neural network (CNN) and then used in the object tracking algorithm. Using high-level features extracted in a CNN, we regard a tracking problem as a similarity comparison problem that finds a specific object within the image. Calculating image similarity entails finding feature compatibility in an image patch and comparing the features of the target object and the features of objects in the image plane. To do this, we created a customized CNN with a Siamese network, which is an architecture with a Y-shaped branch of two same CNNs. This network outputs similar feature information because the same operation is applied to the target object image and an image containing the object using the same weight. We conducted feature extraction and similarity comparison with one-shot learning through this network. A region proposal network (RPN) was used to infer a region where the target object was present from the region with the highest similarity. Using the proposed tracker, deep features of the object were extracted in real time, thereby emphasizing the distinctiveness between objects themselves or between object and background through the feature similarity comparison. Through this, we could improve the tracking algorithm’s performance. In particular, we have shown a robust performance in appearance change and distraction factors. There are three contributions to this work.
We analyze features for object tracking using CNNs trained on large image datasets to find important properties. The features of CNNs show better results than traditional tracking algorithms using hand-crafted features, helping to design effective CNN-based trackers.
We propose a method to combine two CNNs with the same structure to form a Siamese network to handle sudden appearance changes and track target objects through similarity comparison between two images.
The proposed tracking algorithm greatly mitigates object drift. We improved the tracking accuracy by introducing the anchor box concept that estimates the object area through similarity comparison between feature maps extracted from CNN. The evaluation of popular tracking benchmarks shows that the proposed method handles a variety of challenging problems well and has good tracking performance.
The present paper is organized as follows: In
Section 2, studies on Siamese networks and correlation tracking are summarized, while in
Section 3, a fully convolutional Siamese network is described for object tracking. Then, in
Section 4, the performance comparison of experimental results between the proposed tracking algorithm and other latest tracking algorithms is presented. Lastly, in
Section 5, the conclusion of this study and future research direction are presented.
3. Proposed Method
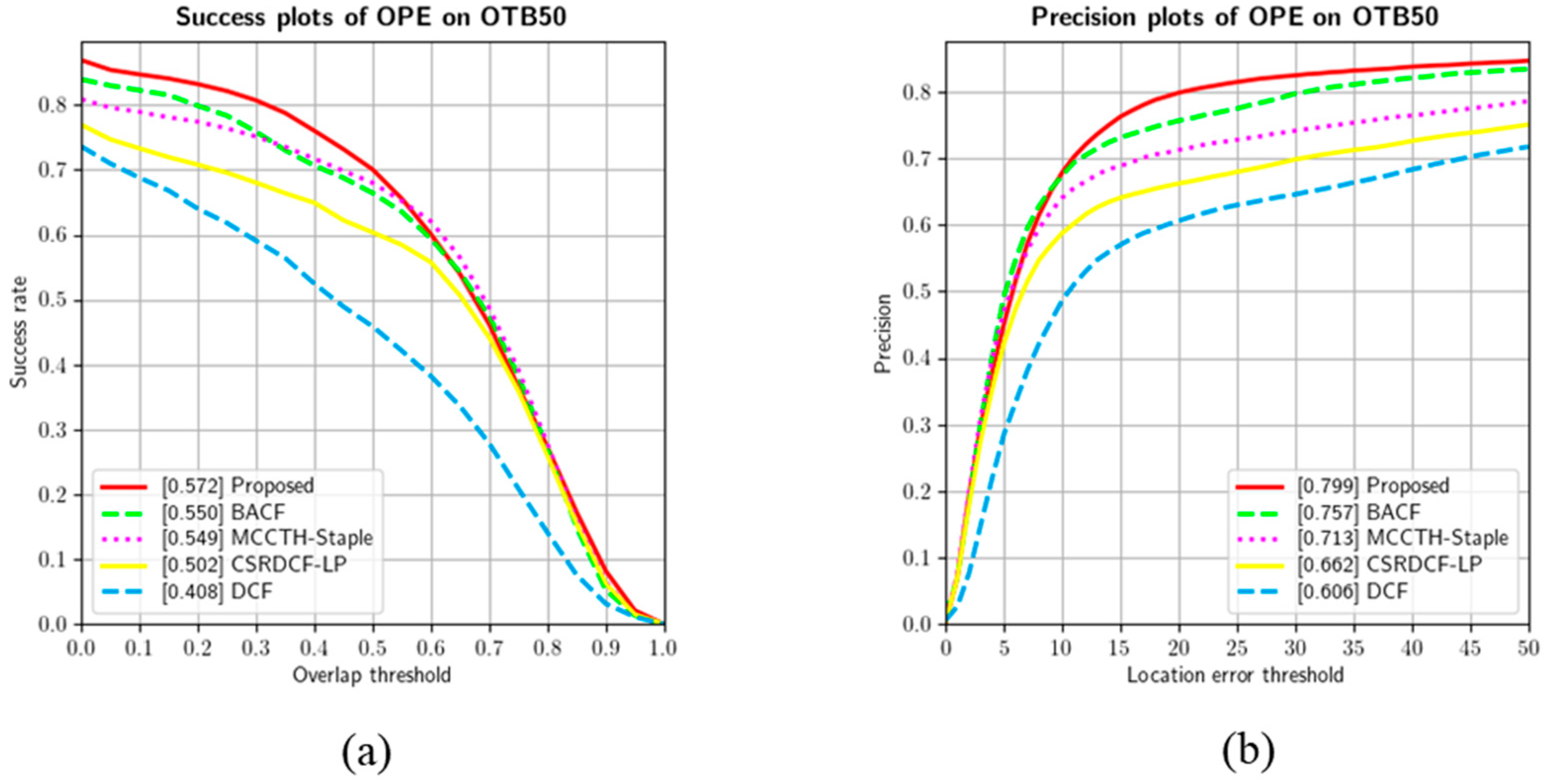
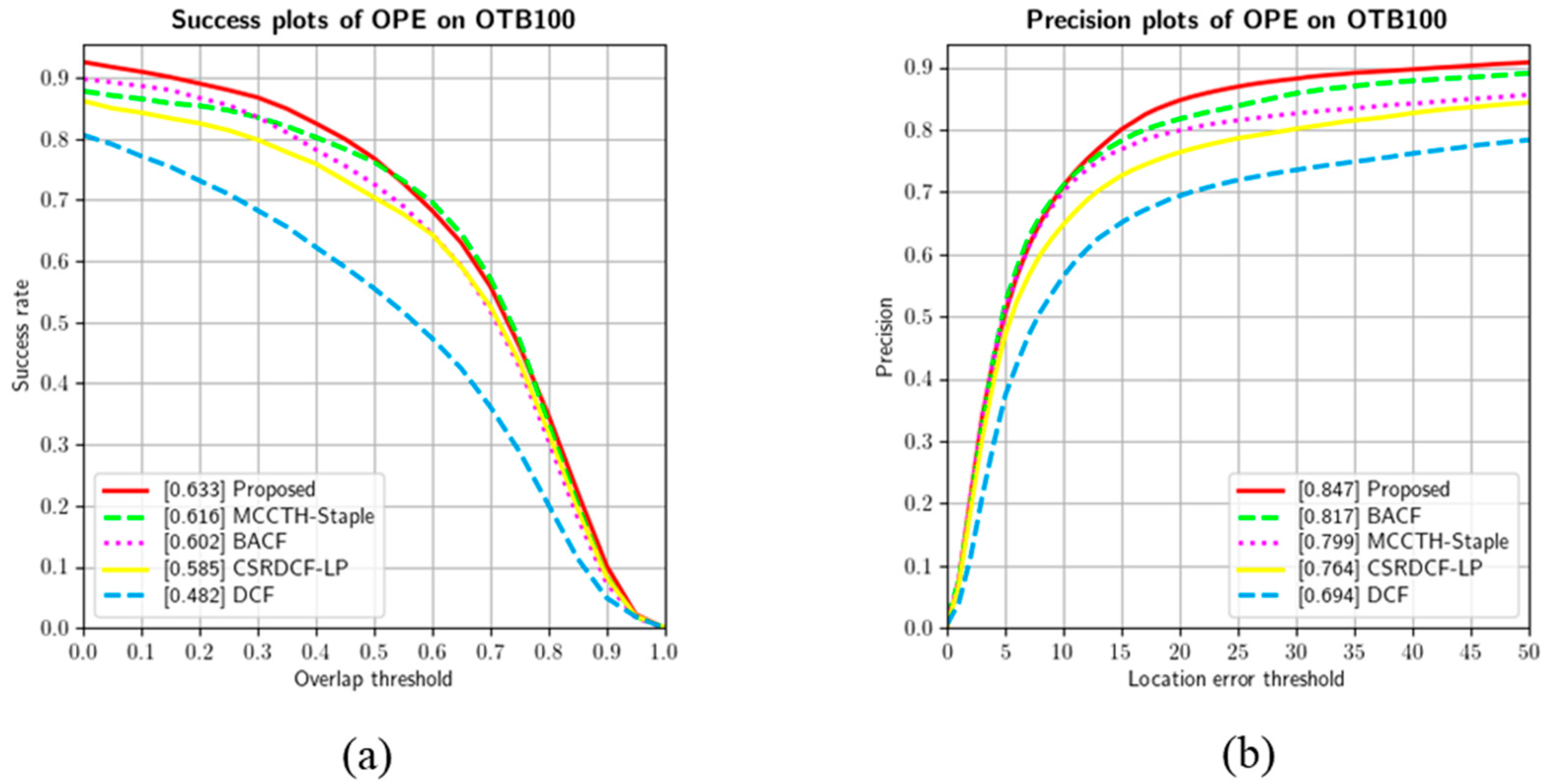
In this section, the proposed network for tracking as shown in
Figure 2 is described. The proposed network employs two images as the input specified as target object and searches images. The object region coordinates them, and information about the presence of the target object are extracted as the inputs pass through the fully CNN-based backbone network and RPN. The backbone network that extracts object features was designed with a customized structure and modified into a Siamese network form. In
Figure 2b, weight sharing means that each kernel of the convolution layer has the same weight. Two images input to the network pass through the same network and output a value indicating similarity. At this time, if the weights are not shared, it is structurally the same network, but it is difficult to obtain the correct result for the input data because different weights are learned. Therefore, the network is learned using the loss value output in
Figure 2c, and the weights have the same value in this process.
3.1. Convolution Block for Feature Extraction
The most in-demand part of computation in a CNN is a fully connected layer, with the network proposed in this study shown as a full CNN, in which fully connected layers are removed and replaced with convolution layers. The computation amount in convolution layers increases with the number of kernels used for feature extraction. A convolution layer was designed by converting it to a bottleneck layer structure to reduce the computation amount. A bottleneck layer structure is effective in reducing the number of parameters by changing the internal structure of the network. In Equation (1), the number of parameters in the network is calculated.
Figure 3 shows comparison of the No. of Parameters in a convolution layer.
The bottleneck structure consists of a three-step cycle of output compression, feature extraction using convolution, and output expansion. The output compression employs a 1 × 1 convolution. A kernel a size of 1 × 1 is used when adjusting the number of input feature maps. The output feature map in the previous layer is used as the input in the next layer. If feature maps are extracted using a smaller number of kernels than the number of input feature maps, the number of feature maps is reduced, thereby significantly decreasing the computation amount. In the feature extraction step, convolution is conducted using a kernel with a size of N × N. In the last output expansion step, the dimension is increased from a 1 × 1 to 3 × 3 convolution. Since the amount of computation and the number of parameters that are linked between layers are significantly reduced if a layer is designed with the bottleneck structure, a deeper network can be designed and learned with the same computing and time resource.
Figure 4 shows the convolution block used in the proposed network, in which each block is composed of one or more bottleneck layers.
The bottlenecks were arranged reflecting the CNN’s characteristic that extracts significant features in the bottlenecks near the input layer, followed by semantic features more and more near the end. To extract more semantic features, a convolution block structure consisting of bottlenecks was iterated to increase the number of kernels, aiming to extract feature information to the highest extent. If the continuous bottleneck structure is used, it is likely for there to be a loss of information. Thus, if more than two structures are iterated, the information flow is preserved by connecting the information in the input feature map to the output feature map.
3.2. Siamese Network Architecture
A Siamese network is a neural network architecture consisting of two or more of the same networks. A Siamese network shares the same parameters and weights. The parameter update can be performed by mirroring two sub-networks.
Figure 5 shows the basic structure diagram of a Siamese network. By comparing feature vectors extracted from two input images, parameters are trained to find the similarity. In a general neural network, a method to predict many classes is trained. If a new class is added or removed to/from a dataset, a problem occurs. In such a case, the neural network has to be updated and the entire dataset should be re-trained. A large amount of data is needed to train a neural network, whereas a Siamese network can train a similarity function to verify whether the appearances of two images are the same.
Figure 5 shows the network structure used to solve the tracking problem. To increase the number of kernels that extract features, a convolution block is layered in the design. The final output feature map in the tracking object region is 18 × 18 × 256 in size, while the final output feature map in the search region is 34 × 34 × 256 in size.
3.3. Region Proposal Network
The RPN is known as a very effective method for object detection. The main purpose of this network is to infer specific objects and regions that are present in the images. This network was introduced in the paper “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks” [
33]. The region proposal is conducted by regressing the center coordinate of the anchor box in the regions where the object is likely to exist inside the image.
For the object region, a feature map that can be obtained in the last layer in the CNN is used, with
Figure 6 showing the structure of the RPN. An anchor box is arranged in every cell of the feature map with a size of N × N. The number of anchor boxes used in the region proposal can be selected by a user, and the use of anchor boxes of various sizes has an advantage of inferring accurate regions. On the other hand, as the number of anchor boxes increases, so does the number of computations.
The key of the RPN is to infer a coordinate of the anchor box through regression and determine whether an object is present. An anchor box includes four values of centerX, centerY, width, and height. The number of anchor boxes used in the inference is determined according to the box scale and aspect ratio. For example, if the scale is three, and the aspect ratio is three, nine anchor boxes are created. The created anchor boxes are positioned in each cell of the feature map. CenterX and centerY are fixed for each anchor box while the width and height are determined by a ratio of the bounding box width and height of the target object.
A probability of object existence is assigned to each created anchor box. If this is zero, no object is present, while a one means that the object is present. The number of probabilities is proportional to the number of anchor boxes. Let us assume that nine anchor boxes are assigned to a feature map of 17 × 17 in size. Then, the number of coordinates to be inferred is calculated as 17 × 17 × 9 × 4 = 10,404, and the number of anchor boxes to be created as 17 × 17 × 9 = 2601. Whether the object is present is determined using the final 2601 probabilities. The final region is assigned by combining anchor boxes where the object is present. In this study, one scale and five sizes of aspect ratios were designated, and the final number of anchor boxes was five.
Figure 7 shows the proposed RPN structure. For its input, a target object feature map of 18 × 18 × 256 in size, which was extracted through the Siamese network, and a search region feature map with a size of 34 × 34 × 256, were used. These feature maps were converted into four feature maps via the convolution layer, which extracts regression and object existence probability values.
At first, feature maps for the anchor box regression values for 256 feature maps were extracted for the target object. The number of obtained output feature maps was calculated as 256 × 5 × 4 = 5120. The values for determining whether the object is present for the same feature map were extracted. Then, 256 × 5 × 2 = 2560 values could be obtained. In the search region, the same numbers of input and output feature maps were applied and computed for the coordinate regression and object existence.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}